表格型算法的局限:
基于表格(Tabular Methods)的传统强化学习(问蒙特卡洛 MC 、动态规划 DP 策略/价值迭代 ,以及 Q-Learning)中,由于所有状态和动作价值都必须依赖一个物理二维矩阵进行显式存储与查表 ,它们在面对稍复杂的现实任务时,就会暴露出一系列致命的劣势:
1. 致命的"维度灾难"(Curse of Dimensionality)
这是表格型算法最根本的痛点 。
- 痛点本质: 表格的大小等于 {总状态数} *{总动作数} 。一旦环境的特征维度增加,状态空间将呈指数级爆炸 。
2. 完全无法处理"连续值"空间(Continuous Spaces)
现实世界中的物理量往往不是一格一格的,而是连续的(例如自动驾驶中方向盘转动的绝对角度、油门踏板开度、或者摄像头拍下的连续像素画面) 。
-
痛点本质: 表格型算法要求状态和动作必须是可数的、离散的。
-
妥协代价: 如果硬要用表格解决,就必须对连续值进行强行切块(离散化分桶)。然而,切得太粗(如方向盘只分左转、直行、右转)会导致控制极度粗糙、智能体频繁画龙;切得太细(如每 0.1 度切一格),又会直接触发上述的第一条"维度灾难" 。
3. 极其低效的"泛化能力"(Zero Generalization)
表格型算法的记忆是完全孤立的,它不具备"举一反三"的推理联想能力。
-
痛点本质: 在神经网络中,相似的状态(比如图片像素只是变动了一点点)会激活相似的神经元,从而共享决策。但在表格中,
Q[状态1, 动作A]和Q[状态2, 动作A]在物理内存上是两个风马牛不相及的独立格子。 -

4. 样本利用率低下(Poor Sample Efficiency)
由于缺乏泛化能力,表格中的每一个格子都必须被智能体的肉身实实在在地踩到过很多次(充分探索),其数值才能够通过时间差分或增量均值稳定收敛 。
- 对于拥有数千万格子的环境,要让表格完全收敛,智能体需要与环境交互几十亿次。在游戏模拟器里这只是耗费时间,但如果是在真实的机器人控制、自动驾驶实车或昂贵的医疗试验中,这种试错成本是人类绝对无法承受的 。
DQN 、PPO 等深度强化学习应运而生
👑 时代的分水岭:为什么 model.py 在这里苏醒了?
为了解决上述表格型算法的全部劣势,人工智能史上演进了最重要的一次技术融合:用深度神经网络(DNN/CNN)作为非线性函数逼近器,去替代这张冰冷、死板的物理表格 。
-
网络的输入可以直接是连续的值(如精确坐标或屏幕像素),再也不需要您在代码里费尽心思做二进制位运算拼接编码了 。
-
整个网络只需要保存一套权重参数,内存占用极小,彻底斩断了维度灾难 。
-
神经网络天然具备极强的泛化与联想能力,在相似的位置它能自动推理出相似的动作,让学习效率发生了质的飞跃 。
DQN
在某些环境中,由于状态每一维度的值都是连续的,无法使用表格记录,因此一个常见的解决方法便是使用函数拟合(function approximation)的思想。
由于神经网络具有强大的表达能力,因此我们可以用一个神经网络来表示函数。若动作是连续(无限)的,神经网络的输入是状态和动作,然后输出一个标量,表示在状态下采取动作能获得的价值。
若动作是离散(有限)的,除了可以采取动作连续情况下的做法,我们还可以只将状态输入到神经网络中,使其同时输出每一个动作的值。
通常 DQN(以及 Q-learning)只能处理动作离散的情况。
那么 Q 网络的损失函数是什么呢?我们先来回顾一下 Q-learning 的更新规则
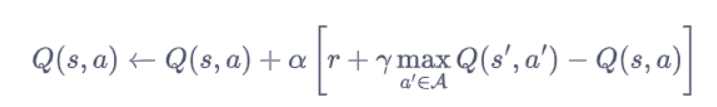
上述公式用时序差分 (temporal difference,TD)学习目标来增量式更新,也就是说要使和 TD 目标靠近。于是,对于一组数据,我们可以很自然地将 Q 网络的损失函数构造为均方误差**(MSE)**的形式:
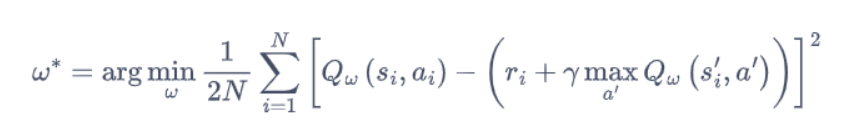
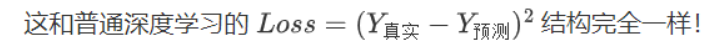
至此,我们就可以将 Q-learning 扩展到神经网络形式------深度 Q 网络(deep Q network,DQN)算法。
经验回放:
在一般的有监督学习中,假设训练数据是独立同分布的,我们每次训练神经网络的时候从训练数据中随机采样一个或若干个数据来进行梯度下降,随着学习的不断进行,每一个训练数据会被使用多次。在原来的 Q-learning 算法中,每一个数据只会用来更新一次值。
为了更好地将 Q-learning 和深度神经网络结合,DQN 算法采用了经验回放 (experience replay)方法,具体做法为维护一个回放缓冲区,将每次从环境中采样得到的四元组数据(状态、动作、奖励、下一状态)存储到回放缓冲区中,训练 Q 网络的时候再从回放缓冲区中随机采样若干数据来进行训练。这么做可以起到以下两个作用。
(1)使样本满足独立假设。在 MDP 中交互采样得到的数据本身不满足独立假设,因为这一时刻的状态和上一时刻的状态有关。非独立同分布的数据对训练神经网络有很大的影响,会使神经网络拟合到最近训练的数据上。采用经验回放可以打破样本之间的相关性,让其满足独立假设。
(2)提高样本效率。每一个样本可以被使用多次,十分适合深度神经网络的梯度学习。
目标网络:

综上所述,DQN 算法的具体流程如下:


前向传播:
一、 前向传播的具体步骤
前向传播的本质,就是极其密集的矩阵乘法 和加法。数据就像流水一样,从左边的输入层,一层一层地流向右边的输出层。
在一个标准的神经元内部,数据流入时会经历两道工序:
二、 在 DQN 里的前向传播
把这个过程代入到你熟悉的 DQN 迷宫游戏中:
反向传播:
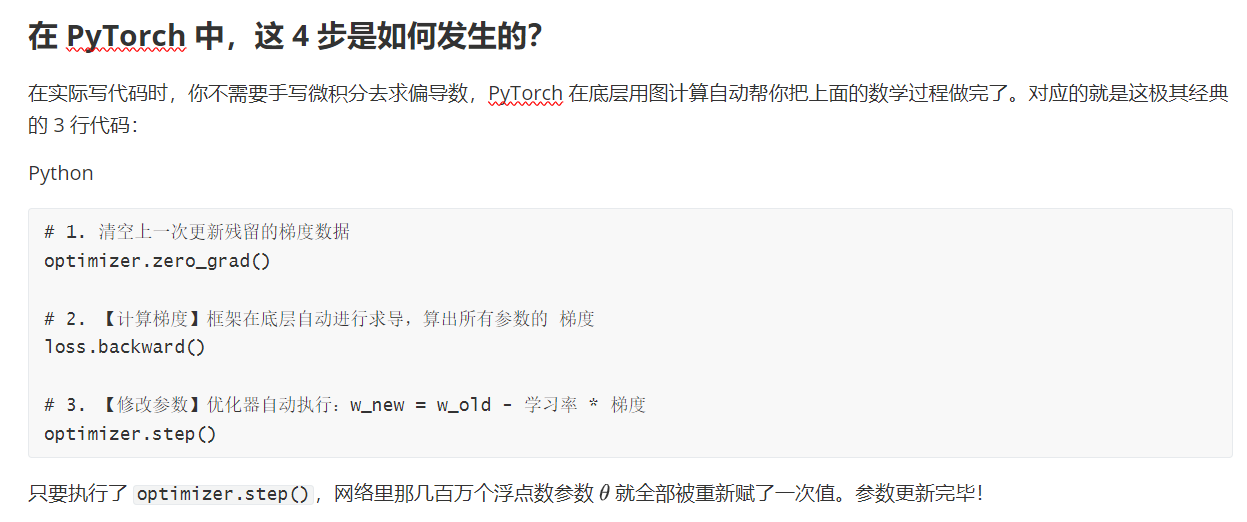
在 DQN 中,神经网络由无数个参数(权重 w 和偏置 b)组成。我们将这些参数统称为 \theta。参数更新的唯一目的,就是为了让损失函数(Loss,即预测值和目标值的差距)降到最低。
这个更新过程严格遵循以下 4 个纯粹的数学步骤:



DQN 代码实践
python
import random # 导入random库,用于生成随机数(如epsilon-贪婪中的随机动作)以及从经验池中随机抽样
import gym # 导入gym库,用于构建和交互强化学习物理环境
import numpy as np # 导入numpy库,用于进行高效的矩阵/数组运算和数据格式转换
import collections # 导入collections库,主要为了使用里面的deque(双端队列)来构建经验池
from tqdm import tqdm # 导入tqdm库,用于在终端打印进度条,方便观察训练进度
import torch # 导入PyTorch核心库,用于构建深度神经网络并提供张量(Tensor)计算支持
import torch.nn.functional as F # 导入PyTorch的函数接口,包含常用的激活函数(如ReLU)和损失函数(如MSE)
import matplotlib.pyplot as plt # 导入matplotlib绘图库,用于在训练结束后绘制奖励(Reward)走势曲线图
import rl_utils # 导入自定义的强化学习工具包(通常包含计算收益、画图等辅助函数)
class ReplayBuffer:
''' 经验回放池:用于存储智能体与环境交互的记录,并支持随机打乱抽样,打破数据相关性 '''
def __init__(self, capacity):
# 初始化一个双端队列,maxlen限制了最大容量。当存满时,新数据会自动把最老的数据挤掉(先进先出)
self.buffer = collections.deque(maxlen=capacity)
def add(self, state, action, reward, next_state, done): # 定义添加数据的方法,接收单步交互的五元组
# 将这5个变量打包成一个元组(Tuple),像"拍立得照片"一样追加到队列末尾
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size): # 定义随机抽样方法,batch_size是每次抽取的样本数量
# 从buffer中随机无放回地抽出batch_size个元组,放到transitions列表中
transitions = random.sample(self.buffer, batch_size)
# 核心解包:将抽出的三十几个元组,横向拆解成独立的5个元组(所有的状态放一起,所有的动作放一起...)
state, action, reward, next_state, done = zip(*transitions)
# 将拆解后的状态和下一状态转为Numpy数组(便于后续转PyTorch张量),并将这5个批次数据返回
return np.array(state), action, reward, np.array(next_state), done
def size(self): # 定义查询当前经验池大小的方法
# 返回队列中目前实际存放的经验条数
return len(self.buffer)
class Qnet(torch.nn.Module):
''' 只有一层隐藏层的Q网络:用来逼近 Q 函数,输入环境状态,一次性输出所有动作的价值 '''
def __init__(self, state_dim, hidden_dim, action_dim): # 初始化方法,传入状态维度、隐藏层节点数和动作维度
super(Qnet, self).__init__() # 调用父类 torch.nn.Module 的初始化方法,这是PyTorch规定动作
self.fc1 = torch.nn.Linear(state_dim, hidden_dim) # 定义第一层全连接层,输入大小为状态维度,输出大小为隐藏层维度
self.fc2 = torch.nn.Linear(hidden_dim, action_dim) # 定义输出层,输入大小为隐藏层维度,输出大小为动作空间维度
def forward(self, x): # 定义前向传播过程,x 是输入的状态向量
x = F.relu(self.fc1(x)) # 状态 x 经过第一层线性计算后,使用 ReLU 激活函数过滤(截断负数),增加非线性拟合能力
return self.fc2(x) # 将隐藏层输出传入最后一层,直接输出每个动作对应的 Q 值(注:不加激活函数,因为要输出真实得分)
class DQN:
''' DQN算法核心:将深度神经网络与Q-Learning结合的大脑 '''
def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma,
epsilon, target_update, device): # 初始化算法所需要的所有超参数
self.action_dim = action_dim # 记录动作空间的维度,供后续随机探索使用
# 实例化【主网络(Main Net)】,并将其搬运到指定的设备上(如 CPU 或 cuda:0 GPU)
self.q_net = Qnet(state_dim, hidden_dim,
self.action_dim).to(device)
# 实例化【目标网络(Target Net)】,结构和主网络一模一样,专门用来输出稳定的目标 Q 值(充当固定的靶子)
self.target_q_net = Qnet(state_dim, hidden_dim,
self.action_dim).to(device)
# 实例化 Adam 优化器,负责在反向传播时更新【主网络】的参数,设置步长为 learning_rate
self.optimizer = torch.optim.Adam(self.q_net.parameters(),
lr=learning_rate)
self.gamma = gamma # 存储折扣因子 gamma,控制对未来长远奖励的重视程度
self.epsilon = epsilon # 存储 epsilon 值,控制随机探索的概率
self.target_update = target_update # 目标网络同步频率(即每隔多少步,把主网络的参数拷贝给目标网络一次)
self.count = 0 # 初始化计数器,用来记录网络更新了多少次,以决定是否触发目标网络的同步
self.device = device # 记录当前使用的计算设备
def take_action(self, state): # 定义策略函数,基于 epsilon-贪婪策略根据当前状态选择动作
if np.random.random() < self.epsilon: # 生成一个0到1的随机数,如果小于epsilon(触发探索)
action = np.random.randint(self.action_dim) # 在动作空间内完全随机盲选一个整数动作返回
else: # 否则(触发利用),依赖已经训练的网络来做决策
state = torch.tensor([state], dtype=torch.float).to(self.device) # 将传入的Numpy状态数组转为PyTorch浮点张量,并送入设备
action = self.q_net(state).argmax().item() # 将状态送入【主网络】前向传播,用argmax取出最高分对应的动作索引,并转为标量数字
return action # 返回决定执行的动作
def update(self, transition_dict): # 最核心的训练更新函数,接收从经验池抽取出的一个批次(Batch)的数据字典
# 下面 5 行分别从字典中提取 状态、动作、奖励、下一状态、完成标志,并将它们全部转换为 PyTorch 张量并搬入计算设备
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device) # 状态矩阵,维度: [batch_size, state_dim]
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(
self.device) # 用 view(-1, 1) 将一维动作序列重塑为列向量,维度: [batch_size, 1],方便下面gather操作
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device) # 奖励同样重塑为列向量,维度: [batch_size, 1]
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device) # 下一状态矩阵,维度: [batch_size, state_dim]
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device) # 完成标志重塑为列向量,结束为1.0,未结束为0.0
# 【计算当前预测值 Q(s, a)】:
# self.q_net(states) 算出这批状态下所有动作的打分。gather(1, actions) 表示在这张打分表里,精准挑出当年真实执行过的那个动作的得分
q_values = self.q_net(states).gather(1, actions)
# 【计算未来最大期望 max Q(s', a')】:
# self.target_q_net(next_states) 用【被冻结的目标网络】预测下一状态所有动作的分数
# .max(1)[0] 沿着动作维度挑出最高分,.view(-1, 1)将其排成一列
max_next_q_values = self.target_q_net(next_states).max(1)[0].view(
-1, 1)
# 【计算绝对真理标签 (TD Target)】:即时奖励 + 折扣因子 * 未来最大期望
# 绝妙细节:*(1 - dones)!如果 dones 为 1(踩雷死掉了),那么 1-1=0,整个未来期望会被强制清零,只剩下眼前的惨痛奖励
q_targets = rewards + self.gamma * max_next_q_values * (1 - dones)
# 【计算损失 Loss】:计算主网络预测值 q_values 和目标真理值 q_targets 之间的 MSE(均方误差)
dqn_loss = torch.mean(F.mse_loss(q_values, q_targets))
self.optimizer.zero_grad() # PyTorch机制:在反向传播前,必须清空优化器中上一步残留的梯度垃圾
dqn_loss.backward() # 灵魂一步:根据损失值自动执行反向传播,计算出【主网络】中每个参数对误差的责任分锅(梯度)
self.optimizer.step() # 优化器根据刚才算出的梯度,沿着让误差变小的方向,切实修改【主网络】的神经元参数权重
# 【维稳机制:定期同步靶子】
if self.count % self.target_update == 0: # 检查计数器,看是否达到了规定的同步步数(比如每隔100步)
self.target_q_net.load_state_dict(
self.q_net.state_dict()) # 通过 load_state_dict 进行参数硬拷贝,把【主网络】最新的聪明权重直接覆盖给【目标网络】
self.count += 1 # 每次更新完成,将更新次数计数器加1