01、Redis支持哪些数据类型?各自的使用场景是什么?
1.String (字符串)
·存储结构: key-value形式
·使用场景:

缓存:存储用户信息、配置信息等。手机验证码
计数器:DECR命令实现访问计数INCR。
分布式锁:SETNX命令实现分布式锁
Session共享:存储用户会话信息
2.Hash (哈希)
存储结构: field-value组成的map,适合存储对象
使用场景:

存储对象:用户信息、商品信息等
购物车:用户ID为key,field为商品ID,value为数量
配置分组:相关配置项放在同一个hash中
3.List(列表)
·存储结构: 双向链表,按插入顺序排序
使用场景

消息队列:LPUSHBRPOP
最新列表:朋友圈动态、最新文章等0
历史记录:用户搜索历史、浏览记录
4.Set(集合)
·存储结构: 无序、不重复的字符串集合
使用场景:

标签系统:用户标签、文章标签
共同好友/关注:SINTER 求交集
抽奖活动:随机抽取SRANDMEMBER
5.Sorted Set(有序集合)
·存储结构: Set基础上为每个元素关联一个分数(score),用于排序
使用场景:
。排行榜:游戏积分榜、热搜榜
。延迟队列:用时间戳作为score
。范围查找:按分数范围查询


02、Redis的适用场景
一、核心特性与场景映射
首先,理解Redis的以下特性是分析其场景的关键:
1.内存存储,极致速度:
数据主要在内存中,读写性能极高(可达10万+/秒QPS)。
2.丰富的数据结构:
支持 Strings, Hashes, Lists, Sets, Sorted Sets, Bitmaps, HyperLogLogs用于高效地进行基数统计(如统计独立访客数),Streams等,而不仅仅是简单的Key-Value。
3.单线程与原子性:
命令操作是原子的,无需担心并发竞争,特别适合计数器、状态同步等场景。
4.持久化可选:
支持RDB快照和AOF日志,能在性能与数据安全间取得平衡。
二、主要适用场景分类
1.缓存-最经典的场景
利用内存的高速度,缓解后端数据库(如MySQL)的压力。
·热点数据缓存: 用户信息、商品详情、文章内容等频繁读取的数据。
·会话缓存: 分布式系统中的用户Session集中存储,实现无状态服务。
·全页缓存: 缓存整个HTML页面片段。
优点: 显著降低数据库负载,提升应用响应速度。
2.实时计算与统计
利用其原子操作和高效数据结构处理实时数据。
计数器: 文章点赞数、视频播放量、用户粉丝数。INCR,INCRBY 命令是原子的。
排行榜: 使用SortedSet,能高效实现根据分数排序和范围查询,如游戏积分榜、热搜榜。
布隆过滤器: 使用 Bitmaps 或模块,用于大规模数据去重,判断某个元素是否存在(如新闻去重、垃圾邮件过滤)
3.复杂业务逻辑的数据结构优化
将关系数据库的复杂计算"卸载"到Redis。
社交关系: 使用Set 存储粉丝、关注列表,SINTER 命令可快速求共同关注。
最新列表: 使用List 存储最新的N条动态,如用户最近登录记录。
购物车: 使用 Hash 以用户ID:商品ID 为键,存储商品数量和属性,读写非常高效。
三、经典案例场景
电商秒杀
库存扣减: 用String或Hash 预存库存,通过DECR 原子扣减,防止超卖。
用户频率限制: 用String 记录用户访问次数,防止刷单。
秒杀结果临时存储: 成功用户ID存入Set,快速过滤重复请求。
社交媒体:
Feed流: 用户动态用List 或Sorted Set 存储,实现分页拉取。
点赞/关注: 用Set 存储点赞用户列表,用Sorted Set 存储关注时间线。
03、Redis的优缺点
Redis是一个基于内存、支持持久化的高性能键值数据库,常被用作缓存、消息中间件和轻量级数据存储。它并非传统意义上的关系型数据库替代品,而是一个功能丰富的特种工具。
二、优点(为什么选择Redis)
1.极致性能
内存存储: 数据主要驻留内存,读写操作直接在内存中进行,速度极快(读约10万+/秒,写约8万+/秒)。
单线程模型: 避免了多线程上下文切换和竞争条件,保证了原子操作,且CPU不是其瓶颈。
高效数据结构: 不仅是简单的键值对,其值支持字符串、列表、集合、哈希、有序集合等,这些结构在内存中经过优化,操作效率极高。
2.丰富的数据结构与功能
超越普通缓存: 除了GET/SET,还提供如列表推拉、集合交并差、有序集合排名、地理空间计算等,*能直接实现复杂业务逻辑(*如排行榜、好友关系、消息队列)。
多功能扩展: 支持发布/订阅、Lua脚本、事务、Stream(作为消息队列)、位图操作等。
3.持久化保障
RDB(快照): 定时全量备份,恢复快,适合备份。
AOF(追加日志):记录所有写操作,数据完整性高,可配置不同刷盘策略平衡性能与安全。
5.广泛的生态与语言支持
。几乎所有主流编程语言都有成熟的客户端。
。与Java生态(如Spring Boot的Spring Data Redis)集成无缝,是微服务架构中缓存和共享会话的首选
三、缺点与挑战
1.容量与成本瓶颈
内存限制: 数据量受物理内存限制,大容量数据存储成本高昂。虽然有虚拟内存/磁盘存储方案,但会严重丧失性能优势。
扩容成本: 内存扩容或集群扩缩容比硬盘更昂贵、更复杂。
2.持久化与数据安全的风险点
RDB-AOF权衡:RBD可能丢失最后一次快照后的数据,AOF文件更大且恢复慢。需要根据业务容忍度仔细配置。
3.功能局限性
非关系型:不支持复杂查询(如联表)、没有原生二级索引。复杂查询需在客户端处理或借助其他结构
4."缓存穿透/击穿/雪崩"
这是使用Redis作为圣典三大问题,需要额外的策略来防护:。
穿透: 查询不存在的数据(布隆过滤器/空值缓存)。
击穿: 热点key过期瞬间大量请求到DB(互斥锁/永不过期)。
雪崩: 大量key同时过期(随机过期时间/集群部署)。
04、与关系型数据库对比(mysql)

总结:Redis最适合作为高性能缓存和特定数据结构存储,需与持久化数据库配合使用,形成互补的存储体系架构。在选择时需要根据数据特性、一致性要求、查询复杂用等维度综合评估。
05、Redis是单线程还是多线程?为什么设计为单线程?
一、核心结论
Redis采用混合线程模型:核心命令处理是单线程的,但部分功能使用多线程。
Redis6.0前:网络I/O和命令处理由单个主线程完成,但持久化、异步删除等由后台线程处理
Redis6.0+:网络I/O多线程化,但命令执行仍是单线程
二、为什么核心命令处理设计为单线程?
1.避免并发复杂性
**无锁设计:**单线程天然避免了多线程的锁竞争、死锁、数据竞争等问题
原子性保证: 每个Redis命令都是原子操作,简化了数据结构的实现
2.性能优势
内存级操作:R edis主要操作内存,速度极快(纳秒级),单线程已能充分压榨CPU
避免上下文切换: 多线程频繁切换消耗大量CPU资源(15-20%)
3.1/O多路复用
·非阻塞I/O: 单线程可处理数万并发连接
三、单线程模型的瓶颈与优化瓶颈:
1.大键操作阻塞: 删除包含百万元素的Hash可能阻塞数百毫秒
2.复杂命令耗时: KEYS*、FLUSHDB等可能阻塞服务
3.持久化Fork: RDB的fork操作可能阻塞(特别是大内存实例)
Redis的解决方案:
**1.异步化:**UNLINK、ASYNC FLUSH等命令
**2.渐进式处理:**SCAN代替KEYS,渐进式rehash
**3.配置优化:**调整持久化策略,使用混合持久化
总结
Redis的单线程设计是架构哲学的选择,而非技术限制:
优势: 简化实现、避免锁竞争、保证原子性、高缓存命中率
演进: 在保持核心单线程优势的同时,通过I/O多线程化解决网络瓶颈
面试要点:
Redis通过单线程命令处理+多线程网络I/O+后台线程的混合模型,在保持简单性和原子性的同时,有效提升了网络密集型场景的性能。这种设计使其在高并发、低延迟场景中表现出色,同时避免了传统多线程数据库的复杂性。
06、Redis如何实现持久化?RDB和AOF的区别是什么?
Redis提供两种持久化机制,确保数据在重启后不丢失:
RDB (Redis Database)
工作原理: 定时生成内存数据的二进制快照文件(dump.rdb)
触发方式:
。手动执行SAVE(阻塞)或BGSAVE(后台异步)
。配置自动触发(如save 9001表示900秒内至少1个键被修改)
。执行SHUTDOWN 或FLUSHALL时自动触发
核心流程:
a.fork()创建子进程(写时复制技术)
b.子进程将内存数据写入临时RDB文件
c.替换旧的RDB文件
2.AOF (Append Only File)
·工作原理: 记录所有写操作命令,以Redis协议格式追加到文件
·写入策略 (appendfsync配置):
。always:每个写命令都同步刷盘(最安全,性能最低)
everysec:每秒同步一次(默认推荐,平衡安全与性能)
no:由操作系统决定何时同步(性能最高,数据可能丢失)
- 重写机制:
解决AOF文件膨胀问题
通过 BGREWRITEAOF 创建新AOF文件,移除冗余命令
3.混合持久化 (Redis 4.0+)
·结合两者优势:RDB快照+增量AOF日志
·生成的文件包含:RDB格式数据+后续AOF命令

三、生产环境建议
1.同时启用RDB和AOF(Redis 4.0+):
。RDB用于定期备份和快速恢复
。AOF保证数据安全性
。重启时优先使用AOF恢复(数据更完整)
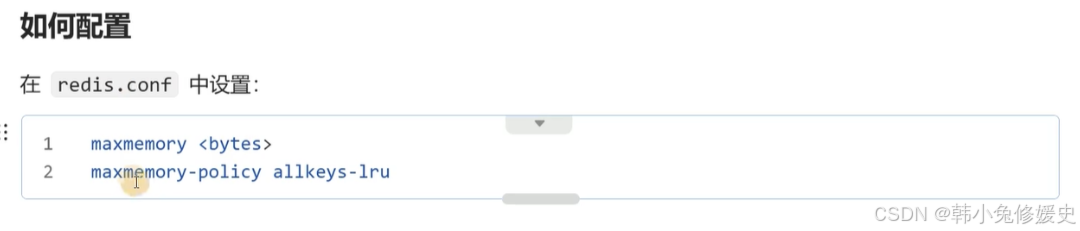
2.配置示例:

07、内存淘汰策略有哪些?(至少列出4种)
Redis提供了多种内存淘汰策略,用于在内存使用达到 maxmemory限制时决定如何释放内存。
1.noeviction
描述: 默认策略。当内存不足时,新写入操作会报错(如 oOM command notallowed when used memory),读操作正常,但无法写入新数据。
适用场景 :对数据一致性要求极高,不允许丢失任何数据的场景(需确保内存足够或有其它扩容机制)
2.allkeys-Iru
描述: 从所有key中,淘汰最近最少使用的key。
实现: 基于LRU算法,优先淘汰最久未被访问的数据。
适用场景: 适合热点数据分布较均匀的场景,能有效保留常用数据。
3.volatile-Iru
描述: 仅从设置了过期时间(TTL)的key中,淘汰最近最少使用的key。
特点: 不影响未设置过期时间的key(持久化数据)。
适用场景: 希望持久化数据常驻内存,仅对临时数据进行淘汰。
4.allkeys-random
描述: 从所有key中随机淘汰任意key。
适用场景: 所有key访问概率均等,或没有明显访问规律。
5.volatile-random
描述: 仅从设置了过期时间的key中随机淘汰。
适用场景: 需保留持久化数据,且临时数据无明确访问规律。
6.volatile-ttl
描述: 从设置了过期时间的key中,淘汰剩余存活时间最短的key。
适用场景: 优先淘汰即将过期的数据,适合短期缓存场景。
7.allkeys-Ifu (Redis 4.0+)
描述: 从所有key中,淘汰最不经常使用的key。
特点: 基于访问频率(LFU算法),比LRU更精准识别冷门数据 。
适用场景: 需要根据访问频率淘汰低频数据。
8.volatile-Ifu (Redis 4.0+)
描述: 仅从设置了过期时间的key中,淘汰最不经常使用的key。
适用场景: 结合了LFU算法和volatile范围,适用于临时数据的频率淘汰。
选择策略的建议
1.数据特点:
-
若数据访问有冷热区分一LRU/LFU。
-
若数据无规律一random。
-
若需区分永久数据和临时数据一volatile-*。
2.版本支持:Redis 4.0+建议优先考虑LFU(更智能)。
3.风险容忍:不允许数据丢失可选noeviction(需监控内存)。
09、Redis的过期策略有哪些?
Redis的过期策略是一个综合体系,主要包含两种核心的过期键删除策略+内存淘汰机制。
一、核心过期键删除策略
Redis采用**"惰性删除"和"定期删除"**两种策略相结合的方式,来移除过期的键值对。这两种策略是协同工作的,缺一不可。
1.惰性删除
当客户端尝试访问一个键时,Redis会先检查这个键是否已过期。如果过期,则立即删除该键,并返回空值。"访问"是触发条件,包括GET、HGET 等任何读写操作。
优点:
**对CPU友好: **只在访问时进行过期检查,不会占用额外的CPU时间进行扫描。
**精准: **只删除被访问到的过期键,目标明确。
缺点:
**对内存不友好:**如果一个键永远不再被访问,即使它早已过期,也会一直占用内存,造成内存泄漏。这是
惰性删除最大的问题。
2.定期删除
Redis会周期性地(默认每100ms执行一次)从设置了过期时间的键中,随机抽取一部分(默认20个键)进行检查,并删除其中已过期的键。
过程:
a.从过期字典中随机抽取N个键。
b.检查这N个键是否过期。
c.删除所有已过期的键。
d.如果本轮删除的过期键比例超过 25%(可配置),则立即重复步骤1,继续检查下一批。这样可以快速清理掉大量集中过期的键。
e.如果比例低于25%,则停止本轮检查,等待下一个周期。
- 优点:
**减少内存泄漏:**通过定期扫描,可以清理掉那些长期不被访问的"僵尸"过期键,弥补了惰性删除的不足。
- 缺点:
CPU时间片的权衡: 扫描的频率和每次扫描的耗时需要仔细设置。如果太频繁或检查太多键,会影响Redis的响应性能;如果太少,则又退化为类似惰性删除的效果。
非实时性: 不能保证键在过期后立即被删除,会有一个时间窗口(最多到下一个定期扫描周期)。
小结: 惰性删除是"访问时触发",定期删除是"系统定时抽样"。两者互补,惰性删除解决了大部分访问键的实时删除问题,而定期删除则用于清理那些"死"键,防止内存泄漏。
总结与综合工作流程
1.写入时: 当一个键被设置过期时间(EXPIRE/PEXPIRE),这个键和它的过期时间会被存储在一个独立的过期字典 中。
2.访问时(惰性删除):每次客户端访问一个键,Redis都会先去过期字典检查。如果过期,则删除并返回nil。
3.定期扫描(定期删除): Redis的定时任务 serverCron 会每隔100ms执行一次,随机抽取部分过期键进行检查和删除,防止内存泄漏。
4.内存不足时(淘汰策略):当经过前面步骤,内存使用仍达到上限,Redis会根据配置的maxmemory-policy,从指定的键范围内(所有键或仅过期键)按照特定算法(LRU/LFU/TTL/随机)淘汰一部分键,以腾出空间接受新写入。

10、Redis的持久化机制中,AOF重写的过程是怎样的?
Redis AOF重写过程详解
AOF(Append Only File)重写是Redis持久化机制中用于解决AOF文件体积膨胀问题的核心优化手段。以下是AOF重写的完整过程:
1.重写的触发时机
- ·自动触发 :通过配置 auto-ac-rewrite-percentage(增长比例)和auto-aof-rewrite-min-size(最小文件大小)
- ·手动触发:执行BGREWRITEAOF命令
- 启动时触发:如果AOF文件损坏,Redis启动时会尝试重写
2.重写的核心思想
通过读取当前数据库状态,生成一个新的、更紧凑的AOF文件,替代原有庞大的AOF文件。新文件只包含重建当前数据集所需的最少命令,消除冗余命令(如多次set同一个key、已删除key的操作等)
3.详细执行过程
步骤1:创建子进程
- 主进程fork一个子进程执行重写任务,避免阻塞主进程
- 此时父子进程共享内存数据(利用操作系统的写时复制机制)
步骤2:子进程处理
子进程执行流程:
1.扫描当前数据库中所有键值对
2.为每个键生成对应的写入命令
-
对于字符串类型:直接生成SET命令
-
对于列表/集合/哈希等:生成批量写入命令
3.将生成的命令写入临时AOF文件(名称类似temp-rewriteaof-bgpid.aof
步骤3:处理重写期间的写入
- 重写缓冲区:主进程在重写期间将所有新执行的写命令同时写入两个地方:
- a.原有AOF缓冲区(同步到原有AOF文件)
- b.AOF重写缓冲区(专门为本次重写准备)
- ·确保重写期间的数据一致性
步骤4:最终合并
当子进程完成重写后:
1.子进程向父进程发送完成信号
2.父进程将AOF重写缓冲区中得所有命令追加到新的AOF文件末尾
3.原子性地用新的AOF文件替换旧的AOF文件(rename操作)

总结
AOF重写是Redis保持AOF文件高效性的关键机制,通过后台子进程生成紧凑的新AOF文件,既解决了文件膨胀问题,又保证了数据完整性和服务可用性。理解这一机制对于合理配置Redis持久化和保障数据安全至关重要