
🔥 个人主页: 杨利杰YJlio
❄️ 个人专栏: 《Sysinternals实战教程》 《Windows PowerShell 实战》 《WINDOWS教程》 《IOS教程》
《微信助手》 《锤子助手》 《Python》 《Kali Linux》
《那些年未解决的Windows疑难杂症》
🌟 让复杂的事情更简单,让重复的工作自动化


2023-09-25:ChatGPT 从纯文本走向多模态交互,看、听、说能力意味着什么?
- [1、ChatGPT 为什么要从纯文本走向多模态?](#1、ChatGPT 为什么要从纯文本走向多模态?)
- 2、"看、听、说"分别解决了什么问题?
-
- [2.1 看:图像理解](#2.1 看:图像理解)
- [2.2 听:语音识别](#2.2 听:语音识别)
- [2.3 说:语音回应](#2.3 说:语音回应)
- 3、多模态交互的完整流程是什么?
- 4、从纯文本到多模态,本质变化在哪里?
- 5、多模态能力可以应用在哪些场景?
-
- [5.1 识图问答](#5.1 识图问答)
- [5.2 语音助手](#5.2 语音助手)
- [5.3 学习辅导](#5.3 学习辅导)
- [5.4 内容创作](#5.4 内容创作)
- [5.5 无障碍交流](#5.5 无障碍交流)
- 6、这次升级对普通用户意味着什么?
- 7、我的理解:多模态不是功能升级,而是交互范式升级
- 8、总结
2023 年 9 月 25 日,ChatGPT 迎来了一个非常重要的能力节点:开始逐步支持"看、听、说"能力。
这意味着 ChatGPT 不再只是一个只能接收文字、输出文字的聊天工具,而是开始进入一个更接近真实人机交互的阶段。
简单说:
以前的 ChatGPT,主要是"读文字、写文字"。 现在的 ChatGPT,开始具备"看图片、听语音、说出来"的多模态交互能力。 这背后的核心变化,不是功能多了几个按钮,而是人机交互方式发生了升级。

1、ChatGPT 为什么要从纯文本走向多模态?
过去我们和 AI 对话,主要依赖文字输入。
比如:
- 我们输入一个问题;
- AI 理解文字;
- AI 输出文字答案。
这种方式已经很强,但它仍然有明显限制:很多真实世界的信息并不是以文字形式存在的。
比如:
- 一张图片里的故障现象;
- 一段语音里的问题描述;
- 一个界面截图中的报错信息;
- 一张图表里的趋势变化;
- 一个实物照片里的细节识别。
如果只能靠文字描述,用户就必须先把看到的东西转成文字,再交给 AI 分析。这个过程不仅麻烦,而且容易丢失信息。
所以,多模态能力的价值就在于:让 AI 直接理解更多类型的信息,而不是只理解文字。

从这张结构图可以看出,多模态交互并不是简单地把图片、语音、文字放在一起,而是让模型具备统一处理多种信息的能力。
它大致包括三类输入和两类输出:
| 类型 | 能力 | 说明 |
|---|---|---|
| 文本输入 | 理解文字问题 | 继续支持传统文字问答 |
| 图像理解 | 识别图片内容 | 可以分析截图、照片、图表等 |
| 语音输入 | 听懂语音内容 | 用户可以直接说话提问 |
| 文本回复 | 输出结构化答案 | 适合阅读、复制、整理 |
| 语音输出 | 直接语音播报 | 让交流更接近日常对话 |
这就是为什么我认为,2023 年 9 月 25 日这个节点非常关键:它代表 ChatGPT 从"文本型助手"开始向"多模态智能助手"演进。

2、"看、听、说"分别解决了什么问题?
多模态能力可以拆成三个关键词:看、听、说。
2.1 看:图像理解
"看"指的是 ChatGPT 可以理解图片内容。
比如用户上传一张图片,ChatGPT 可以帮助分析:
- 图片里有什么;
- 截图中出现了什么错误;
- 图表表达了什么趋势;
- 某个界面应该如何操作;
- 某个实物、场景、文档截图大概表达了什么。
对于技术学习和桌面运维场景来说,这个能力非常实用。
比如以后用户电脑出现报错,不一定非要把错误代码手动打出来,可以直接上传截图,让 AI 辅助判断问题方向。
2.2 听:语音识别
"听"指的是 ChatGPT 可以接收语音输入。
这解决的是输入效率问题。
有些时候,我们并不方便打字,尤其是:
- 手机端临时提问;
- 开车、走路、做事时需要快速咨询;
- 用户表达较长问题时;
- 学习英语口语或练习对话时。
语音输入让 ChatGPT 更像一个可以随时交流的助手,而不是一个必须依赖键盘输入的工具。
2.3 说:语音回应
"说"指的是 ChatGPT 可以用语音方式进行回应。
这让 AI 的反馈方式从"阅读答案"变成"听答案"。
在学习、陪练、口语交流、无障碍场景中,语音输出的价值会更明显。
尤其是英语学习、知识讲解、语音陪练这类场景,语音回应会让交互体验更自然。

3、多模态交互的完整流程是什么?
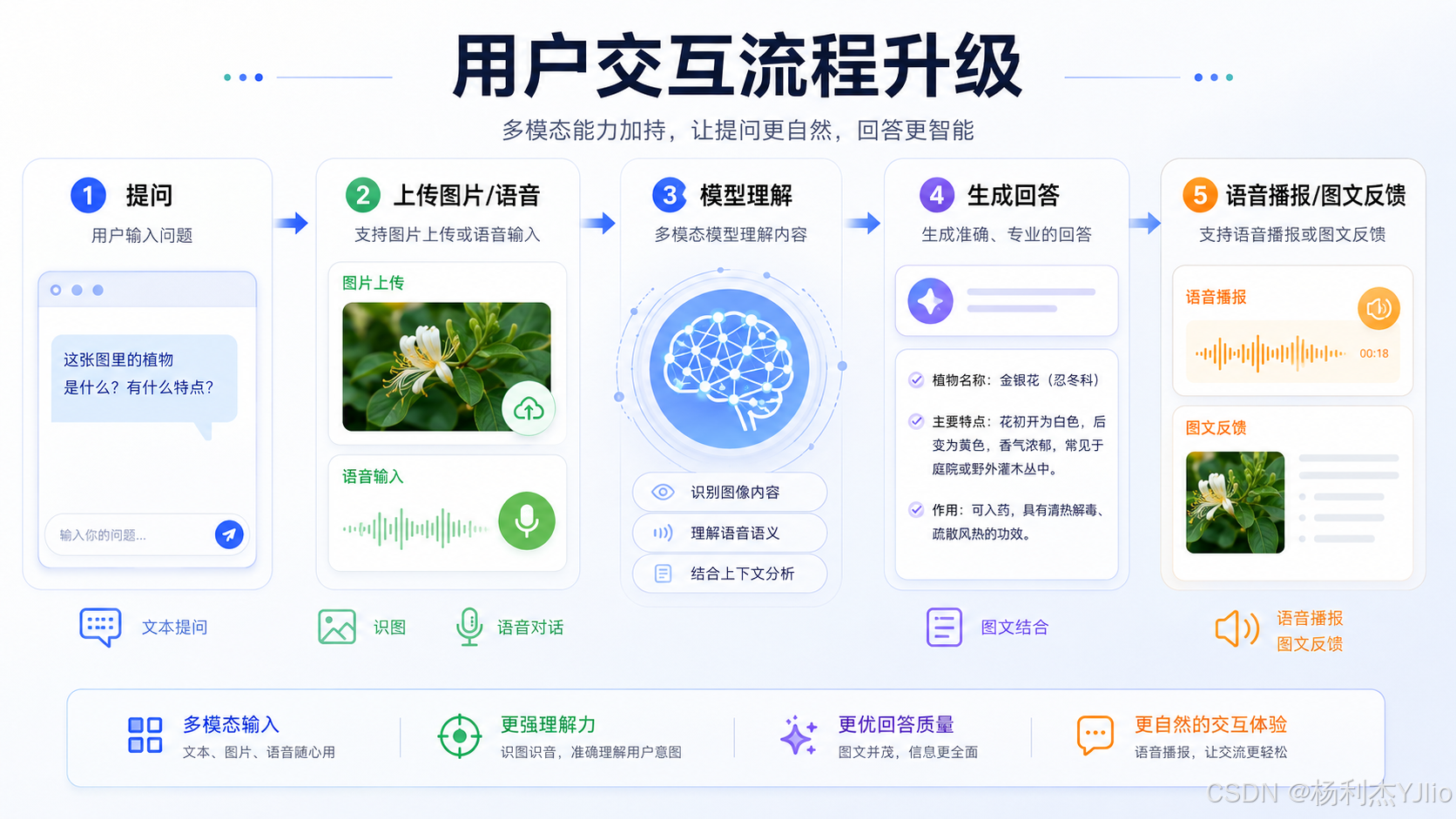
从用户角度看,多模态交互大致可以理解为五步:
- 用户提出问题
- 上传图片或输入语音
- 模型理解文本、图片、语音内容
- 生成结构化回答
- 通过文字、语音或图文结合方式反馈
这个流程看似简单,但核心变化非常大。
以前的流程是:
text
输入文字 → 理解文字 → 输出文字现在的流程变成:
text
输入文字 / 图片 / 语音 → 多模态理解 → 输出文字 / 语音 / 图文反馈也就是说,ChatGPT 的交互边界被扩大了。
用户提问
输入方式
文字输入
图片上传
语音输入
模型统一理解
输出方式
文字回答
语音播报
图文反馈
更清晰
更自然
更直观
这个流程最大的意义是:用户不需要为了适应 AI 而改变表达方式,AI 开始适应用户更自然的表达方式。
这才是多模态能力真正重要的地方。

4、从纯文本到多模态,本质变化在哪里?
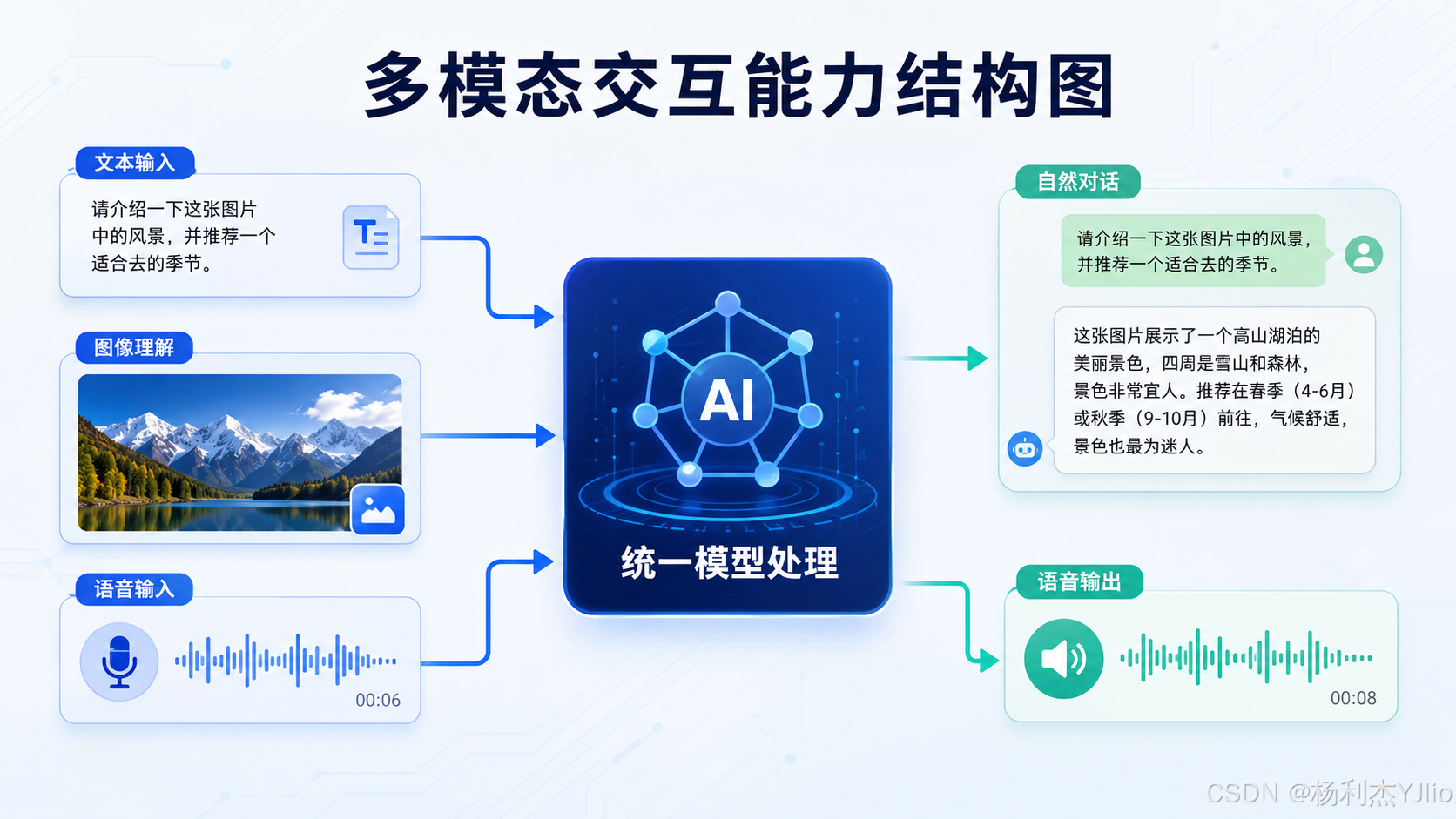
这张对比图把变化讲得很清楚。
以前的 AI 交互更像是:
我打字,你回答。
现在的 AI 交互开始变成:
我可以打字,也可以说话,还可以发图片;你不仅能读懂文字,也能看懂图片、听懂语音,并用更自然的方式回应我。
这个变化可以从四个维度理解。
| 维度 | 纯文本阶段 | 多模态阶段 |
|---|---|---|
| 输入方式 | 主要依赖键盘文字 | 支持文字、图片、语音等多种输入 |
| 理解对象 | 主要理解文本 | 可以理解图像、语音、上下文 |
| 交互体验 | 更像查询工具 | 更像智能助手 |
| 应用场景 | 问答、写作、查询 | 学习、办公、识图、语音陪练、辅助分析 |
这里要特别强调一点:
多模态不是为了炫技,而是为了降低用户表达成本。
用户看到什么,就可以直接发什么;用户想到什么,就可以直接说出来。
这才是它真正提升效率的地方。

5、多模态能力可以应用在哪些场景?

多模态能力带来的变化,不只是聊天方式变得更自然,更重要的是应用场景被扩大了。
5.1 识图问答
用户可以上传图片,让 ChatGPT 帮助识别和解释。
比如:
- 识别图片中的地点;
- 分析图片中的物品;
- 看懂图表趋势;
- 分析界面截图;
- 辅助理解操作步骤。
对于技术博客、运维排障、学习笔记来说,识图能力非常有价值。
5.2 语音助手
语音输入和语音输出结合后,ChatGPT 更接近一个语音助手。
它可以用于:
- 语音提问;
- 语音答疑;
- 口语练习;
- 知识讲解;
- 移动场景下快速沟通。
5.3 学习辅导
多模态能力对学习场景也非常友好。
比如学生可以上传题目图片,让 AI 辅助讲解;也可以用语音追问,让学习过程更接近真实老师答疑。
5.4 内容创作
对于写作、博客、文案、知识整理来说,多模态能力也能提高效率。
比如:
- 根据图片生成说明文字;
- 根据截图整理教程步骤;
- 根据语音想法生成文章初稿;
- 根据图表提炼结论;
- 根据文章内容生成配图思路。
5.5 无障碍交流
语音转文字、文字转语音、图像理解等能力,也能帮助更多人降低沟通门槛。
这类能力在无障碍沟通、辅助阅读、信息转写等场景中会越来越重要。

6、这次升级对普通用户意味着什么?
我觉得,这次升级对普通用户最大的意义可以总结成三句话:
第一,提问门槛降低了。
用户不必把所有信息都转成文字,可以直接发图片、说语音。
第二,理解能力增强了。
AI 不再只看文字,而是能结合图像、语音和上下文进行理解。
第三,交互体验更自然了。
AI 不只是一个文字工具,而是更接近一个可以交流、可以解释、可以陪练的助手。
这意味着未来使用 AI 的方式会越来越接近真实沟通。
不是人去适应工具,而是工具逐渐适应人的表达方式。

7、我的理解:多模态不是功能升级,而是交互范式升级
如果只是从表面看,多模态好像只是多了几个功能:
- 可以上传图片;
- 可以语音输入;
- 可以语音回复。
但如果往深一层看,它代表的是 AI 产品形态的变化。
过去,ChatGPT 更像是一个"文本问答系统"。
现在,它开始向"综合智能助手"发展。
这个变化的核心不是按钮变多了,而是:
AI 开始理解更接近真实世界的信息。
真实世界不是纯文字的。
真实世界里有图片、声音、场景、动作、环境、截图、表格、语气和上下文。
当 AI 能够处理这些信息时,它能参与的场景就会明显扩大。
8、总结
2023 年 9 月 25 日,ChatGPT 开始支持"看、听、说"能力,这是一个非常值得记录的产品演进节点。
它标志着 ChatGPT 从纯文本对话,开始走向多模态交互。
本文可以用一句话总结:
ChatGPT 的多模态能力,本质上不是让 AI 多几个输入输出方式,而是让人机交互变得更自然、更直观、更接近真实沟通。
对于普通用户来说,它降低了使用门槛;
对于学习者来说,它提升了理解效率;
对于创作者来说,它拓展了内容生产方式;
对于技术人员来说,它提供了新的辅助分析入口。
未来,AI 工具的竞争,可能不只是回答得准不准,还包括:
- 是否能理解更多信息;
- 是否能更自然地交流;
- 是否能嵌入更多真实工作场景;
- 是否能真正帮助用户减少重复劳动。
这也是我持续关注 ChatGPT、多模态 AI 和自动化工具的原因。
因为它们正在把复杂的信息处理过程,变得越来越简单。
🔝 返回顶部