作为后端开发,我们每天都在和 MySQL 事务打交道:转账扣款要加事务、订单创建要加事务、数据批量更新要加事务。我们都知道 "事务能保证数据安全",面试时也能脱口而出 "事务有 ACID 四大特性"。
但只要面试官多追问几句,很多人就会卡壳:
- ACID 四大特性,InnoDB 底层到底是怎么实现的?
- 并发事务会带来哪些问题?脏读、不可重复读、幻读到底有什么区别?
- 四个隔离级别到底是怎么解决这些问题的?底层靠的是什么?
- 为什么 MySQL 默认隔离级别是可重复读,而 Oracle 用读已提交?
- 线上的死锁、长事务阻塞、主从延迟,到底和事务有什么关系?
其实事务从来不是一个黑盒,它的所有设计,都是围绕着「在高并发场景下保证数据一致性」这个核心目标展开的。这篇文章,我们就从最基础的业务场景出发,一步步拆解 MySQL 事务的全貌,从 ACID 特性到并发问题,从隔离级别到底层的锁与 MVCC,再到线上踩坑的最佳实践,彻底搞懂 MySQL 事务。
看完这篇,你不仅能轻松拿捏所有 MySQL 事务相关的面试题,更能从底层规避线上事务的各种坑,写出更健壮的业务代码。
一、引言:为什么我们需要事务?
在讲所有理论之前,我们先看一个所有人都懂的经典场景:银行转账。
假设你要给朋友转 1000 元,这个操作可以拆成两步:
- 从你的账户里扣除 1000 元
- 给朋友的账户里增加 1000 元
这两个操作必须是一个不可分割的整体:要么都成功,要么都失败。如果第一步执行成功,第二步执行到一半,数据库突然崩溃了,就会出现 "你的钱扣了,朋友的钱没收到" 的灾难性后果。
而事务,就是用来解决这个问题的。事务是一组数据库操作的最小执行单元,这组操作要么全部执行成功,要么全部执行失败回滚,不允许出现部分成功部分失败的情况。
除了转账这种强一致性场景,我们日常业务中的订单创建(扣库存 + 生成订单 + 扣优惠券)、数据批量更新、多表联动修改,都离不开事务。可以说,事务是关系型数据库能支撑金融、电商等核心业务的基石。
二、核心基石:事务的 ACID 四大特性
提到事务,所有人最先想到的就是 ACID 四大特性,但很多人只是死记硬背四个单词,却搞不懂它们之间的关系,以及 MySQL 底层是怎么实现的。
这里先纠正一个全网流传最广的认知误区:ACID 四个特性不是并列关系。一致性(Consistency)是事务的最终目标,原子性(Atomicity)、隔离性(Isolation)、持久性(Durability)是实现一致性的三大手段。数据库所有的设计,都是为了通过 AID 三大特性,最终保证数据的一致性。
下面我们逐个拆解每个特性的定义,以及 InnoDB 对应的底层实现。
1. 原子性(Atomicity)
原子性的核心定义是:事务是最小的执行单元,不可分割,事务内的所有操作,要么全部执行成功,要么全部执行失败回滚,不存在中间状态。
就像我们前面的转账例子,扣钱和加钱两个操作,不可能出现 "扣钱成功了,加钱失败了,钱就凭空消失了" 的情况,一旦中间出现异常,所有已经执行的操作都会回滚到事务开始前的状态,就像这个事务从来没有执行过一样。
InnoDB 实现原子性的核心:undo log(回滚日志) undo log 是逻辑日志,它记录的是数据修改的反向操作。比如你执行了一条update user set balance = balance - 1000 where id = 1,undo log 就会记录一条update user set balance = balance + 1000 where id = 1的反向操作。
当事务需要回滚时,InnoDB 就会执行 undo log 里的反向操作,把数据恢复到事务开始前的状态,从而保证了事务的原子性。同时,undo log 也是后面要讲的 MVCC(多版本并发控制)的核心基础。
2. 一致性(Consistency)
一致性的核心定义是:事务执行前后,数据的完整性约束没有被破坏。
这里的完整性约束,包括两个层面:
- 数据库层面的约束:比如主键唯一约束、外键约束、非空约束、字段的 check 约束等。比如转账前后,两个账户的总金额必须保持不变;用户 ID 不能重复,外键关联的记录必须存在。
- 业务层面的约束:这个是数据库无法保证的,需要业务代码来实现。比如转账不能转负数金额,库存不能扣成负数,订单金额必须等于商品金额 + 运费。
这里必须再次强调:一致性是事务的最终目标。原子性保证了操作不会出现中间状态,隔离性保证了并发事务之间不会互相干扰,持久性保证了提交的数据不会丢失,这三个特性共同保证了数据库层面的一致性。而业务层面的一致性,必须由开发人员通过正确的业务代码来保证。
3. 隔离性(Isolation)
隔离性的核心定义是:多个事务并发执行的时候,事务内部的操作和其他事务是相互隔离的,并发执行的各个事务之间不会互相干扰。
如果说原子性是事务的基础,那隔离性就是事务中最复杂、最核心的部分。我们的数据库不可能只处理一个事务,线上业务每秒都会有成百上千个事务并发执行,多个事务同时修改、查询同一张表、同一行数据,必然会出现冲突。而隔离性,就是用来解决并发事务之间的冲突问题的。
隔离性的底层实现,是我们后面要重点讲的锁机制 和MVCC(多版本并发控制),MySQL 的四个隔离级别,本质上就是隔离性的不同实现程度。
4. 持久性(Durability)
持久性的核心定义是:一个事务一旦提交成功,它对数据库的修改就是永久的,后续的任何操作、甚至数据库崩溃、机器宕机,都不会导致提交的数据丢失。
比如你转账成功了,收到了银行的扣款短信,哪怕之后银行的数据库宕机了,你的扣款记录和朋友的收款记录也不会消失,数据库重启后必须能恢复到提交后的状态。
InnoDB 实现持久性的核心:redo log(重做日志)+ WAL 预写日志机制我们都知道,MySQL 的数据最终是存在磁盘上的,但如果每次事务提交,都把修改的整页数据刷到磁盘,会有两个致命问题:一是随机 IO 性能极差,二是刷盘粒度太大,只修改了 1 行数据,也要刷 16KB 的整页数据,开销极大。
InnoDB 用 WAL(Write-Ahead Logging,预写日志)机制解决了这个问题:先写日志,再刷磁盘。当事务提交时,InnoDB 不会立刻把修改的数据刷到磁盘,而是先把修改操作记录到 redo log 里,等系统空闲的时候,再把 redo log 里的修改异步刷到磁盘上。
redo log 是物理日志,记录的是 "某个数据页做了什么修改",大小固定,循环写入。哪怕数据库宕机了,重启后只要读取 redo log,就能把未刷到磁盘的修改恢复回来,从而保证了事务的持久性。
这里补充一句:我们常说的 binlog(归档日志)是 Server 层的日志,主要用于主从复制和数据归档,不负责事务的持久性,只有 InnoDB 引擎的 redo log 才是实现持久性的核心。
三、并发事务的代价:事务带来的 3 大经典问题
如果数据库永远只有一个事务在执行,那只要保证原子性和持久性,就能保证一致性,根本不需要隔离性。但现实是,线上业务永远是高并发的,多个事务同时操作同一份数据,必然会带来各种数据一致性问题。
SQL 标准中,定义了并发事务带来的 3 大经典问题,也是我们面试中必背的内容。下面我们用具体的 SQL 场景,逐个拆解每个问题的定义、复现方式和危害。
我们先创建一张测试表,提前插入一条数据,所有场景都基于这张表演示:
sql
CREATE TABLE `user_account` (
`id` int NOT NULL PRIMARY KEY AUTO_INCREMENT,
`name` varchar(32) NOT NULL COMMENT '用户名',
`balance` int NOT NULL DEFAULT 0 COMMENT '账户余额'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO `user_account` (`id`, `name`, `balance`) VALUES (1, '张三', 1000);1. 脏读(Dirty Read)
定义 :一个事务读到了另一个事务未提交的修改数据。如果另一个事务最终回滚了,那当前事务读到的数据就是无效的、脏的,这就是脏读。
复现场景:
| 时间 | 事务 A(转账扣款) | 事务 B(查询余额) |
|---|---|---|
| T1 | 开启事务 | 开启事务 |
| T2 | 执行 UPDATE,把张三的余额改成 0,未提交 | - |
| T3 | - | 执行 SELECT,读到张三的余额是 0 |
| T4 | 事务回滚,余额恢复成 1000 | - |
| T5 | - | 基于余额 0 做业务处理,出现数据错误 |
危害:事务 B 基于脏数据做了业务判断,比如给张三开通了欠费提醒,甚至冻结了账户,但实际上张三的账户里还有 1000 元,导致业务逻辑完全错误,这在金融场景中是致命的。
2. 不可重复读(Non-Repeatable Read)
定义 :同一个事务内,用相同的条件两次查询同一条记录,得到的结果不一样。因为在两次查询之间,有另一个事务修改了这条数据并提交了,导致当前事务两次读取的结果不一致,这就是不可重复读。
复现场景:
| 时间 | 事务 A(修改余额) | 事务 B(两次查询) |
|---|---|---|
| T1 | 开启事务 | 开启事务 |
| T2 | - | 第一次 SELECT,读到张三的余额是 1000 |
| T3 | 执行 UPDATE,把余额改成 0,提交事务 | - |
| T4 | - | 第二次 SELECT,读到张三的余额是 0 |
| T5 | - | 同一个事务内两次查询结果不一致,业务判断出错 |
危害:同一个事务内,多次读取同一条数据的结果不一致,会导致业务逻辑混乱。比如事务 B 在 T2 时刻查到余额 1000,判断可以扣款 800,结果在 T4 时刻执行扣款的时候,余额已经变成 0 了,导致扣款失败。
3. 幻读(Phantom Read)
定义 :同一个事务内,用相同的条件两次查询,得到的结果集行数不一样。因为在两次查询之间,有另一个事务插入了符合查询条件的新数据并提交了,导致当前事务第二次查询多了几条 "凭空出现" 的记录,就像出现了幻觉一样,这就是幻读。
复现场景:我们先给表多插入几条数据:
sql
INSERT INTO `user_account` (`id`, `name`, `balance`) VALUES (2, '李四', 2000), (3, '王五', 3000);| 时间 | 事务 A(插入数据) | 事务 B(范围查询) |
|---|---|---|
| T1 | 开启事务 | 开启事务 |
| T2 | - | 第一次 SELECT,查询 id<5 的用户,得到 3 条记录 |
| T3 | 插入一条 id=4 的用户,提交事务 | - |
| T4 | - | 第二次 SELECT,查询 id<5 的用户,得到 4 条记录 |
| T5 | - | 同一个事务内两次查询行数不一致,出现幻读 |
很多人会把不可重复读和幻读搞混,这里明确核心区别:
- 不可重复读的核心是同一条数据的内容被修改了 ,针对的是
UPDATE/DELETE操作,解决方案是锁住这条记录; - 幻读的核心是结果集的行数变了 ,针对的是
INSERT操作,只锁住已有记录没用,必须锁住记录之间的间隙,防止新数据插入。
四、第一层解决方案:SQL 标准的 4 个事务隔离级别
为了解决上面的 3 大并发问题,SQL 标准定义了 4 个事务隔离级别,每个级别对应不同的隔离强度,解决的问题也不同,隔离级别越高,并发性能越差,数据一致性越强。
我们先通过一张表,清晰地看到四个隔离级别分别解决了什么问题:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 并发性能 |
|---|---|---|---|---|
| 读未提交(Read Uncommitted) | 可能 | 可能 | 可能 | 最高 |
| 读已提交(Read Committed) | 不可能 | 可能 | 可能 | 较高 |
| 可重复读(Repeatable Read) | 不可能 | 不可能 | 可能(标准 SQL) | 一般 |
| 串行化(Serializable) | 不可能 | 不可能 | 不可能 | 最低 |
下面我们逐个拆解每个隔离级别的定义、适用场景,以及 MySQL 的支持情况。
1. 读未提交(Read Uncommitted)
最低的隔离级别,一个事务能读到其他事务未提交的修改数据。这个级别解决不了任何并发问题,脏读、不可重复读、幻读都可能发生,而且性能也没有比其他级别高多少,线上业务基本不会使用。
2. 读已提交(Read Committed,简称 RC)
只能读到其他事务已经提交的数据,彻底解决了脏读问题,但无法解决不可重复读和幻读。
这个级别是 Oracle、PostgreSQL 等大多数数据库的默认隔离级别,适合绝大多数对一致性要求不是极致严格、但对并发性能要求高的业务场景,比如普通的电商订单查询、内容管理系统等。
3. 可重复读(Repeatable Read,简称 RR)
同一个事务内,多次读取同一条数据的结果是一致的,彻底解决了脏读和不可重复读问题。在标准 SQL 的定义中,这个级别还是无法解决幻读问题。
重点:MySQL InnoDB 的默认隔离级别就是 RR,而且和标准 SQL 的 RR 有本质区别 ------InnoDB 通过临键锁(Next-Key Lock)+ MVCC,在 RR 级别下彻底解决了幻读问题,这也是 MySQL 选择 RR 作为默认隔离级别的核心原因,既保证了较高的数据一致性,又兼顾了并发性能。
4. 串行化(Serializable)
最高的隔离级别,所有事务完全串行执行,读加共享锁,写加排他锁,读写互斥,写读互斥。这个级别彻底解决了脏读、不可重复读、幻读的所有问题,但并发性能极差,只有对数据一致性要求极致严格、几乎没有并发的场景才会使用,比如金融核心账务系统,线上业务基本不会用。
五、底层核心原理:隔离级别到底是怎么实现的?
很多人背熟了四个隔离级别,却不知道它们底层到底是怎么实现的。其实隔离级别的底层,靠的是两大核心技术:锁机制 和MVCC(多版本并发控制)。
简单来说:锁机制解决了写 - 写之间的冲突,实现了写写互斥;而 MVCC 解决了读 - 写之间的冲突,实现了读写不阻塞,读不加锁,大幅提升了数据库的并发性能。
一、InnoDB 的锁机制
锁是实现隔离性的基础,InnoDB 的锁体系非常完善,我们只讲和事务隔离级别相关的核心内容。
1. 按锁的功能划分:共享锁与排他锁
- 共享锁(S 锁,读锁) :当事务对数据加了 S 锁,其他事务可以再加 S 锁读数据,但不能加 X 锁修改数据。实现了读读不阻塞,读写阻塞。加锁方式:
SELECT * FROM user_account WHERE id = 1 LOCK IN SHARE MODE; - 排他锁(X 锁,写锁) :当事务对数据加了 X 锁,其他事务不能加任何锁,既不能读也不能写。实现了写写阻塞,读写阻塞。加锁方式:
SELECT * FROM user_account WHERE id = 1 FOR UPDATE;注意:INSERT/UPDATE/DELETE语句,会自动给对应的数据加 X 锁,不需要手动加锁。
2. 按锁的粒度划分:全局锁、表级锁、行级锁
- 全局锁:锁住整个数据库,所有读写都阻塞,只用在全库逻辑备份的场景,日常业务不会用。
- 表级锁:锁住整张表,分为表共享读锁和表排他写锁,开销小,加锁快,但锁粒度大,并发性能差,MyISAM 引擎用的就是表级锁,InnoDB 只有在特殊场景下才会用。
- 行级锁:锁住表中的某一行或几行数据,锁粒度最小,并发性能最高,是 InnoDB 的核心优势。但行级锁是基于索引实现的,如果更新语句没有命中索引,InnoDB 会升级为表锁,导致全表阻塞,这是线上高频踩坑点。
3. 行级锁的细分:记录锁、间隙锁、临键锁
这三个锁是 InnoDB 实现 RR 隔离级别、解决幻读问题的核心,也是面试必问的内容。
- 记录锁(Record Lock) :精准锁住某一条索引记录,比如
WHERE id = 1,只会锁住 id=1 的这一行记录,其他行完全不受影响。 - 间隙锁(Gap Lock):锁住两个索引记录之间的间隙,不锁住记录本身,只防止其他事务在这个间隙里插入新数据,这是解决幻读的关键。比如表中有 id=1 和 id=5 的两条记录,间隙锁会锁住 (1,5) 这个区间,其他事务无法插入 id=2、3、4 的记录,自然就不会出现幻读。
- 临键锁(Next-Key Lock) :InnoDB RR 级别下的默认行锁算法,临键锁 = 记录锁 + 间隙锁 ,是一个左开右闭的区间。比如表中有 id=1、5、10 三条记录,临键锁会把索引分成 (-∞,1]、(1,5]、(5,10]、(10,+∞] 四个区间,当你查询
WHERE id <= 5时,InnoDB 会锁住 (-∞,1]、(1,5] 两个区间,既锁住已有记录,又锁住间隙,彻底杜绝了其他事务插入符合条件的数据,从根本上解决了幻读问题。
二、MVCC(多版本并发控制)
如果只有锁机制,那读写之间是互相阻塞的,并发性能会很差。比如一个事务修改了某行数据,加了 X 锁,其他事务就只能等着,不能读这行数据,这在高并发场景下是无法接受的。
而 MVCC,就是 InnoDB 用来解决读写冲突的核心技术,实现了读写不阻塞,读不加锁,读写不冲突,大幅提升了数据库的并发性能。
MVCC 的全称是 Multi-Version Concurrency Control,多版本并发控制,核心思想是:给每行数据维护多个版本,事务读取数据时,读取的是符合当前事务可见性的历史版本,而不是最新的加锁版本,从而实现了不用加锁也能读到一致的数据。
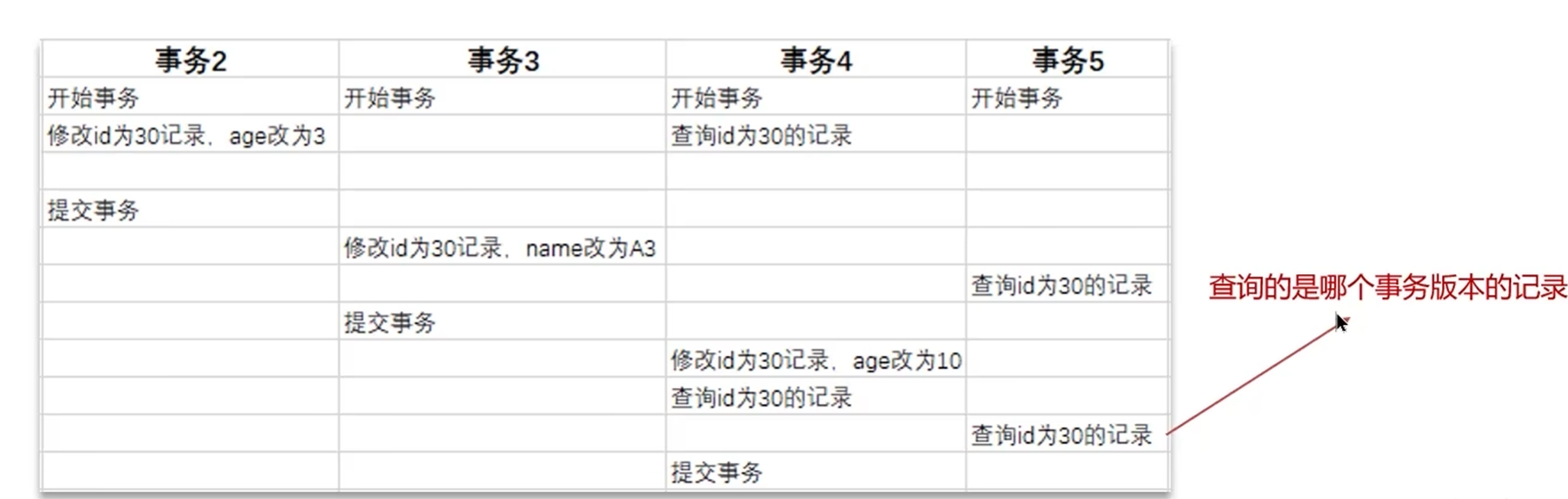
下面我们拆解 MVCC 的三大核心实现:隐藏字段、undo log 版本链、Read View 读视图。
1. 每行数据的 3 个隐藏字段
InnoDB 的每行数据,除了我们定义的字段,还会自动添加 3 个隐藏字段:
- DB_TRX_ID(6 字节):最近一次修改这条数据的事务 ID,事务 ID 是 InnoDB 按事务开启顺序递增分配的,唯一标识一个事务。
- DB_ROLL_PTR(7 字节):回滚指针,指向这条数据对应的 undo log,也就是这条数据的上一个历史版本。
- DB_ROW_ID(6 字节):隐藏的自增主键,如果我们的表没有定义主键,InnoDB 会自动用这个字段生成聚簇索引;如果有主键,这个字段就不会存在。
2. undo log 版本链
每次我们修改数据的时候,InnoDB 都会做两件事:
- 把修改前的旧版本数据写入 undo log;
- 把当前行的 DB_ROLL_PTR 指针,指向这条 undo log,同时更新 DB_TRX_ID 为当前事务的 ID。
这样一来,同一行数据的所有历史版本,就通过回滚指针,串联成了一个单向链表,也就是undo log 版本链。链表的头部是最新的版本,尾部是最老的历史版本。
比如
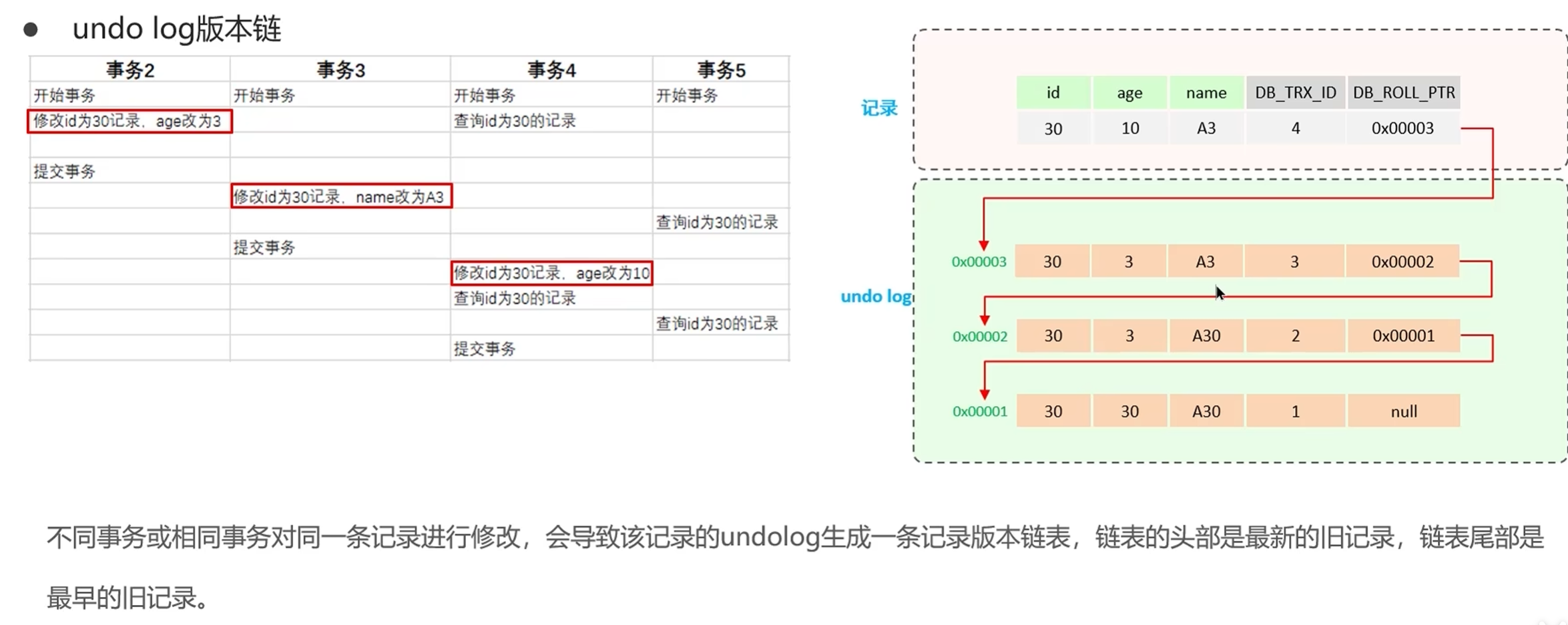
3. Read View 读视图与可见性规则
有了版本链,那事务到底能看到版本链里的哪个版本呢?这就靠 Read View(读视图)来判断。
Read View 是事务执行快照读(普通的不加锁 SELECT 语句)时,生成的一个数据快照,记录了当前数据库中活跃的(未提交的)事务信息,用来判断版本链中的哪个数据版本对当前事务是可见的。
Read View 有 4 个核心字段:
- m_ids:生成 Read View 时,当前数据库中所有活跃的(未提交的)事务 ID 列表;
- min_trx_id:m_ids 中最小的事务 ID,也就是当前未提交事务中最早开启的那个;
- max_trx_id:生成 Read View 时,数据库下一个要分配的事务 ID,也就是当前已提交的最大事务 ID+1;
- creator_trx_id:生成这个 Read View 的当前事务的 ID。
有了 Read View,InnoDB 就会按照下面的可见性判断规则,从版本链的头部开始,逐个判断版本是否可见,找到第一个可见的版本就返回:
- 如果版本的 DB_TRX_ID == creator_trx_id:说明这个版本是当前事务自己修改的,可见;
- 如果版本的 DB_TRX_ID < min_trx_id:说明这个版本的事务,在生成 Read View 之前就已经提交了,可见;
- 如果版本的 DB_TRX_ID >= max_trx_id:说明这个版本的事务,是在生成 Read View 之后才开启的,不可见;
- 如果版本的 DB_TRX_ID 在 min_trx_id 和 max_trx_id 之间:判断 DB_TRX_ID 是否在 m_ids 列表里,如果在,说明这个事务还没提交,不可见;如果不在,说明已经提交了,可见。
有了 Read View,InnoDB 就会按照下面的可见性判断规则,从版本链的头部开始,逐个判断版本是否可见,找到第一个可见的版本就返回:
- 如果版本的 DB_TRX_ID == creator_trx_id:说明这个版本是当前事务自己修改的,可见;
- 如果版本的 DB_TRX_ID < min_trx_id:说明这个版本的事务,在生成 Read View 之前就已经提交了,可见;
- 如果版本的 DB_TRX_ID >= max_trx_id:说明这个版本的事务,是在生成 Read View 之后才开启的,不可见;
- 如果版本的 DB_TRX_ID 在 min_trx_id 和 max_trx_id 之间:判断 DB_TRX_ID 是否在 m_ids 列表里,如果在,说明这个事务还没提交,不可见;如果不在,说明已经提交了,可见。
4. RC 和 RR 隔离级别的核心区别:Read View 的生成时机
很多人都知道 RC 和 RR 的区别是能不能重复读,但不知道底层为什么会有这个区别,核心原因就是Read View 的生成时机不同:
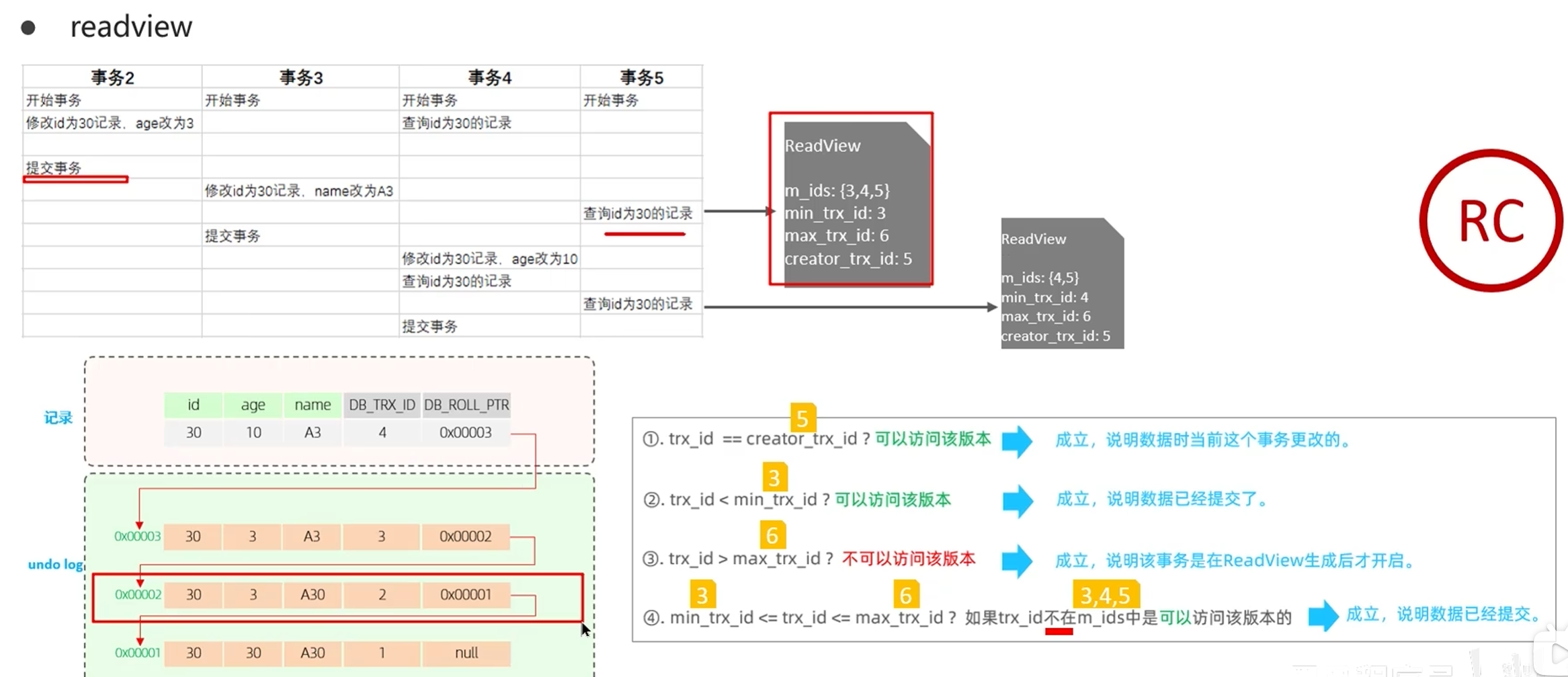
- 读已提交(RC)级别 :事务中每次执行快照读(SELECT)的时候,都会生成一个全新的 Read View。所以每次 SELECT,都能读到其他事务已经提交的最新数据,自然就会出现同一个事务内两次读取结果不一致的情况,也就是不可重复读。
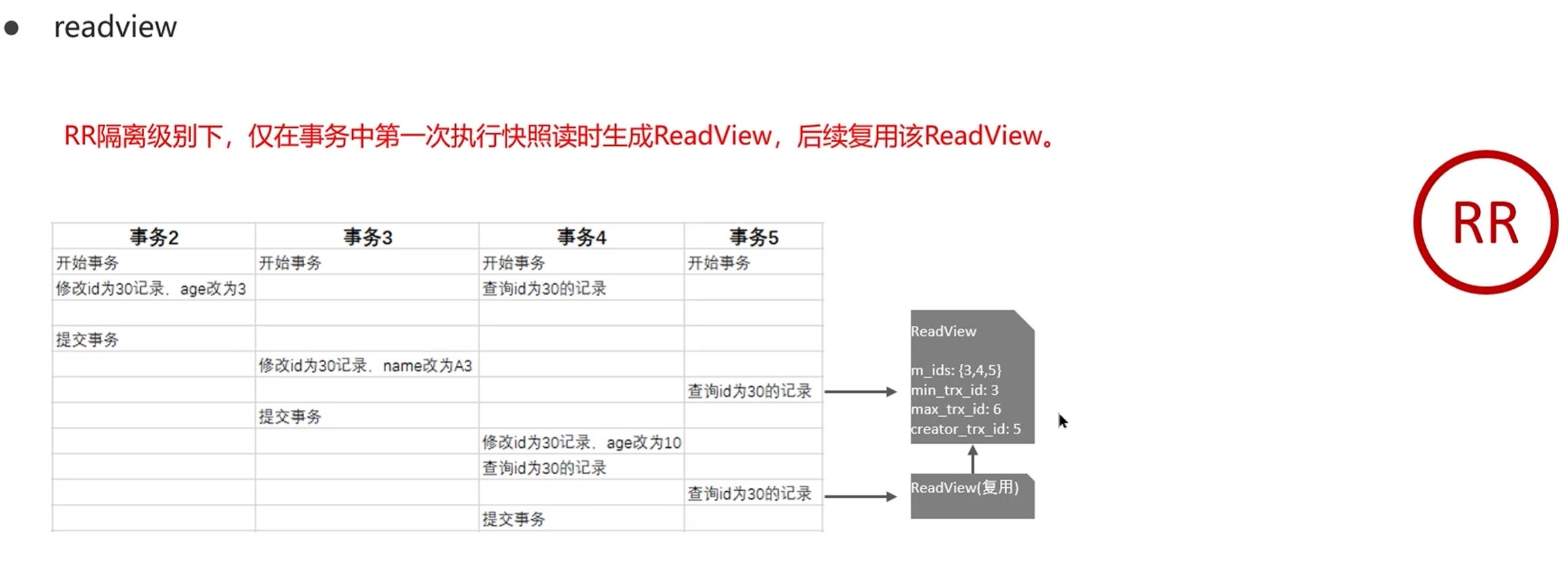
- 可重复读(RR)级别 :只有事务中第一次执行快照读(SELECT)的时候,才会生成 Read View,之后的所有快照读,都会复用这个第一次生成的 Read View。所以整个事务内,看到的数据版本都是一致的,哪怕中间有其他事务修改了数据并提交,当前事务也看不到,自然就实现了可重复读。
5. 快照读与当前读
最后我们补充两个关键概念,很多人搞不懂 MVCC 和锁的关系,就是因为没分清这两个概念:
- 快照读:普通的不加锁 SELECT 语句,就是快照读,靠 MVCC 实现,读的是历史版本,不加锁,读写不阻塞,性能极高。
- 当前读 :读取的是数据的最新版本,会加锁,靠锁机制实现。包括
SELECT ... FOR UPDATE、SELECT ... LOCK IN SHARE MODE、INSERT、UPDATE、DELETE这些语句,都是当前读。
到这里,我们就能彻底搞懂 InnoDB RR 级别是怎么解决幻读的了:
- 快照读场景下:靠 MVCC 复用 Read View,整个事务内看到的结果集都是一致的,看不到其他事务新插入的数据,不会出现幻读;
- 当前读场景下:靠临键锁锁住查询条件对应的整个索引区间,包括间隙,其他事务无法插入符合条件的新数据,从根本上杜绝了幻读。
六、事务带来的更多线上问题:死锁与大事务
除了前面讲的脏读、不可重复读、幻读,事务在实际线上业务中,还会带来两个最常见、最头疼的问题:死锁 和大事务。这两个问题是线上数据库性能下降、服务阻塞、甚至雪崩的核心元凶之一。
一、死锁
1. 什么是死锁?
死锁是指两个或多个事务,互相等待对方持有的锁,导致所有事务都无限阻塞,无法继续执行的现象。
举个最简单的例子:
- 事务 A 持有 id=1 的行锁,等待获取 id=2 的行锁;
- 事务 B 持有 id=2 的行锁,等待获取 id=1 的行锁;两个事务都在等对方释放锁,永远等不到,就形成了死锁。
2. 死锁的四个必要条件
死锁的发生,必须同时满足四个条件,缺一不可:
- 互斥条件:一个锁只能被一个事务持有,其他事务必须等待,直到锁释放;
- 请求与保持条件:事务已经持有了至少一个锁,又申请新的锁,而新的锁被其他事务持有,当前事务阻塞,但不释放自己已经持有的锁;
- 不剥夺条件:事务已经持有的锁,只能自己主动释放,其他事务不能强行剥夺;
- 循环等待条件:多个事务之间,形成了头尾相接的循环等待锁的关系。
3. InnoDB 处理死锁的两种方式
- 死锁等待超时 :通过
innodb_lock_wait_timeout参数设置超时时间,默认 50 秒,超过这个时间,就自动回滚等待的事务,打破死锁。这个方式效率很低,需要等超时时间,线上一般不会用默认值,会调小。 - 主动死锁检测:InnoDB 默认开启了死锁检测,当发现死锁时,会主动回滚代价最小的那个事务(比如修改行数最少的事务),打破循环等待,解决死锁。
4. 死锁的排查与避免
- 排查死锁 :执行
show engine innodb status;命令,在输出的内容中,找到LATEST DETECTED DEADLOCK部分,里面会详细记录死锁发生的时间、两个事务分别持有和等待的锁、执行的 SQL 语句,从而定位死锁原因。 - 避免死锁的核心方案 :
- 统一资源访问顺序:这是最有效的方式。比如所有事务都按 id 从小到大的顺序更新记录,就不会出现事务 A 等 id=2、事务 B 等 id=1 的情况,从根本上打破循环等待条件。
- 避免大事务,缩小事务范围:尽量让事务变短,减少锁的持有时间,降低死锁的概率。不要在事务里执行大量操作,不要在事务里等待用户输入。
- 尽量用索引访问数据:避免无索引的更新语句,导致行锁升级为表锁,大幅增加死锁概率。
- 降低隔离级别:RC 级别下没有间隙锁,只有记录锁,锁的范围更小,死锁概率比 RR 级别低很多,如果业务允许,可以用 RC 级别。
- 避免一次性更新太多数据:批量更新尽量拆分,减少一次性锁住的记录数量。
二、大事务
1. 什么是大事务?
大事务,就是运行时间长、操作数据量大、持有锁时间长的事务。比如一个事务里循环更新 10 万条数据、一个事务执行了几十秒、在事务里调用了第三方 RPC 接口,这些都是典型的大事务。
2. 大事务的核心危害
- 锁持有时间过长,导致大量事务阻塞:大事务会持有大量行锁,持有时间长达几秒甚至几十秒,其他要修改这些数据的事务都会被阻塞,导致数据库连接被打满,服务雪崩。
- undo log 膨胀,占用大量磁盘空间:大事务会生成大量的 undo log,而且在事务提交之前,undo log 不能被清理,会一直占用磁盘空间,甚至导致磁盘打满。同时 undo log 过多,会导致数据库性能下降。
- 主从延迟严重:大事务在主库执行了几十秒,提交后传到从库,从库也要执行几十秒,会导致主从延迟飙升,读写分离场景下,从库读到的是几十秒前的旧数据,业务出现问题。
- 数据库崩溃恢复时间长:大事务如果在执行过程中数据库崩溃,恢复时需要回滚大量操作,导致数据库长时间无法启动。
- 死锁概率大幅提升:大事务持有锁的时间长,和其他事务冲突的概率大幅增加,更容易发生死锁。
3. 大事务的优化方案
- 拆分大事务为多个小事务,分批提交:这是最核心的优化手段。比如批量更新 10 万条数据,拆分成 100 个小事务,每个事务更新 1000 条,分批提交,大幅减少锁持有时间和 undo log 的生成。
- 避免在事务中执行非数据库操作:不要在事务里调用 RPC 接口、HTTP 请求、文件 IO、循环等待等操作,这些操作会拉长事务的执行时间,导致锁一直被持有。非数据库操作一定要放到事务外执行。
- 读操作尽量放到事务外:不需要事务保证一致性的读操作,不要放到事务里,减少事务内的操作,缩短事务执行时间。
- 控制事务的边界:尽量晚开启事务,早提交事务。不要在业务代码开头就开启事务,而是在真正要执行数据库写操作的时候再开启,执行完立刻提交。
- 避免在事务中循环执行 SQL :循环执行 SQL 会大幅拉长事务时间,尽量改成批量操作,比如用
INSERT ... ON DUPLICATE KEY UPDATE批量插入更新,用IN语句代替循环单条查询。
七、实战指南:MySQL 事务开发最佳实践
前面讲了这么多原理,最终还是要落到实际开发中。下面给大家总结 10 条可直接落地的 MySQL 事务开发最佳实践,帮你避开 90% 的事务坑。
- 优先使用 InnoDB 引擎,不要用 MyISAM:MyISAM 不支持事务、不支持行锁、不支持崩溃恢复,完全不适合线上业务,哪怕是只读场景,也优先用 InnoDB。
- 优先使用默认的 RR 隔离级别,不要随便修改:MySQL 默认的 RR 级别,兼顾了一致性和性能,还解决了幻读问题,适合绝大多数业务场景。只有对并发性能要求极高、能接受不可重复读的场景,再改成 RC 级别,线上绝对不要用读未提交和串行化。
- 绝对禁止使用长事务、大事务,事务越短越好:这是线上最核心的规范,90% 的数据库阻塞、死锁、主从延迟问题,都是大事务导致的。
- 不要在事务里执行任何非数据库操作:RPC 调用、HTTP 请求、文件 IO、等待用户输入、本地计算等,全部放到事务外执行,避免拉长事务时间。
- 批量操作必须拆分,分批提交:更新、插入超过 1000 条数据,必须拆分成小批次,每个批次一个事务,不要一个事务处理几万条数据。
- 更新语句必须命中索引,避免行锁升表锁:更新、删除语句的 WHERE 条件必须有索引,没有索引的话,InnoDB 会锁住全表,导致所有事务都被阻塞,线上灾难性事故。
- 统一资源访问顺序,避免死锁:多个表、多条记录的更新,必须按固定的顺序执行,比如按主键从小到大的顺序,从根本上避免死锁。
- 避免在事务内先查询再更新,尽量用原子更新 :不要用
SELECT查出数据→业务代码计算→UPDATE更新的模式,高并发下会出现数据不一致,尽量用UPDATE table SET num = num - 1 WHERE id = 1这种原子更新语句。如果必须先查,要用SELECT ... FOR UPDATE加锁,防止并发修改。 - 不要滥用手动加锁 :普通的 SELECT 不要随便加
LOCK IN SHARE MODE或FOR UPDATE,会导致锁范围扩大,并发性能下降,死锁概率提升,只有必要的场景才手动加锁。 - 禁止在循环里开启和提交事务:循环里开启事务,会频繁创建和销毁事务,同时生成大量小事务,导致数据库性能下降,还可能导致主从延迟,尽量改成批量操作。
八、误区纠正 & 高频面试题解答
常见误区纠正
- 误区 :ACID 四个特性是并列的,一致性是靠数据库实现的。纠正:一致性是事务的最终目标,原子性、隔离性、持久性是实现一致性的手段。数据库只能保证数据层面的一致性,业务层面的一致性必须靠正确的业务代码实现。
- 误区 :InnoDB 的 RR 级别不能解决幻读。纠正:标准 SQL 的 RR 级别不能解决幻读,但 InnoDB 的 RR 级别,通过 MVCC(快照读)和临键锁(当前读),完全解决了幻读问题。
- 误区 :MVCC 在所有隔离级别下都生效。纠正:MVCC 只在 RC 和 RR 级别下生效。读未提交每次都读最新的行,不需要版本链;串行化所有操作都加锁,不需要 MVCC。
- 误区 :隔离级别越高,数据越安全,越好。纠正:隔离级别越高,并发性能越差,要根据业务场景选择,不是越高越好。绝大多数业务场景,RR 级别完全足够。
- 误区 :binlog 是实现事务持久性的核心。纠正:binlog 是 Server 层的归档日志,用于主从复制和数据归档,不负责事务持久性。InnoDB 引擎的 redo log,才是实现事务持久性的核心。
高频面试题解答
- **问:讲一下事务的 ACID 四大特性,以及 InnoDB 是怎么实现 ACID 的?**答:原子性靠 undo log 回滚日志实现,一致性是最终目标,靠原子性、隔离性、持久性 + 业务代码实现,隔离性靠锁机制和 MVCC 实现,持久性靠 redo log 和 WAL 预写日志机制实现。
- **问:并发事务会带来哪些问题?脏读、不可重复读、幻读分别是什么?**答:并发事务会带来脏读、不可重复读、幻读三大问题,分别对应读到未提交数据、同一事务两次读同一条数据结果不同、同一事务两次读结果集行数不同。
- **问:SQL 标准的四个隔离级别是什么?分别解决了什么问题?**答:读未提交(什么都解决不了)、读已提交(解决脏读)、可重复读(解决脏读、不可重复读)、串行化(解决所有问题)。
- **问:InnoDB 的默认隔离级别是什么?和标准 SQL 的有什么区别?**答:InnoDB 默认隔离级别是可重复读(RR),标准 SQL 的 RR 级别无法解决幻读,而 InnoDB 通过 MVCC 和临键锁,在 RR 级别下彻底解决了幻读问题。
- **问:讲一下 MVCC 的实现原理?**答:MVCC 靠每行数据的隐藏字段、undo log 版本链、Read View 读视图实现。通过隐藏字段和 undo log 构建数据的多版本链,再通过 Read View 的可见性规则,判断事务能看到哪个版本的数据,实现了读写不阻塞。
- **问:RC 和 RR 隔离级别有什么核心区别?底层是怎么实现的?**答:核心区别是 Read View 的生成时机不同。RC 级别每次 SELECT 都生成新的 Read View,所以会出现不可重复读;RR 级别第一次 SELECT 生成 Read View,之后复用,所以实现了可重复读。同时 RC 级别只有记录锁,RR 级别有临键锁,能解决幻读。
- **问:InnoDB 是怎么解决幻读问题的?**答:快照读场景下,靠 MVCC 复用 Read View,保证整个事务内读到的结果集一致;当前读场景下,靠临键锁锁住查询对应的索引区间和间隙,防止其他事务插入新数据,从根本上解决幻读。
- 问:什么是死锁?死锁的四个必要条件?怎么排查和避免死锁? 答:死锁是多个事务互相等待对方持有的锁,无限阻塞的现象。四个必要条件是互斥、请求与保持、不剥夺、循环等待。排查用
show engine innodb status看死锁日志,避免的核心是统一资源访问顺序、缩小事务范围、用索引访问数据。 - **问:什么是大事务?有什么危害?怎么优化?**答:大事务是运行时间长、操作数据量大的事务。危害包括锁阻塞、undo log 膨胀、主从延迟、死锁概率提升。优化核心是拆分大事务为小事务、避免事务内非数据库操作、控制事务边界。
- **问:快照读和当前读有什么区别?**答:快照读是普通的不加锁 SELECT,靠 MVCC 实现,读历史版本,不加锁,性能高;当前读是加锁的 SELECT 和 INSERT/UPDATE/DELETE,读最新版本,靠锁机制实现,会加锁。
九、总结
写到这里,相信你已经彻底搞懂了 MySQL 事务的全貌。
MySQL 事务的本质,就是为了解决高并发场景下的数据一致性问题。从 ACID 四大特性,到四个隔离级别,再到底层的锁机制和 MVCC,所有的设计,都是在「数据一致性」和「并发性能」之间做权衡。
没有完美的隔离级别,也没有万能的解决方案,只有最适合业务场景的选择。理解了事务的底层原理,你就不会再死记硬背隔离级别的规则,而是能从底层判断,业务该用什么隔离级别,怎么写事务代码不会踩坑,怎么排查线上的死锁、阻塞问题,真正做到知其然,更知其所以然。
技术学习的尽头,从来不是死记硬背语法和 API,而是搞懂底层的设计逻辑。当你能从锁和 MVCC 的视角看懂事务的设计,你就跨过了 MySQL 从入门到进阶的那道门槛。