论文解读
SFINet:面向多模态图像融合的空间-频率统一学习框架
论文:Man Zhou 等,A General Spatial-Frequency Learning Framework for Multimodal Image Fusion ,IEEE TPAMI 2025。
关键词:多模态图像融合、全色锐化、深度超分辨率、傅里叶变换、空间-频率学习、可逆神经算子。
核心观点
这篇论文的出发点很直接:全色锐化和 RGB 引导深度超分辨率本质上都是"用高分辨率引导模态补齐低分辨率目标模态的高频信息"。既然退化过程天然发生在频率域,只在空间域用卷积学习映射是不完整的。作者提出 SFINet / SFINet++,把空间域的局部纹理建模、频率域的全局上下文建模,以及二者之间的交互补偿放进一个统一框架。
研究背景与问题定义
多模态图像融合的典型目标是:输入一个低分辨率目标图像和一个高分辨率引导图像,输出兼具目标模态语义/光谱一致性与引导模态空间细节的高分辨率结果。论文重点验证了两个代表性任务:
- Pan-sharpening:用高分辨率 PAN 图像引导低分辨率 MS 图像,恢复高空间分辨率多光谱影像。
- Depth image super-resolution:用高分辨率 RGB 图像引导低分辨率深度图,恢复边界清晰的高分辨率深度图。
过去很多深度方法主要在空间域操作,用卷积堆叠学习局部映射。但下采样会直接丢失高频成分,单纯依赖空间域像素损失,容易出现纹理细节不足、边界模糊、全局频率结构恢复不稳定等问题。
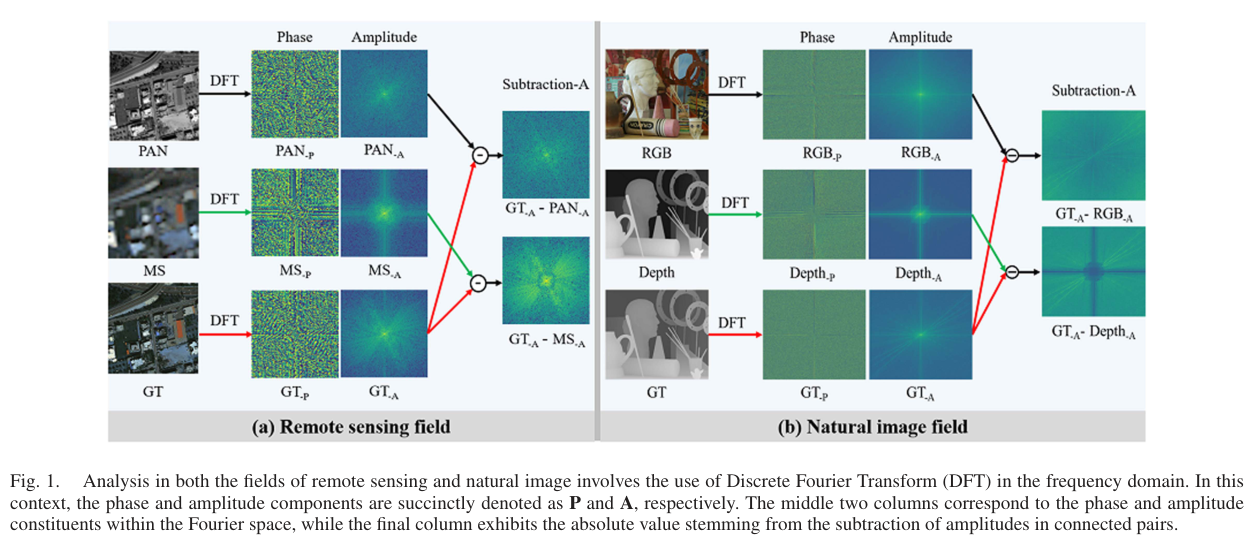
图 1 是这篇论文的动机核心。作者把全色锐化和深度超分辨率都放到 DFT 频域里看:相位更对应结构与边缘,振幅更对应频率能量分布。PAN/RGB 通常提供更强的高频结构信息,MS/depth 则保留目标模态的语义或光谱属性。因此,融合模型需要同时关注空间域局部细节和频率域全局结构。
方法框架概览
SFINet 的基本输入可以抽象成两类:低分辨率目标模态经过上采样后的特征,以及高分辨率引导模态特征。网络由多个 SFIB(Spatial-Frequency Information Integration Block)级联构成,每个 SFIB 都包含三部分:
- Frequency Domain Branch, FD:用傅里叶变换处理振幅和相位,获得全局频率表征。
- Spatial Domain Branch, SD:用可逆神经算子建模局部空间信息,保留细节与跨模态信息。
- Dual-domain Interaction, DI:让空间与频率表征互补,先补偿再融合。
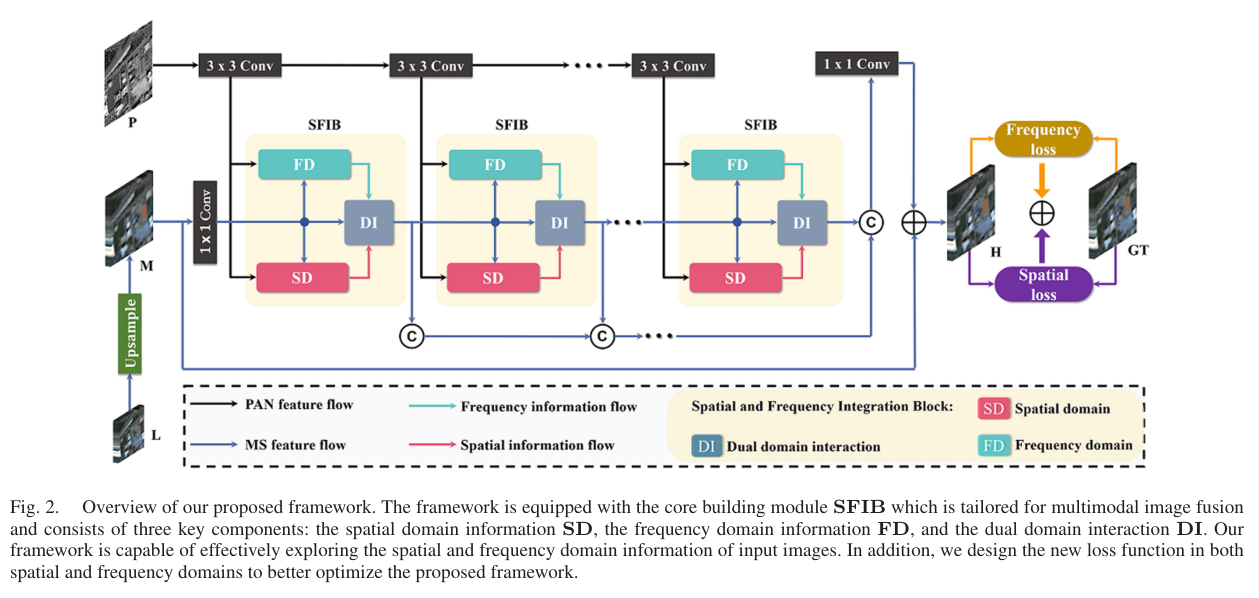
对全色锐化任务,论文将上采样后的 MS 图像记作 MMM,PAN 特征记作 FpF_pFp,网络输出为:
H=SFIBs(M,Fp)+M H = \operatorname{SFIBs}(M, F_p) + M H=SFIBs(M,Fp)+M
这里的残差连接有两个作用:一是让模型专注于补充缺失细节,二是保持目标模态的基础光谱/语义信息不被过度改写。
关键公式与机制拆解
1. 图像傅里叶变换
给定图像或特征图 x∈RH×W×Cx \in \mathbb{R}^{H \times W \times C}x∈RH×W×C,对每个通道独立做二维 DFT:
F(x)(u,v)=1HW∑h=0H−1∑w=0W−1x(h,w)e−j2π(hHu+wWv) \mathcal{F}(x)(u,v)=\frac{1}{\sqrt{HW}}\sum_{h=0}^{H-1}\sum_{w=0}^{W-1}x(h,w)e^{-j2\pi(\frac{h}{H}u+\frac{w}{W}v)} F(x)(u,v)=HW 1h=0∑H−1w=0∑W−1x(h,w)e−j2π(Hhu+Wwv)
频域复数可以拆成实部 R(x)R(x)R(x) 和虚部 I(x)I(x)I(x),进而得到振幅和相位:
A(x)(u,v)=R2(x)(u,v)+I2(x)(u,v) A(x)(u,v)=\sqrt{R^2(x)(u,v)+I^2(x)(u,v)} A(x)(u,v)=R2(x)(u,v)+I2(x)(u,v)
P(x)(u,v)=arctan(I(x)(u,v)R(x)(u,v)) P(x)(u,v)=\arctan\left(\frac{I(x)(u,v)}{R(x)(u,v)}\right) P(x)(u,v)=arctan(R(x)(u,v)I(x)(u,v))
论文把这个分解作为全局信息建模的入口:振幅分支关注频率能量,相位分支关注结构排列。
2. 频率分支:融合振幅与相位
对于第 iii 个 SFIB,设 PAN/RGB 引导特征为 FpiF_p^iFpi,MS/depth 目标特征为 FmsiF_{ms}^iFmsi。先分别做傅里叶变换:
A(Fpi),P(Fpi)=F(Fpi) A(F_p^i), P(F_p^i)=\mathcal{F}(F_p^i) A(Fpi),P(Fpi)=F(Fpi)
A(Fmsi),P(Fmsi)=F(Fmsi) A(F_{ms}^i), P(F_{ms}^i)=\mathcal{F}(F_{ms}^i) A(Fmsi),P(Fmsi)=F(Fmsi)
随后用两个操作 OA(⋅)O_A(\cdot)OA(⋅) 和 OP(⋅)O_P(\cdot)OP(⋅) 分别融合振幅和相位:
A(Fpmi)=OA(CatA(Fpi),A(Fmsi)) A(F_{pm}^i)=O_A(\operatorname{Cat}A(F_p\^i), A(F_{ms}\^i)) A(Fpmi)=OA(CatA(Fpi),A(Fmsi))
P(Fpmi)=OP(CatP(Fpi),P(Fmsi)) P(F_{pm}^i)=O_P(\operatorname{Cat}P(F_p\^i), P(F_{ms}\^i)) P(Fpmi)=OP(CatP(Fpi),P(Fmsi))
最后通过逆傅里叶变换回到空间表示:
Ffrei=F−1(A(Fpmi),P(Fpmi)) F_{fre}^i=\mathcal{F}^{-1}(A(F_{pm}^i), P(F_{pm}^i)) Ffrei=F−1(A(Fpmi),P(Fpmi))
这个分支提供的是 image-wide receptive field,也就是空间卷积很难高效覆盖的全局频率上下文。
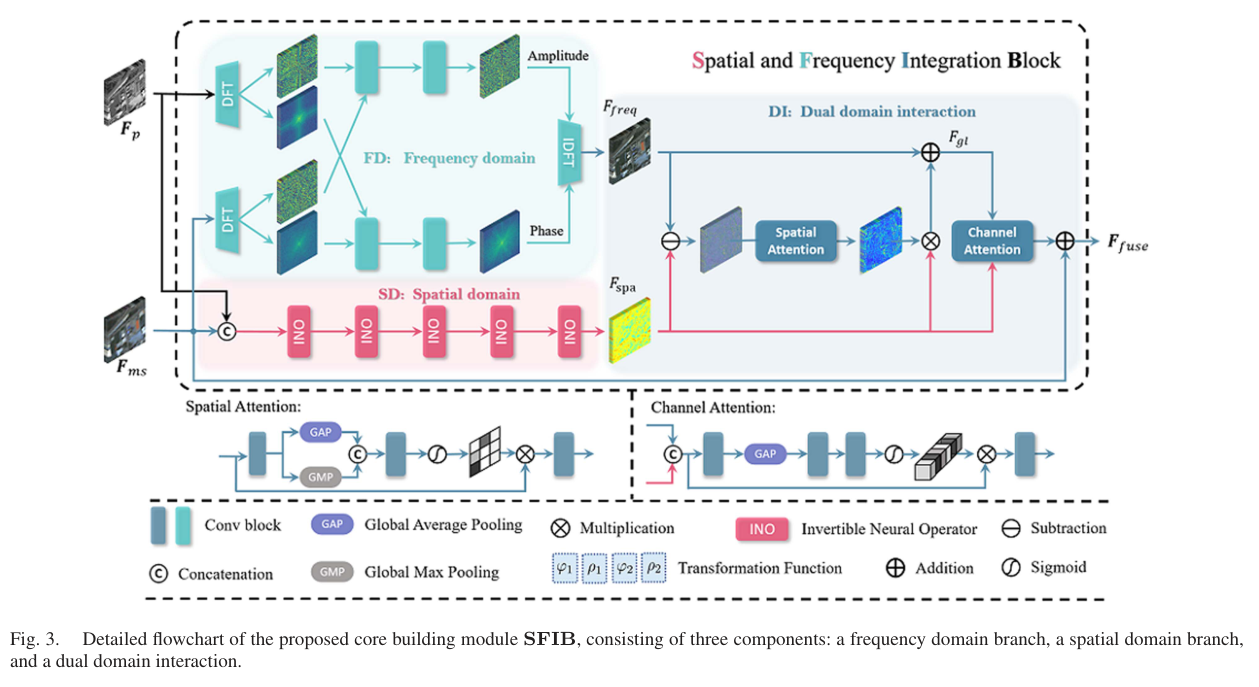
3. 空间分支:可逆神经算子保留局部细节
SFINet++ 相比 SFINet 的关键改进,是把原始空间分支里的普通卷积单元替换成 information-lossless invertible neural operator。对于第 iii 个 SFIB,耦合仿射变换写作:
Fspi=Fpi⊙exp(ϕ1(Fmsi))+ρ1(Fmsi) F_{sp}^i = F_p^i \odot \exp(\phi_1(F_{ms}^i)) + \rho_1(F_{ms}^i) Fspi=Fpi⊙exp(ϕ1(Fmsi))+ρ1(Fmsi)
Fsmsi=Fmsi⊙exp(ϕ2(Fpi))+ρ2(Fpi) F_{sms}^i = F_{ms}^i \odot \exp(\phi_2(F_p^i)) + \rho_2(F_p^i) Fsmsi=Fmsi⊙exp(ϕ2(Fpi))+ρ2(Fpi)
其中 ϕ(⋅)\phi(\cdot)ϕ(⋅) 是尺度函数,ρ(⋅)\rho(\cdot)ρ(⋅) 是平移函数,⊙\odot⊙ 表示 Hadamard 乘积。这个结构的直觉是:一个模态不只是简单拼接给另一个模态,而是通过尺度和平移动态调制另一模态的特征。
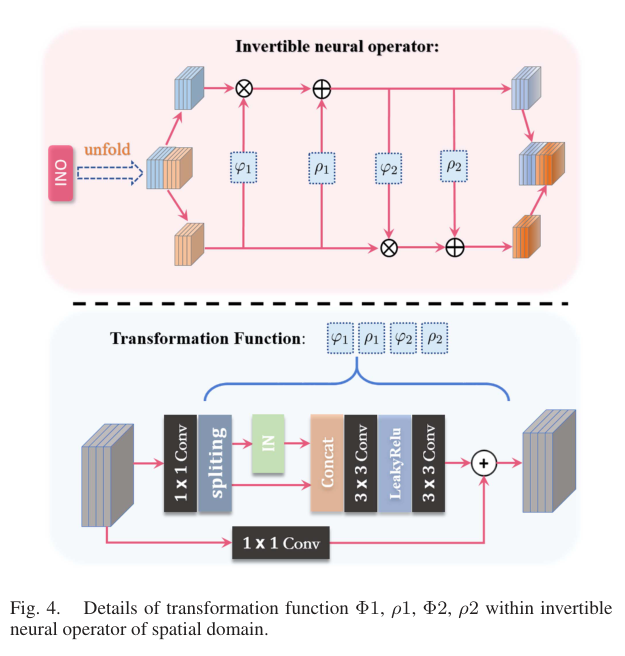
变换函数内部还使用 half-instance normalization。以 FpiF_p^iFpi 为例:
Fepi=Conv(Fpi) F_{ep}^i=\operatorname{Conv}(F_p^i) Fepi=Conv(Fpi)
F1epi,F2epi=split(Fepi) F_{1ep}^i,F_{2ep}^i=\operatorname{split}(F_{ep}^i) F1epi,F2epi=split(Fepi)
Fsipi=Conv(CatIN(F1epi),F2epi) F_{sip}^i=\operatorname{Conv}(\operatorname{Cat}\\operatorname{IN}(F_{1ep}\^i),F_{2ep}\^i) Fsipi=Conv(CatIN(F1epi),F2epi)
一半特征归一化,一半特征保持原始信息,可以在增强变换能力的同时减少信息损失。
4. 双域交互:先补偿,再融合
频率分支 FfreiF_{fre}^iFfrei 擅长全局结构,但细节不足;空间分支 FspaiF_{spa}^iFspai 擅长局部纹理,但全局上下文弱。论文设计了两步交互。
第一步是信息补偿,用二者差异引导空间注意力:
Fgli=Ffrei+SA(Ffrei−Fspai)×Fspai F_{gl}^i = F_{fre}^i + SA(F_{fre}^i-F_{spa}^i) \times F_{spa}^i Fgli=Ffrei+SA(Ffrei−Fspai)×Fspai
空间注意力由平均池化、最大池化和卷积得到:
Fspa=σ(Conv(CatFavg,Fmax)) F_{spa} = \sigma(\operatorname{Conv}(\operatorname{Cat}F_{avg},F_{max})) Fspa=σ(Conv(CatFavg,Fmax))
第二步是信息融合,将增强后的全局频率特征与局部空间特征做通道注意力:
Ffusei=CA(CatFgli,Fspai)+Fmsi F_{fuse}^i = CA(\operatorname{Cat}F_{gl}\^i,F_{spa}\^i) + F_{ms}^i Ffusei=CA(CatFgli,Fspai)+Fmsi
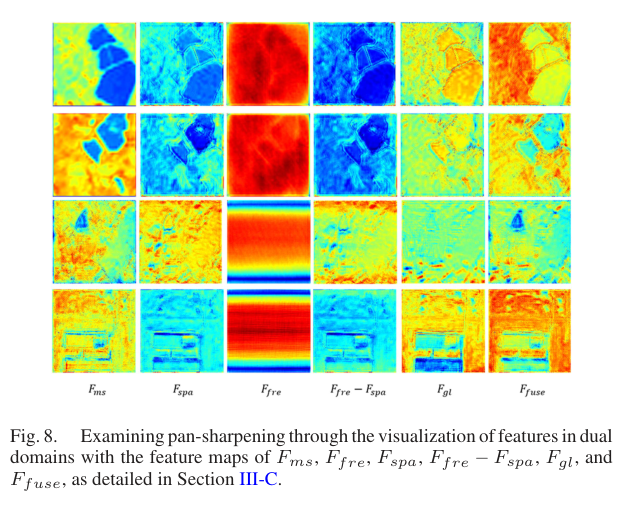
图 5 解释了为什么双域交互有意义:FfreF_{fre}Ffre 更像全局响应,FspaF_{spa}Fspa 更像局部纹理,二者差异能提示模型哪里需要补偿,融合后的 FfuseF_{fuse}Ffuse 同时保留更清晰的空间结构和目标模态信息。
5. 空间-频率联合损失
传统方法多用像素级空间损失。本文在此基础上加入频率域监督。空间损失为:
Lspa=∥H−GT∥1 \mathcal{L}_{spa}=\|H-GT\|_1 Lspa=∥H−GT∥1
频率损失同时约束振幅和相位:
Lfre=∥A(H)−A(GT)∥1+∥P(H)−P(GT)∥1 \mathcal{L}_{fre}=\|A(H)-A(GT)\|_1+\|P(H)-P(GT)\|_1 Lfre=∥A(H)−A(GT)∥1+∥P(H)−P(GT)∥1
总损失为:
L=Lspa+λLfre,λ=0.1 \mathcal{L}=\mathcal{L}{spa}+\lambda\mathcal{L}{fre}, \quad \lambda=0.1 L=Lspa+λLfre,λ=0.1
这个损失很关键:结构上做空间-频率双分支,训练目标也必须同时约束空间像素与频率分布,否则频率分支容易变成"附属模块"。
实验设置与评价任务
论文在两个任务上验证通用性:
| 任务 | 数据集 | 主要指标 | 目的 |
|---|---|---|---|
| 全色锐化 | WorldView-II、GaoFen2、WorldView-III | PSNR、SSIM、SAM、ERGAS、QNR 等 | 验证遥感 MS/PAN 融合能力 |
| 全分辨率全色锐化 | GaoFen2、WorldView-II real-world scenes | DλD_\lambdaDλ、DSD_SDS、QNR | 验证真实无 GT 场景泛化 |
| 深度超分辨率 | NYU v2、Middlebury、Lu | RMSE / MAE | 验证 RGB-D 多模态融合泛化 |
在训练上,全色锐化实验使用 Adam,batch size 为 4,初始学习率 5×10−45\times 10^{-4}5×10−4,训练 1000 epochs;深度超分辨率使用 NYU v2 训练,并在 Middlebury 和 Lu 上测试泛化。
主要实验结果分析
全色锐化实验里,SFINet / SFINet++ 在 WorldView-II、GaoFen2、WorldView-III 三个数据集上整体优于传统方法和深度学习方法。论文报告 SFINet++ 在 PSNR 上相对已有最佳方法分别提升约 0.10 dB、0.17 dB、0.09 dB。这个提升看起来不夸张,但在全色锐化这种指标已经高度竞争的任务里,配合 SAM、ERGAS、QNR 等指标同步改善,说明模型不是简单锐化边缘,而是在空间细节和光谱一致性之间取得更好平衡。
在真实全分辨率场景里,SFINet++ 也表现更稳。这里没有高分辨率 GT,所以评估更依赖无参考指标 DλD_\lambdaDλ、DSD_SDS 和 QNR。论文结论是:一些方法能增强细节,但容易牺牲光谱一致性;SFINet++ 在空间增强和光谱保持之间更均衡。
深度超分辨率实验进一步证明该框架不是只适用于遥感全色锐化。模型在 NYU v2 训练后,在 Middlebury 和 Lu 上也有较好泛化。对于 bicubic down-sampling,论文报告相比 DKN 在平均 RMSE 上分别降低 0.09、0.38、0.87(对应 4x、8x、16x);对于 direct down-sampling,也在 4x、8x、16x 上取得更低 RMSE。
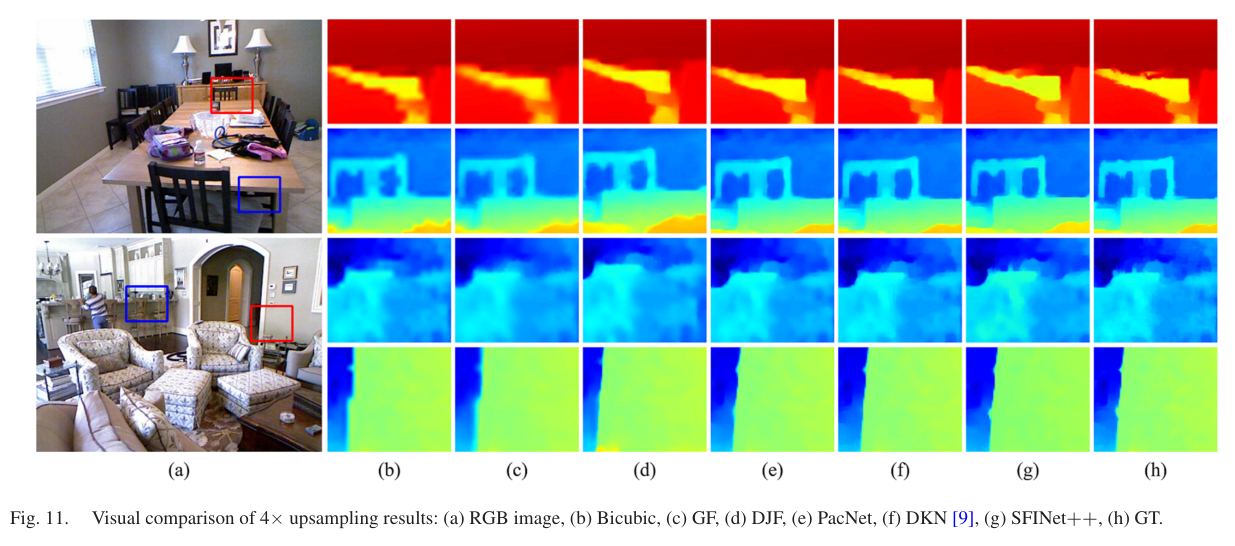
可视化上,SFINet++ 更擅长恢复边界和细长结构。传统引导滤波容易过平滑,部分深度学习方法会出现伪边界或局部 artifacts,而 SFINet++ 借助频率全局信息与空间局部细节的交互,能得到更清晰的深度边缘。
消融实验与机制验证
论文的消融实验主要回答三个问题:
- SFIB 数量是否越多越好? 结果显示,模块数从 1 增加到 8 时性能持续提升,但继续增加会出现收益饱和甚至下降。论文默认选择 K=5K=5K=5,在性能和计算量之间折中。
- 频率分支是否必要? 去掉频率分支后,性能明显下降,说明全局频率信息不是可有可无的装饰,而是恢复高质量融合结果的关键。
- 频率损失是否必要? 去掉频率损失后,各项指标严重退化。这说明频率域监督直接影响模型能否学到正确的全局频率分布。
方法价值与技术启示
我认为这篇论文最有价值的地方不在于"用了 FFT",而在于它把频域建模做成了完整闭环:
- 问题动机闭环:从下采样丢失高频信息出发,说明为什么多模态融合天然需要频域视角。
- 结构设计闭环:频率分支负责全局,空间分支负责局部,双域交互负责互补融合。
- 优化目标闭环:除了像素级空间损失,还用振幅和相位约束频率域恢复。
- 任务泛化闭环:同一个框架能覆盖全色锐化和深度超分辨率,说明空间-频率思想具有一定通用性。
这也给后续多模态融合模型一个很清晰的启示:多模态不只是"通道拼接 + 卷积融合",还应该分析不同模态在频率结构、相位边界和全局能量分布上的互补关系。
局限性与后续研究方向
当然,SFINet 仍有一些值得继续推进的地方:
- 频域处理虽然带来全局感受野,但 FFT 和双分支结构会增加工程复杂度。
- 论文主要验证了 PAN/MS 和 RGB/depth 两类场景,面向红外、SAR、事件相机等更复杂模态还需要进一步验证。
- 频率域里的振幅/相位融合目前仍偏模块化,未来可以考虑更自适应的频带选择或可学习频率分解。
- 对无 GT 真实场景的评估仍依赖有限无参考指标,真实业务质量还需要更多主观和任务级评估。
总结
SFINet / SFINet++ 可以看作多模态图像融合从"空间域卷积映射"走向"空间-频率双域协同学习"的代表性尝试。它把全局频率上下文、局部空间纹理、双域交互补偿和频率损失放进同一个框架,在全色锐化和深度超分辨率两个任务上都取得了较强表现。对于需要同时保持结构、细节和模态一致性的融合任务,这种空间-频率统一建模思路很值得继续跟进。