1.先说两者区别
在 PyTorch 中,nn.BCEWithLogitsLoss() 和 nn.BCELoss() 都是用于二分类任务(Binary Cross Entropy)的损失函数,但它们在处理输入数据的阶段上有着关键的区别。
简单来说:一个自带 Sigmoid 激活函数,一个不带。
核心区别
1. nn.BCELoss()
-
数学公式 :
-
输入要求 :输入的数据
必须是已经经过 Sigmoid (或其它归一化)映射到
-
标准流水线:
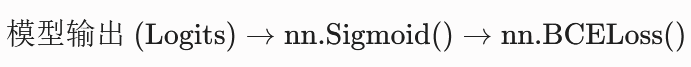
2. nn.BCEWithLogitsLoss()
-
数学公式 :将 Sigmoid 融合进了 BCE 公式中,即
-
输入要求 :输入的是模型直接输出的 Logits (即没有经过激活函数的原始得分,数值范围在
-
标准流水线:
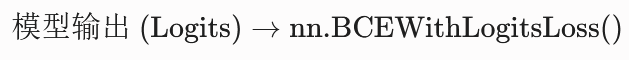
为什么推荐使用 nn.BCEWithLogitsLoss()?
在实际开发中,强烈推荐优先选择 nn.BCEWithLogitsLoss()。原因主要有两个:
1. 数值稳定性(Log-Sum-Exp 技巧)
当使用 nn.BCELoss() 时,你需要手动计算 torch.sigmoid(logits)。如果模型的输出非常大(例如 100)或非常小(例如 -100),Sigmoid 的结果会无限接近 1 或 0。
在后续计算 或
时,极易出现
的情况,从而导致数值溢出,产生
NaN(Not a Number)。
而 nn.BCEWithLogitsLoss() 在底层将 Sigmoid 和 BCE 结合在了一起,利用了数学上的优化技巧(Log-Sum-Exp),避免了直接计算接近 0 的对数,极大地提高了训练的数值稳定性。
2. 简化代码结构
不需要在网络结构的最后专门加一层 nn.Sigmoid(),模型只负责输出 Raw Scorers(Logits),损失函数负责处理激活和损失计算,逻辑更清晰。
代码对比示例
通过代码可以直观地看到,两者的计算结果在数学上是完全等价的:
python
import torch
import torch.nn as nn
# 模拟模型的原始输出 (Logits)
logits = torch.tensor([1.5, -2.0, 0.5], dtype=torch.float32)
# 真实的标签 (Labels)
targets = torch.tensor([1.0, 0.0, 1.0], dtype=torch.float32)
# --- 方法 1: 使用 BCELoss (需要手动显式调用 Sigmoid) ---
bce_loss = nn.BCELoss()
probs = torch.sigmoid(logits) # 先转为概率: [0.8176, 0.1192, 0.6225]
loss_method1 = bce_loss(probs, targets)
# --- 方法 2: 使用 BCEWithLogitsLoss (直接传入 Logits) ---
bce_with_logits_loss = nn.BCEWithLogitsLoss()
loss_method2 = bce_with_logits_loss(logits, targets)
print(f"BCELoss 结果: {loss_method1.item():.4f}")
print(f"BCEWithLogitsLoss 结果: {loss_method2.item():.4f}")
# 输出结果完全一致,例如:0.2974决策指南(如何选择)
你可以根据你当前模型最后一层的输出来决定:
-
选择
nn.BCEWithLogitsLoss()(首选):-
你的网络最后一层是
nn.Linear,没有加任何激活函数。 -
你想追求更好的数值稳定性,防止训练过程中突发
NaN。
-
-
选择
nn.BCELoss():-
你的网络结构是现成的,且最后一层已经固化了
nn.Sigmoid()。 -
在推理(Predict)阶段,你必须从网络直接拿到概率值,且不想拆分网络结构。
-
⚠️ 避坑提示 :千万不要在网络最后一层加了
nn.Sigmoid()的同时,又使用nn.BCEWithLogitsLoss(),这相当于对模型输出做了两次 Sigmoid,会导致模型无法正常收敛。
2.BiLSTM过拟合 + 验证损失上下震荡问题
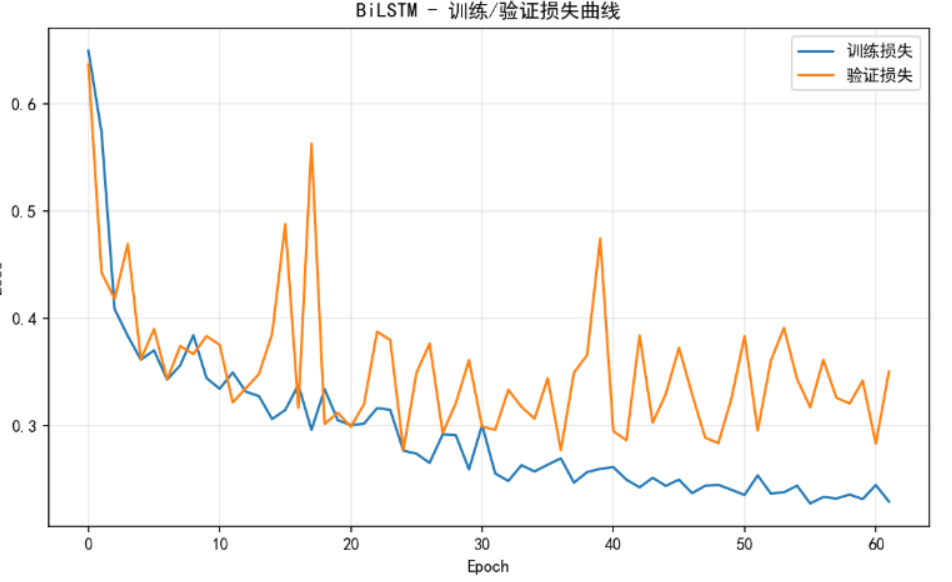
Epoch 5/80 - Train Loss: 0.3616, Val Loss: 0.3619
Epoch 10/80 - Train Loss: 0.3445, Val Loss: 0.3837
Epoch 15/80 - Train Loss: 0.3063, Val Loss: 0.3858
Epoch 20/80 - Train Loss: 0.3053, Val Loss: 0.3122
Epoch 25/80 - Train Loss: 0.2768, Val Loss: 0.2774
Epoch 30/80 - Train Loss: 0.2594, Val Loss: 0.3613
Epoch 35/80 - Train Loss: 0.2575, Val Loss: 0.3066
Epoch 40/80 - Train Loss: 0.2599, Val Loss: 0.4746
Epoch 45/80 - Train Loss: 0.2440, Val Loss: 0.3297
Epoch 50/80 - Train Loss: 0.2404, Val Loss: 0.3254
Epoch 55/80 - Train Loss: 0.2442, Val Loss: 0.3437
Epoch 60/80 - Train Loss: 0.2317, Val Loss: 0.3421
早停触发!最佳epoch: 37, 最佳验证损失: 0.2774
图片和上面的信息是我训练BiLSTM模型过程中的训练损失和验证损失的变化过程,从0轮-60轮的整个过程都只有Train Loss在下降,而Val Loss一直在0.3-0.4之间上下震荡并且整体也不下降,整个过程损失极其不稳定,请问这是出现了什么问题?
问题分解
问题 A:训练 loss 持续下降,验证 loss 在 epoch 20 之后不再下降 → 过拟合(主因)
证据链:
- Epoch 5:train 0.36 / val 0.36(健康)
- Epoch 25:train 0.28 / val 0.28(健康,最佳点附近)
- Epoch 60:train 0.23 / val 0.32~0.47(train-val gap 0.1+)
- 早停在 best epoch 37 (val=0.2774) 触发,这是预期内的正常行为
你的样本规模 vs 模型容量已经接近临界点:
- 训练样本只有 ~3150(70% × 4500)
- BiLSTM 双向 2 层 + hidden_dim=64 + FC 三层 ≈ 5~6 万参数
- weight_decay=1e-4 偏弱
- fc_dropout=0.4 看似够,但配合 BiLSTM 隐状态信息冗余,模型仍能记住训练集
问题 B:验证 loss 出现 0.40 → 0.56 → 0.30 这种 垂直尖刺 → BCELoss + Sigmoid 的数值灾难(很重要)
这是你这条曲线最异常的现象,单看 train-val gap 不会出现这种单 epoch 跳一倍的剧烈震荡。根因:
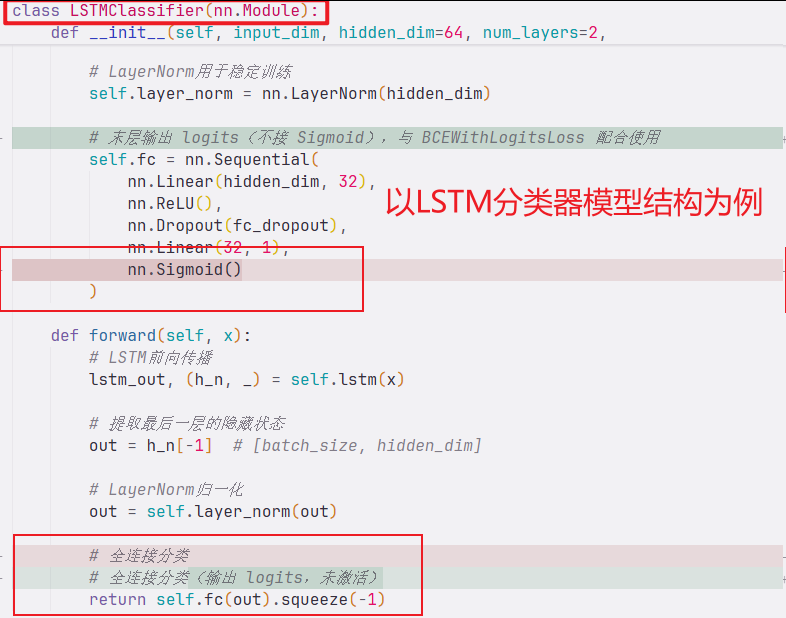
nn.Linear(32, 1),
nn.Sigmoid() # 模型最后强行压到 (0,1)
...
criterion = nn.BCELoss() # 输入概率,已经压过的概率这套组合的致命点:当模型对某个验证样本自信地错了 (比如真实标签 1,预测 0.001),它的 BCE 单点 loss 是 -log(0.001) ≈ 6.9,而正常样本的 loss 大约 0.20.5。**只要 batch 里出现 12 个这种"自信错误"样本,整个 batch 的平均 loss 就会被拉到 0.5 以上**。
这正好对应你看到的尖刺规律:
- Epoch 17 那个 0.56 的尖刺:恰好出现在模型刚开始真正"自信化"的拐点
- Epoch 30~50 之间的反复尖刺:训练集越拟合,对验证集中类别不均衡的少数恶意样本犯"自信错误"的概率越高
- 训练 loss 看不到尖刺:因为 dropout 让训练时模型不会那么自信
nn.Sigmoid() + BCELoss 走的不是 log-sum-exp 数值技巧,没有 logit clipping,扁平区的梯度也是 0。等价于直接让"困难样本"在评估时贡献几乎无界的 loss。
问题 C:类别 2:1 不均衡,BCE 没设 pos_weight
3000 正常 vs 1500 恶意。模型倾向预测"正常",对少数的恶意样本一旦犯错就和上面问题 B 叠加,进一步放大尖刺。
建议的修复(按优先级)
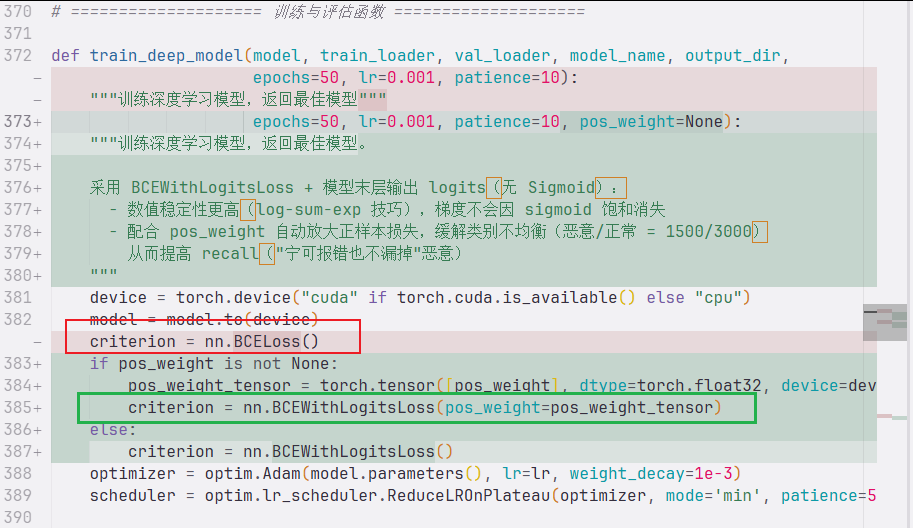
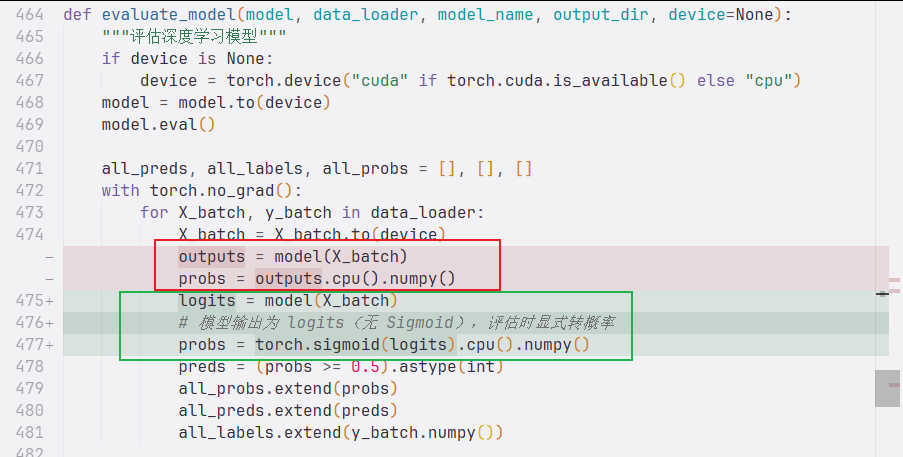
优先级 1:消除 val loss 尖刺
把所有 5 个模型末层的 nn.Sigmoid() 删掉,把 nn.BCELoss() 换成 nn.BCEWithLogitsLoss(pos_weight=...),评估时再 torch.sigmoid(logits)。
这个改动之后:
- 数值稳定,"自信错误"样本贡献的 loss 被截断
- 顺便解决类别不均衡(pos_weight=2.0 让恶意类梯度加权 2 倍)
- val loss 曲线会立刻变光滑,单纯过拟合的渐进上升而不是尖刺
优先级 2:抑制过拟合
最有性价比的两项:
weight_decay=1e-4→5e-4或1e-3- batch_size 32 → 64:梯度估计更稳,配合学习率不变即可
如果还要更激进,把 BiLSTM 的 hidden_dim=64 降到 32,参数量减半。
优先级 3:监控指标改成 val F1 而不是 val loss
你现在按 val_loss 选最佳模型,但 val_loss 因为问题 B 不可靠。直接监控 val F1 更稳,逻辑:
# 保存最佳模型时
val_metrics = evaluate_model(model, val_loader, ...)
val_f1 = val_metrics['f1_score']
if val_f1 > best_val_f1:
best_val_f1 = val_f1
torch.save(...)要不要我直接改?
我建议这样推进,让你能逐步验证每一项的效果:
- 先只做优先级 1(改 loss + 加 pos_weight),重跑 BiLSTM 看曲线 ------ 你会看到 val 的尖刺消失
- 再做优先级 2(weight_decay + batch_size)------ val 曲线整体抬高的现象会被压制
- 如果还过拟合,再考虑降 hidden_dim 或动监控指标
要不要我现在就改第 1 步?这是修改最小、收益最直接的一步,改完前你可以保留当前代码备份对比。
3.代码直观对比Diff
1.模型的末层 nn.Sigmoid() 全部删除
2.改训练函数:用 BCEWithLogitsLoss(pos_weight=...) 替代 BCELoss,评估处增加 torch.sigmoid()。