深度学习导论:从"让计算机总结规律"到神经网络表征学习
深度学习入门专栏 · 第 1 篇
适合读者:刚接触人工智能、机器学习或深度学习的学习者
摘要
深度学习是现代人工智能的重要技术基础。它的核心思想是:利用多层神经网络从数据中自动学习有效表示,并将这些表示用于分类、检测、预测、生成等任务。与依赖人工规则或手工特征工程的传统方法相比,深度学习更擅长处理图像、语音、文本、时序信号等高维复杂数据。本文从规则驱动与数据驱动的差异出发,解释人工智能、机器学习与深度学习之间的关系,进一步介绍神经网络的多层表征、模型训练流程、典型应用、优势局限和入门学习路径。为便于理解,文中结合猫狗识别、学习时间与考试分数预测等直观例子,并给出简单代码示例和运行结果。
关键词: 深度学习;机器学习;人工智能;神经网络;表征学习;数据驱动建模
1. 为什么需要深度学习
计算机程序最传统的工作方式是"人写规则,机器执行规则"。例如,要让计算机判断一张图片中是猫还是狗,最直接的想法是人为设计判断条件:耳朵尖可能是猫,嘴巴长可能是狗,胡须明显可能是猫,体型较大可能是狗。
这种方法在简单任务中有效,但在真实图像中很快会遇到困难。图片可能光线很暗,动物可能只露出半张脸,背景可能很杂乱,猫和狗的体型、毛色、姿态也存在巨大差异。此时,人很难把所有判断规则完整写出来。
机器学习改变了这个思路:不再要求人手写全部规则,而是把大量样本交给模型,让模型从样本中学习输入与输出之间的规律。深度学习进一步使用多层神经网络,让模型自动学习更复杂、更抽象的特征表示。
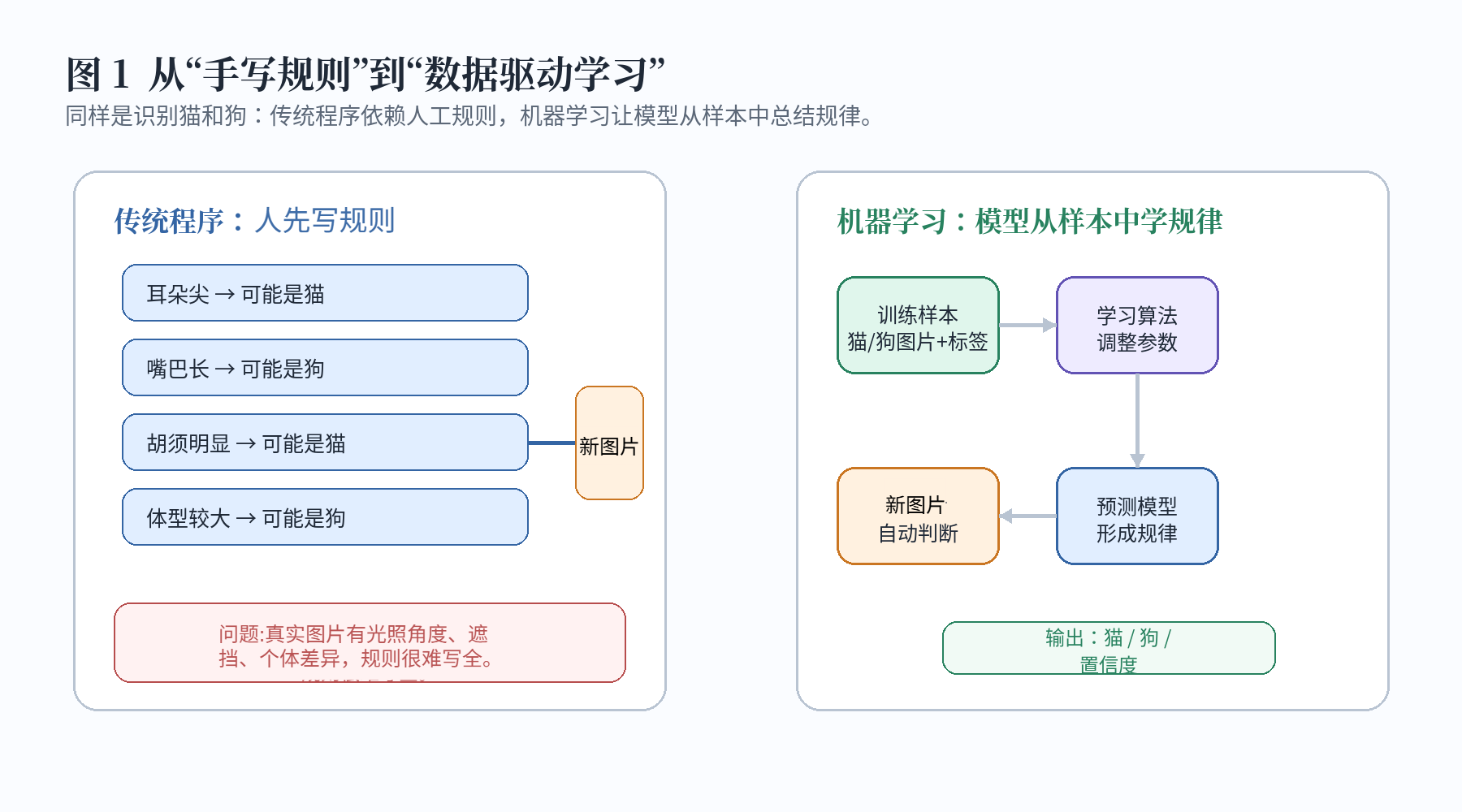
这个转变非常关键。传统程序更像是"人把经验翻译成代码",而机器学习和深度学习更像是"人提供样本,模型自己总结经验"。
2. 人工智能、机器学习与深度学习的关系
人工智能、机器学习和深度学习不是三个完全并列的概念,而是存在包含关系。
人工智能(Artificial Intelligence, AI)是更大的研究领域,目标是让机器具备一定的感知、推理、决策或生成能力。机器学习(Machine Learning, ML)是实现人工智能的重要路径,它强调从数据中学习规律。深度学习(Deep Learning, DL)是机器学习中的一个重要分支,通常以多层神经网络为主要模型结构。
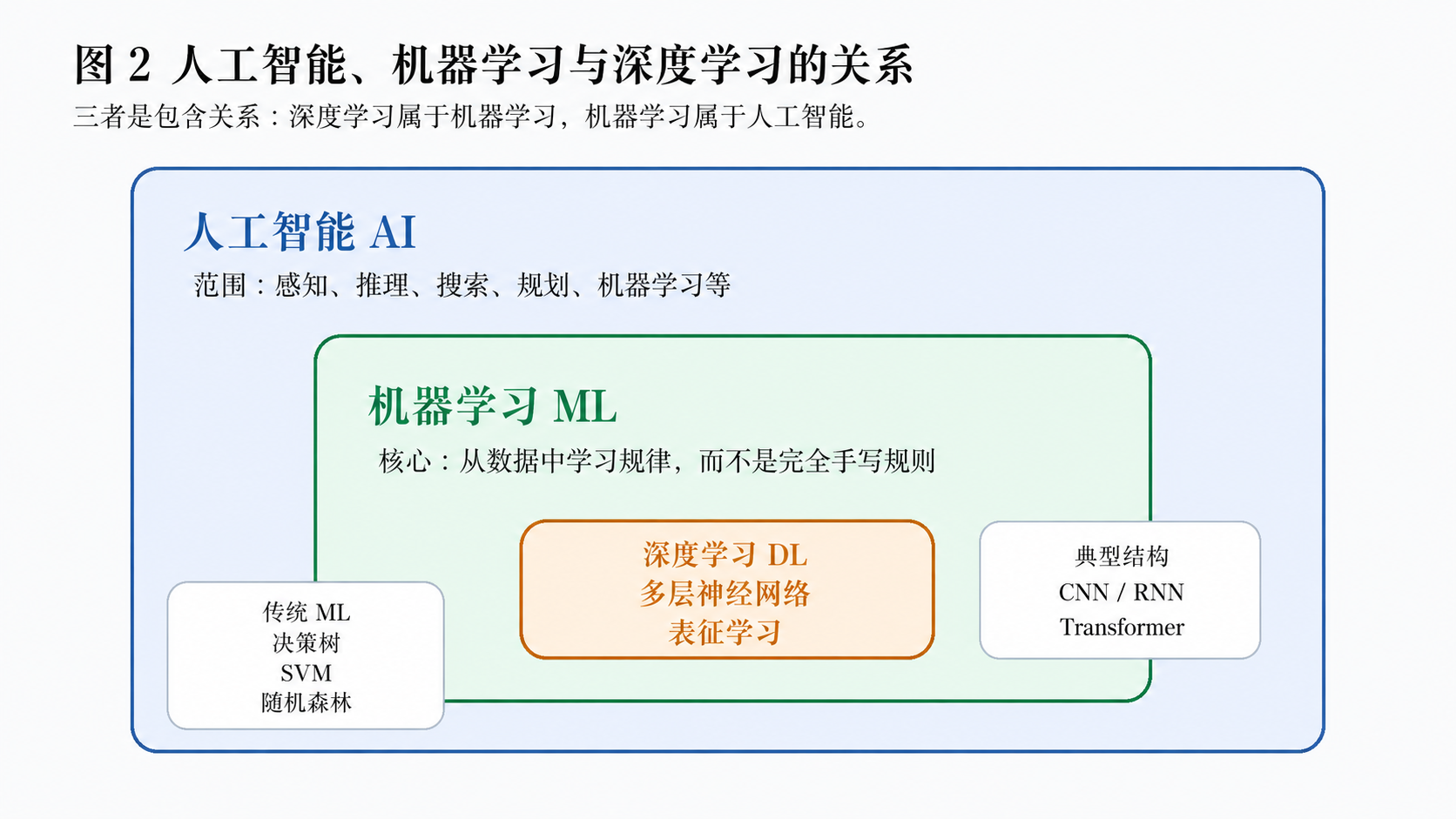
可以用一句话概括:
深度学习属于机器学习,机器学习属于人工智能;但并非所有人工智能方法都是机器学习,也并非所有机器学习方法都是深度学习。
例如,决策树、随机森林、支持向量机等方法通常属于传统机器学习;卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)和 Transformer 等模型,则属于深度学习的重要模型结构。
3. "深度"到底是什么意思
深度学习中的"深度",主要指神经网络具有多个可训练层。每一层都会对输入数据进行一次变换,浅层通常学习比较简单的模式,深层逐渐组合出更抽象的表示。
以猫狗图片识别为例,可以把神经网络的学习过程粗略理解为:
- 浅层可能关注边缘、颜色变化、纹理等基础模式;
- 中间层可能组合出耳朵、眼睛、鼻子、毛发等局部结构;
- 深层可能形成与"猫"或"狗"相关的整体判断依据;
- 输出层给出最终预测结果,例如"猫的概率为 0.82"。
需要注意的是,这是一种便于理解的功能性解释。真实神经网络内部学习到的是高维数学表示,并不一定像人一样明确存储"耳朵""胡须"这样的概念。
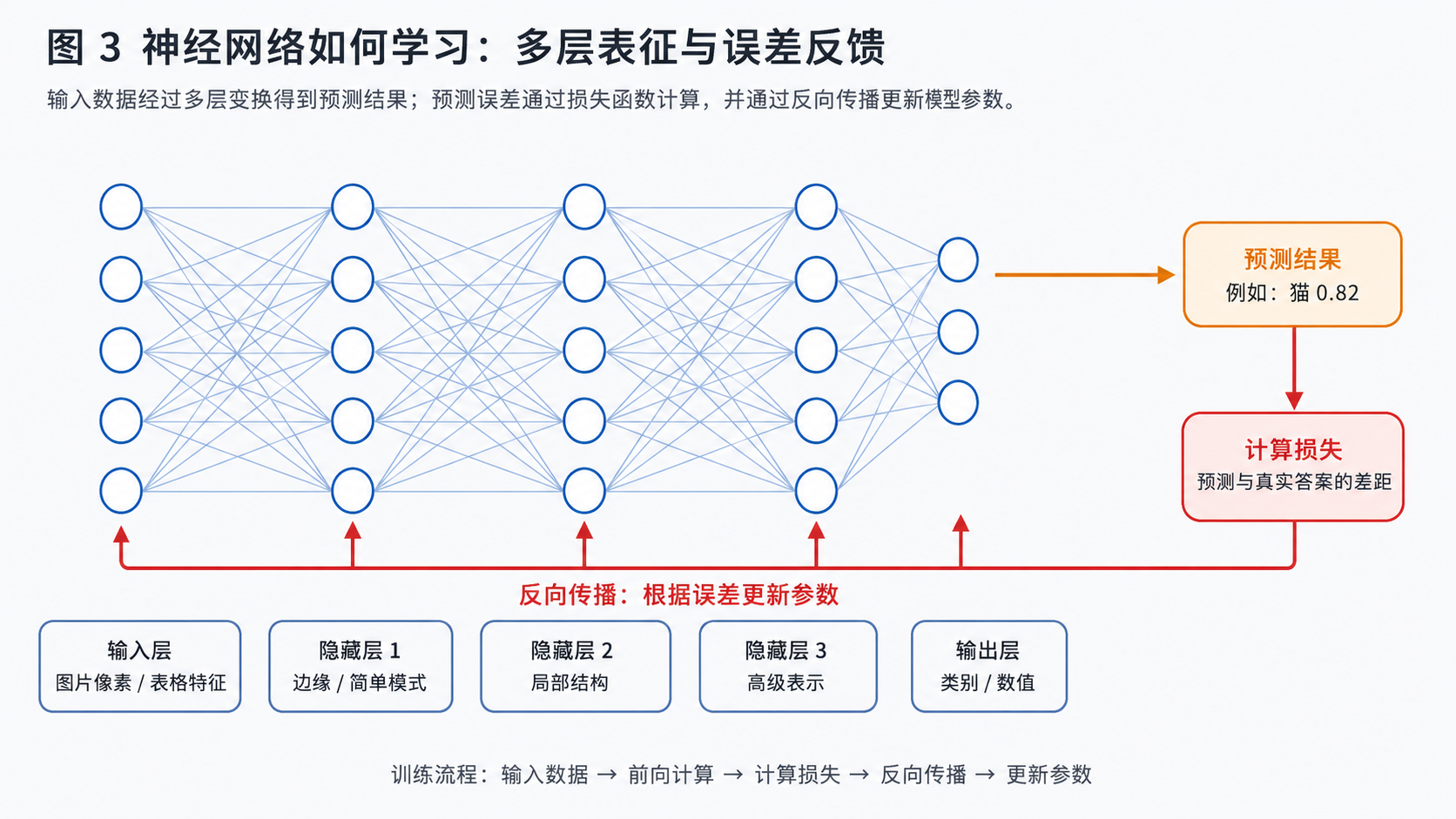
神经网络之所以强大,一个重要原因是它可以自动完成特征学习。传统图像识别往往需要人工设计边缘、纹理、颜色直方图等特征;深度学习模型则可以在训练过程中自己学习哪些特征对任务有用。
4. 神经网络到底在学习什么
神经网络训练的本质是"不断减少预测错误"。
设输入样本为 (x),真实标签为 (y),神经网络的预测函数为 (f_\theta(x)),其中 (\theta) 表示模型参数。训练的目标可以写成:
minθL(fθ(x),y) \min_{\theta} \mathcal{L}\left(f_\theta(x), y\right) θminL(fθ(x),y)
其中,(\mathcal{L}) 是损失函数,用来衡量预测结果和真实答案之间的差距。损失越小,说明模型预测越接近真实答案。
可以用"做菜调盐"的例子理解这个过程。第一次做菜盐放多了,下一次就少放一点;如果又太淡,再稍微加一点。经过多次尝试,盐量会逐渐接近合适范围。神经网络训练也是类似的:模型先预测,计算错误,再根据错误调整参数。
一个典型训练循环包括:
- 输入训练数据;
- 模型进行前向传播,得到预测结果;
- 使用损失函数计算预测误差;
- 通过反向传播计算梯度;
- 使用优化器更新参数;
- 重复以上过程,直到模型性能趋于稳定。
常见优化算法包括随机梯度下降(SGD)、Momentum、RMSProp 和 Adam。对于初学者来说,先理解"模型根据错误不断调整参数"比立即推导复杂公式更重要。
5. 一个最小代码示例:从数据中学习规律
下面用一个非常简单的例子说明"模型从数据中学习规律"。
假设我们记录了学习时间和考试分数:
| 学习时间 / h | 考试分数 |
|---|---|
| 1 | 50 |
| 2 | 60 |
| 3 | 70 |
| 4 | 80 |
从表中可以看出,学习时间每增加 1 小时,分数大约增加 10 分。我们可以让模型根据已有数据学习这个关系,并预测学习 5 小时可能得到多少分。
python
import numpy as np
# 学习时间,单位:小时
x = np.array([1, 2, 3, 4])
# 考试分数
y = np.array([50, 60, 70, 80])
# 用一次多项式拟合线性关系:y = a*x + b
# coef[0] 是斜率 a,coef[1] 是截距 b
coef = np.polyfit(x, y, deg=1)
a, b = coef
# 预测学习 5 小时的分数
x_new = 5
y_pred = a * x_new + b
print(f"模型学到的关系:分数 = {a:.1f} × 学习时间 + {b:.1f}")
print(f"学习 {x_new} 小时的预测分数:{y_pred:.1f}")运行结果:
text
模型学到的关系:分数 = 10.0 × 学习时间 + 40.0
学习 5 小时的预测分数:90.0这个例子不是深度学习模型,但它体现了机器学习最基本的思想:模型没有被手工写入"学习 5 小时等于 90 分"的规则,而是从已有样本中拟合出了输入和输出之间的关系。
深度学习也是类似思想,只是它面对的数据更复杂,模型结构更复杂。例如,在图像识别中,输入不再是一个简单数字,而是一张由成千上万个像素组成的图片;输出也可能不是一个分数,而是"猫、狗、汽车、行人"等类别概率。
6. 再看一个"神经元"的简单计算
神经网络可以看作由许多"神经元"连接而成。一个最简单的神经元会完成三件事:输入特征、乘以权重、加上偏置,然后得到输出。
假设我们仍然用学习时间预测分数,可以写成:
y^=wx+b \hat{y} = w x + b y^=wx+b
其中,(x) 是学习时间,(w) 是权重,(b) 是偏置,(\hat{y}) 是预测分数。
python
# 一个最简单的"神经元"示例
x = 5 # 学习 5 小时
w = 10 # 每多学 1 小时,预测分数增加 10 分
b = 40 # 基础分数
y_hat = w * x + b
print(f"预测分数:{y_hat}")运行结果:
text
预测分数:90真实神经网络会有大量这样的权重和偏置。训练过程就是让这些参数不断调整,使模型的预测结果越来越接近真实答案。
7. 深度学习适合解决哪些问题
深度学习特别适合处理规律复杂、特征难以人工设计的问题。
7.1 图像识别
例如猫狗识别、人脸识别、工业缺陷检测、医学影像分析、农作物病害识别等。图像数据本质上是像素矩阵,人工设计所有有效特征非常困难,而 CNN 等深度模型可以自动学习图像中的边缘、纹理、局部结构和高级语义信息。
7.2 语音识别
语音数据是随时间变化的连续信号。深度学习可以学习声音片段与文字之间的对应关系,因此被广泛用于语音输入、智能音箱、会议转写等场景。
7.3 自然语言处理
文本分类、机器翻译、问答系统、摘要生成和大语言模型都与深度学习密切相关。Transformer 通过注意力机制建模词与词之间的关系,显著推动了自然语言处理和生成式人工智能的发展。
7.4 科研与工程应用
在科研和工程中,深度学习常用于材料缺陷检测、设备故障预测、遥感影像分析、种子活力检测、医学诊断辅助等任务。这类问题通常具有数据维度高、噪声复杂、人工规则难以完整描述等特点。
8. 深度学习的优势与局限
深度学习的主要优势是自动表征学习。模型可以直接从原始数据中学习任务相关特征,减少对人工特征工程的依赖。在数据充足、任务明确、训练流程规范的情况下,深度学习往往能够取得很好的效果。
但深度学习不是万能方法。它至少有以下局限:
- 依赖数据质量。 如果样本数量不足、标注错误较多或数据分布偏差明显,模型很难得到可靠结果。
- 容易过拟合。 模型可能把训练样本记得很熟,但遇到新样本时表现变差。
- 计算成本较高。 复杂模型通常需要 GPU 等硬件支持。
- 可解释性有限。 模型给出预测结果后,人不一定能完全解释其内部判断依据。
- 实验设计要求高。 必须严格区分训练集、验证集和测试集,避免数据泄漏和过度调参。
过拟合可以用"背例题"来理解。一个学生如果只背熟了练习册上的题,考试题稍微变化就不会做,说明他并没有真正掌握规律。模型也是一样:训练集表现很好,不代表在真实场景中也一定可靠。
9. 一个规范深度学习实验应该包含什么
一个完整实验通常包括:数据采集、数据清洗、数据标注、数据划分、模型构建、模型训练、验证集调参、测试集评估和误差分析。
其中,数据划分尤其重要:
- 训练集用于学习模型参数;
- 验证集用于选择模型和调整超参数;
- 测试集只用于最终性能评估。
如果测试集参与了模型选择或参数调整,最终结果就可能偏乐观,论文或报告中的结论也会变得不可靠。
常见评价指标包括 Accuracy、Precision、Recall、F1-score、ROC-AUC、PR-AUC 和 MSE 等。不同任务应选择不同指标。例如,在类别不平衡的二分类任务中,只报告 Accuracy 往往不够,还应结合 F1-score、ROC-AUC 或 PR-AUC 综合判断模型性能。
10. 初学者如何开始学习深度学习
建议按"概念---数学---代码---实验---应用"的顺序学习,而不是一开始就追逐复杂模型。
较合理的学习路径如下:
- 学会 Python 基础语法和常用库;
- 掌握 NumPy、Matplotlib 等科学计算工具;
- 理解训练集、验证集、测试集、损失函数、过拟合和泛化;
- 学习神经网络中的权重、偏置、激活函数、反向传播和优化器;
- 选择 PyTorch 或 TensorFlow 作为主要深度学习框架;
- 逐步学习 CNN、RNN、LSTM、Transformer 等典型结构;
- 通过图像分类、文本分类或时间序列预测等小项目形成完整训练经验。
学习深度学习时,不应只关注模型能不能跑起来,还要关注实验是否规范、数据是否可靠、评价指标是否合适、结论是否能够被结果支持。
11. 本篇小结
深度学习可以理解为机器学习中的多层神经网络方法。它的核心价值在于:从数据中自动学习有效表示,并用这些表示完成预测、分类、检测或生成任务。
本篇需要记住四点:
- 深度学习不是魔法,而是一种数据驱动建模方法;
- "深度"主要指模型具有多个可训练层;
- 神经网络训练的本质是不断减少预测误差;
- 可靠的深度学习结果依赖高质量数据、规范实验流程和合理评价指标。
下一篇将进一步介绍神经网络的基本组成,包括输入、权重、偏置、激活函数、损失函数和反向传播,并通过更具体的计算过程解释神经网络如何完成一次预测。
参考文献与推荐阅读
1 LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015 , 521 , 436--444. https://doi.org/10.1038/nature14539
2 Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning . MIT Press, 2016. https://www.deeplearningbook.org/
3 Krizhevsky, A.; Sutskever, I.; Hinton, G. E. ImageNet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems , 2012. https://proceedings.neurips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html
4 Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Advances in Neural Information Processing Systems , 2017. https://arxiv.org/abs/1706.03762
5 Chollet, F. Deep Learning with Python , 2nd ed.; Manning Publications, 2021.
6 Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 3rd ed.; O'Reilly Media, 2022.