Redis数据类型
- [Redis String](#Redis String)
- [Redis hash](#Redis hash)
- [Redis List](#Redis List)
- [Redis Set](#Redis Set)
- [Redis sorted set](#Redis sorted set)
Redis 包含五种基础数据类型(String、List、Set、ZSet、Hash),下面进行具体介绍
Redis String
一、关键特性
二进制安全:不会解析、转义任何特殊字符,可以存普通字符串、数字、JSON、图片字节、序列化对象等;
容量限制:一个 String 类型的值最多可以容纳 512 MB 数据;
支持数字原子操作:存整型字符串时,可直接自增 / 自减,单命令原子性,高并发无线程安全问题;
所有 Redis Key 本身也都是 String 类型。
二、底层实现
Redis String 类型底层是用 SDS(Simple Dynamic String,简单动态字符串)实现的。
SDS 核心源码结构(redis/src/sds.h)如下:
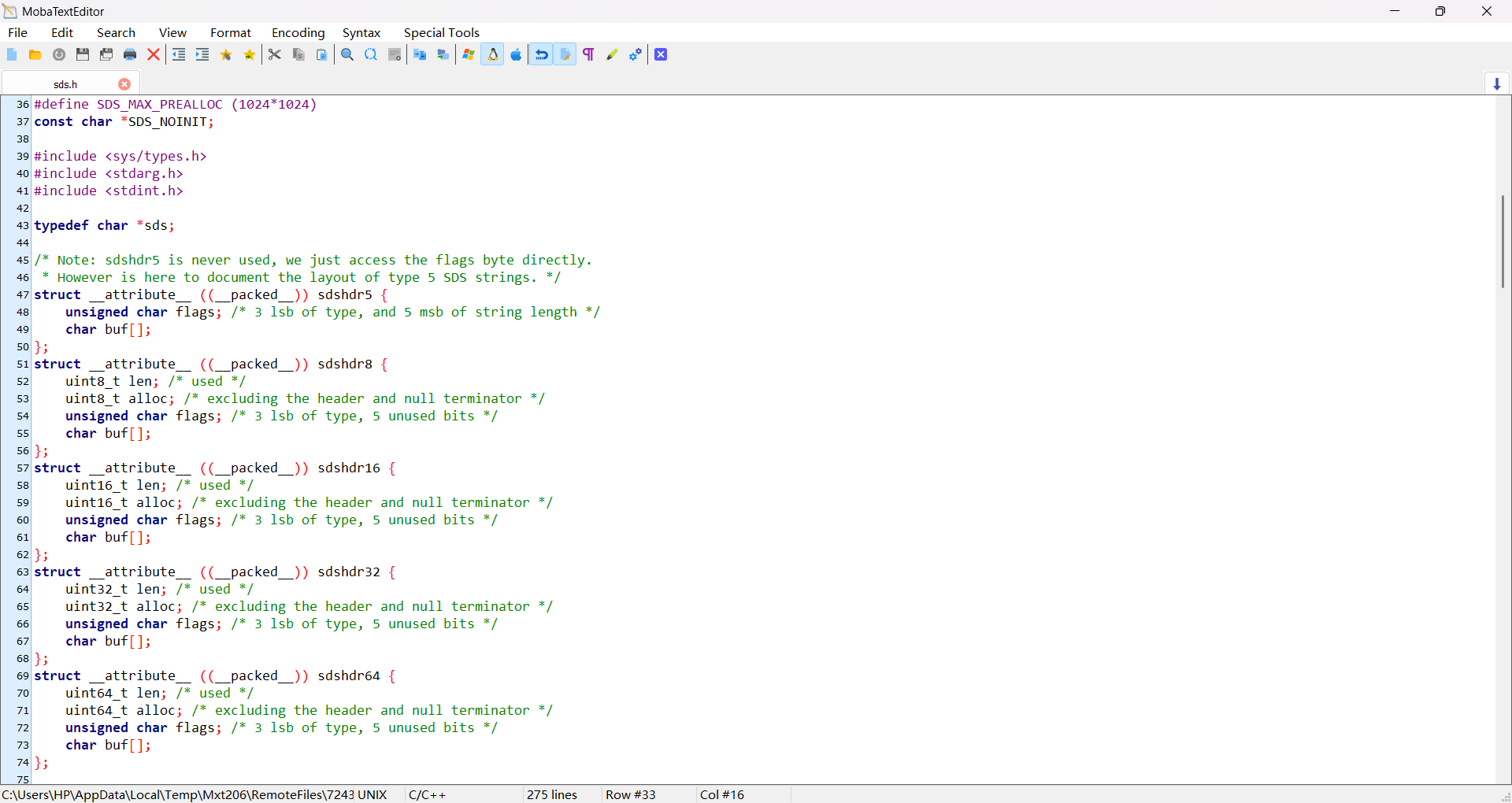
其核心结构体分为 sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64,其中sdshdr8/16/32/64共用统一设计,sdshdr5为极简专属结构;所有结构体区别仅在于len和alloc字段的位宽(8/16/32/64 位)。
标准 SDS 结构体(sdshdr8/16/32/64)内存布局:
len:实际存储数据的字节数(不包括末尾的 '\0'),用于 O(1) 获取长度;
alloc:已分配的用于存储数据的字节数(不包括末尾的 '\0'),即 buf\[\] 数组中数据部分的大小;
flags:1 字节,低 3 位标识 SDS 结构体类型(0=sdshdr5, 1=sdshdr8, 2=sdshdr16, 3=sdshdr32, 4=sdshdr64),高 5 位未使用;
char buf\[\]:字符数组,前 len 字节存储实际数据,第 len+1 字节为 '\0'(兼容 C 语言库函数)。
极简 SDS 结构体(sdshdr5):仅包含flags+buf,无len和alloc字段;flags 高 5 位存储字符串长度,低 3 位标识类型,仅用于长度 < 32 的内部短字符串。
SDS 类型选择机制:Redis 根据字符串长度自动选择最小结构体,以最大化内存效率。
C 语言通过字符数组实现字符串,存在三个致命缺陷,也是 Redis 设计 SDS 的核心原因:
C 字符串以 '\0' 作为结束标志,数据包含 '\0'(如图片、序列化对象、音频的二进制数据),会被截断,非二进制安全;
获取 C 字符串长度需遍历整个字符数组直到 '\0',时间复杂度为 O(n);
修改字符串(扩容 / 缩容)需频繁手动重分配内存,易引发内存碎片或溢出,且无法预分配空间优化性能。
Redis String 针对性解决了上述缺陷,SDS 对 C 字符串的核心优化如下:
通过 len 字段标记数据实际长度,不依赖 '\0' 判断结束,buf\[\] 可存储任意二进制数据,二进制安全;
获取长度只需直接读取 len 字段,无需遍历,时间复杂度为 O(1);
内存操作高效,扩容时会额外分配空闲空间(alloc - len),减少后续修改的内存重分配次数;缩容时不会立即释放多余内存,而是标记为空闲空间,供后续使用;
三、String 三种底层编码
int /embstr/raw 是 Redis String 类型在 RedisObject 层面的「上层内存优化编码」,用来决定要不要用 SDS、以及 SDS 和 RedisObject 怎么排布内存。
- int 编码
条件:value 是纯整数
底层:不创建任何 SDS 结构
直接把数字整型塞进 RedisObject 内部,不靠指针、不分配 SDS 内存。 - embstr 编码
条件:字符串 ≤44 字节
底层:使用最小的 sdshdr8 类型 SDS
内存布局:RedisObject + SDS 合并在同一块连续内存,一次 malloc 分配
特点:共用一块内存、无额外指针开销、缓存友好;只读不可改,一旦修改就废弃当前 embstr,转成 raw 编码。 - raw 编码
条件:字符串 > 44 字节 / embstr 被修改 / int 转字符串
底层:使用任意规格 SDS(sdshdr8/16/32/64 自动选)
内存布局:RedisObject 是一块内存,单独在堆上再分配一块 SDS 内存;通过 RedisObject->ptr 指针指向 SDS
特点:结构分离、支持动态扩容、支持长字符串、支持修改。
命令
赋值与取值:
SET key value
GET key
当键不存在时返回空结果

向尾部追加值:
APPEND key value
APPEND 的作用是向键值的末尾追加value。如果键不存在则将该键的值设置为value,即相当于 SET key value。返回值是追加后字符串的总长度。

获取字符串长度:
STRLEN key
STRLEN 命令返回键值的长度,如果键不存在则返回0。

同时设置/获取多个键值:
MSET key value key value ...
MGET key key ...

应用
java
package com.qcby.springbootTest;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.ValueOperations;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@SpringBootTest
@RunWith(SpringRunner.class)
public class SpringbootTest {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Test
public void hello() {
// 获取 String 类型操作工具
ValueOperations<String, Object> valueOps = redisTemplate.opsForValue();
valueOps.set("name", "minxr");
String ss = (String) valueOps.get("name");
System.out.println(ss);
// append
String oldValue = (String) valueOps.get("name");
valueOps.set("name", oldValue + "jintao");
ss = (String) valueOps.get("name");
System.out.println(ss);
// 覆盖原来的数据
valueOps.set("name", "jintao");
System.out.println(valueOps.get("name"));
// 删除key对应的记录
redisTemplate.delete("name");
System.out.println(valueOps.get("name"));
Map<String, Object> multiMap = new HashMap<>();
multiMap.put("name", "minxr");
multiMap.put("jarorwar", "aaa");
// 批量存储
redisTemplate.opsForValue().multiSet(multiMap);
// 批量获取
List<Object> mgetResult = redisTemplate.opsForValue().multiGet(Arrays.asList("name", "jarorwar"));
System.out.println(mgetResult);
// 无需手动关闭连接!RedisTemplate 自动管理连接池
}
}其中 ValueOperations<String, Object> valueOps = redisTemplate.opsForValue(); 是 Spring Data Redis 中获取操作 Redis String 类型(键值对)数据的专用操作对象。通过 redisTemplate 生成针对 Redis String 类型的操作实例 valueOps,后续可通过该实例执行 Redis String 类型的所有核心操作。

java
@Test
public void testKey() {
// 清空当前数据库
redisTemplate.getConnectionFactory().getConnection().flushDb();
System.out.println("清空数据库成功");
// 判断key是否存在
boolean exists = redisTemplate.hasKey("foo");
System.out.println(exists);
// 存储数据
redisTemplate.opsForValue().set("key", "values");
exists = redisTemplate.hasKey("key");
System.out.println(exists);
}其中 redisTemplate.getConnectionFactory().getConnection().flushDb(); 是调用 Redis 的FLUSHDB命令,清空当前选中的 Redis 数据库的所有数据。

java
@Test
public void testString() {
ValueOperations<String, Object> valueOps = redisTemplate.opsForValue();
try {
// 基础 set/get
valueOps.set("key", "Hello World!");
String value = (String) valueOps.get("key");
System.out.println(value);
// 清空数据
redisTemplate.getConnectionFactory().getConnection().flushDb();
System.out.println("清空数据库成功");
// 存储数据
valueOps.set("foo", "bar");
System.out.println(valueOps.get("foo"));
// 若key不存在,则存储
Boolean setNxResult = valueOps.setIfAbsent("foo", "foo not exits");
System.out.println(valueOps.get("foo"));
// 覆盖数据
valueOps.set("foo", "foo update");
System.out.println(valueOps.get("foo"));
// 追加数据
String oldFoo = (String) valueOps.get("foo");
valueOps.set("foo", oldFoo + " hello, world");
System.out.println(valueOps.get("foo"));
// 设置key的有效期,并存储数据
valueOps.set("foo", "foo not exits", 2, TimeUnit.SECONDS);
System.out.println(valueOps.get("foo"));
try {
Thread.sleep(3000); // 等待3秒,超过有效期
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(valueOps.get("foo"));
// 获取并更改数据
valueOps.set("foo", "foo update");
Object getSetResult = valueOps.getAndSet("foo", "foo modify");
System.out.println(getSetResult);
// 截取value的值
// RedisTemplate 无直接 getrange 方法,需手动截取字符串
String fooValue = (String) valueOps.get("foo");
String subValue = fooValue.substring(1, 4); // 截取索引1-3(左闭右开)
System.out.println(subValue);
// mset 批量存储
Map<String, Object> msetMap = new HashMap<>();
msetMap.put("mset1", "mvalue1");
msetMap.put("mset2", "mvalue2");
msetMap.put("mset3", "mvalue3");
msetMap.put("mset4", "mvalue4");
redisTemplate.opsForValue().multiSet(msetMap);
// 批量获取
List<Object> mgetList = valueOps.multiGet(Arrays.asList("mset1", "mset2", "mset3", "mset4"));
System.out.println(mgetList);
// 批量删除
Long delCount = redisTemplate.delete(Arrays.asList("foo", "foo1", "foo3"));
System.out.println(delCount);
} catch (Exception e) {
e.printStackTrace();
}
}其中 valueOps.setIfAbsent("foo", "foo not exits"); 是 Spring Data Redis 中对 Redis SETNX(SET if Not Exists)命令的封装。仅当指定的 Key 在 Redis 中不存在时,才将该 Key-Value 对写入 Redis,若 Key 已存在,则不执行任何操作。整个操作是原子性的,可直接用于实现分布式锁、防止重复写入等场景。

Redis hash
当使用 Redis String 存储序列化后的 JSON 数据时需要执行如下命令:
bash
SET user:1 '{"birthday":1557743055507,"ename":"zhangsan","districtId":2,"sex":1,"id":1,"edate":1557743055507,"age":18,"sal":8000.0}'查询该结果:
bash
GET user:1
返回的是完整 JSON 字符串
当基于 Redis 的 String 类型存储 JSON 序列化后的结构化数据,若仅需更新字段,需先从 Redis 中读取完整的 JSON 字符串并传输至应用层,随后将其反序列化为内存对象,在对象层面修改目标字段的属性值,完成后重新将整个对象序列化为 JSON 字符串,最终将新的 JSON 字符串全量覆写回 Redis 对应的键中。
该操作模式存在两类核心问题:
- 资源利用效率低下:若仅需更新单个字段,却需完成完整 JSON 字符串的网络传输、全量反序列化 / 序列化计算开销,以及全量数据的 Redis 写入操作,造成网络带宽、CPU 计算资源与 Redis 存储 IO 的无效消耗,且该浪费程度会随 JSON 数据体量的增大而显著加剧;
- 并发更新数据一致性风险:多线程 / 多进程并发更新不同字段时,若未引入并发控制机制,后执行的全量覆写操作会覆盖先执行操作的修改结果,导致更新丢失问题,破坏数据的最终一致性。
Redis Hash 是一种 键 - 字段 - 值(Key-Field-Value)三级映射的复合数据类型,属于 Redis 的基础数据结构。其本质是在单个 Redis 键(Key)下,构建一组无序的、唯一的字段(Field)到值(Value)的映射关系,可抽象为结构化的键值对容器。
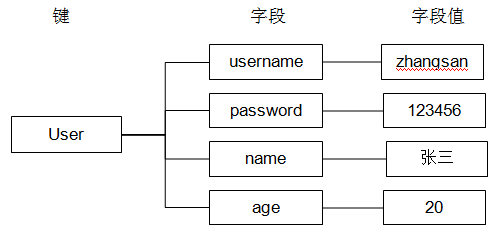
核心特性:
- 字段与值类型:Field 为字符串类型且在单个 Hash 内唯一;Value 为字符串(支持二进制数据,通过 SDS 存储);
- 容量上限:单 Hash 最大字段数 = 2^32 - 1;
- 原子性:对单个字段的所有操作(新增、修改、查询、删除)均为原子性操作,无需额外加锁即可避免并发更新冲突;
- 内存效率:无冗余序列化字符(如 JSON 的{}/""/,),字段与值直接映射;
- 时间复杂度:核心操作(HSET/HGET/HDEL)的时间复杂度均为 O(1),批量操作(HMSET/HMGET)的时间复杂度为 O(N)(N 为操作的字段数)。
从数据结构设计角度,Redis Hash 底层实现采用两种方式:
当 Hash 中字段 - 值对数量少且值较小时,采用压缩列表(ziplist) 存储,连续内存块的紧凑数据结构(lengthvaluelengthvalue...),无指针开销,以节省内存;
当数据量超过阈值(默认字段数 > 512 或 单个值 > 64 字节),自动转为哈希表(hashtable) 存储,保证高并发下的读写性能,时间复杂度均为 O(1)。
命令
一次设置与获取一个字段值
HSET key field value
HGET key field
HSET命令不区分插入和更新操作,当执行插入操作时HSET命令返回1,当执行更新操作时返回0

一次设置与获取多个字段值
HMSET key field value field value ...
HMGET key field field ...
HGETALL key

判断字段是否存在
HEXISTS key field

当字段不存在时赋值
HSETNX key field value
类似HSET,区别在于如果字段已经存在,该命令不执行任何操作。

删除字段
HDEL key field field ...
删除一个或多个字段,返回值是被删除的字段个数

获取字段名或字段值
HKEYS key
HVALS key

获取字段数量
HLEN key

应用
java
@Test
public void testHash() {
// 获取Hash类型的操作对象
HashOperations<String, String, String> hashOps = redisTemplate.opsForHash();
// 批量设置Hash字段
Map<String, String> pairs = new HashMap<>();
pairs.put("name", "Akshi");
pairs.put("age", "2");
pairs.put("sex", "Female");
hashOps.putAll("kid", pairs);
// 获取单个字段值(返回List)
List<String> name = hashOps.multiGet("kid", Collections.singletonList("name"));
System.out.println(name);
// 删除指定字段
hashOps.delete("kid", "age");
System.out.println(hashOps.multiGet("kid", Collections.singletonList("pwd")));
// 获取Hash的字段数量
System.out.println(hashOps.size("kid"));
// 判断Hash键是否存在
System.out.println(redisTemplate.hasKey("kid"));
// 获取所有字段名
System.out.println(hashOps.keys("kid"));
// 获取所有字段值
System.out.println(hashOps.values("kid"));
// 遍历所有字段和值
Set<String> keys = hashOps.keys("kid");
Iterator<String> iter = keys.iterator();
while (iter.hasNext()) {
String key = iter.next();
System.out.println(key + ":" + hashOps.multiGet("kid", Collections.singletonList(key)));
}
// 批量获取指定字段值
List<String> values = hashOps.multiGet("kid", Arrays.asList("name", "age", "sex"));
System.out.println(values);
// 获取所有字段名
Set<String> setValues = hashOps.keys("kid");
System.out.println(setValues);
// 获取所有字段值
values = hashOps.values("kid");
System.out.println(values);
// 获取整个Hash的所有字段和值
Map<String, String> allPairs = hashOps.entries("kid");
System.out.println(allPairs);
// 清空当前数据库
redisTemplate.getConnectionFactory().getConnection().flushDb();
System.out.println("清除当前数据库");
// 新增Hash数据
hashOps.put("hashs", "entryKey", "entryValue");
hashOps.put("hashs", "entryKey1", "entryValue1");
hashOps.put("hashs", "entryKey2", "entryValue2");
// 判断字段是否存在
System.out.println(hashOps.hasKey("hashs", "entryKey"));
// 获取单个字段值
System.out.println(hashOps.get("hashs", "entryKey"));
// 批量获取字段值
System.out.println(hashOps.multiGet("hashs", Arrays.asList("entryKey", "entryKey1")));
// 删除指定字段
Long delCount = hashOps.delete("hashs", "entryKey");
System.out.println(delCount);
// 字段值自增
// 注意:entryKey已被删除,此处会先初始化为0再自增123
Long incrResult = hashOps.increment("hashs", "entryKey", 123L);
System.out.println(incrResult);
// 获取所有字段名
System.out.println(hashOps.keys("hashs"));
// 获取所有字段值
System.out.println(hashOps.values("hashs"));
}HashOperations<String, String, String> hashOps = redisTemplate.opsForHash(); 是 Spring Data Redis 中获取操作 Redis Hash(哈希)类型数据的专用操作对象。通过 redisTemplate 生成针对 Redis Hash 类型的操作实例 hashOps,后续可通过该实例执行 Redis Hash 类型的所有核心操作。
其中 Collections.singletonList("name") 是 java.util.Collections 提供的静态方法,用于创建一个包含指定单个元素的不可变 List 集合。

Redis List
Redis List(列表)是一种有序、可重复、双向链表语义的字符串序列容器,其元素按插入顺序严格排序,支持通过正向索引(从 0 开始,0 表示首个元素)和反向索引(从 - 1 开始,-1 表示最后一个元素)访问指定位置的元素。List 的核心操作语义聚焦于列表的头部和尾部的元素插入、删除与查询,同时支持对指定区间的元素进行批量获取或裁剪。
Redis List 的底层实现是根据版本迭代和数据特征自适应优化:
Redis 3.2 版本之前:采用双结构自适应策略,当列表元素数量≤512 且单个元素字节数≤64 字节时,使用压缩列表(ziplist) 存储,连续内存块结构,最大化内存利用率;当数据规模突破上述阈值时,自动切换为双向链表(double linked list) 存储,通过节点指针实现双向遍历,保证头尾操作效率。
Redis 3.2 及以上版本:统一采用快速列表(quicklist) 作为底层存储结构。quicklist 本质是双向链表与压缩列表的复合结构,双向链表的每个节点(node)封装一个压缩列表(ziplist),列表元素被批量存储在 ziplist 中。该设计既保留了双向链表头尾操作高效的特性,又通过 ziplist 的紧凑存储降低了内存开销,是内存效率与操作性能的最优平衡。
命令
向列表两端增加元素。
LPUSH key value value ...
RPUSH key value value ...

从列表两端弹出元素
LPOP key
RPOP key
LPOP命令从列表左边弹出一个元素,会分两步完成,第一步是将列表左边的元素从列表中移除,第二步是返回被移除的元素值。

获取列表中元素的个数
LLEN key

获取列表片段
LRANGE key start stop
LRANGE 命令是列表类型最常用的命令之一,获取列表中的某一片段,将返回 start、stop 之间的所有元素(包含两端的元素),索引从0开始。索引可以是负数,如:"-1"代表最后边的一个元素。

删除列表中指定的值
LREM key count value
LREM 命令会删除列表中前count个值为value的元素,返回实际删除的元素个数。
根据count值的不同,该命令的执行方式会有所不同:
当count>0时, LREM会从列表左边开始删除。
当count<0时, LREM会从列表后边开始删除。
当count=0时, LREM删除所有值为value的元素。
获得/设置指定索引的元素值
LINDEX key index
LSET key index value

向列表中插入元素
LINSERT key BEFORE|AFTER pivot value
该命令首先会在列表中从左到右查找值为pivot的元素,然后根据第二个参数是BEFORE还是AFTER来决定将value插入到该元素的前面还是后面。
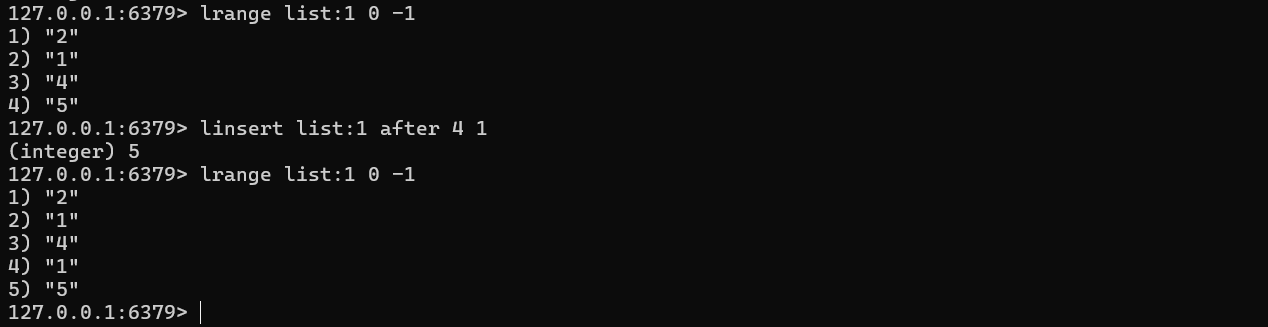
将元素从一个列表转移到另一个列表中
RPOPLPUSH source destination
从源列表 list 的尾部移除最后一个元素,并返回这个元素;将该元素添加到目标列表 newlist 的头部;若目标列表 newlist 不存在,会自动创建;若源列表 list 为空,命令返回 nil,且不会对目标列表做任何操作。

应用
java
@Test
public void testList() {
String messagesKey = "messages";
String listsKey = "lists";
// 开始前移除messages所有内容
redisTemplate.delete(messagesKey);
// 右推元素到messages
redisTemplate.opsForList().rightPush(messagesKey, "Hello how are you?");
redisTemplate.opsForList().rightPush(messagesKey, "Fine thanks. I'm having fun with redis.");
redisTemplate.opsForList().rightPush(messagesKey, "I should look into this NOSQL thing ASAP");
// 获取messages所有元素
List<Object> messagesValues = redisTemplate.opsForList().range(messagesKey, 0, -1);
System.out.println("messages列表内容:" + messagesValues);
// 清空当前数据库
redisTemplate.getConnectionFactory().getConnection().flushDb();
System.out.println("清空当前数据库成功");
// 左推元素到lists
redisTemplate.opsForList().leftPush(listsKey, "vector");
redisTemplate.opsForList().leftPush(listsKey, "ArrayList");
redisTemplate.opsForList().leftPush(listsKey, "LinkedList");
// 获取lists长度
Long listLength = redisTemplate.opsForList().size(listsKey);
System.out.println("lists列表长度:" + listLength);
// 获取lists前4个元素
List<Object> listRange = redisTemplate.opsForList().range(listsKey, 0, 3);
System.out.println("lists列表0-3索引内容:" + listRange);
// 修改lists索引0的元素
redisTemplate.opsForList().set(listsKey, 0, "hello list!");
System.out.println("修改lists索引0元素成功");
// 获取lists索引1的元素
Object listIndexValue = redisTemplate.opsForList().index(listsKey, 1);
System.out.println("lists索引1的元素:" + listIndexValue);
// 1删除lists中1个"vector"元素
Long removeCount = redisTemplate.opsForList().remove(listsKey, 1, "vector");
System.out.println("删除vector的数量:" + removeCount);
// 裁剪lists,只保留0-1索引
redisTemplate.opsForList().trim(listsKey, 0, 1);
System.out.println("裁剪lists为0-1索引成功");
// 列表左出栈
Object popValue = redisTemplate.opsForList().leftPop(listsKey);
System.out.println("lists左出栈元素:" + popValue);
// 获取lists所有剩余元素
List<Object> finalListValues = redisTemplate.opsForList().range(listsKey, 0, -1);
System.out.println("lists最终剩余内容:" + finalListValues);
}
Redis Set
Redis Set(集合)是一种无序、唯一字符串元素集合,属于 Redis 的五大基础数据类型之一。其设计核心目标是解决唯一性存储与数学集合运算两大场景,通过底层数据结构的智能选择与原子操作机制,实现高效、可靠的集合操作。
Redis Set 的底层实现:
- 整数集合(intset):内存紧凑优化存储
- 触发条件:集合内所有元素均为 64 位有符号整数,集合元素数量不超过 Redis 配置项 set-max-intset-entries(默认值 512)。
- 核心特性:
有序连续内存块结构,通过二分查找实现元素操作;
无哈希表指针开销,内存紧凑;
仅支持整数元素,无法存储字符串。
- 哈希表(hashtable):通用高效实现
- 触发条件(当集合满足以下任一条件):集合包含非整数元素,集合元素数量超过 set-max-intset-entries 阈值。
- 核心特性:
采用 Redis 通用的字典结构,将 Set 中的每个元素作为哈希表的键(Key),利用 Key 的唯一性天然保证 Set 元素不重复;
哈希表的值(Value)为固定空占位符,保证添加、删除、存在性判断的时间复杂度为 O (1);
intset 向哈希表的转换是单向不可逆的(即使后续元素数量减少或全部为整数,也不会回退)。
核心特性
唯一性:集合内不存在重复元素,执行 SADD 命令添加已存在的元素时,命令返回值为 0,集合本身无任何变化,天然支持去重场景;
无序性:元素无固定存储顺序,也无索引(区别于 Redis List 的索引访问),SMEMBERS命令返回元素的顺序与添加顺序无关;
原子性:所有操作(SADD/SREM/SMEMBERS 等)均为原子操作,操作要么完全执行,要么完全不执行,无中间状态,无需额外加锁;
元素类型:集合内所有元素均为字符串类型,不支持嵌套其他数据结构;
集合运算能力:支持原子性的数学集合运算(交集、并集、差集),运算性能由参与集合的大小决定(如交集SINTER的时间复杂度为 O (N*M),N 为最小集合大小,M 为集合数量)。
命令
增加/删除元素
SADD key member member ...
SREM key member member ...

获得集合中的所有元素
SMEMBERS key

判断元素是否在集合中,无论集合中有多少元素都可以极速的返回结果。
SISMEMBER key member

Redis sorted set
Redis 有序集合(Sorted Set,简称 ZSet)是在集合(Set)元素唯一核心特性的基础上,为每个元素(member)关联一个 64 位浮点型分值(score),使其具备有序性。这一设计让 ZSet 不仅支持集合的基础操作,还可高效完成与分值强相关的操作,是 Redis 针对 "有序且唯一" 存储场景优化的核心数据类型。
Redis ZSet 是 Set(元素唯一性) 与 Score(数值有序性) 的复合数据结构:Map<Member, Score>
Member(成员):字符串(基于 SDS 实现,二进制安全),全局唯一
Score(分值):64 位双精度浮点数(IEEE 754 Double)
特殊值:支持 -inf 和 +inf,常用于范围查询的边界。
排序规则(双重排序):
第一优先级:按 Score 从小到大 排序。
第二优先级:当 Score 相同时,按 Member 的字典序(Lexicographical Order) 从小到大排序。
这一规则是 ZSet 能够实现确定性排序以及支持 ZRANGEBYLEX(字典序范围查询)的理论基础。
无论访问两端还是中间元素,核心操作的时间复杂度均为 O (logN)(N 为元素总数),即使读取中间部分数据,性能也保持稳定高效;
范围查询(如 ZRANGEBYSCORE)时间复杂度为 O (logN + K)(K 为返回元素数)。
元素(member)全局唯一,重复添加相同 member 仅会覆盖其 score,不会新增元素,继承 Set 的唯一性特征。
核心特性:
唯一性与幂等性:Member 唯一,ZADD key score member 是幂等的,重复添加相同 Member 且 Score 不变时,集合状态不改变返回 0;
确定性排序:由于引入了 Score 相同按字典序的规则,ZSet 的排序结果是完全确定的;
原子性:单个 ZSet 命令是原子的;
浮点数精度陷阱:在进行范围查询(如 ZRANGEBYSCORE key 3.3 3.3)时可能查不到预期数据,业务层将分数乘以 100 或 1000 转为 Long (整数) 存储,可规避精度问题。
命令
增加元素
ZADD key score member score member ...
向有序集合中加入一个元素和该元素的分数,如果该元素已经存在则会用新的分数替换原有的分数。返回值是新加入到集合中的元素个数,不包含之前已经存在的元素。

获取元素的分数
ZSCORE key member

获得排名在某个范围的元素列表
ZRANGE key start stop WITHSCORES
按照元素分数从小到大的顺序返回索引从start到stop之间的所有元素(包含两端的元素)
ZREVRANGE key start stop WITHSCORES
按照元素分数从大到小的顺序返回索引从start到stop之间的所有元素(包含两端的元素)

如果需要获得元素的分数的可以在命令尾部加上WITHSCORES参数

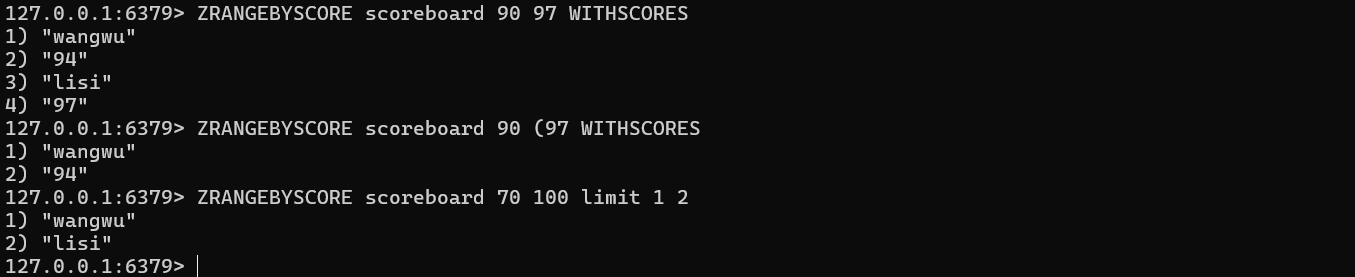
获得指定分数范围的元素
ZRANGEBYSCORE key min max WITHSCORES LIMIT offset count
需要注意的是 ( 表示开区间
增加某个元素的分数,返回值是更改后的分数
ZINCRBY key increment member
获得集合中元素的数量
ZCARD key
获得指定分数范围内的元素个数
ZCOUNT key min max

按照排名范围删除元素
ZREMRANGEBYRANK key start stop
按照分数范围删除元素
ZREMRANGEBYSCORE key min max

获取指定元素在有序集合中的升序排名
ZRANK key member
获取指定元素在有序集合中的降序排名
ZREVRANK key member
设置key的生存时间
Redis 在实际使用过程中更多的用作缓存,然而缓存的数据一般都是需要设置生存时间的,到期后数据销毁。
设置key的生存时间(单位:秒),即key在多少秒后会自动删除
EXPIRE key seconds
查看key生于的生存时间(-1:key 存在且永久有效,-2:key 不存在)
TTL key
清除生存时间
PERSIST key
生存时间设置单位为:毫秒
PEXPIRE key milliseconds

返回满足给定 pattern 的所有key
keys

确认一个 key 是否存在
exists

删除一个 key
del

重命名 key
rename

返回值的类型
type

应用
java
@Test
public void sortedSet() {
String hackersKey = "hackers";
String zsetKey = "zset";
// 第一部分:hackers集合操作
// 添加ZSet元素
redisTemplate.opsForZSet().add(hackersKey, "Alan Kay", 1940);
redisTemplate.opsForZSet().add(hackersKey, "Richard Stallman", 1953);
redisTemplate.opsForZSet().add(hackersKey, "Yukihiro Matsumoto", 1965);
redisTemplate.opsForZSet().add(hackersKey, "Claude Shannon", 1916);
redisTemplate.opsForZSet().add(hackersKey, "Linus Torvalds", 1969);
redisTemplate.opsForZSet().add(hackersKey, "Alan Turing", 1912);
// 按score升序获取所有元素
Set<Object> setValues = redisTemplate.opsForZSet().range(hackersKey, 0, -1);
System.out.println("按score升序的hackers:" + setValues);
// 按score降序获取所有元素
Set<Object> setValues2 = redisTemplate.opsForZSet().reverseRange(hackersKey, 0, -1);
System.out.println("按score降序的hackers:" + setValues2);
// 第二部分:zset集合操作
// 清空当前数据库
redisTemplate.getConnectionFactory().getConnection().flushDb();
System.out.println("清空当前Redis数据库成功");
// 添加zset元素
redisTemplate.opsForZSet().add(zsetKey, "hello", 10.1);
redisTemplate.opsForZSet().add(zsetKey, ":", 10.0);
redisTemplate.opsForZSet().add(zsetKey, "zset", 9.0);
redisTemplate.opsForZSet().add(zsetKey, "zset!", 11.0);
// 获取ZSet元素个数
Long zcard = redisTemplate.opsForZSet().size(zsetKey);
System.out.println("zset元素个数:" + zcard);
// 获取指定元素的score
Double zscore = redisTemplate.opsForZSet().score(zsetKey, "zset");
System.out.println("zset元素'zset'的score:" + zscore);
// 获取ZSet所有元素
Set<Object> zrange = redisTemplate.opsForZSet().range(zsetKey, 0, -1);
System.out.println("zset所有元素(升序):" + zrange);
// 删除指定元素
Long zrem = redisTemplate.opsForZSet().remove(zsetKey, "zset!");
System.out.println("删除zset!的结果(1=成功,0=失败):" + zrem);
// 统计score在[9.5, 10.5]范围内的元素个数
Long zcount = redisTemplate.opsForZSet().count(zsetKey, 9.5, 10.5);
System.out.println("score在9.5-10.5之间的元素个数:" + zcount);
// 获取删除后的zset所有元素
Set<Object> finalZrange = redisTemplate.opsForZSet().range(zsetKey, 0, -1);
System.out.println("删除zset!后zset的所有元素:" + finalZrange);
}
java
@Test
public void test() throws InterruptedException {
Set<String> allKeys = StringRedisTemplate.keys("*");
System.out.println(allKeys);
// 通配符查询包含name的key
Set<String> nameKeys = StringRedisTemplate.keys("*name");
System.out.println(nameKeys);
// 删除指定key
Boolean delSuccess = StringRedisTemplate.delete("sanmdde");
System.out.println(delSuccess ? 1 : 0);
// 获取key的过期时间
Long ttl = StringRedisTemplate.getExpire("sname");
System.out.println(ttl);
// 设置key+过期时间
StringRedisTemplate.opsForValue().set("timekey", "min", 10, TimeUnit.SECONDS);
// 睡眠5秒
Thread.sleep(5000);
// 再次查询过期时间
Long ttlAfterSleep = StringRedisTemplate.getExpire("timekey");
System.out.println(ttlAfterSleep);
// 重新设置过期时间
StringRedisTemplate.opsForValue().set("timekey", "min", 8, TimeUnit.SECONDS);
Long ttlAfterReset = StringRedisTemplate.getExpire("timekey");
System.out.println(ttlAfterReset);
// 检查key是否存在
Boolean exists = StringRedisTemplate.hasKey("key");
System.out.println(exists);
// 重命名key
String renameResult = "OK";
if (StringRedisTemplate.hasKey("timekey")) {
StringRedisTemplate.rename("timekey", "time");
} else {
renameResult = "ERR no such key";
}
System.out.println(renameResult);
// 获取原key的值
String oldKeyVal = StringRedisTemplate.opsForValue().get("timekey");
System.out.println(oldKeyVal);
// 获取新key的值
String newKeyVal = StringRedisTemplate.opsForValue().get("time");
System.out.println(newKeyVal);
// List操作
// 清空list "a"
StringRedisTemplate.delete("a");
// 右推元素
StringRedisTemplate.opsForList().rightPush("a", "1");
// 左推元素
StringRedisTemplate.opsForList().leftPush("a", "6");
StringRedisTemplate.opsForList().leftPush("a", "3");
StringRedisTemplate.opsForList().leftPush("a", "9");
// 获取list所有元素
List<String> listAll = StringRedisTemplate.opsForList().range("a", 0, -1);
System.out.println(listAll);
}