前期准备
可以去huggingface或hf-mirror镜像站等下载Qwen3.5的模型,比如https://huggingface.co/Qwen/Qwen3.5-0.8B/tree/main 或https://hf-mirror.com/Qwen/Qwen3.5-0.8B/tree/main下载模型相关文件,保存到合适路径,比如/Users/Zhuanz/Desktop/work/Qwen3.5/model
在终端进入Llama-Factory项目(如果之前没克隆过这个项目,则直接git clone https://github.com/hiyouga/LLaMAFactory,无需git pull)
先git pull更新,如果文件冲突,可以改名备份,或者执行git checkout -- 你的文件路径(比如git checkout -- data/dataset_info.json)丢冲突文件后再执行git pull更新
source .venv/bin/activate激活已有的虚拟环境(没有则需要创建虚拟环境)
llamafactory-cli webui启动加载模型报错
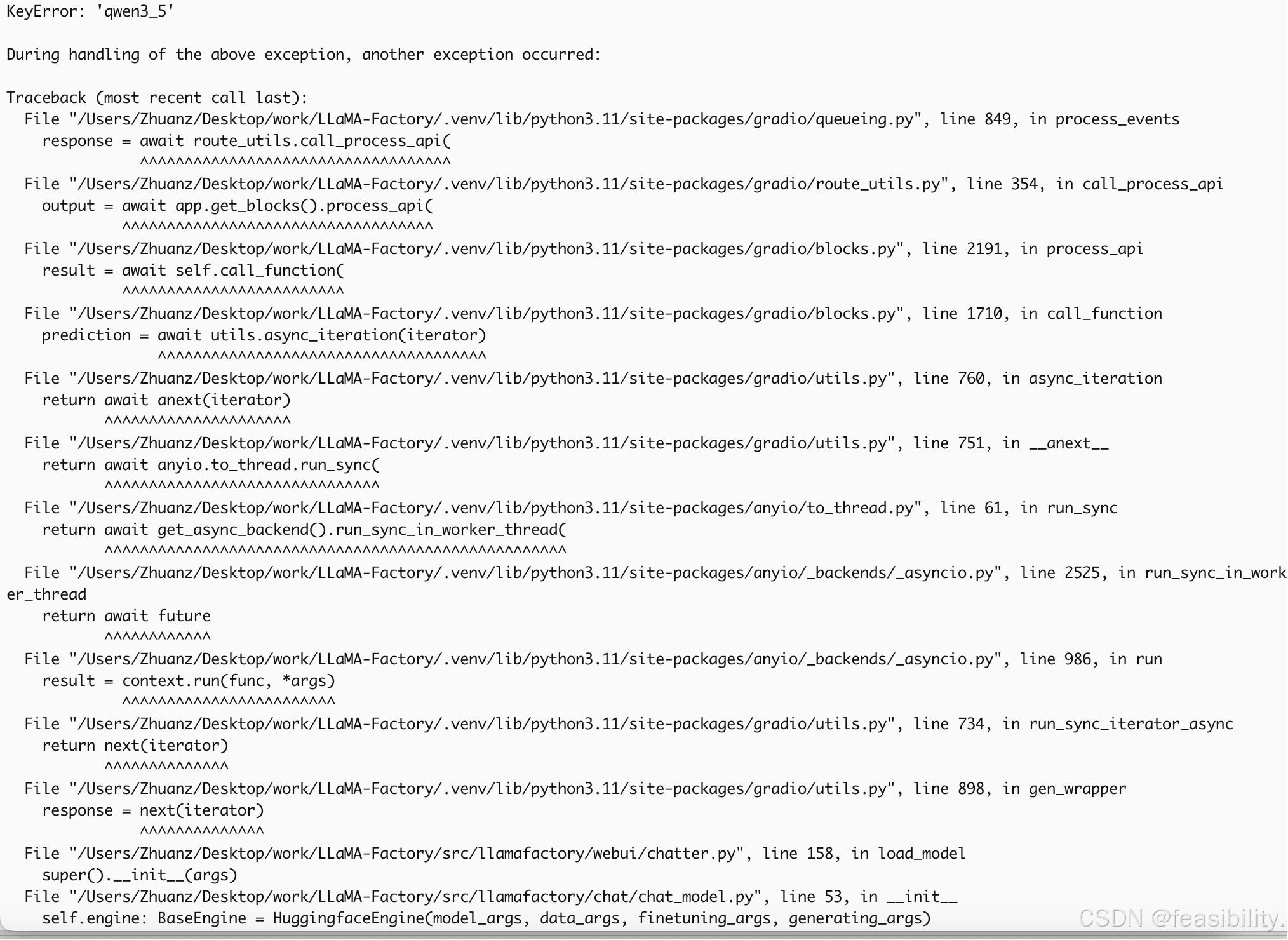
根据提示uv pip install --upgrade transformers(加uv是因为我用了uv创建python虚拟环境,不是用uv则不需要加)
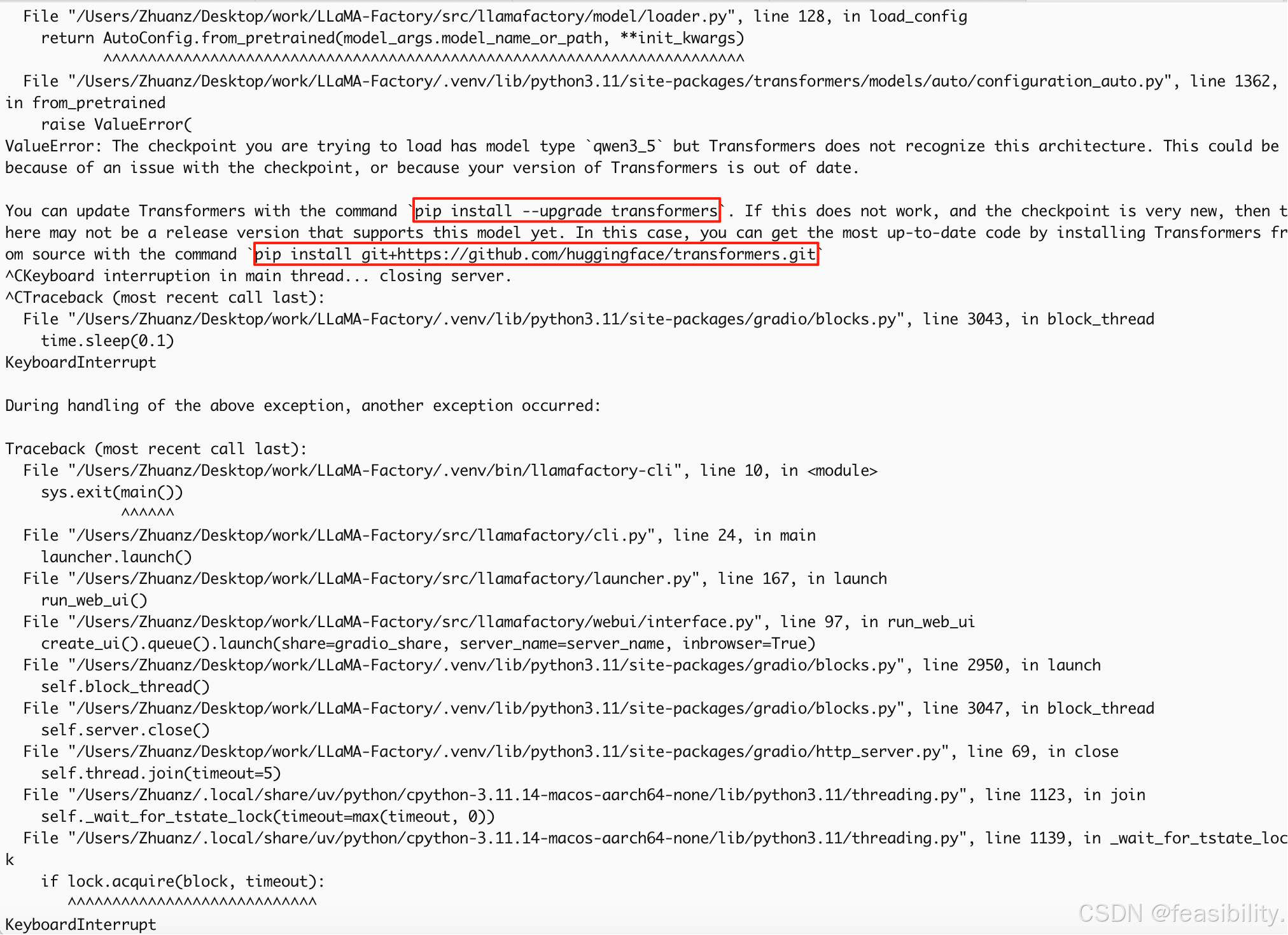
再次启动,又报错,原因是目前仅支持transformers版本范围是4.55.0~5.6.0
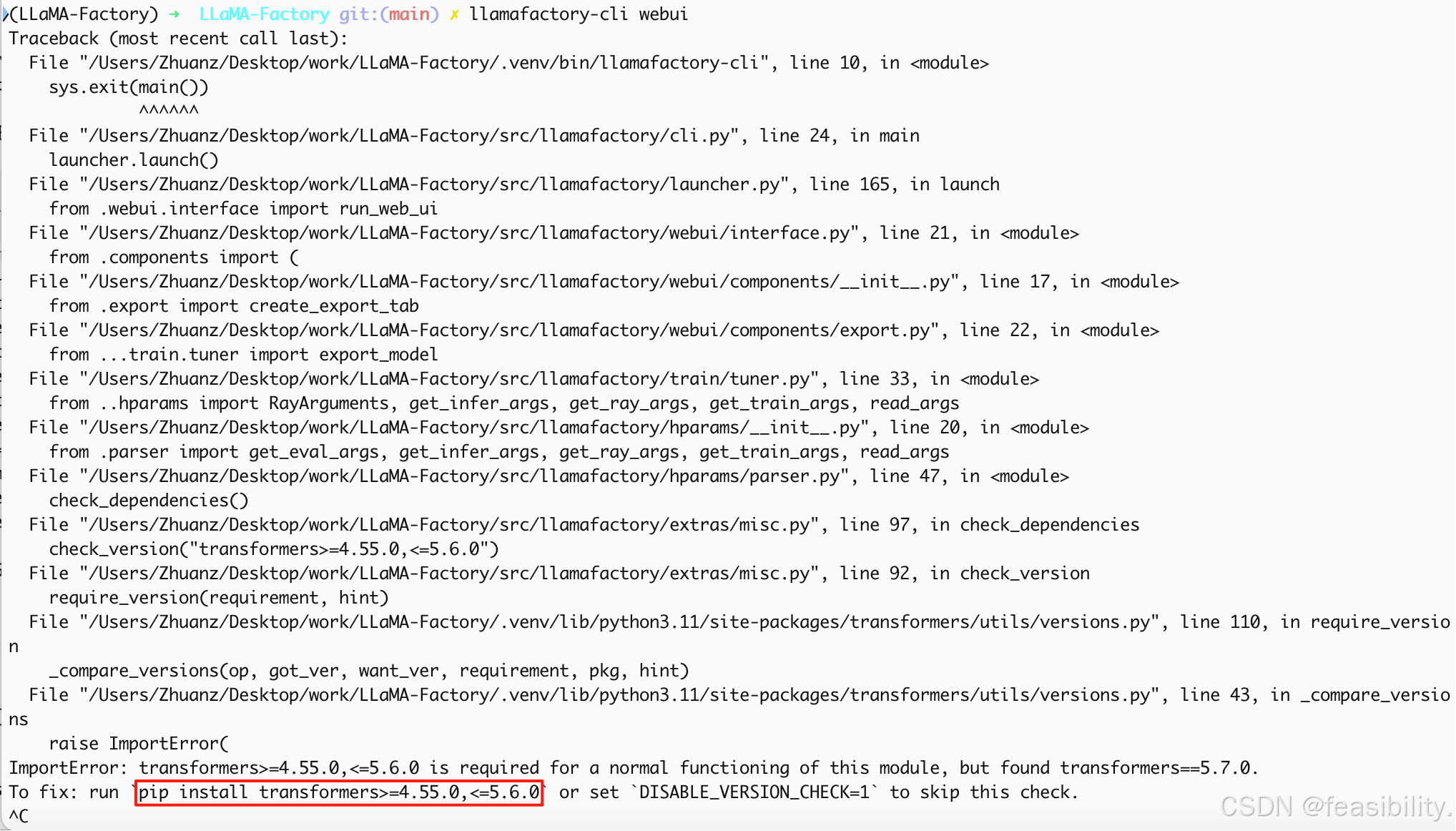
执行uv pip install transformers==5.6.0,再次启动
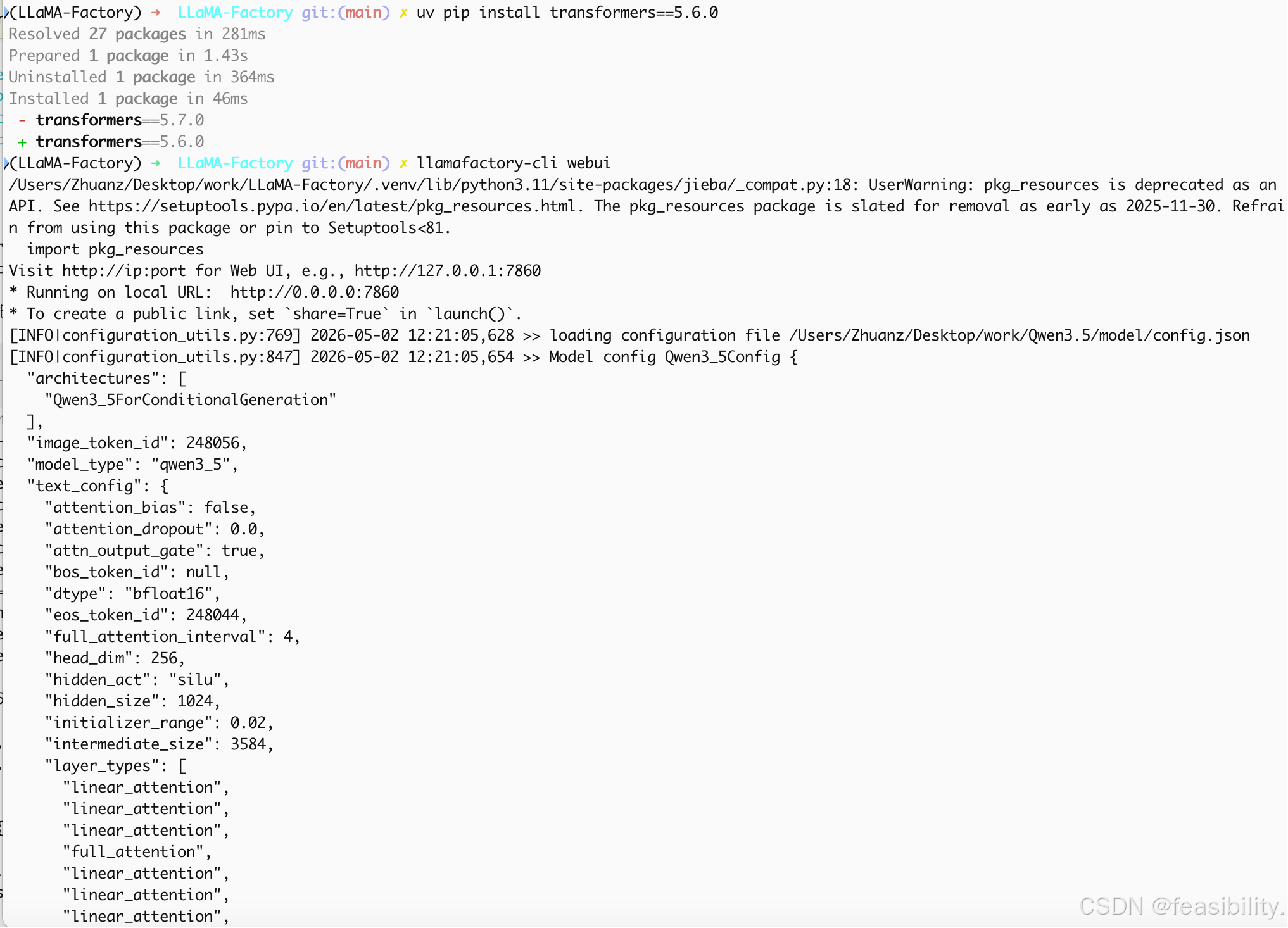
出现报错,torch2.9不支持3d卷积,可能是torch和torchvision的冲突
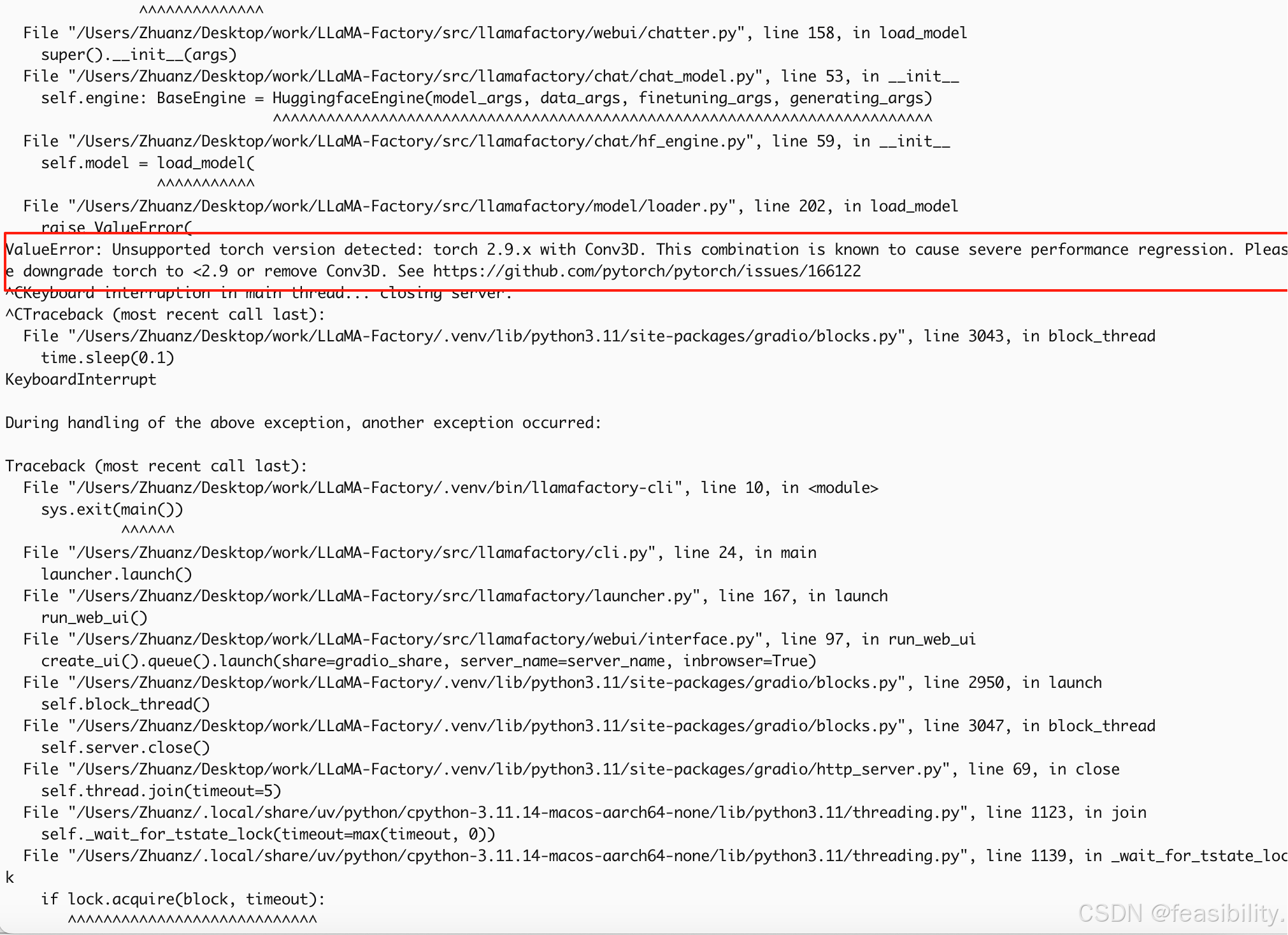
执行uv pip uninstall torch torchvision torchaudio卸载,再执行uv pip install torch torchvision torchaudio


Llama-Factory运行效果
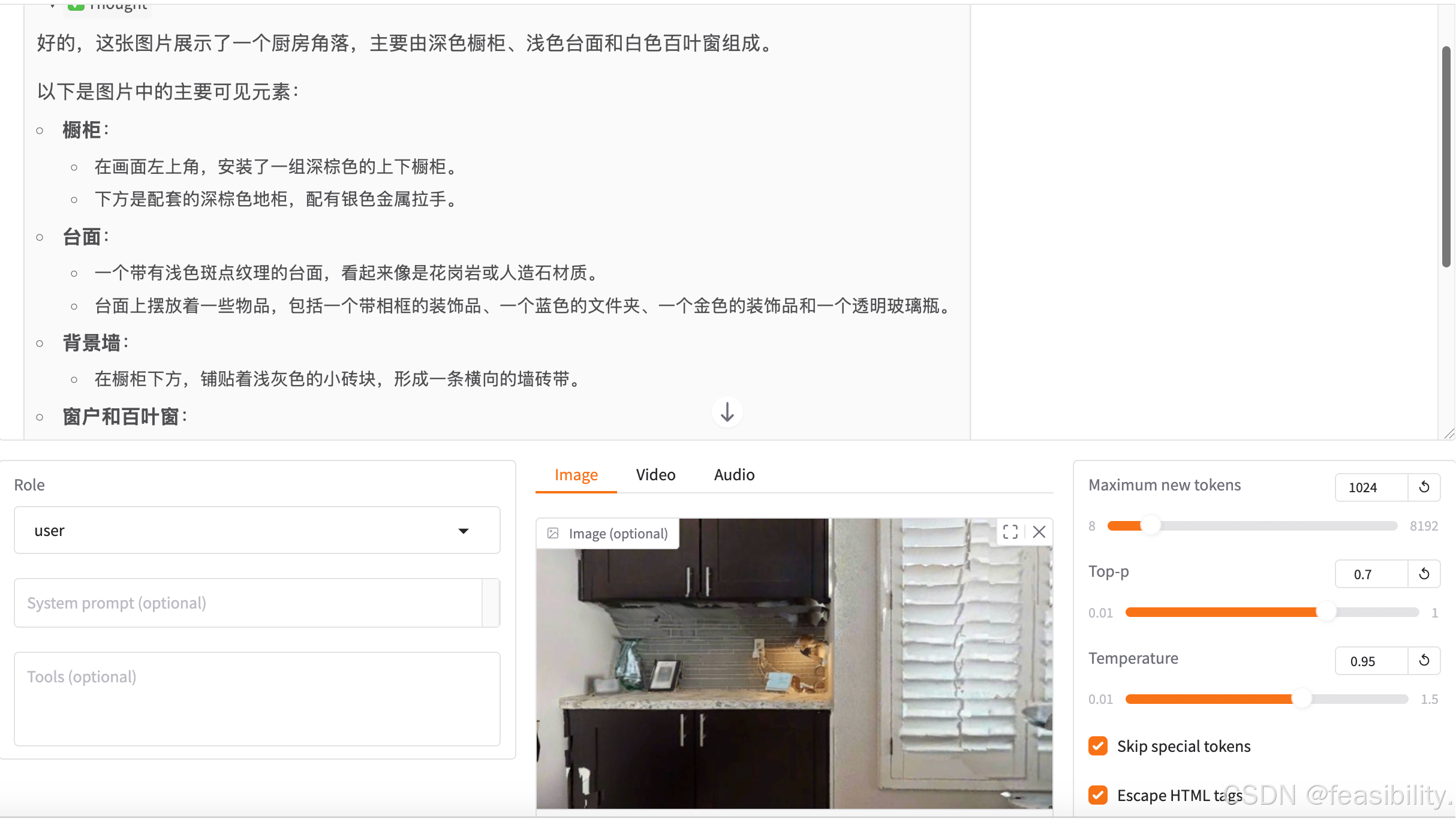
运行了lamafactory-cli webui运行,Model name设置为你下载的Qwen3.5的相关模型,比如Qwen3.5-0.8B-Base,model path填你的模型路径,点击chat进行测试模型的运行效果
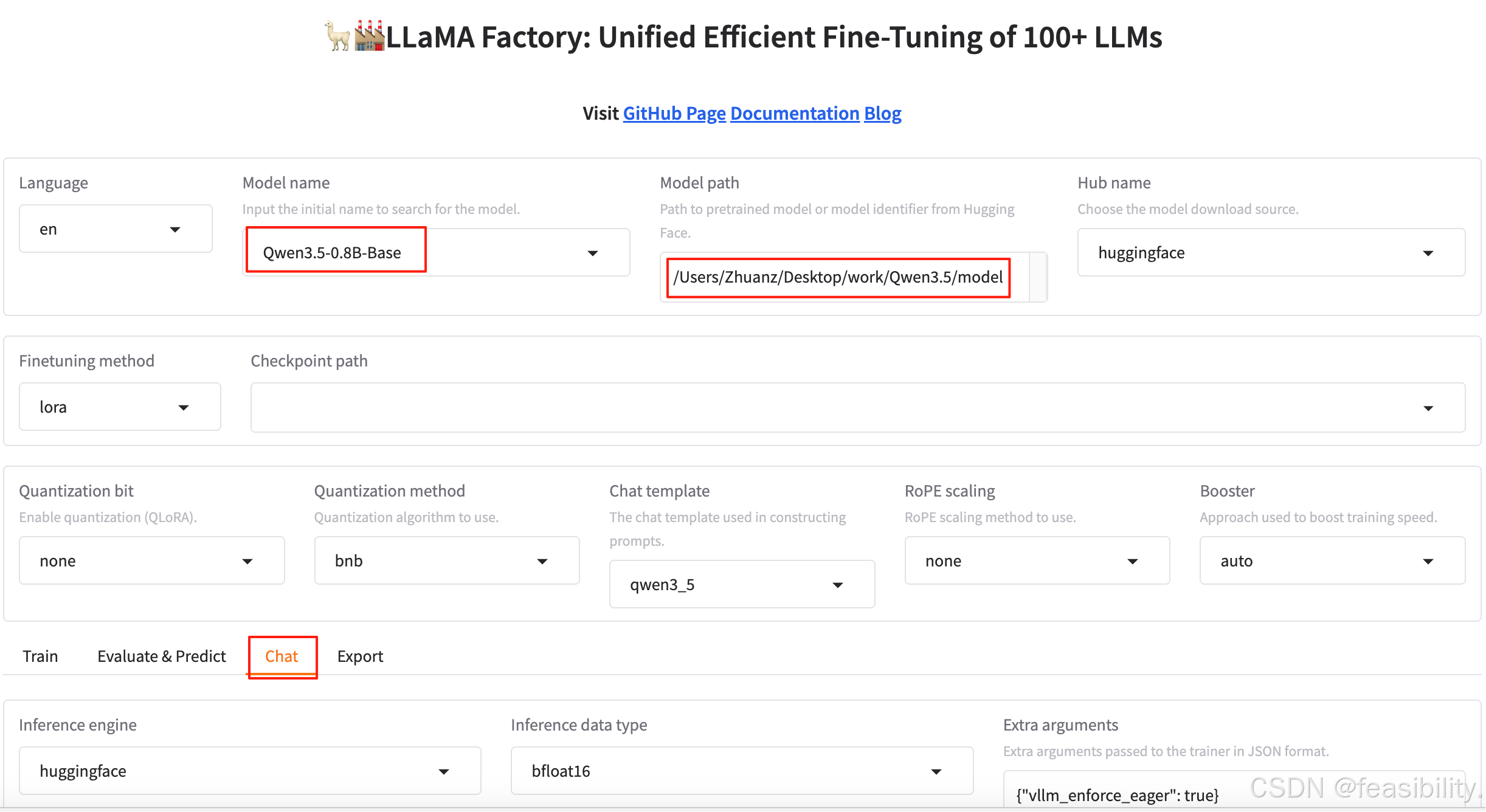
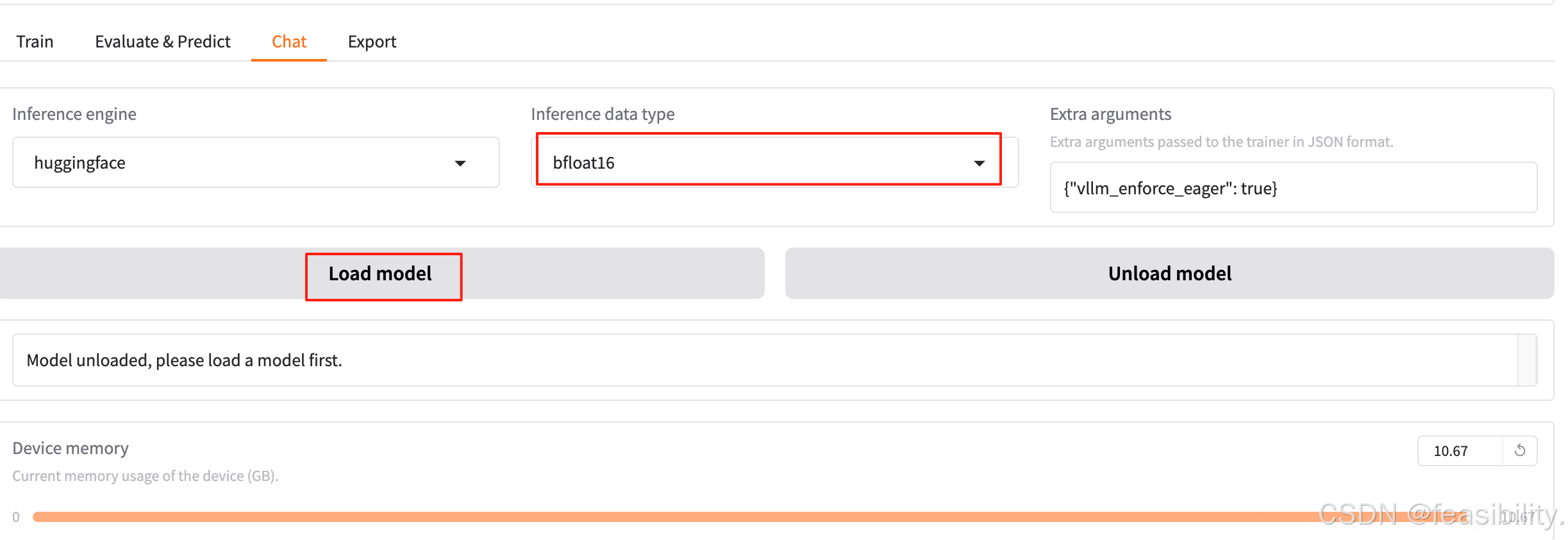
建议设置推理类型为bfloat16或float16,点击Load model加载模型
点击图像,输入提示词,再点击submit提交
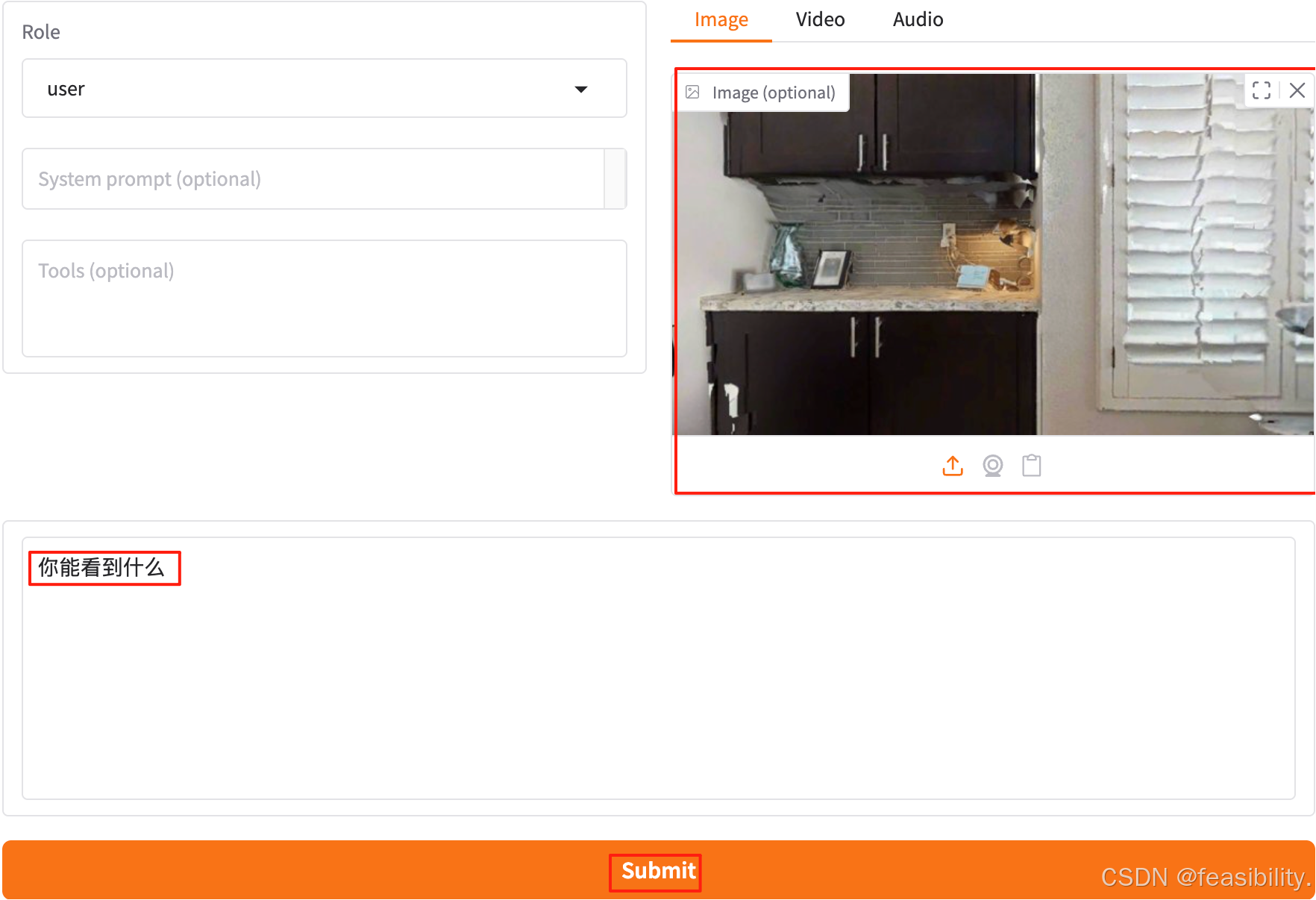
可以看出模型能够基本根据图像准确回答问题
量化导出
作用
量化是将模型权重从高精度(如FP16)压缩到低精度(如4-bit)的技术,核心作用是大幅减少内存和磁盘占用------例如7B模型从14GB降到4GB左右,让消费级设备也能运行大模型。
推理速度则因硬件而异:CPU上通常显著加速,因为瓶颈是内存带宽,读取更少数据直接提升吞吐量;GPU上则可能因反量化开销而变慢或仅微幅提升,高端显卡尤其如此。因此量化是"用精度换空间"的权衡,适合内存紧张的场景,但追求极致速度时未必最优。
下面仅做示范,如果只看量化导出成功可以跳到llama.cpp。
llama-factory
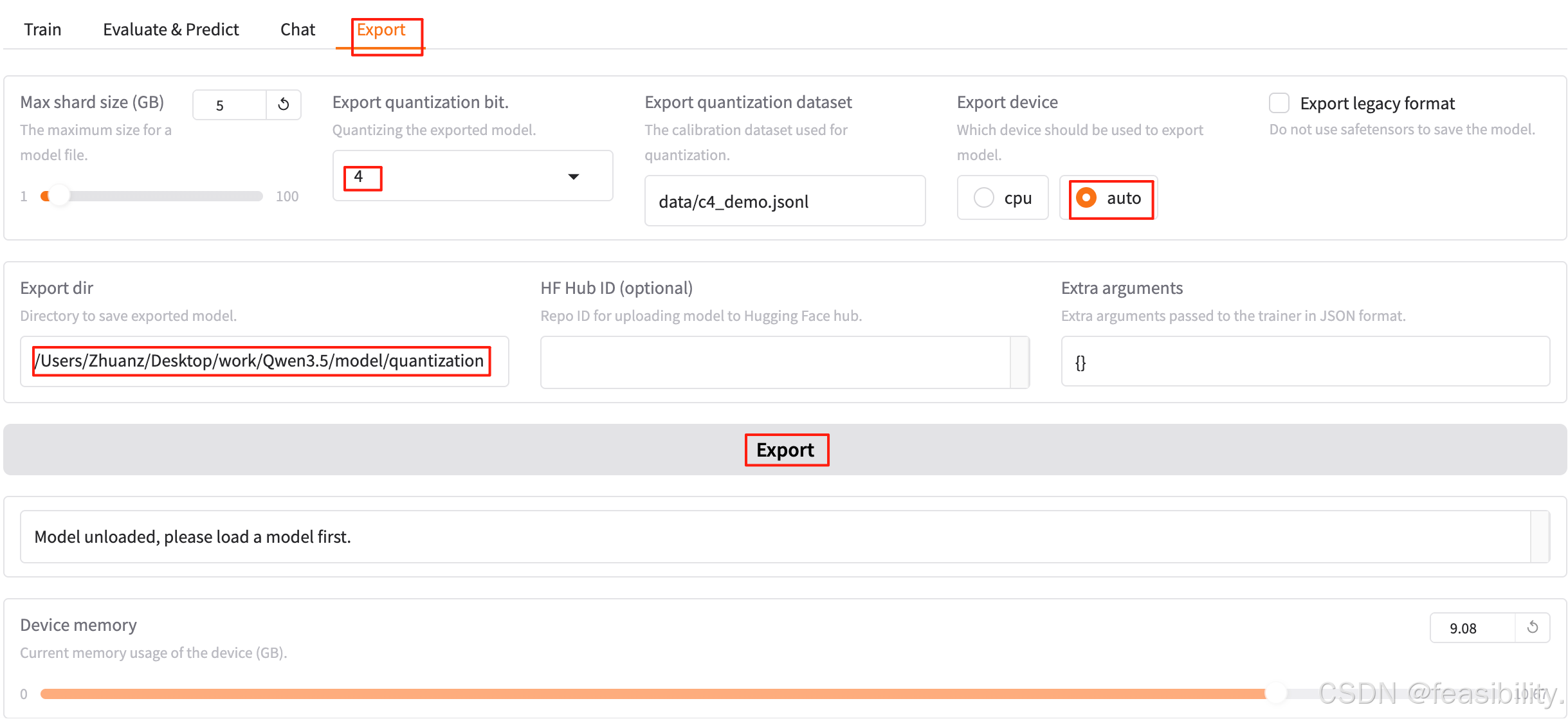
点击Export,设置量化精度,比如4bit,导出设备可选auto自动选择,Export dir填写导出模型的路径,量化数据集建议不修改,点击Export导出
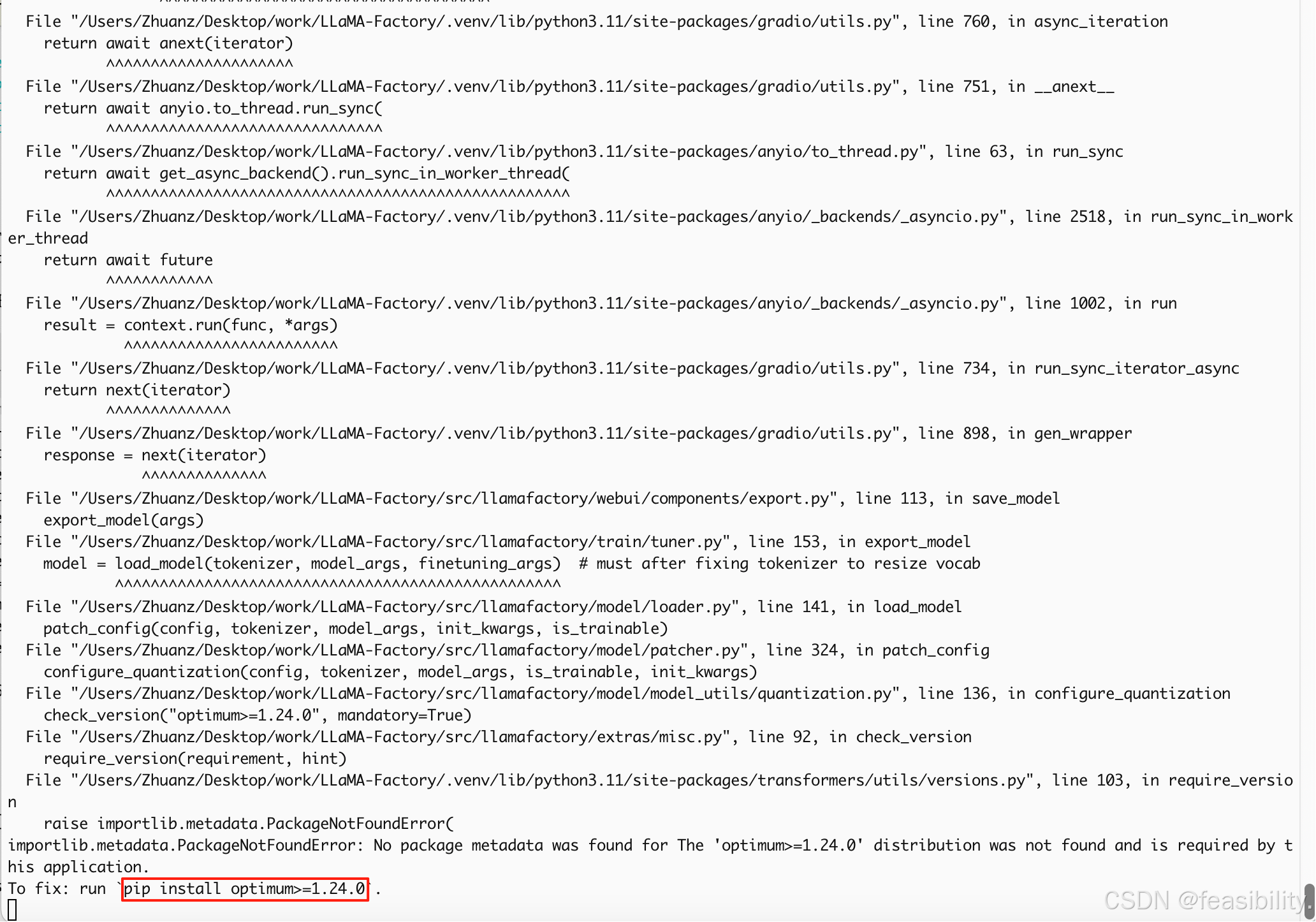
出现报错,是项目要求optimum库必须1.24.0及以上,可以先中断退出,执行uv pip install 'optimum>=1.24.0'

安装后再次导出,出现报错,是项目要求gptqmodel>库必须2.0.0及以上

中断后执行uv pip install 'gptqmodel>=2.0.0'
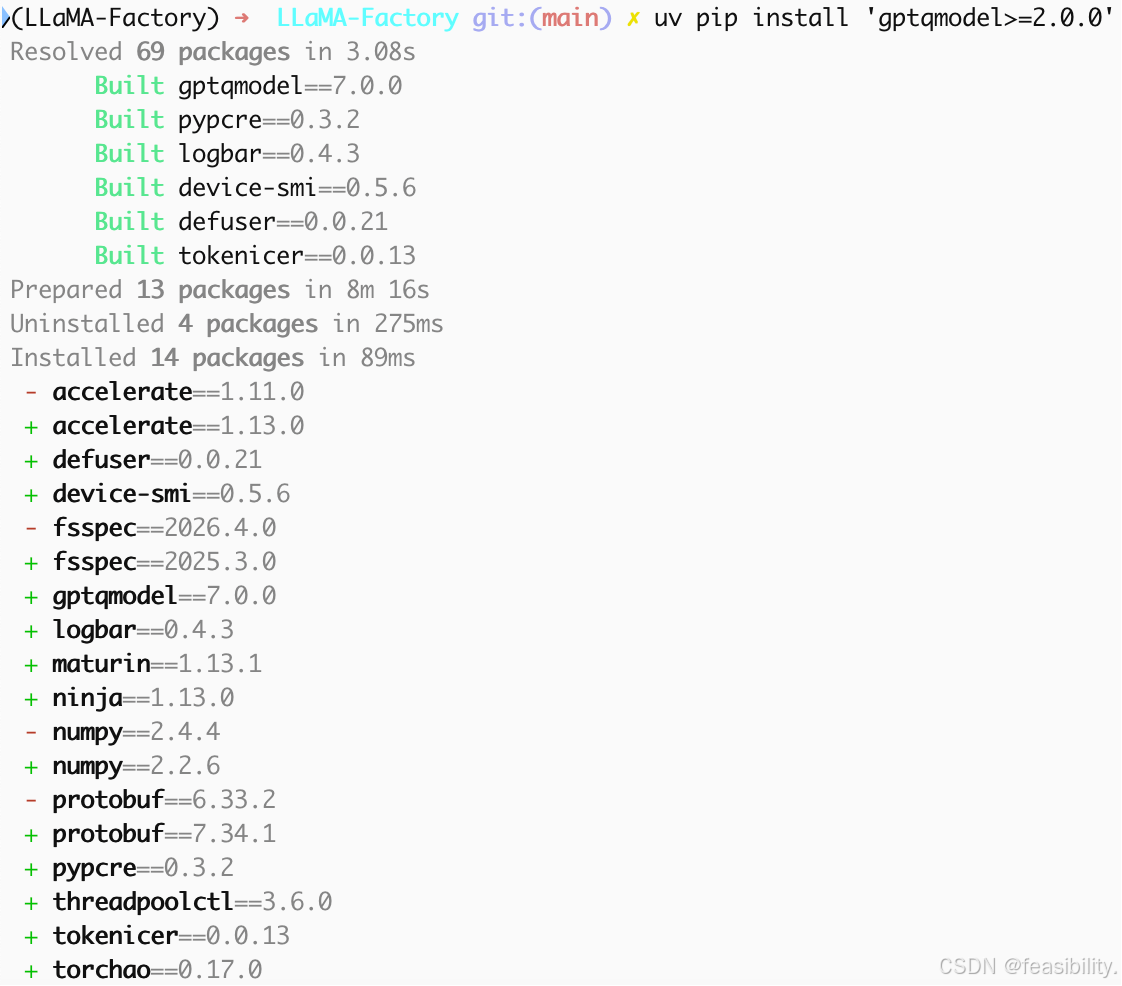
再次启动并导出
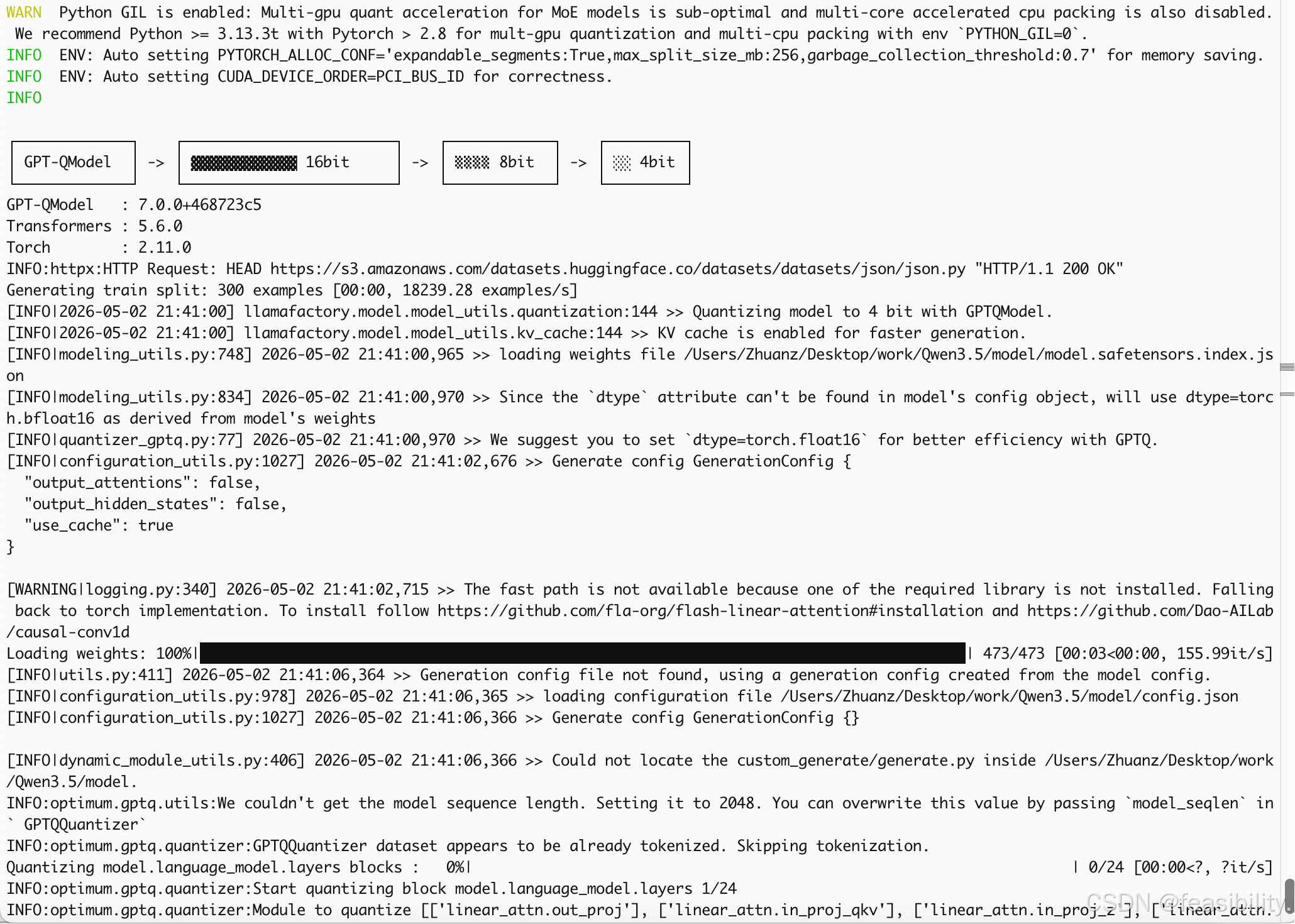
这里由于内存不足最终没有量化成功,待后续内存足够再处理
llama.cpp
执行git clone https://github.com/loong64/llama.cpp克隆项目再执行cd llama.cpp进入项目,如果之前克隆过可以终端进入llama.cpp项目直接执行git pull更新
执行source .venv/bin/activate激活uv虚拟环境(没有的话需要先创建和下载库)
执行uv pip install transformers==5.5 -i https://mirrors.aliyun.com/pypi/simple更新transformers库
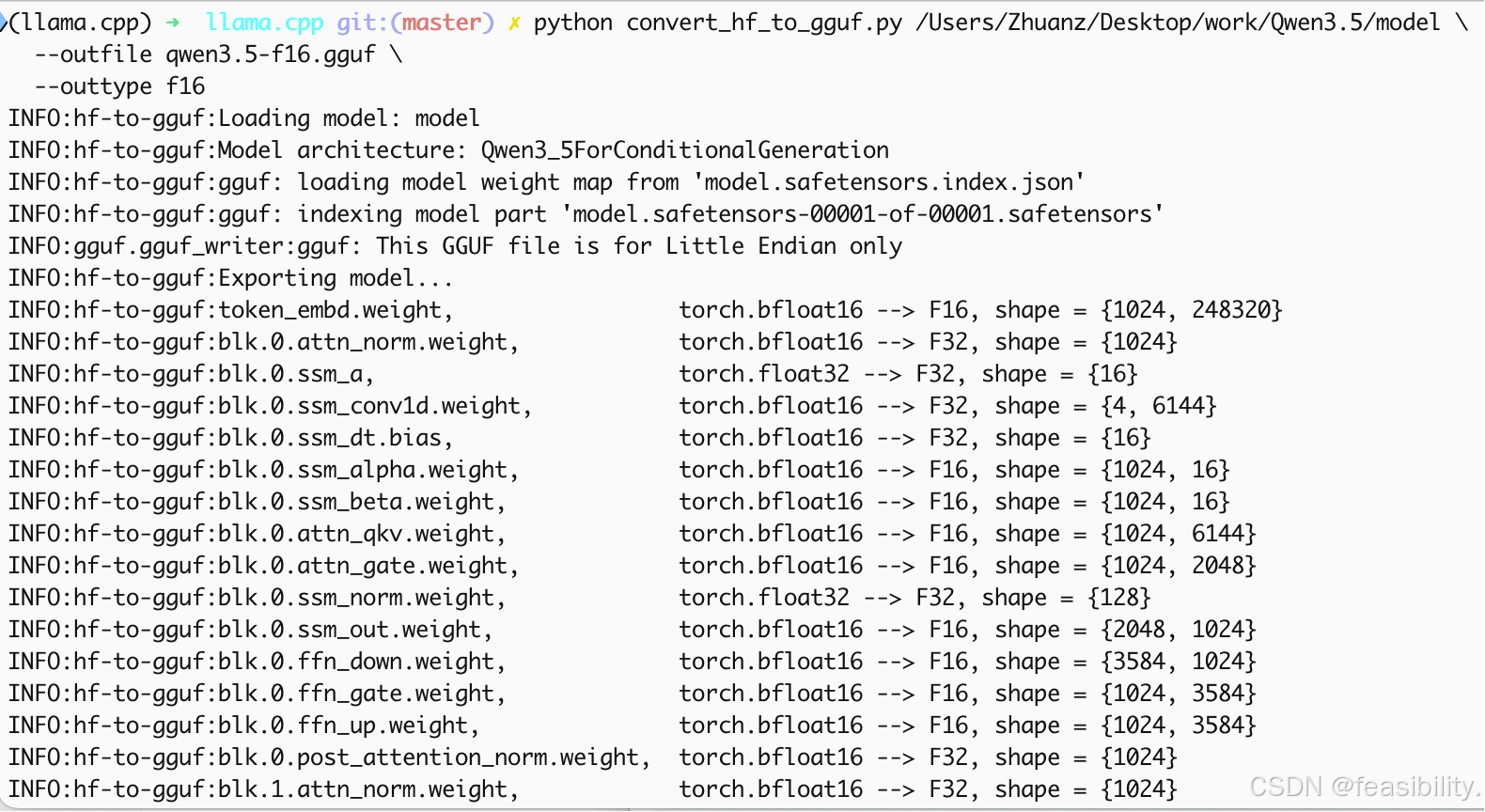
执行python convert_hf_to_gguf.py qwen3.5模型的路径 \
--outfile qwen3.5-f16.gguf \
--outtype f16 把Qwen3.5模型的语言部分转换为精度float16,qwen3.5模型的路径以实际为准,比如/Users/Zhuanz/Desktop/work/Qwen3.5/model,得到qwen3.5-f16.gguf
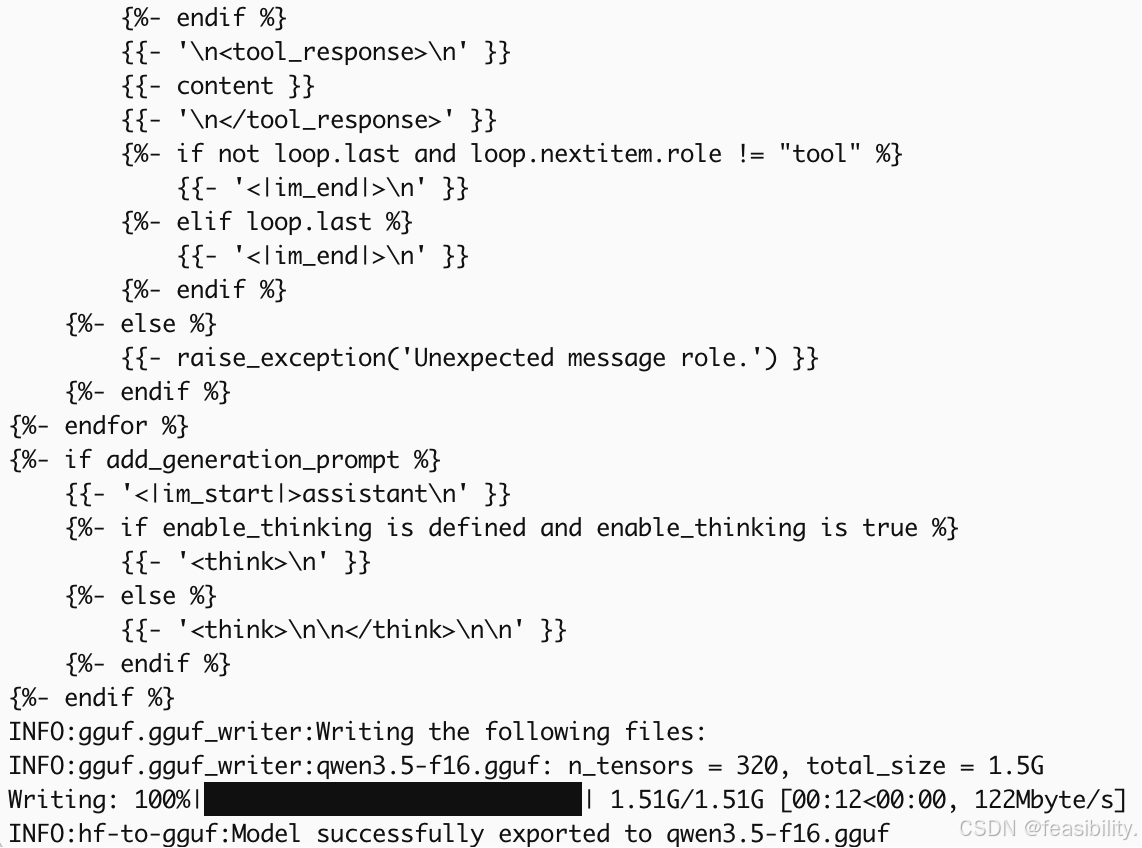
执行python convert_hf_to_gguf.py 你的qwen3.5模型的路径 \
--mmproj \
--outfile mmproj-qwen3.5-f16.gguf \
--outtype f16 把Qwen3.5模型的视觉投影器转换为精度float16,qwen3.5模型的路径以实际为准,比如/Users/Zhuanz/Desktop/work/Qwen3.5/model,得到mmproj-qwen3.5-f16.gguf
编译命令在各平台有差异:
| 平台 | 编译命令 |
|---|---|
| macOS (Apple Silicon) | cmake -B build -DLLAMA_METAL=ON cmake --build build --config Release -j $(sysctl -n hw.ncpu) |
| macOS (Intel) | cmake -B build(不用 METAL) cmake --build build --config Release -j $(sysctl -n hw.ncpu) |
| Linux (NVIDIA GPU) | cmake -B build -DLLAMA_CUDA=ON cmake --build build --config Release -j $(nproc) |
| Linux (CPU only) | cmake -B build cmake --build build --config Release -j $(nproc) |
| Windows (NVIDIA GPU) | cmake -B build -DLLAMA_CUDA=ON cmake --build build --config Release -j %NUMBER_OF_PROCESSORS% |
| Windows (CPU only) | cmake -B build cmake --build build --config Release -j %NUMBER_OF_PROCESSORS% |
关键区别:
-
-DLLAMA_METAL=ON仅 macOS Apple Silicon 有效(Metal 是苹果专属 GPU 框架) -
Linux/Windows NVIDIA 显卡用
-DLLAMA_CUDA=ON -
CPU only 不需要加任何加速选项
-
并行编译线程数:
$(sysctl -n hw.ncpu)是 macOS 命令,Linux 用$(nproc),Windows 用%NUMBER_OF_PROCESSORS%
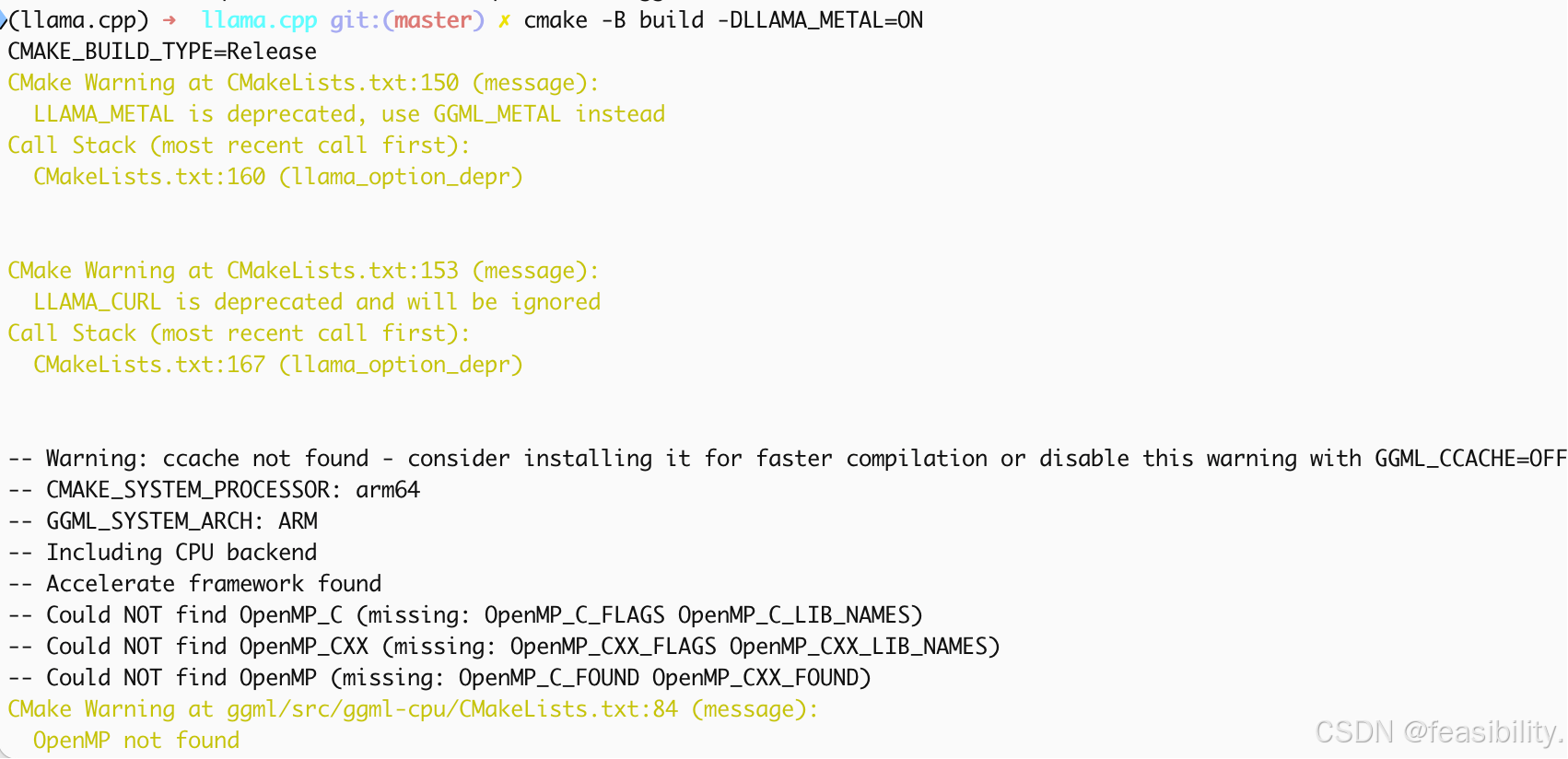
构建build目录文件(之前有也要重新构建),这里是Mac(apple)先执行cmake -B build -DLLAMA_METAL=ON
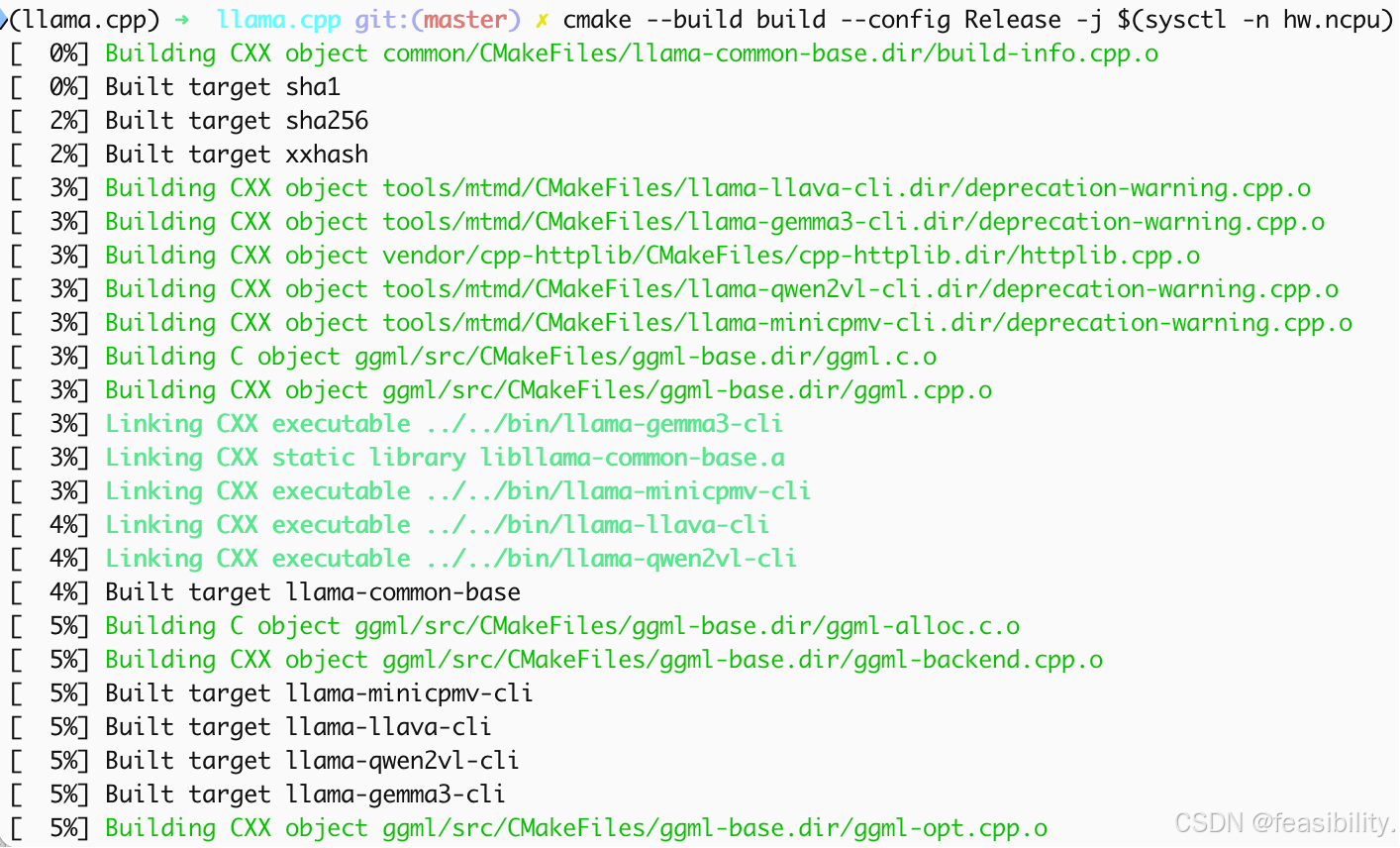
执行cmake --build build --config Release -j $(sysctl -n hw.ncpu)进行编译
执行./build/bin/llama-quantize qwen3.5-f16.gguf qwen3.5-Q4_K_M.gguf 量化类型
常用量化类型:Q4_K_M、Q5_K_S、Q8_0、IQ3_S(int3)
这里以Q4_K_M为例
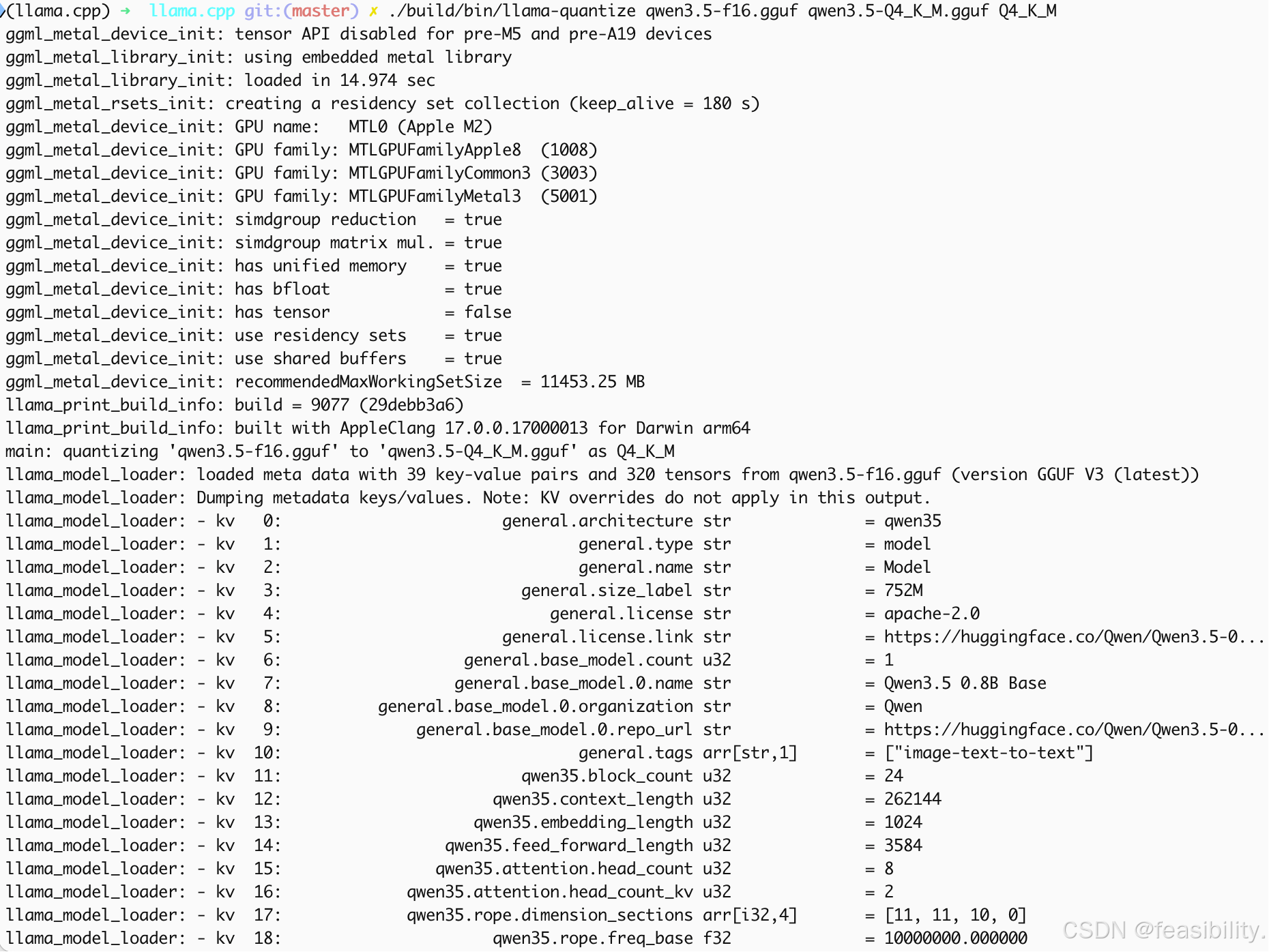
14s多完成量化,得到约529MB的量化模型

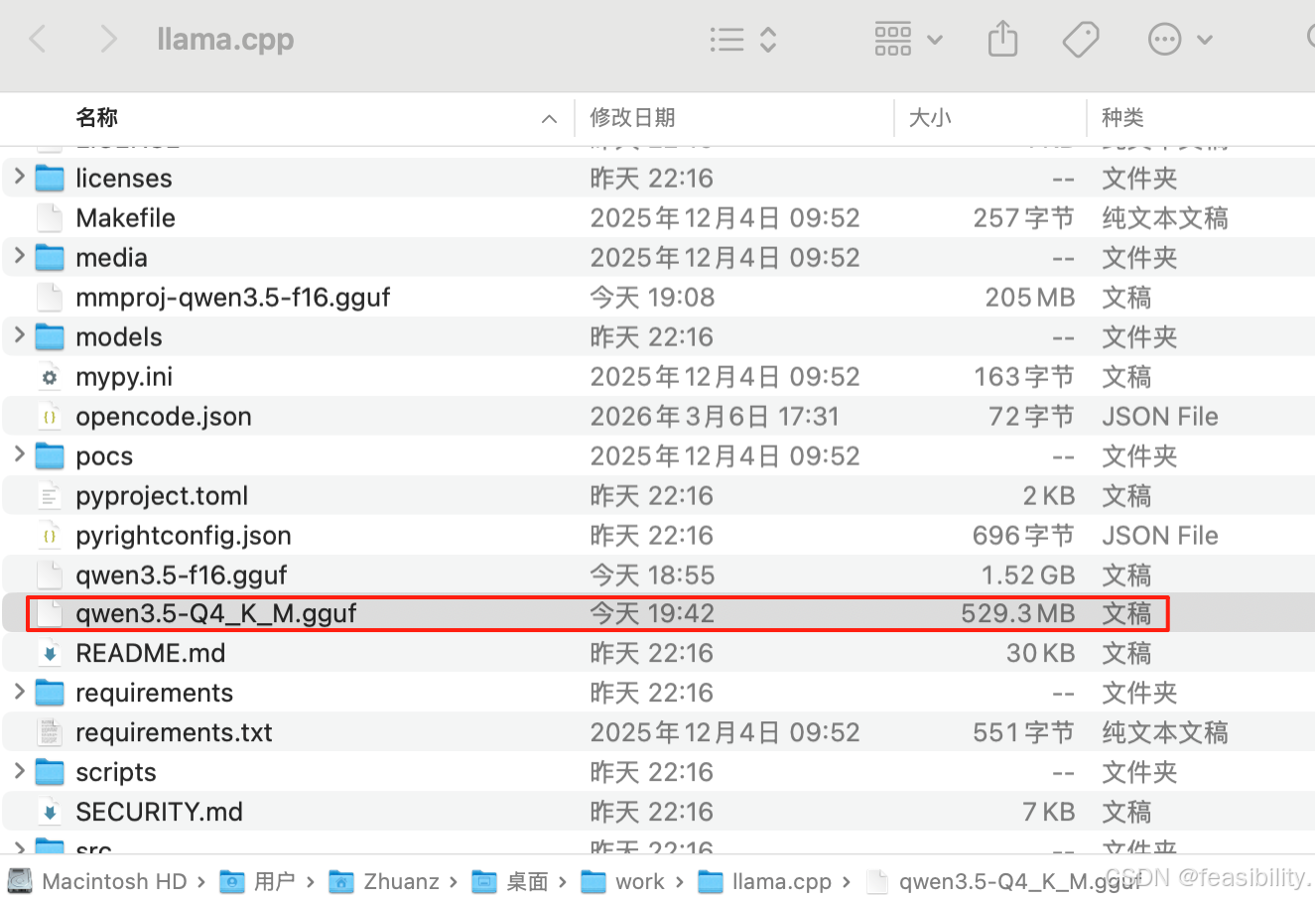
mmproj 文件很小(通常几十MB),这里实际得到的是205MB,量化收益有限,但也可以量化:
./build/bin/llama-quantize \
mmproj-model-f16.gguf \
mmproj-model-Q4_K_M.gguf \
Q4_K_M
不过官方通常建议保持 fp16 以保证图像理解质量。
./build/bin/llama-cli \
-m /Users/Zhuanz/Desktop/work/Qwen3.5/model/gguf/model-Q4_K_M.gguf \
--mmproj /Users/Zhuanz/Desktop/work/Qwen3.5/model/gguf/mmproj-model-f16.gguf \
--add vision-image \
-p "describe this image"
执行./build/bin/llama-mtmd-cli \
-m qwen3.5-Q4_K_M.gguf \
--mmproj mmproj-qwen3.5-f16.gguf \
--image /Users/Zhuanz/Desktop/img/people.jpg \
-p "描述这张图片" \
-ngl 99 \
--jinja 测试量化的模型回复效果,image是图片路径,p是用户提示词
llama_perf_context_print: load time = 1524.99 ms
llama_perf_context_print: prompt eval time = 2089.67 ms / 965 tokens ( 2.17 ms per token, 461.80 tokens per second)
llama_perf_context_print: eval time = 43273.08 ms / 1013 runs ( 42.72 ms per token, 23.41 tokens per second)
llama_perf_context_print: total time = 46160.44 ms / 1978 tokens
llama_perf_context_print: graphs reused = 1008
ngl设置99的作用是把 99 层模型权重 offload 到 GPU(即Mac的mps) , 推理速度快,但GPU 内存占用高,不加则默认CPU推理;加jinja是因为chat template 是 jinja 格式,不加会报错error: invalid argument:
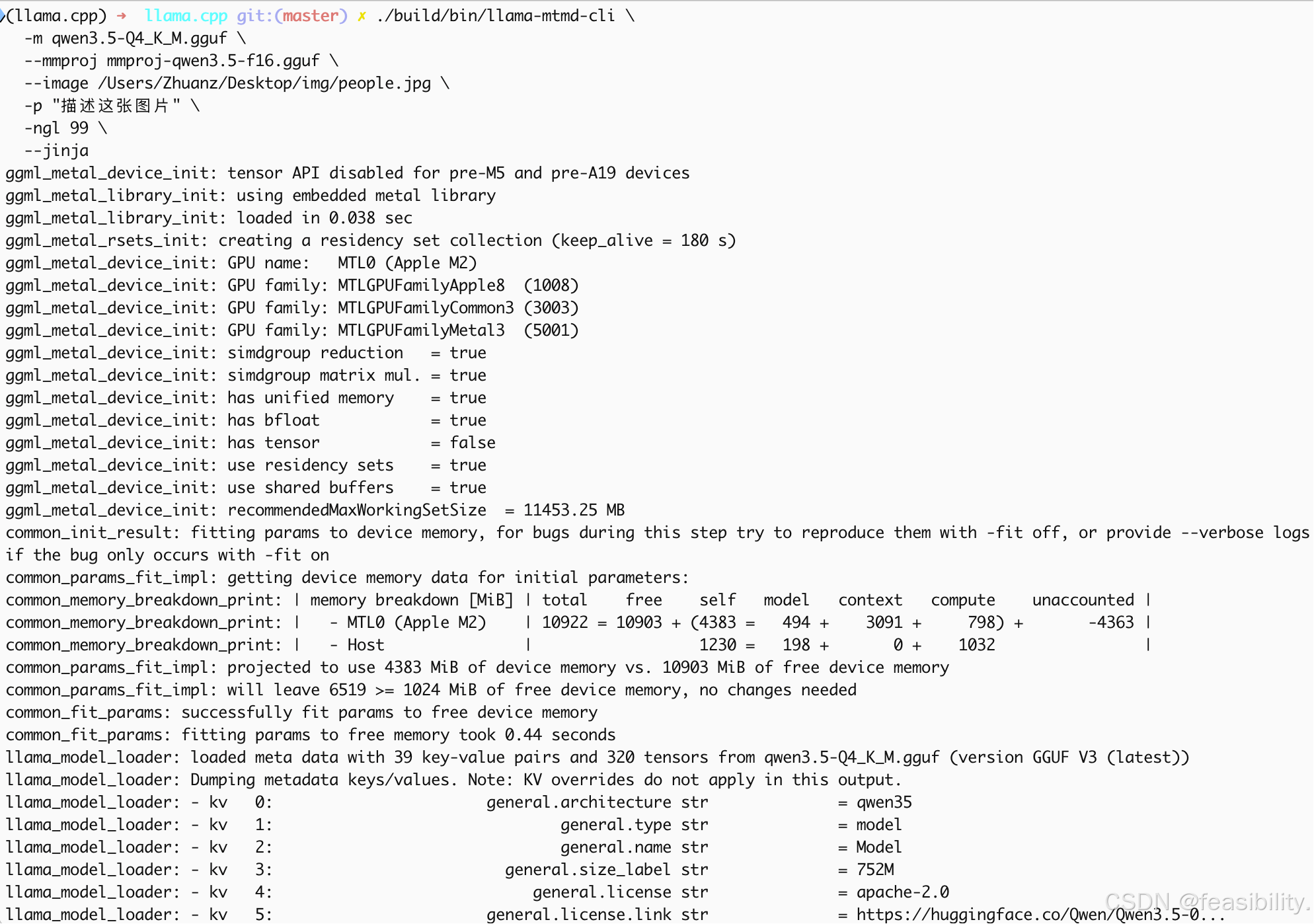
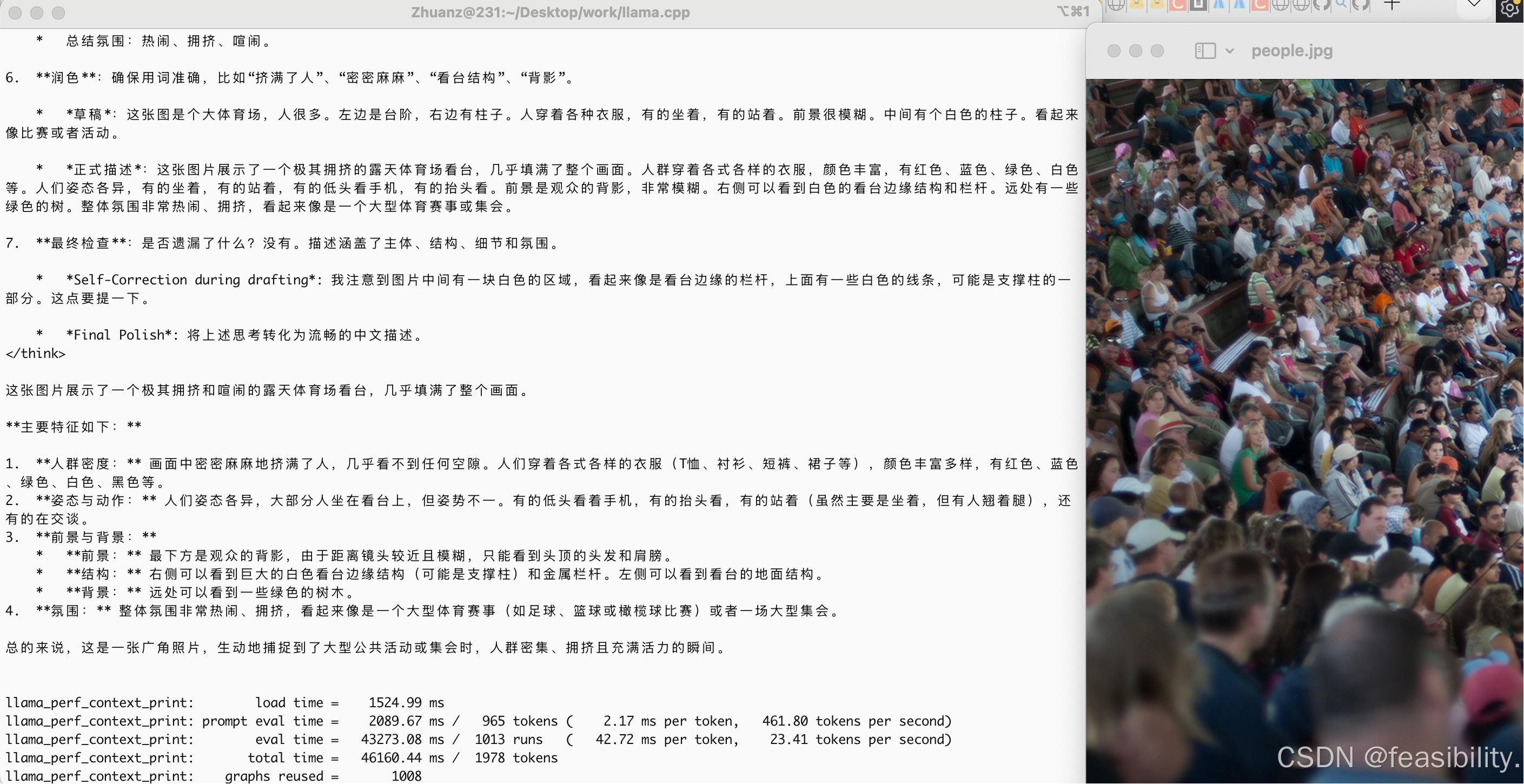
可以发现模型基本回答正确,能注意到不少细节,比如有树木、站立的人和不同衣服的人

也可以执行./build/bin/llama-cli \
-m qwen3.5-Q4_K_M.gguf \
--mmproj mmproj-qwen3.5-f16.gguf \
--image /Users/Zhuanz/Desktop/img/people.jpg \
-p "描述这张图片" \
-ngl 99 \
--jinja 可以多轮对话,深入/exit或按ctrl+c退出
同样回答基本正确,且显示了更可读的信息
Prompt: 324.8 t/s | Generation: 24.6 t/s


部署推理服务
部署
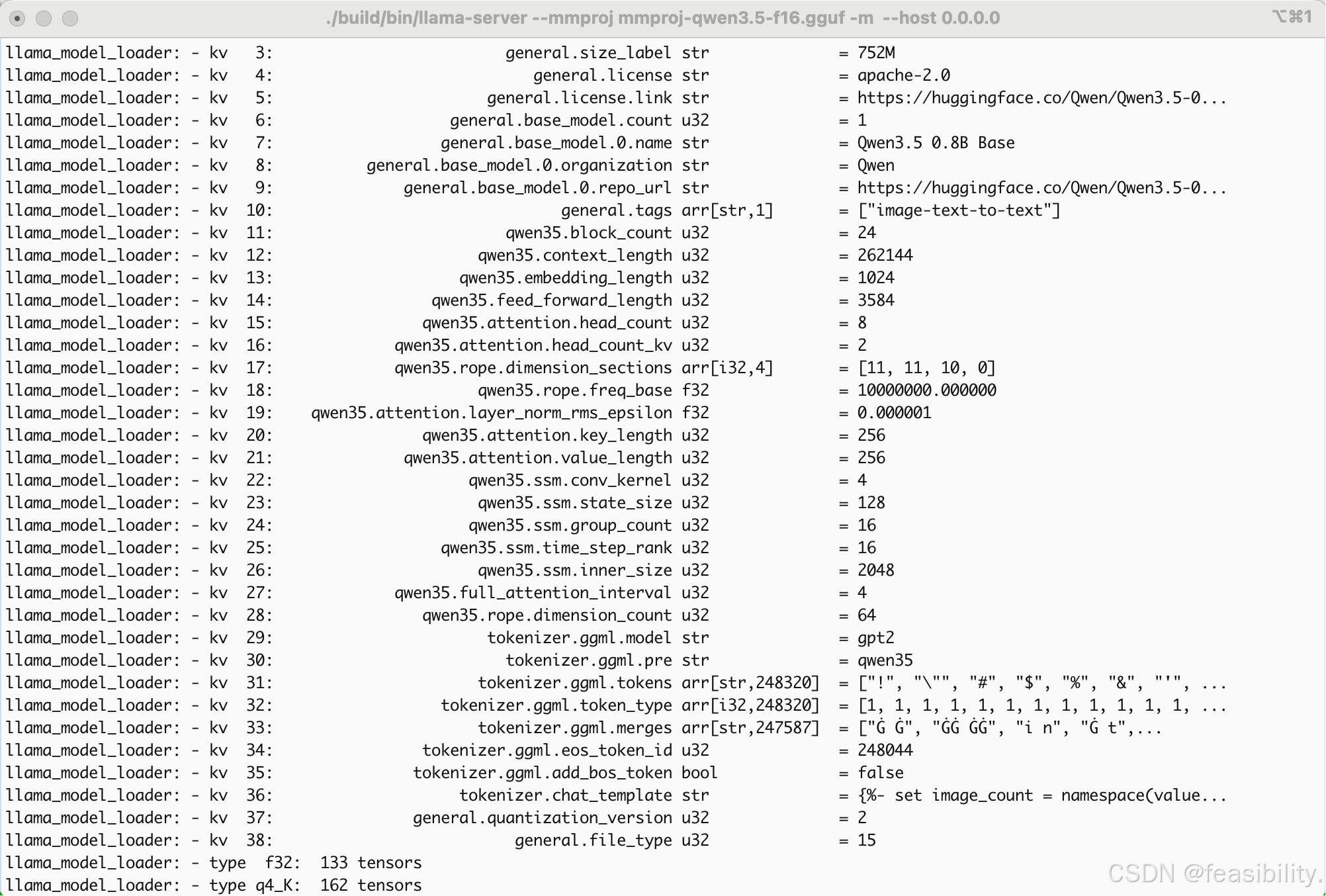
执行./build/bin/llama-server \
--mmproj mmproj-qwen3.5-f16.gguf \
-m qwen3.5-Q4_K_M.gguf \
--host 0.0.0.0 \
--port 8080 \
-t 10 \
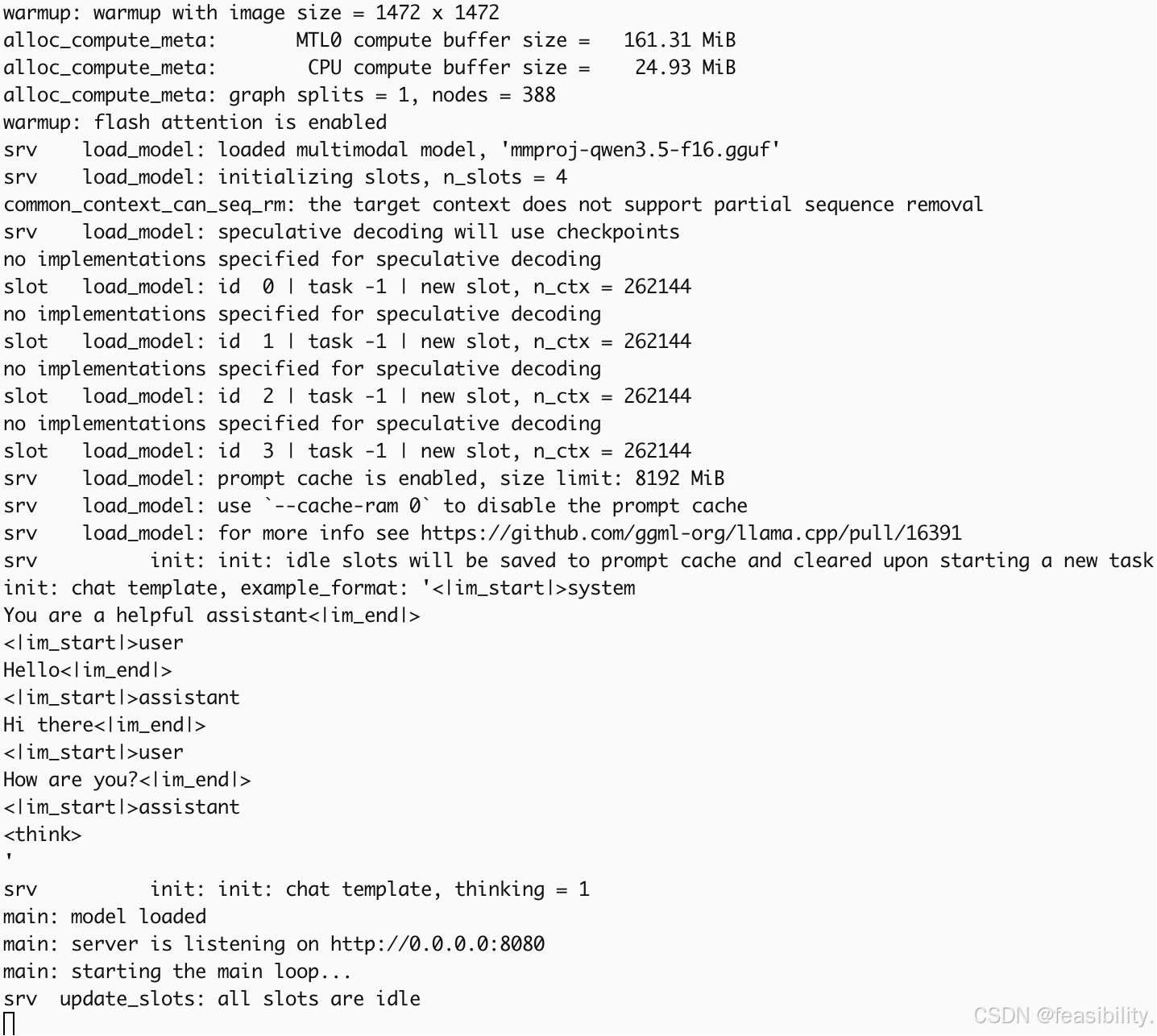
-ngl 99使用 llama-server 启动 REST API 服务
必须先--mmproj,再放 -m,不然会出现报错error: invalid argument,host为0.0.0.0允许局域网访问,port是端口号可修改,参数t是线程数
ui界面访问
服务启动后访问 http://localhost:8080 可以打开ui界面
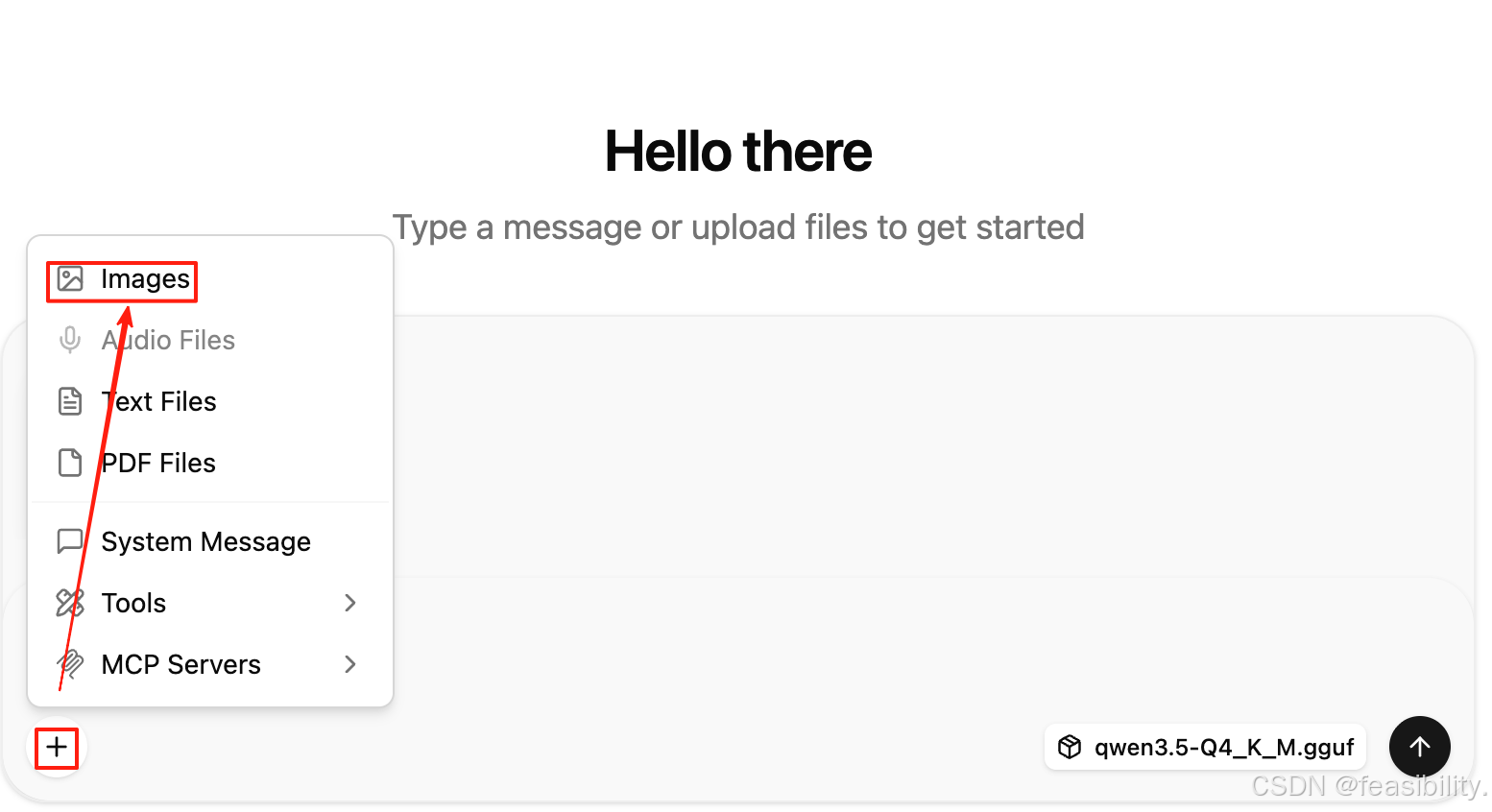
测试对话,点击加号选择images可以添加图片
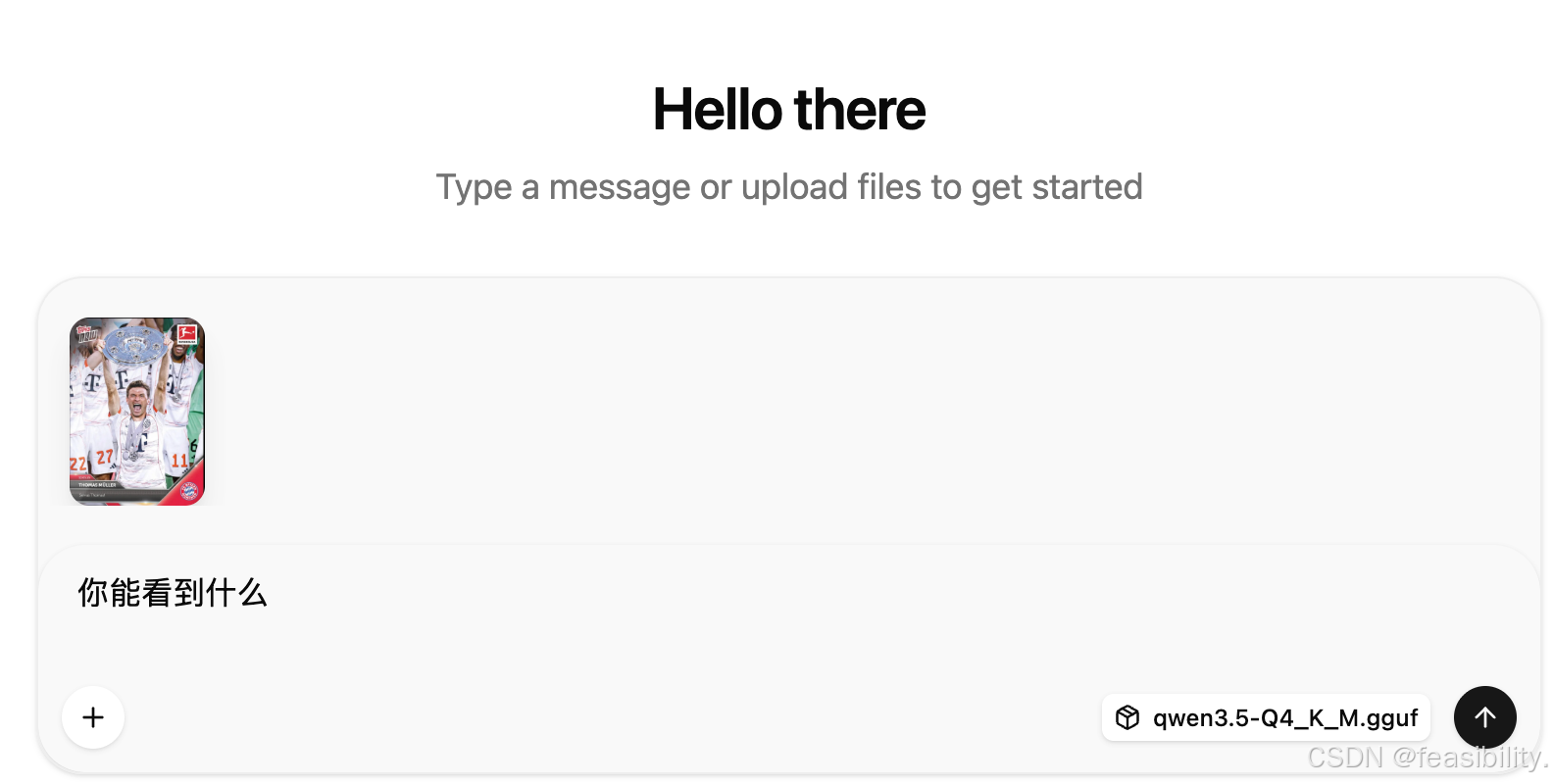
模型根据图片回答了问题,基本正确,也注意到年份等细节,另外也可以看到token消耗和用时等信息
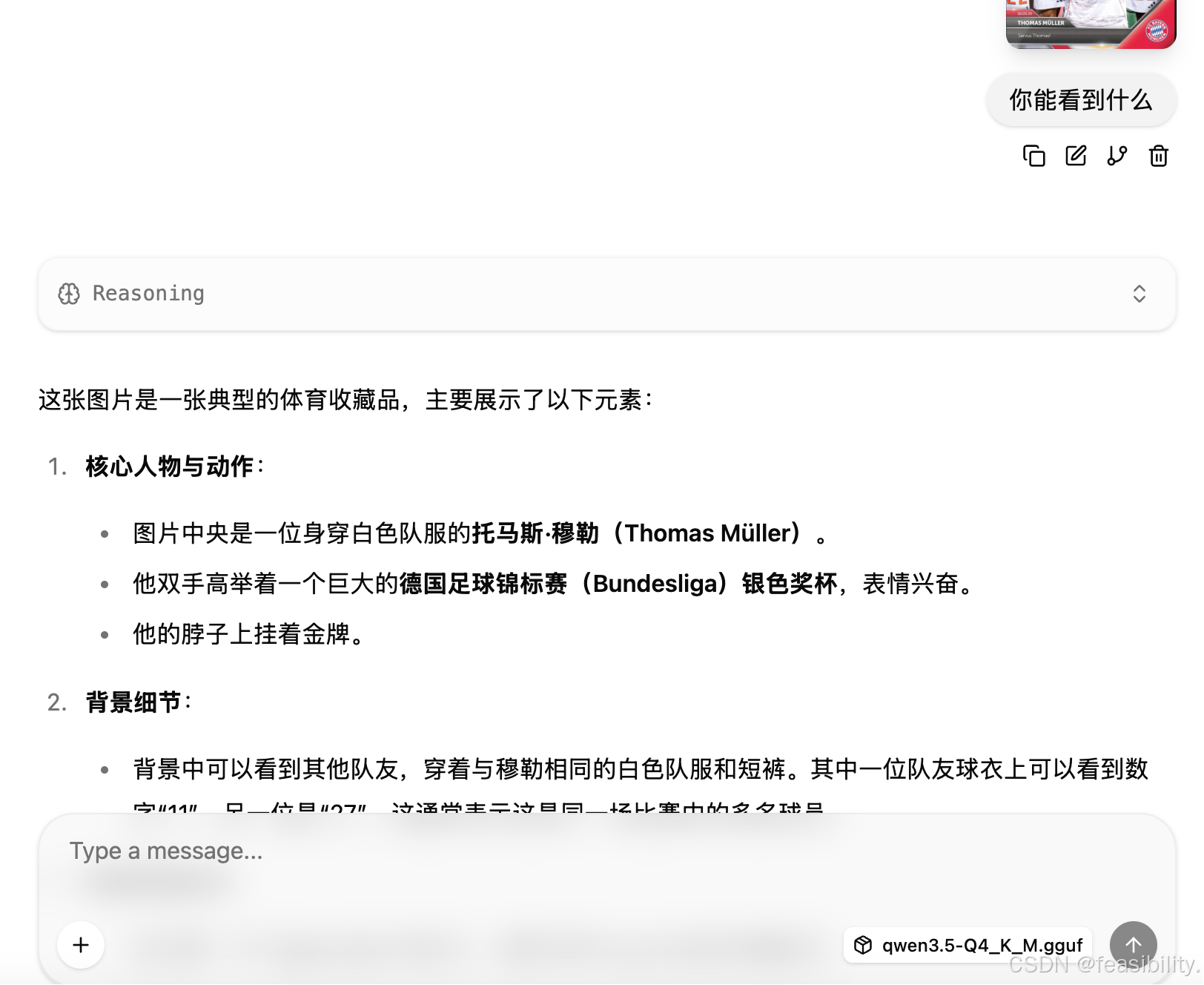
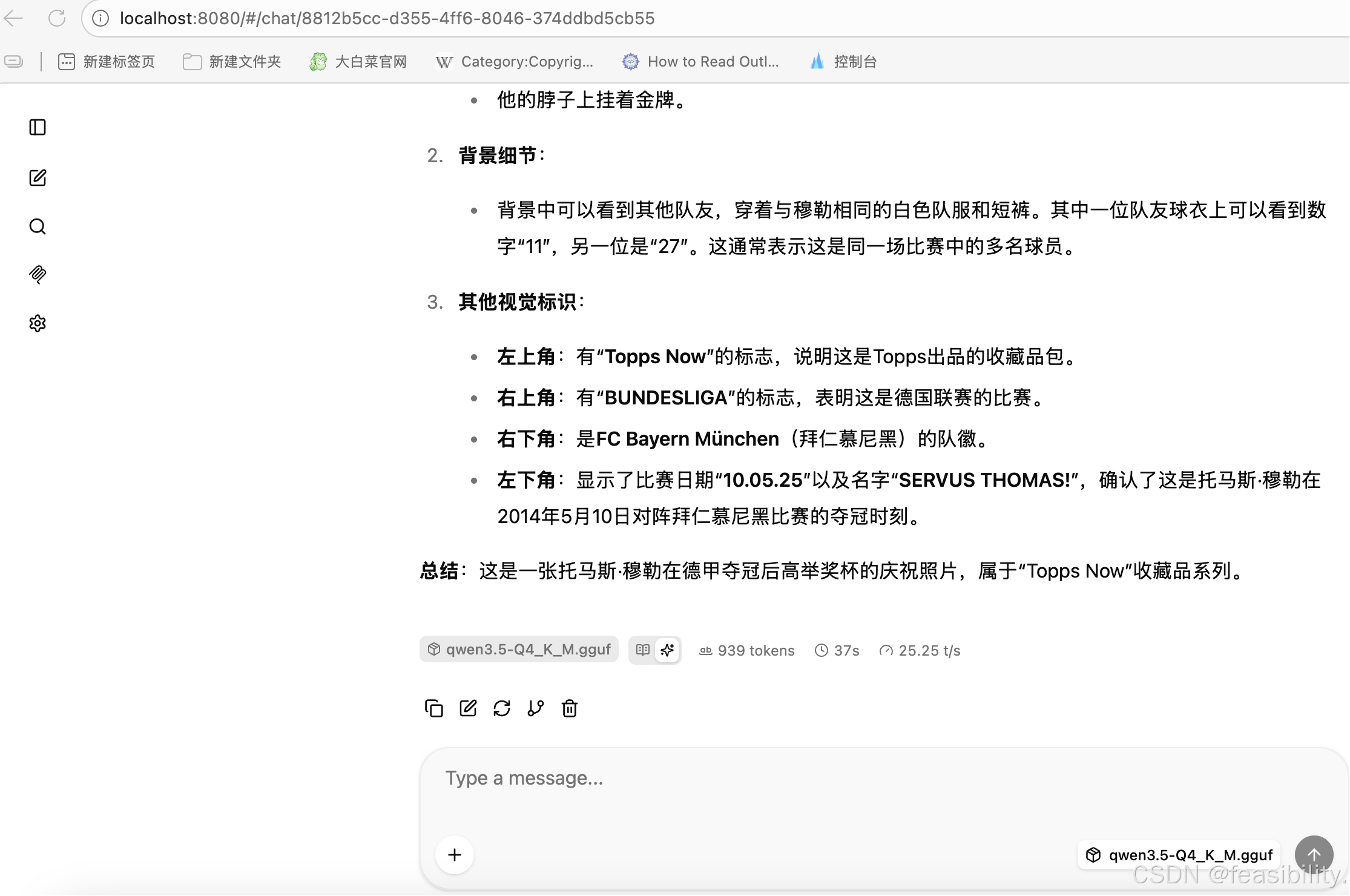
调用API
传本地图片需转为base64格式(转base64的方法在不同系统有差异,这里以mac为例)
开个新终端,执行curl -X POST http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3.5",
"messages": [{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,'$(base64 -i /Users/Zhuanz/Downloads/img.jpeg | tr -d '\n')'"}},
{"type": "text", "text": "描述这张图片"}
]
}]
}' /Users/Zhuanz/Downloads/img.jpeg可换成其他图片路径
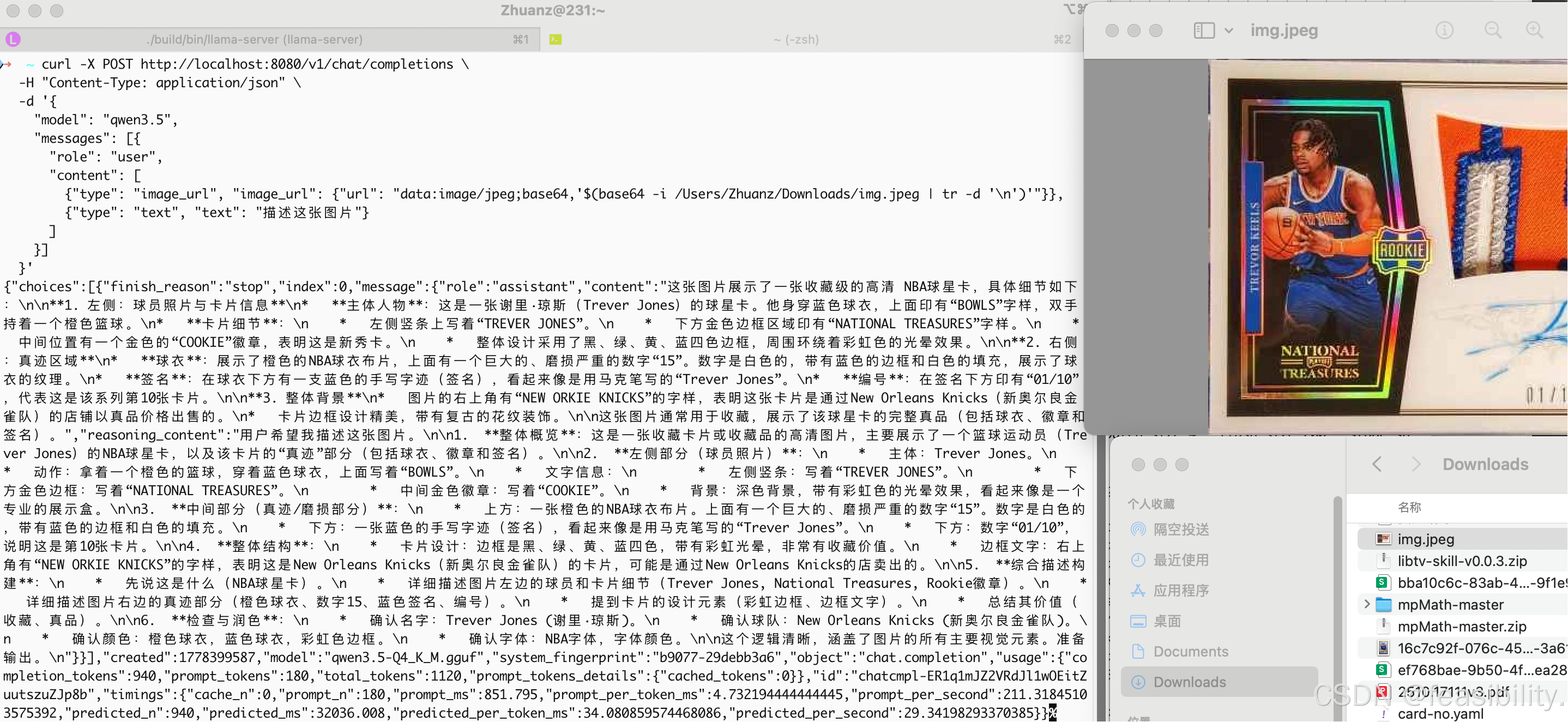
创作不易,禁止抄袭,转载请附上原文链接及标题