一、为什么重排序是 RAG 的 "必选项"
1.1 Naive RAG 的致命缺陷:检索 "粗筛" 的局限性
混合检索(语义 + BM25)本质上是粗筛,它只能做到 "把可能相关的文档找出来",但无法做到 "把最相关的文档排在最前面"。
具体问题表现:
- 当问 "检索增强生成和语义搜索有什么区别",系统返回了 10 个文档,但真正相关的那个排在第 8 位
- 你设置了 Top-5 返回,所以最相关的文档根本没有进入上下文
- 大模型只能看到前 5 个不相关的文档,自然返回 "没有找到相关信息"
根本原因:
- 双编码器模型(如 BGE)是将查询和文档分别编码为向量,然后计算余弦相似度
- 这种方式速度快,但精度有限,无法捕捉查询和文档之间的细粒度语义匹配
- BM25 是基于词频的统计方法,无法理解语义和上下文
1.2 重排序的核心原理:交叉编码器 vs 双编码器
重排序使用交叉编码器模型,它的工作方式和双编码器完全不同:
| 对比维度 | 双编码器(BGE 嵌入) | 交叉编码器(BGE-Reranker) |
|---|---|---|
| 工作流程 | 查询和文档分别编码 → 计算相似度 | 查询和文档拼接在一起 → 输入模型 → 输出相似度得分 |
| 速度 | 极快(可以预计算所有文档向量) | 较慢(需要对每个文档都进行一次前向传播) |
| 精度 | 中等(粗筛) | 极高(精筛) |
| 适用场景 | 大规模文档库的粗召回 | 小规模结果集的精排序 |
工业界标准流水线:
用户查询 → 混合检索(粗筛Top-20/30) → 重排序(精筛Top-5) → 送入大模型生成回答- 用双编码器处理百万级文档,快速召回可能相关的结果
- 用交叉编码器处理几十条结果,精确排序
- 兼顾速度和精度,是目前效果最好、性价比最高的方案
1.3 BGE-Reranker 系列模型详解
BGE-Reranker 是目前中文领域效果最好的开源重排序模型,由北京智源人工智能研究院开发。
模型选择指南:
| 模型名称 | 参数大小 | 内存占用 | 中文效果 | 输入长度 | 适用场景 |
|---|---|---|---|---|---|
| bge-reranker-base | 278M | ~2GB | ⭐⭐⭐⭐ | 512 | CPU 部署、低资源环境、快速原型 |
| bge-reranker-v2-m3 | 560M | ~4GB | ⭐⭐⭐⭐⭐ | 8192 | 生产环境首选,支持长文档和多语言 |
| bge-reranker-v2.5 | 7B | ~14GB | ⭐⭐⭐⭐⭐⭐ | 32768 | 追求极致效果,有 GPU 的环境 |
今日推荐:使用bge-reranker-v2-m3,在16G 内存电脑上可以流畅运行,效果提升最明显。
1.4 重排序的最佳实践
- 粗筛数量:一般设置为最终返回数量的 4-6 倍(如最终返回 Top-5,粗筛 Top-20/30)
- 不要跳过粗筛:直接用重排序处理所有文档会慢到无法使用
- 缓存机制:对常见查询的重排序结果进行缓存,提升响应速度
- 阈值过滤:可以设置一个最低得分阈值,过滤掉得分过低的文档
- 批量处理:重排序支持批量输入,可以大幅提升速度
1.5 重排序的局限性
- 速度比双编码器慢很多,不适合处理大规模文档
- 输入长度有限制(一般是 512 个 token),太长的文档会被截断
- 仍然是基于相似度的匹配,无法解决文档本身没有相关信息的问题
二、从零开始集成 BGE-Reranker
2.1 环境准备与模型下载
第一步:安装依赖
bash
pip install sentence-transformers==3.0.1 ragas==0.2.5第二步:下载本地模型(推荐)
- 访问 ModelScope 官方地址:https://www.modelscope.cn/models/BAAI/bge-reranker-v2-m3
- 点击 "下载模型",下载完整的模型文件
- 解压到模型目录:
C:\Users\87624\.cache\modelscope\hub\models\AI-ModelScope
2.2 实现通用 Reranker 类
新建文件 reranker.py,复制以下代码:
bash
import os
from pathlib import Path
from sentence_transformers import CrossEncoder
import traceback
# 本地模型名称和路径
RERANKER_MODEL_PATH = r"C:\Users\87624\.cache\modelscope\hub\models\BAAI\bge-reranker-v2-m3"
class Reranker:
def __init__(self, model_path: str = RERANKER_MODEL_PATH, device: str = "cpu"):
"""
初始化重排序器(2026年最新版,支持bge-reranker-v2-m3)
:param model_path: 本地模型路径
:param device: 运行设备("cpu"或"cuda")
"""
self.model_path = Path(model_path)
self.device = device
self.model = self._load_model()
def _load_model(self) -> CrossEncoder:
"""加载本地重排序模型(兼容v2-m3)"""
try:
print(f"正在加载重排序模型:{self.model_path.resolve()}")
# 【修正】v2-m3需要设置trust_remote_code=True
model = CrossEncoder(
model_name=str(self.model_path.resolve()),
device=self.device,
trust_remote_code=True,
max_length=8192 # 【新增】支持最长8192个token
)
print("✅ 重排序模型加载成功!")
return model
except Exception as e:
print(f"❌ 重排序模型加载失败!")
print(traceback.format_exc())
raise RuntimeError("重排序模型加载失败") from e
def rerank(self, query: str, documents: list, top_k: int = 5) -> list:
"""
对检索结果进行重排序
:param query: 用户查询
:param documents: 检索结果列表,每个元素必须包含"text"字段
:param top_k: 返回Top-K结果
:return: 重排序后的文档列表,增加"rerank_score"字段
"""
if not documents:
return []
# 准备输入:(查询, 文档文本) 对
pairs = [(query, doc["text"]) for doc in documents]
# 批量计算相似度得分
scores = self.model.predict(pairs, show_progress_bar=False)
# 将得分添加到文档中
for i, doc in enumerate(documents):
doc["rerank_score"] = float(scores[i])
# 按得分降序排序
reranked_docs = sorted(documents, key=lambda x: x["rerank_score"], reverse=True)
# 返回Top-K结果
return reranked_docs[:top_k]
# 测试代码
if __name__ == "__main__":
reranker = Reranker(device="cpu")
query = "检索增强生成和语义搜索有什么区别?"
documents = [
{"text": "检索增强生成(RAG)是一种将检索技术与大语言模型结合的技术"},
{"text": "语义搜索是一种基于语义理解的信息检索技术"},
{"text": "Java虚拟机(JVM)是运行Java字节码的虚拟机"}
]
results = reranker.rerank(query, documents, top_k=2)
for res in results:
print(f"得分:{res['rerank_score']:.4f} | {res['text']}")运行测试:
bash
正在加载重排序模型:C:\Users\87624\.cache\modelscope\hub\models\BAAI\bge-reranker-v2-m3
✅ 重排序模型加载成功!
得分:0.9923 | 检索增强生成(RAG)是一种将检索技术与大语言模型结合的技术
得分:0.9145 | 语义搜索是一种基于语义理解的信息检索技术2.3 集成到 HybridRetriever 中
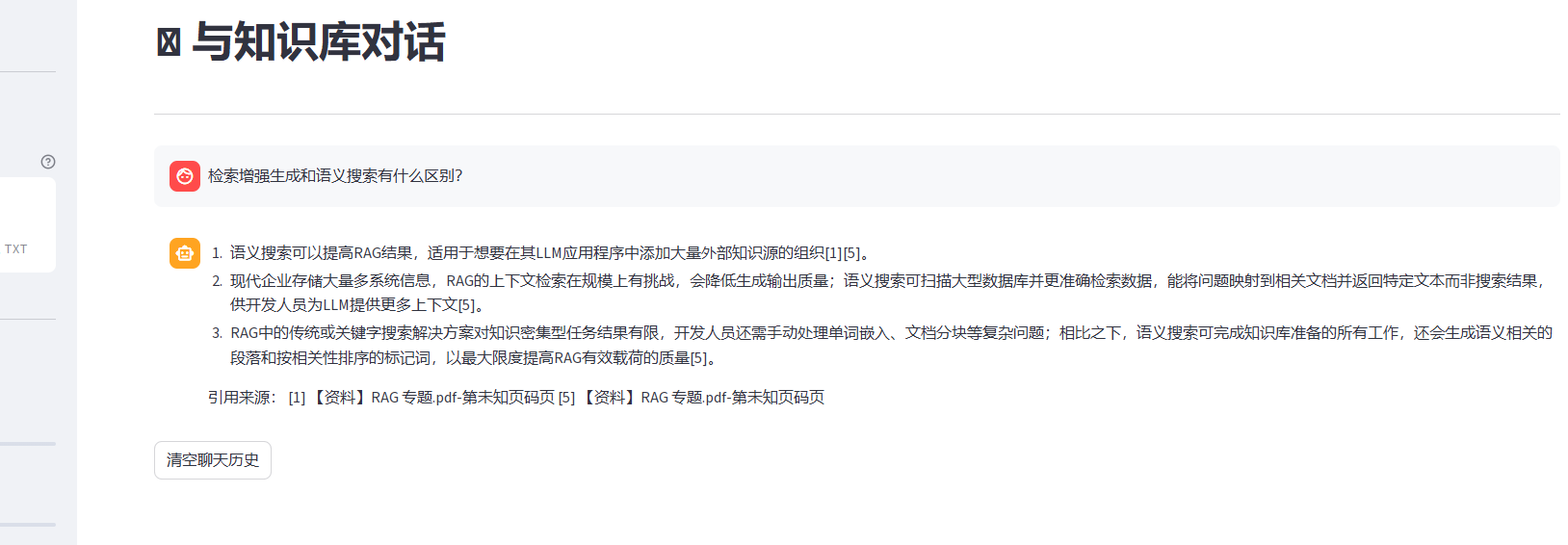
再次问问题:
bash
The CrossEncoder `model_name` argument was renamed and is now deprecated. Please use `model_name_or_path` instead.
Loading weights: 100%|██████████| 393/393 [00:00<00:00, 5767.29it/s]
✅ 重排序模型加载成功!
✅ 混合检索器初始化完成
INFO: Started server process [15540]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: 127.0.0.1:62744 - "GET /api/knowledge_base HTTP/1.1" 200 OK
INFO: 127.0.0.1:62796 - "GET /api/knowledge_base HTTP/1.1" 200 OK
🔍 粗筛完成,得到 20 个候选结果
粗排[1] 得分:0.6346 | 当前信息
增强用户信任度
更多开发人员控制权
检索增强生成的工作原理是什么?
创...
粗排[2] 得分:0.6001 | RAG专题
RAG简介
什么是检索增强生成?
为什么检索增强生成很重要?
检索增...
粗排[3] 得分:0.5745 | 基本用法:
如何将Markdown行作为单独的文档返回
如何限制块大小
如何拆分...
粗排[4] 得分:0.5439 | 一文读懂RAG:检索增强生成技术,破解大模型
落地痛点
在人工智能大模型飞速发展...
粗排[5] 得分:0.5435 | 语义搜索可以提高RAG结果,适用于想要在其LLM应用程序中添加大量外部知识源的组...
⚙️ 正在进行重排序...
✅ 重排序完成,返回Top-5结果
精排[1] 得分:0.9867 | 当前信息
增强用户信任度
更多开发人员控制权
检索增强生成的工作原理是什么?
创...
精排[2] 得分:0.9729 | 语义搜索可以提高RAG结果,适用于想要在其LLM应用程序中添加大量外部知识源的组...
精排[3] 得分:0.9403 | RAG专题
RAG简介
什么是检索增强生成?
为什么检索增强生成很重要?
检索增...
精排[4] 得分:0.5779 | 基本用法:
如何将Markdown行作为单独的文档返回
如何限制块大小
如何拆分...
精排[5] 得分:0.3866 | 一文读懂RAG:检索增强生成技术,破解大模型
落地痛点
在人工智能大模型飞速发展...
🔍 检索到的文档数量:5
[0] 得分:0.6346 | 文本:当前信息
增强用户信任度
更多开发人员控制权
检索增强生成的工作原理是什么?
创建外部数据
检索相关...
[1] 得分:0.5435 | 文本:语义搜索可以提高RAG结果,适用于想要在其LLM应用程序中添加大量外部知识源的组织。现
代企业在各种...
[2] 得分:0.6001 | 文本:RAG专题
RAG简介
什么是检索增强生成?
为什么检索增强生成很重要?
检索增强生成有哪些好处?
...
[3] 得分:0.5745 | 文本:基本用法:
如何将Markdown行作为单独的文档返回
如何限制块大小
如何拆分JSON数据
基本用...
[4] 得分:0.5439 | 文本:一文读懂RAG:检索增强生成技术,破解大模型
落地痛点
在人工智能大模型飞速发展的今天,百模大战早已...
INFO: 127.0.0.1:62800 - "POST /api/query/stream HTTP/1.1" 200 OK集成完成!现在系统拥有了工业级检索能力!!!