文章标题
-
- 一、核心逻辑:为什么是二进制?
- 二、进制转换详解
-
- [2.1 任意进制转十进制:系数加权法](#2.1 任意进制转十进制:系数加权法)
- [2.2 十进制转任意进制:除基取余法](#2.2 十进制转任意进制:除基取余法)
- [2.3 快速转换:8421 码](#2.3 快速转换:8421 码)
- [2.4 常见进制对照与 Java 书写规范](#2.4 常见进制对照与 Java 书写规范)
- 三、不同类型数据的存储规则
-
- [3.1 文本数据](#3.1 文本数据)
- [3.2 图片数据](#3.2 图片数据)
- [3.3 声音数据](#3.3 声音数据)
- [3.4 三种数据存储逻辑总结](#3.4 三种数据存储逻辑总结)
- 四、存储介质的历史演进
-
- [极致折叠:800 米高的"纸塔"](#极致折叠:800 米高的"纸塔")
- 总结

🎬 博主名称: 超级苦力怕
🔥 个人专栏: 《基本功修炼大全》
🚀 每一次思考都是突破的前奏,每一次复盘都是精进的开始!
无论是高清电影、优美乐曲,还是你正在阅读的这篇文章,在计算机底层最终都会化为枯燥的"0"与"1"。
许多初学者面对"计算机为何只认二进制"、"进制间如何高效转换"或"汉字在内存中占几个字节"等问题时,往往知其然而不知其所以然。
本文从底层逻辑出发,系统拆解计算机存储数据的完整链路,适合刚入门编程或准备面试的同学阅读。
一、核心逻辑:为什么是二进制?
计算机中的任意数据(文本、图片、声音)最终都以二进制(Binary)形式存储。二进制由 0 和 1 组成,运算规则为"逢二进一,借一当二"。例如在二进制中,1 + 1 = 10(即十进制的 2)。
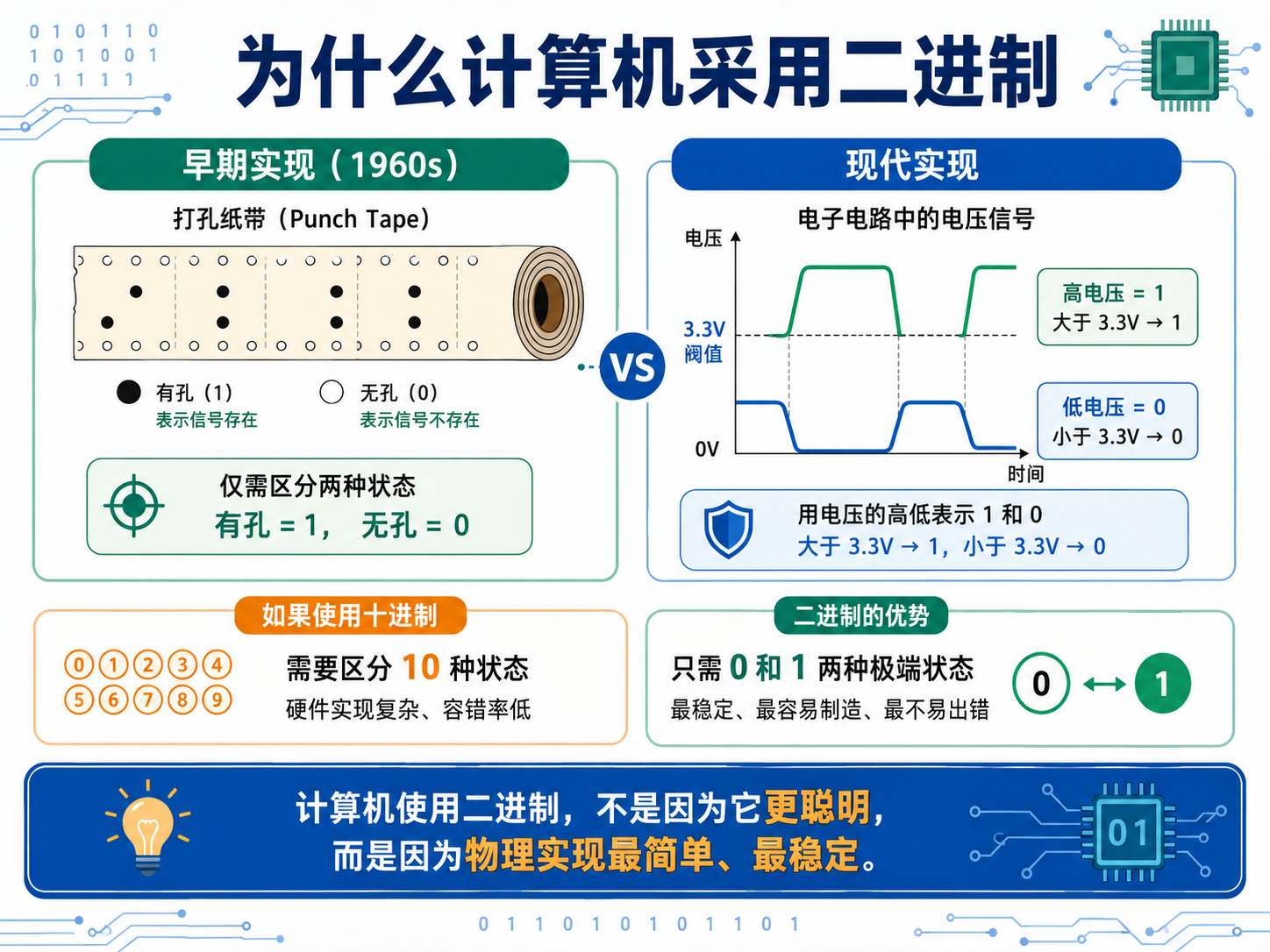
计算机选择二进制并非偶然,而是受限于硬件实现的物理现实:
| 时代 | 实现方式 | 逻辑 |
|---|---|---|
| 早期(1960s) | 打孔纸带 | 有孔为 0,无孔为 1 |
| 现代 | 电路电压 | 大于 3.3V 为 1,小于 3.3V 为 0 |
如果使用十进制,早期需要在纸带上区分十种不同大小或形状的孔,硬件难以精确识别。而二进制只有两种极端状态,将物理容错率拉到了极致。
💡 核心结论: 计算机使用二进制,不是因为二进制"聪明",而是因为"仅识别两种状态"在物理制造上最简单且不易出错。
二、进制转换详解
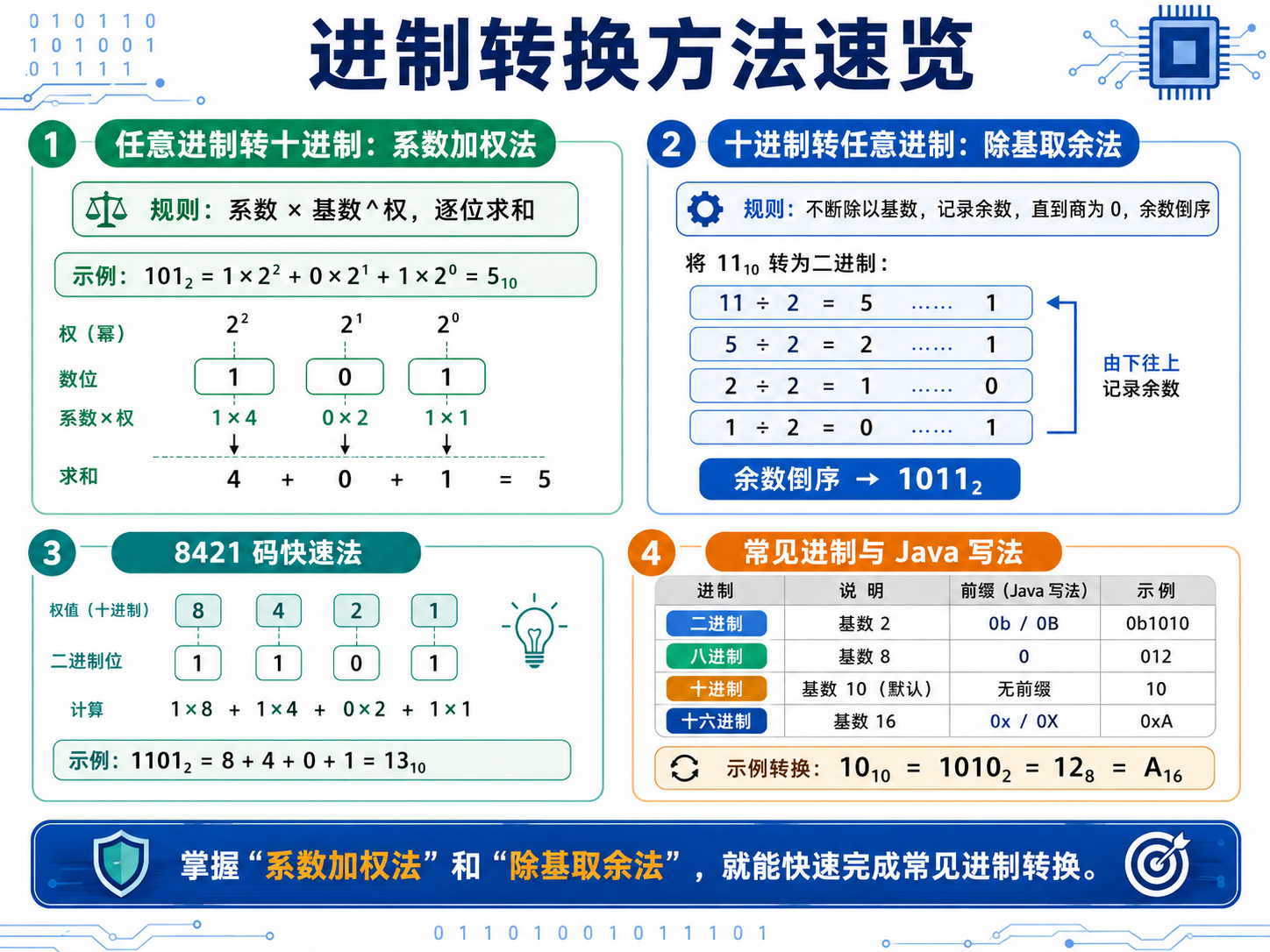
2.1 任意进制转十进制:系数加权法
公式:系数 × 基数^权,逐位求和。
| 概念 | 说明 |
|---|---|
| 系数 | 每一位上的数字 |
| 基数 | 当前进制(二进制基数为 2,八进制为 8) |
| 权 | 从右往左,依次为 0, 1, 2... |
示例:二进制 101 转十进制:1×2² + 0×2¹ + 1×2⁰ = 4 + 0 + 1 = 5
2.2 十进制转任意进制:除基取余法
不断除以基数,记录余数,直到商为 0,将余数倒序拼接。
✅ 十进制 11 转二进制
java
// 除基取余法:不断除以 2,记录余数,倒序排列
int num = 11;
// 11 ÷ 2 = 5 ... 1
// 5 ÷ 2 = 2 ... 1
// 2 ÷ 2 = 1 ... 0
// 1 ÷ 2 = 0 ... 1
// 余数倒序 → 1011
System.out.println(Integer.toBinaryString(11)); // 输出: 10112.3 快速转换:8421 码
针对二进制转十进制,记住每一位的固定权值(从右往左):
... 128 → 64 → 32 → 16 → 8 → 4 → 2 → 1
示例:1101 = 8 + 4 + 0 + 1 = 13
2.4 常见进制对照与 Java 书写规范
| 进制 | 十进制 | 二进制 | 八进制 | 十六进制 | Java 前缀 |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | --- |
| 1 | 1 | 1 | 1 | 1 | --- |
| 2 | 2 | 10 | 2 | 2 | --- |
| 10 | 10 | 1010 | 12 | A | --- |
| 15 | 15 | 1111 | 17 | F | --- |
| 进制类型 | Java 书写规范(JDK7+) | 示例 |
|---|---|---|
| 二进制 | 0b 或 0B 开头 |
0b101 |
| 八进制 | 0 开头 |
017 |
| 十进制 | 默认 | 17 |
| 十六进制 | 0x 或 0X 开头 |
0x123 |
三、不同类型数据的存储规则
3.1 文本数据
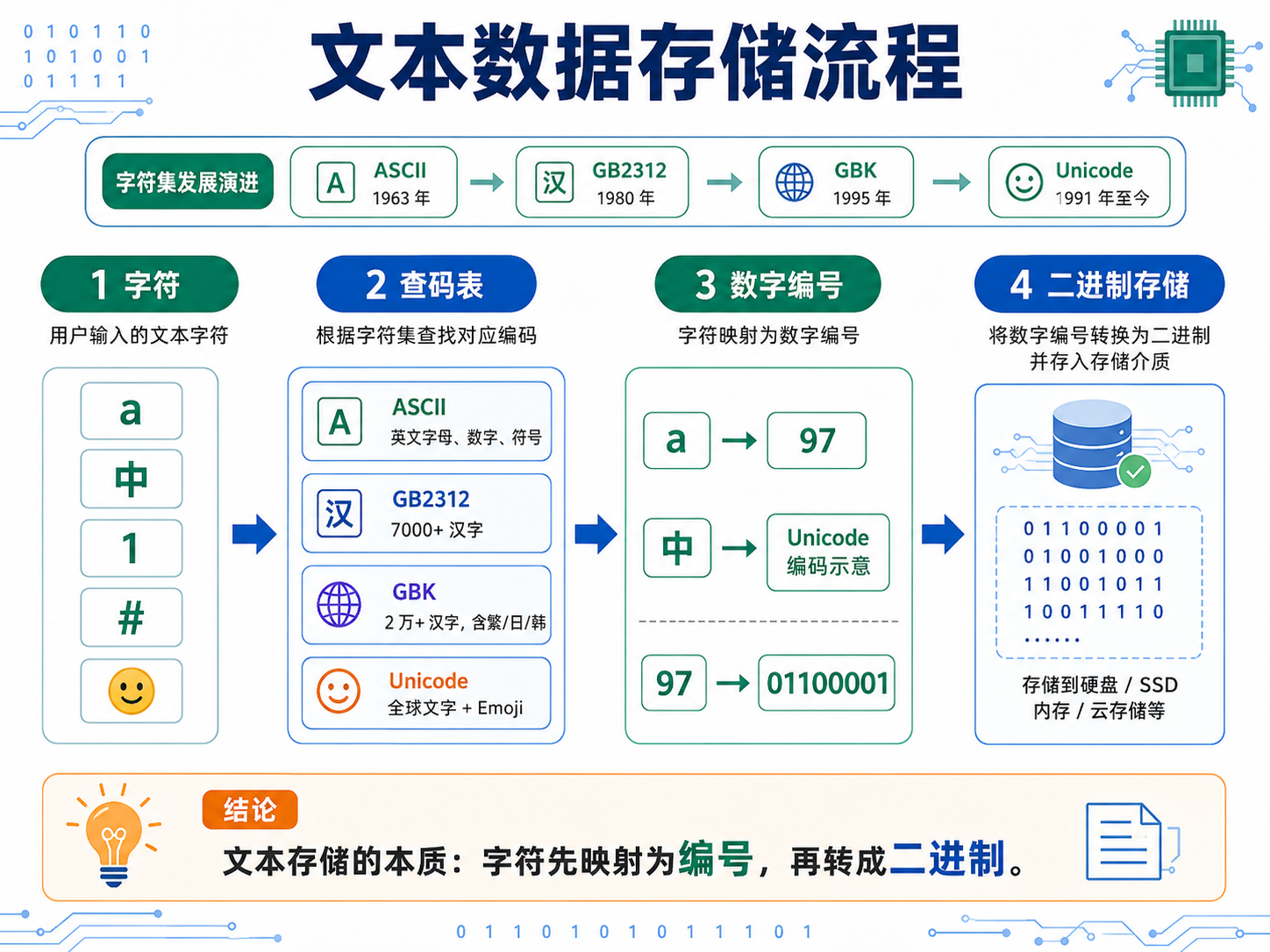
文本通过字符集(码表)建立字符与数字的对应关系------本质上就是"查字典"。
| 字符集 | 年代 | 收录范围 | 说明 |
|---|---|---|---|
| ASCII | 1960s | 英文字母、数字、符号 | 如 a 对应数字 97 |
| GB2312 | 1981 | 7000+ 汉字 | 中国首个汉字编码标准 |
| GBK | 2000 | 2 万+ 汉字,含繁/日/韩 | Windows 默认码表 |
| Unicode | 至今 | 全球文字 + Emoji | 万国码,终极"字典" |
存储流程:字符 → 查码表得数字编号 → 转为二进制
3.2 图片数据
图片由无数个像素点(Pixel)组成网格。如 1920 × 1080 分辨率,表示宽 1920 列、高 1080 行像素。
色彩通过 RGB 光学三原色 调配:
| 颜色通道 | 取值范围 | 示例值 | 含义 |
|---|---|---|---|
| R(红) | 0~255 | 255 | 红色浓度最大 |
| G(绿) | 0~255 | 0 | 无绿色 |
| B(蓝) | 0~255 | 0 | 无蓝色 |
常用 RGB 组合:
(255, 0, 0)→ 纯红色(0, 0, 0)→ 纯黑色(255, 255, 255)→ 纯白色(三色全满合成白光)
存储流程:像素网格 → 每个像素一组 RGB 浓度值 → 转为二进制
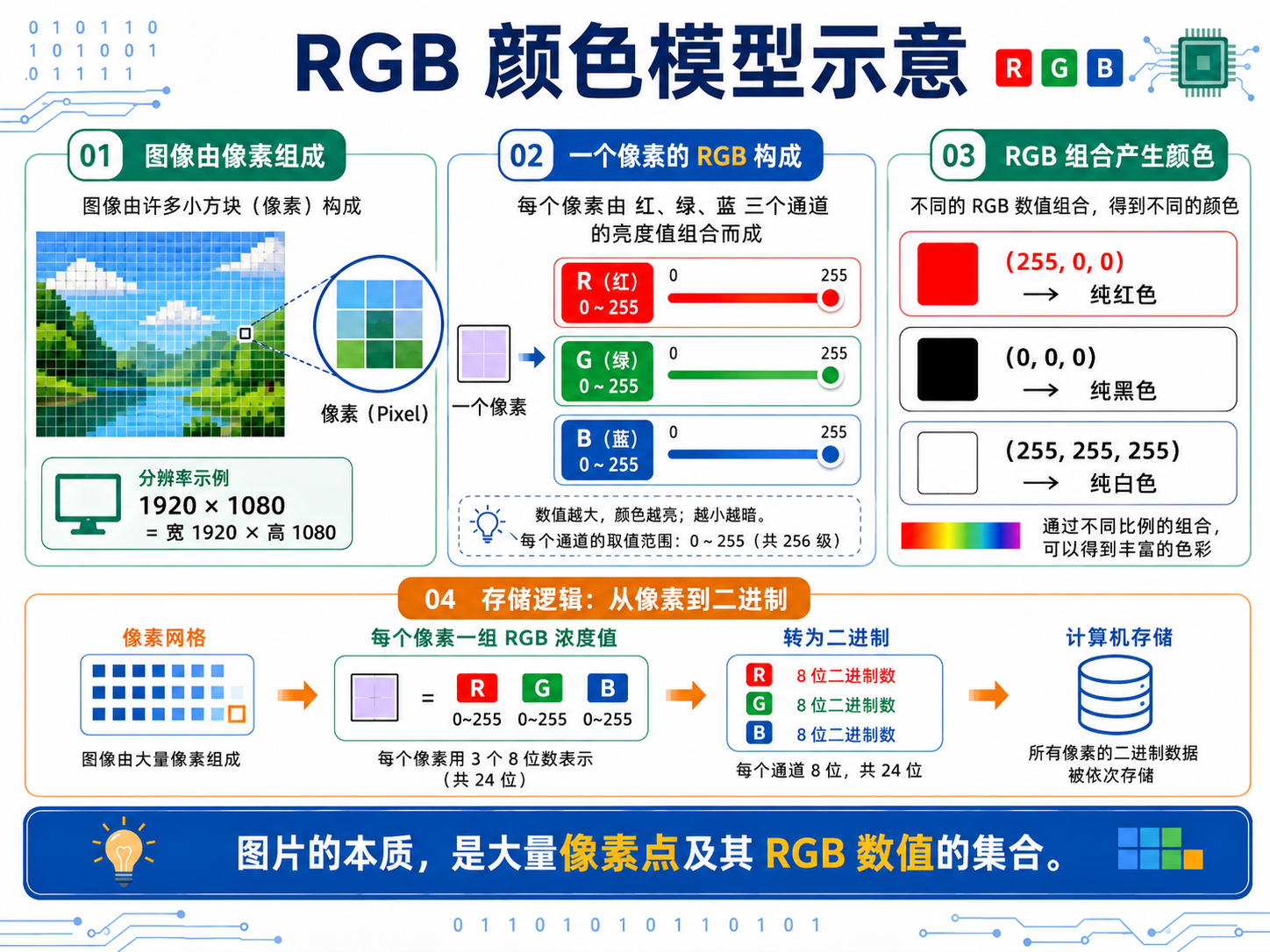
补充:RGB 每个通道用 0~255 表示,是因为这正好是 1 字节 = 8 比特 能编码的全部范围 ------ 从全黑 (0) 到全饱和 (255)。
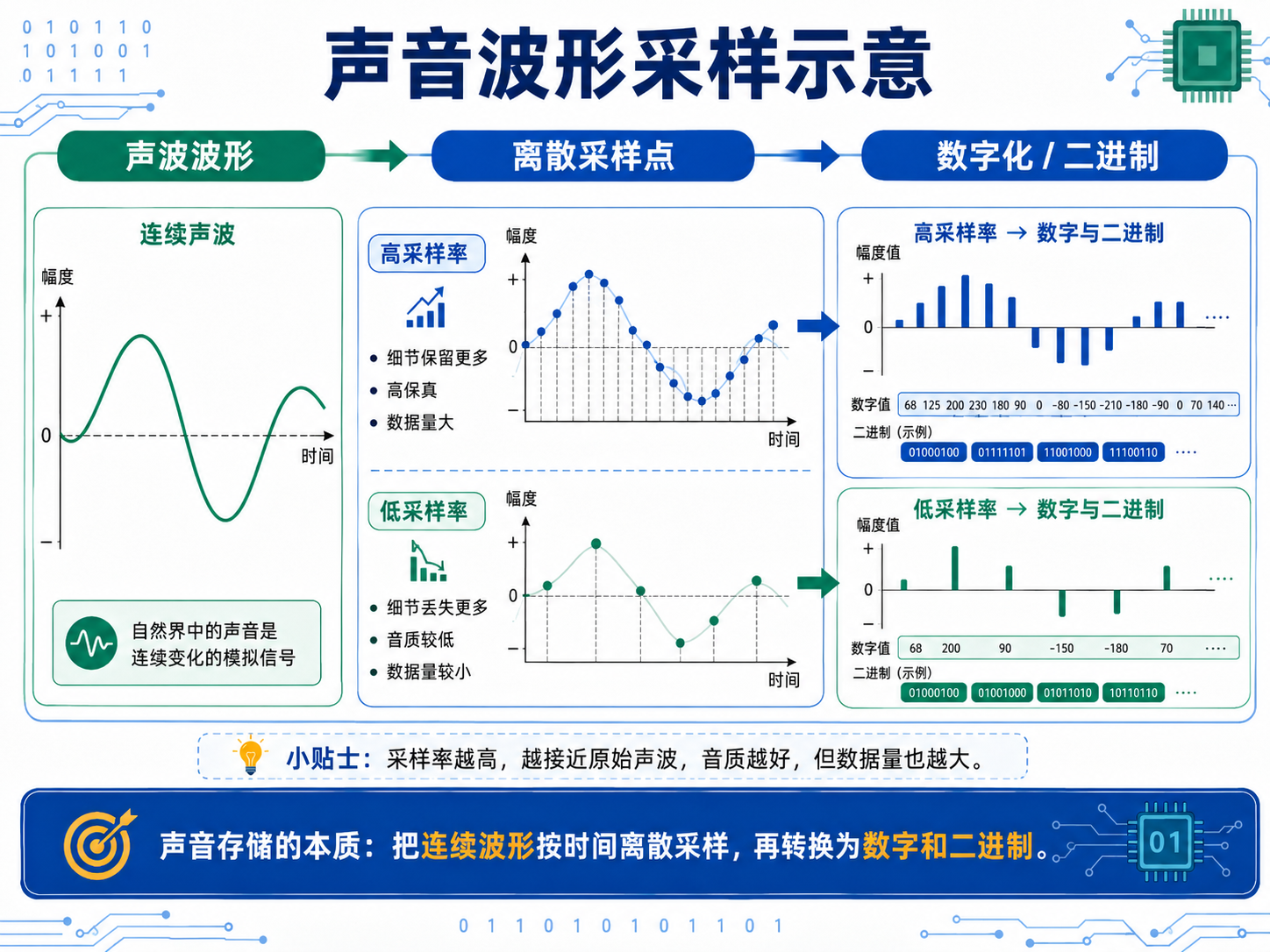
3.3 声音数据
声音通过对声波波形图进行采样(Sampling)存储------在波形的时间轴上记录离散的点位数字。
| 采样率 | 效果 | 数据量 |
|---|---|---|
| 高采样率 | 采样点密集,完美还原声波细节(高保真/无损) | 庞大 |
| 低采样率 | 采样点稀疏,丢失高频细节(全损音质) | 较小 |
存储流程:声波波形 → 离散采样点数字 → 转为二进制
3.4 三种数据存储逻辑总结
| 数据类型 | 核心存储逻辑 | 关键技术点 |
|---|---|---|
| 文本 | 字符 → 码表数字 → 二进制 | ASCII / GBK / Unicode |
| 图片 | 像素 → RGB 浓度值 → 二进制 | 分辨率 / 光学三原色 |
| 声音 | 波形 → 采样点数字 → 二进制 | 采样频率 |
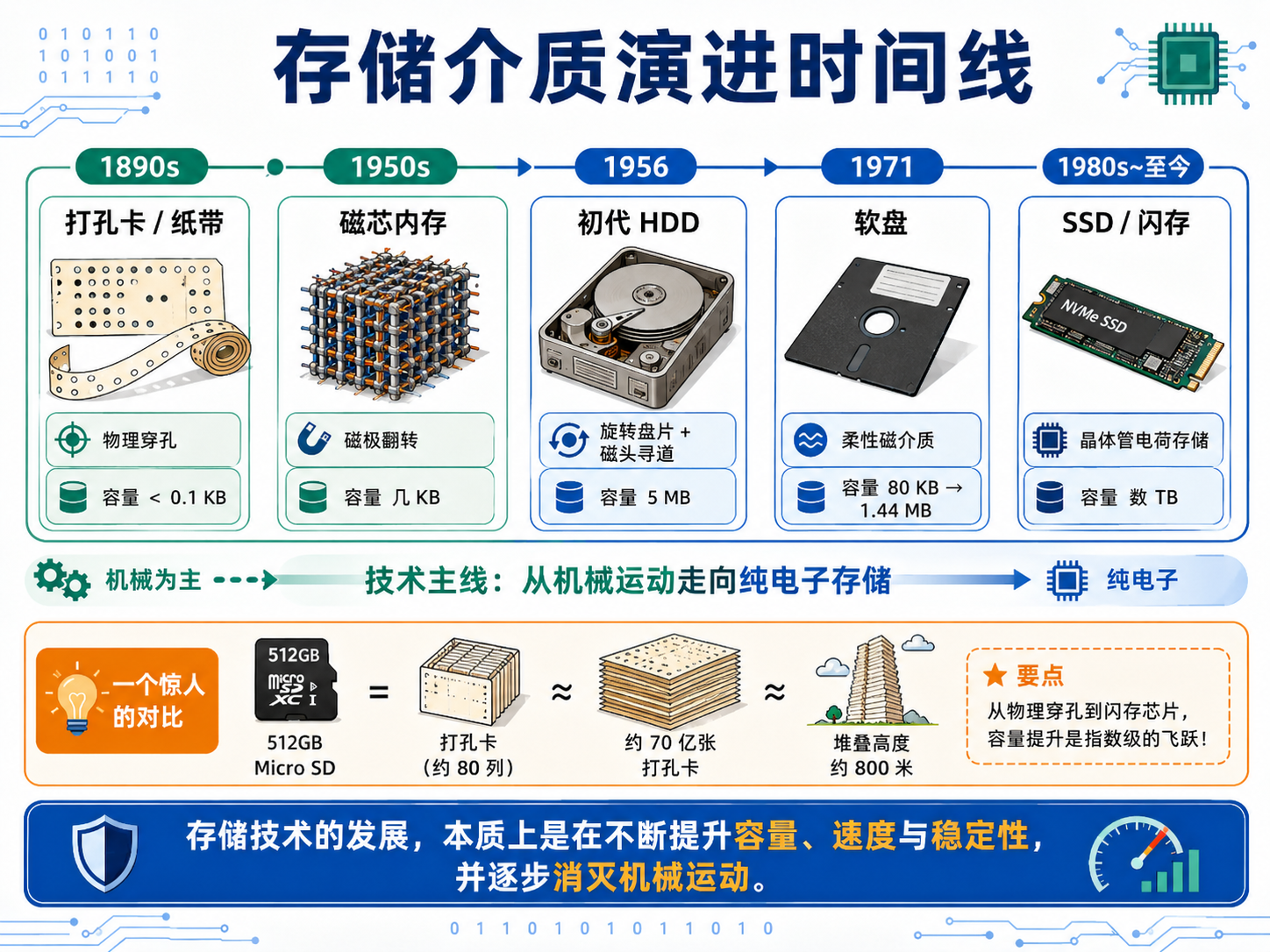
四、存储介质的历史演进
从纸张到纳米晶体管,存储技术经历了一场"消灭机械运动、拥抱电子速度"的革命。
| 时代 | 存储介质 | 核心原理 | 机械部件 | 容量 |
|---|---|---|---|---|
| 1890s | 打孔卡/纸带 | 物理穿孔(源自纺织机) | 无 | < 0.1 KB |
| 1950s | 磁芯内存 | 磁极翻转(手工编织铁氧体环) | 无 | 几 KB |
| 1956 | 初代 HDD | IBM 50 英尺硬盘,50 个盘片 | 有(旋转/寻道) | 5 MB |
| 1971 | 软盘 | 柔性磁介质 | 有 | 80 KB → 1.44 MB |
| 1980s~至今 | SSD/闪存 | 纳米晶体管电荷存储 | 彻底消除 | 数 TB |
💡 核心结论: 存储技术的终极革命在于彻底消灭物理机械运动。当存储不再依赖旋转的盘片和移动的磁头,数据便实现了从"模拟爬行"到"量子跃迁"的飞跃。
极致折叠:800 米高的"纸塔"
存满一张 512GB Micro SD 卡,在 19 世纪末需要约 70 亿张 IBM 打孔卡。全部堆叠起来,高度将达到 800 米------比迪拜哈利法塔还高。计算机存储的百年历史,就是一部将宏伟现实世界不断折叠进微观晶体管的物理史诗。
总结
| 维度 | 核心要点 |
|---|---|
| 根本原因 | 二进制只有两种状态,物理制造最稳定 |
| 进制转换 | 系数加权法(任意→十)+ 除基取余法(十→任意) |
| 文本存储 | 查码表(ASCII → GBK → Unicode) |
| 图片存储 | 像素网格 + RGB 0~255 浓度配方 |
| 声音存储 | 波形采样,采样率决定音质 |
| 硬件演变 | 打孔纸带 → 磁芯 → HDD → SSD,消灭机械运动是主线 |
💡 核心结论:
- 万物皆二进制------无论是颜色、波形还是文字,进入计算机后都必须通过码表或公式变为 0 和 1。
- 掌握"系数乘基数幂"与"除基取余",是理解底层逻辑的钥匙。
- 技术演进不断去机械化------从打孔纸带到 SSD,存储正变得更快、更小、更稳定。
看完这篇解析,你是否已经理解了你屏幕上的每个像素背后的秘密?你在开发中遇到过最难处理的字符编码问题是什么?欢迎在评论区留言讨论!
