大家好呀,我是飞鱼
现在工作中经常需要调用大模型的 API。
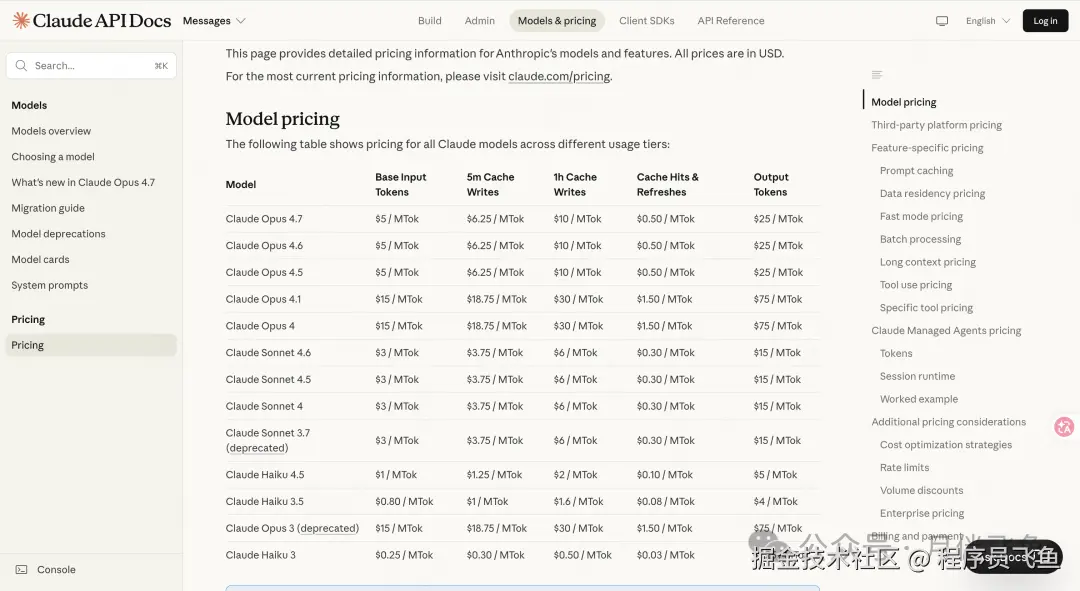
不知道大家有没有没有发现,你打开任何一家大模型 API 的定价页(如下:GPT 和 Claude的)。
同样是TOKEN,输出比输入贵 5 倍?缓存命中的 TOKEN 又便宜 10 倍?

今天就从原理层面,给大家科普解释下这些问题。
具体的话我们得进 GPU 里看看模型推理时究竟发生了什么?
首先当你向大模型发送一条消息,它在后台其实经历了两个阶段,预填充 Prefill 和 解码 Decode。
❝
这两个阶段的分界点恰好是你输入结束,然后模型开始吐字的那一瞬间。
Prefill阶段
❝
模型拿到你的 Prompt 后,会把你输入的所有 TOKEN 一次性塞进 Transformer,然后算出每一个位置的隐藏状态。
最后把最重要的产物 KV CACHE 键值缓存保存下来。
这一阶段是高度并行的。
假设你输入了 1000 个TOKEN, GPU 可以把这 1000 个 TOKEN 同时放进矩阵运算里,一次前向传播全部处理完。
GPU 最擅长的就是这种大矩阵并行计算,这个阶段的瓶颈是算力, GPU 的计算单元几乎被榨干。
每个 TOKEN 分摊下来的成本其实很低。
Decode阶段
❝
Prefill 结束后,模型开始生成输出。
但模型必须一个一个 TOKEN 的往外吐。
因为每生成一个新 TOKEN 都要把它拼回已有序列里才能算下一个。
比如:第 N+1 个 TOKEN 依赖第 N 个 TOKEN 的结果,这是 自回归(Auto Regressive) 的本质,没办法提前并行。
于是每生成一个输出 TOKEN, GPU 都要把整个模型的参数从显存搬到计算单元,然后把不断变长的 KV CACHE 也搬过来,算出下一个TOKEN。
重复以上步骤,这个阶段的瓶颈变成了显存带宽。
这时候 GPU 的算力大部分时间在空转,等着数据从显存慢悠悠传过来。
所以输入走 Prefill 路径:
❝
并行处理,算力拉满,吞吐量高,一张 GPU 一秒可能处理 10 万个输入TOKEN,分摊到单个 TOKEN 的成本自然低。
输出走 Decode 路径:
❝
串行生成带宽瓶颈, GPU 空转严重。
同样一张 GPU 一秒可能只能生成几百个输出 TOKEN 吞吐量差了两三个数量级,自然要贵 3 ~ 5 倍。
顺带也解释了为什么流式响应看起来是一个字一个字蹦出来,因为它就只能这样。
最后缓存命中的 TOKEN 为什么能更便宜?
其实是有一个 Prompt Catching 的设计:
❝
思路就是把 前缀 KV Cache 存在高速缓存里。
下次请求如果前缀一样,直接把现成的 KV Cache 加载进来,跳过 Prefill 的计算环节。
此时付出的成本只有存储这份 KV Cache 的开销,把它加载进计算显存的带宽开销,算力几乎不花。
但缓存是前缀匹配的,你的 Prompt 必须和之前某次请求的开头完全一致,哪怕改一个字,后面的部分就全得重算。
而且缓存有有效期,一般几分钟到几小时,过期就失效。
所以建议把固定不变的内容 System Prompt 长文档放在最前面,把变化的部分用户问题放到最后,能最大化缓存命中率。
最后有几个实用的优化方向
❝
能用缓存就用缓存,把稳定的长前缀放在 Prompt 开头。
控制输出长度,让模型少啰嗦,不只是节省阅读时间,而是实打实省钱。
真的不用害怕长输入,很多业务场景下塞进几千 TOKEN 的上下文,只要能换来一个精准的短输出,总价反而更便宜。
慎用让模型先推理再回答的模式,思考推理模型产生的思考过程往往会被算进输出TOKEN。
❝最后想看技术文章的,可以去我的个人网站:hardyfish.top/