先看这个HR FAQ场景的Agent实现代码:
示例代码取自《AI Agent智能体开发实践》第8章。
# -*- coding: utf-8 -*-
"""
Created on Sun Jul 27 21:05:36 2025
@author: liguo
"""
#1. 安装依赖(首次运行时启用)
# pip install langchain sentence-transformers faiss-cpu pypdf fastapi uvicorn pydantic dashscope
#2. 导入核心库
import os
import dashscope
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.schema import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
from langchain.llms.base import LLM
from typing import Optional, List, Mapping, Any
from langchain.embeddings.base import Embeddings # 导入LangChain嵌入基类
# --------------------------
# 1. 自定义阿里云DashScope嵌入模型(避免Hugging Face依赖)
# --------------------------
class DashScopeEmbeddings(Embeddings):
def __init__(self, model_name: str = "text-embedding-v2"):
self.model_name = model_name # 阿里云嵌入模型,无需下载
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""为文档列表生成嵌入向量"""
response = dashscope.TextEmbedding.call(
model=self.model_name,
input=texts
)
# 检查响应是否成功(修改部分)
if hasattr(response, 'output') and 'embeddings' in response.output:
return [item["embedding"] for item in response.output["embeddings"]]
else:
raise Exception(f"嵌入模型调用失败: {getattr(response, 'message', '未知错误')}")
def embed_query(self, text: str) -> List[float]:
"""为查询文本生成嵌入向量"""
return self.embed_documents([text])[0]
# --------------------------
# 2. 自定义阿里云DashScope LLM(兼容旧版本LangChain)
# --------------------------
class DashScopeLLM(LLM):
model_name: str = "qwen-plus" # Qwen模型版本
temperature: float = 0.3
max_tokens: int = 512
@property
def _llm_type(self) -> str:
return "dashscope"
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[Any] = None,** kwargs: Any,
) -> str:
if stop is not None:
raise ValueError("不支持stop参数")
# 调用阿里云DashScope API
response = dashscope.Generation.call(
model=self.model_name,
prompt=prompt,
temperature=self.temperature,
max_tokens=self.max_tokens,
**kwargs
)
# 检查响应是否成功(修改部分)
if hasattr(response, 'output') and hasattr(response.output, 'text'):
return response.output.text
else:
raise Exception(f"LLM调用失败: {getattr(response, 'message', '未知错误')}")
@property
def _identifying_params(self) -> Mapping[str, Any]:
return {
"model_name": self.model_name,
"temperature": self.temperature,
"max_tokens": self.max_tokens
}
# --------------------------
# 3. 准备FAQ数据
# --------------------------
faq_data = [
{"question": "公司的工作时间是什么?", "answer": "工作日为周一至周五,上午9:00到下午6:00。"},
{"question": "如何申请年假?", "answer": "通过HR系统提交休假申请,主管审批后生效。"},
{"question": "有没有远程办公政策?", "answer": "支持混合办公模式,每周可在家工作最多两天。"},
{"question": "加班有补贴吗?", "answer": "是的,超过晚上8点的加班可申请调休或加班费。"}
]
# 转换为LangChain Document格式
documents = []
for item in faq_data:
content = f"问题: {item['question']}\n答案: {item['answer']}"
documents.append(Document(page_content=content, metadata={"source": "faq"}))
print(f"共加载 {len(documents)} 条 FAQ 数据")
# --------------------------
# 4. 文本分割
# --------------------------
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
split_docs = text_splitter.split_documents(documents)
print(f"切分后得到 {len(split_docs)} 个文本块")
# --------------------------
# 5. 初始化嵌入模型+FAISS向量库
# --------------------------
# 1. 设置阿里云API密钥(替换为你的真实密钥),系统环境变量中设置DASHSCOPE_API_KEY即可
#DASHSCOPE_API_KEY = "your_actual_api_key_here" # 👉 必须替换!
#dashscope.api_key = os.getenv["DASHSCOPE_API_KEY"] # 显式初始化dashscope
# 2. 使用阿里云嵌入模型(无需下载,直接调用API)
embeddings = DashScopeEmbeddings(model_name="text-embedding-v2")
# 3. 构建FAISS向量库(无网络依赖,本地生成)
db = FAISS.from_documents(split_docs, embeddings)
db.save_local("faiss_index_dashscope") # 保存到本地,下次可直接加载
print("FAISS向量库已保存到本地\n\n")
# --------------------------
# 6. 构建检索器+测试检索
# --------------------------
retriever = db.as_retriever(search_kwargs={"k": 2}) # 返回Top2相关结果
# 测试检索
#query = "怎么请假?"
#docs = retriever.get_relevant_documents(query)
#docs = retriever.invoke(query)
#print("\n检索结果:")
#for i, doc in enumerate(docs):
# print(f"{i+1}. {doc.page_content}\n")
# --------------------------
# 7. 初始化LLM+创建RAG问答链
# --------------------------
llm = DashScopeLLM(
model_name="qwen-plus", # 可选:qwen-turbo(更快更便宜)、qwen-max(更准)
temperature=0.3,
max_tokens=512
)
# 定义RAG提示模板(引导模型使用检索到的上下文)
prompt_template = """严格使用以下上下文回答问题,不要编造信息。如果上下文没有相关内容,直接说"不知道"。
上下文:
{context}
问题: {question}
回答:"""
from langchain.prompts import PromptTemplate
PROMPT = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
# 创建RAG链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 将检索到的上下文"填充"到提示中
retriever=retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": PROMPT} # 传入自定义提示
)
# --------------------------
# 8. 问答函数+测试
# --------------------------
def ask_question(question: str):
print(f"👉 提问: {question}")
response=""
try:
result = qa_chain.invoke({"query": question})
#print(f"✅ 回答: {result['result']}")
response=f"✅ 回答: {result['result']}"
# 显示参考来源
if result["source_documents"]:
response=response + "\n📎 参考来源:\n"
for i, doc in enumerate(result["source_documents"]):
response=response + f" [{i+1}] {doc.page_content.split('答案: ')[-1]}\n"
except Exception as e:
# print(f"❌ 错误: {str(e)}")
return f"❌ 错误: {str(e)}"
return response + ("-" * 50) +"\n"
# 测试单轮问答
print( ask_question("我该怎么申请年假?") )
print( ask_question("上班时间是几点?") )
print( ask_question("可以远程办公吗?") )
print( ask_question("远程办公有什么规定?") )
print( ask_question("那我可以一周在家三天吗?") )
import gradio as gr
def yes_man(query, history):
response = ask_question(query)
return response
gr.ChatInterface(
yes_man,
#type="messages",
chatbot=gr.Chatbot( height=400),
textbox=gr.Textbox(placeholder="请在这里输入你的问题", container=False, scale=5, submit_btn="提交"),
title="欢迎使用RAG问答系统!请问有什么可以帮助您的?",
description="可以问我关于HR方面的问题",
#theme="ocean",
cache_examples=True,
).launch()代码运行结果:
C:\Users\xiayu\miniconda3\envs\langchain03\python.exe "C:\Users\xiayu\PyCharmMiscProject\AI-Agent-Dev-Practices-Code\第10章代码\10.1-LangChain 的完整实现一个简单的 RAG 问答智能体.py"
共加载 4 条 FAQ 数据
切分后得到 4 个文本块
FAISS向量库已保存到本地
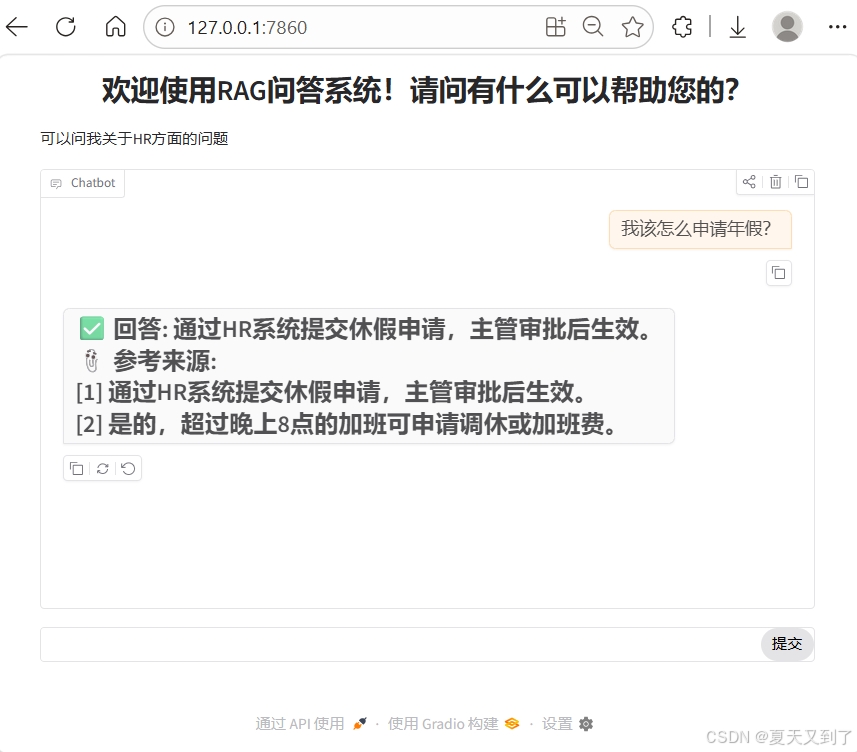
👉 提问: 我该怎么申请年假?
✅ 回答: 通过HR系统提交休假申请,主管审批后生效。
📎 参考来源:
1 通过HR系统提交休假申请,主管审批后生效。
2 是的,超过晚上8点的加班可申请调休或加班费。
👉 提问: 上班时间是几点?
✅ 回答: 上午9:00。
📎 参考来源:
1 工作日为周一至周五,上午9:00到下午6:00。
2 支持混合办公模式,每周可在家工作最多两天。
👉 提问: 可以远程办公吗?
✅ 回答: 支持混合办公模式,每周可在家工作最多两天。
📎 参考来源:
1 支持混合办公模式,每周可在家工作最多两天。
2 通过HR系统提交休假申请,主管审批后生效。
👉 提问: 远程办公有什么规定?
✅ 回答: 远程办公需遵循混合办公模式,每周最多在家工作两天。
📎 参考来源:
1 支持混合办公模式,每周可在家工作最多两天。
2 通过HR系统提交休假申请,主管审批后生效。
👉 提问: 那我可以一周在家三天吗?
✅ 回答: 不可以,每周最多在家工作两天。
📎 参考来源:
1 支持混合办公模式,每周可在家工作最多两天。
2 工作日为周一至周五,上午9:00到下午6:00。
* Running on local URL: http://127.0.0.1:7860
* To create a public link, set `share=True` in `launch()`.
👉 提问: 我该怎么申请年假?
访问网址http://127.0.0.1:7860,界面如下,输入"我该怎么申请年假?",查看效果:
一、整体演示目的(一句话版)
构建一个基于阿里云 DashScope + LangChain + FAISS 的本地 RAG 问答系统,用于 HR FAQ 场景的原型演示。
它的核心目标是:
✅ 不依赖 HuggingFace
✅ 使用国产大模型(通义千问)
✅ 基于自有 FAQ 知识库回答
✅ 防止大模型胡编乱造
✅ 提供 Web 交互界面(Gradio)
二、整体运行流程(高层视角)
用户输入问题
↓
Gradio 接收
↓
ask_question()
↓
RetrievalQA Chain
↓
1️⃣ FAISS 检索相关 FAQ
↓
2️⃣ Prompt 组装(上下文 + 问题)
↓
3️⃣ DashScope LLM 生成答案
↓
返回回答 + 参考来源三、代码逐模块解析
1️⃣ 安装依赖(环境准备)
pip install langchain sentence-transformers faiss-cpu pypdf fastapi uvicorn pydantic dashscope📌 实际作用:
| 包名 | 用途 |
|---|---|
| langchain | RAG 编排框架 |
| faiss-cpu | 本地向量数据库 |
| dashscope | 阿里云 embedding / LLM |
| gradio | Web UI |
| pypdf | (预留)PDF 文档支持 |
⚠️ 说明:
sentence-transformers虽然安装了,但并未使用,你已成功绕开它。
2️⃣ DashScopeEmbeddings(核心:向量化)
class DashScopeEmbeddings(Embeddings):作用
✅ 把文本变成向量
✅ 用于:
-
FAQ 入库
-
用户提问检索
调用关系
FAQ文本 → text-embedding-v2 → 向量 → FAISS关键方法
| 方法 | 用途 |
|---|---|
| embed_documents | FAQ 批量向量化 |
| embed_query | 用户问题向量化 |
✅ 这是整个系统"不依赖 HF"的关键点
3️⃣ DashScopeLLM(大模型接口)
class DashScopeLLM(LLM):作用
✅ 封装通义千问(qwen-plus)
✅ 让 LangChain 把它当成"自己的 LLM"
输入
Prompt(上下文 + 问题)输出
自然语言回答4️⃣ FAQ 数据准备
faq_data = [
{"question": "...", "answer": "..."}
]作用
✅ 模拟企业内部 HR 知识库
✅ 每条 FAQ 转成 LangChain Document
Document(
page_content="问题: ...\n答案: ...",
metadata={"source": "faq"}
)📌 这一步本质是:
结构化知识 → 非结构化文本
5️⃣ 文本切分(RecursiveCharacterTextSplitter)
chunk_size=500
chunk_overlap=50为什么要切?
-
FAQ 本身很短
-
但未来可扩展到:
-
PDF
-
长文档
-
制度文件
-
✅ 这里更多是预留能力
6️⃣ FAISS 向量库构建
db = FAISS.from_documents(split_docs, embeddings)
db.save_local("faiss_index_dashscope")作用
✅ 把所有 FAQ 向量化并存储
✅ 支持快速相似度检索
📌 本质是一个:
本地"语义搜索引擎"
7️⃣ 检索器(Retriever)
retriever = db.as_retriever(k=2)含义
✅ 用户每问一个问题
✅ 从 FAQ 中找 最相关的 2 条
8️⃣ Prompt 模板(防幻觉关键)
严格使用以下上下文回答问题
如果上下文没有相关内容,直接说"不知道"作用
✅ 强制模型:
-
只基于 FAQ
-
不自由发挥
📌 这是 RAG 的灵魂
9️⃣ RetrievalQA 链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
chain_type="stuff"
)这一行做了什么?
✅ 自动完成:
-
用户问题
-
检索 FAQ
-
拼 Prompt
-
调用 LLM
-
返回答案
📌 这就是 LangChain 的核心价值
🔟 问答函数(业务入口)
ask_question(question)功能
✅ 封装:
-
调用 RAG 链
-
打印/返回回答
-
展示参考来源
✅ 非常适合:
-
单元测试
-
后端接口
-
CLI 演示
1️⃣1️⃣ Gradio Web 界面
gr.ChatInterface(yes_man)作用
✅ 把命令行问答升级为:
-
Web 聊天界面
-
可给非技术人员演示
📌 一行代码获得:
-
输入框
-
聊天窗口
-
提交按钮
四、数据流动全过程(示意图)
用户问:怎么申请年假?
↓
Gradio
↓
ask_question()
↓
RetrievalQA
↓
FAISS 检索
→ "如何申请年假?"
↓
Prompt 组装
→ 上下文 + 问题
↓
Qwen LLM
↓
回答 + 来源
↓
Web 页面显示五、这个 Demo 的演示目的总结
| 维度 | 目的 |
|---|---|
| 技术 | 展示 LangChain + 国产模型 RAG |
| 业务 | HR FAQ 自动问答 |
| 架构 | 本地知识库 + 云端 LLM |
| 安全 | 不依赖外网 HF |
| 产品 | 可给领导 / 同事演示 |
| 扩展 | 可接 PDF / 数据库 / 企业微信 |
六、一句话总结
这段代码是一个"工程级 RAG 最小可行产品(MVP)",非常适合作为企业 HR 智能问答系统的第一版原型。