抛开语义相似度:让 Agent 直接搬开向量索引,用 grep 撸原始语料
最近翻 arXiv 看到一篇挺有意思的 paper:《Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction》,作者来自 Texas A&M、Waterloo、UCSD、Stanford、UIUC 这一票学校,外加 Verdent AI、Lambda 几家公司。

标题已经把核心观点透得差不多了------别再围着 retriever 转了,搜索这件事本身就值得重新想一遍。笔者读完觉得挺受启发,下面把这篇论文掰开揉碎讲一讲。
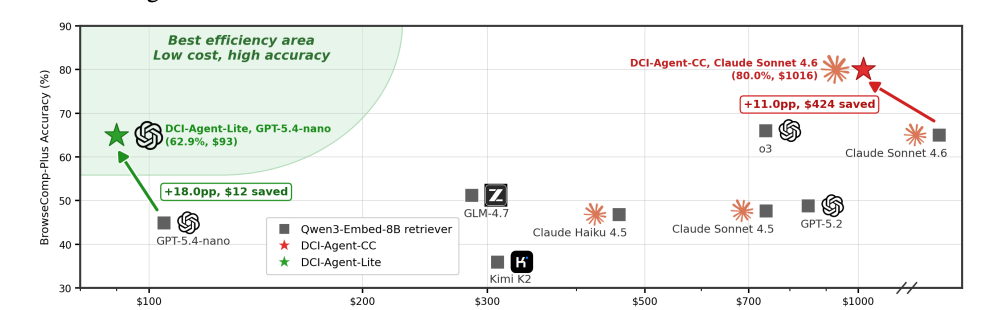
图 1:BrowseComp-Plus 上性能 vs 成本的 Pareto 前沿。蓝色五角星是 Qwen3-Embed-8B 检索器的方案,绿色五角星是这篇论文的两个 DCI-Agent。可以看到右上角性价比那块,DCI 的方案直接把传统 retriever 拍在沙滩上------准确率高 11 个点,成本反而省了 424 刀。
麦克卢汉那句老话又被翻出来了
论文一上来就引了一句麦克卢汉:"The medium shapes and controls the scale and form of human association and action."(媒介本身决定了交互的尺度与形式)
放在 Agent 检索这个语境下,这句话就变成了:Agent 怎么"看到"语料库,决定了它能干什么、不能干什么。
传统那套 RAG 流程大家都熟------文档切块、构 index、走 BM25 或者 dense embedding,每次扔个 query 进去拿回 top-k。这套范式在静态大语料、单轮问答的场景里没啥问题,效率也够。但作者说,问题出在哪儿?出在 Agent 越来越能打了。
像 Search-R1、ASearcher、再到 BrowseComp-Plus 这类新基准里的 deep research 任务,Agent 已经能自己规划、改写 query、多轮搜索了。但不管它再怎么折腾,跟语料库之间始终隔着一层 retriever,每一步只能看到被压缩过的 top-k 切片。这就尴尬了------Agent 有想法,但"眼睛"被限制死了。
举几个 retriever 老大难的场景:要做精确字符串匹配怎么办?要把好几个弱信号叠起来组合查询怎么办?发现一个新线索想立刻在原文里 verify 一下怎么办?这些事情走传统检索接口都很别扭,很多有用的证据在 top-k 之前就被过滤掉了,下游再强的推理也救不回来。
那不如让 Agent 直接 grep?
作者的思路简单粗暴------既然 retriever 是瓶颈,那干脆把这一层拆掉。让 Agent 直接拿 bash、grep、find、cat 这些通用终端工具,对着原始语料库直接撸。
这个思路被命名为 Direct Corpus Interaction(DCI),直译就是"直接语料交互"。
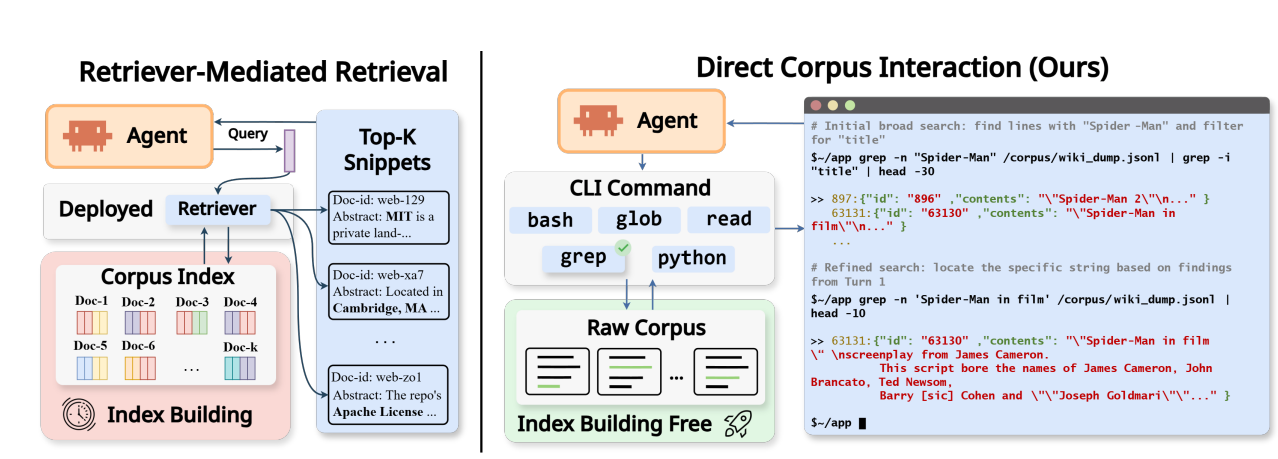
图 2:左边是传统的 retriever-mediated 模式,离线建好 index,Agent 提 query 拿 top-k;右边是 DCI 模式,Agent 直接拿 grep、glob、bash 这些命令在原始语料上操作,没有 embedding 模型,没有向量索引,啥都没有,就一个 shell。
听起来有点反直觉对吧?2026 年了,怎么还在玩 grep?但仔细想想,这件事其实挺合理:
Coding Agent 这一两年已经把 CLI-based 操作玩得很熟了------SWE-agent、Agentless、Claude Code、OpenHands、Aider 这些项目都证明了一件事:grep + read + bash 这套组合拳,对一个够强的模型来说,足以在一个仓库里精确定位、改代码、跑测试。既然写代码能这么干,搜文档为啥不行?
DCI 这套范式的好处也很直白:
- 没有离线建索引的开销,扔个语料过去就能搜
- 天然适应动态语料,文件改了立刻就能搜到,不用重建 index
- 接口分辨率高 ------Agent 可以做
grep 'foo' file | grep 'bar'这种叠加约束,可以grep -n 'keyword' file | head看精确位置和上下文 - 语义理解从 index 下沉到 LLM 自己,模型变强直接吃到红利
两个 Agent 实现:一个轻量,一个全武装
为了对照实验,作者搞了两套 DCI 实现:
DCI-Agent-Lite 是个极简版本,基于一个叫 Pi 的轻量终端编码 agent 改造而来,只给两个工具:bash 和 read。底模用的是 GPT-5.4 nano,reasoning effort 拉满到 high。这个版本的目的是把"接口变化"这个变量隔离干净------没有任何检索专用模块,没有 embedding,没有 reranker,纯靠 shell。
DCI-Agent-CC 则是把 Claude Code 直接拿来当 harness,底模换成 Claude Sonnet 4.6,medium reasoning。这个版本是为了探性能上限------更强的 prompt、更鲁棒的工具编排、内置上下文管理都加上。但要注意,它本质上还是 DCI,没碰任何 retriever 接口。
两个 agent 的 max turn budget 都是 300,给足探索空间。
长 trajectory 怎么不爆 context?
DCI 一个绕不开的问题是------grep 一搜可能几百上千个 match,cat 一个文件可能几万 token,几十轮搜下来 context window 早炸了。
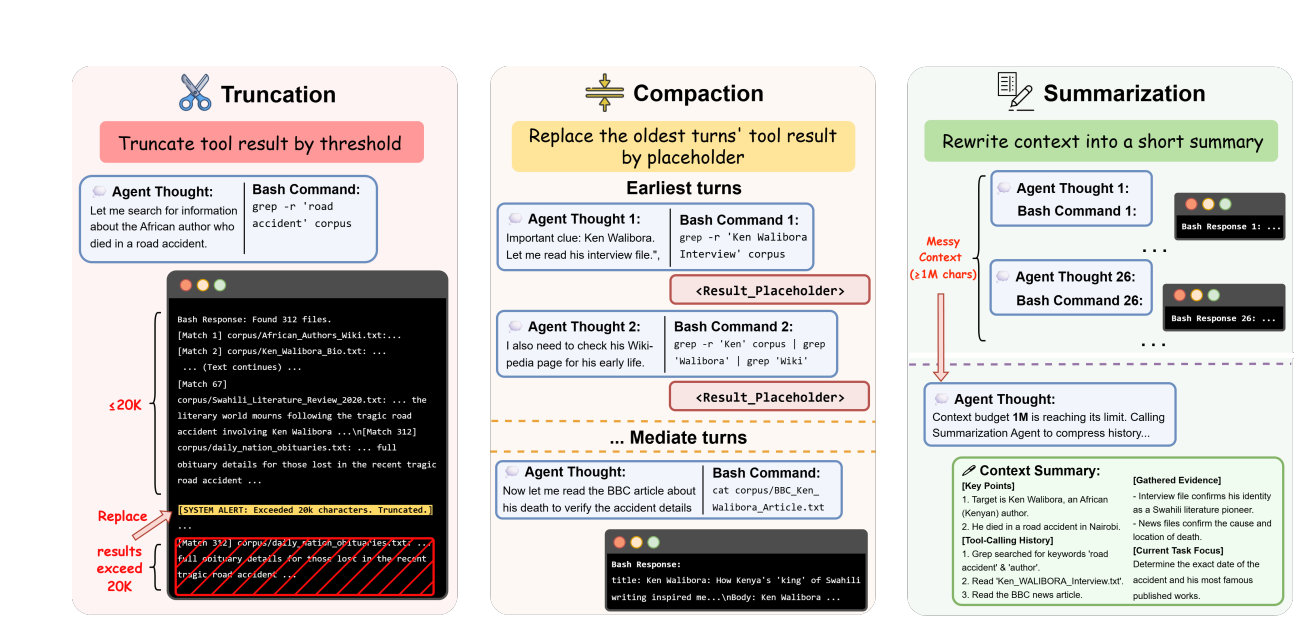
图 3:三种运行时上下文管理策略------截断、压实、摘要。
作者给 DCI-Agent-Lite 配了一套轻量的运行时上下文管理,三个机制叠着用:
截断(Truncation) 是最简单的------每个 tool call 的输出超过一定字符数就截掉,但保留"这个调用发生过"的痕迹。
压实(Compaction) 不需要调 LLM,纯内存操作。当累积 tool 输出超过阈值,就把老旧轮次的 tool result 替换成短占位符,但保留 tool call 的结构骨架。
摘要(Summarization) 是最重的干预------上下文压力还是太大,就让一个摘要 agent 把历史压成一段简短总结,最近几轮原样保留。
这三个机制组合出 L0 到 L4 五档策略,从完全不管到全开。L0 啥都不做,L1 只截断到 50K 字符,L2 截到 20K,L3 加上压实,L4 再叠摘要。
评估别只看准确率,得看 Coverage 和 Localization
光看答题准确率没法说清楚 DCI 和传统检索的差别在哪儿。所以作者引入了两个轨迹级别的指标。
Coverage(覆盖率):这条 trajectory 到底有没有 surface 出 gold document?分三个口径------any(至少碰到一个)、mean(recall,平均碰到几个)、all(全部碰到)。这是个"广度"指标。
Localization(定位精度):surface 到 gold document 之后,能不能在文档内部精准定位到关键证据片段?这是个"深度"指标,反映"够到关键文档之后能不能再往下钻"的能力。
简单说,coverage 测"够没够到",localization 测"够到之后能不能精修"。这两个一组合,DCI 和 retriever 的差异就显形了。
实测结果:把 retriever 按在地上摩擦
作者跑了三类 benchmark:BrowseComp-Plus(agentic search)、6 个多跳 QA(NQ/Trivia/Bamboogle/HotpotQA/2Wiki/MuSiQue)、6 个 IR ranking(BRIGHT 4 个 + BEIR 2 个)。
Agentic Search 这块 ,同样用 Claude Sonnet 4.6 做底模,把 Qwen3-Embedding-8B 这个 retriever 换成 DCI,准确率从 69.0% 干到 80.0%(+11 个点),成本从 1440 刀降到 1016 刀(-29.4%)。DCI-Agent-CC 也直接超过了所有 retrieval baseline,包括最强的 GPT-5 + Qwen3-Embedding-8B 组合(71.7%),高出 8.3 个点。轻量版 DCI-Agent-Lite 跑出 62.9% 准确率,成本只要 93 刀------和 o3 + Qwen3-Embedding-8B(66%)打得有来有回,但成本省了 647 刀。
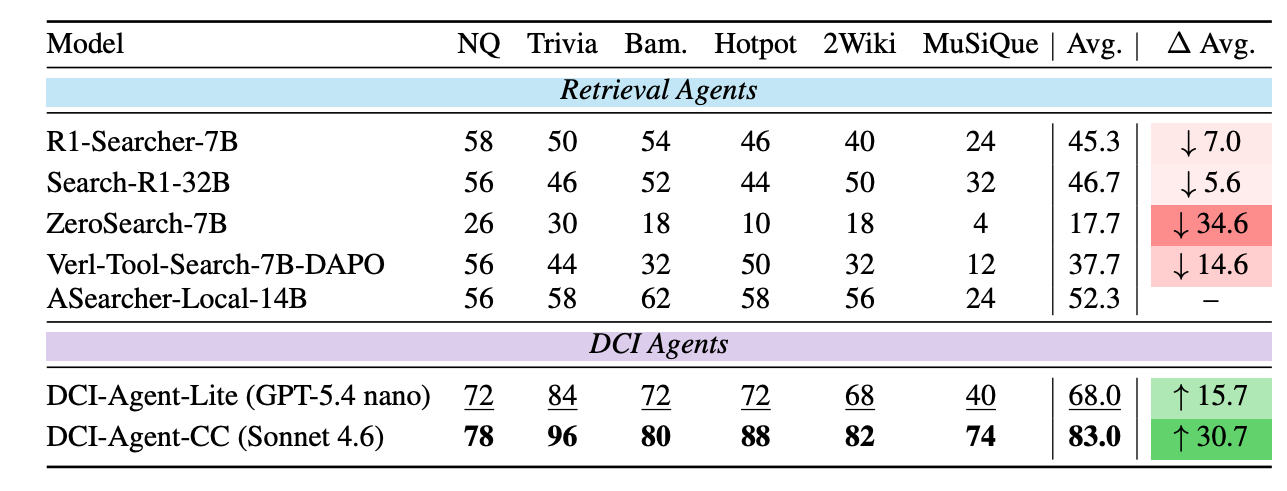
多跳 QA 这块 ,DCI-Agent-CC 平均准确率 83.0%,比最强的 retrieval agent baseline ASearcher-Local-14B(52.3%)整整高了 30.7 个点。最夸张的是难度最高的 MuSiQue,DCI-Agent-CC 拿到 74%,ASearcher 只有 24%------50 个点的差距。HotpotQA 高 30 个点,2Wiki 高 26 个点。轻量版 DCI-Agent-Lite 也有 68%,妥妥第二名。
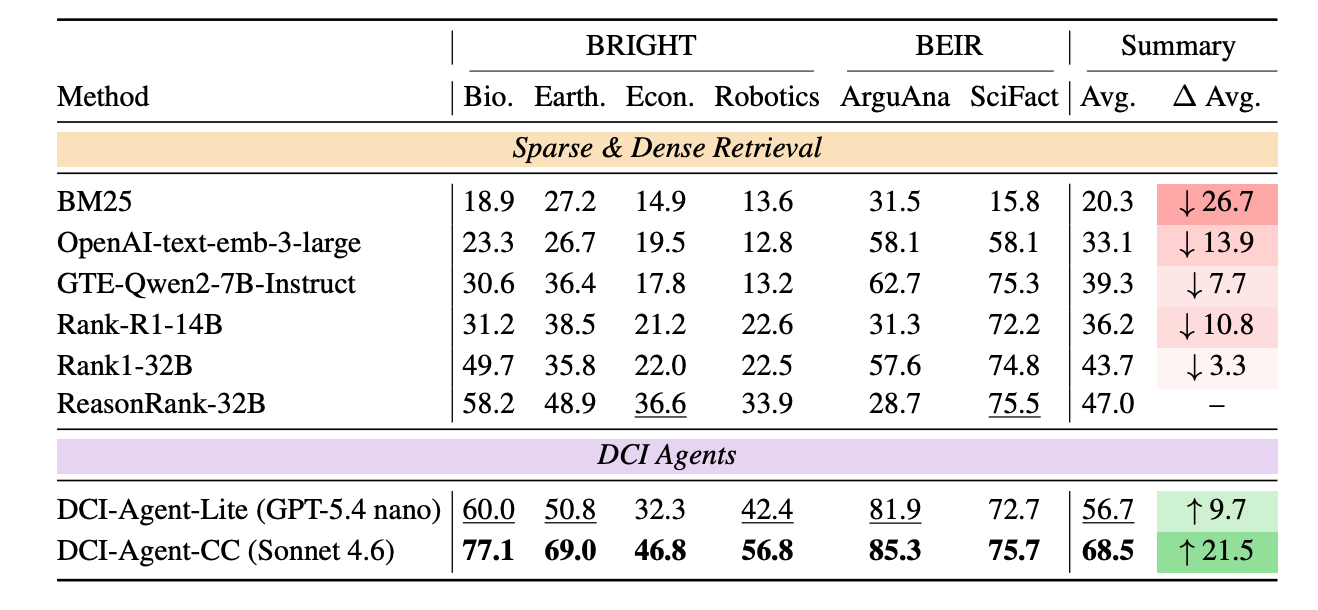
IR ranking 这块就更夸张了,按理说这是 retriever 的主场吧?结果 DCI-Agent-CC 在 6 个数据集上全部夺冠,平均 NDCG@10 干到 68.5,比最强的 ReasonRank-32B(47.0)高了 21.5 个点。Lite 版本 56.7,也比 ReasonRank-32B 高 9.7 个点。
那 DCI 到底赢在哪儿了?
这是论文最有意思的部分------作者花了很大篇幅做控制变量,搞清楚 gain 到底从哪儿来。
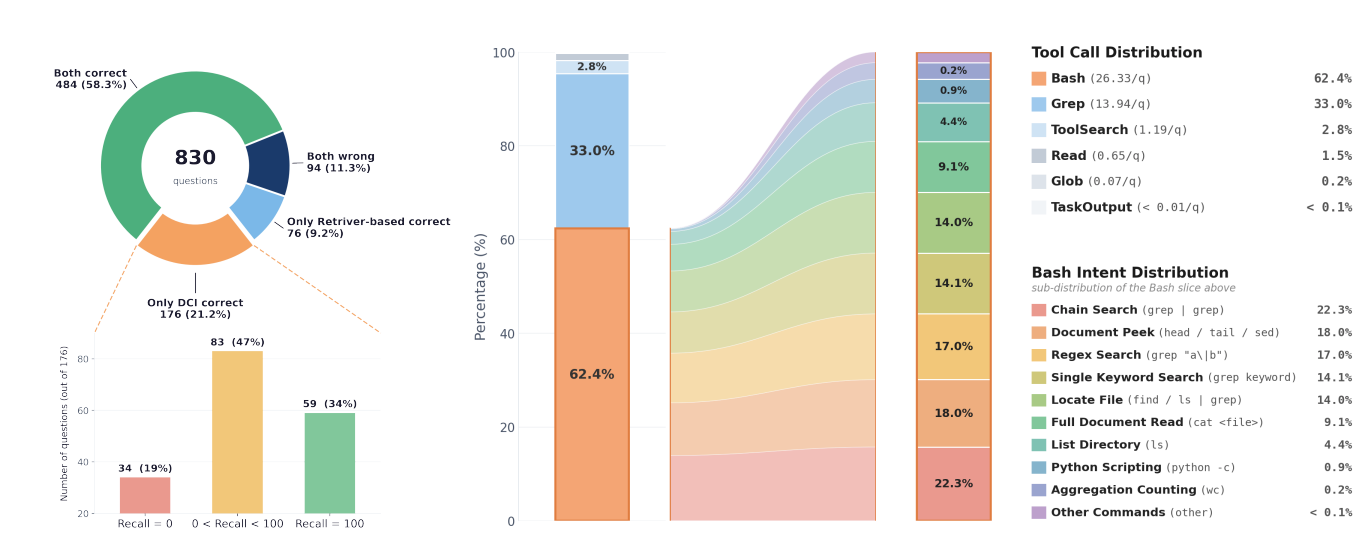
图 4:左边是 BrowseComp-Plus 全部 830 题上 DCI-Agent-CC vs 传统 retriever 的对比,右边是 DCI 调工具的分布------Bash 占 62.4%,Grep 占 33%,剩下零零碎碎。Bash 内部又拆成 chain search、document peek、regex 这些具体意图。
先看 RQ1 之后的反直觉发现:DCI 赢,不是因为它捞到了更多 gold document。
在 100 题的子集上对比,Qwen3-Embedding-8B 的 mean coverage 是 56.7%,DCI-Agent-Lite 只有 28.0%。但 coverage_any(至少抓到一个 gold doc)两者几乎打平(74.0 vs 70.0),而 localization 分数 DCI 是 48.4,retriever 只有 21.7------差了 26.7 个点。
这就说明问题了。BrowseComp-Plus 的题目大部分只有 1-4 个 gold document,DCI 一旦抓到一个有用的文档,立马就能切换模式:从"广撒网"变成"深挖局部"。它放弃了把整条 gold chain 全部捞回来的执念,而是专注于"已经够到的那个文档我能不能榨出更多价值"。
作者把这个现象命名为 retrieval interface resolution(检索接口分辨率)------retriever 给的是"文档级"或者"段落级"分辨率,而 DCI 能给到"字符级"分辨率。Agent 可以精确锁定一行、一句、甚至一个 token 周围的上下文,再据此发起下一轮搜索。
工具使用分布也印证了这点。Bash 命令里头,chain search(grep 套 grep)占了 22.3%,document peek(head/tail/sed 看局部)占 18%,regex search 17%,单关键词 grep 14.1%,find 文件 14%------这些全是"精修"型操作。完整 cat 一个文件只占 9.2%。Agent 在干的事情就是:组合约束、精确匹配、片段验证、按需读取。
不是所有场景都吃这套
作者也很诚实,做了几个 stress test 来划清边界。
RQ4 - 语料规模这道坎:作者把 BrowseComp-Plus 的语料从 100K 文档扩到 200K(注入 FineWeb 的 distractor),然后扩到 400K。
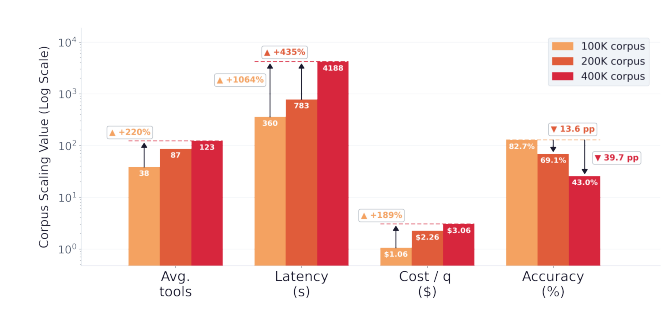
图 5:DCI-Agent-CC 在不同语料规模下的表现------100K 时性价比最优,200K 时工具调用次数从 38.5 涨到 86.9,准确率掉 13.6 个点;400K 时直接崩,准确率掉到 37.5%,平均要调 122.4 次工具,还有 20 题打到 budget 上限。
这个结论挺关键------DCI 在搜索深度上扩展性很好,但在搜索广度上代价陡升。一旦 Agent 找到一个好的"锚点文档",后续操作很高效;但找到第一个锚点的成本,会随候选空间膨胀而急剧上升。所以传统的 dense/sparse 检索在大规模静态语料上仍然有不可替代的价值。
RQ5 - 上下文管理策略到底重要吗:跑了 L0 到 L4 五档对比。结论挺反直觉------更激进的管理不一定更好,呈现明显的非单调曲线。L1 速度最快、保留 gold 证据最多(31.3),但 L3 准确率最高(77)。L2 成本最低但准确率最差(69),L4 加了摘要反而又掉了。
这说明什么?该忘的得忘。完整保留所有证据 ≠ 保留好的工作状态。多步假设修订需要"选择性遗忘",压缩太弱会让 Agent 漂移,压缩太狠又把有用的中间结构丢了。要找那个 sweet spot。
RQ6 - 工具表达力到底贡献了多少:这个 ablation 很狠。作者把 DCI-Agent-Lite 的工具削到只剩 read + grep(连 bash 管道都不给),看看还能不能打。
结果是------能打。read + grep 跑出 61% 准确率,仍然比 Qwen3-Embedding-8B 的 retriever(45%)高 16 个点,工具调用次数还差不多。完整 bash 工具集再多 12 个点,但工具用量、延迟、算力都翻倍。
所以最核心的 gain 来自接口本身的变化,而不是 bash 多么花哨。一个最小工具集就能撬动大部分提升。
扒一扒代码:薄薄一层 Python 套在 Pi 上面
RQ6 那段说"最小工具集就够用",那这个最小工具集到底长啥样?光看 paper 不过瘾,笔者顺手把仓库 clone 下来扒了一遍(github.com/DCI-Agent/DCI-Agent-Lite),结果发现整套东西的工程实现比想象中要"轻"很多------总共 87% Python + 13% Shell,目录结构也清清爽爽。
整体架构:DCI-Agent-Lite ≈ Pi + 上下文管理补丁 + 评测脚手架
先讲个反直觉的事------DCI-Agent-Lite 自己的 Python 代码量很少,它本质上是一个胶水层 。真正干活的 agent 内核是 Pi,一个由 Earendil 团队开发的极简终端编码 agent(用 TypeScript 写的,npm 装)。
仓库目录结构大致是这样:
DCI-Agent-Lite/
├── src/dci/ # Python CLI 包装层(dci-agent-lite 入口)
├── prompts/ # 任务模板和评测 prompt
├── scripts/ # 数据下载 + benchmark 跑分脚本
├── setup.sh # 一键装环境
└── pyproject.toml # uv 管理 Python 依赖注意 setup.sh 里有一步是去 clone jdf-prog/pi-mono(论文一作 Dongfu Jiang 的 fork)的 codex/context-management-ablation 分支,然后 npm run build。也就是说,作者把 Pi fork 了一份,在上面打了"上下文管理 ablation"的补丁------论文里 L0 到 L4 那五档策略,就是这个补丁实现的。Lite 这边的 Python 代码主要负责:参数透传、调起 Pi 进程、收集输出、保存 trajectory。
为啥选 Pi 当底座
Pi 的设计哲学跟 DCI 简直是绝配------Pi 官网那句 slogan "There are many agent harnesses, but this one is yours"已经说明问题。具体看几个关键属性:
极简的 system prompt。Pi 的默认 system prompt 短到出乎意料,没有那些"你是一个有用的助手"之类的废话,给 token 留足空间。这对长 trajectory 的 deep research 场景特别关键。
只有少数原生工具,bash 是核心 。Pi 不像 Claude Code 那样自带一堆 Read/Grep/Glob/Edit/Task 工具,它就给你一个 bash + 一个 read,剩下的全靠你自己拼 shell 命令。这正好是论文 RQ6 想验证的------最小工具集就够用。
内置 compaction 机制。Pi 默认会在接近 context limit 时自动把老旧消息摘要成短文本。作者在 fork 里把这个机制扩展成了可调档的 L0-L4 策略。
没有花哨功能。没有 sub-agents、没有 plan mode、没有 MCP------这些都是 Pi 故意"砍掉"的,都靠 extension 自己加。这种"砍到见骨"的风格让作者很容易做控制实验:能确定性能差异不是 harness 引入的噪声。
跑起来到底是个啥流程
最小可运行的命令长这样:
bash
uv run dci-agent-lite \
--provider openai \
--model gpt-5.4-nano \
--cwd "corpus/wiki_corpus" \
--extra-arg="--thinking high" \
--extra-arg="--context-management-level level3" \
"用当前目录下的 wiki_dump.jsonl 回答:伦敦大火起源于哪条街?用 rg 不要用 grep。"拆开看关键参数:
--cwd "corpus/wiki_corpus" 是个重点------Agent 的工作目录就是语料目录 。Pi 启动后 bash 的 pwd 直接指向 wiki_dump.jsonl 所在的文件夹。Agent 后续所有 rg、find、cat 都在这里跑,相当于让模型"住进"了语料库里。这个设计跟论文里"agent operates directly within the environment it is reasoning over"那句话完美对上。
--extra-arg="--thinking high" 透传给 Pi,再透传给 OpenAI 的 reasoning effort。GPT-5.4 nano 的便宜 + 高 thinking effort 是这个 lite 版本能打的关键配方。
--extra-arg="--context-management-level level3" 就是论文里 Table 1 那五档策略的开关,level3 是默认值(截断 + 压实,不开摘要)。
User prompt 里那句 "Use rg instead of grep for fast searching" 看起来像废话,其实是个工程细节------rg(ripgrep)比 grep 快一个量级,对百万文档的语料几乎是必需的。setup.sh 里也专门装 ripgrep。
Trajectory 是怎么落盘的
跑完之后,agent 会把整个搜索过程序列化到 outputs/runs/<timestamp>/ 下面:
question.txt--- 原始问题final.txt--- 最终答案conversation_full.json--- 完整对话历史,每一轮的 thought、bash command、tool result 全在里面
这个 JSON 就是论文里做 trajectory 分析的原料------RQ2 那张 tool 分布图(grep 33%、bash chain search 22.3% 等等),就是从这种 JSON 里解析出来的。也是为啥论文能那么细粒度地拆解 agent 在干啥。
上下文管理那一层到底怎么实现的
这是工程上最值得说道的地方。论文里画了三种机制(截断/压实/摘要),但落到 Pi 这种 agent loop 里具体是怎么挂上去的?根据 Pi 的扩展机制(extensions 可以"在每轮之前注入消息、过滤消息历史")和作者打的补丁,大致可以推断:
截断 发生在 tool result 写入 message 历史之前------bash 跑完,原始输出可能几万字符,截断逻辑根据 level 的阈值(L1 是 50K,L2-L4 是 20K)卡掉多余部分,给模型看的就是截断后的版本。这个对 token 消耗影响最大。
压实 是"in-memory, zero-LLM operation"------纯结构化操作,不调模型。一旦累积 tool 输出超过 240K 字符(L3 的阈值),就把"除最近 12 轮以外"的老旧 tool result 替换成 <Result_Placeholder> 占位符,但 tool call 本身的结构("曾经调过 grep xxx")还保留着。这样 agent 知道自己干过什么,但不再背着那些已经消化过的原文。
摘要是 L4 才启用的重型操作------压实之后如果估算 token 还是超阈值,就调一次 LLM 把压实后的历史压成一段简短总结,最近 20K token 原样保留。论文还提到一个细节:连续三次摘要失败就放弃,避免死循环。
这三层从轻到重叠加,配合论文 RQ5 那个非单调结论(L3 最优、L1/L4 次之、L2 最差),其实就把一件事讲清楚了------该忘什么、什么时候忘、怎么忘,本身就是工程问题,没法靠"压得越狠越好"这种朴素直觉解决。
为啥这套东西能跑出 62.9%
把上面这些拼起来,DCI-Agent-Lite 能在 BrowseComp-Plus 上干掉 GPT-5.2 + retriever 的方案(用的还是便宜的 GPT-5.4 nano),笔者觉得是这几个因素叠出来的:
一是 Pi 的 system prompt 极简,token 不浪费在"自我介绍"上。二是工作目录直指语料,agent 不需要费力学一套自定义的 retrieval API,它本来就会用 bash。三是 context 管理把长 trajectory 的爆炸问题压住了,300 turn budget 才有可能不爆。四是 GPT-5.4 nano 的 high reasoning effort + ripgrep 的速度让"边搜边想"这个循环跑得起来。
最后一个特别打动笔者的点是------这玩意儿真的可以直接对着自己电脑里的文档跑 。仓库 README 那句"Your private deep-research assistant"不是营销话------不需要给任何云服务上传文档、不需要装 vector DB、不需要等几个小时跑 embedding。uv run dci-agent-lite --cwd ~/my-papers/,开干。这种"开箱即用"对个人知识库场景吸引力相当强。
笔者的几点感受
读完这篇 paper、又把代码扒了一遍,笔者觉得它真正有价值的不是某个具体数字,而是把"检索"这件事重新框定成了一个 接口设计问题,而不仅是 retriever 设计问题。
过去十年的检索研究基本都在卷模型------更好的 sparse 算法、更强的 dense embedding、更聪明的 reranker。但如果 Agent 自己已经能像研究者一样思考------提假设、验证字符串、读上下文、改 query------那压缩成相似度向量这一层反而成了瓶颈。给它一个更高分辨率的接口,让它自己处理语义,整体表现可能反而更好。
当然这套范式也有清晰的边界:
- 大规模静态语料(千万级文档以上)依然是 dense retriever 的天下
- 对底模能力要求很高,弱模型扛不住长 trajectory 的复杂搜索
- 成本结构变了------从"一次性建 index 的固定成本"变成"每次搜索的边际成本",对于高 QPS 服务不见得划算
- 评估指标得更新------光看 recall@k 已经不够了,得看 trajectory 级的 localization
但反过来说,在那种本地、异构、动态变化的 agentic workspace 里------比如开发者本地的代码库、企业内部不断更新的文档、研究者电脑里散落的 PDF------DCI 这套范式是真有竞争力的。不用建索引,文件改了立刻能搜,Agent 直接在它推理的那个环境里操作,体感会非常顺。
而且 GitHub 上 Anthropic 这一年推 Claude Code、推 agent skills,整个 agent 工具链都在往这个方向走------把 LLM 直接放到 shell 里、放到文件系统里、放到真实环境里。从这个角度看,DCI 几乎是水到渠成的产物。
下一步值得追一下的方向,笔者觉得有几个:DCI 怎么和传统检索做混合(比如先 dense 召回粗筛,再 grep 精修);怎么给 DCI 加缓存层降低重复搜索的成本;以及更轻量的 base model(7B/14B 那一档)能不能也吃到这套范式的红利。
仓库目前 9 个 star、1 个 fork,论文是上周刚挂 arXiv 的(2605.05242),整个项目还很早期。但笔者觉得这套思路值得追------它的工程门槛低到几乎所有人都可以复现一遍,跑跑自己的 PDF、自己的 Notion 导出,看看效果到底如何。比读 paper 有趣多了。