当我们执行一条简单的 UPDATE t SET name = 'new' WHERE id = 1;时,MySQL内部究竟发生了什么?这个过程远比我们想象的要复杂和精妙。它不仅涉及数据的修改,更关系到数据库的核心特性:性能、持久性和事务。
下面,就让我们一同深入MySQL InnoDB存储引擎的心脏,揭开UPDATE语句的神秘面纱。
一、 核心流程总览
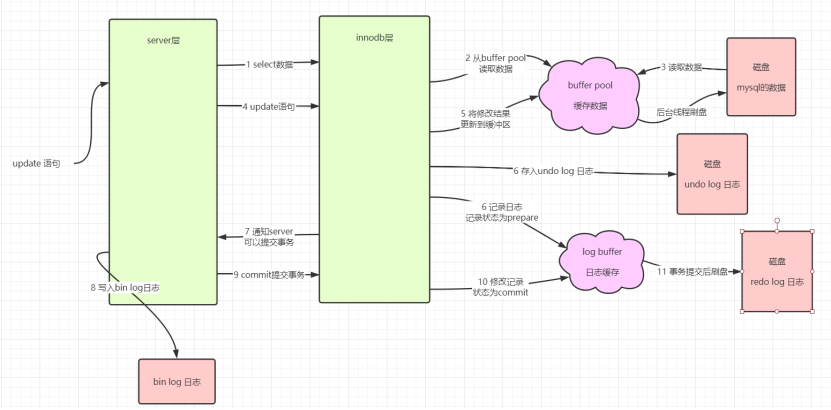
与SELECT语句类似,UPDATE也需要经历连接器、分析器、优化器、执行器这几层。但最关键的不同在于存储引擎层的处理。一个简化的UPDATE核心流程如下:
-
执行器通过优化器选定的计划,调用InnoDB引擎的接口。
-
引擎 首先检查内存缓冲池(
Buffer Pool)中是否有所需的数据页。如果没有,则从磁盘加载到Buffer Pool中。 -
执行器获取到数据行,进行修改(将内存中的
name字段改为'new')。 -
引擎 先将本次更改记录到
Redo Log(重做日志),并置于prepare状态。 -
引擎 将本次更改的旧值记录到
Undo Log(回滚日志),用于事务回滚和MVCC。 -
执行器通知引擎,事务可以提交。
-
引擎 将
Redo Log的状态置为commit。 -
Server层 记录本次更改的逻辑日志
Binlog(二进制日志)。 -
执行器收到完成通知,返回给客户端。
-
后续由后台线程,在合适的时机将
Buffer Pool中的"脏页"刷新到磁盘数据文件。
核心思想 :WAL(Write-Ahead Logging,预写式日志) 和 两阶段提交。先写日志(Redo Log),再在后台刷数据。这极大地提升了数据库的吞吐量和崩溃恢复能力。
接下来,我们重点剖析其中几个关键组件。
二、 核心组件详解
1. Buffer Pool:加速的基石
Buffer Pool是InnoDB在内存中开辟的一块核心区域,用于缓存数据和索引页。所有数据的读写都优先在Buffer Pool中进行,从而避免每次操作都直接访问慢速磁盘。
-
工作单元:以"页"(Page,默认16KB)为单位进行读写。
-
脏页(Dirty Page) :在内存中被修改但尚未刷回磁盘的数据页,称为"脏页"。InnoDB有专门的后台线程(如
Page Cleaner Thread)负责将脏页写回磁盘。 -
刷新策略 :由参数
innodb_max_dirty_pages_pct等控制。当脏页比例超过阈值时,会触发更积极的刷盘,防止脏页堆积影响正常读写。
sql
-- 查看Buffer Pool大小(默认128M)
SHOW VARIABLES LIKE 'innodb_buffer_pool_size';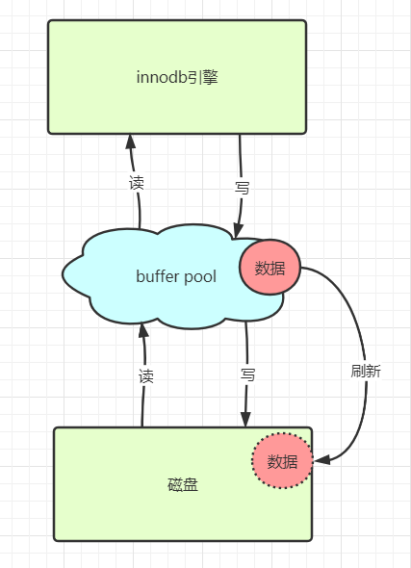
2. Redo Log:崩溃恢复的保证
问题 :如果数据在Buffer Pool中修改后,数据库突然崩溃,内存中的数据丢失,岂不是永久性丢失了?
解决方案 :Redo Log。它是一种物理日志,记录的是"在某个数据页上做了什么修改"。
-
目的 :确保事务的持久性(Durability)。即使发生宕机,重启后也能根据Redo Log重新"重做"这些修改,恢复数据。
-
写入方式 :顺序追加写入。相比于更新数据时可能产生的随机IO,顺序IO的效率极高,这是WAL技术性能优势的关键。
-
组成 :通常由两个固定大小的文件(如
ib_logfile0,ib_logfile1)循环写入。 -
刷盘策略 :由关键参数
innodb_flush_log_at_trx_commit控制:-
=1(默认):每次事务提交都刷盘。最安全,性能相对较低。
-
=0:每秒刷盘一次。性能好,但宕机可能丢失1秒数据。
-
=2:每次提交只写入操作系统缓存,每秒刷盘。性能折中,操作系统宕机仍会丢数据。
-
sql
-- 查看Redo Log相关配置
SHOW VARIABLES LIKE '%innodb_log%';
SHOW VARIABLES LIKE 'innodb_flush_log_at_trx_commit';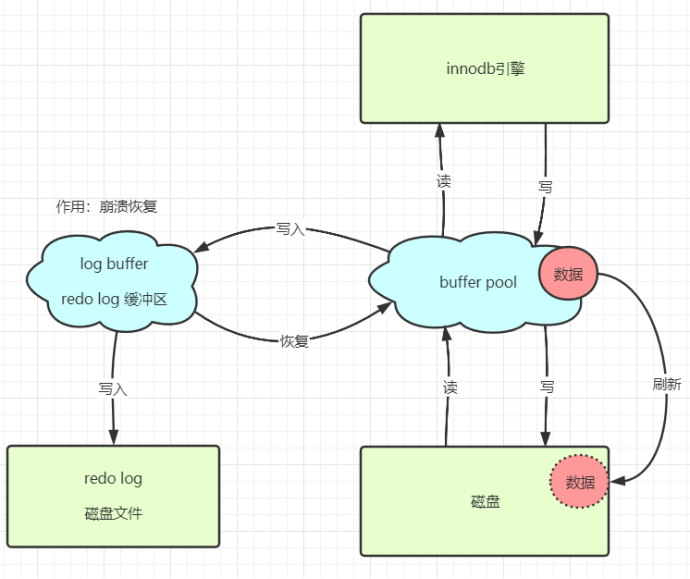
3. Undo Log:回滚与MVCC的支柱
Undo Log是逻辑日志,记录与事务操作相反的内容(例如,UPDATE操作会记录被修改行的旧版本数据)。
-
目的:
-
实现事务回滚 ,保证事务的原子性(Atomicity)。如果事务需要回滚,引擎可以用Undo Log中的记录将数据恢复到事务前的状态。
-
实现MVCC(多版本并发控制) 。这是实现
READ COMMITTED和REPEATABLE READ隔离级别的关键。当一个旧事务需要读取数据时,InnoDB会根据Undo Log链构建出该事务开始时的数据快照(ReadView),从而实现非锁定的一致性读。
-
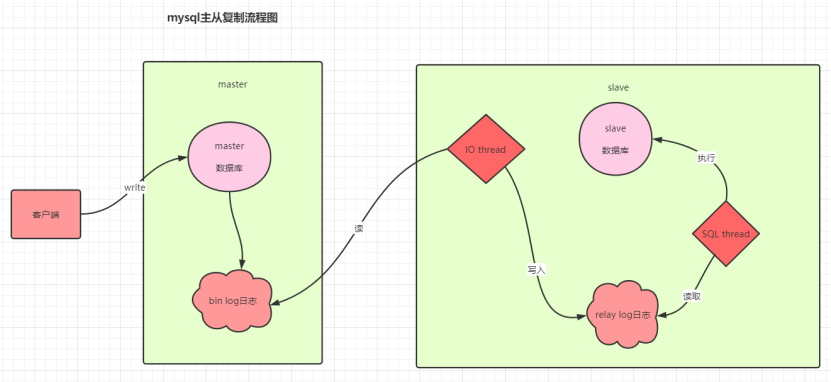
4. Binlog:归档与复制的桥梁
Binlog(二进制日志)是Server层实现的逻辑日志,记录所有引起数据变更的SQL语句(或行的变更前/后内容)。
-
目的:
-
主从复制(Replication):从库(Slave)通过拉取和应用主库(Master)的Binlog来实现数据同步。
-
数据恢复:可以用于基于时间点的数据恢复(PITR)。
-
-
与Redo Log的区别:
-
层级:Redo Log是InnoDB引擎层,物理日志;Binlog是Server层,逻辑日志。
-
内容:Redo Log记录"如何修改页面";Binlog记录"语句的原始逻辑"。
-
写入时机 :在事务提交过程中,通过两阶段提交协议与Redo Log协同,确保两者逻辑一致。
-
三、 UPDATE完整流程串联(以默认设置为例)
假设我们执行 UPDATE t SET name = 'B' WHERE id = 1;,且name原值为'A'。
-
发起请求:客户端通过连接发送SQL。
-
Server层处理:经过连接、解析、优化,执行器决定调用InnoDB接口。
-
引擎取数据 :InnoDB根据id=1查找数据页。页不在
Buffer Pool则从磁盘读入。 -
写Undo Log :在修改内存数据前,先将
id=1, name='A'这条记录写入Undo Log,形成版本链。 -
修改内存数据 :将
Buffer Pool中对应数据行的name改为'B'。该页标记为脏页。 -
写Redo Log :将"在页P中,将id=1的行,name字段改为'B'"这个操作写入Redo Log Buffer,并将日志状态标记为
prepare。 -
通知Server层:执行器告知引擎,准备就绪。
-
写Binlog:Server层将本条UPDATE语句的逻辑写入Binlog文件。
-
最终提交:执行器调用引擎的提交接口。
-
两阶段提交-第二阶段 :引擎将刚才写入的Redo Log记录状态更新为
commit。 -
返回结果:引擎返回成功,执行器通知客户端更新完成。
-
后台刷盘:此后某个时刻:
-
Binlog会被轮转或归档。 -
Redo Log中的记录在被覆盖前,其对应的脏页会被后台线程持久化到表数据文件(.ibd)中。 -
如果系统非常繁忙,脏页也可能在事务提交前就被刷新。
-
四、 总结与启示
一条UPDATE语句,实际上是数据库核心机制的一场协同演出:
-
Buffer Pool 用空间换时间,承担加速重任。
-
Redo Log 是忠诚的卫士,用顺序IO保证持久性与性能。
-
Undo Log 是时光机和多面手,支撑了回滚和MVCC。
-
Binlog 是档案馆和信使,负责归档和主从同步。
理解这个过程,对于优化数据库性能 (如合理设置Buffer Pool大小、Redo Log文件大小和刷盘策略)、理解事务隔离级别 、以及进行数据恢复和主从架构设计都具有重要意义。它让我们明白,数据库的可靠与高效,正是建立在这样一套精巧而严谨的架构之上。