深入解析 RAG (检索增强生成):从原理到 Python 实战
在大型语言模型(LLM)迅速发展的今天,我们常常会遇到模型"一本正经地胡说八道"或者无法获取最新内部数据的窘境。为了解决这些问题,RAG(Retrieval Augmented Generation,检索增强生成) 技术应运而生。本文将带你从 RAG 的核心概念、工作流程、代码实战,一路深入到系统的难点优化与评估方法。
一、什么是 RAG?
RAG 为生成式模型搭建了与外部世界交互的有效通路 。它的核心作用类似搜索引擎:先检索出与用户提问高度相关的知识或对话历史,再结合原始提问构造信息丰富的 prompt,从而引导模型输出精准结果 。我们可以将其本质简化理解为:RAG = 检索技术 + 大语言模型 ICL 提示 。
1. 为什么我们需要 RAG?(大模型的局限性)
尽管大语言模型能力强大,但它依然存在一些固有的短板:
知识局限性:模型知识完全源自训练数据,主流大模型训练集多基于公开网络数据,对实时性、非公开或离线数据无法覆盖,导致这类知识缺失 。
幻觉问题:AI 模型底层基于数学概率运算输出结果,当模型缺乏某领域知识或不擅长对应场景时,可能一本正经输出错误内容(即幻觉),且使用者若无该领域知识将很难区分 。
数据安全性:将企业私域数据上传至第三方平台进行训练存在泄露风险,纯依赖通用大模型会在数据安全与应用效果间妥协,从而限制了落地场景 。
2. RAG 的核心作用
RAG 通过"检索+生成"模式弥补了上述短板,具备以下特性:
外接外部数据优势:可深度接入外部数据库资源,弥补模型在垂直专业领域和时效性上的短板,输出更精准的答案 。
数据隐私安全保障:连接的私有数据库不参与大模型集中训练,既能提升输出质量,又能避免敏感信息流入大模型训练流程 。
效果受多因素影响:RAG 的表现与语言模型性能、输入数据质量、算法设计及检索系统架构强相关,需针对性优化 。
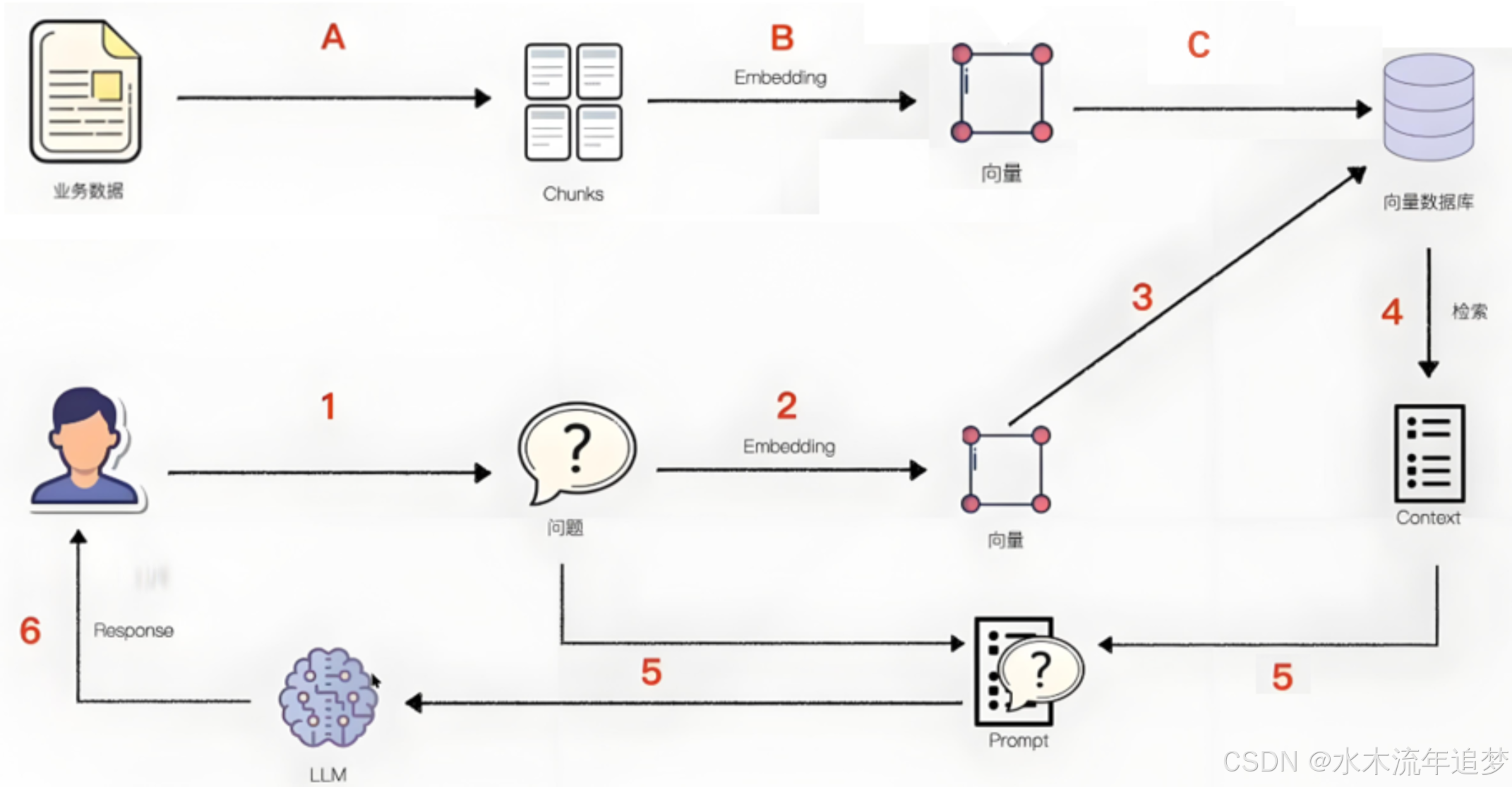
二、RAG 的标准工作流程
一个标准的 RAG 系统通常包含以下几个关键步骤:
1. 文档准备与数据分块 (Chunking)
构建 RAG 的首要步骤是准备知识文档,包括 Word、TXT、CSV、PDF、图片或视频等 。首先需要通过 PDF 提取器或 OCR 技术将这些多元知识源统一转化为模型可理解的纯文本数据 。
随后,因为大模型能接受的输入长度有限,需要对长篇内容进行切片(数据分块) 。常用的分块方法包括:
依据文档结构:按章节、标题、段落等进行分块(如 Markdown 层级切分) 。
固定大小分块:按固定字符/单词/token 数切分,并设置重叠(Overlap)以保留上下文连贯性 。
语义切分:按段落切分后,利用 embedding 模型转化为向量,再使用聚类算法将语义相关的片段进行合并或调整 。
2. 文本向量化 (Embedding)
文本向量化是实现问题与文档检索匹配的核心前提 。常用的模型有 BGE、Qwen3 Embedding、xiaobu Embedding 等 。
问题侧向量化:用户提问后,先通过 Embedding 模型对问题进行处理 。
文档侧向量化:知识文档分块后,需对每个文本块单独进行向量化 。
3. 向量数据库与检索
经过 Embedding 的向量会被批量存入专门用于存储和检索向量数据的系统(如 Milvus、Faiss、Chroma 等)中,作为 RAG 的知识底座 。
在实际检索时,通常结合以下两种技术快速定位匹配内容:
关键字搜索:如 BM25 算法 。
向量检索:如 ANN(近似最近邻)检索算法 。
4. 组装 Prompt 与 LLM 生成
使用 In-Context Learning 技术,将问题背景、用户问题以及检索到的相关文本拼接成一个 Prompt,最后输入大模型获取最终回答 。
三、动手实现简易 RAG 系统
以下是一个 RAG 处理流程的 Python 实现演示(支持 PDF 问答),包含了文档提取、向量化、双路召回(BM25+Embedding)与大模型生成的完整链路。
python
import PyPDF2
from rank_bm25 import BM25Okapi
import jieba
from sentence_transformers import SentenceTransformer
import json
import requests
# 1. 词嵌入模型加载
xiaobu_embed_model = SentenceTransformer('/xxx/maple77/xiaobu-embedding-v2')
# 2. PDF 文本提取
def pdf_to_text(pdf_path):
pdf2word_page = []
with open(pdf_path, 'rb') as pdf_file:
pdf_reader = PyPDF2.PdfReader(pdf_file)
for page_num in range(len(pdf_reader.pages)):
page = pdf_reader.pages[page_num]
pdf2word_page.append({
'page': 'page_' + str(page_num + 1),
'content': page.extract_text()
})
return pdf2word_page
# 3. BM25 关键字检索
def bm25_search(question_text, bm25_model):
doc_scores = bm25_model.get_scores(jieba.lcut(question_text))
scores_dict = {pos: soc for pos, soc in enumerate(doc_scores)}
# 过滤掉 0 分的并倒序排序
scores_dict_filter = dict(filter(lambda x: x[1] != 0, scores_dict.items()))
if scores_dict_filter:
sorted_scores = sorted(scores_dict_filter.items(), key=lambda item: item[1], reverse=True)
return [idx for idx, score in sorted_scores[:10]]
else:
return []
# 4. 向量化计算与检索
def xiaobu_model(pdf2word_page):
pdf_content_sentences = [x['content'] for x in pdf2word_page]
return xiaobu_embed_model.encode(pdf_content_sentences, normalize_embeddings=True)
def xiaobu_model_search(question_text, pdf2word_page):
pdf_embeddings = xiaobu_model(pdf2word_page)
question_embeddings = xiaobu_embed_model.encode(question_text, normalize_embeddings=True)
score = question_embeddings @ pdf_embeddings.T
return score.argsort()[::-1][:10]
# 5. 多路召回融合排序 (Fusion Sort)
def fusion_sort(m3e_top, bm_top):
fusion_score = {}
k = 60
for idx, q in enumerate(bm_top):
fusion_score[q] = fusion_score.get(q, 0) + 1 / (idx + k)
for idx, q in enumerate(m3e_top):
fusion_score[q] = fusion_score.get(q, 0) + 1 / (idx + k)
return sorted(fusion_score.items(), key=lambda item: item[1], reverse=True)
# 6. 大模型请求与 Prompt 组装
def LLM_chat(query, studentbook_content=[]):
if not studentbook_content:
return "未提供相关资料"
content = {
"model": "qwen2.5:14b",
"stream": False,
"messages": [
{"role": "system", "content": "你是专家,请遵循原则,基于提供的资料回答问题。"},
{"role": "user", "content": f"仔细阅读以下内容:{studentbook_content}\n请回答问题:{query}"}
]
}
url = 'http://xxxxxxxx' # 替换为你的大模型 API
result = requests.post(url, data=json.dumps(content))
data = result.content.decode('utf-8')
return json.loads(data)['message']['content'](注意:以上代码并非工业级别实现,主要用于演示原理。实际生产环境中建议使用 Elasticsearch 等专业引擎处理检索和倒排索引,并引入停用词筛选及更精细的 PDF 解析工具 。)
四、RAG 的落地难点与优化方向
1. RAG 的核心难点
在实际业务落地时,RAG 面临诸多挑战:
知识向量库的建立:需要应对多种数据文件类型的差异化切分逻辑;chunk-size 和 overlap 会直接影响检索的颗粒度;向量化工具和 embedding 模型是否需要微调也需要精细权衡 。
检索准确度与用户提问质量:模糊的提问会大幅拉低检索效率。因此,系统需要具备"问题转换能力",通过语义理解和意图拓展将劣质提问转化为高质量查询 。同时还需要优化向量数据、召回和重排环节 。
2. 进阶优化方向
为提升 RAG 的表现,业界通常在以下几个方向发力:
-
多模态 RAG(处理图文音视频)
-
文本块/图片/视频的结构解析提取
-
不同检索方法与模型的混合使用
-
检索倒排索引
-
多路召回规则设计
-
重排序(Rerank)模型引入
五、如何科学评估 RAG 的检索能力?
由于用户的输入与开源大模型的输出都有一定不可控性,RAG 评估的核心重点在于检索环节(即能否把答案所在的文本准确找出来) 。以下是三种主流的检索评估指标:
1. MRR (Mean Reciprocal Rank, 平均倒数排名)
用于衡量搜索引擎返回结果的相关性与排序质量,本质是首个相关结果排名的倒数均值 。
公式 :MRR=1Q∑i=1Q1riMRR=\frac{1}{Q}\sum_{i=1}^{Q}\frac{1}{r_{i}}MRR=Q1∑i=1Qri1,其中 QQQ 是查询总数,rir_iri 是第 iii 个查询中首个相关结果的排名 。
意义:MRR 越高,说明系统越能将相关度高的内容排在前面(如首位),用户体验更优,无需下滑即可看到答案 。
2. Hits Rate (命中率 / Precision@K)
描述前 K 个召回结果中包含正确信息的比例,用于评估系统的精准度 。
公式 :Precision@K = 前K个召回结果中相关文档数量前K个召回结果总数\frac{\text{前K个召回结果中相关文档数量}}{\text{前K个召回结果总数}}前K个召回结果总数前K个召回结果中相关文档数量 。
意义:量化有限召回结果命中相关内容的能力,指导开发者调整召回规则和过滤噪声 。
3. NDCG (归一化折损累计增益)
用于精准评估检索和推荐系统的排序质量。它考虑到靠前的推荐项对用户价值更大,通过对数函数进行位置折现 。
DCG 公式 :DCGk=∑i=1krel(i)log2(i+1)DCG_{k}=\sum_{i=1}^{k}\frac{rel(i)}{log_{2}(i+1)}DCGk=∑i=1klog2(i+1)rel(i) 。
NDCG 公式 :NDCG=DCGIDCGNDCG=\frac{DCG}{IDCG}NDCG=IDCGDCG(利用理想情况下的 IDCG 进行归一化) 。
意义:值越接近 1,反映系统排序与"用户需求"的契合度越高,非常适合强排序场景下的策略优化 。
掌握这套流程和评估体系,你就能更好地搭建并优化出满足企业级需求的 RAG 智能系统了!