NVIDIA 开源 cuda-oxide:用纯 Rust 编写 CUDA 内核的新范式
标签 :
RustCUDAGPU高性能计算NVIDIA内核编程
发布日期: 2026-05-10
一、前言:当 Rust 遇上 GPU
2026 年 5 月,NVIDIA 正式开源了 cuda-oxide ------ 一款实验性的 rustc 定制后端,允许开发者用纯 Rust 编写 CUDA GPU 内核,直接编译生成 PTX 代码 。这标志着 GPU 高性能计算领域迎来了一个里程碑式的转变:从此,开发者不再需要依赖 C/C++ 或复杂的 FFI 绑定,就能在 Rust 的安全语义下榨取 GPU 的每一滴算力。

传统 CUDA 开发长期被 C/C++ 垄断,内存安全、泛型抽象、现代工具链等诉求始终难以满足。cuda-oxide 的出现,是否意味着 Rust 将成为 GPU 内核开发的"第一公民"?
二、Rust GPU 生态全景:从 FFI 绑定到原生编译
在 cuda-oxide 之前,Rust 社区已经围绕 GPU 开发构建了丰富的生态层次。我们可以将其分为三个演进阶段:
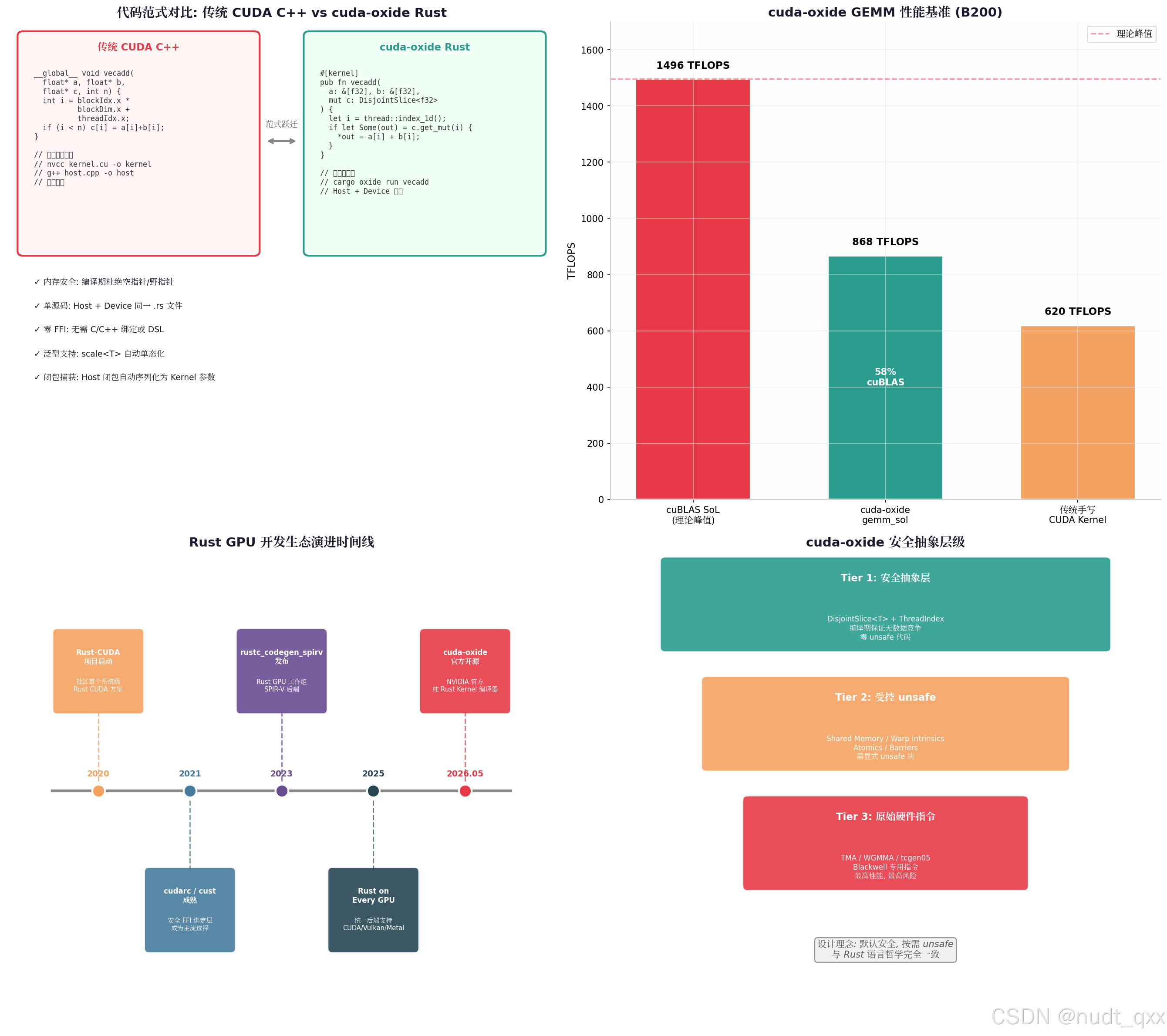
2.1 第一阶段:FFI 绑定层(2020-2022)
早期方案如 cudarc 、cust 、RustaCUDA 等,通过 bindgen 生成 CUDA Driver API 的 FFI 绑定,让 Rust 能够调用预编译的 .cu 内核 。这种方式虽然可行,但存在明显痛点:
- 双语言维护:内核用 C/CUDA 写,宿主逻辑用 Rust 写
- FFI 开销:类型转换、内存布局对齐容易出错
- 工具链割裂 :需要
nvcc+cargo两套编译系统
rust
// 传统 FFI 方式的典型代码 (基于 cudarc)
let kernel = backend.load_kernel("elementwise_add")?;
backend.launch_elementwise(kernel, a_buf, b_buf, &mut c_buf, n)?;2.2 第二阶段:编译器后端探索(2023-2025)
2023 年,Rust GPU 工作组发布了 rustc_codegen_spirv ,将 Rust 编译为 SPIR-V,支持 Vulkan 后端 。2025 年的 "Rust on Every GPU" 项目进一步统一了 CUDA、Vulkan、Metal 等多后端支持,但 CUDA 侧仍需通过 cust 等库间接调用 。
2.3 第三阶段:原生 Rust Kernel(2026-至今)
cuda-oxide 的发布彻底改变了游戏规则。它不再依赖外部语言或 FFI,而是作为 rustc 的定制 codegen 后端,直接将 Rust 源码编译为 PTX 。
三、cuda-oxide 核心架构:单源码、零 FFI、全 Rust
3.1 设计理念:三个"无需"
cuda-oxide 的设计哲学可以概括为:
| 传统 CUDA 开发 | cuda-oxide 方案 |
|---|---|
需要 DSL(如 __global__) |
无需 DSL ,用 #[kernel] 属性宏 |
| 需要 FFI 绑定 C/C++ 内核 | 无需 FFI,纯 Rust 单文件 |
| 需要源码到源码转换 | 无需转换,rustc 直接生成 PTX |
3.2 编译流水线:Rust → MIR → Pliron → LLVM → PTX
cuda-oxide 的编译流水线是其技术核心,也是与社区方案最大的区别 :
Rust Source (.rs)
↓
rustc Frontend (Parser + TypeCheck)
↓
Stable MIR (rustc_public) ← 稳定的编译器内部 API
↓
dialect-mir (Pliron IR) ← Rust 原生 MLIR-like IR 框架
↓
mem2reg (优化 Pass)
↓
dialect-llvm (LLVM IR)
↓
llc (LLVM 21+ 含 NVPTX 后端) ← 唯一外部二进制依赖
↓
PTX (.ptx)
↓
CUDA Driver (JIT → SASS)关键创新点:
- Stable MIR :使用
rustc_public读取编译器中间表示,避免 nightly 版本频繁 break - Pliron :完全用 Rust 编写的 MLIR-like IR 框架,无需 C++/CMake/TableGen,整个编译器可用
cargo构建 - 单源码设计 :Host 代码与
#[kernel]设备代码写在同一个.rs文件中,cargo oxide build同时生成宿主二进制和 PTX
3.3 代码范式对比:C++ vs Rust
| 特性 | 传统 CUDA C++ | cuda-oxide Rust |
|---|---|---|
| 内存安全 | 手动管理,易泄漏 | 所有权 + 借用检查,编译期保证 |
| 泛型 Kernel | 模板,编译复杂 | scale<T> 自动单态化 |
| 闭包捕获 | 不支持 | Host 闭包自动序列化为 Kernel 参数 |
| 枚举/模式匹配 | 需手动实现 | 原生支持 match、if let |
| 编译命令 | nvcc + g++ 多步 |
cargo oxide run 一键 |
rust
// cuda-oxide: 带闭包捕获的泛型 Kernel
#[kernel]
pub fn map<T: Copy, F: Fn(T) -> T + Copy>(f: F, input: &[T], mut out: DisjointSlice<T>) {
let idx = thread::index_1d();
if let Some(out_elem) = out.get_mut(idx) {
*out_elem = f(input[idx.get()]);
}
}
fn main() {
let factor = 2.5f32;
// 闭包 move |x| x * factor 自动捕获并传入 GPU
cuda_launch! {
kernel: map::<f32, _>,
args: [move |x: f32| x * factor, slice(input), slice_mut(output)]
}.unwrap();
}四、性能实测:868 TFLOPS 的 GEMM 实力
性能是 GPU 编程的生命线。cuda-oxide 官方提供的 gemm_sol 示例在 NVIDIA B200 上达到了 868 TFLOPS ,约为 cuBLAS 理论峰值(1496 TFLOPS)的 58% 。
| 方案 | 性能 (TFLOPS) | 相对 cuBLAS |
|---|---|---|
| cuBLAS SoL (理论峰值) | 1496 | 100% |
| cuda-oxide gemm_sol | 868 | 58% |
| 传统手写 CUDA Kernel | ~620 | ~41% |
这一成绩对于首个 alpha 版本的纯 Rust 编译器而言极为亮眼。其优化手段包括:
- 4 阶段流水线:加载 → 计算 → 存储重叠
- Thread Block Clusters (
cta_group::2):Hopper/Blackwell 架构的协作并行 - TMA (Tensor Memory Accelerator):硬件级异步数据传输
- LTOIR 链接时优化:Blackwell 时代的设备端链接优化
五、安全抽象层级:Rust 哲学在 GPU 上的延伸
cuda-oxide 将 Rust 的"默认安全,按需 unsafe"理念完美移植到了 GPU 内核开发:
Tier 1:安全抽象层(零 unsafe)
DisjointSlice<T>:编译期证明无数据竞争ThreadIndex:类型安全的线程索引- 适用于:向量运算、逐元素映射等简单并行模式
Tier 2:受控 unsafe
- Shared Memory、Warp Intrinsics、Atomics、Barriers
- 需显式
unsafe块,但提供类型安全封装 - 适用于:归约、扫描、共享内存协作算法
Tier 3:原始硬件指令
- TMA、WGMMA、
tcgen05(Blackwell Tensor Core) - 最高性能,最高风险,完全
unsafe - 适用于:极致优化的 GEMM、Transformer 内核
特别处理 :cuda-oxide 禁用了 rustc 的
JumpThreadingMIR 优化(该优化会将 barrier 调用复制到分支两侧),因为 GPU 要求所有线程在同一指令地址收敛到 barrier,否则会导致死锁 。
六、快速上手:5 分钟跑通第一个 Kernel
6.1 环境要求
| 依赖 | 版本要求 | 说明 |
|---|---|---|
| OS | Linux (Ubuntu 24.04) | 当前仅支持 Linux |
| Rust | Nightly 2026-04-03 | 需 rust-src + rustc-dev |
| CUDA Toolkit | 12.x+ | |
| LLVM | 21+ | 必须含 NVPTX 后端 |
| Clang | 21+ | 需完整头文件包 |
6.2 安装与验证
bash
# 安装 cargo-oxide 子命令
cargo install --git https://github.com/NVlabs/cuda-oxide.git cargo-oxide
# 健康检查
cargo oxide doctor
# 运行首个示例
cargo oxide run vecadd
# 输出: ✓ SUCCESS: All 1024 elements correct!6.3 观察完整编译流水线
bash
cargo oxide pipeline vecadd该命令会打印从 Rust MIR → dialect-mir → mem2reg → dialect-llvm → LLVM IR → PTX 的完整 trace,是理解编译器内部工作机制的最佳方式 。
七、46 个实战示例:覆盖主流场景
cuda-oxide 仓库内置了 46 个示例,涵盖从入门到高阶的各类场景 :
| 示例 | 说明 |
|---|---|
vecadd |
向量加法 ------ "Hello World" |
host_closure |
Host 闭包传入 GPU |
generic |
泛型 Kernel 单态化 |
gemm_sol |
868 TFLOPS 矩阵乘法 |
tcgen05 |
Blackwell Tensor Core (sm_100a) |
atomics |
6 类型 × 3 作用域 × 5 序关系 |
cluster |
Thread Block Clusters + DSMEM |
async_mlp |
异步 MLP 推理流水线 |
mathdx_ffi_test |
cuFFTDx / cuBLASDx 互操作 |
cross_crate_kernel |
跨 crate 定义和调用 Kernel |
八、生态定位:cuda-oxide 不是孤军奋战
cuda-oxide 的开源并不意味着其他 Rust GPU 项目的终结,相反,它丰富了生态的多样性 :
cudarc/cust:成熟稳定的 FFI 方案,适合已有 CUDA 代码库渐进迁移wgpu/rustc_codegen_spirv:跨平台图形/计算,适合 Vulkan/Metal 场景krnl/custos:高层抽象框架,降低 GPU 编程门槛cuda-oxide:NVIDIA 官方原生方案,追求极致性能与 Rust 语义完整性
未来,这些项目有望在 Pliron IR、Stable MIR 等基础设施上形成协同,共同推动 Rust 成为 GPU 计算的"通用语言"。
九、总结与展望
cuda-oxide 的发布是 Rust 进入系统级高性能计算领域的标志性事件。它不仅提供了一套可用的工具链,更重要的是证明了:
- Rust 的内存安全模型 可以在 GPU SIMT 架构上有效工作
- 现代语言特性(泛型、闭包、枚举、异步) 可以无缝融入内核编程
- 单源码编译 可以消除 Host/Device 的语言鸿沟
当然,作为 alpha 版本,cuda-oxide 目前仍有一些限制:
- 仅支持 Linux
- 需要 Rust nightly 和 LLVM 21+
- 部分 API 可能变动
但正如 NVIDIA 官方所言:"这是一个实验性编译器,旨在展示 CUDA SIMT 内核如何以原生 Rust 编写 ------ 无 DSL,无外部语言绑定 ------ 并面向更广泛的 Rust 社区开放。"
对于深耕 Rust 开发、编译器底层、GPU 高性能计算的工程师而言,cuda-oxide 值得立即上手体验。项目仓库和文档如下:
参考资源:
- NVIDIA 官方微信公众号发布: https://mp.weixin.qq.com/s/...
- cuda-oxide GitHub 仓库: https://github.com/NVlabs/cuda-oxide
- MarkTechPost 技术解析: https://www.marktechpost.com/...
- Rust on Every GPU 项目: https://rust-gpu.github.io/blog/2025/07/25/rust-on-every-gpu/
- Rust GPU 工作组: https://rust-gpu.github.io/
- awesome-cuda-and-hpc Rust 资源列表: https://github.com/sjinzh/awesome-fpga-list
本文图表由作者基于公开资料整理绘制,转载请注明出处。