****论文题目:****基于大语言模型的类人单次故障诊断(Human-Like One-Shot Fault Diagnosis via Large Language Model)
****期刊:****IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS: SYSTEMS
****摘要:****少量样本学习故障诊断方法在复杂系统中取得了较好的诊断效果,但现有方法无法实现类似人类的单镜头诊断学习。本研究使用大型语言模型(large language model, 大型语言模型)来增强类似人类推理的故障诊断。首先,我们将传感器数据转换为基于语言的表示,以获得更详细的特征描述。然后,通过大型语言模型的推理过程,将先验知识引入到基于语言的诊断数据中,实现信息增益。此外,我们应用算术编码对预测概率进行编码,形成一个基于熵的压缩器,逼近由Kolmogorov复杂度导出的信息距离。我们利用信息距离作为学习度量,实现了类人少量样本学习的单镜头故障诊断。在冷水机组系统上的实验结果表明,在大型语言模型的支持下,我们的方法可以实现零误差的类人故障诊断。该方法有望显著提高复杂工业系统的智能故障感知和维护能力,同时也为大型语言模型在工业故障诊断中的应用提供了一种新的研究范式。
用大语言模型实现"类人"单样本故障诊断:一篇来自 IEEE TSMC 的前沿工作解读
一、背景与动机:工业冷水机组的故障诊断难题
建筑系统消耗了全球近 40% 的能源,其中暖通空调(HVAC)系统在大型建筑中的能耗占比高达 30%~60%。冷水机组(Chiller)作为 HVAC 的核心设备,长期运行后会出现冷冻水流量减少、制冷剂泄漏、冷凝器积垢等多种故障。这些故障往往不会触发系统警报,却会悄无声息地拉低设备效率、抬高能耗,最终影响建筑使用者的舒适性。因此,准确、高效地诊断冷水机组故障,是工业智能运维领域的重要课题。
随着人工智能技术的发展,数据驱动的深度学习方法已被广泛引入故障诊断领域。然而,冷水机组作为一类典型的复杂工业系统,有着两个天然的挑战:
- 热力学与流体力学高度耦合:某个组件的异常可能被其他组件的自我调节所掩盖,导致故障信号被稀释,直接检测极为困难。
- 标注数据极度稀缺:冷水机组是大型工业系统,采集大量带标签的故障数据代价高昂,可用的故障样本非常有限。
在此背景下,小样本故障诊断(Few-Shot Fault Diagnosis) 方法应运而生,并取得了一定进展。但现有方法存在三个关键短板:
- 单样本诊断效率不足:现有小样本方法通常需要 5 个以上的已知样本才能表现良好,无法真正实现仅凭 1 个样本(One-Shot)就做出准确判断。
- 先验知识融入不充分:现有方法主要依赖从有限样本中学习模式,缺乏将领域专家知识或更广泛先验信息引入模型的有效机制。
- 数据表示形式单薄:传统故障诊断数据由原始传感器数值构成,缺乏对故障本质的抽象表达,模型在极少样本条件下难以泛化推理。
二、核心概念:什么是"类人故障诊断"?
本文最重要的贡献之一,是首次给出了"类人故障诊断"(Human-like Fault Diagnosis)的正式定义。
人类专家在诊断故障时,往往只需看过一次某类故障,便能在下次遇到类似情况时快速识别------这正是人脑强大的模式归纳与概念推理能力的体现。作者将这一能力抽象为三个核心要素:
| 能力维度 | 含义 |
|---|---|
| 单样本学习(One-Shot Learning) | 仅从极少量(甚至单个)带标签样本中快速学习并识别新故障类型 |
| 语言理解(Linguistic Understanding) | 将传感器数据转化为结构化语言表示,使系统能从语义层面理解信息 |
| 基于知识的推理(Knowledge-Based Reasoning) | 结合先验知识,通过推理驱动的方式完成诊断 |
在数学形式上,论文将类人小样本故障诊断定义为:学习一个可计算的度量函数 ,在预训练模型
的辅助下,对每个待诊断样本 x 找到最匹配的故障概念类
:
其中 可以是在大规模语料上预训练的假设(如 LLM),\\mathcal{F} 量化样本与概念类之间的距离。
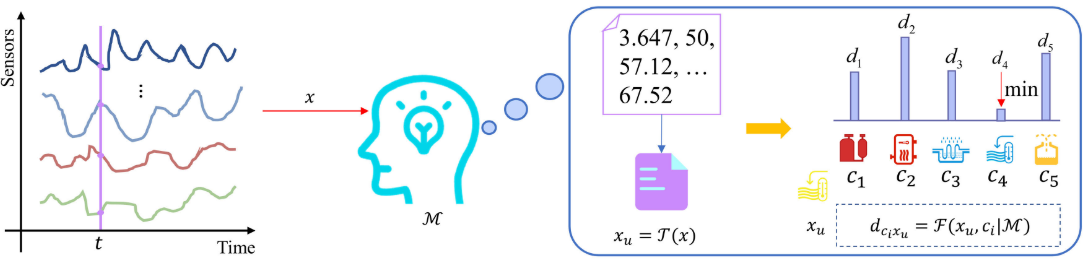
【配图:Figure 1 --- 类人单样本故障诊断整体示意图,展示从传感器数据到文本化、再到信息距离计算和分类的完整流程】
三、方法框架:四个关键模块
本文提出的方法由四个模块组成,整体流程如下图所示:
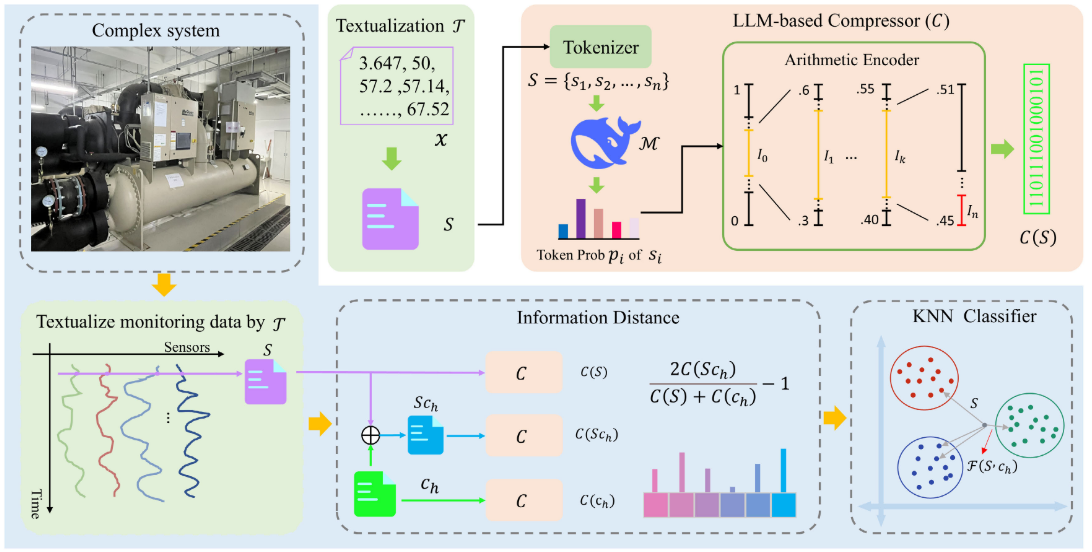
【配图:Figure 2 --- 方法整体框架图,展示传感器数据 → 文本化(T)→ LLM压缩器(C)→ 信息距离计算 → KNN分类器的完整管道】
3.1 信息距离作为学习度量
本文的核心洞察来自信息论:两个对象之间的相似性,可以用将一个转化为另一个所需的最短程序长度来度量,这正是 Kolmogorov 复杂度的精髓。
对于两个对象 x 和 y,将 x 转化为 y(或反向)所需的最小"能量"为:
根据 Church-Turing 假设,这可以用信息距离近似:
其中 是给定 y 时生成 x 所需的最短程序长度(条件 Kolmogorov 复杂度)。这一距离具有通用性:它不依赖任何特定的特征工程,天然适合小样本场景下的泛化。
3.2 传感器数据语言化(Prior-Aware Data Textualization)
LLM 的强大推理能力建立在自然语言之上,无法直接处理原始传感器数值。因此,本文设计了一套两阶段的数据语言化流程:
第一阶段:模板嵌入 将传感器读数按预定义的"描述模板"进行格式化,将每个传感器值与其物理含义、单位对应,生成初步的结构化文本。
第二阶段:LLM推理增强 将结构化文本连同一段包含推理链(Chain-of-Thought) 的专家指令一起输入 DeepSeek-70B,模型基于 HVAC 领域知识输出信息增强的最终文本描述 S:
生成的文本 S 不仅包含传感器的状态描述,还涵盖可能的故障原因、系统性能影响和维护建议,大幅丰富了数据的语义信息密度。
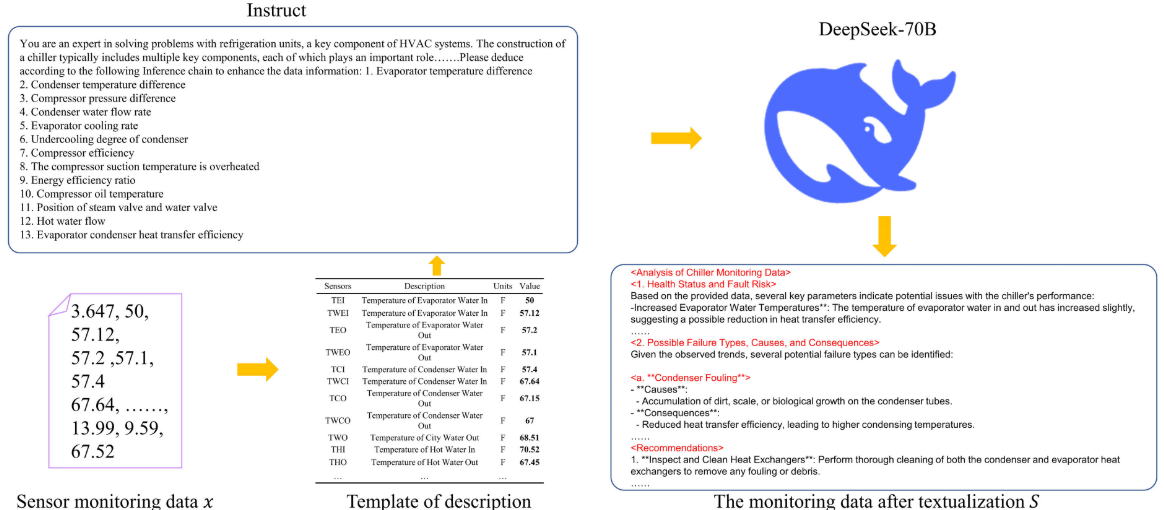
【配图:Figure 3 --- 传感器数据文本化流程图,展示原始数值 → 描述模板 → DeepSeek-70B推理 → 信息增强文本的转化过程】
消融实验表明,这两个阶段缺一不可:
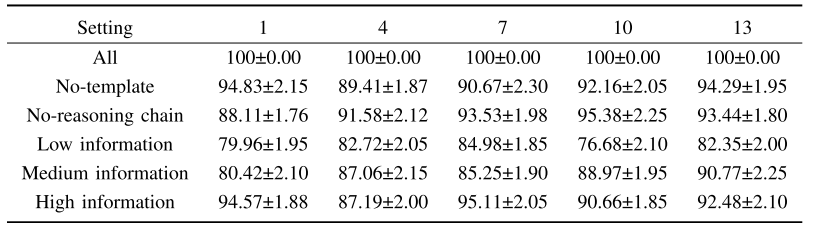
【配图:Table VI --- 消融实验结果表,对比"完整方法 / 无模板 / 无推理链 / 低中高信息量文本"下的诊断准确率】
可见,推理链的缺失对准确率的影响最为显著,这直接说明 LLM 的推理能力是该方法的核心驱动力。
3.3 基于LLM的算术编码压缩器
Kolmogorov 复杂度在理论上不可计算,本文用 LLM + 算术编码 构建了一个熵模型压缩器(LA Compressor)来近似它。
原理 :LLM 的自回归预测过程本质上是对下一个 token 的概率分布建模------这与信息论中的熵编码高度吻合。将文本 S 的 token 序列 输入 LLM,得到每步的预测概率
,则压缩长度(即 Kolmogorov 复杂度的近似)为:
这正是负对数似然(NLL),直接由 LLM 的预测概率计算得到,无需实际执行压缩。
算术编码的区间更新规则如下(编码第 k 个 token 时):
编码区间越窄,说明该序列越"出乎意料"(信息量越大,压缩长度越长);不同故障类别的文本在 LLM 的概率模型下具有截然不同的压缩长度,从而形成天然的分类依据。
与传统压缩算法的对比:
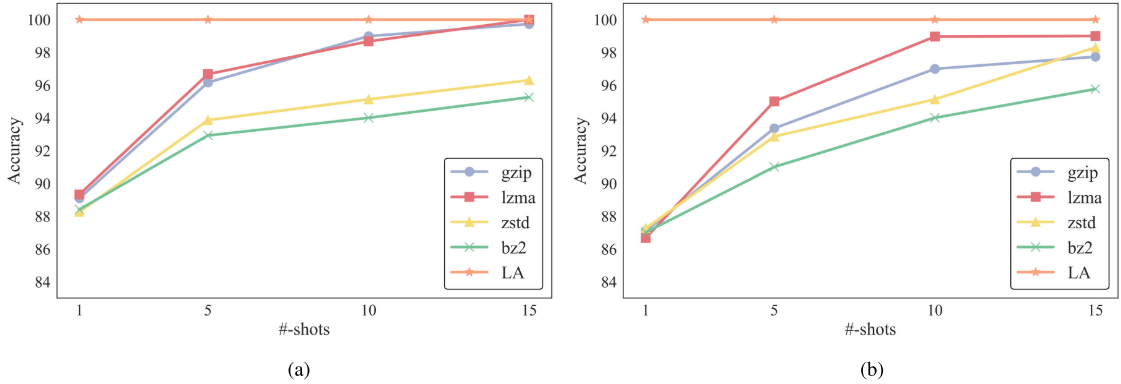
【配图:Figure 12 --- 不同压缩器(LA / gzip / lzma / bz2 / zstd)在 ASHRAE 和 HY-31C 两个数据集上的诊断准确率随 shot 数变化的曲线图】
LA 压缩器在所有 shot 数下均显著优于 gzip、lzma、bz2、zstd 等传统无损压缩算法,且压缩率与诊断准确率呈正相关,验证了"更好的压缩 = 更好的理解"这一信息论直觉。
3.4 信息距离近似与故障诊断
基于 LA 压缩器,论文引入归一化信息距离(NID) 并设计了最终的学习度量函数:
其中:
:待诊断样本文本的压缩长度
这一度量的直觉是:如果 S 和 属于同一故障类别,则拼接后 LLM 对它们的联合描述能更好地"预测"彼此,压缩长度更短,距离更小。
最终,使用 K近邻(KNN)分类器 根据信息距离对待诊断样本进行分类,完成一次类人单样本故障诊断。
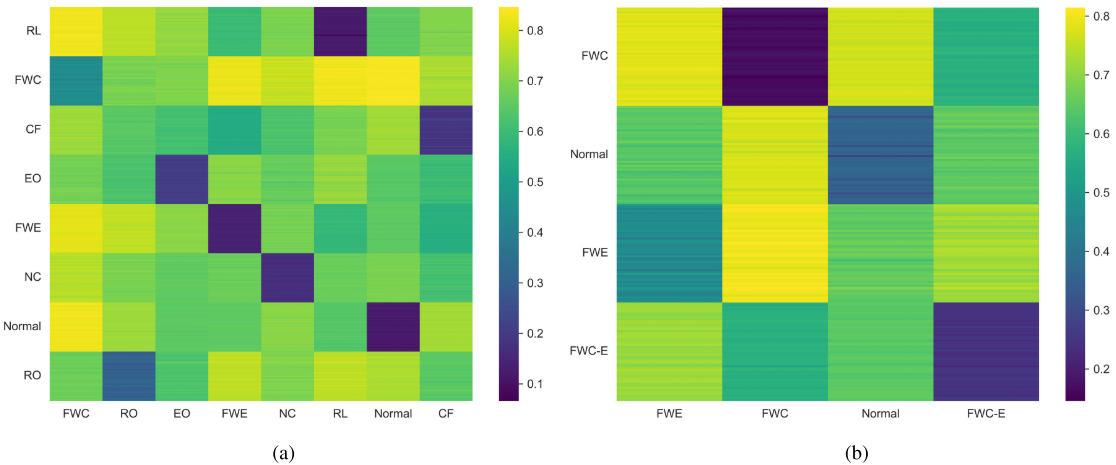
【配图:Figure 8 --- 信息距离矩阵可视化,分别展示 ASHRAE 和 HY-31C 两个数据集上不同故障类别间的信息距离热图,可观察到明显的类内聚集和类间分离结构】

【配图:Figure 9 --- KNN分类可视化,展示测试样本围绕各故障概念类样本(黑圈标注)的聚类分布情况】
四、实验设置
4.1 数据集
本文在三个数据集上进行了验证:
① ASHRAE 1043-RP 数据集
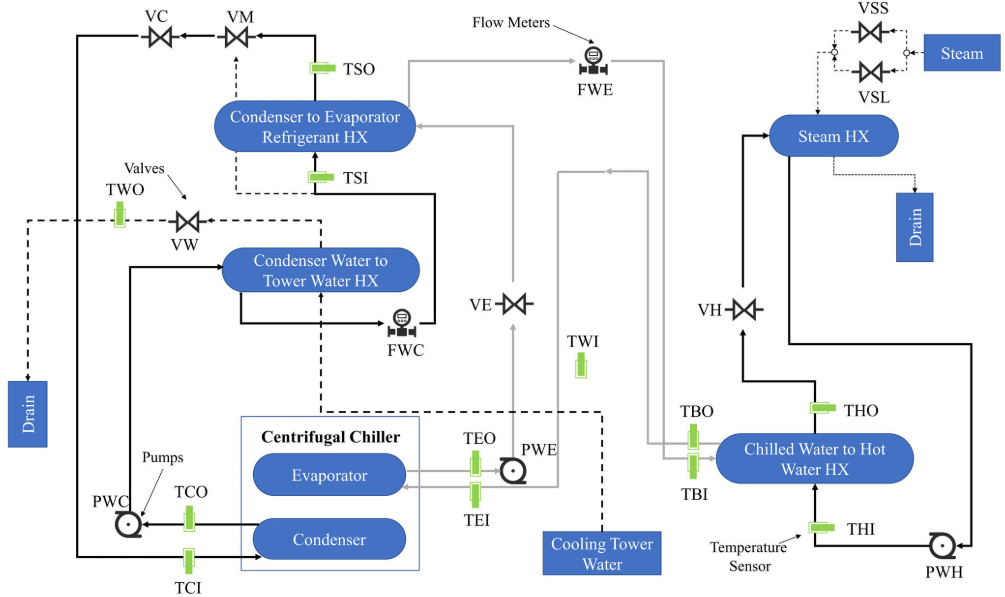
【配图:Figure 4 --- ASHRAE 冷水机测试台示意图,展示传感器布置位置与系统结构】
- 来源:美国采暖制冷空调工程师学会(ASHRAE)1043-RP 项目,学界广泛使用的标准基准数据集
- 包含正常状态 + 7种故障:蒸发器水流量减少(FWE)、冷凝器水流量减少(FWC)、制冷剂泄漏(RL)、冷凝器积垢(CF)、油过多(EO)、制冷剂过充(RO)、不凝性气体(NC)
- 采样间隔:10秒;包含 48 个传感器测量值 + 16 个实时计算参数
② HY-31C 数据集

【配图:Figure 5 --- HY-31C 螺旋式冷水机实验测试台照片】
- 来源:作者课题组自建螺旋式冷水机实验平台,包含 4 种故障类别(正常、FWE、FWC、FWC-E)
- 特点:故障严重程度较低、类别可分性有限,是对方法在更难场景下的考验
③ 热泵数据集(GSHP)

【配图:Figure 6 --- 北京某政府机构 5000kW 地源热泵系统照片】
- 来源:北京某政府机构管理的大规模浅层地热能利用项目,5000kW 额定功率
- 包含 6 种故障:旁路阀关闭(BVC)、高旁路压差(HDP)、导叶限位(GVL)开关故障、低压级电机轴承温度过高(EBT)、蒸发器压力过低(LEP)、低级油泵关闭(LOP)
- 特点:早期故障持续约 24 小时,具有长时性和潜伏性,诊断难度极高
4.2 对比方法
共与 8 种方法进行对比,涵盖三类典型小样本学习方法:
| 编号 | 方法 | 类别 |
|---|---|---|
| M0 | SeGMVAE | 基于无标签数据的半监督学习 |
| M1 | OTMatch | 基于无标签数据的半监督学习 |
| M2 | MPOS-RVFL | 基于无标签数据的半监督学习 |
| M3 | POEM | 传统小样本(元学习) |
| M4 | MD-BFSC | 传统小样本(元学习) |
| M5 | ICoT-GAN | 传统小样本(数据增强) |
| M6 | CWGAN | 传统小样本(数据增强) |
| M7 | ECMFGN | 传统小样本(数据增强) |
五、实验结果与分析
5.1 主要诊断结果
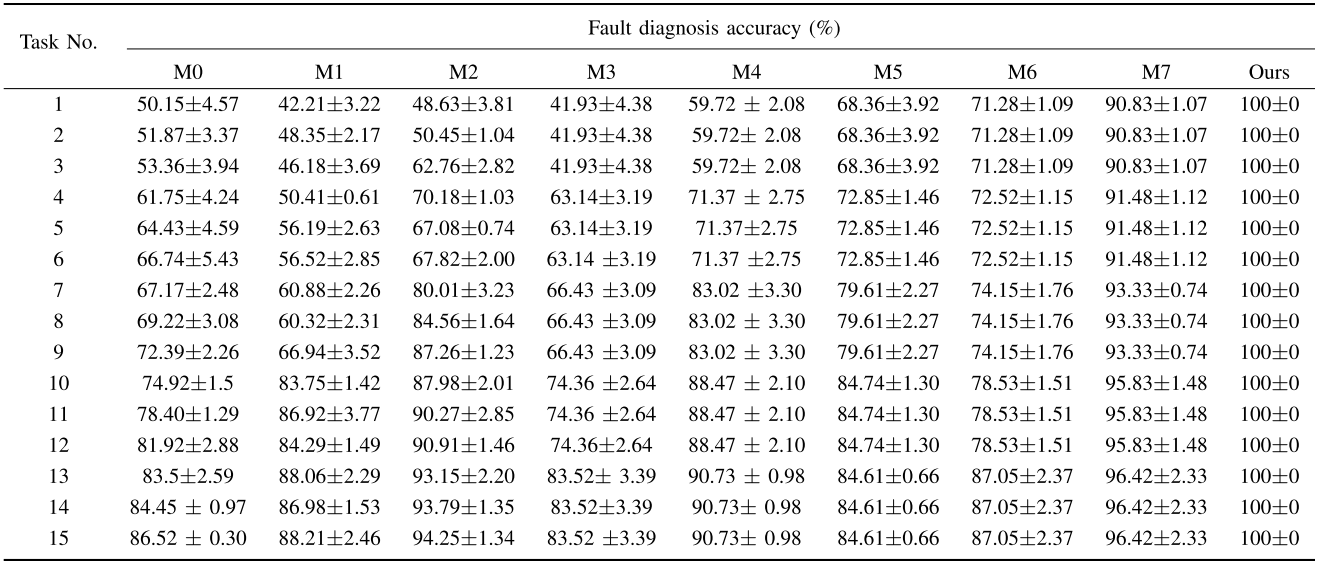
【配图建议:Table III --- ASHRAE 1043-RP 数据集上各方法在不同 shot 数(任务1~15,对应1~5 shot)下的故障诊断准确率对比表】
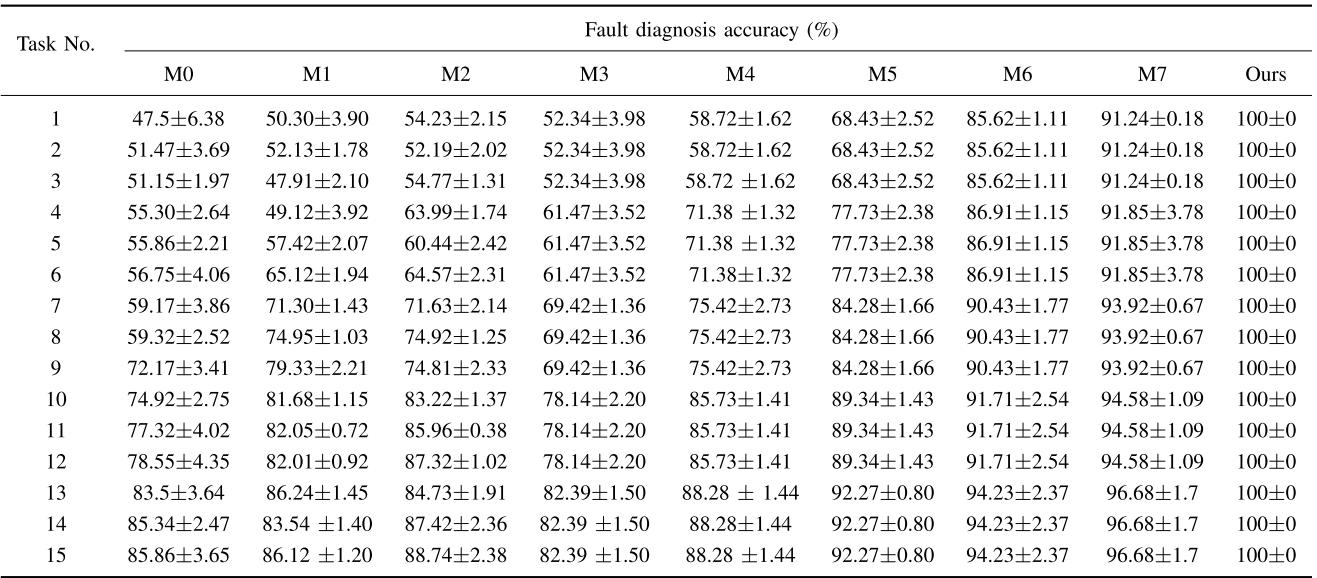
【配图建议:Table IV --- HY-31C 数据集上各方法在不同 shot 数下的故障诊断准确率对比表】
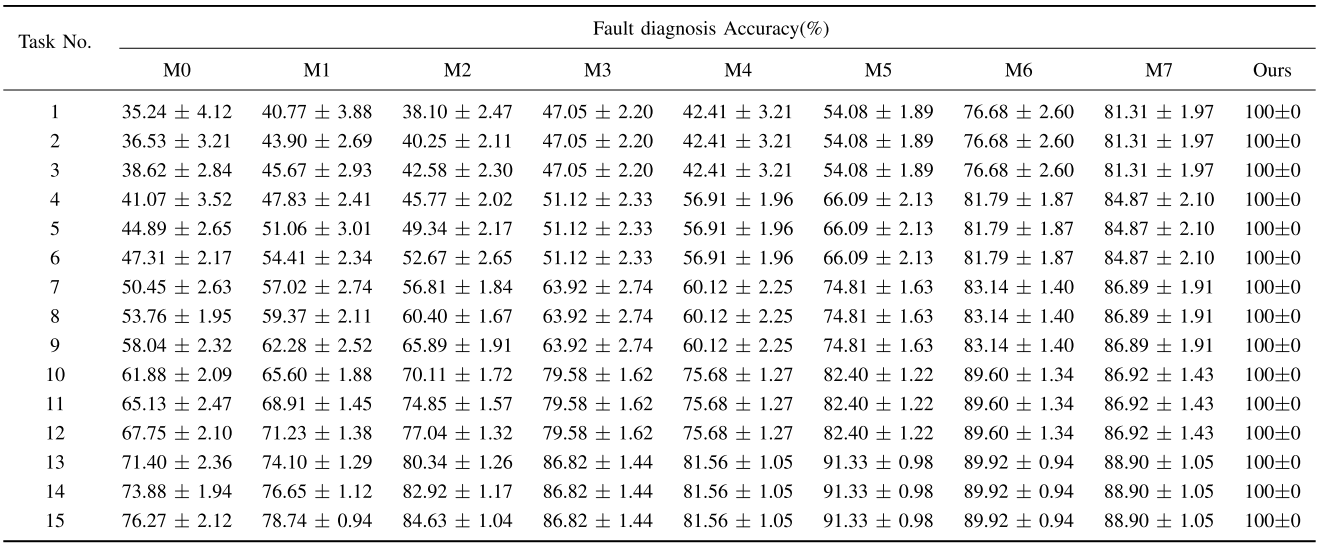
【配图建议:Table V --- 热泵数据集上各方法在不同 shot 数下的故障诊断准确率对比表】
本文方法(Ours)在 1~5 shot 的所有任务配置下,在三个数据集上均取得了 100±0 的诊断准确率,实现了真正意义上的零误差单样本故障诊断。而最强对比基线 M7(ECMFGN)在 ASHRAE 数据集 1-shot 设置下仅达到 90.83±1.07,差距超过 9 个百分点。
从对比分析中可以归纳出以下规律:
- 基于无标签数据的半监督方法(M0、M1、M2) 在 shot 数 ≤ 4 时表现反而不如传统小样本方法,原因在于:冷水机组数据的耦合效应导致故障类别可分性降低,大量无标签数据引入了额外噪声,干扰了模型性能。
- 基于生成模型的数据增强方法(M5、M6、M7) 在 shot < 4 时优于非增强方法,但始终无法逼近本文方法,因为复杂系统中的故障模式涉及强多变量耦合,伪样本生成质量难以保证。
- 本文方法的零标准差(std=0) 尤为突出:通过对LLM自回归概率进行算术编码,完全消除了概率估计引入的不确定性,诊断稳定性无与伦比。
5.2 LLM 参数规模的影响
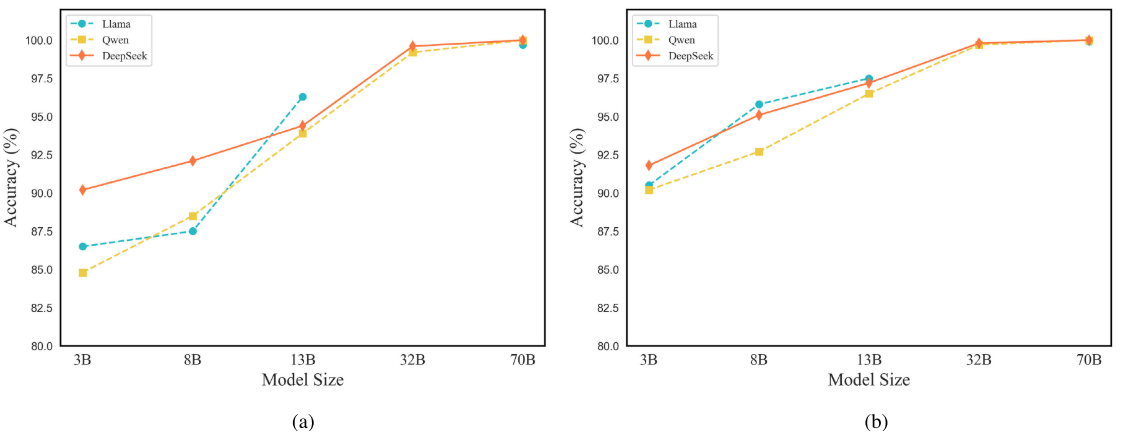
【配图:Figure 10 --- 不同参数规模(3B/8B/13B/32B/70B)的 Llama / Qwen / DeepSeek 三个模型系列在 ASHRAE 和 HY-31C 上的 1-shot 诊断准确率曲线图】
实验对比了 Llama、Qwen、DeepSeek 三个模型系列从 3B 到 70B 不同参数规模下的诊断性能,发现:
- 参数规模 < 32B 时,所有模型均无法达到 100% 准确率,与大模型的扩展律(Scaling Law)相吻合------更强的推理能力需要足够的模型容量支撑。
- DeepSeek 在低参数规模下优于同规模的 Llama 和 Qwen,表明 DeepSeek 的小参数模型具备更强的推理能力,这与其 R1 系列强化推理训练的设计理念一致。
- 三个模型系列在 70B 参数时性能趋于一致,均实现 100% 准确率。
5.3 故障概念类的可区分性
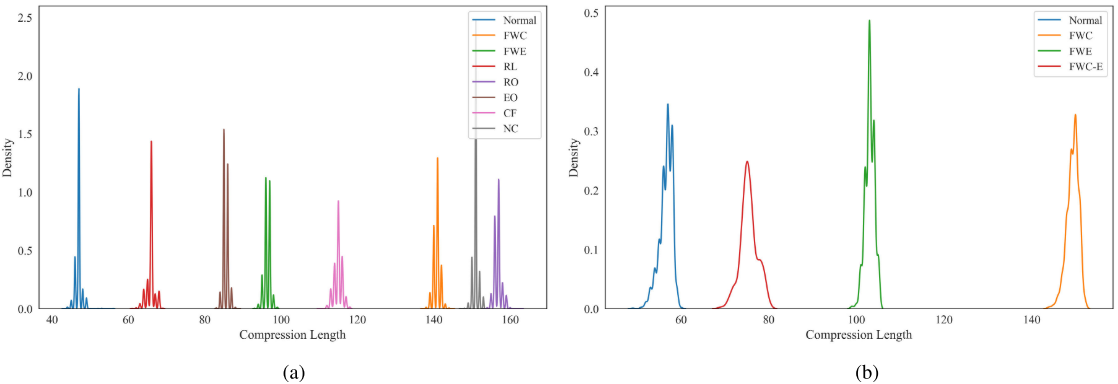
【配图:Figure 11 --- LA 压缩器对两个数据集中各故障类别样本的压缩长度分布图,可见不同故障类别对应截然不同的压缩长度区间】
将 LA 压缩器作用于两个数据集的所有样本后,不同故障类别呈现出截然分离的压缩长度分布。这意味着即使每类故障只有一个样本作为概念类,信息距离度量也能准确区分它们,从而支撑零误差单样本诊断。
5.4 聚合方式的影响
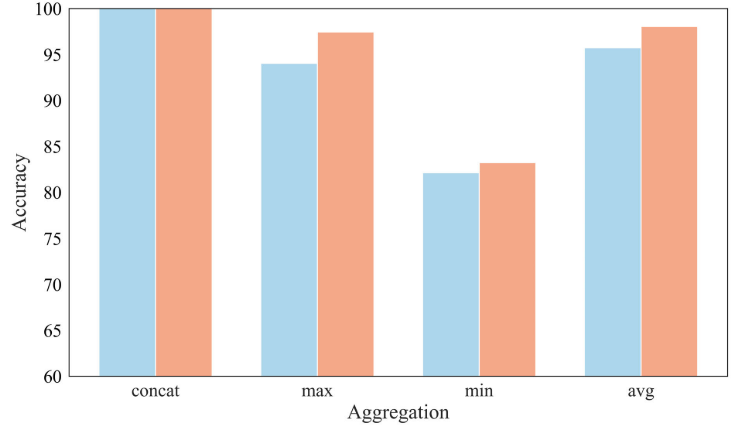
【配图:Figure 13 --- 不同聚合方式(concat / max / min / avg)对诊断准确率影响的柱状图】
论文对比了 concat(拼接)、max(最大值)、min(最小值)、avg(平均值)四种将概念类 与待诊断样本 S 融合的方式,拼接方式(concat)取得了最高的诊断准确率,印证了其在信息距离计算中的有效性。
5.5 计算资源消耗

【配图:Table VII --- DeepSeek 70B / 32B / 13B 三个版本在单样本诊断中的时间与 GPU 内存开销对比表】
由于无需任何参数更新,该方法可在单次推理中完成诊断。DeepSeek-70B 单样本诊断耗时约 3.16 秒,对工业实时应用而言已相当实用。
六、方法小结与意义
本文的整体方法逻辑可以用一句话概括:
把冷水机传感器数据"翻译"成大语言模型能理解的语言,再用大模型充当"压缩器"衡量数据之间的相似性,从而用信息论的方式实现了单样本故障诊断。
这一框架的核心优势在于:
- 无需系统建模:不依赖数字孪生或热力学模型,直接利用 LLM 的通用先验知识。
- 非参数化推理:不对 LLM 做任何微调,整个诊断流程仅调用推理接口,部署门槛低。
- 零标准差稳定性:基于算术编码的确定性计算彻底消除了随机性,每次诊断结果完全一致。
- 极强的样本效率:仅需每类故障 1 个标注样本,即可实现 100% 准确率,在工业场景中极具实用价值。
七、局限性与未来方向
论文作者坦诚指出,当前方法也存在一定局限:
- 推理开销较高:DeepSeek-70B 单样本诊断需要约 3 秒,且占用约 58GB 显存,不适合资源极度受限的边缘设备。
- 对 LLM 规模有依赖:小于 32B 的模型无法达到 100% 准确率,这对硬件条件有一定要求。
未来研究方向包括:
- 针对特定工业系统设计 LLM 微调策略,进一步提升推理能力;
- 探索高效低成本的边缘部署方案,使 LLM 驱动的诊断方法在资源受限环境中也能落地。
八、总结
这篇发表于 IEEE TSMC 2026 的工作,将大语言模型的推理能力与 Kolmogorov 复杂度理论优雅地结合,首次实现了真正意义上的类人单样本工业故障诊断,在三个数据集上全面取得零误差结果,并以完整的消融分析和对比实验验证了每个模块的必要性。它不仅为冷水机故障诊断提供了一条全新的技术路径,也为 LLM 在工业智能领域的应用开辟了一个充满潜力的新范式。