Hadoop的安装和部署是大数据生态圈体系中最麻烦的一个。Hadoop部署完成后,进一步地部署Spark和Flink就非常容易了。Hadoop的部署模式分为本地模式、伪分布模式和全分布模式。在学习完成了ZooKeeper的相关内容后,还将进一步地学习Hadoop HA的部署。这里重点讨论一下Hadoop的伪分布部署模式。
| 视频讲解如下 |
|---|
| 【赵渝强老师】Hadoop的伪分布部署模式 |
一、 Hadoop的目录结构
在部署Hadoop之前,需要对Hadoop的目录结构要有一定了解。先执行下面的语句将Hadoop的安装介质解压的/root/training目录。
powershell
tar -zxvf hadoop-3.1.2.tar.gz -C ~/training/
# 下面展示了Hadoop的目录结构:
[root@bigdata111 training]# tree -d -L 3 hadoop-3.1.2/
hadoop-3.1.2/ ─ ─ ── HADOOP_HOME目录
├── bin ─ ─ ── 最基本的管理和使用脚本所在的目录
├── etc ─ ─ ── 配置文件所在目录
│ └── hadoop
│ └── shellprofile.d
├── include ─ ─ ── 对外提供的编程库头文件目录
├── lib ─ ─ ── 对外提供的编程动态库和静态库
│ └── native
│ └── examples
├── libexec ─ ─ ── 各个服务Shell配置文件所在的目录
│ ├── shellprofile.d
│ └── tools
├── sbin ─ ─ ── Hadoop管理脚本所在目录
│ └── FederationStateStore
│ ├── MySQL
│ └── SQLServer
└── share
├── doc
│ └── hadoop
└── hadoop ─ ─ ── ─ 各个模块编译后的Jar包所在目录
├── client
├── common
├── hdfs
├── mapreduce
├── tools
└── yarn为了方便操作Hadoop,需要设置HADOOP_HOME的环境变量,并把bin和sbin目录加入系统的PATH路径中。下面列举了具体的步骤。
(1)编辑文件~/.bash_profile文件。
powershell
vi /root/.bash_profile(2)输入下面的环境变量信息,并保存退出。
powershell
HADOOP_HOME=/root/training/hadoop-3.1.2
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH(3)生效环境变量。
powershell
source /root/.bash_profile
二、 【实战】部署Hadoop伪分布模式
Hadoop伪分布式模式是在单机上模拟一个分布式环境,它具备Hadoop的所有功能特性,即:具备HDFS和Yarn。由于在伪分布模式下依然只有一台主机,因此这种模式并不是真正的集群环境。这种模式更多的是在开发和测试环境中使用该模式,不建议在生产环境中使用Hadoop的伪分布模式。
(1)进入Hadoop配置文件所在的目录
powershell
cd /root/training/hadoop-3.1.2/etc/hadoop/(2)修改文件hadoop-env.sh,设置JAVA_HOME
powershell
export JAVA_HOME=/root/training/jdk1.8.0_181(3)在/root/.bash_profile文件中增加下面的环境变量,并执行source语句生效环境变量。
powershell
export HDFS_DATANODE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root(4)进入Hadoop配置文件所在目录。
powershell
cd /root/training/hadoop-3.1.2/etc/hadoop/(5)修改hdfs-site.xml文件,增加下面的内容。
powershell
<!--数据块的冗余度,默认为3-->
<!--冗余度的配置原则一般与数据节点的个数一致,最大不超过3-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--禁用HDFS的权限功能-->
<!--开发环境设置为false-->
<!--生产环境设置为true-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>(6)修改core-site.xml文件,增加下面的内容。
powershell
<!--NameNode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata111:9000</value>
</property>
<!--HDFS对应于操作系统目录-->
<!--该参数的默认值是Linux的tmp目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-3.1.2/tmp</value>
</property> (7)修改mapred-site.xml文件,增加下面的内容。
powershell
<!--配置MapReduce运行的框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--以下是配置Hadoop的环境变量-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property> (8)修改yarn-site.xml文件,增加下面的内容。
powershell
<!--配置的ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata111</value>
</property>
<!--NodeManager采用shuffle洗牌的方式来执行任务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>(9)执行命令对NameNode进行格式化。
powershell
hdfs namenode -format
# 格式化成功后,将看到如下的日志信息:
Storage directory /root/training/hadoop-3.1.2/tmp/dfs/name has been successfully formatted.(10)执行命令启动Hadoop集群,如下图所示:
powershell
start-all.sh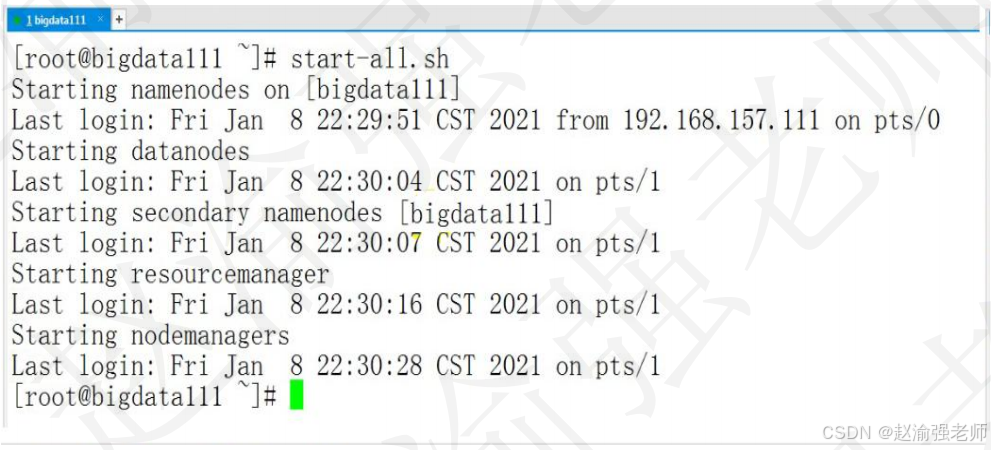
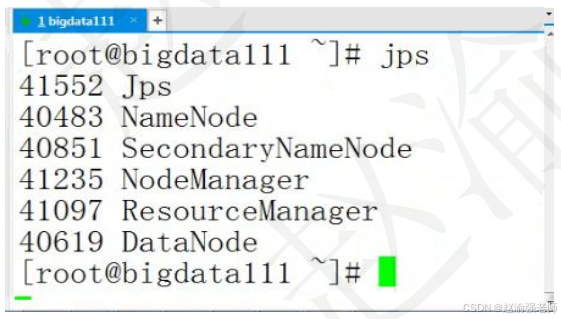
(11)执行jps命令查看后台的进程,如下图所示。
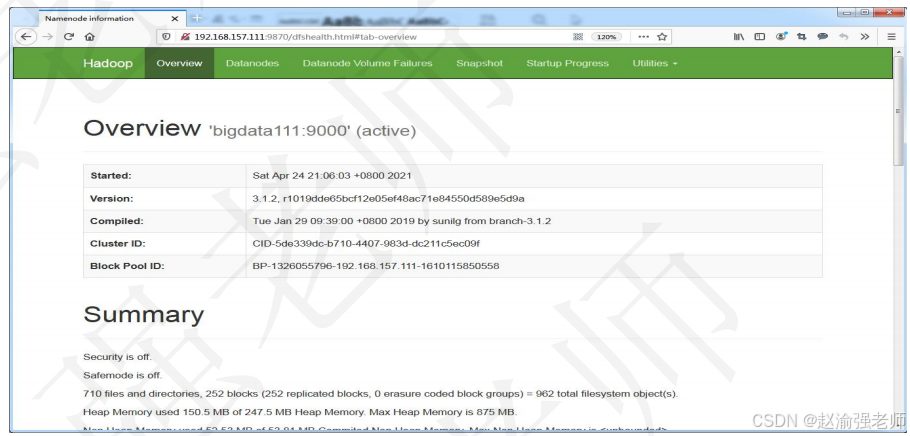
(12)通过9870端口访问HDFS的Web Consol,如下图所示。
(13)通过8081端口访问Yarn的Web Console,如下图所示。
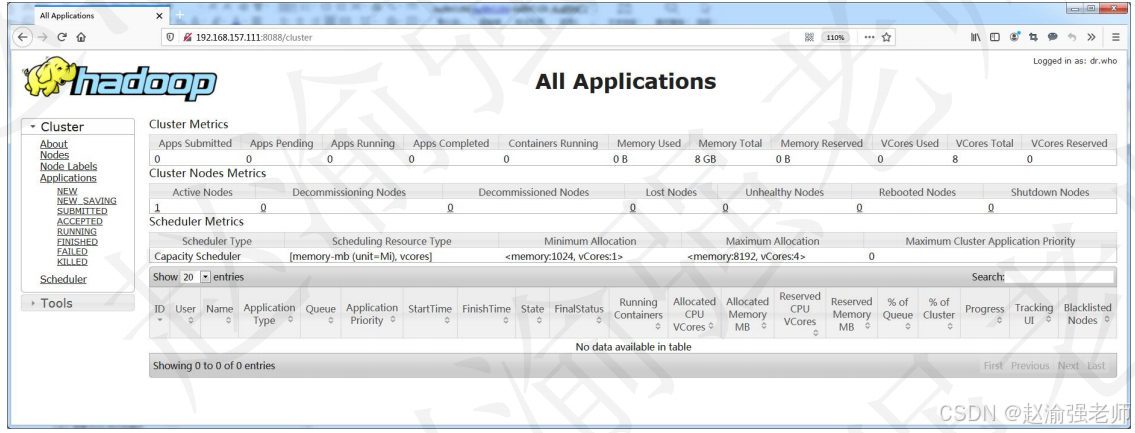
(14)执行命令在HDFS上创建/input目录。
powershell
hdfs dfs -mkdir /input(15)执行命令将/root/temp/data.txt文件上传到/input目录。
powershell
hdfs dfs -put /root/temp/data.txt /input(16)执行MapReduce WordCount任务。
powershell
cd /root/training/hadoop-3.1.2/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-3.1.2.jar wordcount /input/data.txt /output/wc(17)刷新Yarn的Web Console,观察任务的执行过程,如下图所示。
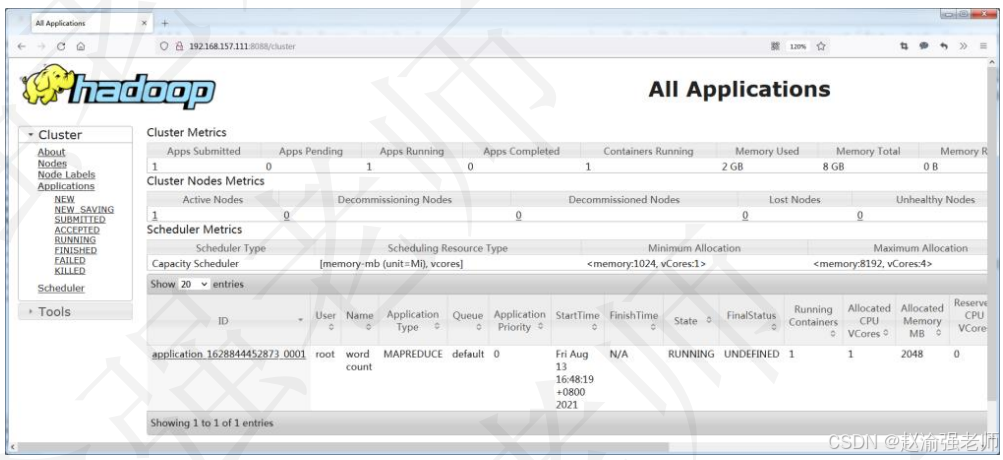
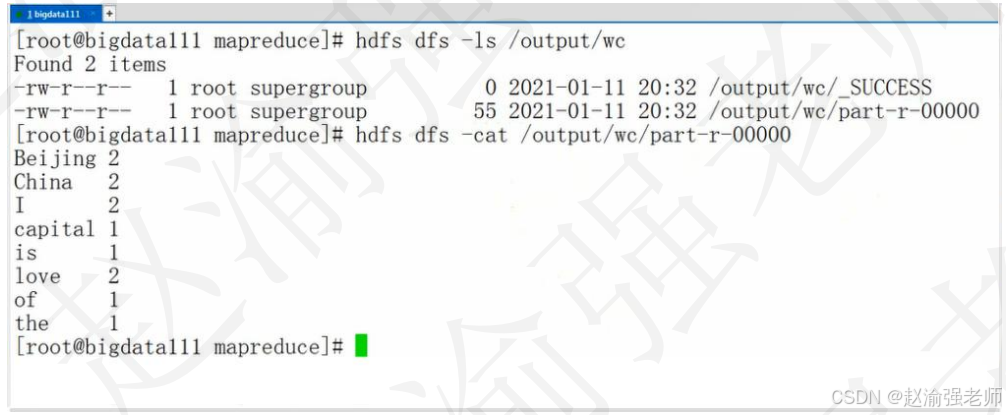
(18)任务执行完成后,在HDFS上观察输出的结果,如下图所示。