目录
[1 核心概念与组件](#1 核心概念与组件)
[2 目标检测数据集:COCO](#2 目标检测数据集:COCO)
[3 绘制边界框实现](#3 绘制边界框实现)
[4 目标检测数据集](#4 目标检测数据集)
前言
目标检测(Object Detection)是计算机视觉领域的核心任务之一。它的目标不仅要识别图像中出现了什么 (分类),还要确定这些物体在哪里(定位)。
图像分类通常是对于一个场景中识别一个主体;
而目标检测是将一个场景中所有我们感兴趣的物体识别出来,还有物体的位置。
// 下面是一个交通场景的目标检测示例:识别汽车、行人以及标识等(不同颜色的边缘框体现)
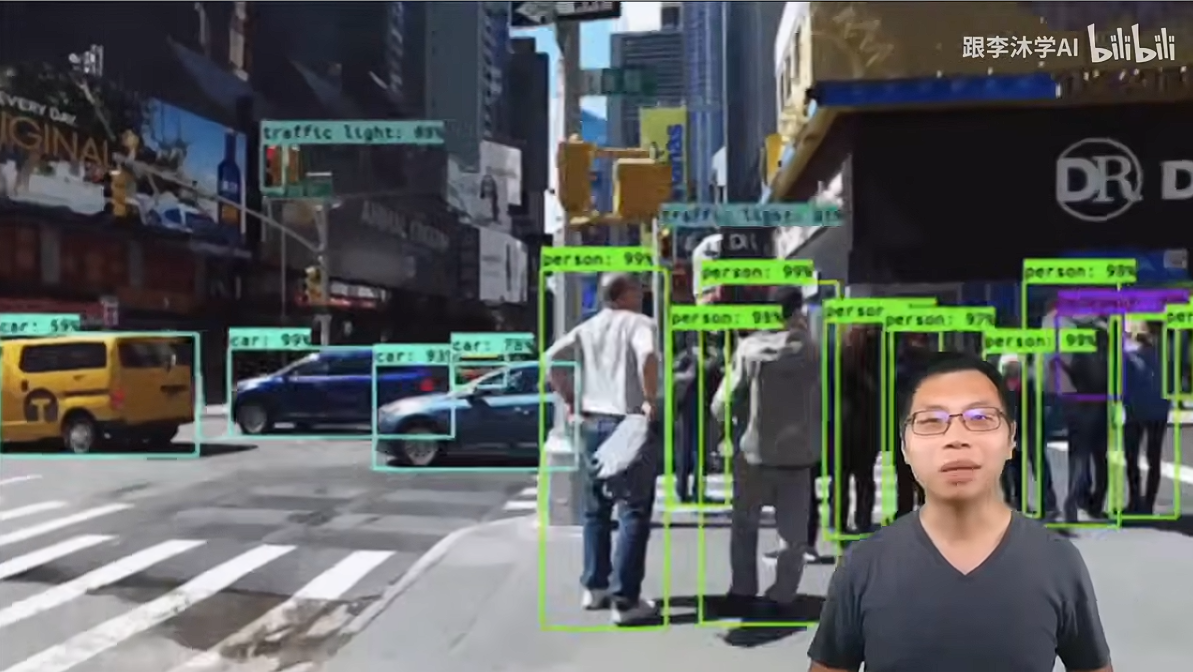
1 核心概念与组件
通常,目标检测的输出是一个边界框(Bounding Box),由坐标 和类别标签(Class Label)组成。
边缘框(Bounding Box):紧贴物体的矩形框
- 通过4个数字定义:①(左上x,左上y,右下x,右下y); ②(左上x,左上y,宽,高)
- 在图像中,对于一些不规则形过强-延展太大的物体,比如有一个角延伸出去,可以只框住主体部分而不包含这个角。由于对物体边缘界定存在偏差,通常来说是找几个人,对同一张图象标记之后取平均。
置信度(Confidence):模型认为该框内包含目标点概率及其位置准确性的得分。
IoU(Intersection over Union):交并比,衡量预测与真实框(Ground Truth)的重叠程度。
**非极大值抑制(NMS):**一种后处理技术。当模型对用一个物体预测出多个框时,NMS会剔除重叠度高且置信度较低的框,只保留最准确的一个。
不难知道,图像标注的成本很高,因此物体识别和目标识别的数据集相较于图像分类的数据集来说,其规模要小很多。
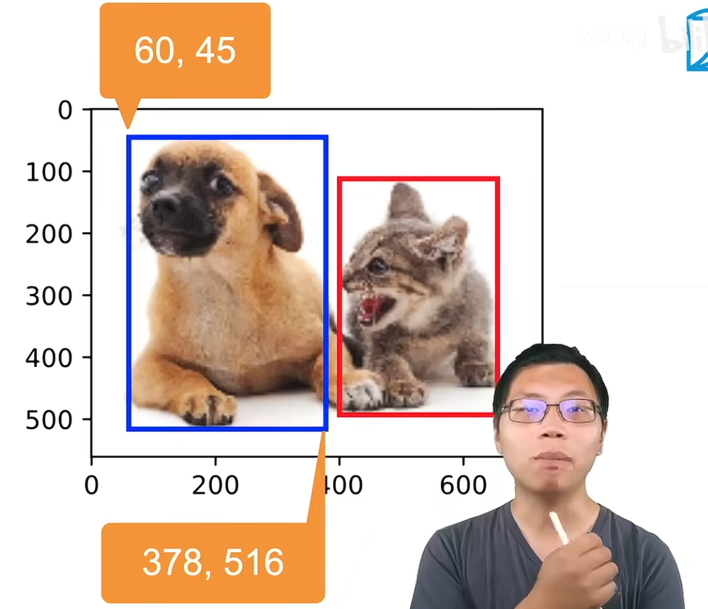
2 目标检测数据集:COCO
COCO 数据集(Common Objects in Context)是计算机视觉领域最流行、最具挑战性 的数据集之一。它由微软赞助,旨在推动 *++目标检测、实例分割、关键点检测和场景理解++*等任务的发展。
与早期的 Pascal VOC 数据集相比,COCO 的图片更接近真实生活场景,背景复杂且物体尺寸变化剧烈。
(1)核心特点
- 物体分割:不仅提供边界框,还提供精确到像素的掩膜
- 上下文关系:物体出现在自然、复杂的日常场景中,而不是单一的背景;
- 小物体丰富:数据集中包含大量小尺寸物体,对模型的检测能力提出了更高要求;
- 多样化任务:支持目标检测、示例分割、人体关键点检测、全景分割以及图像描述......
(2) 数据规模
COCO 通常分为训练集(Train)、验证集(Val)和测试集(Test),包含80个目标类别,330K张图像,每张图片标注5个框,标注实例总数超过150M个。

(3) 评价指标
COCO 定义了一套非常严格的评价标准,目前已成为论文中衡量模型性能的通用标准:
-
AP (Average Precision): 在多个 IoU 阈值(从 0.5 到 0.95,步长 0.05)下的平均精度。这要求模型不仅要找得准,定位还要非常精确。
-
: IoU 阈值为 0.5 时的 AP(类似 Pascal VOC 的标准)。
-
3 绘制边界框实现
(1)简单查看一下图片:
python
%matplotlib
import torch
from d2l import torch as d2l
d2l.set_figsize()
img = d2l.plt.imread('./data/img/catdog.jpg')
d2l.plt.imshow(img)//输出:
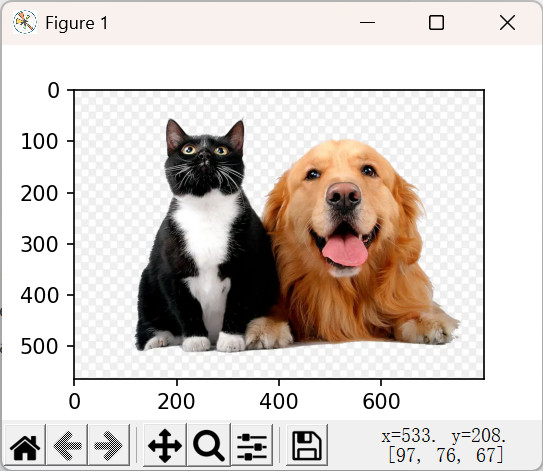
(2)定义边界框的不同表示方式之间转换的函数:
python
def box_corner_to_center(boxes):
"""(左上,右下)→(中间,宽,高)"""
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
boxes = torch.stack((cx, cy, w, h), axis=-1)
return boxes
def box_center_to_corner(boxes):
"""(中间,宽,高)→(左上,右下)"""
cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
x1 = cx - w * 0.5
y1 = cy - h * 0.5
x2 = cx + w * 0.5
y2 = cy + h * 0.5
boxes = torch.stack((x1, y1, x2, y2), axis=-1)
return boxes(3)定义边界框
python
dog_bbox, cat_bbox = [333.0, 92.0, 755.0, 504.0], [117.0, 51.0, 431.0, 515.0]
boxes = torch.tensor((dog_bbox, cat_bbox), dtype=torch.float32)
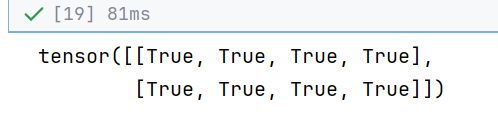
box_center_to_corner(box_corner_to_center(boxes)) == boxes//输出:注意数值的定义小数部分为0,否则容易因精度问题出现False。
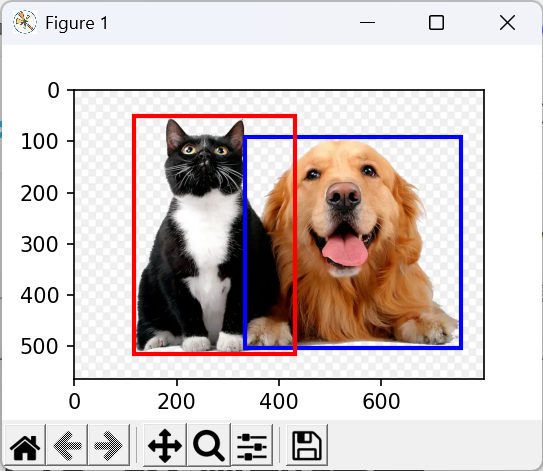
(4)绘制边界框
python
def bbox_to_rect(bbox, color):
return d2l.plt.Rectangle(xy=(bbox[0], bbox[1]),
width=bbox[2]-bbox[0], height=bbox[3]-bbox[1],
fill=False, edgecolor=color,linewidth=2)
fig = d2l.plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red'))//输出:
4 目标检测数据集
目标检测数据集没有特别好的、小型的数据集(类似于 CIFAR-10、Fashtion-MNIST这样的),导致要跑一个模型训练的话因为数据原因非常慢。
为了方便入门,课程提供了一个很小的数据集:banana-detection。它包含了一组香蕉🍌的照片,并生成了1000张不同角度和大小的香蕉图像,然后在一些背景图片的随机位置上放一张香蕉的图像,最后在图片上为这些香蕉标记了边界框。
(1)下载数据集
python
%matplotlib inline
import os
import pandas as pd
import torch
import torchvision
from d2l import torch as d2l
#@save
d2l.DATA_HUB['banana-detection'] = (
d2l.DATA_URL + 'banana-detection.zip',
'5de26c8fce5ccdea9f91267273464dc968d20d72')(2)读取数据集
read_data_bananas():下载数据集并解压,根据 is_train 的值读取 csv 文件。
注意哎最后 return 的地方,将标签数据转换为张量之后,还对边界框的坐标做了归一化。
- .unsqueeze(1):在张量的指定位置增加一个维度,这里的1表示在第1个位置增加一个维度,其目的是为了模拟"一张图像中可能包含多个目标"的情况 ------ ① 在执行此操作前,单个图像的标签形状是 (5,),代表 5 个数值;② 执行后,形状变为 (1, 5)。最外层的 1 代表这张图片里有 1 个检测目标。这样,数据集就能统一处理包含不同数量目标的图像了。
- /256处理:在原始数据集中,边界框的坐标值(如左上角 x, y)是以像素为单位的绝对值。
通过将坐标除以 256(高宽),可以将它们的取值范围从 0, 256 压缩到 0, 1 之间。
这种归一化处理对于深度学习模型的训练非常重要,它能加快模型的收敛速度并提高训练的稳定性。
python
#@save
def read_data_bananas(is_train=True):
"""读取香蕉检测数据集中的图像和标签"""
data_dir = d2l.download_extract('banana-detection')
csv_fname = os.path.join(data_dir, 'bananas_train' if is_train
else 'bananas_val', 'label.csv')
csv_data = pd.read_csv(csv_fname)
csv_data = csv_data.set_index('img_name')
images, targets = [], []
for img_name, target in csv_data.iterrows():
images.append(torchvision.io.read_image(
os.path.join(data_dir, 'bananas_train' if is_train else
'bananas_val', 'images', f'{img_name}')))
# 这里的target包含(类别,左上角x,左上角y,右下角x,右下角y),
# 其中所有图像都具有相同的香蕉类(索引为0)
targets.append(list(target))
return images, torch.tensor(targets).unsqueeze(1) / 256(3)组织数据集
自定义BananaDatset类别用于加载香蕉检测数据集:
python
#@save
class BananasDataset(torch.utils.data.Dataset):
"""一个用于加载香蕉检测数据集的自定义数据集"""
def __init__(self, is_train):
self.features, self.labels = read_data_bananas(is_train)
print('read ' + str(len(self.features)) + (f' training examples' if
is_train else f' validation examples'))
def __getitem__(self, idx):
return (self.features[idx].float(), self.labels[idx])
def __len__(self):
return len(self.features)加载香蕉检测数据集:
python
#@save
def load_data_bananas(batch_size):
"""加载香蕉检测数据集"""
train_iter = torch.utils.data.DataLoader(BananasDataset(is_train=True),
batch_size, shuffle=True)
val_iter = torch.utils.data.DataLoader(BananasDataset(is_train=False),
batch_size)
return train_iter, val_iter我们读取一个小批量并打印其中的图像和标签的形状;next(iter(train_iter))表示从数据迭代器中取出一个批次(batch)的数据。
batch0、batch1分别表示图像、标签的形状,其中图像的形状是:32个样本,通道数为3,尺寸为256×256,而标签小批量的形状为(批量大小,m,5),其中m是数据集中的任何图像中边界框可能出现的最大数量。
" 小批量计算虽然高效,但它要求每张图像含有相同数量的边界框,以便放在同一个批量中。 通常来说,图像可能拥有不同数量个边界框;因此,在达到 m 之前,边界框少于 m 的图像将被非法边界框填充。 这样,每个边界框的标签将被长度为5的数组表示。
数组中的第一个元素是边界框中对象的类别,其中-1表示用于填充的非法边界框。 数组的其余四个元素是边界框左上角和右下角的(x,y)坐标值(值域在0~1之间)。 对于香蕉数据集而言,由于每张图像上只有一个边界框,因此m=1。"
python
batch_size, edge_size = 32, 256
train_iter, _ = load_data_bananas(batch_size)
batch = next(iter(train_iter))
batch[0].shape, batch[1].shape//输出:

(4)演示
获取小批量的前10张图象:
- .permute(0,2,3,1):表示维度变换。PyTorch读取图片格式:(batchsize,channel, height, width),而Matplotlib显示图片需要(height,width,channel)格式,因此此行代码将通道维移到了最后。
- /255:表示归一化还原,将像素值从0,255缩放到0,1,这是很多深度学习框架和绘图库处理浮点数图像的标准格式。
python
imgs = (batch[0][0:10].permute(0, 2, 3, 1)) / 255
axes = d2l.show_images(imgs, 2, 5, scale=2)
for ax, label in zip(axes, batch[1][0:10]):
d2l.show_bboxes(ax, [label[0][1:5] * edge_size], colors=['w'])//输出:区间,

总结
用于目标检测的数据集在与图像分类的数据加载类似,但是在目标检测中,标签还包含真实边界框(位置)的信息。