HarmonyOS 实战:从一次语音识别率排查,讲透音频采集、PCM 与 ASR 同源校验
-
- 一、识别率问题是怎么暴露出来的?
-
- [1.1 现场问题为什么经常不是模型本身](#1.1 现场问题为什么经常不是模型本身)
- [1.2 为什么我最后单独整理了一个Demo](#1.2 为什么我最后单独整理了一个Demo)
- 二、音频快递线:理解PCM在鸿蒙音频体系里的角色
-
- [2.1 为什么语音场景经常落到 PCM / 16kHz / 单声道 / 16bit](#2.1 为什么语音场景经常落到 PCM / 16kHz / 单声道 / 16bit)
- [2.2 PCM、WAV、编码格式之间是什么关系](#2.2 PCM、WAV、编码格式之间是什么关系)
- [2.3 鸿蒙里处理PCM的几种主流能力(应用层)](#2.3 鸿蒙里处理PCM的几种主流能力(应用层))
- [2.4 Native层和编解码相关能力怎么选](#2.4 Native层和编解码相关能力怎么选)
- [2.5 AudioCapturer + AVPlayer + 鸿蒙ASR本机检验](#2.5 AudioCapturer + AVPlayer + 鸿蒙ASR本机检验)
- 三、把排查过程工具化:离线任务式页面的设计
-
- [3.1 任务包为什么要本地化](#3.1 任务包为什么要本地化)
- [3.2 数据模型怎么设计](#3.2 数据模型怎么设计)
- [3.3 任务初始化为什么要围绕索引展开](#3.3 任务初始化为什么要围绕索引展开)
- 四、核心链路落地:同一份PCM同时服务波形、WAV落盘和ASR
-
- [4.1 录音规格为什么要先对齐](#4.1 录音规格为什么要先对齐)
- [4.2 为什么要自己补WAV头](#4.2 为什么要自己补WAV头)
- [4.3 一次采样,三路消费](#4.3 一次采样,三路消费)
- [4.4 收尾逻辑为什么比开始逻辑更容易出问题](#4.4 收尾逻辑为什么比开始逻辑更容易出问题)
- 五、接第三方ASR时,为什么一定要做"同源校验"
-
- [5.1 AsrRecognizerManager只负责会话,不负责采音](#5.1 AsrRecognizerManager只负责会话,不负责采音)
- [5.2 识别真正消费的是录音器送上来的那段PCM](#5.2 识别真正消费的是录音器送上来的那段PCM)
- [5.3 页面层怎么把录音和ASR串成一个流程](#5.3 页面层怎么把录音和ASR串成一个流程)
- [5.4 动态识别度对比为什么先用轻量方案](#5.4 动态识别度对比为什么先用轻量方案)
- 六、页面状态管理:这类小工具最怕状态机有问题
-
- [6.1 为什么音频页最容易在边界场景里乱](#6.1 为什么音频页最容易在边界场景里乱)
- [6.2 当前页面是怎么收状态的](#6.2 当前页面是怎么收状态的)
- [6.3 生命周期里的清理逻辑为什么不能省](#6.3 生命周期里的清理逻辑为什么不能省)
- 常见问题排查与总结
熟悉我的朋友们应该知道,前段时间,我们公司在做一个语音 AI 助手类应用。

整体链路并不复杂:前面做语音输入,接第三方 ASR,后面再接意图理解和执行逻辑。测试跑得一直还可以,直到有一次去现场联调,问题开始集中冒出来。
同样一句控制指令,在工位上识别正常,到了样板间里就不稳定了。人一换、站位一变、背景里多一点空调声或者电视声,识别率马上往下掉。最开始大家都在盯 ASR 结果,以为是识别引擎的问题,后来越排查越发现,很多锅其实不在 ASR 本身,而是在更前面的音频采样链路。
这篇文章就是从这次排查出发,借我整理出来的一个鸿蒙 Demo,把几件事串起来讲清楚:
- 现场识别率问题,为什么很多时候要先查采样链路
- PCM 在鸿蒙音频体系里到底扮演什么角色
- 为什么语音校验一定要做"同源"
- 如何把录音、WAV 落盘、ASR、回放组织成一条完整链路
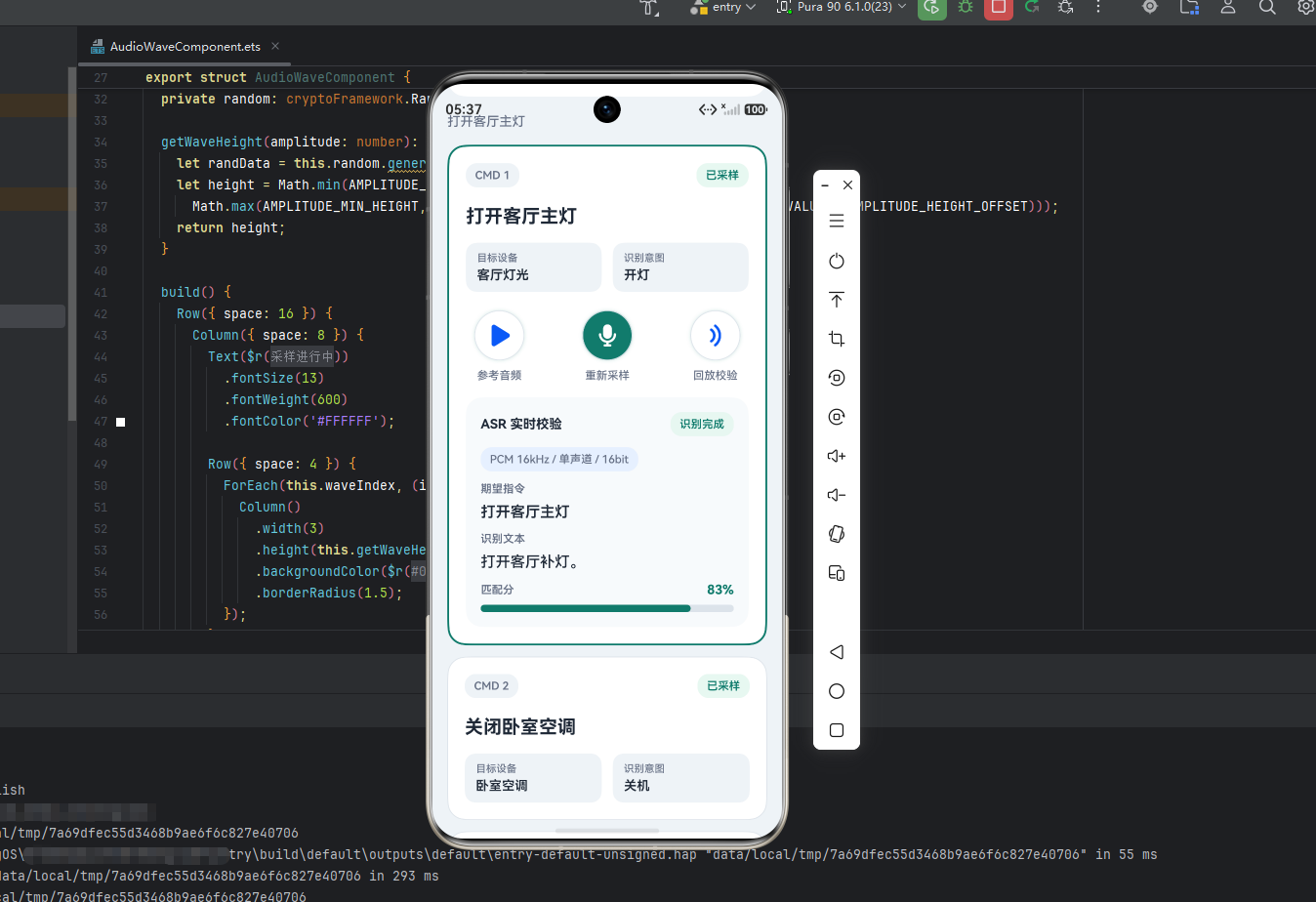
一、识别率问题是怎么暴露出来的?
一开始这个问题并不明显。
因为测试环境相对稳定,说话距离、背景噪声、设备摆位都比较可控。只要链路能跑通,识别结果看上去通常不会太差。可一旦把场景切到现场,问题就不再是"能不能识别",而是"为什么识别波动这么大"。
现场排查时,最典型的现象有两个:
- 不同人说同一句话,识别结果波动明显。
- 同一个人说同一句话,安静环境和复杂环境下差异也很大。
如果只盯着识别文本看,很容易把注意力全部放到第三方 ASR 上。比如去看热词、看参数、看后处理规则。这些当然要看,但很多真实问题根本还没走到那一层。
因为在 ASR 之前,还有一条更基础的链路:
麦克风采集 -> 音频格式组织 -> 数据落盘/上传 -> 识别引擎消费
只要这条链路前面几步不稳,后面的识别再强,也只能接收一份质量不稳定的输入。
1.1 现场问题为什么经常不是模型本身
那次排查,我们最终锁定的问题源头是这几类:
- 采样距离不一致
- 环境噪声变化大
- 录音规格和识别预期不一致
- 回放样本和校验样本不是同一份
- 页面上看起来在"做识别校验",实际上又重新开了一次麦克风
把这些因素放到一起看,方向已经很清楚了:真正需要优先确认的,不是ASR模型强不强,而是送进ASR的那份音频到底长什么样。
1.2 为什么我最后单独整理了一个Demo
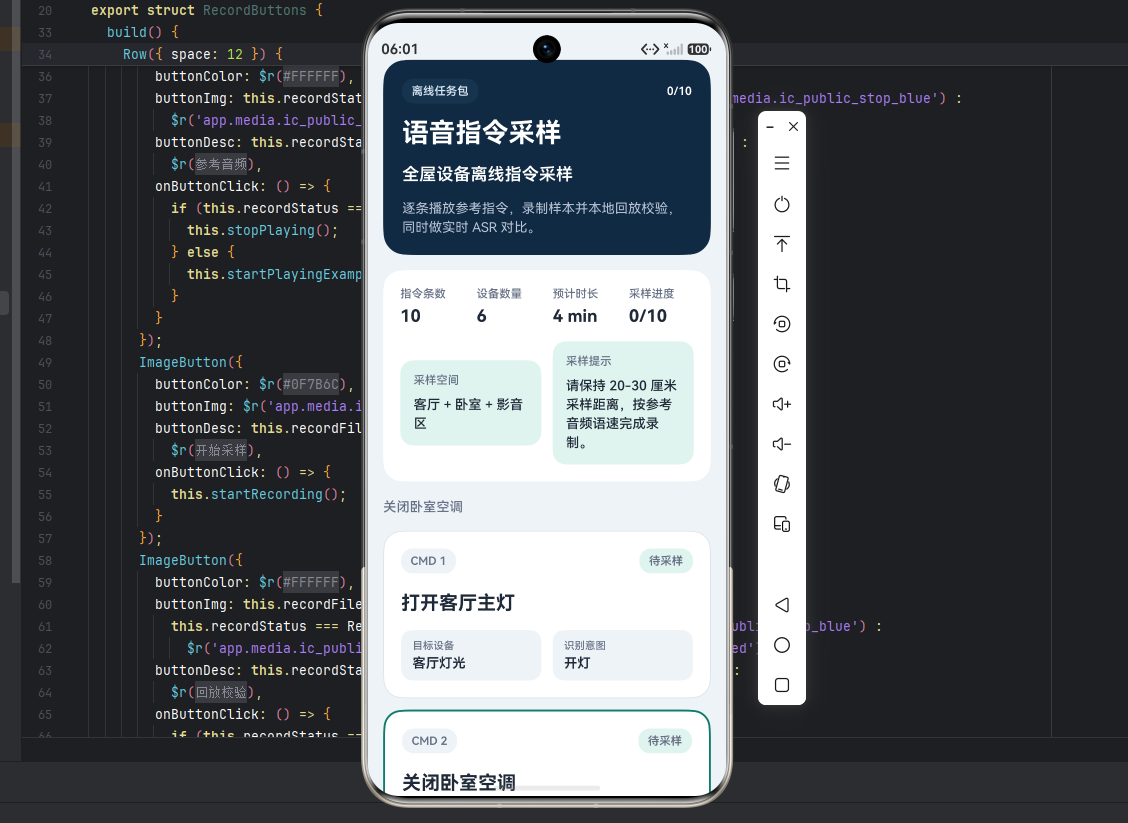
排查到这里,我没有继续在原有大项目里堆日志和临时页面,而是专门把过程整理成了一个小工具。这个工具的目标非常明确:
- 让一条命令先有标准参考音频
- 让采样结果可以本地回放
- 让ASR校验直接消费本次采样的同一份音频
- 让波形、录音文件、识别文本三者能对得上
这样一来,现场再遇到"为什么识别率突然掉了"这类问题时,排查就不会只停留在结果层,而是能回到采样本身。
二、音频快递线:理解PCM在鸿蒙音频体系里的角色
在深入技术之前,我先给你一个贯穿全文的比喻------音频快递线:
| 环节 | 比喻 | 说明 |
|---|---|---|
| 麦克风采集 | 收件口 | 声音进入系统的入口 |
| PCM数据 | 原始包裹 | 未经任何加工的采样数据 |
| 加WAV头 | 贴快递单 | 加文件头,让文件可被识别和播放 |
| ASR识别 | 收件人验货 | 识别引擎消费音频 |
| 同源校验 | 单号对得上 | 确保ASR看到的就是刚才采的那份 |
识别率问题的根源,往往是"包裹"在中途被拆过、换过、或者收件人看到的不是同一个包裹。
2.1 为什么语音场景经常落到 PCM / 16kHz / 单声道 / 16bit
PCM可以简单理解成数字化之后的原始采样数据。麦克风采到的是连续的模拟声波,设备要处理它,必须先把它离散化、数字化,变成一串可以计算的采样点。这串采样点本身,就是PCM的核心内容。
语音识别场景里,很多引擎之所以更偏爱PCM,而不是MP3、AAC这类压缩格式,原因并不复杂:
- 输入结构稳定
- 不需要先额外解码
- 便于直接做后续算法处理
而 16kHz / 单声道 / 16bit 这组规格,则是语音链路里非常常见的一个平衡点:
16kHz:对命令词识别来说通常足够,成本也可控单声道:不增加无意义的数据量16bit:兼容性成熟,表达能力也够
做语音AI助手,不是在追求音乐保真,而是在追求稳定地把一句控制命令听清楚。
2.2 PCM、WAV、编码格式之间是什么关系
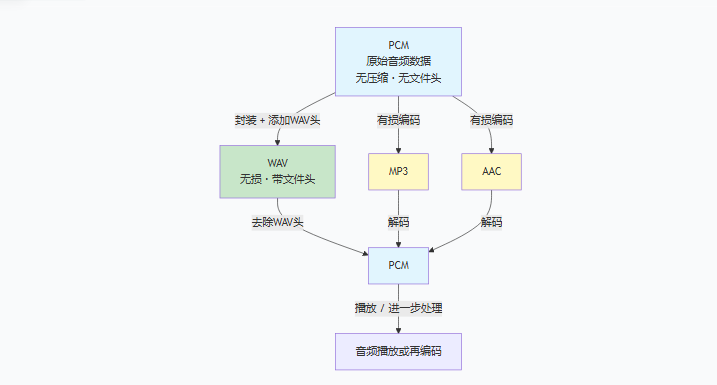
这里有个很容易混掉的点:WAV和PCM不是一回事。
- PCM是原始音频数据
- WAV更像是对PCM的一种封装
可以这么理解,PCM是"原材料",WAV是"带包装的原材料",MP3/AAC是"深加工后的产品"。WAV与PCM可以无损互转,MP3/AAC与PCM虽能编解码,但每次编码都会损失音质。
WAV文件头里会写清楚采样率、声道数、位深、数据区长度这些信息,所以PCM转WAV并不需要重新编码,只需要补上文件头;反过来,WAV转PCM也不需要解码,只是去掉文件头。
这一点在实际工程里很重要。因为它决定了你什么时候需要编码器,什么时候根本不需要:
- PCM -> WAV:加文件头即可
- WAV -> PCM:去掉文件头即可
- PCM -> MP3/AAC:需要编码
- AAC/MP3 -> PCM:需要解码
这也是为什么当前Demo里,我采样时选的是PCM,但落盘时又包装成了WAV。目的不是"更标准",而是为了兼顾两件事:
- 识别链路继续消费原始PCM
- 回放链路可以直接拿生成的音频文件播放
2.3 鸿蒙里处理PCM的几种主流能力(应用层)
如果只从"能不能录、能不能播"看,鸿蒙里处理PCM的入口其实很丰富。
1. AudioCapturer:录PCM
这是当前项目用到的核心能力。它支持设置采样率、声道数、采样格式、编码类型,并通过回调拿到原始PCM数据。这种方式非常适合做语音采样、实时波形分析、ASR前链路输入、音频母带级原始数据录制。
2. AudioRenderer:播PCM
如果你手里已经是PCM数据,而不是一个MP3或AAC文件,那播放侧最直接的选择通常是AudioRenderer。它支持基础播控、音量、静音、倍速、跳转等能力,播放时需要在写数据回调中持续把PCM喂进去。
3. AVPlayer:播压缩音频文件
如果目标是播放MP3、M4A这类普通音频文件,更适合直接用AVPlayer。因为它内部已经帮你把解封装、解码、播放这一套流程接好了。也正因为如此,当前Demo里的参考音频和最终生成的WAV文件回放,走的还是播放器思路,而不是自己手搓PCM播放链路。
2.4 Native层和编解码相关能力怎么选
再往下一层,就是Native API了。
1. OHAudio:底层PCM控制
这是C/C++层的接口,同样围绕PCM工作。适合对性能、时延、控制粒度要求更高的场景。
2. AVCodec + AVMuxer/AVDemuxer:编解码与封装转换
这一组能力主要解决格式转换问题:
- PCM转MP3/AAC:要编码,再封装
- AAC/MP3转PCM:要解封装,再解码
- 同编码格式不同容器间转封装:只解封装和重新封装,不需要编解码
3. OHAudioSuite:高级音频处理
如果你要做均衡器、降噪、混音、实时音效这类处理,通常已经不只是"录"和"播"了,而是要在PCM流上做处理。这类场景更适合放到专门的音频处理管线里去做。
2.5 AudioCapturer + AVPlayer + 鸿蒙ASR本机检验
放回这个项目,选型其实很朴素:
- 采样要拿原始音频:选AudioCapturer
- 回放参考音频和结果文件:选AVPlayer
- 识别走鸿蒙ASR本机检验:直接喂PCM,通过后再换三方调试
这套组合的好处是路径很短,而且每一层的职责都清楚:采样器负责拿到原始数据,播放器负责播资源文件和结果文件,识别引擎负责消费同一份PCM。对于"现场识别率排查"这个目标来说,已经足够合适。
三、把排查过程工具化:离线任务式页面的设计
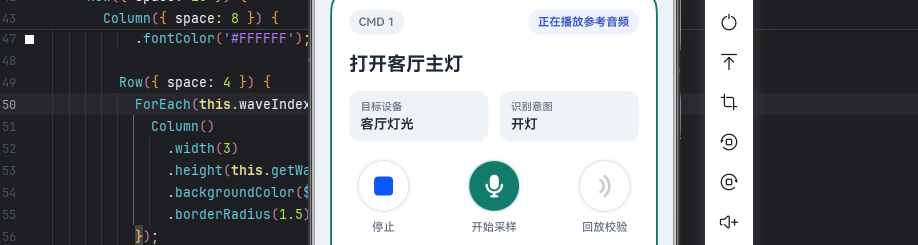
这次Demo的出发点,不是做一个录音页,而是把排查过程里真正有价值的步骤固化下来。
现场识别率不高时,我们真正想确认的事情,其实无非这几件:
- 当前这条命令的标准说法是什么
- 用户现场录到的音频质量怎么样
- 这段音频拿去做识别,和预期差多少
- 这个差异到底是采样问题,还是识别问题
所以我把它整理成了一个离线任务式的页面。每一条任务都带着参考音频、目标设备和预期意图。用户点进去以后,先听参考,再采样,再看同源ASR结果,最后可以本地回放核对。
3.1 任务包为什么要本地化
当前工程里的任务包就是本地rawfile:
json
{
"title": "全屋设备离线指令采样",
"estimated": "4 min",
"deviceCount": 6,
"scene": "客厅 + 卧室 + 影音区",
"tips": "请保持 20-30 厘米采样距离,按参考音频语速完成录制。"
}这里我没有把它做成远程动态拉取,是有意为之。因为这种工具很可能出现在样板间、设备间、联调现场,而不是一个稳定联网的办公环境里。任务包和参考音频跟着应用一起离线下发,反而更接近真实使用方式。
3.2 数据模型怎么设计
当前工程里的任务模型如下:
ts
export interface OralContent {
title: string,
estimated: string,
deviceCount: number,
scene: string,
tips: string,
sentences: SentenceMedia[]
}
export interface SentenceMedia {
content: string,
audio: string,
device: string,
intent: string
}这个结构的价值不在于抽象多高级,而在于它把页面从"录音工具页"往"问题排查页"拽了一步。因为一条任务不再只有一句文本,还带着参考音频、设备信息、意图信息、场景说明。这样一来,页面展示的就不再只是"说一句话",而是"针对某个设备的某条命令做一次完整采样和校验"。
3.3 任务初始化为什么要围绕索引展开
页面初始化阶段,当前实现是这样做的:
ts
aboutToAppear(): void {
this.avRecorderManager = new AVRecorderManager();
this.avPlayerManager = new AVPlayerManager();
this.asrRecognizerManager = new AsrRecognizerManager();
let resourceManager = this.getUIContext().getHostContext()?.resourceManager;
if (resourceManager) {
this.oralContent = RawfileUtil.readDataFromRawfile(resourceManager);
}
if (this.oralContent) {
let sentenceCount = this.oralContent.sentences.length;
this.recordFiles = new Array(sentenceCount).fill('');
this.asrTexts = new Array(sentenceCount).fill('');
this.asrScores = new Array(sentenceCount).fill(0);
this.asrPhases = new Array(sentenceCount).fill('idle');
this.asrErrors = new Array(sentenceCount).fill('');
}
}这里比较对的一点,是所有结果状态都按任务索引展开。这意味着sentences是主数据,录音结果、识别结果、得分状态都是附着在每条任务上的结果数据。这种写法非常适合中等复杂度的工具页,逻辑不会飘,也方便后面按任务维度做回放和复盘。
四、核心链路落地:同一份PCM同时服务波形、WAV落盘和ASR
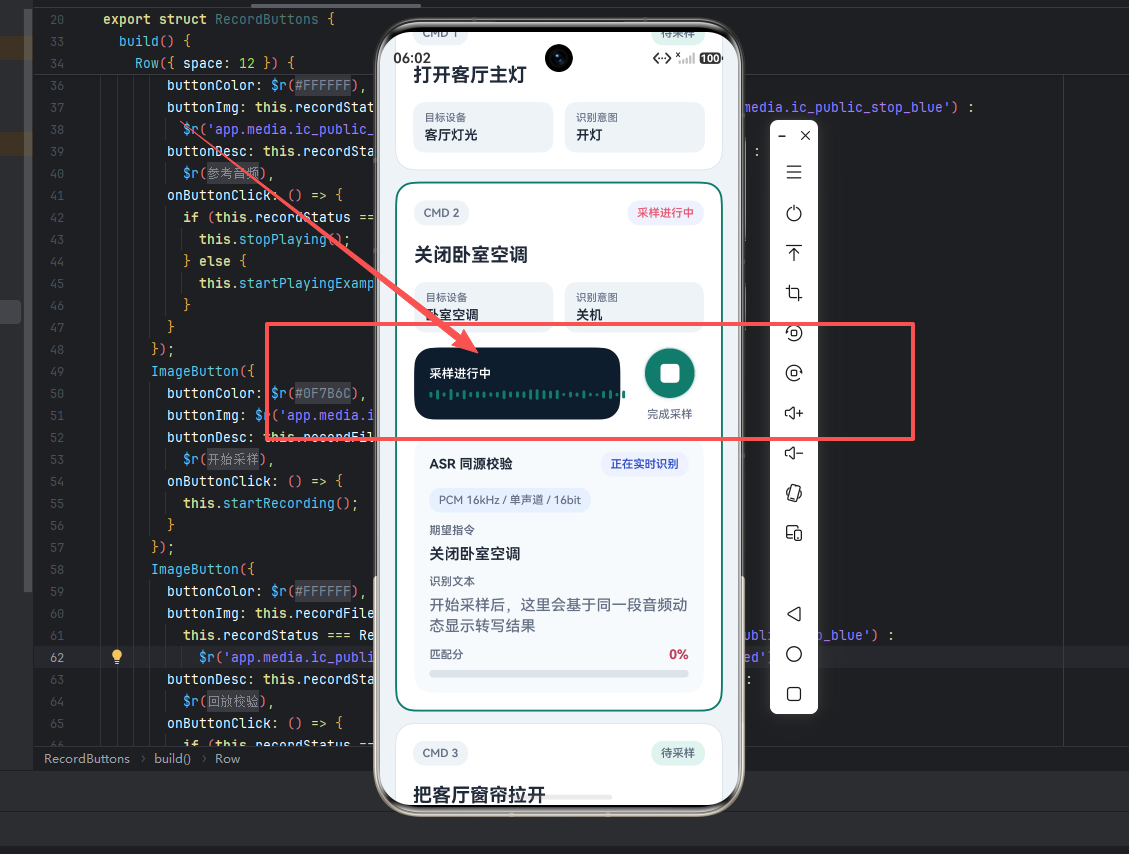
过去很多初学者写音频处理逻辑时,会有一个隐藏问题:录音走一套逻辑,ASR校验再走一套逻辑。表面上两边都能跑,实际上它们看见的不是同一份音频。这种实现拿来演示可以,拿来做问题排查价值很有限。
4.1 录音规格为什么要先对齐
当前工程里,录音器不是走压缩录制,而是直接用AudioCapturer采原始PCM:
ts
private readonly streamInfo: audio.AudioStreamInfo = {
samplingRate: audio.AudioSamplingRate.SAMPLE_RATE_16000,
channels: audio.AudioChannel.CHANNEL_1,
sampleFormat: audio.AudioSampleFormat.SAMPLE_FORMAT_S16LE,
encodingType: audio.AudioEncodingType.ENCODING_TYPE_RAW
};
private readonly capturerInfo: audio.AudioCapturerInfo = {
source: audio.SourceType.SOURCE_TYPE_MIC,
capturerFlags: 0
};
private readonly capturerOptions: audio.AudioCapturerOptions = {
streamInfo: this.streamInfo,
capturerInfo: this.capturerInfo
};这一层如果不先对齐,后面不是得解码,就是得转码,链路复杂度会立刻上来。
4.2 为什么要自己补WAV头
前面说过,采样时要原始PCM,但结果文件又需要可回放。当前实现用的办法,就是录制时写PCM数据,落盘时补WAV头:
ts
private createWaveHeader(dataLength: number): ArrayBuffer {
let header = new ArrayBuffer(WAV_HEADER_LENGTH);
let view = new DataView(header);
let byteRate = PCM_SAMPLE_RATE * PCM_CHANNEL_COUNT * PCM_BITS_PER_SAMPLE / 8;
let blockAlign = PCM_CHANNEL_COUNT * PCM_BITS_PER_SAMPLE / 8;
this.writeAscii(view, 0, 'RIFF');
view.setUint32(4, 36 + dataLength, true);
this.writeAscii(view, 8, 'WAVE');
this.writeAscii(view, 12, 'fmt ');
view.setUint32(16, 16, true);
view.setUint16(20, 1, true);
view.setUint16(22, PCM_CHANNEL_COUNT, true);
view.setUint32(24, PCM_SAMPLE_RATE, true);
view.setUint32(28, byteRate, true);
view.setUint16(32, blockAlign, true);
view.setUint16(34, PCM_BITS_PER_SAMPLE, true);
this.writeAscii(view, 36, 'data');
view.setUint32(40, dataLength, true);
return header;
}这一步做完以后,这份录音既保留了识别侧需要的原始规格,又能直接进入回放链路。
4.3 一次采样,三路消费
真正把事情串起来的是handleReadData:
ts
private handleReadData(buffer: ArrayBuffer) {
// 1. 计算振幅,驱动波形
this.currentAmplitude = Math.max(this.currentAmplitude, this.calculateAmplitude(buffer));
// 2. 把同一份PCM往上送,给ASR实时消费
this.onPcmData?.(buffer);
if (this.fileFd === undefined) {
return;
}
// 3. 把这段PCM写进本地WAV文件
let writeOffset = WAV_HEADER_LENGTH + this.recordedBytes;
this.recordedBytes += buffer.byteLength;
let writeOptions: WriteOptions = {
offset: writeOffset,
length: buffer.byteLength
};
this.pendingWrite = this.pendingWrite.then(async () => {
if (this.fileFd === undefined) {
return;
}
await fileIo.write(this.fileFd, buffer, writeOptions);
}).catch((error: BusinessError) => {
LOGGER.error(`Failed to write PCM buffer. Code: ${error.code}, message: ${error.message}`);
});
}这段代码的价值非常直接:
- 波形看的是这段音频
- 落盘存的是这段音频
- ASR识别的还是这段音频
一次麦克风采集,同时服务三条后续链路。这就是"同源"的工程基础。
4.4 收尾逻辑为什么比开始逻辑更容易出问题
录音结束时,如果只会停录音,不会收尾,后面现场一频繁操作就会暴露问题。
当前实现里的结束逻辑是这样收的:
ts
private async finishCurrentRecording(notifyFinished: boolean) {
this.clearTimer();
let finishedPath = this.filePath;
if (this.audioCapturer &&
(this.audioCapturer.state === audio.AudioState.STATE_RUNNING ||
this.audioCapturer.state === audio.AudioState.STATE_PAUSED)) {
await this.audioCapturer.stop();
}
await this.pendingWrite;
await this.finalizeWaveFile();
if (this.audioCapturer &&
this.audioCapturer.state !== audio.AudioState.STATE_RELEASED &&
this.audioCapturer.state !== audio.AudioState.STATE_NEW) {
await this.audioCapturer.release();
}
this.audioCapturer = undefined;
await this.closeFile();
this.filePath = '';
this.recordedBytes = 0;
this.tickCount = 0;
this.currentAmplitude = 0;
this.pendingWrite = Promise.resolve();
this.onPcmData = undefined;
AppStorage.setOrCreate('recordStatus', RecordStatus.IDLE);
if (notifyFinished && finishedPath) {
this.onRecordingFinish(finishedPath);
this.onRecordingFinish = () => {};
}
}这类代码平时不显眼,但项目里最容易出问题的,恰恰就是文件句柄、异步写入、状态重置、回调清理这些边界。
五、接第三方ASR时,为什么一定要做"同源校验"
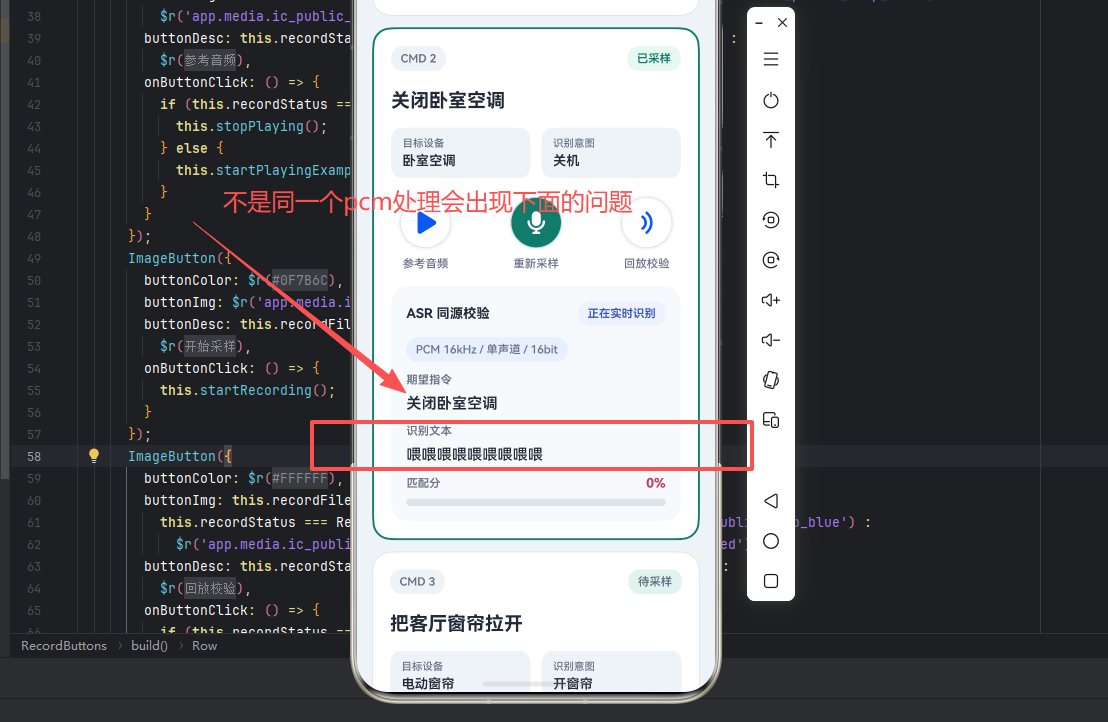
说到ASR,这次实现里我最想强调的一点就是:不要让校验链路重新开一支麦克风。
因为现场排查时,真正想看的不是"用户现在再说一遍,ASR识别得怎么样",而是"刚刚录下来的那段样本,ASR最终识别成了什么"。
5.1 AsrRecognizerManager只负责会话,不负责采音
所以当前工程里,AsrRecognizerManager的职责被我压得很窄。它不再拥有自己的采集器,只管识别会话:
ts
export class AsrRecognizerManager {
private engine?: speechRecognizer.SpeechRecognitionEngine;
private currentSessionId: string = '';
private callbacks?: AsrRecognitionCallbacks;
private finishRequested: boolean = false;
async startRecognition(callbacks: AsrRecognitionCallbacks) {
await this.ensureEngine();
if (!this.engine) {
callbacks.onError?.('ASR engine unavailable');
return;
}
if (this.currentSessionId) {
await this.stopRecognition(false);
}
this.callbacks = callbacks;
this.finishRequested = false;
this.currentSessionId = `asr_${Date.now()}`;
let audioInfo: speechRecognizer.AudioInfo = {
audioType: 'pcm',
sampleRate: 16000,
soundChannel: 1,
sampleBit: 16
};
let startParams: speechRecognizer.StartParams = {
sessionId: this.currentSessionId,
audioInfo: audioInfo,
extraParams: {
'recognitionMode': 0,
'vadBegin': 2000,
'vadEnd': 1500,
'maxAudioDuration': 20000
}
};
this.engine.startListening(startParams);
}
}这里最关键的不是参数多复杂,而是它和录音侧吃的是同一套PCM规格。
5.2 识别真正消费的是录音器送上来的那段PCM
真正把录音链路和识别链路接起来的是这段:
ts
writeAudio(buffer: ArrayBuffer) {
if (!this.engine || !this.currentSessionId || this.finishRequested) {
return;
}
this.engine.writeAudio(this.currentSessionId, new Uint8Array(buffer));
}也就是说,ASR看到的音频,不是它自己重新采的一遍,而是录音器刚刚拿到的那段数据。
5.3 页面层怎么把录音和ASR串成一个流程
页面开始采样时,会先拉起ASR会话,再启动录音,并在录音过程中把每一帧PCM送进识别引擎:
ts
startRecording: async () => {
if (this.recordStatus === RecordStatus.PLAYING_RECORD ||
this.recordStatus === RecordStatus.PLAYING_EXAMPLE) {
await this.avPlayerManager?.stopAudio();
}
await this.startAsrSession(sentence, index);
this.avRecorderManager?.setRecordingFinishedCallback((filePath) => {
this.recordFiles[index] = filePath;
this.amplitude = 0;
this.asrRecognizerManager?.stopRecognition();
});
let started = await this.avRecorderManager?.startRecordingProcess(
this.getUIContext(),
index,
(amplitude) => {
this.getUIContext().animateTo({
curve: Curve.EaseInOut,
duration: AMPLITUDE_INTERVAL
}, () => {
this.amplitude = amplitude / AMPLITUDE_MAX * AMPLITUDE_MAX_HEIGHT;
});
},
(buffer: ArrayBuffer) => {
this.asrRecognizerManager?.writeAudio(buffer);
}
);
if (!started) {
this.amplitude = 0;
await this.asrRecognizerManager?.stopRecognition(false);
}
}这段逻辑放回业务语境里,就是一句话:本次采样、本次波形、本次落盘、本次ASR,全部指向同一份音频。
这才叫"校验本次样本"。
5.4 动态识别度对比为什么先用轻量方案
当前Demo里没有上复杂评测体系,而是用了一个轻量方案:规范化文本,再做编辑距离,最后转成一个0到1的相似度。
ts
export class SimilarityUtil {
static calculateSimilarity(expected: string, actual: string): number {
let expectedText = SimilarityUtil.normalize(expected);
let actualText = SimilarityUtil.normalize(actual);
if (!expectedText.length || !actualText.length) {
return 0;
}
let distance = SimilarityUtil.levenshteinDistance(expectedText, actualText);
let maxLength = Math.max(expectedText.length, actualText.length);
return Math.max(0, 1 - distance / maxLength);
}
}它当然不是正式评测指标,但放在排查工具里很好用。因为我们现在只是想快速回答一个问题:这条样本和预期偏得厉不厉害,要不要重录。
六、页面状态管理:这类小工具最怕状态机有问题
这个页面的功能点其实不多:
- 播放参考音频
- 开始采样
- 停止采样
- 回放本地录音
- 展示ASR结果和识别度
真正容易出问题的,从来不是这些按钮本身,而是它们撞在一起的时候怎么办。
6.1 为什么音频页最容易在边界场景里乱
比如:
- 参考音频还在播,用户已经点了开始采样
- 正在采样,用户切到另一条指令
- 正在回放,页面进后台了
- ASR还没结束,录音先失败了
这些场景如果不收,页面很容易出现一种假稳定:UI看着没问题,底层资源其实已经乱了。
6.2 当前页面是怎么收状态的
当前工程里,核心状态很少,主要就是:
- currentIndex
- recordStatus
- recordFilesindex
- asrTexts / asrScores / asrPhases / asrErrors
其中RecordStatus定义得很克制:
ts
export enum RecordStatus {
IDLE,
RECORDING,
PLAYING_EXAMPLE,
PLAYING_RECORD
}卡片顶部状态文案也是从这些事实状态里推出来的:
ts
getStatusText(index: number): ResourceStr {
if (this.isActiveCard(index)) {
switch (this.recordStatus) {
case RecordStatus.RECORDING:
return $r('app.string.sampling_recording');
case RecordStatus.PLAYING_EXAMPLE:
return $r('app.string.sampling_playing_reference');
case RecordStatus.PLAYING_RECORD:
return $r('app.string.sampling_playing_record');
default:
break;
}
}
return this.recordFiles[index]
? $r('app.string.sampling_done')
: $r('app.string.sampling_pending');
}这种写法的好处很实际:不会越写越多布尔值,也不容易出现状态互相打架。
6.3 生命周期里的清理逻辑为什么不能省
最后,页面生命周期里的清理一定要交代清楚:
ts
onPageHide(): void {
if (this.avRecorderManager && this.recordStatus === RecordStatus.RECORDING) {
this.avRecorderManager.stopRecordingProcess();
}
if (this.avPlayerManager && (
this.recordStatus === RecordStatus.PLAYING_RECORD ||
this.recordStatus === RecordStatus.PLAYING_EXAMPLE
)) {
this.avPlayerManager.stopAudio();
}
this.asrRecognizerManager?.stopRecognition(false);
}
aboutToDisappear(): void {
this.avRecorderManager?.releaseRecorder();
this.avPlayerManager?.releasePlayer();
this.asrRecognizerManager?.release();
}常见问题排查与总结
Q1:录音文件无法播放
- 检查WAV头写入是否正确(采样率、声道数、位深是否与PCM数据匹配)
- 确认finalizeWaveFile在录音结束时被调用
- 确认dataLength字段是否填写了正确的PCM数据大小
Q2:ASR识别结果与预期偏差大
- 确认ASR消费的PCM规格(16kHz/单声道/16bit)与录音规格一致
- 检查writeAudio是否在录音过程中持续调用,而非仅结束时发送一次
- 检查ASR引擎的vadBegin/vadEnd参数是否与语速匹配
Q3:页面状态混乱(如停止录音后UI仍显示录制中)
- 检查RecordStatus枚举值是否在所有分支中被正确更新
- 确认finishCurrentRecording中的notifyFinished回调被正确触发
- 检查AppStorage.setOrCreate('recordStatus', RecordStatus.IDLE)是否被执行
Q4:多次录制后无法再次开始录音
- 检查AudioCapturer是否被正确release()并重置为undefined
- 确认文件句柄fileFd在每次录制结束后被关闭
- 检查pendingWrite Promise链是否被正确清空
Q5:波形显示异常(不动或跳动不规则)
- 确认calculateAmplitude函数的算法是否正确(通常是对PCM采样点取绝对值后平均)
- 检查波形刷新频率是否与handleReadData回调频率匹配
- 确认振幅归一化系数是否适配当前位深(16bit最大值32768)
如果早把这个小工具带到现场,我就能当场验证:
- 采样规格对不对?看录制的WAV文件属性
- 环境噪声大不大?回放录音可以回传到远端测试
- ASR是不是吃到了同一份音频?同源消费,链路透明
这就是"同源校验"的价值------不是在猜问题出在哪,而是用一条完整的链路证明:音频从麦克风到ASR,全程没走样。
就像快递单上的每一个环节都能对上------收件人收到的,就是寄件人发出的那个原包裹。