我们当时搞的购物车服务,其实还是有点庞大的,看似是一个简单的CRUD,但是当你真正去实现一个购物车的时候,发现压根不是那回事。
当商品类型从单一SKU扩展到普通商品、套餐组合、活动商品,拼单等混合的时候,一次加购操作从校验库存、加载促销规则、计算包装费、调用结算中心到最后持久化,涉及十几个步骤,有的能并行有的必须串行,有的允许失败有的必须成功。把这些逻辑全堆在一个Service方法里,维护性不好。
这篇文章聊的就是怎么从架构层面解决这些问题:用什么样的引擎来编排这些业务流程、购物车数据怎么存才能扛住千万级并发、以及不同类型的购物车如何共享一套基础设施。
后续我会单独出专栏,把每个模块的实现细节拆开来讲。这篇文章只聊架构设计思路,不会涉及太多代码细节。
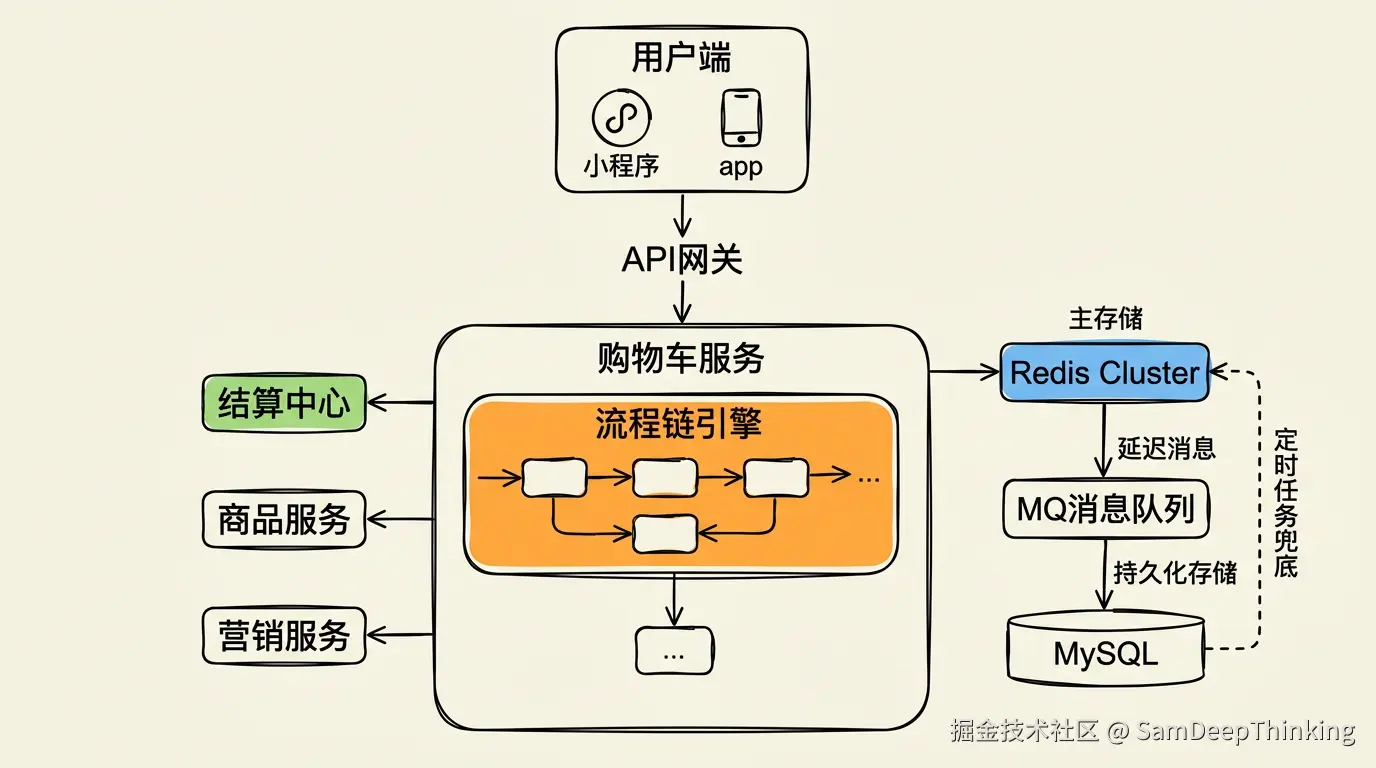
全局概览
先给一个整体视角。购物车服务在整个电商链路中的位置,大致是这样的:
用户端(小程序/App)的所有购物车操作,经过网关后打到购物车服务。购物车服务内部的核心逻辑由流程链引擎驱动,数据主存储在Redis Cluster,通过MQ异步持久化到MySQL。购物车不做价格计算,价格相关的逻辑全部下沉到结算中心,购物车通过RPC调用结算中心拿到最终价格。商品信息、库存状态、促销规则这些数据,则通过RPC调用商品服务和营销服务获取。
几个关键的架构决策:
- Redis Cluster作为数据主存储,不是缓存。购物车的所有读写操作直接打Redis,不经过MySQL
- MQ异步落库到MySQL,作为数据持久化层和BI分析数据源
- 流程链引擎编排所有业务逻辑,每种购物车操作(加购、勾选、查详情、结算)对应一条独立的流程链
- 结算中心解耦,购物车只管理商品组合,不涉及价格计算
下面逐个展开讲。
流程链引擎
为什么不能把逻辑写在Service方法里
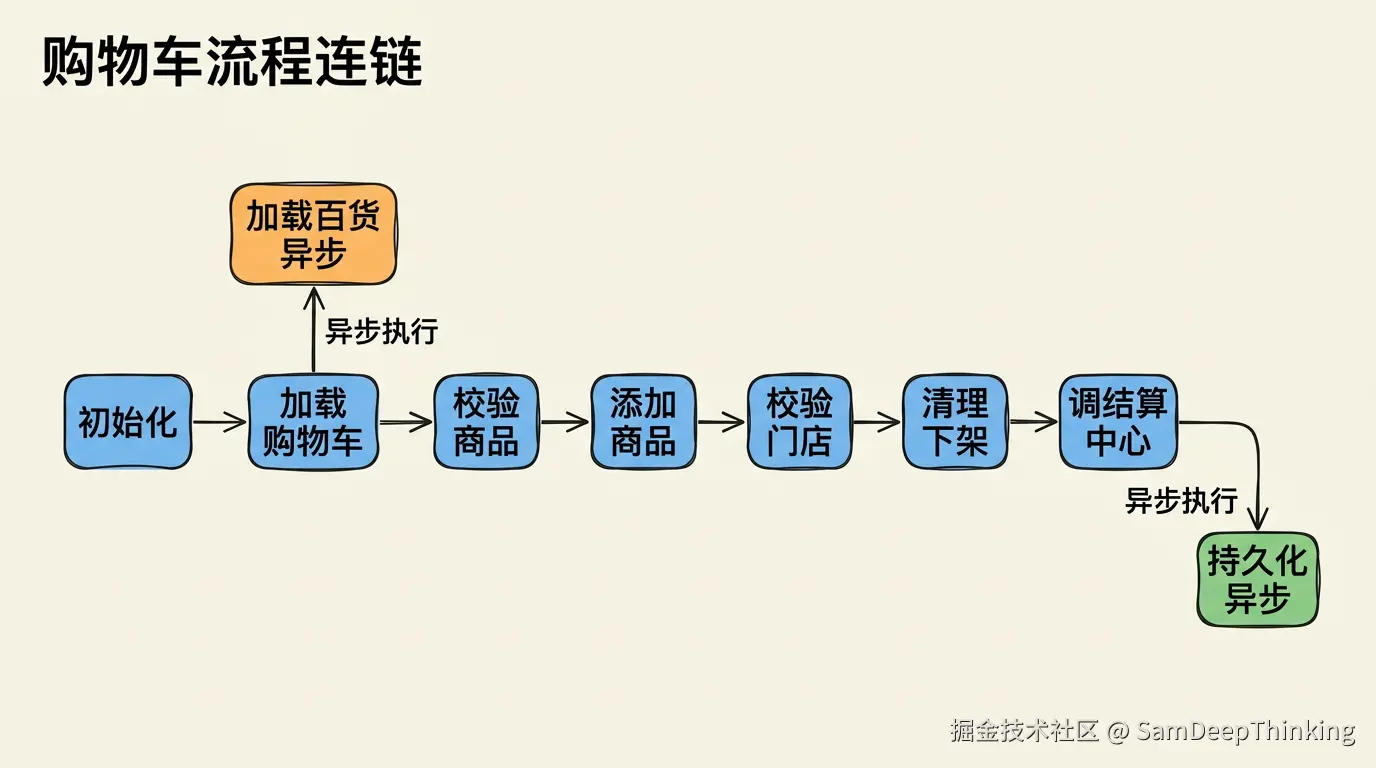
一个加购操作的完整流程大概是这样:初始化上下文 → 加载购物车数据 → 校验商品是否可售 → 构建商品单元 → 加载关联商品(异步)→ 清洗无效商品 → 添加商品到购物车 → 校验门店状态(等待异步完成)→ 清理下架商品 → 处理包装费 → 加载促销规则 → 调用结算中心 → 异步持久化。
十几个步骤。如果写在一个方法里,至少三个问题:
第一,不同操作之间的步骤有大量重叠。加购和勾选共享80%的步骤,只有中间几步不一样。写在方法里就得if-else区分,改一个步骤怕影响另一个操作。
第二,有些步骤之间有并行机会。比如加载关联商品和清洗当前购物车商品,这两件事互不依赖,可以并行执行。写在方法里很难优雅地处理这种并行依赖关系。
第三,保存购物车这个步骤不需要阻塞请求返回。用户点了加购,购物车数据写Redis成功就可以返回了,持久化可以异步做。这种同步异步混合的执行策略,在普通的Service方法里很难表达。
所以需要一个流程编排引擎来解决这三个问题:步骤复用、并行执行、同步异步混合。
流程链的核心抽象
整个引擎只有两个核心概念:处理节点和处理链。
处理节点定义了一个步骤该做什么:
Java
public interface ProcessNode<T extends ContextRule> {
default boolean isEnable(T context) { return true; }
boolean execute(T context);
default String getName() { return this.getClass().getSimpleName(); }
}处理链负责编排这些节点的执行顺序和方式:
Java
new ProcessChain<EditContext>("加购")
.context(new EditContext(user, form, cartKey))
.sync(initNode).sync(loadCartNode).sync(validateItemNode)
.async(1, loadRelatedItemsNode)
.sync(addItemNode).sync(checkShopNode, 1)
.async(persistCartNode).done();sync()是同步执行,按顺序一个个走。async(1, node)是异步执行,丢到线程池里跑,数字1是这个异步任务的编号。sync(node, 1)表示这个同步节点执行之前,先等编号1的异步任务完成。
这样就解决了前面说的三个问题:
步骤复用:每个处理节点是独立的Spring Bean,哪条链需要就组装进去,不需要就不放。
并行执行:有依赖关系的用编号等待,无依赖的直接并行。比如查购物车详情时,加载关联商品(async 1)、清洗关联数据(async 2, 等待1)、清洗普通商品(async 3)三个异步任务可以并行,后面的校验门店状态(sync, 等待1,2,3)会等这三个都完成再执行。
同步异步混合:保存购物车用async()不带编号(或负编号),意味着链结束时不等它完成。用户请求返回了,后台默默把数据持久化。
不同操作的流程链编排对比
这是四种核心购物车操作各自的流程链步骤,可以看到共享基础设施的程度:
| 流程步骤 | 加购 | 勾选 | 查详情 | 结算 |
|---|---|---|---|---|
| 初始化上下文 | 同步 | 同步 | 同步 | 同步 |
| 加载下架数据 | 同步 | 同步 | 同步 | 同步 |
| 加载购物车 | 同步 | 同步 | 同步 | 同步 |
| 校验商品可售 | 同步 | - | - | - |
| 构建商品单元 | 同步 | - | - | - |
| 处理勾选状态 | - | 同步 | - | - |
| 加载关联商品 | 异步 | 同步 | 异步 | 异步 |
| 清洗无效商品 | 同步 | 同步 | 异步 | 同步 |
| 添加到购物车 | 同步 | - | - | - |
| 校验门店状态 | 同步(等待异步) | 同步 | 同步(等待全部异步) | 同步 |
| 清理下架商品 | 同步 | 同步 | 同步 | 同步 |
| 处理包装费 | 同步 | 同步 | 同步 | 同步 |
| 加载促销规则 | 同步 | 同步 | 同步 | 同步 |
| 调用结算中心 | 同步 | 同步 | 同步 | 同步 |
| 持久化 | 异步(不等待) | 异步(不等待) | 异步(不等待) | 异步(不等待) |
加购链最长,有15个步骤。查详情链用了更多的异步并行,因为它不修改数据,多个读操作可以安全地并发执行。所有操作链都把持久化放在最后一步异步执行,不阻塞用户请求。
这张表也是我判断这套架构是否合理的依据:如果大部分步骤只在一种操作中出现,说明拆分粒度太细了,不如直接写在方法里;如果大部分步骤在所有操作中都出现,说明复用率高,流程链引擎的收益明显。从表中看,大约60%的步骤被多种操作共享,这个比例说明引擎化是值得的。
Redis主存储与异步落库
为什么选Redis做主存储
购物车数据放Redis还是MySQL,这不是一个见仁见智的问题,在千万级用户体量下答案很明确:Redis。
原因有三个:
第一,购物车是写多读多的场景。用户每加一个商品、改一次数量、选一次规格,都是一次写操作。高峰期(比如大促或者新品上线)写入QPS可能到数万级,MySQL单实例的写入能力大约在几千到万级TPS,分库分表能提升但架构复杂度剧增。
第二,购物车数据结构天然适合Redis Hash。一个用户的购物车可以用一个Hash表示,field是商品类型(普通商品、套餐、包装),value是对应的JSON数组。加购就是读出来、追加、写回去,Redis Hash的hget/hset操作是O(1)的。
第三,购物车数据有过期属性。90天没操作的购物车可以直接过期清理,Redis天然支持TTL。MySQL要做这种清理需要额外的定时任务扫描删除。
实际的存储结构大致是这样:
Java
Key: cart:user:{userId}
Fields: product_item → [商品列表JSON]
combo / package → {对应类型JSON}
version → 版本号, timestamp → 最近操作时间每个用户一个Hash Key,不同类型的商品放在不同的field里。个人购物车TTL设为90天,拼单购物车TTL设为1天。
Redis Cluster的选型决策
Redis有三种部署模式:主从复制、哨兵、集群。千万级用户场景选哪个,需要算两笔账。
先算存储量,这是选Cluster最直接的理由。 千万用户不是所有人都有购物车数据,按30%活跃率算,300万个购物车Hash。每个Hash平均大小约5KB(包含几件到十几件商品的JSON),总共约15GB。考虑到Redis内存碎片和数据结构开销,实际内存占用大约是原始数据的1.52倍,按30GB估算。如果按全量千万用户算,原始数据50GB,实际占用75100GB。
问题出在RDB持久化。Redis做RDB快照时会fork子进程,fork瞬间需要复制页表,写时复制(COW)机制下如果写入频繁,父子进程的内存占用会逐渐接近两倍。一台128GB的机器,跑100GB的Redis实例,RDB触发时内存大概率不够用。要么关RDB只用AOF(丢数据风险增大),要么限制单实例容量在机器内存的一半以下。无论哪种,单实例在这个数据量级下都很勉强。
再看写入QPS。 千万用户中日活假设20%(200万),每人每天平均操作购物车3次,就是600万次写操作/天。均摊下来约70次/秒。高峰时段集中了一天50%的流量,假设集中在4小时内,高峰期平均约200/s,尖峰秒级可能到千级别。大促期间DAU和人均操作都会翻倍,尖峰QPS可能到几千。
单master对简单命令的理论吞吐是10万+/s,但购物车用的是HGET/HSET操作5KB左右的value,实际吞吐大概在3~5万/s。日常几千的峰值,单master是扛得住的。选Cluster不是因为单master的QPS不够,而是因为存储量撑不住单实例。既然存储已经需要分片了,写入能力的线性扩展就是附带的收益,大促场景下不需要担心单点瓶颈。
| 部署模式 | 写能力 | 存储容量 | 自动故障转移 | 水平扩展 | 适用规模 |
|---|---|---|---|---|---|
| 主从复制 | 单主写入,有上限 | 单机内存 | 无,需人工介入 | 不支持 | 百万以下 |
| 哨兵模式 | 单主写入,有上限 | 单机内存 | 有 | 不支持 | 百万级 |
| Cluster集群 | 多主分片写入 | 多节点叠加 | 有 | 支持 | 千万级及以上 |
结论:千万级用户建议上Cluster。
Cluster把16384个哈希槽分散到多个master节点,存储和写入压力都被分摊。购物车场景用Cluster还有一个天然优势:购物车数据按用户ID隔离,不存在跨用户的事务需求。用户ID做Hash分片后,同一个用户的数据一定落在同一个slot,不会出现跨slot操作。这和订单系统不一样(订单可能需要按商家维度做跨用户查询),购物车是天生适合Cluster分片的业务。
实际部署建议6节点起步(3主3从),每个master分配约20GB内存。业务量上涨后平滑扩展到9节点或12节点即可,不需要改应用代码。
Redis数据为什么必须落库
Redis虽然有RDB和AOF持久化机制,但指望它当唯一存储是有风险的:
- 集群故障切换时,主从切换可能丢几秒的写入数据
- 运维失误(误执行FLUSHDB)、机器硬件故障,都可能导致数据丢失
- 客服需要恢复用户购物车数据,从Redis里不方便查
- 运营和BI团队需要分析用户的加购行为、购物车转化率,必须有结构化的MySQL数据
京东的购物车系统也是类似架构:Redis作为主存储承接读写,MySQL作为持久化存储做兜底和分析。异步双写,对短暂的写入延迟有一定容忍度。
异步落库方案的技术选型
怎么把Redis的数据同步到MySQL?三种方案摆在面前:
| 方案 | 实时性 | 可靠性 | 实现复杂度 | 适用场景 |
|---|---|---|---|---|
| MQ实时异步 | 秒级延迟 | MQ故障时有风险 | 中等 | 对跨端一致性有要求 |
| 定时任务扫描 | 分钟级延迟 | 有时间窗口风险 | 简单 | 可接受分钟级延迟 |
| 混合方案(MQ + 定时兜底) | 秒级 | 最高 | 较高 | 大厂生产环境 |
我最开始倾向于定时任务,因为实现简单,购物车数据不像订单那样对丢失零容忍。后来在生产环境碰到一个问题:用户在手机上加了3件商品,切到电脑上打开发现购物车是空的。定时任务还没跑到,MySQL里没有最新数据,而电脑端走了降级逻辑从MySQL读取。对用户来说这就是Bug。
购物车跨端一致性的要求,决定了必须用实时异步。 但MQ本身也可能挂,所以最终选了MQ + 定时任务兜底的混合方案。正常链路走MQ,几秒内落库;MQ挂了或者消费失败,定时任务每5分钟扫一次,对比Redis和MySQL中购物车的version字段,不一致的重新同步。
有人会问:MQ和定时任务都上,是不是过度设计?
不是。定时任务的角色是保险绳,正常情况下它什么都不做(对比version发现一致就跳过)。只在MQ链路出故障时才生效。这两套机制的职责不重叠:MQ负责实时,定时任务负责兜底。维护成本可接受。
高频操作的写合并
这里有一个容易被忽略的问题:用户在购物车里加1、减1、再加1,3秒内可能操作5次。如果每次操作都立刻发MQ,一个用户一天操作20次购物车,千万活跃用户就是两亿条MQ消息。数据库也扛不住这种写入频率。
核心认知:购物车只需要持久化最终状态,中间状态没有业务意义。
用户把数量从1改到2再改到3,MySQL里只需要最终值3,中间的变化过程不需要记录。这和订单不一样,订单的每次状态变更都有业务含义,购物车没有。
基于这个认知,写合并策略有三种选择:
| 策略 | 原理 | 延迟 | MQ流量削减效果 |
|---|---|---|---|
| 延迟消息合并 | 操作后发延迟5秒的MQ消息,消费时读Redis最新状态 | 5秒 | 5秒内N次操作→1次落库 |
| 脏标记 + 定时刷盘 | 写Redis时打dirty标记,定时扫描批量落库 | 3~10秒 | N次操作→1次落库 |
| 本地攒批 + 定时提交 | 应用内存攒变更,到阈值后批量发MQ | 可控 | 攒批期间→1次落库 |
我选延迟消息。做法是:用户每次操作购物车写Redis成功后,检查一个expire为5秒的标记key(cart:sync:{userId})。如果这个key不存在,发一条延迟5秒的MQ消息并设置标记key;如果key已存在,说明5秒内已经发过消息了,跳过。
5秒后消费者收到消息,从Redis读取当前最新状态,一次性写入MySQL(replace into全量覆盖)。不管中间用户操作了多少次,落库只有最终状态。
为什么不选脏标记方案?两个原因:第一,脏标记需要额外维护一个dirty集合,定时任务扫描这个集合时如果用户量大会有热点问题;第二,定时任务的写入是批量的、周期性的,每隔几秒一波写入打到数据库,对MySQL不够友好。延迟消息的写入天然是分散的(每个用户的5秒倒计时起点不同),数据库压力更均匀。
降级策略
任何依赖外部组件的架构都需要考虑挂了怎么办:
Redis Cluster全挂:概率极低但必须有预案。自动降级到MySQL直读直写,QPS承接能力下降但业务不中断。恢复后从MySQL预热数据回Redis。
MQ挂了:Redis继续正常服务(主存储不受影响),定时任务兜底落库,用户无感知。MQ恢复后积压的消息自动消费。
MySQL挂了:对用户无影响(用户请求只走Redis),但异步落库会暂停。MQ消息堆积,MySQL恢复后自动消费堆积消息补数据。
多类型购物车的抽象
这套购物车系统不只服务一种场景。有个人购物车(一个人自己下单)、拼单购物车(多人拼一单)、团餐购物车(企业团餐)。三种购物车的业务逻辑差异很大,但底层的流程链引擎和Redis存储方案是共享的。
| 购物车类型 | 存储Key模式 | 过期时间 | 写入者 | 结算方式 |
|---|---|---|---|---|
| 个人购物车 | cart:user:{userId} | 90天 | 单人 | 独立结算 |
| 拼单购物车 | cart:spell:{roomId}:{userId} | 1天 | 多人各写各的 | 合并结算 |
| 团餐购物车 | cart:group:{userId} | 90天 | 单人 | 团餐结算 |
三种购物车共享相同的流程链基础设施(ProcessChain + ProcessNode),但各自组装不同的流程节点。比如拼单购物车额外需要一个「同步房间版本号」的节点,团餐购物车需要一个「校验团餐菜单」的节点,这些节点在个人购物车链中不存在。
这种设计的好处是:新增一种购物车类型时,不需要从零开始。创建一个新的Service实现,组装需要的流程节点,定义自己的Redis Key模式,就完成了。共享的节点(如调用结算中心、持久化、清洗下架商品)直接复用,只需要写差异化的节点。
与结算中心的协作
购物车系统有一个明确的职责边界:只管理商品组合,不做价格计算。
用户在购物车里看到的价格、优惠、满减金额,都不是购物车自己算的。购物车的流程链中有一个节点专门做这件事:把当前购物车里的商品列表和用户信息打包,通过RPC调用结算中心,结算中心返回每件商品的最终价格和优惠明细。
为什么要这样拆分?因为价格计算的规则复杂度远高于购物车本身。满减、折扣、优惠券叠加、会员价、限时特价,这些规则的排列组合和优先级处理,如果放在购物车服务里,购物车会变成一个巨无霸。结算中心独立出来后,购物车的代码量和复杂度控制在一个合理范围内。
降级策略:结算中心超时或不可用时,购物车返回商品原价,并在前端标注「促销信息加载中」。用户能看到购物车内容,只是价格暂时不准确。等结算中心恢复后刷新即可。这比购物车整个不可用要好。
小结
购物车系统的架构设计,核心不在于用了什么技术组件,而在于几个关键判断:
第一个判断是购物车数据的特性。购物车是整体性数据,每次修改都是全量覆盖。用户加了一件商品,实际是把整个购物车读出来、追加一件、整体写回去。这个特性决定了它的一致性要求比订单低得多,可以接受最终一致性,可以用延迟消息做写合并。如果你的业务数据也有类似的「全量覆盖」特性,很多架构方案可以直接复用。
第二个判断是流程编排的投入产出比。不是所有业务都需要自研流程引擎。判断标准很简单:如果你的核心操作超过8个步骤,且不同操作之间共享超过50%的步骤,引擎化的收益就是正的。如果只有三五个步骤或者每种操作完全独立,直接写方法反而更清晰。
第三个判断是存储架构跟着数据量走。Redis Cluster不是因为它先进才选,是因为千万级用户的存储量和写入QPS算下来,单master撑不住。如果你的用户量在百万以下,哨兵模式完全够用。架构选型不是选最强的,是选刚好够用且留有余量的。
购物车看起来简单,但它是「简单的接口、复杂的内部」的典型代表。 好的架构不是把它变复杂,而是用合理的抽象把复杂度管理起来,让每一层看起来都是简单的。
渠道发布
最近在知乎出了「应付6000万会员的秒杀系统专栏」和「几亿用户,百万并发的C端商品系统实战」专栏,感兴趣的可以订阅一下。至于知识星球的,可以搜:
- 老码头的技术浮生录
它是一个能实际帮你解决难题的星球。有问题的,找知心的Sam哥,支持无限次语音一对一解决你遇到的难题。「另外后续我新写的所有对外的付费专栏,在星球内都是免费的,且可以拿到所有源代码。」
知识星球内后续将推出20+个付费专栏,覆盖电商全链路:
| 选购线 | 用户会员营销线 | 中后台 |
|---|---|---|
| 购物车服务 | 营销系统 | 订单系统 |
| 商品服务 | 用户系统 | 支付系统 |
| 菜单服务 | 结算服务 |
从前台选购到中后台结算,星球成员全部免费,后续新增也不额外收费。
我的知乎账号:
- SamDeepThinking