文章目录
前置知识
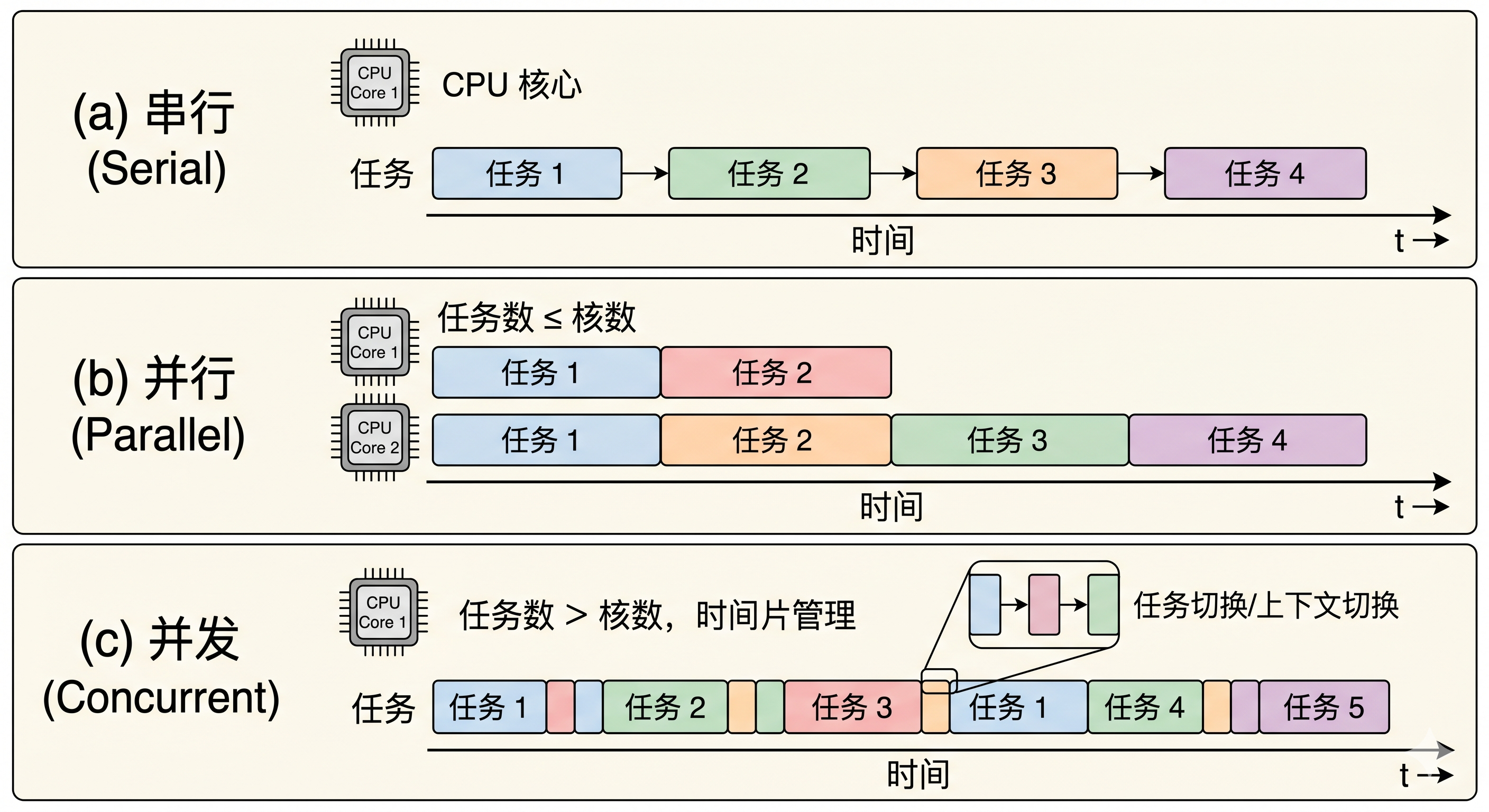
串行、并行、并发
- 串行:一个CPU上,按顺序完成多个任务。
- 并行:指的是任务数小于等于CPU核数,即任务真的可以一起执行。
- 并发:一个CPU采用时间片管理方式,交替地处理多个任务。一般是任务多于CPU核数,通过操作系统地各种任务调度算法,实现多个任务"一起"执行。(实际上总有一些任务不在执行,因为切换任务的速度相当快,看上去一起执行而已)
- 并发并不一定比串行要好
进程、线程、协程
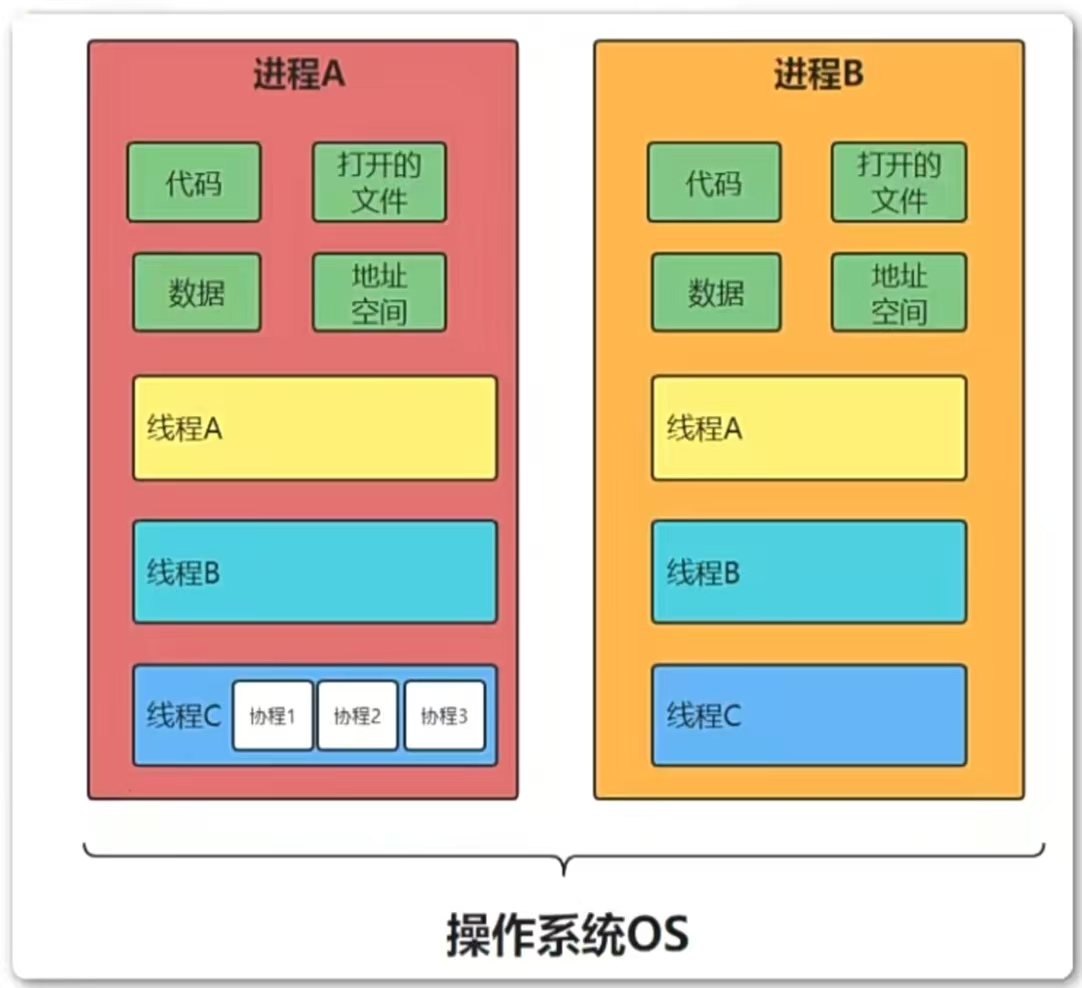
- 线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位。
- 一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线。
- 进程之间相互独立,但是同一进程下的各个线程之间共享程序的内存空间(包括代码段、数据集、堆等)及一些进程级的资源(如打开文件和信号),某进程内的线程在其他进程中不可见。
- 调度和切换:线程上下文切换比进程上下文切换要快得多。
- 进程:拥有自己独立的堆和栈,既不共享堆,也不共享栈,进程由操作系统调度;进程切换需要的资源很大,效率低。
- 线程:拥有自己独立的堆和栈,共享堆,不共享栈,标准线程由操作系统调度;线程切换需要的资源一般,效率一般。(不考虑GIL的情况下)
- 协程:拥有自己独立的栈和共享的堆,共享堆,不共享栈,协程由程序员在协程的代码里显示调度;协程切换任务资源很小,效率高。由程序员自己写程序来管理,例如:当发生IO阻塞时,CPU一致等待IO返回,处于空转状态,这个时候用协程,去运行其他任务,提高效率。
同步、异步
- 同步(
synchronous):A调用B,等待B返回结果后,A继续执行。 - 异步(
asyncharonous):A调用B,A继续执行,不等待B返回结果;B有结果了,通知A,A再做处理。 - 同步与异步强调的时消息通信机制。
线程Thread
线程的创建
- Python的标准库提供了两个模块:
_thread和threading,_thread是低级模块,threading是高级模块,对_thread进行了封装。绝大多数情况下,我们只使用threading这个高级模块。 - 线程的创建可以分为两种方式:
- 方法包装
- 类包装
- 线程的执行统一通过
start()方法,换句话说,必须手动启动线程。 - 方法模式创建线程
- 下面的代码块执行的过程会存在控制流抢占的情况
python
from threading import Thread
def func(name):
print(f"Thread: {name} start.")
num = 0
for i in range(10):
num += i
print(f"Thread: {name} end.")
return True
if __name__ == "__main__":
print("Main thread start.")
t1 = Thread(target=func, args=("t1",))
t2 = Thread(target=func, args=("t2",))
"""
# Thread 不会获取所执行方法的返回结果的
if t1.start() and t2.start():
print("All thread end.")
else:
print("Not expect.")
"""
t1.start()
t2.start()
print("Main thread end.")
"""
# 没有进行守护线程,包括主线程在内都是相互独立的
Main thread start.
Thread: t1 start.
Thread: t2 start.Thread: t1 end.
Main thread end.Thread: t2 end.
"""- 类方法创建线程
python
from threading import Thread
class MyThread(Thread):
def __init__(self, name):
Thread.__init__(self)
self.name = name
def run(self):
""" 重写 run 方法 """
print(f"Thread {self.name} start.")
print(f"Thread {self.name} end.")
if __name__ == "__main__":
print("Main thread start.")
t1 = MyThread("t1")
t2 = MyThread("t2")
t2.start()
t1.start()
print("Main thread end.")
"""
# 依旧出现输出流抢占的情形
Main thread start.
Thread t2 start.
Thread t2 end.Thread t1 start.
Thread t1 end.Main thread end.
"""join()
- 之前的代码,主线程不会等待子线程结束。如果需要等待子线程结束后,再结束主线程,可以使用
join()方法。
python
from threading import Thread
def func(name):
print(f"Thread: {name} start.")
num = 0
for i in range(10):
num += i
print(f"Thread: {name} end.")
return True
if __name__ == "__main__":
print("Main thread start.")
t1 = Thread(target=func, args=("t1",))
t2 = Thread(target=func, args=("t2",))
t1.start()
t2.start()
# Main thread 会等待 t1, t2 结束后再往下执行
t1.join()
t2.join()
print("Main thread end.")
"""
Main thread start.
Thread: t1 start.
Thread: t1 end.Thread: t2 start.
Thread: t2 end.
Main thread end.
"""- 守护线程,主要特征是它的生命周期,主线程死亡,它也就随之死亡。在Python中,线程通过
setDaemon(True|False)来设置是否为守护线程。 - 守护线程的作用是为其他线程提供便利服务,守护线程最经典的应用就是GC(垃圾回收器)
python
from threading import Thread
from time import sleep
class MyThread(Thread):
def __init__(self, name):
Thread.__init__(self)
self.name = name
def run(self):
print(f"Thread {self.name} start.")
sleep(3)
print(f"Thread {self.name} end.")
if __name__ == "__main__":
print("Main thread start.")
t1 = MyThread("t1")
# 调用 setDaemon 方法设置 t1 为守护线程
t1.daemon = True
t1.start()
print("Main thread end.")
"""
Main thread start.
Thread t1 start.Main thread end.
"""全局锁GIL问题
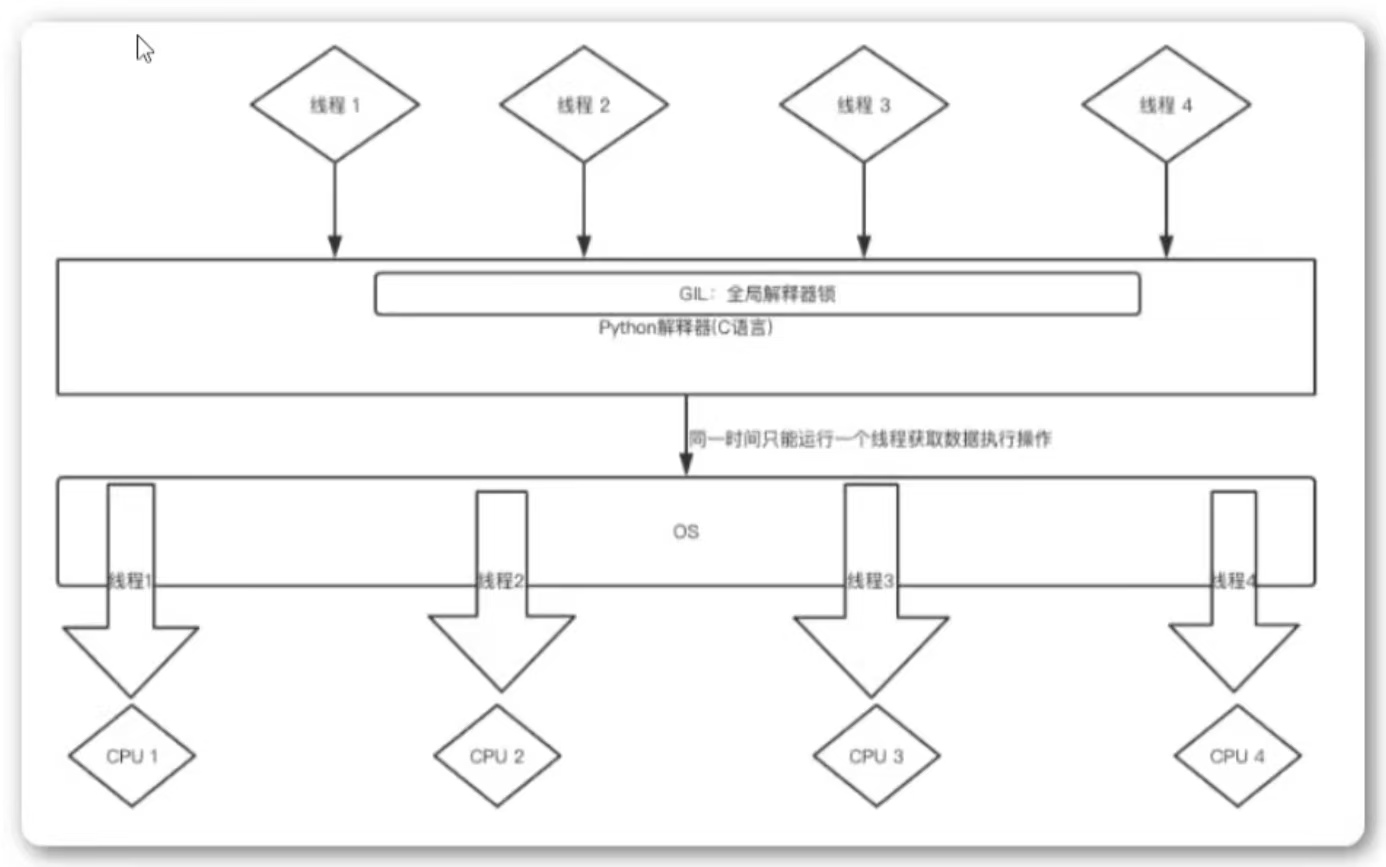
-
在python中,无论CPU有多少个核,在Cpython解释器中都是假象,同一时间执行的线程只有一个线程,这是python开发时的设计缺陷,因此python中的线程是"含有水分的线程"。
-
Python GIL(Global Interpreter Lock)
Python代码的执行是由Python虚拟机(也叫做解释器主循环,Cpython版本)来控制,Python在设计之初就考虑到要在解释器的主循环中,同时只有一个线程在执行,即在任意时刻,只有一个线程在解释器中运行。对Python虚拟机的访问由全局解释锁(GIL)来控制,正是这个锁能保证同一时刻只有一个线程在运行。
-
注:GIL并不是Python的特性,它是在实现Python解释器(CPython)时所引入的一个概念,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行,就没有GIL的问题,然而因为CPython时大部分环境下默认的Python执行环境。所以很多人的意识里CPython就是Python,也就想当然地把GIL归结为Python语言的缺陷,这样的理解是不正确的。
线程同步与互斥锁(《操作系统》)
- 以排队的方法解决同一个资源,多个任务想调用的实际问题。
- 线程同步:
处理多线程问题时,多个线程访问同一个对象,并且某些线程还要修改 这个对象。这个时候,就需要用到线程同步。线程同步是一种等待机制,多个需要同时访问此对象的进入这个对象的等待池形成队列,等待千米那的线程使用完毕后,下一个线程再使用。
python
from threading import Thread
import time, random
class Bank:
def __init__(self, id):
self.id = id
self.balance = 1000
def withdraw(self, money, person):
print(f"{person} 想取 {money} 元,当前余额: {self.balance}")
if self.balance >= money:
time.sleep(3)
self.balance -= money
print(f"{person} 取款成功,余额剩余: {self.balance}")
return True
else:
print(f"{person} 取款失败,余额不足")
return False
class Person(Thread):
def __init__(self, bank, name, amount):
super().__init__()
self.bank = bank
self.name = name
self.amount = amount
def run(self):
self.bank.withdraw(self.amount, self.name)
if __name__ == "__main__":
shared_bank = Bank("0626")
man = Person(shared_bank, "丈夫", 800)
woman = Person(shared_bank, "妻子", 500)
man.start()
woman.start()
man.join()
woman.join()
print(f"最终余额: {shared_bank.balance}")
"""
丈夫 想取 800 元,当前余额: 1000
妻子 想取 500 元,当前余额: 1000
丈夫 取款成功,余额剩余: 200
妻子 取款成功,余额剩余: -300
最终余额: -300
"""- 我们可以通过"锁机制"来实现线程同步问题,"锁机制"有如下几个要点:
- 必须使用同一个锁对象(抢占、释放需要是同一个锁对象)
- 互斥锁的作用就是保证同一时刻只能有一个线程去操作共享数据,保证共享数据不会出现错误问题
- 使用互斥锁的好处确保某段关键代码只能由一个线程从头到尾去执行
- 使用互斥锁会影响代码的执行效率
- 同时持有多把锁,容易出现死锁的情况
- 什么是互斥锁?
互斥锁:对共享数据进行锁定,保证同一时刻只能有一个线程去操作。
注:互斥锁是多个线程一起去抢 ,抢到锁的线程先执行,没有抢到锁的线程需要等待,等互斥锁使用完释放后,其他等待的线程再去抢这个锁。
threading模块中定义了Lock变量,这个变量本质是一个函数,通过调用这个函数可以获取一个互斥锁。
python
from threading import Thread, Lock
from time import sleep
class Bank:
def __init__(self, id):
self.id = id
self.balance = 1000
self.lock = Lock() # 为每一张银行卡添加互斥锁,保证同时只有一个用户可以操作
def withdraw(self, name, amount):
self.lock.acquire() # 添加锁
print(f"{name}要取 {amount}元。")
if self.balance >= amount:
sleep(3) # 为了尽量模拟出冲突情况,在真正扣款前进行 sleep
self.balance -= amount
print(f"{name}成功取出 {amount}元。")
self.lock.release()
return True
else:
print(f"{name}取款失败,余额不足!")
self.lock.release()
return False
class Person(Thread):
def __init__(self, name, bank, amount):
super().__init__()
self.bank = bank
self.name = name
self.amount = amount
def run(self):
self.bank.withdraw(self.name, self.amount)
if __name__ == "__main__":
card = Bank('0626')
man = Person('丈夫', card, 800)
woman = Person('妻子', card, 600)
man.start()
woman.start()
man.join()
woman.join()
print(f"{card.id} 的余额为 {card.balance}")
"""
丈夫要取 800元。
丈夫成功取出 800元。
妻子要取 600元。
妻子取款失败,余额不足!
0626 的余额为 200
"""死锁
-
在多线程程序中,死锁问题很大一部分是由于一个线程同时获取多个锁导致的。
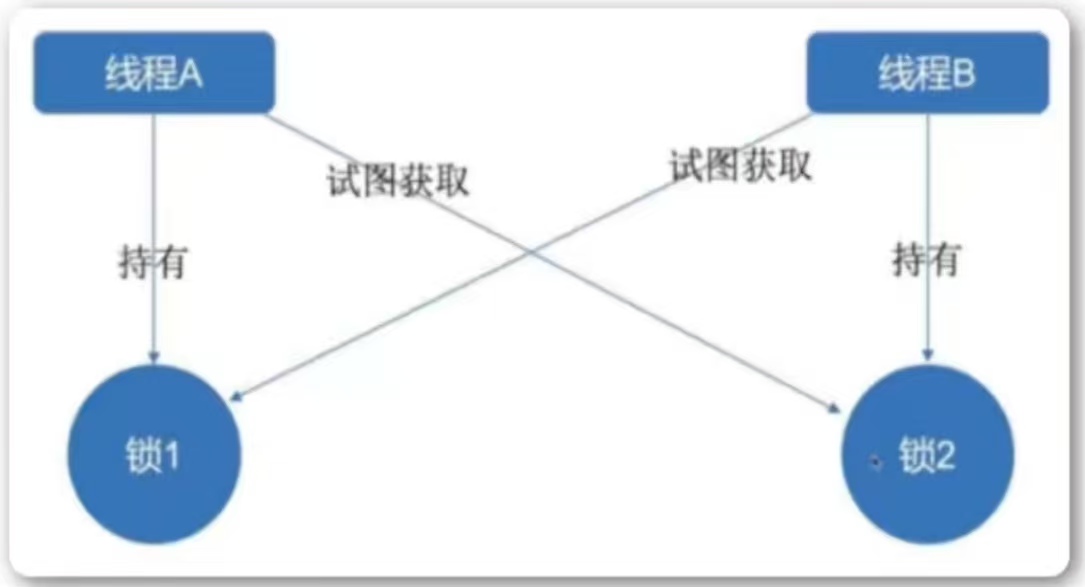
-
一般是由于允许线程拥有部分资源导致的,解决方案可以参考《操作系统》课程中的资源调度算法,印象中好像有一个是银行家算法可以判断整个任务队列能都完成。
-
尽量避免一个线程同时拥有多把锁的情况。
信号量(Semaphore)
- 互斥锁使用后,一个资源同时只有一个线程访问。如果某个资源,我们同时想让3个(指定数值)个线程访问,可以通过信号量机制来完成。
- 信号量控制同时访问资源的数量。信号量和锁相似,锁同时只允许一个对象(线程)通过,信号量同一时间允许多个对象(线程)通过。
- 应用场景:
- 在读写文件时,一般只能有一个线程在写,而读可以有多个线程同时进行,如果需要限制同时以读文件的线程个数,这个时候可以使用信号量(如果使用互斥锁,同一时刻只能由一个线程读)
- 在做爬虫抓取数据时。
- 信号量底层机制就是一个内置的计数器,每当资源被获取时(
acquire())计数器-1,资源释放(release())时,计数器+1.
python
""" 一个房间最多容纳 n 个人 """
from threading import Thread, Semaphore
from time import sleep
def house(name, semaphore):
semaphore.acquire()
print(f"[+] {name}进入了房间...")
sleep(2)
print(f"[-] {name}走出了房间...")
semaphore.release()
if __name__ == "__main__":
n = 2
semaphore = Semaphore(n) # 信号量对象
for i in range(5):
t = Thread(target=house, args=(f"{i}", semaphore))
t.start()
"""
[+] 0进入了房间...
[+] 1进入了房间...
[-] 0走出了房间...
[+] 2进入了房间...
[-] 1走出了房间...
[+] 3进入了房间...
[-] 2走出了房间...
[-] 3走出了房间...[+] 4进入了房间...
[-] 4走出了房间...
"""事件(Event)
- 事件主要用于唤醒正在阻塞等待状态的线程;
Event对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在初始情况下,Event对象中的信号标志被设置为假,如果有线程等待一个Event对象,而这个Event对象的标志为假,那么这个线程将会一直被阻塞直至该标志为真。一个线程如果将一个Event对象设置为真,它将唤醒 所有等待这个Event对象的线程,如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件,继续执行。触发器(并非数据库中的触发器,相当于时某些线程的开关)Event()可以创建一个事件管理标志,该标志(event)默认为False,event对象主要由四种方法调用:
| 方法名 | 注释 |
|---|---|
| event.wait(timeout=None) | 调用该方法的线程会被阻塞,如果设置了timeout参数,超时后,线程会停止阻塞继续执行 |
| event.set() | 将event的标志设置为True,调用wait方法的所有线程将被唤醒 |
| event.clear() | 将event的标志设置为True,调用wait方法的所有线程将被唤醒 |
| event.is_set() | 判断event的标志是否为True |
python
""" 等待父母回来吃饭 """
from threading import Thread, Event
from time import sleep
def eat(name):
print(f"{name}进入就餐状态。")
sleep(1)
event.wait()
print(f"{name}开始就餐...")
if __name__ == "__main__":
# 创建事件
event = Event()
sister = Thread(target=eat, args=("sister", ))
brother = Thread(target=eat, args=("brother", ))
sister.start()
brother.start()
# 父母回家,开始就餐
print("父母回到家,开饭...")
event.set()
# 父母收拾东西,等下再吃
sleep(10)
parents = Thread(target=eat, args=("parents", ))
parents.start()
"""
sister进入就餐状态。
brother进入就餐状态。
父母回到家,开饭...
brother开始就餐...
sister开始就餐...
parents进入就餐状态。
parents开始就餐...
"""生产者和消费者模式
- 多线程编程下,经常需要多个线程并发和协作,这个时候需要了解并发写作模型中的"生产者/消费者模式"
生产者 → 数据 缓冲区 → 数据 消费者 生产者\xrightarrow{数据}缓冲区\xrightarrow{数据}消费者 生产者数据 缓冲区数据 消费者 - 分工解析:
- 生产者:负责生产数据的模块(方法、对象、线程、进程)
- 消费者:负责处理数据的模块(方法、对象、线程、进程)
- 缓冲区:消费者不能直接使用生产者的数据,它们之间有个"缓冲区"。生产者将生产好的数据放入"缓冲区",消费者从"缓冲区"拿去要处理的数据。
- 缓冲区是实现并发的核心,缓冲区的设置有3个好处:(其实这里我认为和《计算机组成原理》或者《操作系统》中学到的缓冲区的作用基本类似,主打解决一个效率不匹配的问题)
- 实现线程的并发协作
有了缓冲区之后,生产者线程只需要向缓冲区中存入数据,而不需要关心消费者处理数据的情况;同样,消费者只需要从缓冲区读取数据,不需要关心生产者生成数据的情况。这样就在逻辑上实现了"生产者线程"和"消费者线程"的分离。 - 解耦了生产者和消费者
生产者和消费者不再绑定。 - 提高效率
生产者生成数据慢时,缓冲区仍有数据,不影响消费者使用;消费者处理数据慢时,生产者仍然可以向缓冲区存取数据。
- 实现线程的并发协作
- 缓冲区和
queue对象
从一个线程向另外一个线程发送数据最安全的方式就是使用queue库中的队列。创建一个或多个线程共享的queue对象,这些线程可以通过使用put()和get()操作来向队列添加或者删除元素。queue对象已经包含了必要的锁,因此通过它可以在多个线程中安全地存取数据。
python
from threading import Thread, Lock
from queue import Queue
from time import sleep
import random
MAX_LENGTH = 10
PRODUCTION_CHECK_TIME = 5
class Producer(Thread):
def __init__(self, category):
super().__init__()
self.category = category
def run(self):
while True:
product_lock.acquire()
if plates.qsize() < MAX_LENGTH:
print(f"第 {plates.qsize()} 个盘子中放入 {self.category}.")
plates.put(self.category)
else:
print("盘子都已经放满了,稍后再放。")
product_lock.release()
sleep(PRODUCTION_CHECK_TIME)
class Consumer(Thread):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
while True:
consum_lock.acquire()
print(f"{self.name}拿走了一个{plates.get()}")
consum_lock.release()
sleep(random.uniform(1, 10))
if __name__ == "__main__":
plates = Queue()
product_lock = Lock()
consum_lock = Lock()
producer_apple = Producer('apple')
producer_orange = Producer('orange')
producer_banana = Producer('banana')
consumer1 = Consumer('Alce')
consumer2 = Consumer('Bob')
consumer3 = Consumer('chenxing')
producer_apple.start()
producer_orange.start()
producer_banana.start()
consumer1.start()
consumer2.start()
consumer3.start()
"""
第 0 个盘子中放入 apple.
第 1 个盘子中放入 orange.
第 2 个盘子中放入 banana.Alce拿走了一个apple
Bob拿走了一个orange
chenxing拿走了一个banana
第 0 个盘子中放入 apple.
第 1 个盘子中放入 orange.
Alce拿走了一个apple
第 1 个盘子中放入 banana.
chenxing拿走了一个orange
Alce拿走了一个banana
第 0 个盘子中放入 apple.
Bob拿走了一个apple第 1 个盘子中放入 orange.
第 1 个盘子中放入 banana.
Alce拿走了一个orange
chenxing拿走了一个banana
第 0 个盘子中放入 apple.
Bob拿走了一个apple
"""进程(Process)
-
进程
Process:拥有自己独立的堆和栈,既不共享堆也不共享栈,进程由操作系统调度;进程切换需要的资源很大,效率低。 -
对于操作系统而言,一个任务就是一个进程,例如,打开一个浏览器就是启动一个浏览器进程,启动一个笔记本进程,打开两个记事本就启动了两个记事本进程,打开一个Word文档就启动了一个Word进程。
-
进程的优缺点:
- 可以使用计算机多核,进行任务的并发执行,提高执行效率
- 运行不受其他进程影响,创建方便
- 空间独立,数据安全
- 进程的创建和删除消耗的系统资源较多
方法模式创建进程
- Python标准库提供了模块
multiprocessing - 进程的创建可以分为两种模式:
- 方法包装
- 类包装
- 创建进程后,使用
start()启动进程 - 进程的主进程等待也是通过
join()函数操作
python
from multiprocessing import Process
from time import sleep
import os
def func(name):
print(f"Process:{name} start.")
print(f"当前进程的ID: {os.getpid()}")
print(f"父进程ID: {os.getppid()}")
sleep(3)
print(f"Process:{name} end.")
if __name__ == "__main__":
print(f"当前进程的ID: {os.getpid()}")
# 创建进程
p1 = Process(target=func, args=('p1', ))
p1.start()
p2 = Process(target=func, args=('p2', ))
p2.start()
"""
当前进程的ID: 24696
Process:p1 start.
当前进程的ID: 7204
父进程ID: 24696
Process:p2 start.
当前进程的ID: 23512
父进程ID: 24696
Process:p1 end.
Process:p2 end.
"""- 在Windows操作系统上实现的多进程程序,存在一个bug,我们必须存在
if __name__ == "__main__":这一行代码,否则就会无限递归创建子进程从而报错。
类模式创建进程
- 与使用
Thread类创建子线程的方式相似,使用Process类创建实例化对象,其本质是调用该类的构造方法创建新进程,Process类的构造格式如下:
def __init__(self, group=None, target=None, name=None, args=(), kwargs=()
group:该参数未进行实现,不需要传参
target:为新建进程指定执行任务,也就是指定一个函数
name:为新建进程设置名称
args:为target参数指定的参数传递非关键字参数
kwargs:为target参数指定的参数传递关键字参数
python
from multiprocessing import Process
from time import sleep
class MyProcess(Process):
def __init__(self, name):
Process.__init__(self)
self.name = name
def run(self):
print(f"Process({self.name}) start.")
sleep(3)
print(f"Process({self.name}) end.")
if __name__ == "__main__":
p1 = MyProcess('p1')
p1.start()
p2 = MyProcess('p2')
p2.start()
"""
Process(p1) start.
Process(p2) start.
Process(p1) end.
Process(p2) end.
"""Queue实现进程间通信
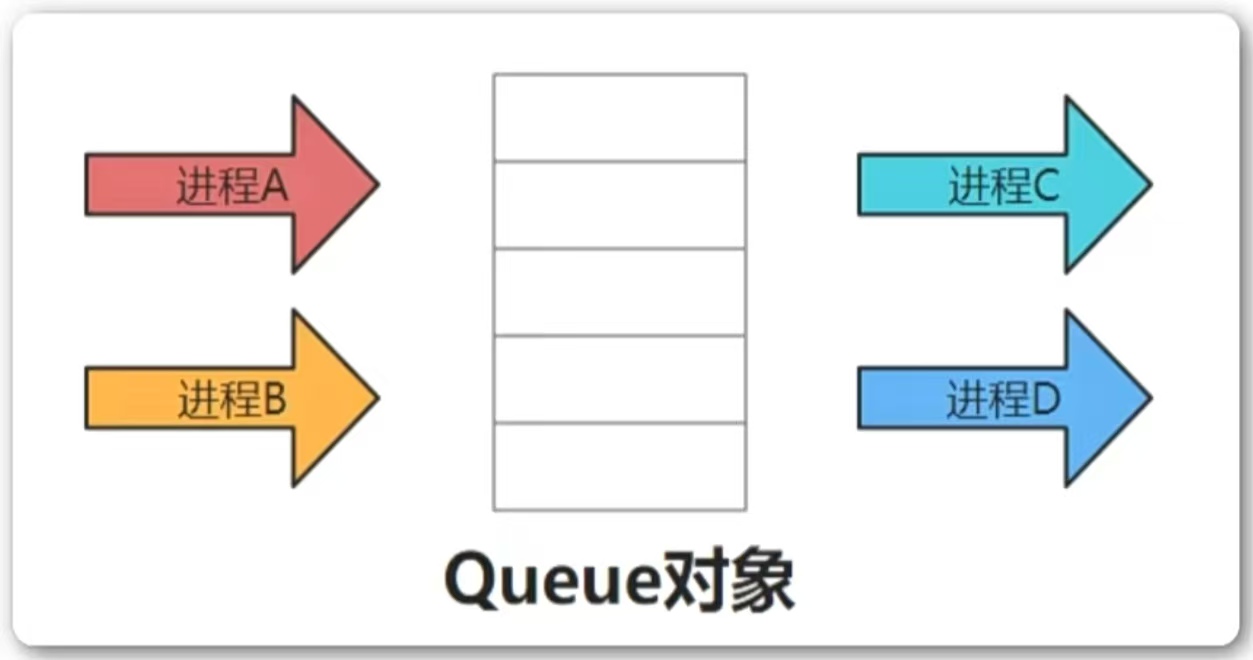
- 在多线程中使用了
queue模块中的Queue类实现了生产者消费者模式,但是要实现进程间通信,需要使用multiprocessing模块中的Queue类。这是因为对于进程而言,不共享堆,也不共享栈,而对于多线程而言,它们都可以访问同一个进程中的全局变量。
python
from multiprocessing import Process, Queue
from time import sleep
import random
def producer(queue):
for i in range(5):
print(f"生产第{i}条消息...")
item = random.uniform(0.1, 0.5)
print(f"[生产者] 放入{item}!")
queue.put(item)
sleep(random.uniform(0.1, 0.5))
queue.put(None)
print("生产结束。")
def consumer(queue):
while True:
item = queue.get() # 从管道读取并反序列化
if item is None:
print("[消费者] 收到结束信号,退出")
break
print(f"[消费者] 消费了: {item}")
sleep(random.uniform(0.2, 0.6))
if __name__ == "__main__":
places = Queue()
p = Process(target=producer, args=(places, ))
c = Process(target=consumer, args=(places, ))
p.start()
c.start()
"""
生产第0条消息...
[生产者] 放入0.30275834271383745!
[消费者] 消费了: 0.30275834271383745
生产第1条消息...
[生产者] 放入0.3317314425740986!
[消费者] 消费了: 0.3317314425740986
生产第2条消息...
[生产者] 放入0.30695167308161353!
[消费者] 消费了: 0.30695167308161353
生产第3条消息...
[生产者] 放入0.45917458592019134!
生产第4条消息...
[生产者] 放入0.48542903583573926!
[消费者] 消费了: 0.45917458592019134
生产结束。
[消费者] 消费了: 0.48542903583573926
[消费者] 收到结束信号,退出
"""- 注意:可以和线程的"生产者消费者模式"进行对比,我们可以发现,对于线程而言,我们定义完队列之后,就默认所有的线程可以操作这个全局对象了;但是对于进程而言,我们需要把队列对象
Queue传入到方法或者类的参数中。
Pipe管道实现进程间的通信

Pipe方法返回(conn1, conn2)代表一个管道的两个端。Pipe方法有duplex参数,如果duplex参数为True(默认值),那么这个管道就是全双工模式,也就是conn1与conn2均可收发。若duplex为False,conn1只负责接收信息,conn2只负责发信息。send和recv方法分别是发送和接收消息的方法。例如:在全双工模式下,可以调用conn1.send发送消息,conn1.recv接收消息。如果没有消息可接收,recv方法会一直阻塞。如果管道已经关闭,那么recv方法会抛出EOFError。
python
from multiprocessing import Process, Pipe
from time import sleep
import os
def func1(conn1):
sub_info = "Hello"
print(f"进程1--{os.getpid()}发送数据:{sub_info}")
conn1.send(sub_info)
sleep(1)
print(f"来自进程2:{conn1.recv()}")
sleep(1)
def func2(conn2):
sub_info = "你好"
print(f"进程2--{os.getpid()}发送数据:{sub_info}")
conn2.send(sub_info)
sleep(1)
print(f"来自进程1:{conn2.recv()}")
sleep(1)
if __name__ == "__main__":
conn1, conn2 = Pipe()
p1 = Process(target=func1, args=(conn1, ))
p2 = Process(target=func2, args=(conn2, ))
p1.start()
p2.start()
"""
进程1--28980发送数据:Hello
进程2--7460发送数据:你好
来自进程2:你好
来自进程1:Hello
"""Manger管理器实现进程间的通信
- 管理器提供了一种创建共享数据的方法,从而可以在不同进程中共享。
python
from multiprocessing import Process, Manager
def func1(name, m_list, m_dict):
m_dict['name'] = 'chenxing'
m_list.append('你好')
def func2(name, m_list, m_dict):
m_dict['name'] = 'xingchen'
m_list.append('世界')
if __name__ == "__main__":
with Manager() as mgr:
m_list = mgr.list()
m_dict = mgr.dict()
m_list.append('Hello!')
p1 = Process(target=func1, args=('p1', m_list, m_dict, ))
p2 = Process(target=func2, args=('p2', m_list, m_dict, ))
p1.start()
p2.start()
p1.join()
p2.join()
print(f"list: {m_list}")
print(f"dict = {m_dict}")
"""
list: ['Hello!', '你好', '世界']
dict = {'name': 'xingchen'}
"""进程池(Pool)
- 进程池可以提供指定数量的进程供给用户使用,即当有新的请求提交到进程池中时,如果池未满,则会创建一个新的进程用来执行该请求;反之,如果池中的进程数已经达到规定最大值,那么该请求就会等待,只要池中有进程空闲下来,该请求就能得到执行。
- 进程池的优点:
- 提高效率,节省开辟进程和开辟内存空间的时间及销毁进程的时间
- 节省内存空间
| 类/方法 | 功能 | 参数 |
|---|---|---|
Pool(processes) |
创建进程池对象 | processes表示进程池中有多少个进程 |
pool.apply_async(func, args, kwds) |
异步执行;将事件放入到进程池队列 | func事件函数,args以元组形式给func传参,kwds以字典形式给func传参。返回值:返回一个代表进程池事件的对象,通过返回值的get()方法可以得到事件函数的返回值 |
pool.apply(func, args, kwds) |
同步执行;将事件放入到进程池队列 | func事件函数,args以元组形式给func传参,kwds以字典形式给func传参。 |
pool.close() |
关闭进程池 | |
pool.join() |
回收进程池 | |
pool.map(func, iter) |
类似于Python的map函数,将要做的事件放入进程池 | func要执行的函数;iter迭代对象 |
- 进程池模板(入门)
python
from multiprocessing import Pool
from time import sleep
import os
def func1(name):
print(f"Process{os.getpid()}--> {name}")
sleep(2)
return "callback"
def func2(args):
print(args)
if __name__ == "__main__":
pool = Pool(3)
pool.apply_async(func=func1, args=('p1', ), callback=func2) # func1 的返回结果会作为 callback 方法的参数
pool.apply_async(func=func1, args=('p2', ))
pool.apply_async(func=func1, args=('p3', ))
pool.apply_async(func=func1, args=('p4', ))
pool.apply_async(func=func1, args=('p5', ))
pool.close()
pool.join()
"""
Process29228--> p1 # 进程号为 29228 ⭐
Process32908--> p2
Process22952--> p3
callback
Process29228--> p4 # 进程号为 29228 ⭐
Process32908--> p5
"""- 进程池模板(进阶)
python
from multiprocessing import Pool
from time import sleep
import os
def func(name):
print(f"Process{os.getpid()}-->{name}")
sleep(2)
return name
if __name__ == "__main__":
with Pool(3) as pool:
args = pool.map(func, ('p1', 'p2', 'p3', 'p4', 'p5', )) # pool.map(func, iter)
for a in args:
print(a)
"""
Process2176-->p1 # 2176
Process3408-->p2
Process27924-->p3
Process2176-->p4 # 2176
Process3408-->p5
p1
p2
p3
p4
p5
"""协程(Coroutines)
-
协程(Coroutines),也叫做纤程(Fiber)
-
协程,全程是"协同程序",用来实现任务写作。是一种在线程中,比线程更加轻量级的存在,由程序员自己写程序管理。(线程、进程是由操作系统来管理)
-
当出现IO阻塞时,CPU一直等待IO返回,处于空转状态。这个时候用协程,可以执行其他任务。当IO返回结果后,再回来处理数据,充分利用IO等待的时间,提高效率。
-
协程的核心(控制流的让出和恢复):
- 每个协程有自己的执行栈,可以保存自己的执行现场
- 可以由用户程序按需创建协程(例如:遇到IO操作)
- 协程主动让出(yield)执行权时,会保存执行现场(保存中断时的寄存器上下文和栈),然后切换到其他协程
- 协程恢复执行(resume)时,根据之前保存的执行现场恢复到终端前的状态,继续执行,这样就通过协程实现了轻量的由用户态调度的多任务模型
-
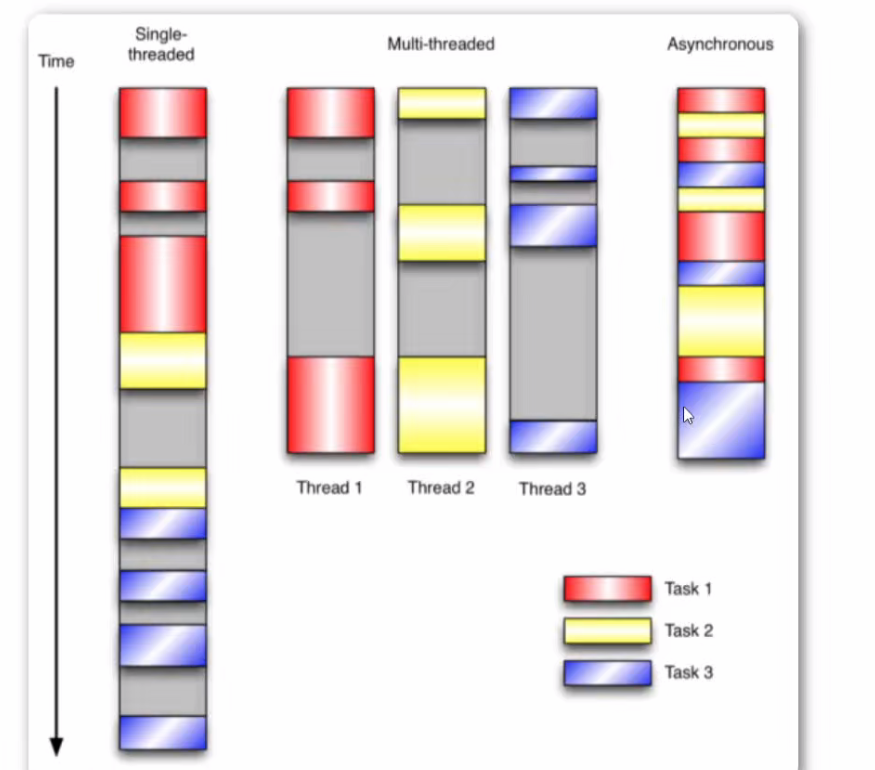
协程和多线程比较
例如,有3个任务需要完成,每个任务都在等待I/O操作时阻塞自身。阻塞在I/O操作上所花费的时间已经用灰色框标示出来。
-
协程的优点:
- 由于自身带有上下文和栈,无需线程上下文切换的开销,属于程序级别的切换,操作系统感知不到,因而更加轻量级;
- 无需原子操作的锁定及同步的开销;
- 方便切换控制流,简化编程模型;
- 单线程内就可以实现并发效果,最大限度地利用CPU,且可扩展性高,成本低(注:一个CPU支持上万个协程都不是问题,所以很适合用于高并发处理)
-
asyncio协程是写爬虫比较好的方式,比多线程和多进程都好。开辟新的进程或线程是非常耗时的。
-
协程的缺点:
- 无法利用多核资源:协程本质上是个单线程,它不能同时将单个CPU的多个核利用到,协程需要和进程配合才能榨取多核CPU的性能
- 平时不常见,适用于CPU密集型应用
使用yield实现协程(已淘汰)
asyncio实现协程
- 正常执行的函数时是不会中断的,所以要写一个能够中断的函数,需要加
async async用来声明一个函数为异步函数,一部函数的特点就是能在函数执行过程中挂起,去执行其他异步函数,等到挂起条件(假设挂起条件为sleep(5))消失后,也就是5秒之后再执行。await用来声明程序挂起,例如异步程序执行到某一步时需要等待的时间很长,就将此挂起,去执行其他异步程序。asyncio是Python3.5之后的协程模块,是Python实现并发重要的包,这个包使用事件循环驱动实现并发- 不使用
asyncio的任务切换
python
import time
def func1():
for i in range(3):
print(f'北京:第{i}次打印啦')
time.sleep(1)
return "func1执行完毕"
def func2():
for k in range(3):
print(f'上海:第{k}次打印了' )
time.sleep(1)
return "func2执行完毕"
def main():
func1()
func2()
if __name__ == '__main__':
start_time = time.time()
main()
end_time = time.time()
print(f"耗时{end_time-start_time}") # 耗时6.004143953323364- 使用
asyncio的任务切换
python
import asyncio
import time
async def func1(): #async表示方法是异步的
for i in range(3):
print(f'北京:第{i}次打印啦')
await asyncio.sleep(1)
return "func1执行完毕"
async def func2():
for k in range(3):
print(f'上海:第{k}次打印了' )
await asyncio.sleep(1)
return "func2执行完毕"
async def main():
res = await asyncio.gather(func1(), func2())
#await异步执行func1方法
#返回值为函数的返回值列表
print(res)
if __name__ == '__main__':
start_time = time.time()
asyncio.run(main())
end_time = time.time()
print(f"耗时{end_time-start_time}") # 耗时3.0314831733703613