目录
[1. 分片(Shard)------ 把大文件切成小块](#1. 分片(Shard)—— 把大文件切成小块)
[1.1 为什么要分片?](#1.1 为什么要分片?)
[1.2 分片是什么?](#1.2 分片是什么?)
[1.3 分片的能力与不足](#1.3 分片的能力与不足)
[2. 压缩 ------ 数据库默默帮你节省空间](#2. 压缩 —— 数据库默默帮你节省空间)
[2.1 压缩解决了分片的什么问题?](#2.1 压缩解决了分片的什么问题?)
[2.2 压缩的原理](#2.2 压缩的原理)
[3. 降采样(Downsampling)------ 生产环境的核心优化](#3. 降采样(Downsampling)—— 生产环境的核心优化)
[3.1 MySQL的做法](#3.1 MySQL的做法)
[3.2 InfluxDB 的做法(Flux + 落盘)](#3.2 InfluxDB 的做法(Flux + 落盘))
[第一步:写降采样 Task,结果持久化](#第一步:写降采样 Task,结果持久化)
[3.3 核心区别对比](#3.3 核心区别对比)
[3.4 降采样解决了压缩的什么问题?](#3.4 降采样解决了压缩的什么问题?)
[3.5 降采样的能力与不足:](#3.5 降采样的能力与不足:)
[3.6 生产标准方案:双桶架构](#3.6 生产标准方案:双桶架构)
[二、三者关系:分片 → 压缩 → 降采样](#二、三者关系:分片 → 压缩 → 降采样)
在前面的章节中,我们已经成功通过 Java 实体类 AirSensorData 将空气传感器数据写入 InfluxDB,measurement 为 airSensors,包含 sensor_id(tag)、temperature 、humidity、co 等指标,数据格式稳定、接入通畅。也参照官方文档,使用 Task 定时同步过空气传感器数据,模拟时序数据每日的上送。
但进入生产环境必须解决三大问题:
- 海量时序数据占用空间爆炸,查询越来越慢
- 历史明细数据无需永久保存,只需保留统计结果
- 原始数据存在异常值、缺失值,需要自动清洗
这三大痛点,是时序数据库从 "能用" 走向 "生产可用" 的必经之路。而 InfluxDB 恰好提供了一套原生、高效、零外部依赖 的解决方案,它由四个关键技术组成:分片、压缩、降采样、Task 定时任务。
InfluxDB 提供了三把"手术刀":分片(Sharding) 、压缩(Compaction) 、降采样(Downsampling)。它们分别从存储结构、数据编码、数据粒度三个维度下手,互相配合,缺一不可。
在动手写 Task 之前,我们得先弄清楚这三把刀到底在切什么
一、先搞懂:分片、压缩、降采样是什么?
1. 分片(Shard)------把大文件切成小块
1.1 为什么要分片?
分片顾名思义就是把超大的整体数据,按规则拆分成多个小分片,分散存储在不同节点。
例如:传统的单机关系数据库MySQL,默认没有原生分片能力 ,所有业务数据最终都落在单节点单个 / 少数大数据文件里,会出现三大致命问题:
- 查询慢:查 1 天的数据也要扫描整个大文件
- 删不掉:删除过期数据需要遍历整个文件做标记删除,速度极慢且会产生大量碎片
- 扩不动:受单节点磁盘、CPU、内存限制,无法分布式存储,单节点容量有上限
分片的出现完美解决了这些问题:它把连续的时间流切成一个个独立的、不可修改的文件块(Shard),每个 Shard 对应一个固定的时间窗口(如 1 天)
分片的本质:给数据打上 "时间标签",让数据有了生命周期和位置属性。
1.2 分片是什么?
InfluxDB是时序数据库,**所有数据都按时间组织,**分片是InfluxDB存储引擎的按时间切割数据的物理存储最小单元单位。
写入数据时,InfluxDB不会吧所有数据塞进一个巨大的文件中,而是按照时间范围切成一个个独立的"文件块",这就是分片,分片是按时间范围切分的物理存储单元 。------所有数据写入时就被自动归入对应的时间分片
InfluxDB 不需要你手动指定每个分片覆盖多长时间,它会根据 Bucket 的保留策略 自动计算:
| Bucket 保留时间 | 默认 Shard Group Duration |
|---|---|
| ≤ 2 天 | 1 小时 |
| 2 天 ~ 6 个月 | 1 天 |
| ≥ 6 个月 | 7 天 |
❌误区:Shard 越小越灵活,但也不是越小越好。过多的 Shard 会拉低查询效率(OpenShard 开销大),需要根据数据量取舍。
我的保留策略是30天->默认1天,通过 Java 客户端(@Measurement(name = "airSensors"))写入数据时,InfluxDB 内部做了这些事:
① 确定归属 Bucket
→ 数据写入指定的 Bucket(比如 "echola-bucket ")
→ 这个 Bucket 的保留策略决定了 Shard Group Duration(比如保留30天 → 默认1天)
② 按时间路由到 Shard Group
→ 时间戳 2026-05-01T01:08:21 的数据
→ 归属于 Shard Group "2026-05-01"(覆盖这一天 00:00:00 ~ 23:59:59)
③ 进入该 Shard Group 的唯一 Shard(单机版)
→ 这个 Shard 负责存储 "2026-05-01" 这整天的所有数据
→ 目录结构大概是这样:
javascript
/data/echola-bucket/airSensors/123/ ← shard ID=123
├── 000000001-000000001.tsm ← TSM 数据文件
├── index/ ← TSI 索引文件
└── wal/ ← WAL 预写日志每个 Shard 内部包含:
-
TSM 文件(列式存储的数据文件)
-
WAL 文件(预写日志,先写这里再刷入 TSM)
-
索引文件(TSI,加速按 tag 查询)
时间轴 ─────────────────────────────────────────────>
| Shard 1 | Shard 2 | Shard 3 |
| 7天前~6天前 | 6天前~5天前 | 5天前~4天前 |
用一个简单的例子:
有 100GB / 天的原始数据,30 天就是 3TB。
不分片:这 3TB 数据存在 1 个大文件里
分片:分成 30 个 1 天的 Shard:这 3TB 数据存在 30 个小文件里
总大小还是 3TB,一分不少
这就是分片留下的第一个、也是最大的问题:它解决了 "数据怎么放" 的问题,但完全没有解决 "数据占多大" 的问题
1.3 分片的能力与不足
| 说明 | |
|---|---|
| 核心能力 | 1. 过期时以 Shard 为最小单元整块删除,瞬间释放磁盘空间,不会像 MySQL DELETE 那样锁表、产生碎片 2. 查询时只扫描目标时间范围内的 Shard,避免全表扫描 3. 支持冷热数据分离,热数据存 SSD,冷数据存 HDD |
| 主要不足 | 1. 不分担查询压力 :数据量越大,单个 Shard 内部扫描依然越慢。 2. 数量过多有副作用:Shard 越碎,查询时要打开的文件句柄越多,反而拖慢性能 |
那如何解决数据占空间大的问题呢?------压缩
2. 压缩 ------ 数据库默默帮你节省空间
当数据写入 InfluxDB 时,完整的流程是:
- 数据到达,根据时间戳找到对应的 Shard
- 数据先写入 WAL 日志(未压缩)
- 数据进入内存缓存(Cache)
- 当 Cache 满了(达到 25MB(默认) 或 10 分钟无写入时),数据被刷入磁盘,自动执行压缩,生成一个 TSM 文件
- 删除对应的 WAL 日志段
每个 Shard 都是一个完全独立的微型数据库,拥有自己完整的存储栈:
一个Shard的完整结构
├── WAL目录(预写日志)
├── Cache(内存缓存)
└── TSM文件目录(磁盘持久化数据)
├── 000000001-000000001.tsm
├── 000000002-000000002.tsm
└── ...也就是说:所有持久化到磁盘的 Shard 文件,天生就是压缩后的。不存在 "未压缩的 Shard" 这种东西。
当Shard中的数据变成"冷Shard🥶"后,数据一旦从Cache写到磁盘中,形成只读的TSM文件 。随后,InfluxDB会在后台自动对这些只读文件进行多级压缩与合并,以优化存储空间和查询性能
官方定义:"冷 Shard" 的精确触发条件
当一个 Shard最后一次写入操作发生后,经过
compact-full-write-cold-duration时间(默认 4 小时),InfluxDB 会将其标记为 "冷 Shard",并触发全量压缩
以目前的原始桶echola-bucket为例子:
- Shard Group Duration:1 天
- 保留策略:30 天
cache-snapshot-write-cold-duration:默认 10 分钟compact-full-write-cold-duration:默认 4 小时
那么一个 Shard 的完整生命周期是:
| 时间点 | 事件 | 状态 | 数据位置 | 压缩阶段 | 压缩比 |
|---|---|---|---|---|---|
| 2026-05-08 00:00:00 | Shard 创建,开始接受写入 | 热 Shard | 内存 Cache+WAL | 无 | 0:1 |
| 2026-05-08 00:25:00 | Cache 达到 25MB,第一次刷盘 | 热 Shard | 内存 Cache+WAL+1 个 TSM 文件 | 实时压缩 | ~5:1 |
| 2026-05-08 23:59:59 | Shard Group 时间窗口结束 | 温 Shard | 内存 Cache+WAL + 多个 TSM 文件 | 实时压缩 | ~5:1 |
| 2026-05-09 00:09:59 | 连续 10 分钟无写入 | 温 Shard | 多个 TSM 文件 | 实时压缩 | ~5:1 |
| 2026-05-09 00:10:00 | 触发冷 Cache 快照,最后 1MB 数据刷盘,清空 Cache 和 WAL | 温 Shard | 所有数据都在磁盘的多个 TSM 文件中 | 实时压缩 | ~5:1 |
| 2026-05-09 04:09:59 | 连续 4 小时无写入 | 即将变冷 | 多个 TSM 文件 | 实时压缩 | ~5:1 |
| 2026-05-09 04:10:00 | 触发全量压缩,合并所有 TSM 文件 | 冷 Shard | 1 个大的最优压缩 TSM 文件 | 全量压缩 | ~10:1~100:1 |
| 2026-06-07 00:00:00 | 保留期结束,Shard 被物理删除 | 已删除 | - | - | - |
可以看见即使 Shard Group 的时间窗口已经结束,InfluxDB 仍然会等待 4 小时,确保不会再有任何迟到的数据写入,然后才会将其标记为只读并进行全量压缩
2.1 压缩解决了分片的什么问题?
压缩是纯数据编码方式的优化,它利用时序数据的强冗余特性,在不丢失任何信息的前提下,把每个数据点的大小压缩到原来的 1/10~1/100
回到刚才的例子:
100GB / 天的原始数据,分成 30 个 1 天的 Shard
未压缩:总大小 3TB
压缩后:总大小 300GB(平均压缩比 10:1)
压缩在分片的基础上,直接把存储成本降低了一个数量级。
更重要的是,压缩不仅不影响性能,反而会同时提升写入和查询性能:
- 写入时:需要写入磁盘的数据量减少了 90%,磁盘 IO 瓶颈大幅缓解
- 查询时:需要从磁盘读取的数据量减少了 90%,查询速度提升 10 倍以上
2.2 压缩的原理
InfluxDB 的 TSM 文件针对时序数据做了专门优化:
- 时间戳:使用 Delta 编码(存储相邻时间戳的差值,而非完整时间戳)。
- 数值:使用 XOR 压缩(存储相邻数值的异或结果,对于变化平缓的传感器数据,压缩效果极佳)。
但注意:自动压缩只能减少体积,不能减少数据条数。 如果你的传感器每秒上报一条数据,压缩后依然是每秒一条,查询依然会慢。无论怎么压缩,数据点的总数是不变的。
以空气传感器的时间戳为例:
假设一个 TSM 块包含 1000 个连续的空气传感器数据点,上报间隔为 10 秒:
时间戳序列(纳秒):
T0: 1715155200000000000 (2026-05-08 14:00:00)
T1: 1715155210000000000 (T0 + 10秒)
T2: 1715155220000000000 (T1 + 10秒)
T3: 1715155230000000000 (T2 + 10秒)
...
T999: 1715165190000000000 (T998 + 10秒)TSM 文件中的实际存储内容:
[块头]
第一个完整时间戳: 1715155200000000000 (8字节)
第一个Delta值: 10000000000纳秒 (4字节)
Delta-of-Delta值: 0 (1比特)
重复次数: 998次 (2字节)
[数据部分]
... (数值和标签数据)惊人的计算结果:
- 1000 个时间戳,总共只需要存储:8 + 4 + 0.125 + 2 = 14.125 字节
- 平均每个时间戳:14.125 字节 ÷ 1000 = 0.014125 字节 = 0.113 比特
- 压缩比:(1000 × 8 字节) ÷ 14.125 字节 ≈ 566:1
压缩已经把每个数据点压到了物理极限:
- 时间戳:从 8 字节压缩到平均 2 比特(压缩比 32:1)
- 浮点数:从 8 字节压缩到平均 1.5 字节(压缩比 5:1)
- 标签:从几十字节压缩到几个比特(压缩比 1000:1)
1000 台设备每秒上报 1 个点,一天就是 8640 万个点,一年就是 315 亿个点。即使每个点只占 1 字节,一年也需要 31.5GB,10 年就是 315GB。
对于需要保留 5 年、10 年甚至更久历史数据的行业(如环保、电力、工业)来说,即使有压缩,长期数据量仍然会大到无法承受。
这就是压缩留下的问题:它解决了 "每个点占多大" 的问题,但完全没有解决 "有多少个点" 的问题。
InfluxDB 存储引擎在后台对已关闭(只读)的 Shard 自动执行高比例压缩。时序数据时间连续、值相近,压缩比极高(通常 1:10 甚至更高)。
| 说明 | |
|---|---|
| 核心能力 | 1. 全自动、零配置 ,静默削减磁盘成本。 2. 压缩比极高,时序列式存储天然有利于编码压缩算法 |
| 主要不足 | 1. 只减体积,不减行数 :一秒一条的数据压缩完依然是一秒一条,扫描开销丝毫未降。 2. 只在后台对冷数据生效,刚写入的热分片体积较大,存在"写入放大"阶段 |
生产环境压缩最佳实践
- 永远不要关闭压缩:InfluxDB 2.x 默认开启压缩,关闭它没有任何好处
- 不要使用通用压缩算法:TSM 的专用压缩算法比 GZIP、LZ4 效率高得多
- 定期执行 Compaction:合并小的 TSM 文件,提升压缩比和查询性能
- 查看压缩效果 :使用
influxd inspect report-db命令查看每个桶的实际压缩比
由于保留策略是30天,30 天之前的所有数据,会被 InfluxDB 自动、永久、物理删除。
InfluxDB 的过期数据清理并非逐行
DELETE,而是以 Shard 为最小单元进行整块删除------当整个 Shard 内所有数据的时间戳都超出保留期限,存储引擎直接删除该 Shard 对应的 TSM 文件和索引,释放磁盘空间。这种机制效率极高,但也意味着:一旦过期,数据不可恢复
对于真实的业务需求,"只保留30天"显然是远远不够的,一般查询都是近一天、近7天、近一月和近一年等。
但又不能设置为数据永久保存,海量的数据名字会快速撑满磁盘,随着时间推移,查询跨度稍大就会出现查询缓慢、IO压力飙升的问题
这就引申出来了------降采样
3. 降采样(Downsampling)------ 生产环境的核心优化
降采样的核心逻辑是:"丢明细、留统计"------ 用低粒度的聚合数据(如每小时平均温度)代替高粒度的原始数据(如每秒一次的温度读数),从而大幅减少数据条数,提升查询效率。
3.1 MySQL的做法
传统MySQL统计一天内的各个设备每小时的平均温度是将一天的所有温度数据取出来,把一天的所有温度数据取出来,再按照小时分组求平均。
sql
SELECT
sensor_id,
DATE_FORMAT(record_time, '%Y-%m-%d %H:00:00') AS hour,
AVG(temperature) AS avg_temp,
MAX(temperature) AS max_temp,
MIN(temperature) AS min_temp
FROM air_sensor_data
WHERE record_time >= '2026-05-01 00:00:00'
AND record_time < '2026-05-02 00:00:00'
GROUP BY sensor_id, hour;在数据量少时,这样查询是没有问题,但是有些设备的上送是按照s级计算,当数据量越来越多,缺点就暴漏出来了,查询越来越慢
1 个传感器每2s上送一次,一天 43,200行,100 个传感器一天 432w 行。查一周需要扫描 3024w 万行,接口响应必定超时
一般要么就是写定时任务脚本,把原始数据按照小时级算出来统计值,将其存储到另一张表,直接去查询中间表,本质上就是"降采样",但需要自行写代码,管理定时调度,处理失败重试
3.2 InfluxDB 的做法(Flux + 落盘)
而InfluxDb的降采样,就可以原生解决这些问题,不再需要外部脚本。它的实现方式就是上一节提到的 Task + aggregateWindow:
第一步:写降采样 Task,结果持久化
先创建一个聚合桶:echola-agg-bucket,Task → Create Task → 选择 New Task,在Task中创建一个airSensor-Hour-AGG的任务,每小时聚合一次,算 mean/max/min/num
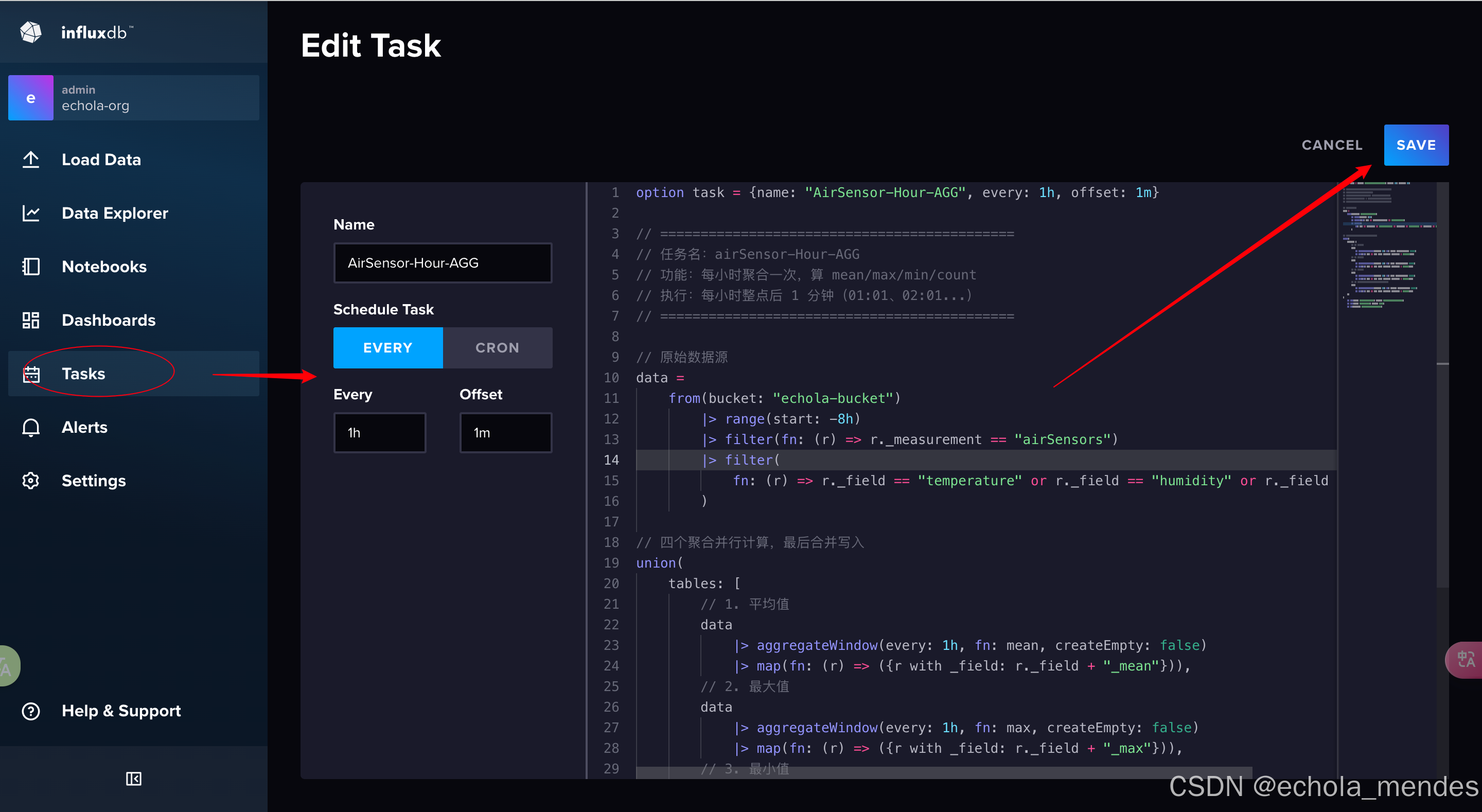
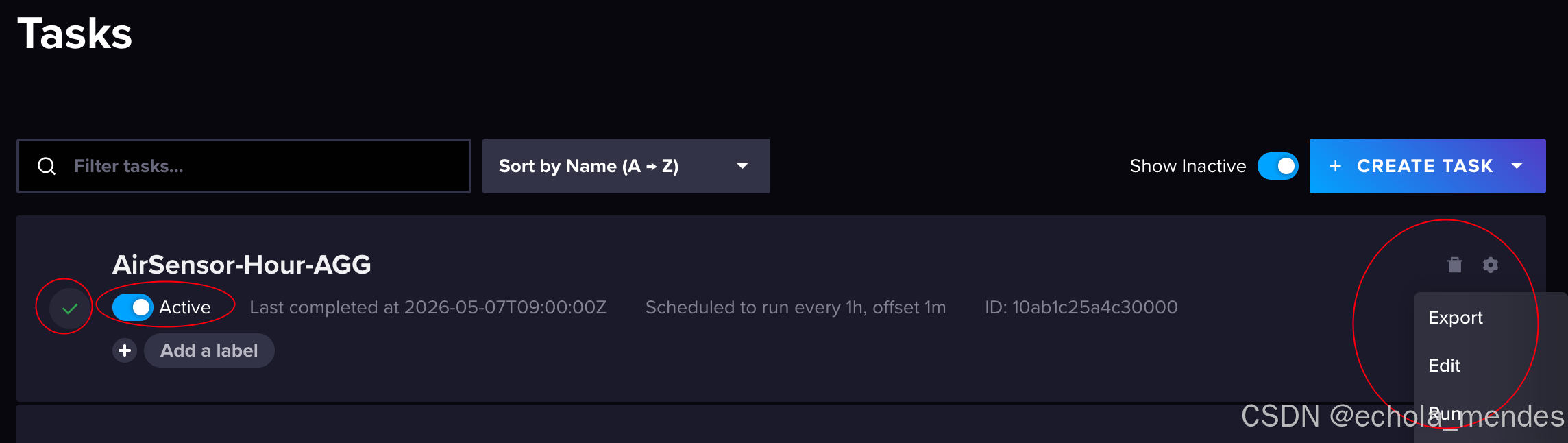
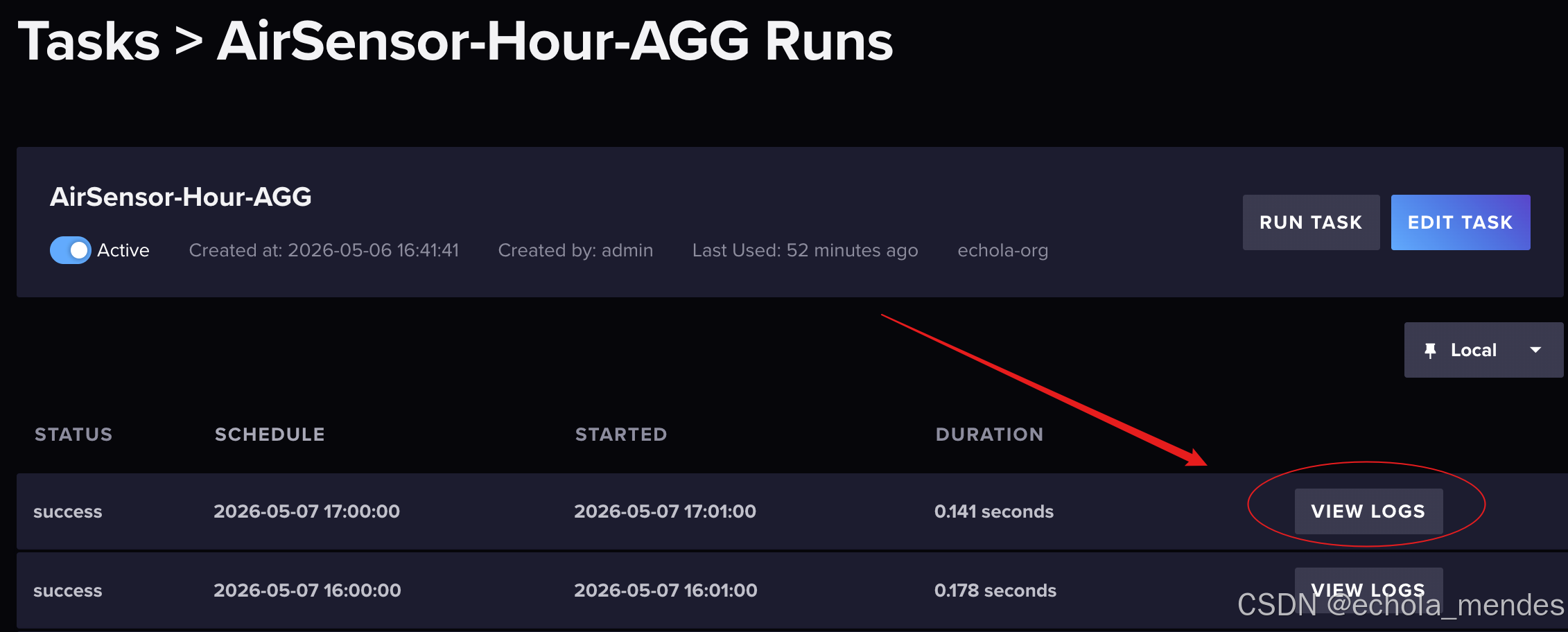
创建成功后,激活Active任务Task,Run Task后,如果执行成功,左侧会显示✅,悬停在Tsak点点击进入后,即可点击 View Logs查询运行日志信息
javascript
option task = {name: "AirSensor-Hour-AGG", every: 1h, offset: 1m}
// 原始数据源
data =
from(bucket: "echola-bucket")
|> range(start: -8h)
|> filter(fn: (r) => r._measurement == "airSensors")
|> filter(
fn: (r) => r._field == "temperature" or r._field == "humidity" or r._field == "co",
)
// 四个聚合并行计算,最后合并写入
union(
tables: [
// 1. 平均值
data
|> aggregateWindow(every: 1h, fn: mean, createEmpty: false)
|> map(fn: (r) => ({r with _field: r._field + "_mean"})),
// 2. 最大值
data
|> aggregateWindow(every: 1h, fn: max, createEmpty: false)
|> map(fn: (r) => ({r with _field: r._field + "_max"})),
// 3. 最小值
data
|> aggregateWindow(every: 1h, fn: min, createEmpty: false)
|> map(fn: (r) => ({r with _field: r._field + "_min"})),
// 4. 数据条数(判断是否有数据缺失)
data
|> aggregateWindow(every: 1h, fn: count, createEmpty: false)
|> map(fn: (r) => ({r with _field: r._field + "_num"})),
],
)
|> set(key: "_measurement", value: "airSensors_hourly")
|> set(key: "agg_type", value: "1h")
|> to(bucket: "echola-agg-bucket")这里的时区是:|> range(start: -8h) 而不是 |> range(start: -1h),是由于InfluxDB存储是按照UTC时间,与北京时间有8小时偏移。注意本文Flux查询使用的UTC时间,先忽略时差问题,后面再细讲。
对于MySQL方案,InfluxDB有三个优势:
- 存储与计算都在数据库内部完成------不需要把 3024w 行的数据通过网络拖到代码中计算,直接在存储引擎上聚合,执行速度快几十倍
- 按时间自动忽略过期数据(不读死数据)------分片机制让InfluxDB在的数据时天然跳过不属于查询范围的Shard,而MySQL需要靠索引进行扫描
- 聚合结果自动落入新的Bucket,不同策略独立管理------原始桶30天自动删除,聚合桶保留1年。这条"自动流水线"在 MySQL 里要写一堆脚本和 Cron 才能勉强模拟。
Task执行之后,聚合桶里存储的数据就是:
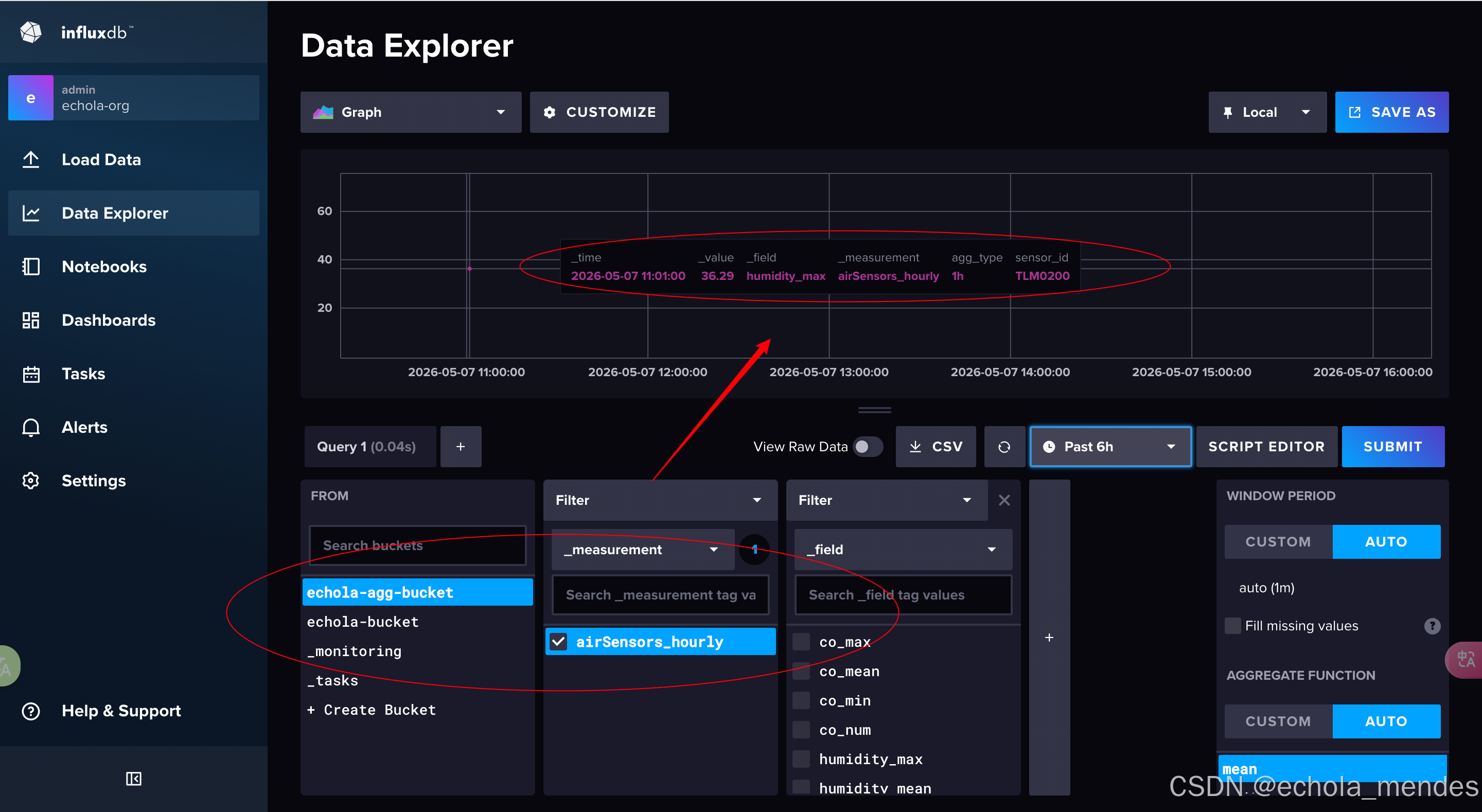
数据格式大概是这样:
| _measurement | sensor_id | _field | _value | _time |
|---|---|---|---|---|
| airSensors_hourly | TLM0100 | temperature_mean | 24.6 | 2026-05-01T12:00:00Z |
| airSensors_hourly | TLM0100 | humidity_mean | 35.2 | 2026-05-01T12:00:00Z |
| airSensors_hourly | TLM0100 | co_mean | 0.47 | 2026-05-01T12:00:00Z |
| airSensors_hourly | TLM0101 | temperature_mean | 32.0 | 2026-05-01T12:00:00Z |
| ... | ... | ... | ... | ... |
第二步:查询聚合结果
查某个传感器全天逐小时温度均值
javascript
from(bucket: "echola-agg-bucket")
|> range(start: 2026-05-01T00:00:00Z, stop: 2026-05-02T00:00:00Z)
|> filter(fn: (r) => r._measurement == "airSensors_hourly")
|> filter(fn: (r) => r.sensor_id == "TLM0100")
|> filter(fn: (r) => r._field == "temperature_mean")可以看到直接查询出每个小时的平均温度
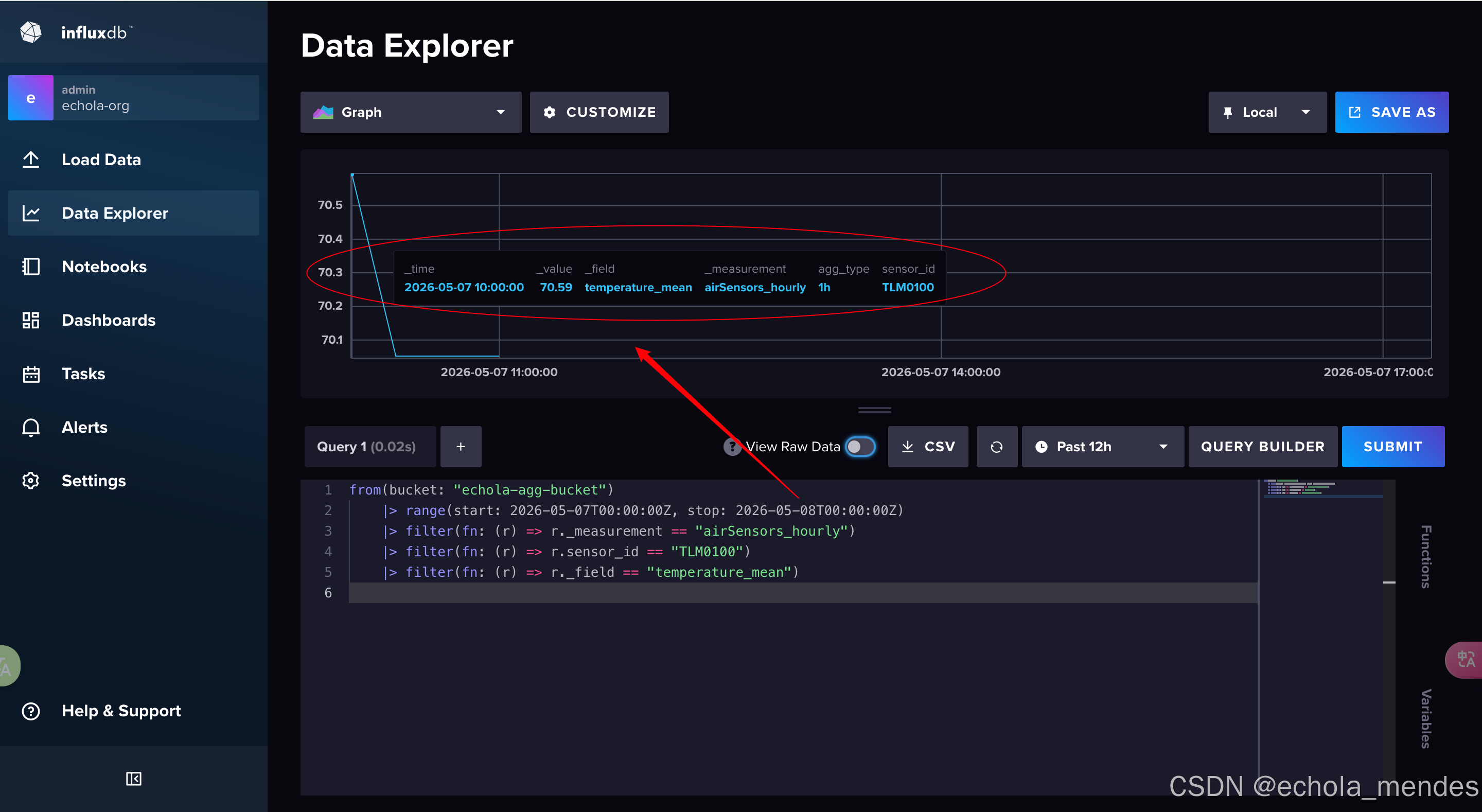
如果同时查询温度均值+最大值+最小值,需要使用Pivot展开
javascript
from(bucket: "echola-agg-bucket")
|> range(start: 2026-05-07T00:00:00Z, stop: 2026-05-08T00:00:00Z)
|> filter(fn: (r) => r._measurement == "airSensors_hourly")
|> filter(fn: (r) => r.sensor_id == "TLM0100")
|> filter(fn: (r) => r._field == "temperature_mean" or
r._field == "temperature_max" or
r._field == "temperature_min")
|> pivot(
rowKey: ["_time"],
columnKey: ["_field"],
valueColumn: "_value"
)pivot 之后的结果和 MySQL 的 SELECT 几乎一样:一行里同时有 temperature_mean、temperature_max、temperature_min 三列,返回的数据格式大概是:
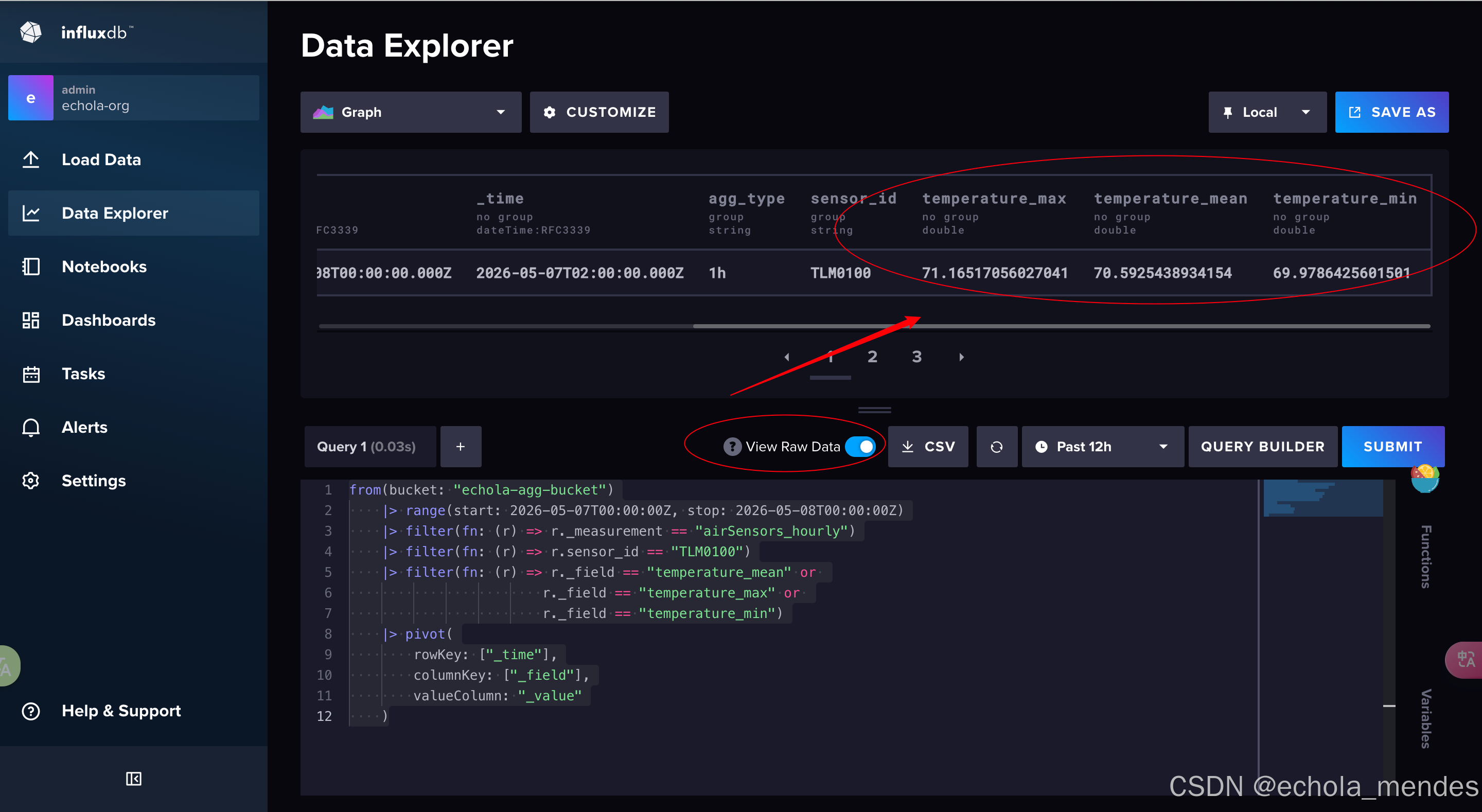
数据格式:
| _time | temperature_mean | temperature_max | temperature_min |
|---|---|---|---|
| 2026-05-01T12:00:00Z | 50.2 | 50.9 | 48.7 |
| 2026-05-01T13:00:00Z | 52.5 | 53.6 | 51.4 |
| 2026-05-01T14:00:00Z | 53.2 | 54.2 | 52.1 |
3.3 核心区别对比
| MySQL | InfluxDB | |
|---|---|---|
| 聚合时机 | 查询时现算(读时聚合) | Task 提前算好(写时聚合) |
| 数据落盘 | 不落盘,每次查都算 | 算完写入聚合桶,永久保留 |
| 扫描量 | 每次扫原始表的全量明细 | 只扫聚合桶的统计记录 |
| 查询速度 | 数据量大时明显变慢 | 始终很快,因为扫描量固定 |
| 历史数据 | 原始数据删除后无法回溯 | 聚合数据保留期独立,不受原始桶影响 |
3.4 降采样解决了压缩的什么问题?
降采样是纯数据密度的优化,它通过聚合统计,把高频的原始数据变成低频的统计值,直接减少数据点的数量
还是刚才的例子:
1000 台设备,每秒 1 个点
原始数据:8640 万点 / 天,30 天 25.9 亿点,压缩后 300GB
小时级聚合:2.4 万点 / 天,30 天 72 万点,压缩后 30MB
天级聚合:1000 点 / 天,1 年 36.5 万点,压缩后 15MB
年级聚合:1000 点 / 年,10 年 1 万点,压缩后几百 KB
降采样在压缩的基础上,又把长期存储成本降低了 3~4 个数量级
3.5 降采样的能力与不足:
降采样的本质缺陷:它是有损操作,只能处理历史数据
降采样是唯一会丢失信息的技术:
- 它永久丢失了原始数据的精度,无法恢复
- 它只能处理已经结束的时间窗口,无法处理正在写入的实时数据
这就是为什么我们必须保留 30 天的原始数据:用于最近的故障排查和异常点溯源。而 30 天以上的数据,我们只关心趋势,不关心每个单独的点。
降采样是把高精度的明细数据(如每秒一条),按时间窗口聚合成低精度的统计数据(如每小时一条均值、最大值)。
| 说明 | |
|---|---|
| 核心能力 | 1. 数据条数数量级减少 ,查询速度飞升。 2. 可永久保留统计趋势 ,让"查近一年"成为可能。 3. 可在聚合时顺便清洗异常值 |
| 主要不足 | 1. 不省存储,只省条数 :从源头上减少了行数,间接省空间,但它本身不负责编码压缩。 2. 统计信息不可还原 :算完均值就丢了原始明细,想追溯异常瞬间必须回查原始桶。 3. 窗口边界敏感:Task 的时间窗口和延迟窗口如果设计不好,会重复写入或漏数据 |
3.6 生产标准方案:双桶架构
生产环境绝对不会只用一个桶 + 30 天保留 ,而是用而是用「原始桶短保留 + 聚合桶长保留」的双桶标准方案。
- 原始桶 (echola-bucket):保留 30 天明细数据(用于最近的精细查询、故障排查),保留策略 30 天,Shard Group Duration 1 天。
- 聚合桶(echola-agg-bucket):保留 1 年甚至更久的聚合数据(用于长期趋势分析),保留策略 1 年,Shard Group Duration 7 天。
表格更直观一点(空气传感器场景):
| 桶名称 | 用途 | 保留策略 (RP) | Shard Group Duration | 写入模式 | 查询场景 |
|---|---|---|---|---|---|
echola-bucket |
原始明细数据 | 30 天 | 1 天 | 设备直写 / 网关批量写入 | 最近 30 天故障排查、异常点溯源、分钟级精细分析 |
echola-agg-bucket |
多层聚合数据 | 3 年 | 7 天 | 仅由系统 Task 自动写入(禁止人工写入) | 1 个月~3 年趋势分析、报表生成、大屏展示 |
- 原始桶 1 天 Shard:高频写入场景下,1 天 Shard 能最大化写入性能,且 30 天保留期结束后,整个 Shard 文件可直接物理删除,回收磁盘速度最快
- 聚合桶 7 天 Shard:聚合数据写入量极低(约为原始数据的 1/100~1/1000),7 天 Shard 能减少元数据数量,提升长期查询性能
- 3 年聚合保留期:满足环保、工业等行业对历史数据的合规要求,如需更长可延长至 5 年
- 禁止人工写入聚合桶:保证数据一致性,所有聚合数据必须由系统 Task 自动生成
降采样的聚合策略设计
以空气传感器数据为例,我们可以设计多层聚合,一般都是小时、天、周、月、年:
| 聚合粒度 | 时间窗口 | 保留时长 | 核心聚合指标 | 典型应用 |
|---|---|---|---|---|
| 小时级 | 1 小时 | 3 年 | 平均值、最大值、最小值、中位数、95 百分位数、数据点数 | 日趋势分析、小时峰值统计 |
| 天级 | 1 天(北京时间 00:00~23:59) | 3 年 | 平均值、最大值、最小值、中位数、95 百分位数、日均值、超标时长 | 日报表、月度对比 |
| 周级 | 1 周(周一至周日) | 3 年 | 周平均值、周最大值、周最小值、超标天数 | 周报表、季度趋势 |
| 月级 | 1 自然月 | 3 年 | 月平均值、月最大值、月最小值、超标天数、优良天数 | 月报表、年度考核 |
| 年级 | 1 自然年 | 永久 | 年平均值、年最大值、年最小值、年度优良率 | 年报、年度对比分析 |
上面已经有了小时级的聚合,那现在就可以直接使用上一聚合结果计算,无需直接读取原始数据,大幅提升性能:
- 天极聚合:基于小时级数据,每天凌晨 00:05 执行
- 周级聚合:基于天级数据,每周一凌晨 00:10 执行
- 月级聚合:基于天级数据,每月 1 日凌晨 00:15 执行
- 年级聚合:基于月级数据,每年 1 月 1 日凌晨 00:30 执行
关键设计原则
- 时区对齐 :所有聚合窗口必须使用北京时间 (UTC+8),而非默认 UTC 时间,这是国内生产环境最容易踩的坑
- 增量聚合:Task 只处理上一个完整的时间窗口,避免重复计算和数据覆盖
- 指标精简:每个粒度只保留业务真正需要的指标,不要盲目聚合所有可能的指标
- 数据完整性校验 :每个聚合结果必须包含
num字段,用于判断原始数据是否完整
天聚合Task,直接基于airSensors_hourly数据生成,保持了union多聚合并行、_field后缀命名的一致逻辑:
javascript
option task = {name: "AirSensor-Daily-AGG", every: 1d, offset: 5m}
// 小时聚合数据源(从聚合桶读取)
hourly_data =
from(bucket: "echola-agg-bucket")
|> range(start: -1d)
|> filter(fn: (r) => r._measurement == "airSensors_hourly")
|> filter(
fn: (r) =>
r._field =~ /.*_mean$/ or // 匹配所有_mean后缀字段
r._field =~ /.*_max$/ or // 匹配所有_max后缀字段
r._field =~ /.*_min$/ or // 匹配所有_min后缀字段
r._field =~ /.*_num$/, // 匹配所有_num后缀字段
)
// 四个聚合并行计算(基于小时聚合结果),最后合并写入
union(
tables: [
// 1. 对小时_mean求天平均
hourly_data
|> filter(fn: (r) => r._field =~ /.*_mean$/)
|> aggregateWindow(
every: 1d,
fn: mean,
createEmpty: false,
location: timezone.location(name: "Asia/Shanghai") // 北京时间对齐
)
|> map(fn: (r) => ({r with _field: r._field + "_daily"})),
// 2. 对小时_max求天最大
hourly_data
|> filter(fn: (r) => r._field =~ /.*_max$/)
|> aggregateWindow(
every: 1d,
fn: max,
createEmpty: false,
location: timezone.location(name: "Asia/Shanghai")
)
|> map(fn: (r) => ({r with _field: r._field + "_daily"})),
// 3. 对小时_min求天最小
hourly_data
|> filter(fn: (r) => r._field =~ /.*_min$/)
|> aggregateWindow(
every: 1d,
fn: min,
createEmpty: false,
location: timezone.location(name: "Asia/Shanghai")
)
|> map(fn: (r) => ({r with _field: r._field + "_daily"})),
// 4. 对小时_num求天总和(总数据条数)
hourly_data
|> filter(fn: (r) => r._field =~ /.*_num$/)
|> aggregateWindow(
every: 1d,
fn: sum,
createEmpty: false,
location: timezone.location(name: "Asia/Shanghai")
)
|> map(fn: (r) => ({r with _field: r._field + "_daily"})),
],
)
|> set(key: "_measurement", value: "airSensors_daily")
|> set(key: "agg_type", value: "1d")
|> to(bucket: "echola-agg-bucket")以此内推,聚合同中可以有多层聚合数据:
bash
echola-agg-bucket
├── airSensors_hourly # 小时级聚合measurement
├── airSensors_daily # 天级聚合measurement
├── airSensors_weekly # 周级聚合measurement
├── airSensors_monthly # 月级聚合measurement
└── airSensors_yearly # 年级聚合measurement这样,当查询 "近一年的温度趋势" 时,直接从聚合桶查小时级数据,数据量从 "365 天 × 24 小时 × 3600 秒 = 3153 万条" 降到 "365 天 × 24 小时 = 8760 条",查询速度提升数千倍。
如果使用从聚合桶查月级数据,单台设备的数据量从原始的365天 × 24小时 × 3600秒 = 3153万条,骤降至12条,查询速度提升260 万倍。可以看到明显提升了数据查询的效率
二、三者关系:分片 → 压缩 → 降采样
用一句话总结:
分片决定数据如何存储 压缩让存储空间更小 降采样让数据条数更少 Task 让这一切自动执行
它们配合起来,才能完美解决生产三大问题:
- 分片 → 快速删除过期明细,不卡顿
- 压缩 → 降低存储成本
- 降采样 → 保留历史统计结果,丢弃无用明细
- Task → 定时执行降采样 + 数据清洗
一个数据点的完整生命周期
一个温度数据点从传感器产生到最终归档的完整旅程:
- 传感器在 2026-05-08 14:35:22 上报温度 25.3℃
- 数据进入 InfluxDB,根据时间戳分配到 "2026-05-08" 这个 Shard
- 数据在内存中缓存,当 Cache 满了后刷入磁盘,自动压缩(从 16 字节压缩到约 2 字节)
- 2026-05-08 15:00,小时级聚合 Task 执行,读取 14:00~15:00 的压缩数据,计算出 14 点的平均温度 25.1℃
- 平均温度写入聚合桶的 "2026-05-08"Shard,自动再次压缩
- 2026-05-09 00:05,天级聚合 Task 执行,读取前一天的 24 个小时级数据,计算出日平均温度 24.8℃
- 日平均温度写入聚合桶的 "2026-05"Shard,自动再次压缩
- 30 天后,原始桶的 "2026-05-08"Shard 被整个物理删除,回收磁盘空间
- 3 年后,聚合桶的小时级数据被删除,只保留天级及以上数据
- 10 年后,只保留年级聚合数据,用于历史对比
用一个例子来说明:
以现在的空气传感器项目为例,假设:
- 1000 台设备,每台每秒上报 1 个数据点
- 原始数据写入量:100GB / 天
- 原始桶保留 30 天,聚合桶保留 3 年
| 技术组合 | 原始桶 30 天大小 | 聚合桶 3 年大小 | 总存储量 | 节省比例 |
|---|---|---|---|---|
| 什么都不做 | 3TB | 1095TB | 1098TB | 0% |
| 只有分片 | 3TB | 1095TB | 1098TB | 0% |
| 分片 + 降采样 | 3TB | 10GB | 3.01TB | 99.7% |
| 分片 + 降采样 + 压缩 | 300GB | 1GB | 301GB | 99.97% |
看到差距了吗?
- 降采样把总数据量从 1098TB 降到了 3TB(减少了 99.7%)
- 压缩又在这个基础上再减少了90%,从 3TB 降到了 300GB
这就是为什么即使有了分片和降采样,压缩仍然是必不可少的 ------ 它能在降采样的基础上,再给你带来10 倍以上的存储节省。
| 技术 | 核心作用 | 数据损失 | 适用范围 | 存储节省 |
|---|---|---|---|---|
| 分片 | 生命周期管理 + 精准查询 | 无 | 所有数据 | 0% |
| 降采样 | 减少长期数据点数 | 有(丢失精度) | 历史数据 | 90%~99% |
| 压缩 | 减少每个数据点的大小 | 无 | 所有数据 | 90%~99% |
三者关系一句话 :分片管删除效率、压缩管磁盘体积、降采样管查询速度。只有一个,生产必然在某个维度上失控;三者齐了,才构成完整无短板的生产存储方案