前言
本章内容与上一章节的图像分类任务(CIFAR-10)相近,主要区别在于:① 图像数据更复杂,多样性更大,图像增广处理不一致;② 使用预训练的模型,并采用冻结微调策略; ③ 预测的输出不再是类别,而是一个包含所有类别预测概率的向量。
下面着重介绍区别之处。
ImageNetDogs 数据集介绍
比赛网址:https://www.kaggle.com/c/dog-breed-identification
ImageNetDogs 是 ImageNet 数据集中针对犬类的子集,用于训练精细的图像分类,包含120个犬种,而且每个类别的训练图像数量有限。且相较于CIFAR-10,每张图像更高更宽,尺寸不一。

与CIFAR-10任务不同的是,本任务对于测试集中的每张图片,必须预测它对应于每个品种的概率:
id,affenpinscher,afghan_hound,..,yorkshire_terrier
000621fb3cbb32d8935728e48679680e,0.0083,0.0,...,0.0083
等等。代码实现
1 导包
python
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l2 获取和整理数据集
(1) 下载数据集
同样,为了方便入门,课程提供了小型数据集 kaggle_dog_tiny.zip 文件:
下载地址:https://d2l-data.s3-accelerate.amazonaws.com/kaggle_dog_tiny.zip
python
#@save
d2l.DATA_HUB['dog_tiny'] = (d2l.DATA_URL + 'kaggle_dog_tiny.zip',
'0cb91d09b814ecdc07b50f31f8dcad3e81d6a86d')
# 如果使用Kaggle比赛的完整数据集,请将下面的变量更改为False
demo = True
if demo:
data_dir = d2l.download_extract('dog_tiny')
else:
data_dir = os.path.join('.', 'data', 'dog-breed-identification')(2)整理数据集
读取训练数据标签、拆分验证集并整理训练集。
python
def reorg_dog_data(data_dir, valid_ratio):
labels = d2l.read_csv_labels(os.path.join(data_dir, 'labels.csv'))
d2l.reorg_train_valid(data_dir, labels, valid_ratio)
d2l.reorg_test(data_dir)
batch_size = 32 if demo else 128
valid_ratio = 0.1
reorg_dog_data(data_dir, valid_ratio)3 图像增广
ImageNet中图像的尺寸更大,也更复杂,多样性更大。
对于训练数据:设置随机裁剪0.08的比例其实是因为图像尺寸更大,拿到图像的一条腿/一只眼睛就可以判断其类别;另外对亮度、饱和度以及对比度也加了噪声以做更强一些的正则。
python
transform_train = torchvision.transforms.Compose([
# 随机裁剪图像,所得图像为原始面积的0.08~1之间,高宽比在3/4和4/3之间。
# 然后,缩放图像以创建224x224的新图像
torchvision.transforms.RandomResizedCrop(224, scale=(0.08, 1.0),
ratio=(3.0/4.0, 4.0/3.0)),
torchvision.transforms.RandomHorizontalFlip(),
# 由于数据比较复杂,多样性较大,因此随机更改亮度,对比度和饱和度
torchvision.transforms.ColorJitter(brightness=0.4,
contrast=0.4,
saturation=0.4),
torchvision.transforms.ToTensor(),
# 标准化图像的每个通道
torchvision.transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
transform_test = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
# 从图像中心裁切224x224大小的图片
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])4 读取数据集
与前一篇一致:
python
train_ds, train_valid_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_train) for folder in ['train', 'train_valid']]
valid_ds, test_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_test) for folder in ['valid', 'test']]
python
train_iter, train_valid_iter = [torch.utils.data.DataLoader(
dataset, batch_size, shuffle=True, drop_last=True)
for dataset in (train_ds, train_valid_ds)]
valid_iter = torch.utils.data.DataLoader(valid_ds, batch_size, shuffle=False,
drop_last=True)
test_iter = torch.utils.data.DataLoader(test_ds, batch_size, shuffle=False,
drop_last=False)6 微调预训练模型
这里提供一种策略:ImageNetDogs是取自ImageNet数据集上的子集,可以认为官方提供的预训练模型已经能够在原始数据集上取得不错的表现,所有设置:pretrained=True;
另外,为了针对狗的类别分类,添加一个新的单层MLP进行模型微调;
这里采用**"冻结微调"**的策略:模型前面所有卷积层的参数固定,只更新最后的单层MLP的参数;
python
def get_net(devices):
finetune_net = nn.Sequential()
finetune_net.features = torchvision.models.resnet34(pretrained=True)
# 定义一个新的输出网络,共有120个输出类别
finetune_net.output_new = nn.Sequential(nn.Linear(1000, 256),
nn.ReLU(),
nn.Linear(256, 120))
# 将模型参数分配给用于计算的CPU或GPU
finetune_net = finetune_net.to(devices[0])
# 冻结参数
for param in finetune_net.features.parameters():
param.requires_grad = False
return finetune_net7 训练函数
使用交叉熵损失:
python
loss = nn.CrossEntropyLoss(reduction='none')
def evaluate_loss(data_iter, net, devices):
l_sum, n = 0.0, 0
for features, labels in data_iter:
features, labels = features.to(devices[0]), labels.to(devices[0])
outputs = net(features)
l = loss(outputs, labels)
l_sum += l.sum()
n += labels.numel()
return (l_sum / n).to('cpu')与上一篇内容基本一致:
python
def train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period,
lr_decay):
# 只训练小型自定义输出网络
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
trainer = torch.optim.SGD((param for param in net.parameters()
if param.requires_grad), lr=lr, #只更新最后自定义的单层MLP的参数
momentum=0.9, weight_decay=wd)
scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_period, lr_decay)
num_batches, timer = len(train_iter), d2l.Timer()
legend = ['train loss']
if valid_iter is not None:
legend.append('valid loss')
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=legend)
for epoch in range(num_epochs):
metric = d2l.Accumulator(2)
for i, (features, labels) in enumerate(train_iter):
timer.start()
features, labels = features.to(devices[0]), labels.to(devices[0])
trainer.zero_grad()
output = net(features)
l = loss(output, labels).sum()
l.backward()
trainer.step()
metric.add(l, labels.shape[0])
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[1], None))
measures = f'train loss {metric[0] / metric[1]:.3f}'
if valid_iter is not None:
valid_loss = evaluate_loss(valid_iter, net, devices)
animator.add(epoch + 1, (None, valid_loss.detach().cpu()))
scheduler.step()
if valid_iter is not None:
measures += f', valid loss {valid_loss:.3f}'
print(measures + f'\n{metric[1] * num_epochs / timer.sum():.1f}'
f' examples/sec on {str(devices)}')8 训练和验证模型
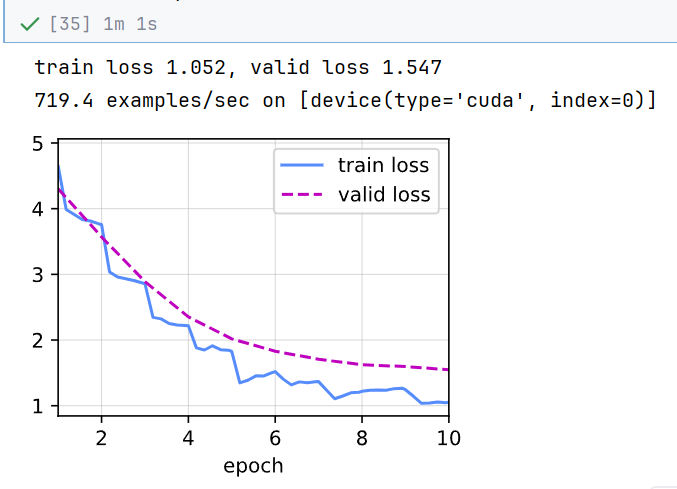
python
devices, num_epochs, lr, wd = d2l.try_all_gpus(), 10, 1e-4, 1e-4
lr_period, lr_decay, net = 2, 0.9, get_net(devices)
train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period,
lr_decay)//测试:
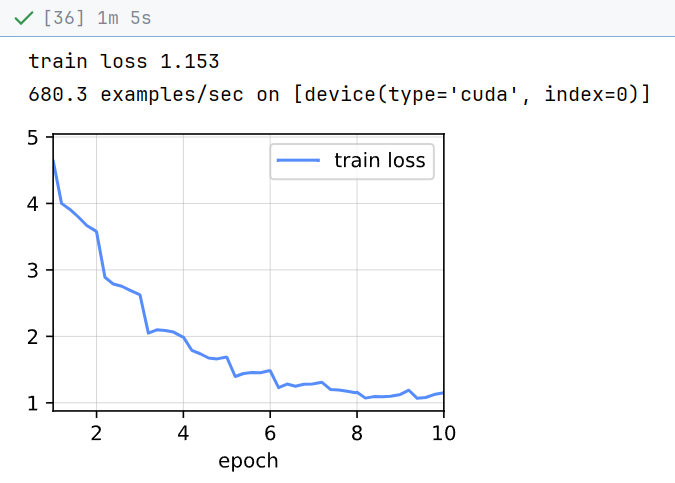
9 对测试集分类
在预测阶段:把数据放到显卡上,让模型跑一遍,然后把输出的结果通过Softmax 函数处理,算出每个类别可能性是多少。
torch.nn.functional.softmax(..., dim=1) ------ 概率转换
- Softmax:将 Logits 转换成 0 到 1 之间的概率值,且所有类别的概率之和严格等于 1。
输入 2.0, 1.0, 0.1 -> 输出 0.659, 0.242, 0.099。
这就意味着模型认为有 65.9% 的把握属于第 1 类。
dim=1 的含义:
在深度学习中,数据的形状通常是 (Batch_Size, Num_Classes),即 (批次大小, 类别数)。
dim=0 是批次维度,dim=1 是类别维度。
设置 dim=1 的意思是:"请针对每一行(每一个样本),把它对应的所有类别分数转换成概率"。这是分类任务中最标准的做法。
为什么要这么做呢?--- --- 当样本数量太多,甚至可能这个样本既是A类别,也属于B类别,此时大家不那么去关心Top 1的结果,反而常常取 Top 5的结果作为参考。
python
net = get_net(devices)
train(net, train_valid_iter, None, num_epochs, lr, wd, devices, lr_period,
lr_decay)
preds = []
for data, label in test_iter:
output = torch.nn.functional.softmax(net(data.to(devices[0])), dim=1)
preds.extend(output.cpu().detach().numpy())
ids = sorted(os.listdir(
os.path.join(data_dir, 'train_valid_test', 'test', 'unknown')))
with open('submission.csv', 'w') as f:
f.write('id,' + ','.join(train_valid_ds.classes) + '\n')
for i, output in zip(ids, preds):
f.write(i.split('.')[0] + ',' + ','.join(
[str(num) for num in output]) + '\n')