声明:
- 🍨 本文为 🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者: K同学啊
相关介绍:
SE注意力机制(Squeeze-and-Excitation Networks)
一、什么是SE?
SE全称为Squeeze-and-Excitation Networks(挤压与激发网络),是由胡杰等人于2018年提出的注意力机制,获得了ImageNet 2017冠军。其核心思想是:让网络自动学习每个特征通道的重要性,然后对通道进行加权,增强有用特征、抑制无用特征。
二、为什么需要SE?
在传统的卷积神经网络中,卷积操作对特征图的所有通道一视同仁。但实际上,不同通道对最终任务的贡献是不同的------有些通道提取到了关键特征,有些通道则是噪声。SE机制的引入,就是为了让网络能够"关注"到哪些通道更重要。
三、SE的三个核心步骤
SE模块的工作流程可以概括为三个步骤:Squeeze、Excitation、Scale。
第一步:Squeeze(挤压)
将每个通道的空间特征压缩为一个标量值。具体操作是使用全局平均池化,将形状为[H, W, C]的特征图压缩为[1, 1, C]。这个标量代表了该通道的"全局响应程度"。
第二步:Excitation(激发)
通过两层全连接网络学习通道之间的依赖关系。第一层降维(通常reduction=16),减少计算量;第二层升维,恢复到原始通道数。最后使用Sigmoid激活函数,将输出映射到0~1之间,得到每个通道的重要性权重。
第三步:Scale(缩放)
将原始特征图与学习到的重要性权重相乘。重要通道的值被放大,不重要通道的值被抑制。
任务1:在DenseNet结构中加入SE注意力机制,并完成猴豆病识别
采用自建数据集,数据集参数如下:
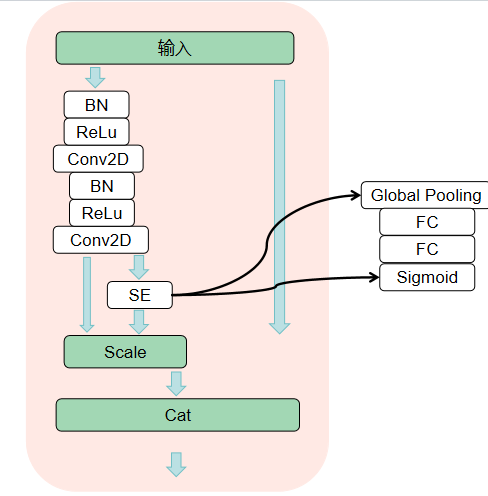
网络结构就是在DenseNet的Bottleneck中加入了一个SE模块
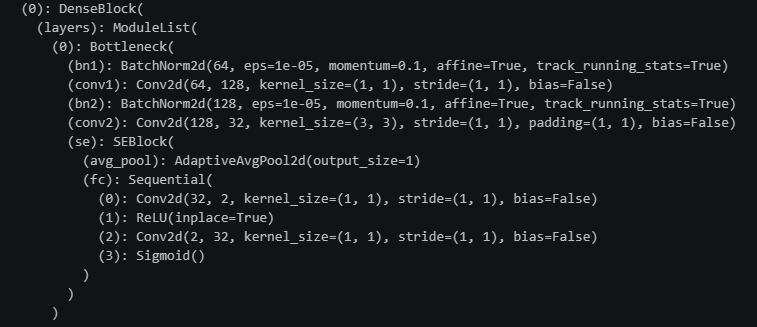
大概就是这样,代码仅需更改Bottleneck部分,并加入了一个封装好的SE类
class SEBlock(nn.Module):
def __init__(self, channels, reduction=16):
super(SEBlock, self).__init__()
inner_channels = max(channels // reduction, 1)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Conv2d(channels, inner_channels, 1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(inner_channels, channels, 1, bias=False),
nn.Sigmoid()
)
def forward(self, x):
y = self.avg_pool(x)
y = self.fc(y)
return x * y
class Bottleneck(nn.Module):
def __init__(self, in_channels, growth_rate):
super(Bottleneck, self).__init__()
self.bn1 = nn.BatchNorm2d(in_channels)
self.conv1 = nn.Conv2d(in_channels, growth_rate * 4, kernel_size=1, bias=False)
self.bn2 = nn.BatchNorm2d(growth_rate * 4)
self.conv2 = nn.Conv2d(growth_rate * 4, growth_rate, kernel_size=3, padding=1, bias=False)
self.se = SEBlock(growth_rate, reduction=16)
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = self.conv2(F.relu(self.bn2(out)))
out = self.se(out)
out = torch.cat([x, out], 1)
return out模型参数如图所示
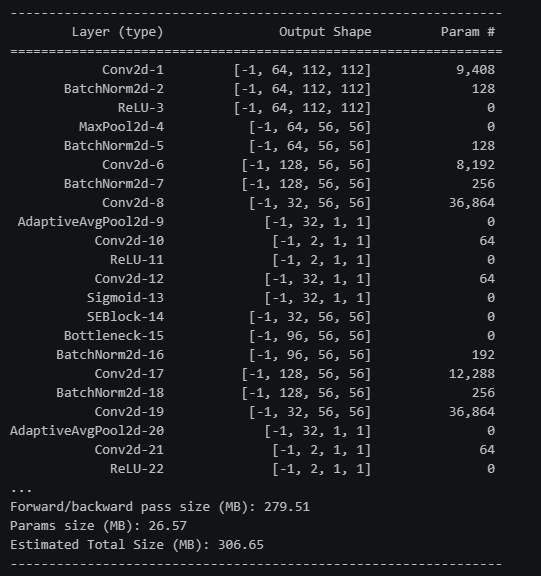
接下来对加入SE模块的模型与未加入SE模块的模型进行测试,对比他们的性能
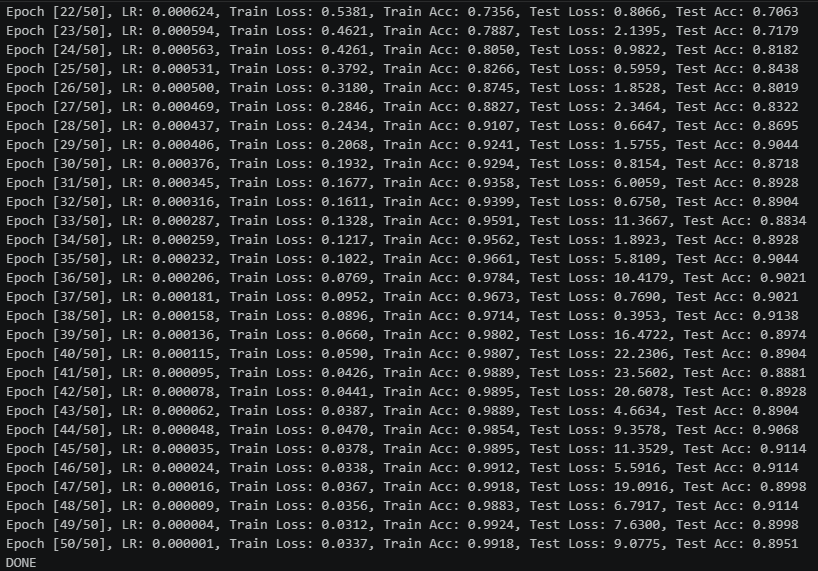
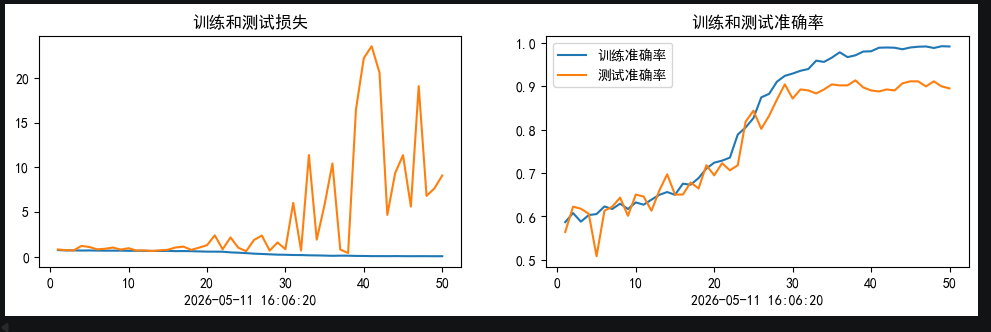
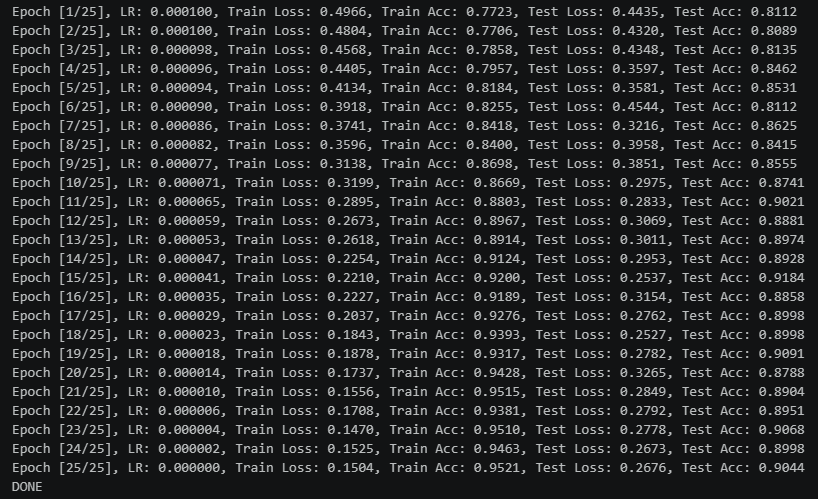
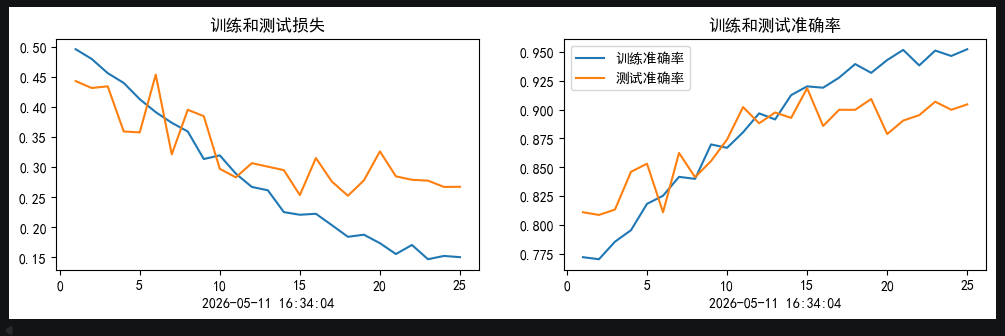
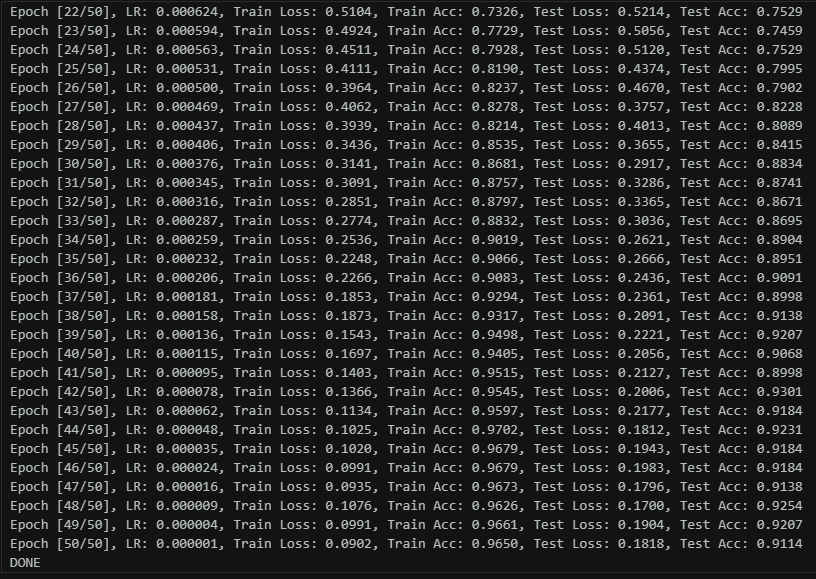
加入SE,50个epochs的0.001初始lr的余弦退火训练结果:
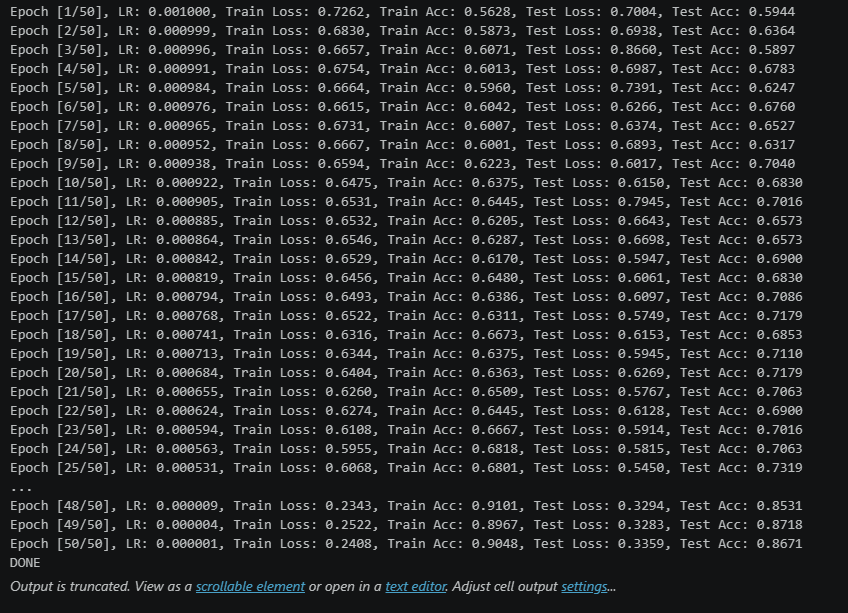
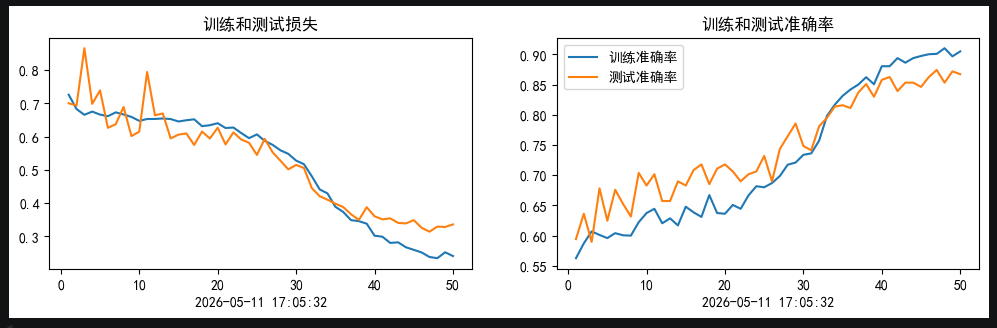
未加入SE,50个epochs的0.001初始lr的余弦退火训练结果:
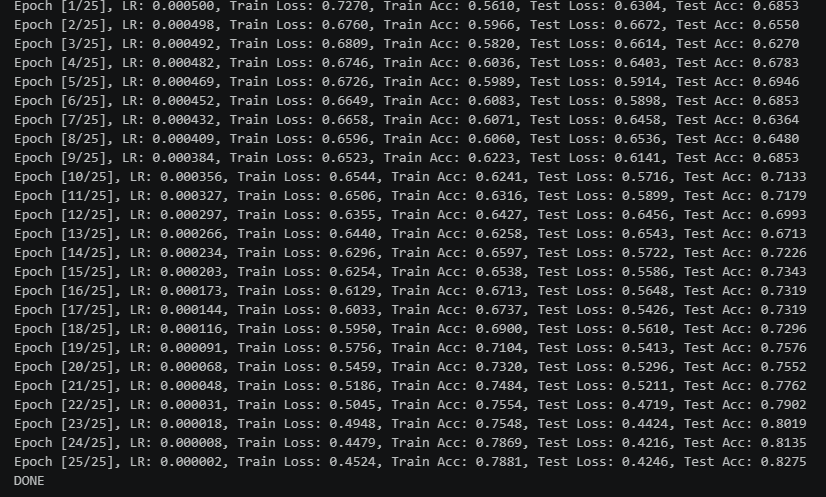
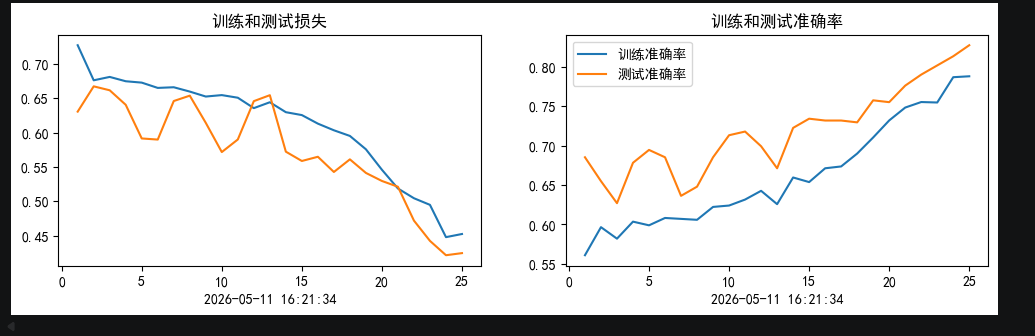
未加入SE,25+25个epochs的0.0005和0.0001初始lr的余弦退火训练结果:
任务1总结:
从训练结果可以看出,加入了SE模块的网络,比未加入的更快收敛.并且在训练集上达到了更高的准确率.并且测试集最优准确率达到91+(达到训练要求89+)
但是同样也有缺点存在,就是在我们这种小样本的情况下,模型出现了很明显的过拟合情况,这一点是小样本+注意力很难去解决的
其次,SE模块的sigmoid输出易饱和(接近0或1),且与DenseNet的特征累积机制叠加后,导致深层网络出现极端数值放大,少数样本logits爆炸使loss骤增但acc不变。
任务2:改进思路
减少注意力机制的影响,改用残差连接
self.alpha = nn.Parameter(torch.tensor(alpha))
.
.
.
return x * (1 - self.alpha + self.alpha * y)通过约束权重值的分配方式不让他太小来降低模型依赖
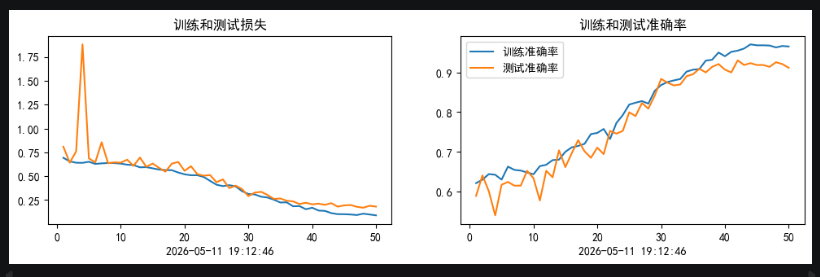
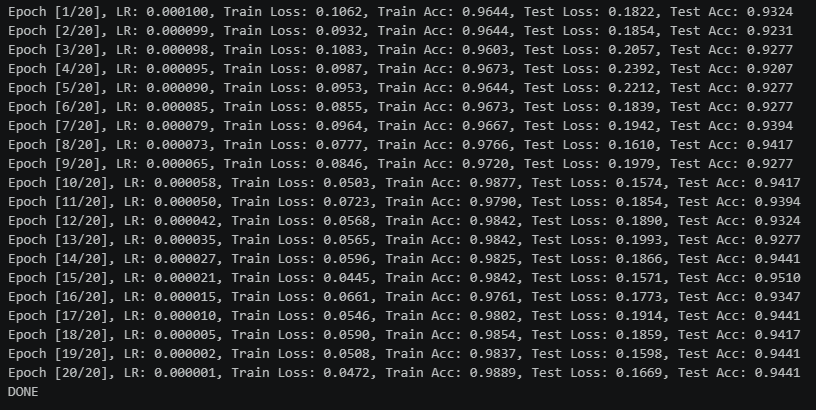
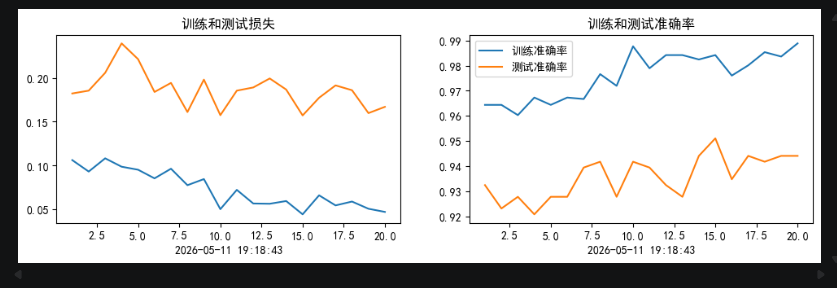
能看到抗拟合性能有明显的提升