
摘要
宿主间的微生物传播是塑造人类与微生物相互作用的基本过程。然而,宏基因组数据中同一物种的共存菌株对推断病原体和共生微生物的传播构成了重大挑战。为此,研究人员开发了TRACS (TRAnsmision Clustering of Strains)算法,这是一种能够精确估计菌株间单核苷酸多态性 (Single Nucleotide Polymorphisms, SNPs)遗传距离的高精度算法,其对宿主内物种多样性具有鲁棒性。通过对粪便微生物群移植(Faecal Microbiota Transplantation, FMT)数据集的分析和广泛的模拟实验,研究证明TRACS的性能优于现有方法。研究人员利用TRACS推断出携带多重菌株患者的传播网络,包括严重急性呼吸综合征冠状病毒2(SARS-CoV-2)的扩增子测序数据、肺炎链球菌(Streptococcus pneumoniae )的深度群体测序数据以及恶性疟原虫(Plasmodium falciparum )感染患者的单细胞基因组测序数据。将TRACS应用于母婴队列的肠道宏基因组样本,揭示了物种特异性的传播率,并识别出短双歧杆菌(Bifidobacterium breve)在婴儿体内持续存在的增加,这一发现此前因多重菌株的存在而被忽略。本研究表明,TRACS可跨微生物界使用,以揭示菌株动态。
背景
宿主间的传播是塑造人类与微生物相互作用的基本过程。利用基因组学追踪病原体的传播已成为公共卫生领域的重要工具,有助于在地方和全球范围内预防疾病传播。除了病原体,理解共生微生物的传播和定植动态将极大地增进我们对微生物组组装和维持的理解,以及饮食、生活方式、文化、临床干预和社会互动如何影响这一过程。此外,人类微生物组中的微生物具有治疗多种人类疾病的潜力。在诸如粪便微生物群移植和活体生物治疗产品等临床干预中识别候选菌株,将大大降低风险并加速基于微生物组的疗法开发。
全基因组测序(Whole-Genome Sequencing, WGS)通过检测单核苷酸多态性,改变了我们推断传播链的能力,使得能够精确追踪缓慢进化的病原体,如耐甲氧西林金黄色葡萄球菌。然而,大多数WGS分析聚焦于单一物种的代表性基因组,忽略了宿主内的微生物菌株多样性。最近的宏基因组方法通过同时分析多个物种和菌株来解决这一问题。针对特定物种的深度群体测序也可以通过靶向富集方法实现,例如培养或PCR扩增子测序,支持对菌株水平传播进行精细分析。然而,现有的用于追踪传播的宏基因组或深度群体测序数据分析方法通常是为精心设计的学术研究开发的。虽然这些方法提供了有价值的见解,例如宿主内变异识别和通过非同义与同义替换比率(dN:dS)识别选择压力,但它们缺乏常规公共卫生监测所需的速度和灵活性。值得注意的是,它们通常缺乏准确区分近期传播(数周至数月)和远缘基因组(数年)所需的时间分辨率。
依赖参考标记基因数据库的工具,如MIDAS和StrainPhIAn,仅考虑物种基因组的一小部分,并且不试图区分物种内多样性。这极大地限制了推断传播的时间分辨率。另一种方法,如StrainGE和inStrain(数据库模式),涉及识别整个数据集中发现的物种,并构建数据集特定的参考基因组数据库用于读段比对。这种方法严重依赖于传播菌株与参考基因组之间的相似性,并且不允许将新样本连续整合到分析中,因此不适合常规基因组监测。
另一种常见方法依赖于从头宏基因组组装 ,包括inStrain(组装模式)和STRONG流程。组装需要高测序覆盖度,并且当传播菌株与参考基因组高度相似时,性能最佳。这些方法通常在组装前将样本合并,然后在共组装流程中进行基因组分箱时表现最好。然而,为了避免广泛的基因组去重复(这实际上将过程转变为基于参考的方法),它们必须应用于样本对或减少的样本子集。这会显著增加计算负担。此外,现有算法通常未考虑样本内同一物种菌株间的重组和共享同源性,这在考虑宏基因组和群体测序数据时,可能对传播推断的准确性产生重大影响。为了解决这些问题,研究人员开发了TRACS,这是一种高精度且易于使用的算法,用于确定两个样本是否可能由近期传播事件相关联。
- Tonkin-Hill, G., Shao, Y., Zarebski, A. E., Mallawaarachchi, S., Xie, O., Maklin, T., Thorpe, H. A., Davies, M. R., Bentley, S. D., Lawley, T. D., & Corander, J. (2026). Strain-level transmission inference across multi-kingdom metagenomic data using TRACS. Nature Microbiology. https://doi.org/10.1038/s41564-026-02339-x
- 期刊:Nature Microbiology
- 发表时间:2026年4月24日(在线发表)
TRACS算法通过识别小至几个SNPs的遗传差异来区分密切相关菌株的传播,这在考虑缓慢进化的病原体时至关重要。该算法采用统计过滤技术来应对可变的序列覆盖度、菌株间的共享同源性以及测序错误。关键的是,TRACS旨在估计准确但保守的SNP距离下限,并独立考虑每个参考比对,从而实现新样本的连续整合。这种算法方法使TRACS能够以类似于传统单分离株基因组流行病学研究中使用SNP距离的方式运行,使其成为准确识别推定传播网络和排除持续公共卫生应用中传播事件的理想工具。然而,与单分离株研究类似,辨别精细尺度的传播结构,例如传播方向,通常需要额外的流行病学数据,如接触者追踪信息。
方法
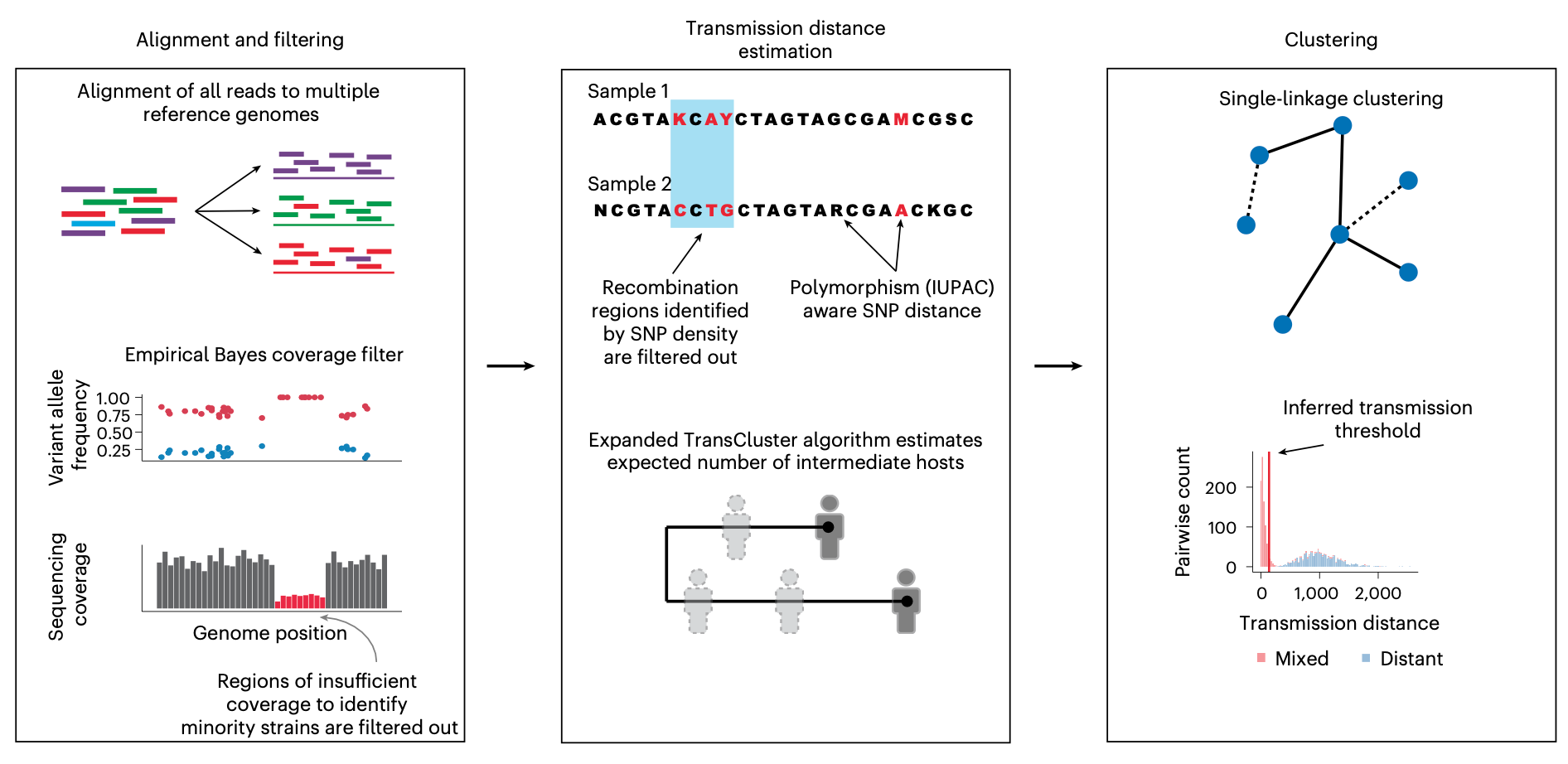
TRACS算法旨在从宏基因组或深度群体测序数据中推断菌株水平的传播。其核心流程整合了参考基因组比对、统计过滤和基于混合分布的阈值推断,以区分近期传播事件和远缘菌株。
输入: 宏基因组或群体测序样本
比对阶段
使用Sourmash识别
样本中最佳代表物种/菌株的参考基因组
将读段独立比对到每个参考基因组
统计过滤阶段
过滤低质量区域
(低覆盖度、多映射读段)
扫描统计量检测重组/高多态性区域
经验贝叶斯方法处理
覆盖度不足区域
生成过滤后的比对结果
转换为基于参考的多序列比对
使用IUPAC-aware算法
计算成对SNP距离
可选: 结合采样日期和
传播世代时间估计中间宿主数
使用混合分布模型推断传播距离阈值
输出: 成对SNP距离矩阵、
推定传播簇、中间宿主估计
核心算法概述:
- 比对阶段:TRACS使用基于哈希的搜索算法"Sourmash"来识别一组最能代表样本中物种及其菌株的参考基因组。与依赖竞争性比对的替代方法不同,TRACS将读段独立比对到每个参考基因组,从而能够在每个位点观察等位基因计数。这使得能够增量添加新样本,并将其他物种整合到参考数据库中,而无需重新处理现有数据。
- 统计过滤:应用一组统计过滤算法来排除受共享序列同源性、多映射读段、比对质量差和低测序覆盖度影响的区域。这包括一个类似于系统发育学中用于检测重组的扫描统计量,可以识别多态性率升高的区域,这些区域通常由共存菌株间的共享序列同源性或基因复制引起。TRACS还包含一种经验贝叶斯方法,用于处理参考基因组中覆盖度不足以准确代表样本中存在的多个菌株的区域。
- 距离计算与聚类:经过滤的比对结果被转换为基于参考的多序列比对。随后,TRACS整合了一个快速、支持国际纯粹与应用化学联合会(IUPAC)编码的成对SNP距离估计算法。可选地,TRACS可以结合采样日期和已知的传播世代时间来估计两个样本之间的预期中间宿主数量。最后,使用单链接层次聚类对成对传播距离估计进行聚类,以推断推定传播簇。传播距离阈值通过混合分布模型推断,以区分已知远缘的样本对和包含近期传播的样本对。
结果
TRACS在模拟样本对中表现优异
为了评估TRACS在包含同一物种多个菌株的样本对中准确估计小遗传距离的能力,研究人员模拟了来自常见肺炎链球菌菌株混合物的全基因组测序读段。对于肺炎链球菌,常见的传播SNP阈值通常小于10个SNPs。在每个样本对中,他们选择一个基因组在样本间以指定的SNP距离(5、50和500个SNPs)共享,并确保传播菌株的最小平均测序覆盖度为5倍。将TRACS算法与InStrain、StrainGE和StrainPhlAn进行了比较。
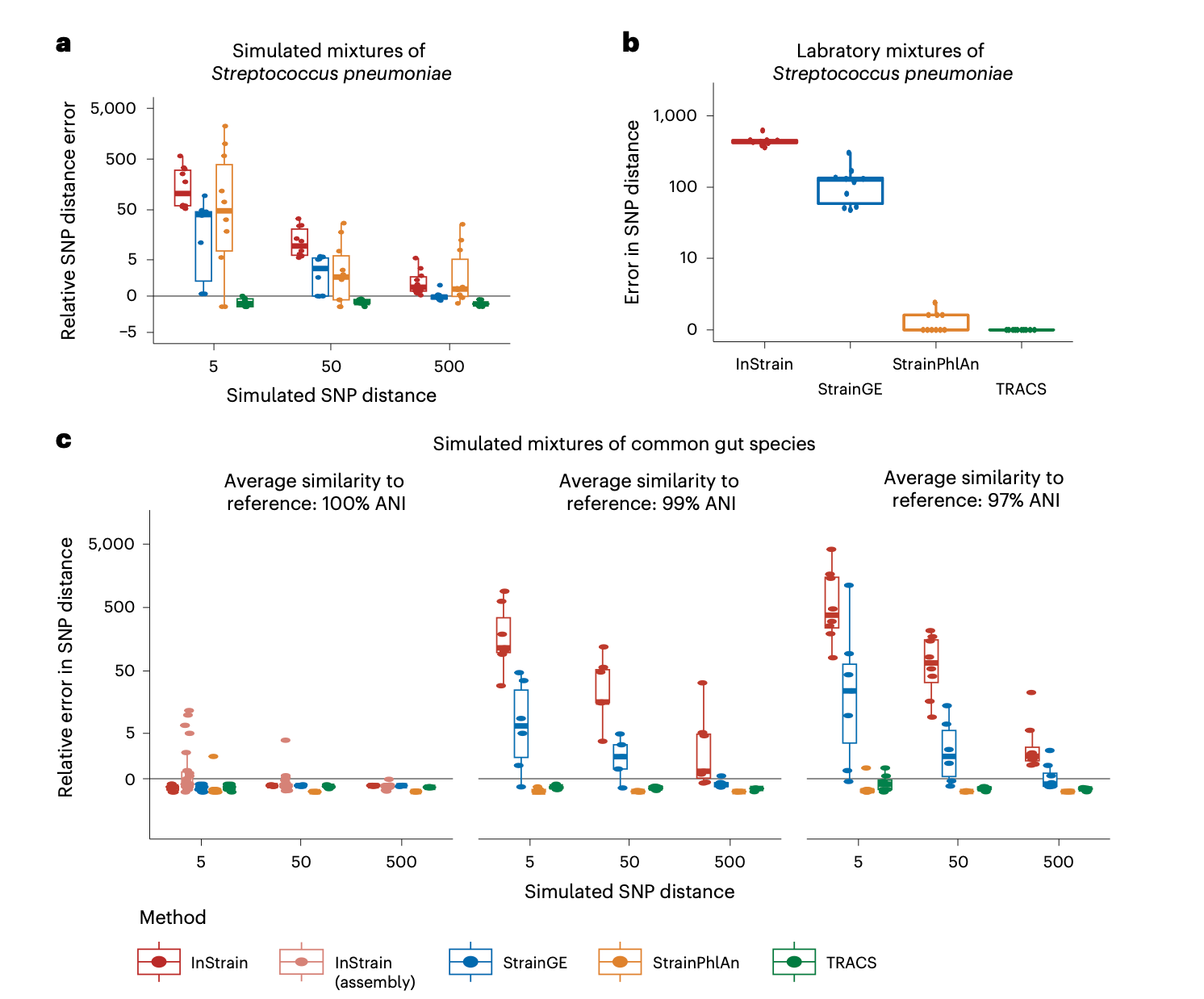
除TRACS外,所有算法都显著高估了遗传距离。这种偏差在低频菌株中更大,限制了这些算法可靠排除近期传播事件的能力,因为许多物种常用的SNP距离阈值远低于这些算法产生的估计值。StrainGE是除TRACS外表现最好的算法,这可能是由于其能够考虑物种内基因组间的竞争性比对,从而有助于减轻水平基因转移的影响。然而,StrainGE仅在较高的SNP值(500个SNPs)下报告了相对准确的SNP距离,这超过了用于区分肺炎链球菌传播的常见阈值(通常小于50个SNPs)。为了确定TRACS算法中哪个过滤器影响最大,研究人员评估了TRACS中实现的统计过滤方法的组合。覆盖度过滤器(包括经验贝叶斯算法)产生了最大的改进,其次是重组过滤器。使用模拟的Nanopore R10.4.1读段重复这些模拟,进一步证明了TRACS与多种高精度测序技术的兼容性。
为了使用具有已知真实情况的实际测序数据验证这些结果,研究人员分析了先前研究中13个不同肺炎链球菌菌株的实验室混合物。在每种情况下,样本之间至少共享一个相同的肺炎球菌基因组,这意味着所有算法都应推断出零个SNPs。TRACS是唯一在所有情况下都能可靠推断出零个SNPs的算法。StrainPhlAn在某些情况下正确识别了零个SNPs;然而,其对标记基因的依赖可能导致其系统性地低估SNP距离,正如后续对FMT数据的分析所示。
为了进一步探索从涉及多个不同物种的宏基因组数据中重建传播链,研究人员模拟了代表常见肠道细菌的基因组混合物,这些混合物与参考数据库的相似度水平不同:100%、99%和97%的成对序列一致性。在这些模拟中,模拟了先前一项使用宏基因组学进行传播研究中识别的单个物种以指定的SNP距离传播。除了StrainPhlAn使用其默认标记基因数据库v4.0.5外,所有方法都使用了一个共同的参考数据库。一旦传播基因组与参考数据库的差异达到至少1%,InStrain对大多数模拟对的SNP距离估计就持续偏高。生成研究特定参考数据库的替代策略,例如所有样本的共组装或单个样本组装后进行去重复,可能会改善这些估计。然而,由于InStrain依赖于竞争性读段比对,建议对其参考数据库进行去重复,以便任何一对基因组的序列一致性不超过98%。因此,在存在同一物种多个菌株的研究中,与组装和/或去重复后的参考基因组存在差异的菌株仍会产生类似的错误。
作为替代方案,研究人员探索了生成样本对特异性参考基因组。在这种模式下,使用metaSPAdes独立组装每对样本,为每对生成唯一的参考数据库。虽然这种方法改善了SNP距离估计,但其计算成本对于大型研究来说是难以承受的。排除组装的计算成本,使用对特异性参考需要InStrain比对和SNP调用步骤,每对大约需要12.5个中央处理器小时。对于一个包含100个样本的中等规模数据集,这将转化为4,950个独立的比对步骤和超过2.5千个CPU小时。此外,如果在给定的一对样本中存在同一物种的多个菌株,这种方法可能仍然无法将传播菌株组装为参考基因组。
跨不同类群增强的传播估计
TRACS算法的一个主要优势是能够在宿主被同一物种的多个菌株定植的情况下识别推定传播事件。这在许多高疾病负担环境中是一个主要问题。与StrainPhlAn等替代算法不同,TRACS算法适用于包括寄生虫、病毒和细菌物种在内的多种分类群。为了证明TRACS算法在广泛病原体中的有效性,研究人员考虑了三种不同环境下特征明确的数据集。
严重急性呼吸综合征冠状病毒2。尽管感染多种SARS-CoV-2菌株相对罕见,但在高疾病负担地区,如医院病房内,尤其是在感染控制程序失效时,其发生率可能很高。为了证明TRACS算法应对这一挑战的能力,研究人员考虑了2020年初从英格兰东部收集的1,181个SARS-CoV-2样本中的37个,这些样本使用Illumina深度扩增子测序进行了处理。这些样本在重复测序以考虑测序错误后,被发现包含多种不同的菌株。将这些样本与混合物中包含单一菌株的样本进行了比较。因此,样本间的最小SNP距离应为零。为了研究将TRACS应用于这些样本的效用,研究人员比较了使用TRACS推断的SNP距离与基于共识序列的方法(无论是否过滤问题位点,如高突变位点和受扩增子测序读段末端影响的区域)推断的SNP距离。
当共享菌株处于少数时,基于共识的方法持续高估了样本间的SNP距离。相比之下,TRACS在所有情况下都正确推断出样本间为0个SNPs,且无需手动过滤问题位点。该示例突显了TRACS既能够解释多重菌株的存在,又能够稳健控制测序错误和高突变位点的影响,这些因素经常导致样本内出现多态性变异。TRACS也可能对宿主内菌株间罕见的重组情况具有鲁棒性。在这种情况下,忽略多态性可能导致共识方法高估SNP距离,而如果对两个亲本菌株都有足够的覆盖度,TRACS仍然能够检测样本间的共享菌株。
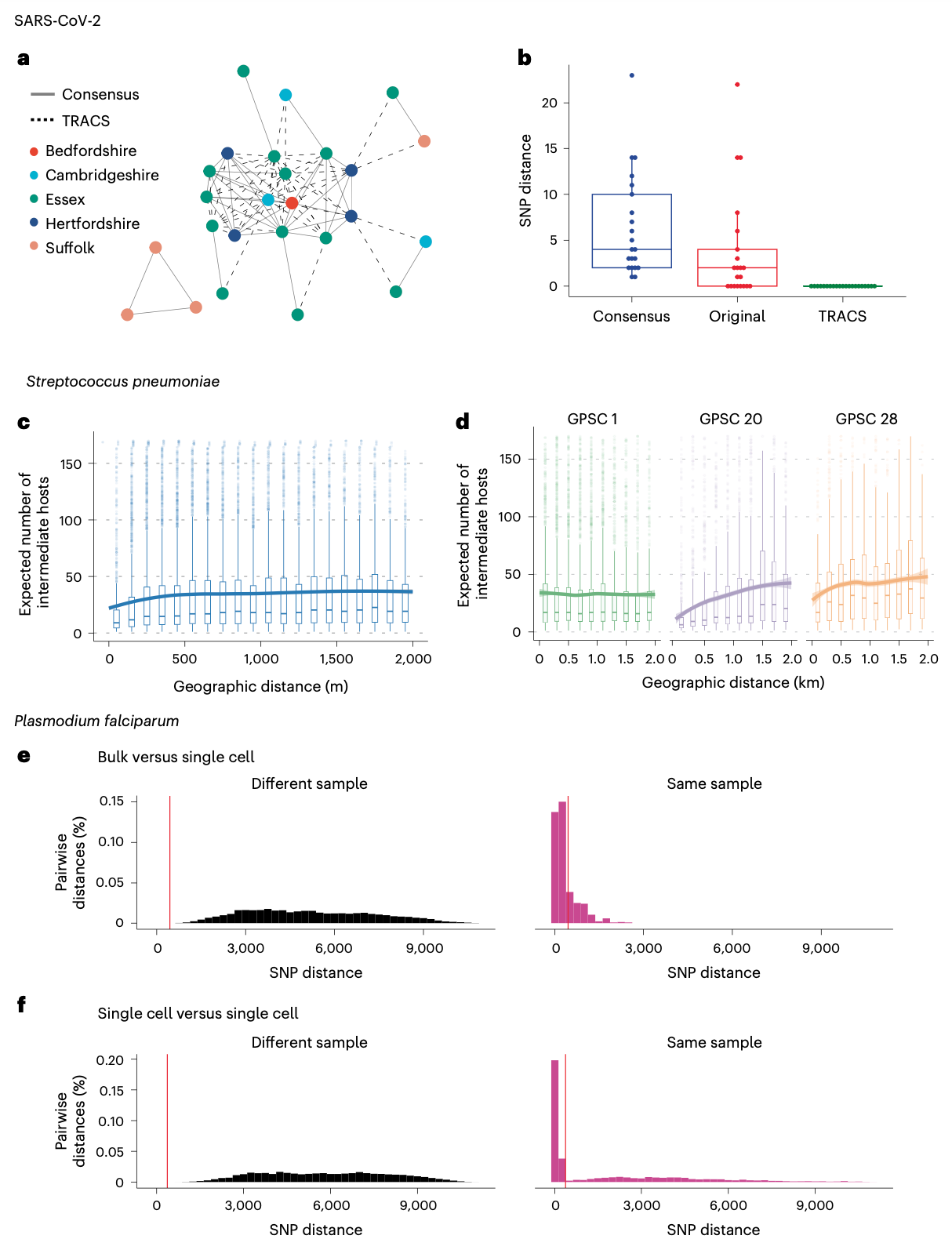
肺炎链球菌。TRACS算法的另一个好处是能够通过结合采样日期来估计两个样本之间的预期中间宿主数量。日期可以作为额外的信息,用于排除序列多样性低的物种或谱系的传播。
为了证明这种方法,研究人员考虑了来自泰国一个难民营的468名婴儿及其145位母亲的3,761份鼻咽拭子,作为先前研究的一部分,这些样本进行了基于培养的富集和全肺炎球菌群体Illumina深度测序。使用来自全球肺炎球菌测序项目的肺炎球菌参考基因组自定义数据库在此数据集上运行了TRACS。与先前的研究一致,假设分子钟速率为每年5.3个SNPs,传播世代时间为2个月。运行TRACS后,将所有样本对之间的预期中间宿主数量与参与者家庭之间的地理距离进行了比较。尽管原始的TransCluster算法先前已应用于此数据集,但它仅估计个体概率,例如直接传播的概率,而不估计中间宿主的总体预期数量。
尽管难民营面积很小,但地理距离与预期中间宿主数量之间存在很强的相关性。有趣的是,并非所有主要谱系都发现了这种相关性。特别是,常见的多重耐药谱系,如全球肺炎球菌测序簇1,在营地内的传播与地理距离之间没有明显的关联。已知这些谱系具有更长的携带持续时间,这可能掩盖地理传播信号。因此,观察到的信号可能由传播更快且携带持续时间更短的谱系驱动,例如GPSC 20。理解支配这些谱系传播的不同动态对于设计旨在减少肺炎球菌疾病的干预措施至关重要。
恶性疟原虫。主要寄生虫病原体基因组大小的增加阻碍了常规全基因组测序在疾病监测中的采用。然而,测序成本的迅速下降导致全基因组测序越来越多地用于追踪主要寄生虫种群,包括每年导致超过50万人死亡的疟疾寄生虫------恶性疟原虫。在疾病负担高的流行地区,经常发现恶性疟原虫的多种菌株。
为了研究TRACS算法准确识别混合恶性疟原虫感染中共享菌株的能力,研究人员考虑了一个涉及来自马拉维Chikhwawa的49个样本的数据集,这些样本恶性疟原虫检测呈阳性。作为先前研究的一部分,除了单细胞和单克隆富集外,还进行了混合群体的Illumina批量测序,产生了49个混合全基因组测序样本和509个单细胞样本。TRACS算法应用于该数据集,使用恶性疟原虫参考基因组。TRACS推断的SNP距离分布显示,来自同一宿主的单细胞样本之间具有大量短SNP距离,这表明TRACS可以准确区分混合感染中密切相关的基因组。相比之下,批量样本与单细胞样本之间的SNP距离分布更广,反映了混合感染中菌株的多样性。使用TRACS混合分布方法推断的SNP阈值能够有效区分近期传播和远缘菌株。
在粪便微生物群移植数据集中识别菌株传播
粪便微生物群移植是一种将供体粪便微生物群移植到受体肠道中以治疗特定疾病的临床干预措施。追踪FMT后供体菌株在受体中的定植对于理解治疗机制和优化供体筛选至关重要。然而,FMT样本通常包含同一物种的多个菌株,这使得使用传统方法准确推断菌株传播变得困难。
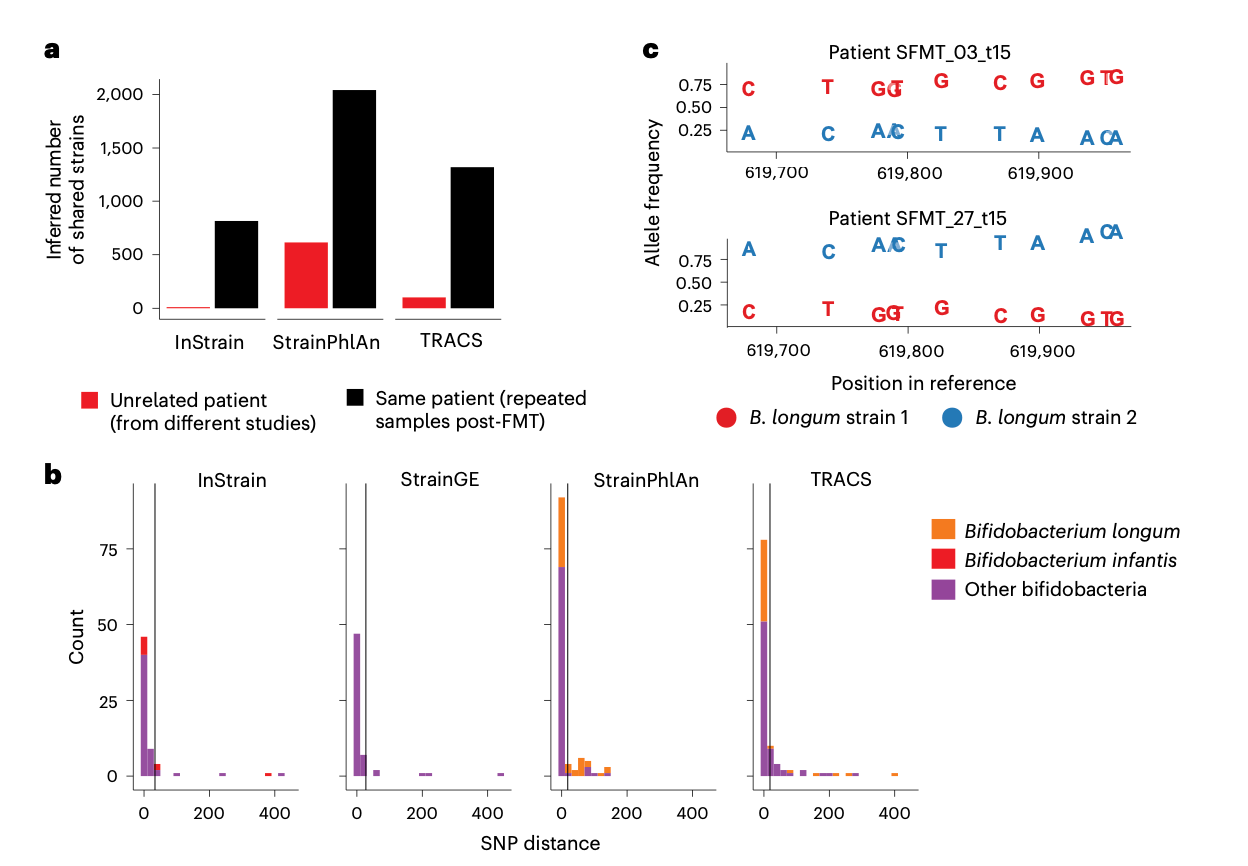
为了评估TRACS在FMT场景中的性能,研究人员分析了一个公开可用的FMT数据集,该数据集包含来自单个供体和多个受体的纵向样本。他们将TRACS与InStrain和StrainGE进行了比较。TRACS在识别供体-受体对之间共享菌株方面表现出更高的灵敏度,特别是在菌株频率较低的情况下。例如,TRACS成功识别了短双歧杆菌从供体到多个受体的传播,而其他方法由于存在多个菌株而未能检测到。此外,TRACS揭示了物种特异性的传播率,某些物种(如普拉梭菌)的传播率高于其他物种。这些发现突显了TRACS在复杂微生物群落中解析精细尺度传播动态的能力。
一个特别有趣的案例是,TRACS在单个供体和多个受体之间检测到了长双歧杆菌的多个菌株传播。等位基因频率分析显示,一个红色菌株在一个受体样本中占主导地位,但在接受相同供体粪便的另一个受体样本中处于少数。这种模式表明,同一供体中的不同菌株可能在不同受体中以不同的频率定植,这可能受受体肠道环境或菌株间竞争的影响。这一发现强调了在FMT和其他微生物组干预措施中考虑菌株水平分辨率的重要性。
英国出生队列中的菌株传播与持续存在
为了探索TRACS在共生微生物传播研究中的应用,研究人员分析了来自英国出生队列的肠道宏基因组样本。该队列包括通过剖腹产和阴道分娩出生的婴儿及其母亲的纵向样本。TRACS被应用于推断母婴之间以及婴儿随时间推移的菌株传播和持续存在。
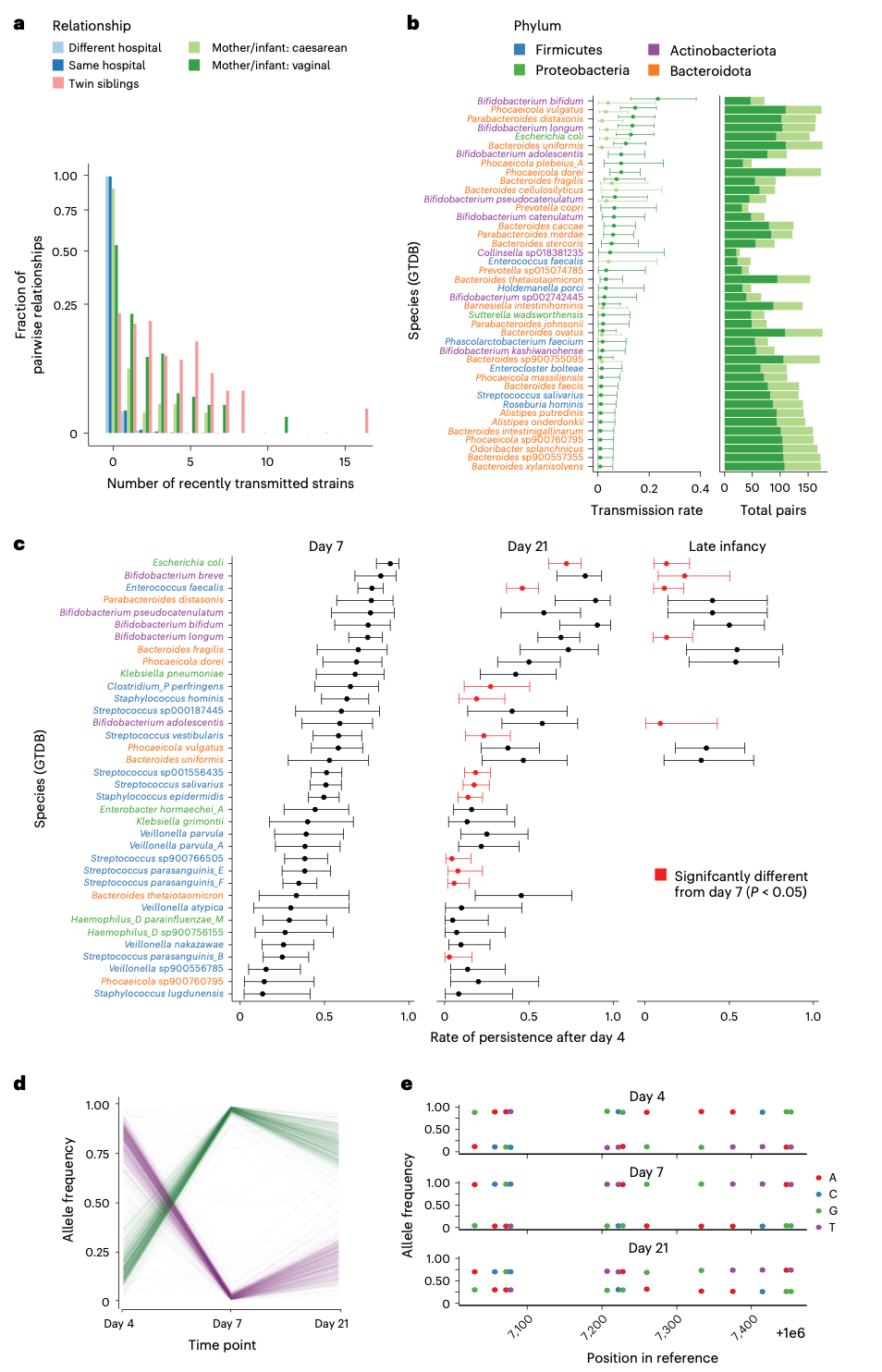
分析显示,分娩方式显著影响了特定细菌物种的传播率。与阴道分娩的婴儿相比,剖腹产出生的婴儿从母亲那里获得双歧杆菌属(Bifidobacterium)和拟杆菌属(Bacteroides)等关键早期定植菌株的几率显著降低。这一发现与先前关于分娩方式对微生物组组装影响的研究一致,但TRACS在菌株水平上提供了更高的分辨率。
值得注意的是,TRACS揭示了之前被忽视的菌株动态。例如,在婴儿样本中,算法检测到两种不同的短双歧杆菌菌株共存,并且在出生后的几周内,菌株的相对丰度发生了动态更替------一种起初占优势的菌株被另一种逐渐取代。这种多菌株共存与演替的现象,由于传统工具通常只考虑优势基因型而被长期忽略。TRACS的分析表明,短双歧杆菌在婴儿体内的持续存在比以前认识到的更为普遍,并且可能对婴儿的免疫发育和长期健康产生重要影响。
此外,研究人员使用TRACS来估计婴儿体内菌株的持续存在时间。分析显示,不同物种的菌株持续存在时间存在显著差异。例如,某些双歧杆菌菌株在婴儿出生后的第一年内持续存在,而其他菌株则被新获得的菌株迅速取代。这种物种特异性的持续模式可能反映了宿主与微生物相互作用的差异,以及不同菌株在婴儿肠道环境中的适应能力。
将TRACS应用于这个大型母婴队列的肠道宏基因组数据,描绘了一幅生命早期微生物组建立的精细图景。分析证实,剖腹产显著降低了母亲向婴儿传递特定共生菌株的几率。值得注意的是,双歧杆菌等早期定植的核心菌群,其菌株在婴儿体内的持久性存在显著物种差异。TRACS的强大之处还在于揭示了之前被忽视的菌株动态。
讨论与结论
本研究介绍了TRACS,一种用于从宏基因组和深度群体测序数据推断菌株水平传播的新算法。通过广泛的模拟和实际数据集验证,研究证明TRACS在准确估计小遗传距离、处理宿主内物种多样性以及跨不同微生物类群应用方面优于现有方法。
TRACS算法的主要优势在于其鲁棒性和灵活性。通过采用统计过滤技术来应对测序错误、低覆盖度区域和菌株间共享同源性,TRACS能够提供准确且保守的SNP距离估计。其独立处理每个参考比对的能力允许新样本的连续整合,使其适用于持续的基因组监测和爆发调查。此外,TRACS能够结合采样日期和传播世代时间来估计中间宿主数量,为传播动力学提供了额外的见解。
在公共卫生应用方面,TRACS具有重要价值。准确识别传播事件对于疫情调查、感染控制措施评估和疫苗策略制定至关重要。TRACS处理多重菌株感染的能力在高疾病负担环境中尤其相关,例如结核病、疟疾和肺炎球菌疾病流行地区,这些地区混合感染很常见。通过提供菌株水平的传播推断,TRACS可以帮助识别传播热点、追踪耐药菌株的传播以及评估干预措施的有效性。
在微生物组研究中,TRACS为理解共生微生物的传播和定植动态提供了新的工具。通过应用于母婴队列,TRACS揭示了物种特异性的传播率,并识别出短双歧杆菌在婴儿体内持续存在的增加。这些发现增进了我们对早期生命微生物组组装的理解,并可能为针对婴儿肠道健康的益生菌干预提供信息。此外,TRACS在FMT研究中识别供体菌株定植的能力可以优化供体筛选和受体监测,从而提高治疗成功率。
尽管TRACS具有诸多优势,但也存在一些局限性。首先,该算法依赖于参考基因组数据库的完整性和质量。在参考数据库未能充分代表样本中存在的菌株多样性的情况下,TRACS的性能可能会下降。其次,虽然TRACS可以估计SNP距离和推断传播簇,但确定传播方向通常需要额外的流行病学数据,如接触者追踪信息。第三,TRACS的计算效率虽然优于某些需要成对组装的方法,但对于超大规模数据集可能仍然具有挑战性。
未来的研究可以集中在以下几个方向:算法优化 以提高计算效率和处理更大数据集的能力;数据库扩展 以涵盖更广泛的微生物多样性;整合多组学数据 如代谢组学或宿主基因组学,以提供更全面的传播动态视图;以及前瞻性应用于正在进行的监测项目,以实时追踪病原体传播和评估干预措施。
总之,TRACS算法通过提供一种准确、鲁棒且灵活的方法来推断菌株水平的传播,填补了现有宏基因组分析工具的空白。其跨病毒、细菌和寄生虫应用的通用性使其成为公共卫生、临床微生物学和微生物组研究中的宝贵工具。随着测序成本的持续下降和宏基因组数据的不断积累,TRACS有望在理解微生物传播动态和制定有效控制策略方面发挥越来越重要的作用。