一、深度学习 (DL) 介绍
1.1 概念
深度学习(Deep Learning, DL)是机器学习算法的一个重要分支,它以人工神经网络 为基础架构,通过多层非线性变换,实现对数据特征的自动提取和学习。
与传统机器学习需要人工设计特征不同,深度学习能够从原始数据中自动学习层次化的特征表示:
-
底层网络学习简单特征(如边缘、纹理)
-
中层网络学习组合特征(如形状、部件)
-
高层网络学习抽象特征(如语义、概念)
1.2 机器学习和深度学习的核心区别对比
| 对比维度 | 传统机器学习 | 深度学习 |
|---|---|---|
| 特征工程 | 需要人工设计和提取特征 | 自动从数据中学习特征 |
| 数据依赖 | 在小数据集上表现良好 | 需要大量数据才能发挥优势 |
| 计算资源 | CPU 即可运行,对硬件要求低 | 需要 GPU 加速,计算密集型 |
| 模型复杂度 | 模型相对简单,可解释性强 | 模型复杂,可解释性弱(黑盒) |
| 训练时间 | 训练速度快,几小时到几天 | 训练时间长,几天到几周 |
| 适用场景 | 结构化数据、简单任务 | 图像、语音、文本等复杂任务 |
| 调参难度 | 参数较少,调参相对简单 | 超参数众多,调参复杂 |
1.3 深度学习的优缺点分析
| 维度 | 优点 | 缺点 |
|---|---|---|
| 特征学习 | ✅ 自动提取特征,无需人工工程 | ❌ 特征学习过程不可解释 |
| 性能表现 | ✅ 在复杂任务上达到甚至超越人类 | ❌ 需要大量标注数据 |
| 通用性 | ✅ 同一架构可适配多种任务 | ❌ 模型迁移需要重新训练 |
| 端到端学习 | ✅ 从原始输入到最终输出一体化 | ❌ 错误难以定位和调试 |
| 计算要求 | ✅ 可并行计算,充分利用 GPU | ❌ 硬件成本高,能耗大 |
| 迭代优化 | ✅ 数据越多,性能持续提升 | ❌ 小数据集上容易过拟合 |
1.4 深度学习发展史
重点节点时间线:
| 年份 | 里程碑事件 |
|---|---|
| 1943 | McCulloch-Pitts 神经元模型提出,人工神经元概念诞生 |
| 1958 | Rosenblatt 提出感知机(Perceptron),第一个神经网络模型 |
| 1969 | Minsky 证明感知机无法解决 XOR 问题,第一次 AI 寒冬开始 |
| 1986 | Rumelhart 提出反向传播算法,神经网络复兴 |
| 1998 | LeCun 提出 LeNet-5,卷积神经网络用于手写数字识别 |
| 2006 | Hinton 提出深度信念网络,深度学习概念正式提出 |
| 2012 | AlexNet 在 ImageNet 竞赛中夺冠,深度学习爆发式发展 |
| 2014 | Goodfellow 提出生成对抗网络(GAN) |
| 2017 | Google 提出 Transformer 架构,注意力机制成为主流 |
| 2020+ | GPT、BERT 等大语言模型涌现,多模态大模型时代 |
详细发展历程:
萌芽期(1940s-1960s):受神经科学启发,科学家开始探索用数学模型模拟人脑神经元。感知机的出现让人们对人工智能充满期待。
第一次寒冬(1970s-1980s 初):感知机的局限性被揭示,加上计算能力不足,神经网络研究陷入低谷。
复兴期(1980s-1990s):反向传播算法的发明解决了多层网络的训练问题。LeNet-5 成功应用于邮政系统的手写数字识别。
第二次寒冬(2000s 初):支持向量机(SVM)等传统机器学习方法表现更优,神经网络再次被冷落。
爆发期(2012 至今):大数据 + GPU 算力 + 算法突破三驾马车驱动,AlexNet、ResNet、Transformer、大语言模型相继出现,深度学习改变世界。
1.5 常见算法 / 模型介绍
ANN 人工神经网络(Artificial Neural Network)
-
最基础的神经网络结构,由全连接层组成
-
每个神经元与上一层所有神经元相连
-
适用于表格数据的分类和回归任务
CNN 卷积神经网络(Convolutional Neural Network)
-
核心是卷积层,通过滑动窗口提取局部特征
-
参数共享,大大减少模型参数量
-
计算机视觉领域的基石,用于图像识别、检测、分割
RNN 循环神经网络(Recurrent Neural Network)
-
具有记忆能力,能够处理序列数据
-
隐藏层状态在时间步之间传递
-
变体:LSTM、GRU,解决长序列梯度消失问题
-
适用于时间序列、自然语言处理任务
Transformer(2017 年出现)
-
完全基于自注意力机制,无需循环或卷积
-
并行计算能力强,训练效率高
-
NLP 领域的绝对主流:BERT、GPT 系列
-
扩展到 CV 领域:ViT(视觉 Transformer)
生成对抗网络(GAN, Generative Adversarial Network)
-
由生成器和判别器组成,二人零和博弈
-
生成器:学习生成逼真的假样本
-
判别器:区分真样本和假样本
-
应用:图像生成、风格迁移、数据增强
其他常见模型
-
AutoEncoder(自编码器):无监督学习,用于降维和特征提取
-
Graph Neural Network(图神经网络):处理图结构数据
-
Diffusion Model(扩散模型):当前最火的生成模型,Stable Diffusion 基础
1.6 应用场景
计算机视觉 CV
-
图像识别:ImageNet 分类、人脸识别、商品识别
-
图像分割:医学影像分割、自动驾驶语义分割
-
目标检测:行人检测、车辆检测、缺陷检测
-
图像生成:AI 绘画、人脸生成、超分辨率
自然语言处理 NLP
-
聊天机器人:智能客服、对话系统、AI 助手
-
语音翻译:机器翻译、语音识别、语音合成
-
生成式 AI 大模型:文章写作、代码生成、知识问答
-
文本分析:情感分析、命名实体识别、文本摘要
推荐系统
-
电商推荐:商品推荐、个性化首页、关联推荐
-
视频推荐:抖音、B 站、YouTube 内容推荐
-
电影 / 音乐 / 文章推荐:Netflix、Spotify、今日头条
多模态大模型
-
同时处理文本、图像、音频、视频等多种模态
-
GPT-4V、Gemini、Claude 3 等代表模型
-
图文问答、视觉推理、跨模态检索
二、深度学习核心名词:张量 (Tensor)
2.1 张量结构图解
张量是深度学习中最基础的数据结构,可以理解为多维数组 。所有神经网络的输入、输出、参数都是以张量形式存储和计算的。
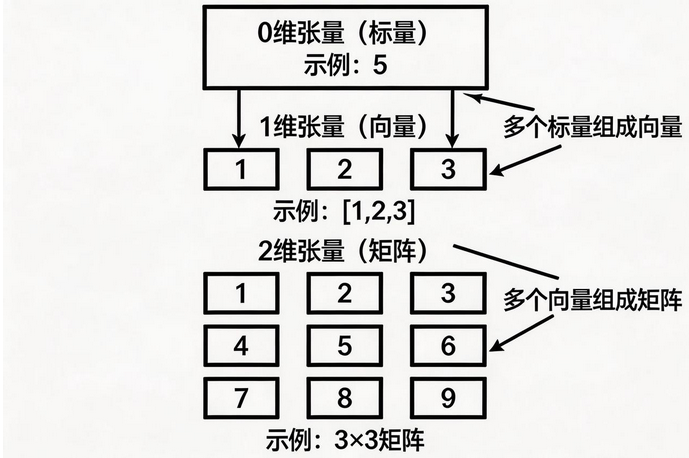
张量的维度概念:
-
0 维张量(标量) :单个数值,如
5、3.14 -
1 维张量(向量) :一维数组,如
[1, 2, 3] -
2 维张量(矩阵):二维数组,如 3×3 矩阵
-
3 维张量 :立方体结构,常用于 RGB 图像、时间序列
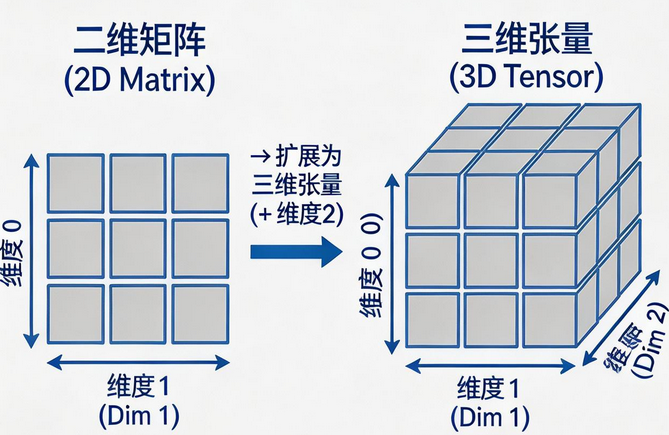
实际应用中的张量形状:
-
灰度图像:
[高度, 宽度]→ 2 维张量 -
RGB 彩色图像:
[通道, 高度, 宽度]→ 3 维张量 -
批量图像:
[batch_size, 通道, 高度, 宽度]→ 4 维张量 -
视频数据:
[batch_size, 帧数, 通道, 高度, 宽度]→ 5 维张量
三、深度学习核心框架:PyTorch
3.1 安装
PyTorch 安装非常简单,使用 pip 即可:
bash
# 安装CPU版本
pip install torch
# 安装GPU版本(根据CUDA版本选择)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118验证安装:
python
import torch
print(torch.__version__) # 查看版本
print(torch.cuda.is_available()) # 检查GPU是否可用3.2 概述
PyTorch 是 Facebook(Meta)开发的 Python 深度学习框架,它:
-
提供对张量的高效处理能力
-
内置自动微分系统,支持自动求导
-
提供各种神经网络模块(nn.Module)
-
支持动态计算图,调试友好
-
学术界和工业界的主流选择
PyTorch 发展史:
| 年份 | 里程碑 |
|---|---|
| 2016 | PyTorch 0.1 发布,基于 Torch 框架 |
| 2018 | PyTorch 1.0 稳定版发布,Caffe2 合并 |
| 2020 | PyTorch 1.7 发布,支持更多硬件 |
| 2022 | PyTorch 2.0 发布,torch.compile 加速 |
| 至今 | 成为最受欢迎的深度学习框架 |
3.3 NumPy 数组和 Tensor 张量核心区别和联系
为什么 NumPy 还有 Tensor?
分工明确,各司其职:
-
NumPy:处理原始数据加载、预处理、结果后处理、可视化
-
PyTorch Tensor:专门负责模型训练和推理,支持 GPU 加速和自动微分
核心区别对比
| 特性 | NumPy 数组 | PyTorch Tensor |
|---|---|---|
| 硬件支持 | 仅 CPU | CPU + GPU + TPU |
| 自动微分 | ❌ 不支持 | ✅ 原生支持 |
| 计算加速 | 有限的 CPU 优化 | GPU 并行计算加速 |
| 计算图 | 无 | 支持动态 / 静态计算图 |
| 分布式训练 | ❌ 不支持 | ✅ 原生支持 |
| 生态系统 | 科学计算通用 | 深度学习专用 |
功能对比
| 功能 | NumPy | PyTorch Tensor |
|---|---|---|
| 基本数学运算 | ✅ | ✅ |
| 线性代数运算 | ✅ | ✅ |
| 随机数生成 | ✅ | ✅ |
| GPU 加速计算 | ❌ | ✅ |
| 自动梯度计算 | ❌ | ✅ |
| 神经网络层 | ❌ | ✅ |
| 模型保存加载 | ❌ | ✅ |
| 分布式训练 | ❌ | ✅ |
性能对比
| 操作 | NumPy (CPU) | PyTorch (CPU) | PyTorch (GPU) |
|---|---|---|---|
| 矩阵乘法 (1000×1000) | ~100ms | ~80ms | ~1ms |
| 大矩阵乘法 (10000×10000) | ~100s | ~80s | ~0.5s |
| 卷积运算 | 慢 | 较快 | 极快 |
| 结论 | 适合小数据 | 略快于 NumPy | 数量级提升 |
创建 API 类似性对比
| 操作 | NumPy | PyTorch Tensor |
|---|---|---|
| 从数据创建 | np.array([1,2,3]) |
torch.tensor([1,2,3]) |
| 全 0 数组 | np.zeros(3,3) |
torch.zeros(3,3) |
| 全 1 数组 | np.ones(3,3) |
torch.ones(3,3) |
| 单位矩阵 | np.eye(3) |
torch.eye(3) |
| 线性空间 | np.linspace(0,1,10) |
torch.linspace(0,1,10) |
| 随机均匀 | np.rand(3,3) |
torch.rand(3,3) |
| 随机正态 | np.randn(3,3) |
torch.randn(3,3) |
计算 API 类似性对比
| 操作 | NumPy | PyTorch Tensor |
|---|---|---|
| 求和 | np.sum(x, axis=0) |
torch.sum(x, dim=0) |
| 均值 | np.mean(x, axis=0) |
torch.mean(x, dim=0) |
| 最大值 | np.max(x, axis=0) |
torch.max(x, dim=0) |
| 矩阵乘法 | np.dot(a, b) |
torch.matmul(a, b) |
| 转置 | x.T |
x.t() 或 x.transpose(0,1) |
| 重塑形状 | x.reshape(3,4) |
x.reshape(3,4) |
| 拼接 | np.concatenate([a,b]) |
torch.cat([a,b]) |
3.4 PyTorch API 汇总
创建张量
基本方式:
python
# 方式1:推荐使用,可指定数据和类型
t1 = torch.tensor(data=[[1,2], [3,4]], dtype=torch.float32)
# 方式2:可指定数据或形状(不推荐)
t2 = torch.Tensor([[1,2], [3,4]]) # 默认float32
t3 = torch.Tensor(2, 3) # 创建2×3未初始化张量
# 方式3:直接指定类型创建
t4 = torch.IntTensor([1, 2, 3])
t5 = torch.FloatTensor([1.0, 2.0, 3.0])线性和随机张量:
python
# 线性张量
t6 = torch.arange(start=0, end=10, step=2) # [0, 2, 4, 6, 8]
t7 = torch.linspace(start=0, end=1, steps=5) # [0, 0.25, 0.5, 0.75, 1]
# 随机张量(设置随机种子保证可复现)
torch.manual_seed(42) # 设置随机种子
print(torch.initial_seed()) # 查看当前种子
t8 = torch.rand(2, 3) # 0-1均匀分布
t9 = torch.randn(2, 3) # 标准正态分布
t10 = torch.randint(low=0, high=10, size=(2, 3)) # 随机整数0/1 / 指定值张量:
python
t11 = torch.zeros(2, 3) # 全0
t12 = torch.ones(2, 3) # 全1
t13 = torch.full(size=(2, 3), fill_value=5) # 全5
# 根据已有张量形状创建
t14 = torch.zeros_like(t1)
t15 = torch.ones_like(t1)
t16 = torch.full_like(t1, fill_value=5)张量中元素类型以及转换操作
张量支持的数据类型:
-
整数类型:uint8, int8, int16, int32, int64
-
浮点类型:float16, float32, float64
-
布尔类型:bool
-
复数类型:complex32, complex64, complex128
三种类型转换方式:
python
t = torch.tensor([1, 2, 3])
# 方式1:类型函数(推荐)
t_float = t.float() # 转float32
t_long = t.long() # 转int64
t_double = t.double() # 转float64
# 方式2:type()方法
t_float2 = t.type(torch.float32)
# 方式3:to()方法
t_float3 = t.to(torch.float32)Tensor 和 NumPy 以及标量互转
python
import numpy as np
# Tensor → NumPy
t = torch.tensor([1, 2, 3])
n1 = t.numpy() # 共享内存
n2 = t.numpy().copy() # 不共享内存
# NumPy → Tensor
n = np.array([1, 2, 3])
t1 = torch.from_numpy(n) # 共享内存
t2 = torch.tensor(n) # 不共享内存
# 单个元素张量 ↔ 标量
scalar = 5
t_scalar = torch.tensor(scalar) # 标量转张量
value = t_scalar.item() # 张量转标量(仅单个元素可用)张量基础运算
python
a = torch.tensor([1, 2, 3])
b = torch.tensor([4, 5, 6])
# 基础运算
c1 = a + b # [5, 7, 9]
c2 = a - b # [-3, -3, -3]
c3 = a * b # [4, 10, 18] 逐元素相乘
c4 = a / b # [0.25, 0.4, 0.5]
# 函数形式
c5 = torch.add(a, b)
c6 = torch.sub(a, b)
c7 = torch.mul(a, b)
c8 = torch.div(a, b)
# 原地操作(带下划线,修改原数据)
a.add_(b) # a现在等于a+b
# 矩阵乘法
m1 = torch.randn(2, 3)
m2 = torch.randn(3, 4)
result = m1 @ m2 # 形状 [2, 4]
result2 = torch.matmul(m1, m2) # 同上张量运算函数
python
t = torch.tensor([[1, 2, 3], [4, 5, 6]])
# 不指定dim,对所有元素计算
print(t.sum()) # 21
print(t.mean()) # 3.5
print(t.max()) # 6
print(t.min()) # 1
# 指定dim,对应维度计算
print(t.sum(dim=0)) # [5, 7, 9] 按列求和
print(t.sum(dim=1)) # [6, 15] 按行求和
# 其他数学函数
t_sqrt = torch.sqrt(t) # 平方根
t_log = torch.log(t) # 自然对数
t_pow = torch.pow(t, 2) # 幂次方
t_exp = torch.exp(t) # 指数函数张量索引操作
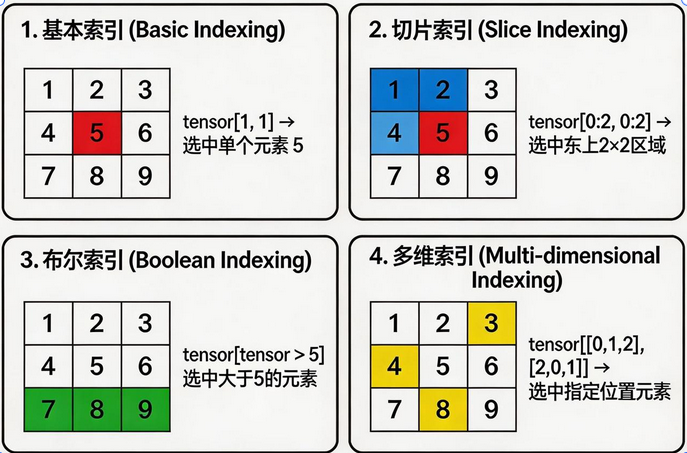
python
t = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 1. 获取单独行列
row1 = t[1, :] # 第2行: [4, 5, 6]
col1 = t[:, 1] # 第2列: [2, 5, 8]
single = t[1, 1] # 单个元素: 5
# 2. 列表获取多行多列
rows = t[[0, 2], :] # 第1、3行
cols = t[:, [0, 2]] # 第1、3列
points = t[[0, 2], [0, 2]] # 坐标点(0,0)和(2,2): [1, 9]
# 3. 切片获取连续区域
sub = t[0:2, 0:2] # 左上2×2区域: [[1,2], [4,5]]
# 4. 布尔索引
mask = t > 5
selected = t[mask] # [6, 7, 8, 9]
# 5. 多维索引(3D张量示例)
t3d = torch.randn(2, 3, 4) # [dim0, dim1, dim2]
elem = t3d[0, 1, 2] # 第0个batch,第1行,第2列张量形状和维度操作
python
t = torch.randn(2, 3, 4)
# shape和reshape
print(t.shape) # torch.Size([2, 3, 4])
print(t.size()) # 同上
t_reshaped = t.reshape(6, 4) # 形状变为[6, 4]
t_auto = t.reshape(2, -1) # -1自动计算: [2, 12]
# contiguous和view
print(t.is_contiguous()) # True
t_contig = t.contiguous() # 确保连续
t_view = t.view(6, 4) # 类似reshape,但要求连续
# squeeze和unsqueeze(降维和升维)
t_unsq = t.unsqueeze(0) # 在dim0增加维度: [1, 2, 3, 4]
t_sq = t_unsq.squeeze(0) # 删除dim0的维度: [2, 3, 4]
# transpose和permute
t_trans = t.transpose(0, 1) # 交换dim0和dim1: [3, 2, 4]
t_perm = t.permute(2, 0, 1) # 重排所有维度: [4, 2, 3]张量拼接操作
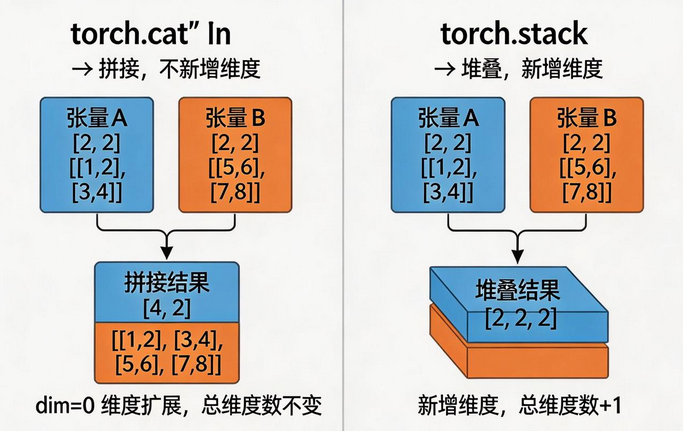
python
t1 = torch.tensor([[1, 2], [3, 4]])
t2 = torch.tensor([[5, 6], [7, 8]])
# torch.cat:拼接,不新增维度
cat0 = torch.cat([t1, t2], dim=0) # 按行拼接: [4, 2]
cat1 = torch.cat([t1, t2], dim=1) # 按列拼接: [2, 4]
# torch.stack:堆叠,新增维度
stack0 = torch.stack([t1, t2], dim=0) # [2, 2, 2]
stack1 = torch.stack([t1, t2], dim=1) # [2, 2, 2]四、PyTorch 自动微分 (自动求导 / 梯度)
4.1 自动微分概念
** 自动微分(Automatic Differentiation,AD)** 是一种利用计算机程序自动计算函数导数的技术。它是机器学习和优化算法中的核心工具,特别是神经网络的梯度下降算法。
自动微分的优势:
-
比手动求导更准确,避免人为错误
-
比数值微分更高效,精度更高
-
比符号微分更灵活,支持复杂控制流
4.2 为什么要计算梯度值
梯度下降法是深度学习的核心优化算法:
w n e w = w o l d − l r × ∇ w L o s s w_{new} = w_{old} - lr \times \nabla w Loss wnew=wold−lr×∇wLoss
其中:
-
w w w:模型权重参数
-
l r lr lr:学习率(超参数,需要提前指定)
-
∇ w L o s s \nabla w Loss ∇wLoss:损失函数对权重的梯度
梯度的作用: 告诉我们参数应该往哪个方向更新才能减小损失值。
注意事项:
-
w 和 b 必须是可自动微分的张量(float 类型)
-
设置
requires_grad=True开启梯度追踪 -
可微分张量不能直接转 numpy,需要
.detach()剥离
4.3 loss.backward () 详解
python
# 1. 创建可微分张量
w = torch.tensor([1.0], requires_grad=True)
b = torch.tensor([0.0], requires_grad=True)
# 2. 前向传播计算loss
x = torch.tensor([2.0])
y_true = torch.tensor([5.0])
y_pred = w * x + b
loss = (y_pred - y_true) ** 2 # MSE损失
# 3. 反向传播计算梯度
loss.backward() # loss必须是标量!
# 4. 查看梯度
print(w.grad) # d(loss)/d(w)
print(b.grad) # d(loss)/d(b)重要注意:梯度累加问题
python
# 多次backward会累加梯度!
for epoch in range(10):
# ... 前向计算loss ...
optimizer.zero_grad() # 必须先清零梯度!
loss.backward()
optimizer.step()4.4 案例
案例 1:自动微分_单轮更新权重
python
import torch
# 1. 初始化参数
w = torch.tensor([1.0], requires_grad=True)
b = torch.tensor([0.0], requires_grad=True)
lr = 0.01
# 2. 准备数据
x = torch.tensor([[1.0], [2.0], [3.0]])
y = torch.tensor([[2.0], [4.0], [6.0]]) # 真实关系: y = 2x
# 3. 前向传播
y_pred = w * x + b
loss = torch.mean((y_pred - y) ** 2)
print(f"初始损失: {loss.item():.4f}")
# 4. 反向传播计算梯度
loss.backward()
print(f"w的梯度: {w.grad.item():.4f}")
print(f"b的梯度: {b.grad.item():.4f}")
# 5. 梯度下降更新权重
with torch.no_grad(): # 更新时不追踪梯度
w -= lr * w.grad
b -= lr * b.grad
# 6. 查看更新后的参数
print(f"更新后w: {w.item():.4f}")
print(f"更新后b: {b.item():.4f}")案例 2:自动微分_多轮更新权重
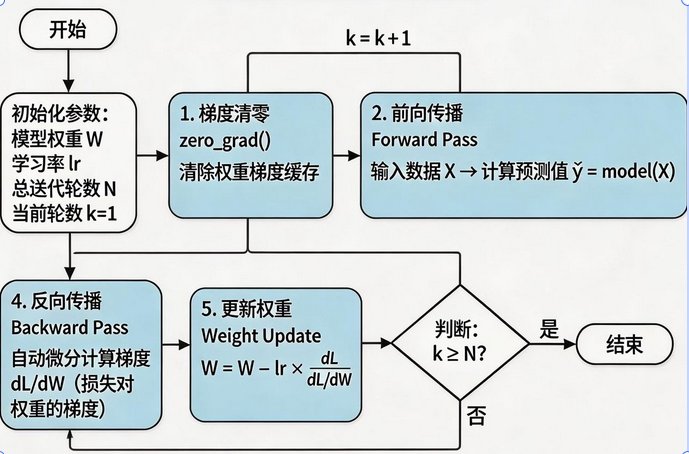
python
import torch
w = torch.tensor([1.0], requires_grad=True)
b = torch.tensor([0.0], requires_grad=True)
lr = 0.01
epochs = 100
x = torch.tensor([[1.0], [2.0], [3.0]])
y = torch.tensor([[2.0], [4.0], [6.0]])
for epoch in range(epochs):
# 前向传播
y_pred = w * x + b
loss = torch.mean((y_pred - y) ** 2)
# 梯度清零!非常重要
if w.grad is not None:
w.grad.zero_()
b.grad.zero_()
# 反向传播
loss.backward()
# 更新参数
with torch.no_grad():
w -= lr * w.grad
b -= lr * b.grad
if (epoch + 1) % 20 == 0:
print(f"Epoch {epoch+1}: loss={loss.item():.4f}, w={w.item():.4f}, b={b.item():.4f}")案例 3:自动微分_综合应用
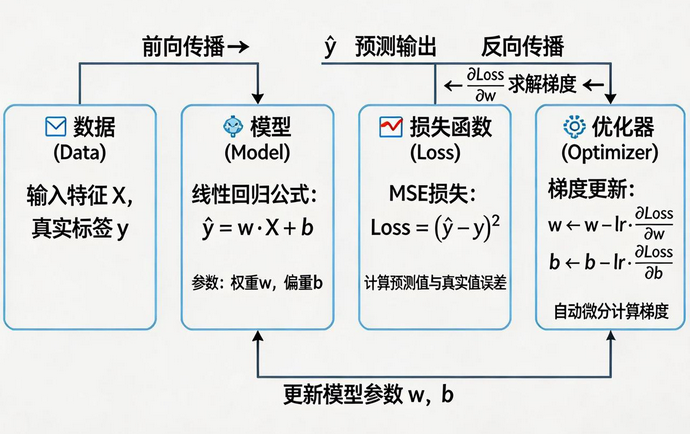
python
import torch
import torch.nn as nn
import torch.optim as optim
# 1. 准备数据
X = torch.randn(100, 1) * 10
y = 2 * X + 3 + torch.randn(100, 1) * 0.5 # y = 2x + 3 + 噪声
# 2. 定义模型
model = nn.Linear(1, 1) # 线性层: y = w*x + b
# 3. 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 4. 训练循环
epochs = 500
for epoch in range(epochs):
# 前向传播
y_pred = model(X)
loss = criterion(y_pred, y)
# 反向传播 + 优化
optimizer.zero_grad() # 梯度清零
loss.backward() # 计算梯度
optimizer.step() # 更新参数
if (epoch + 1) % 100 == 0:
w = model.weight.item()
b = model.bias.item()
print(f"Epoch {epoch+1}: loss={loss.item():.4f}, w={w:.4f}, b={b:.4f}")
print(f"\n最终学到的关系: y = {model.weight.item():.4f}x + {model.bias.item():.4f}")五、人工神经网络 ANN
5.1 什么是神经网络模型
\\ 人工神经网络(Artificial Neural Network, ANN)\\ 是仿生生物学神经元构造出的深度学习计算模型。它由大量相互连接的神经元组成,通过调整连接权重来学习数据中的模式。
核心概念:
-
神经元(Neuron):基本计算单元
-
层(Layer):神经元的集合,分为输入层、隐藏层、输出层
-
权重(Weight):连接的强度,模型学习的目标
-
偏置(Bias):神经元的激活阈值
-
激活函数(Activation):引入非线性变换
5.2 神经元
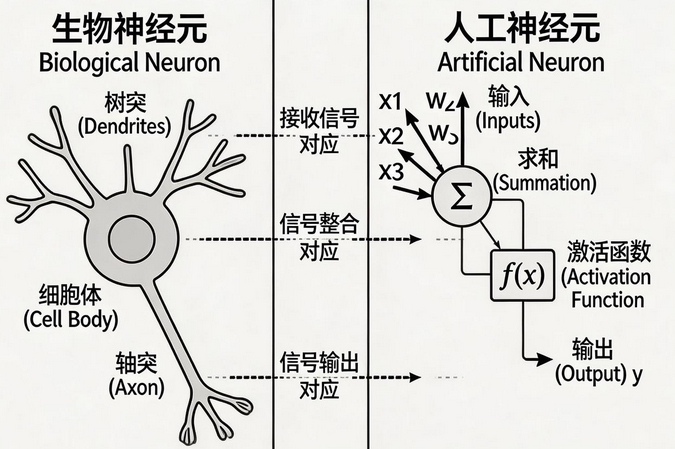
单个神经元的计算:
o u t p u t = f ( ∑ i = 1 n w i x i + b ) output = f(\sum_{i=1}^{n} w_i x_i + b) output=f(∑i=1nwixi+b)
其中:
-
x i x_i xi:输入特征
-
w i w_i wi:对应权重
-
b b b:偏置
-
f f f:激活函数
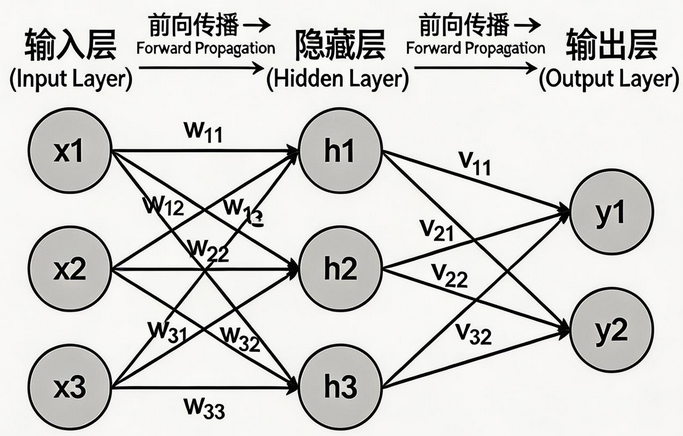
前向传播和反向传播:
-
前向传播:数据从输入层流向输出层,计算预测值
-
反向传播:误差从输出层流向输入层,计算梯度更新权重
5.3 4 大激活函数
概念和作用: 激活函数的核心作用是引入非线性因素。如果没有激活函数,无论网络多深,都只能表示线性变换。
激活函数对比总结
| 激活函数 | 公式 | 值域 | 梯度范围 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|---|
| Sigmoid | σ ( x ) = 1 / ( 1 + e − x ) σ(x) = 1/(1+e^{-x}) σ(x)=1/(1+e−x) | (0, 1) | (0, 0.25] | 输出概率,适合二分类 | 梯度消失,输出非零均值 | 二分类输出层 |
| Tanh | t a n h ( x ) = 2 σ ( 2 x ) − 1 tanh(x) = 2σ(2x)-1 tanh(x)=2σ(2x)−1 | (-1, 1) | (0, 1] | 零均值,收敛更快 | 仍有梯度消失问题 | 浅层网络隐藏层 |
| ReLU | m a x ( 0 , x ) max(0, x) max(0,x) | [0, +∞) | 0 或 1 | 计算快,缓解梯度消失 | 神经元死亡问题 | 隐藏层首选 |
| Softmax | e x i / Σ e x j e^{x_i}/Σe^{x_j} exi/Σexj | (0, 1) | - | 输出概率和为 1 | - | 多分类输出层 |
详解:
Sigmoid:
-
激活值范围:0, 1,没有负信号
-
梯度范围:0, 0.25,深层网络容易梯度消失(0.25^5 ≈ 0.001)
-
输入建议分布在 -6, 6 之间
-
适用于二分类输出层
Tanh:
-
激活值范围:-1, 1,正负信号都有
-
梯度范围:0, 1,梯度消失速度比 sigmoid 慢
-
输入建议分布在 -3, 3 之间
-
适用于浅层神经网络隐藏层
ReLU(优先选择):
-
激活值:0 或正 x,没有负信号
-
梯度:0 或 1,梯度永远为 1,收敛效果好
-
问题:神经元死亡(一旦输入为负,永远不再激活)
-
变体:Leaky ReLU、PReLU 解决死亡问题
Softmax:
-
将线性层输出转换成概率,所有概率和为 1
-
使用:
softmax(dim=1)按行计算概率 -
适用于多分类输出层
5.4 7 大参数 (w 和 b) 初始化
概念和作用: 参数初始化就是对权重 w、偏置 b 的初始值设定。好的初始化可以:
-
防止梯度消失或梯度爆炸
-
打破对称性(每个神经元学习不同特征)
-
加速模型收敛
7 大初始化 API:
python
import torch.nn as nn
import torch.nn.init as init
# 以一个线性层为例
linear = nn.Linear(10, 20)
w = linear.weight
b = linear.bias
# 1. 随机均匀初始化
init.uniform_(w, a=-0.1, b=0.1)
# 2. 随机正态分布初始化
init.normal_(w, mean=0, std=0.01)
# 3. 全0初始化
init.zeros_(b)
# 4. 全1初始化
init.ones_(w)
# 5. 全指定值初始化
init.constant_(b, 0.1)
# 6. He/Kaiming初始化(推荐用于ReLU)
init.kaiming_uniform_(w, mode='fan_in', nonlinearity='relu')
init.kaiming_normal_(w, mode='fan_in', nonlinearity='relu')
# 7. Xavier初始化(推荐用于Sigmoid/Tanh)
init.xavier_uniform_(w)
init.xavier_normal_(w)激活函数对应参数初始化选择:
| 激活函数 | 推荐初始化方法 |
|---|---|
| ReLU / Leaky ReLU | He/Kaiming 初始化 |
| Sigmoid / Tanh | Xavier 初始化 |
| 无激活(线性) | Xavier 或 小随机正态 |
5.5 5 大损失函数
什么是损失函数: 衡量模型预测质量的函数,也叫代价函数、误差函数。根据损失值,结合反向传播和梯度下降实现参数更新。
分类任务的损失函数:
1. 多分类交叉熵损失函数
python
loss_fn = nn.CrossEntropyLoss(reduction='mean')
# 内部自动实现:softmax激活 + 交叉熵计算
# 输入:模型原始输出(不需要手动加softmax)
# 目标:类别标签(0,1,2...)2. 二分类交叉熵损失函数
python
loss_fn = nn.BCELoss(reduction='mean')
# 输入:sigmoid后的概率值
# 目标:0或1的浮点型回归任务的损失函数:
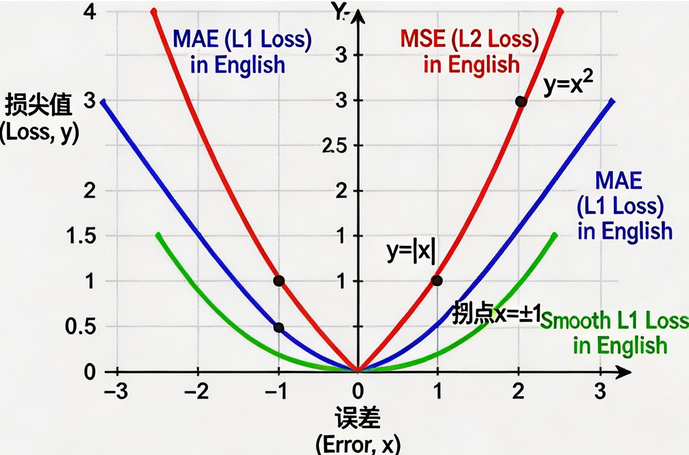
1. MAE 平均绝对误差损失(L1 Loss)
python
loss_fn = nn.L1Loss()
# 公式:loss = |y_pred - y_true|
# 特点:导数为-1/1,对异常值鲁棒
# 对异常样本效果好,不会放大误差2. MSE 均方误差损失(L2 Loss)
python
loss_fn = nn.MSELoss()
# 公式:loss = (y_pred - y_true)²
# 特点:任意位置可导,loss越大梯度越大
# 对异常样本敏感,容易放大误差3. Smooth L1 损失函数
python
loss_fn = nn.SmoothL1Loss()
# 结合MAE和MSE的优点
# |x| < 1时用MSE,|x| ≥ 1时用MAE
# 对异常值鲁棒,不会梯度爆炸
# 目标检测中常用5.6 网络模型优化方法
梯度下降公式
w t + 1 = w t − l r × ∇ w L o s s w_{t+1} = w_t - lr \times \nabla w Loss wt+1=wt−lr×∇wLoss
指数加权平均思想
指数加权平均是很多优化算法的核心:
S t = β × S t − 1 + ( 1 − β ) × G t S_t = \beta \times S_{t-1} + (1 - \beta) \times G_t St=β×St−1+(1−β)×Gt
其中:
-
S t S_t St:当前时刻的加权平均
-
G t G_t Gt:当前时刻的梯度
-
β \beta β:平滑系数(通常 0.9)
-
本质:对历史梯度做平滑,减少震荡
梯度下降优化的两种方式
| 优化角度 | 方法 | 核心思想 | 优点 | 缺点 |
|---|---|---|---|---|
| 梯度角度 | BGD | 全量数据计算梯度 | 梯度准确,收敛稳定 | 速度慢,内存大 |
| SGD | 单样本计算梯度 | 速度快,内存小 | 不稳定,震荡大 | |
| Momentum | 加入历史梯度动量 | 加速收敛,冲出局部最优 | 可能冲过最优点 | |
| MBGD | 小批量数据 | 平衡速度和稳定性 | 需调 batch_size | |
| 学习率角度 | Adagrad | 自适应学习率,历史梯度平方和 | 稀疏数据效果好 | 学习率衰减过快 |
| RMSprop | 指数加权的历史梯度平方 | 避免学习率衰减过快 | 需调超参数 | |
| Adam | Momentum + RMSprop | 自适应,效果好,首选 | 可能不收敛 | |
| 手动衰减 | StepLR/MultiStepLR | 可控性强 | 需手动调参 |
推荐:优先使用 Adam,然后是 SGD+Momentum
5.7 正则化 (解决过拟合问题)
什么是正则化: 解决过拟合问题、提高模型泛化能力的策略。泛化能力指模型在新样本上的表现。
策略 1:范数正则化
L1 正则化:
-
数学形式:损失函数 + λ × ||w||₁ (权重绝对值和)
-
效果:倾向于将部分权重压缩到 0,产生稀疏解
-
作用:自动特征选择,不重要特征权重为 0
L2 正则化(权重衰减):
-
数学形式:损失函数 + λ × ||w||₂² (权重平方和)
-
效果:倾向于所有权重均匀缩小,但不为 0
-
作用:防止权重过大,提高模型稳定性
python
# PyTorch中L2正则化通过优化器实现
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=0.001)策略 2:随机失活 Dropout
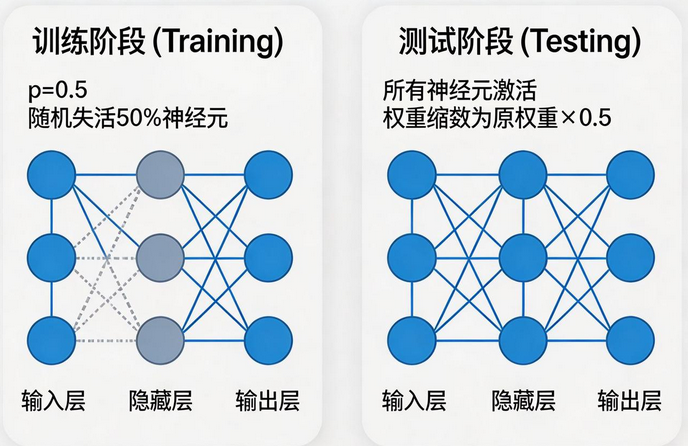
python
class Net(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(10, 20)
self.dropout = nn.Dropout(p=0.5) # 50%概率失活
self.fc2 = nn.Linear(20, 2)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.dropout(x) # 在激活后使用
x = self.fc2(x)
return x
# 重要:训练和测试模式切换
model.train() # 训练模式,Dropout生效
model.eval() # 测试模式,Dropout不生效Dropout 注意事项:
-
在激活层后使用
-
未失活的神经元输出会自动除以 (1-p)
-
测试集上不生效,必须切换模式
策略 3:批量归一化 BN
Batch Normalization 核心思想:
-
规范化每一层的输入分布,均值为 0、方差为 1
-
缓解内部协变量偏移(ICS)问题
作用:
-
正则化效果:不同批次的统计差异引入噪声
-
加快收敛:数据分布均匀,激活函数梯度更大
python
class Net(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(10, 20)
self.bn1 = nn.BatchNorm1d(20) # 在激活前使用
self.fc2 = nn.Linear(20, 2)
def forward(self, x):
x = self.fc1(x)
x = self.bn1(x) # 线性层后,激活前
x = F.relu(x)
x = self.fc2(x)
return x5.8 手机价格分类案例
需求说明
-
任务类型:多分类问题(4 类价格区间)
-
数据规模:2000 个样本,20 个特征
-
数据划分:训练集 1600,测试集 400
-
目标:根据手机参数预测价格区间
完整实现代码:
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# ===================== 1. 数据加载和处理 =====================
def load_data():
# 加载CSV数据
df = pd.read_csv('mobile_price.csv')
# 分离特征和标签
X = df.drop('price_range', axis=1).values
y = df['price_range'].values
# 特征标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# 转换为张量
X_train = torch.FloatTensor(X_train)
y_train = torch.LongTensor(y_train)
X_test = torch.FloatTensor(X_test)
y_test = torch.LongTensor(y_test)
# 创建数据集和数据加载器
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
return train_loader, test_loader
# ===================== 2. 构建神经网络模型 =====================
class PhonePriceNet(nn.Module):
def __init__(self, input_dim=20, hidden_dim=64, output_dim=4):
super().__init__()
# 定义网络层
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.bn1 = nn.BatchNorm1d(hidden_dim)
self.dropout1 = nn.Dropout(0.3)
self.fc2 = nn.Linear(hidden_dim, hidden_dim // 2)
self.bn2 = nn.BatchNorm1d(hidden_dim // 2)
self.dropout2 = nn.Dropout(0.3)
self.fc3 = nn.Linear(hidden_dim // 2, output_dim)
# 参数初始化
self._init_weights()
def _init_weights(self):
"""He初始化,适配ReLU激活函数"""
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight, nonlinearity='relu')
nn.init.constant_(m.bias, 0.01)
def forward(self, x):
"""前向传播"""
# 第一层
x = self.fc1(x)
x = self.bn1(x)
x = F.relu(x)
x = self.dropout1(x)
# 第二层
x = self.fc2(x)
x = self.bn2(x)
x = F.relu(x)
x = self.dropout2(x)
# 输出层(不需要激活,CrossEntropyLoss包含softmax)
x = self.fc3(x)
return x
# ===================== 3. 模型训练 =====================
def train_model(model, train_loader, criterion, optimizer, epochs=100):
model.train()
best_loss = float('inf')
for epoch in range(epochs):
total_loss = 0.0
correct = 0
total = 0
for batch_X, batch_y in train_loader:
# 前向传播
outputs = model(batch_X)
loss = criterion(outputs, batch_y)
# 反向传播 + 优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计
total_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += batch_y.size(0)
correct += (predicted == batch_y).sum().item()
# 打印epoch信息
avg_loss = total_loss / len(train_loader)
accuracy = 100 * correct / total
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch+1}/{epochs}], '
f'Loss: {avg_loss:.4f}, '
f'Accuracy: {accuracy:.2f}%')
# 保存最佳模型
if avg_loss < best_loss:
best_loss = avg_loss
torch.save(model.state_dict(), 'best_model.pth')
print('训练完成!最佳模型已保存。')
# ===================== 4. 模型评估 =====================
def evaluate_model(model, test_loader):
model.eval() # 切换到评估模式
correct = 0
total = 0
with torch.no_grad(): # 不计算梯度
for batch_X, batch_y in test_loader:
outputs = model(batch_X)
_, predicted = torch.max(outputs.data, 1)
total += batch_y.size(0)
correct += (predicted == batch_y).sum().item()
accuracy = 100 * correct / total
print(f'\n测试集准确率: {accuracy:.2f}%')
return accuracy
# ===================== 主程序 =====================
if __name__ == '__main__':
import torch.nn.functional as F
# 1. 加载数据
print('正在加载数据...')
train_loader, test_loader = load_data()
# 2. 创建模型
print('正在创建模型...')
model = PhonePriceNet(input_dim=20, hidden_dim=64, output_dim=4)
# 3. 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4)
# 4. 训练模型
print('开始训练...')
train_model(model, train_loader, criterion, optimizer, epochs=100)
# 5. 加载最佳模型并评估
print('加载最佳模型进行评估...')
model.load_state_dict(torch.load('best_model.pth'))
evaluate_model(model, test_loader)结语
深度学习是一个快速发展的领域,从基础的神经网络到 Transformer 大模型,技术迭代日新月异。本文涵盖了深度学习的核心概念、PyTorch 框架、自动微分、神经网络组件等内容,希望能为你打下坚实的基础。
学习建议:
-
理论与实践结合,多动手写代码
-
从简单任务开始,逐步挑战复杂项目
-
阅读经典论文,理解算法思想
-
关注前沿进展,保持学习热情
数据决定了模型训练的上限,而算法只是不断逼近这个上限。
参考资料:
-
PyTorch 官方文档:https://pytorch.org/docs/
-
TensorFlow Playground:https://playground.tensorflow.org/
-
Deep Learning Book:https://www.deeplearningbook.org/