参考:《动手学深度学习》,https://zh-v2.d2l.ai/index.html
引用自《动手学深度学习》:回归 (regression)是能为一个或多个自变量与因变量之间关系建模的一类方法。在自然科学和社会科学领域,回归经常用来表示输入和输出之间的关系。在机器学习领域中的大多数任务通常都与预测(prediction)有关。当我们想预测一个数值时,就会涉及到回归问题。常见的例子包括:预测价格(房屋、股票等)、预测住院时间(针对住院病人等)、预测需求(零售销量等)。
线性回归 (linear regression)可以追溯到19世纪初,它在回归的各种标准工具中最简单而且最流行。线性回归基于几个简单的假设:首先,假设自变量x\mathbf{x}x和因变量yyy之间的关系是线性的,即yyy可以表示为x\mathbf{x}x中元素的加权和,这里通常允许包含观测值的一些噪声;其次,我们假设任何噪声都比较正常,如噪声遵循正态分布。
一些题外话,如今有了各种深度学习框架,
model.fit()敲一下,模型就训练好了。但不知道你有没有好奇过------这背后到底发生了什么?梯度是怎么算出来的?参数又是怎么一步步更新的?这篇笔记,我们抛开所有"黑盒"工具,从最基础的数学公式出发,从零开始实现线性回归。
本文脉络
- 问题定义:我们要解决什么问题?为什么挑这个?
- 数据准备:造一批带噪声的样本数据
- 数学推导:前向传播、损失计算、反向传播------手把手推导每一步公式
- 代码实现与训练:NumPy 手写实现,跑通训练并可视化
- 换个角度:用 PyTorch 优雅实现同样的功能
预计阅读时间:15 分钟 | 难度:入门 | 前置知识:线性代数基础、Python 基础
一、问题定义:我们要拟合什么?
1.1 目标函数
为了方便说明,我们假设目标函数具有如下表达式:
y=4x+0.8y = 4x + 0.8 y=4x+0.8
你可能觉得,这不就是一次函数吗?初中就学过了。但别忘了:所有复杂的深度学习模型,归根结底都是线性变换和非线性激活的层层叠加。把这个最基础的情况吃透了,后面再复杂的架构也不怕。
1.2 构建模型
在这个简单的例子里,我们已经充分理解了输入和输出之间的变换关系。带着这些先验知识,仅需构建一个一维线性变换模型就能很好地拟合目标函数,如下所示:
y^=wx+b\hat{y} = wx + by^=wx+b
拆开来说:
- www:权重(weight) ,一开始随机给个值,训练的目标是让它慢慢靠近 444
- bbb:偏置(bias) ,同样从随机值出发,目标是逼近 0.80.80.8
- y^\hat{y}y^:模型跑出来的预测值
换个角度想 :从神经网络的视角看,这就是一个不带激活函数的单层全连接层。别嫌它简单,把这个搞明白了,后面加隐藏层、加激活函数,自然就水到渠成了。
二、数据准备:造一批训练样本
2.1 数据怎么来?
现实世界中的数据哪有那么完美,老老实实落在目标函数曲线上的情况几乎不存在。所以我们的做法是:
- 在区间 −2,2-2, 2−2,2 上均匀采样N个点 ,生成输入 XXX,X=x0,x1,......,xN−1⊤X=x_0,x_1,......,x_{N-1}^\topX=x0,x1,......,xN−1⊤
- 套入理想公式,算出理论输出 Yideal=4X+0.8Y_{\text{ideal}} = 4X + 0.8Yideal=4X+0.8
- 撒点高斯噪声 ϵ∼N(0,σ2)\epsilon \sim \mathcal{N}(0, \sigma^2)ϵ∼N(0,σ2),模拟真实场景中的测量误差,得到输出 YYY,Y=y0,y1,......,yN−1⊤Y=y_0,y_1,......,y_{N-1}^\topY=y0,y1,......,yN−1⊤
最终拿到手的数据长这样:
Y=Yideal+ϵ=4X+0.8+ϵ,ϵ∼N(0,0.32)Y = Y_{\text{ideal}} + \epsilon = 4X + 0.8 + \epsilon, \quad \epsilon \sim \mathcal{N}(0, 0.3^2)Y=Yideal+ϵ=4X+0.8+ϵ,ϵ∼N(0,0.32)
python
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec
import matplotlib
import matplotlib.font_manager as fm
# ==================== 中文字体配置 ====================
# 重要:必须在 plt.style.use() 之后设置,否则会被覆盖!
# macOS 可用中文字体(按优先级):
# STHeiti - 系统黑体 | Songti SC - 宋体 | PingFang HK - 苹方
# 方法1:使用 rcParams 设置字体
plt.rcParams['font.sans-serif'] = ['STHeiti', 'Songti SC', 'PingFang HK', 'Kaiti SC', 'Heiti TC']
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
# 方法2:使用 FontProperties 确保字体生效(备用方案)
# 查找系统中可用的中文字体
def get_chinese_font():
"""获取可用的中文字体名称"""
chinese_fonts = ['STHeiti', 'Songti SC', 'PingFang HK', 'Kaiti SC', 'Heiti TC']
available_fonts = [f.name for f in fm.fontManager.ttflist]
for font in chinese_fonts:
if font in available_fonts:
return font
return None
CHINESE_FONT = get_chinese_font()
if CHINESE_FONT:
print(f"找到中文字体: {CHINESE_FONT}")
# 使用找到的字体覆盖默认设置
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.sans-serif'] = [CHINESE_FONT]
else:
print("未找到中文字体,尝试使用默认字体")
print("环境就绪!NumPy版本:", np.__version__)
print("当前字体配置:", plt.rcParams['font.sans-serif'][:3])
# 🎲 设置随机种子保证可复现性
np.random.seed(42)
# ==================== 数据生成参数 ====================
N = 100 # 样本数量
true_w = 4.0 # 真实权重
true_b = 0.8 # 真实偏置
noise_std = 0.3 # 噪声标准差
# 生成输入数据 X: 形状 (N, 1) - 在 [-2, 2] 区间均匀采样
X = np.random.uniform(-2, 2, size=(N, 1)).astype(np.float32)
# 生成目标数据 Y = 4X + 0.8 + 噪声: 形状 (N, 1)
noise = np.random.normal(0, noise_std, size=(N, 1)).astype(np.float32)
Y = true_w * X + true_b + noise
print(f"✅ 数据生成完成!")
print(f" X 形状: {X.shape},范围: [{X.min():.2f}, {X.max():.2f}]")
print(f" Y 形状: {Y.shape},范围: [{Y.min():.2f}, {Y.max():.2f}]")
print(f" 真实参数: w={true_w}, b={true_b}")找到中文字体: STHeiti
环境就绪!NumPy版本: 2.2.6
当前字体配置: ['STHeiti']
✅ 数据生成完成!
X 形状: (100, 1),范围: [-1.98, 1.95]
Y 形状: (100, 1),范围: [-6.96, 8.82]
真实参数: w=4.0, b=0.82.2 先看看数据长什么样
python
# 📈 可视化数据分布
fig, ax = plt.subplots(figsize=(9, 6))
# 绘制散点图(含噪声的观测数据)
ax.scatter(X, Y, alpha=0.6, edgecolors='white', linewidth=0.5, s=50,
label='含噪声的观测数据', color='steelblue')
# 绘制真实函数(不含噪声)
x_line = np.linspace(-2.2, 2.2, 100).reshape(-1, 1)
y_line = true_w * x_line + true_b
ax.plot(x_line, y_line, 'r--', linewidth=2.5, label=f'真实函数: $y = {true_w}x + {true_b}$', alpha=0.8)
ax.set_xlabel('$x$', fontsize=14, fontweight='bold')
ax.set_ylabel('$y$', fontsize=14, fontweight='bold')
ax.set_title('数据集分布:目标函数与观测数据', fontsize=16, fontweight='bold', pad=15)
ax.legend(fontsize=12, loc='upper left')
ax.grid(True, alpha=0.3)
# 添加文本标注
ax.text(0.5, 7.5, f'样本数: {N}\n噪声标准差: {noise_std}',
fontsize=11, bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5))
plt.tight_layout()
plt.show()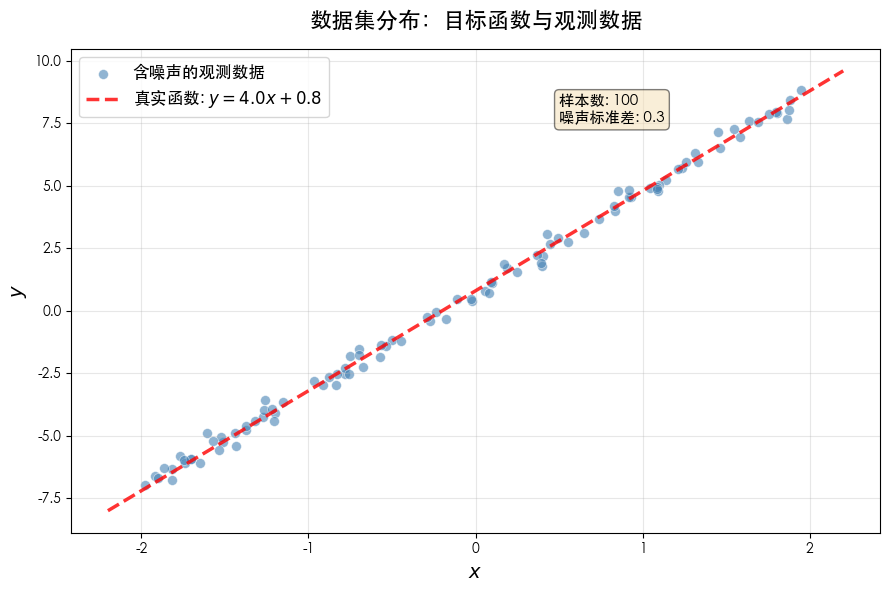
2.3 维度这件事,一开始就要说清楚
做矩阵运算,最怕维度对不上。所以我们从一开始就把每个量的形状标得明明白白:
| 符号 | 含义 | 维度 | 备注 |
|---|---|---|---|
| XXX | 输入特征矩阵 | (N,1)(N, 1)(N,1) | 行数表示样本数,表示NNN 个样本;列数表示特征维度,这里每个样本 1 个特征 |
| YYY | 目标标签 | (N,1)(N, 1)(N,1) | 行数表示样本数,表示NNN 个样本;列数表示输出维度,这里是1表示每个样本只有一个输出值 |
| WWW | 权重矩阵 | (1,1)(1, 1)(1,1) | 输入维度 1 → 输出维度 1 |
| bbb | 偏置 | (1,1)(1, 1)(1,1) | 广播到 (N,1)(N, 1)(N,1),与每个样本相加 |
| ϵ\epsilonϵ | 噪声 | (N,1)(N, 1)(N,1) | 独立同分布的高斯噪声 |
多嘴一句 :为什么要用 (N,1)(N, 1)(N,1) 的二维数组,而不是干脆用 (N,)(N,)(N,) 的一维数组?
因为二维形状能让后续的矩阵乘法维度对齐更加直观。NumPy 的广播机制虽然方便,但偶尔也会让人摸不着头脑,明确维度能少踩很多坑。
三、数学推导:从问题到解法的完整链路
接下来是这篇笔记的重头戏。我们会像剥洋葱一样,一层层把前向传播、损失函数、反向传播的数学过程掰开揉碎,保证每一步都能跟得上。
3.1 前向传播(Forward Pass)
先看单个样本
假设现在只有一个样本 (x,y)(x, y)(x,y),模型要做的事情很简单:
y^=wx+b\hat{y} = wx + by^=wx+b
这里的每个符号代表什么:
- x∈Rx \in \mathbb{R}x∈R:输入,一个实数
- w∈Rw \in \mathbb{R}w∈R:权重,模型要学的参数
- b∈Rb \in \mathbb{R}b∈R:偏置,也是模型要学的参数
- y^∈R\hat{y} \in \mathbb{R}y^∈R:模型给出的预测值
扩展到批量样本(矩阵形式)
实际训练时,我们一般不会一个一个样本地喂,而是一批一起算。假设这批有 NNN 个样本,公式就升级成了:
Y^=XW+b\hat{Y} = XW + bY^=XW+b
维度拆解:
X⏟(N,1)⋅W⏟(1,1)+b⏟(1,1)=Y^⏟(N,1)\underbrace{X}{(N, 1)} \cdot \underbrace{W}{(1, 1)} + \underbrace{b}{(1, 1)} = \underbrace{\hat{Y}}{(N, 1)}(N,1) X⋅(1,1) W+(1,1) b=(N,1) Y^
一个一个来看:
- X∈RN×1X \in \mathbb{R}^{N \times 1}X∈RN×1:输入矩阵,NNN 行 1 列,每个样本占一行
- W∈R1×1W \in \mathbb{R}^{1 \times 1}W∈R1×1:权重矩阵,本质上就是个标量
- b∈R1×1b \in \mathbb{R}^{1 \times 1}b∈R1×1:偏置,靠 NumPy 的广播机制自动加到每个样本上
- Y^∈RN×1\hat{Y} \in \mathbb{R}^{N \times 1}Y^∈RN×1:预测输出,维度跟输入保持一致
一个小技巧 :做矩阵运算的时候,养成随手检查维度的习惯。(N×1)×(1×1)(N \times 1) \times (1 \times 1)(N×1)×(1×1) 的结果是 (N×1)(N \times 1)(N×1),刚好跟目标 YYY 的维度对齐。维度能对得上,公式基本就没问题了。
3.2 损失函数(Loss Function)
模型预测得准不准,得有个衡量标准。这里我们选的是均方误差(Mean Squared Error, MSE):
L=1N∑i=1N(y^i−yi)2L = \frac{1}{N}\sum_{i=1}^{N}(\hat{y}_i - y_i)^2L=N1i=1∑N(y^i−yi)2
写成矩阵的形式更简洁:
L=1N(Y^−Y)⊤(Y^−Y)L = \frac{1}{N}(\hat{Y} - Y)^\top(\hat{Y} - Y)L=N1(Y^−Y)⊤(Y^−Y)
为什么偏偏选 MSE?
- 误差越大,惩罚越狠(平方项的作用)
- 导数好算,数学上很"乖"
- 回归任务的标配,大家都用它
3.3 反向传播(Backward Pass)
好戏来了! 我们需要知道损失函数对参数 WWW 和 bbb 分别有多"敏感",也就是求这两个梯度:
∂L∂W和∂L∂b\frac{\partial L}{\partial W} \quad \text{和} \quad \frac{\partial L}{\partial b}∂W∂L和∂b∂L
第一步:引入中间变量
先把误差向量定义出来:
E=Y^−Y∈RN×1E = \hat{Y} - Y \in \mathbb{R}^{N \times 1}E=Y^−Y∈RN×1
有了它,损失函数可以重新写成:
L=1N∑i=1NEi2=1NE⊤EL = \frac{1}{N}\sum_{i=1}^{N}E_i^2 = \frac{1}{N}E^\top EL=N1i=1∑NEi2=N1E⊤E
第二步:损失对预测值的梯度
对 Y^\hat{Y}Y^ 求导:
∂L∂Y^=∂∂Y^1N(Y\^−Y)⊤(Y\^−Y)\frac{\partial L}{\partial \hat{Y}} = \frac{\partial}{\partial \hat{Y}}\left\\frac{1}{N}(\\hat{Y} - Y)\^\\top(\\hat{Y} - Y)\\right∂Y^∂L=∂Y^∂N1(Y\^−Y)⊤(Y\^−Y)
展开后得到:
∂L∂Y^=2N(Y^−Y)=2NE\frac{\partial L}{\partial \hat{Y}} = \frac{2}{N}(\hat{Y} - Y) = \frac{2}{N}E∂Y^∂L=N2(Y^−Y)=N2E
维度检查 :∂L∂Y^∈RN×1\frac{\partial L}{\partial \hat{Y}} \in \mathbb{R}^{N \times 1}∂Y^∂L∈RN×1,跟 Y^\hat{Y}Y^ 一样,没毛病。
第三步:预测值对参数的梯度
回到前向传播的公式 Y^=XW+b\hat{Y} = XW + bY^=XW+b:
对 WWW 求导:
∂Y^∂W=∂∂W(XW+b)=X\frac{\partial \hat{Y}}{\partial W} = \frac{\partial}{\partial W}(XW + b) = X∂W∂Y^=∂W∂(XW+b)=X
对 bbb 求导:
∂Y^∂b=∂∂b(XW+b)=1N×1\frac{\partial \hat{Y}}{\partial b} = \frac{\partial}{\partial b}(XW + b) = \mathbf{1}_{N \times 1}∂b∂Y^=∂b∂(XW+b)=1N×1
这里的 1N×1\mathbf{1}_{N \times 1}1N×1 是个全 1 向量,因为偏置 bbb 是通过广播加到每个样本上的,每个样本都分到了同样的 bbb。
第四步:链式法则,算出最终梯度
权重梯度:
∂L∂W=∂L∂Y^⋅∂Y^∂W=(2NE)⊤X=2NE⊤X\frac{\partial L}{\partial W} = \frac{\partial L}{\partial \hat{Y}} \cdot \frac{\partial \hat{Y}}{\partial W} = \left(\frac{2}{N}E\right)^\top X = \frac{2}{N}E^\top X∂W∂L=∂Y^∂L⋅∂W∂Y^=(N2E)⊤X=N2E⊤X
维度对一对:
- E⊤∈R1×NE^\top \in \mathbb{R}^{1 \times N}E⊤∈R1×N
- X∈RN×1X \in \mathbb{R}^{N \times 1}X∈RN×1
- E⊤X∈R1×1E^\top X \in \mathbb{R}^{1 \times 1}E⊤X∈R1×1,跟 WWW 的维度一致
写成分量的形式,看得更清楚:
∂L∂W=2N∑i=1N(y^i−yi)⋅xi\frac{\partial L}{\partial W} = \frac{2}{N}\sum_{i=1}^{N}(\hat{y}_i - y_i) \cdot x_i∂W∂L=N2i=1∑N(y^i−yi)⋅xi
偏置梯度:
∂L∂b=∂L∂Y^⋅∂Y^∂b=(2NE)⊤1=2N∑i=1NEi\frac{\partial L}{\partial b} = \frac{\partial L}{\partial \hat{Y}} \cdot \frac{\partial \hat{Y}}{\partial b} = \left(\frac{2}{N}E\right)^\top \mathbf{1} = \frac{2}{N}\sum_{i=1}^{N}E_i∂b∂L=∂Y^∂L⋅∂b∂Y^=(N2E)⊤1=N2i=1∑NEi
维度检查 :∂L∂b∈R1×1\frac{\partial L}{\partial b} \in \mathbb{R}^{1 \times 1}∂b∂L∈R1×1,跟 bbb 一致。
分量形式:
∂L∂b=2N∑i=1N(y^i−yi)\frac{\partial L}{\partial b} = \frac{2}{N}\sum_{i=1}^{N}(\hat{y}_i - y_i)∂b∂L=N2i=1∑N(y^i−yi)
3.4 参数更新(梯度下降)
梯度算出来了,接下来用学习率 η\etaη(learning rate)控制步长,沿着梯度的反方向更新参数:
Wnew=Wold−η⋅∂L∂WW_{\text{new}} = W_{\text{old}} - \eta \cdot \frac{\partial L}{\partial W}Wnew=Wold−η⋅∂W∂L
bnew=bold−η⋅∂L∂bb_{\text{new}} = b_{\text{old}} - \eta \cdot \frac{\partial L}{\partial b}bnew=bold−η⋅∂b∂L
3.5 训练流程一览
把上面的步骤串起来,一个 Epoch 的训练流程长这样:
+---------------------------------------------------------+
| 训练一个 Epoch |
+---------------------------------------------------------+
| |
| 1. 前向传播: Y_hat = XW + b |
| 维度:(N,1) = (N,1)×(1,1) + (1,1) |
| |
| 2. 计算误差: E = Y_hat - Y |
| 维度:(N,1) = (N,1) - (N,1) |
| |
| 3. 计算损失: L = (1/N)×E^T×E |
| 维度:标量 = (1/N)×(1,N)×(N,1) |
| |
| 4. 反向传播: dL/dW = (2/N)×E^T×X |
| dL/db = (2/N)×Sum(E) |
| |
| 5. 参数更新: W ← W - η×(dL/dW) |
| b ← b - η×(dL/db) |
| |
+---------------------------------------------------------+四、代码实现:把数学公式翻译成 NumPy
4.1 模型定义
推导完了,接下来动手。我们先把前面一步步推出来的公式,原封不动地用 NumPy 翻译成一个完整的类。代码里我会逐行标注维度,让数据的来龙去脉一目了然。
python
class LinearMLP:
"""
单层线性 MLP(多层感知机)- 纯 NumPy 实现
========================================
模型结构:
---------
前向传播:Ŷ = XW + b
维度说明:
---------
X : (N, 1) - 输入特征矩阵,N 个样本,每个样本 1 个特征
W : (1, 1) - 权重矩阵
b : (1, 1) - 偏置项
Ŷ (Y_pred) : (N, 1) - 预测输出
Y : (N, 1) - 真实标签
E : (N, 1) - 误差向量 E = Ŷ - Y
梯度维度:
---------
∂L/∂W : (1, 1) - 权重梯度 = (2/N) × Eᵀ × X
∂L/∂b : (1, 1) - 偏置梯度 = (2/N) × ΣE
"""
def __init__(self, seed=42):
"""
初始化参数
初始化策略:
- 权重 W:给个小随机数,避免一开始梯度过大
- 偏置 b:从 0 开始就行
"""
np.random.seed(seed)
# 权重初始化:(1, 1) 矩阵,从标准正态分布采样后乘以 0.1
# 维度:(1, 1)
self.W = np.random.randn(1, 1).astype(np.float32) * 0.1
# 偏置初始化:(1, 1) 零矩阵
# 维度:(1, 1)
self.b = np.zeros((1, 1), dtype=np.float32)
# 保存训练历史,方便后面画图
self.loss_history = []
self.W_history = []
self.b_history = []
self.grad_W_history = []
self.grad_b_history = []
print("参数初始化完成:")
print(f" W = {self.W[0,0]:.4f} (目标值:4.0)")
print(f" b = {self.b[0,0]:.4f} (目标值:0.8)")
print(f" W 维度:{self.W.shape}")
print(f" b 维度:{self.b.shape}")
def forward(self, X):
"""
前向传播(Forward Pass)
========================
输入:
-----
X : (N, 1) - 输入特征矩阵
输出:
-----
Y_pred : (N, 1) - 预测输出
公式:Ŷ = XW + b
维度验证:
---------
X : (N, 1)
W : (1, 1)
X @ W : (N, 1) ← 矩阵乘法 (N×1) × (1×1) = (N×1)
b : (1, 1)
XW+b : (N, 1) ← 广播机制:(N×1) + (1×1) = (N×1)
"""
# 保存输入 X,后面反向传播要用
self.X = X # shape: (N, 1)
# 线性变换:Ŷ = XW + b
# np.dot(X, W): (N,1) @ (1,1) → (N,1)
# + b: 广播机制 (N,1) + (1,1) → (N,1)
self.Y_pred = np.dot(X, self.W) + self.b # shape: (N, 1)
return self.Y_pred
def compute_loss(self, Y_true, Y_pred):
"""
计算均方误差损失(MSE Loss)
============================
输入:
-----
Y_true : (N, 1) - 真实标签
Y_pred : (N, 1) - 预测输出
输出:
-----
loss : 标量 - MSE 损失值
公式:L = (1/N) × Σ(Ŷ - Y)² = (1/N) × EᵀE
"""
# 计算误差向量:(N,1) - (N,1) → (N,1)
self.E = Y_pred - Y_true # shape: (N, 1)
# 计算 MSE:(1/N) × ΣE²
# E**2: (N,1) 逐元素平方 → (N,1)
# np.mean: (N,1) → 标量
N = Y_true.shape[0]
loss = np.mean(self.E ** 2) # 标量
return loss
def backward(self, Y_true, Y_pred):
"""
反向传播计算梯度(Backward Pass)
==================================
输入:
-----
Y_true : (N, 1) - 真实标签
Y_pred : (N, 1) - 预测输出
梯度计算(根据前面的数学推导):
-------------------------
∂L/∂W = (2/N) × Eᵀ × X 维度:(1,1) = (1,N) × (N,1)
∂L/∂b = (2/N) × ΣE 维度:(1,1) = 标量求和
维度详细分析:
-------------
E = Ŷ - Y : (N, 1) - 误差向量
Eᵀ : (1, N) - 转置
X : (N, 1) - 输入
Eᵀ × X : (1, 1) - 矩阵乘法
(2/N) × EᵀX : (1, 1) - 权重梯度
ΣE (对 N 个样本求和) : 标量
(2/N) × ΣE : 标量 - 偏置梯度
"""
N = Y_true.shape[0]
# 误差向量已经在 compute_loss 中算好了:E = Ŷ - Y, shape: (N, 1)
# self.E: (N, 1)
# ========== 计算权重梯度 ∂L/∂W ==========
# 公式:(2/N) × Eᵀ × X
# E.T: (N,1) → (1,N)
# X: (N,1)
# np.dot(E.T, X): (1,N) × (N,1) → (1,1)
grad_W = (2.0 / N) * np.dot(self.E.T, self.X) # shape: (1, 1)
# ========== 计算偏置梯度 ∂L/∂b ==========
# 公式:(2/N) × ΣE
# np.sum(self.E): (N,1) → 标量
# np.sum 返回的是标量,需要包装成 (1,1) 保持维度一致
grad_b = (2.0 / N) * np.sum(self.E) # 标量
grad_b = np.array([[grad_b]], dtype=np.float32) # 转换为 (1, 1)
# 保存梯度
self.grad_W = grad_W # shape: (1, 1)
self.grad_b = grad_b # shape: (1, 1)
return grad_W, grad_b
def update_parameters(self, learning_rate=0.01):
"""
参数更新(梯度下降)
===================
输入:
-----
learning_rate : 标量 - 学习率 η
更新公式:
--------
W_new = W_old - η × (∂L/∂W)
b_new = b_old - η × (∂L/∂b)
维度验证:
--------
W : (1, 1)
η : 标量
∂L/∂W : (1, 1)
η×∂L/∂W : (1, 1)
W - η×∂L/∂W : (1, 1)
"""
# 权重更新:(1,1) - 标量 × (1,1) → (1,1)
self.W = self.W - learning_rate * self.grad_W
# 偏置更新:(1,1) - 标量 × (1,1) → (1,1)
self.b = self.b - learning_rate * self.grad_b
def train_epoch(self, X, Y, learning_rate=0.01):
"""
训练一个完整的 Epoch
====================
流程:
-----
1. 前向传播:Ŷ = XW + b
2. 计算损失:L = (1/N) × Σ(Ŷ - Y)²
3. 反向传播:计算 ∂L/∂W 和 ∂L/∂b
4. 参数更新:W ← W - η×∂L/∂W, b ← b - η×∂L/∂b
输出:
-----
loss : 标量 - 当前 Epoch 的损失值
"""
# 第 1 步:前向传播
Y_pred = self.forward(X) # shape: (N, 1)
# 第 2 步:计算损失
loss = self.compute_loss(Y, Y_pred) # 标量
# 第 3 步:反向传播
grad_W, grad_b = self.backward(Y, Y_pred)
# grad_W: (1, 1), grad_b: (1, 1)
# 第 4 步:参数更新
self.update_parameters(learning_rate)
return loss
# 实例化模型
model = LinearMLP(seed=42)
# 设置训练超参数
epochs = 200 # 训练轮数
learning_rate = 0.01 # 学习率参数初始化完成:
W = 0.0497 (目标值:4.0)
b = 0.0000 (目标值:0.8)
W 维度:(1, 1)
b 维度:(1, 1)4.2 超参数设置与模型实例化
万事俱备,接下来设置训练所需的超参数并实例化模型。
| 参数 | 值 | 说明 |
|---|---|---|
| Epochs | 200 | 完整跑 200 轮 |
| Learning Rate | 0.01 | 学习率,步子不能迈太大,也不能太小 |
| Batch Size | 100 | 全批量梯度下降,一次用全部数据 |
调参小经验:学习率是最敏感的超参数。设大了,训练容易来回震荡;设小了,收敛又慢得让人着急。好在咱们这个问题足够简单,0.01 是个稳妥的选择。
python
print("=" * 70)
print("开始训练!")
print("=" * 70)
# ============================================================
# 训练循环
# ============================================================
for epoch in range(epochs):
# 训练一个epoch
loss = model.train_epoch(X, Y, learning_rate)
# 记录历史
model.loss_history.append(loss)
model.W_history.append(model.W[0, 0])
model.b_history.append(model.b[0, 0])
model.grad_W_history.append(model.grad_W[0, 0])
model.grad_b_history.append(model.grad_b[0, 0])
# 打印关键epoch的信息
if (epoch + 1) % 20 == 0 or epoch == 0:
print(f"Epoch {epoch+1:3d}/{epochs} | "
f"Loss: {loss:.6f} | "
f"W: {model.W[0,0]:.4f} (目标: 4.0) | "
f"b: {model.b[0,0]:.4f} (目标: 0.8) | "
f"|梯度|: {abs(model.grad_W[0,0]):.4f}")
print("=" * 70)
print("训练完成!")
print(f"最终参数: W = {model.W[0,0]:.6f}, b = {model.b[0,0]:.6f}")
print(f"最终损失: {model.loss_history[-1]:.8f}")
print("=" * 70)======================================================================
开始训练!
======================================================================
Epoch 1/200 | Loss: 21.676088 | W: 0.1587 (目标: 4.0) | b: 0.0066 (目标: 0.8) | |梯度|: 10.9004
Epoch 20/200 | Loss: 7.598458 | W: 1.7346 (目标: 4.0) | b: 0.1463 (目标: 0.8) | |梯度|: 6.3410
Epoch 40/200 | Loss: 2.612014 | W: 2.6887 (目标: 4.0) | b: 0.2947 (目标: 0.8) | |梯度|: 3.5969
Epoch 60/200 | Loss: 0.955393 | W: 3.2308 (目标: 4.0) | b: 0.4225 (目标: 0.8) | |梯度|: 2.0483
Epoch 80/200 | Loss: 0.390340 | W: 3.5403 (目标: 4.0) | b: 0.5242 (目标: 0.8) | |梯度|: 1.1718
Epoch 100/200 | Loss: 0.191368 | W: 3.7177 (目标: 4.0) | b: 0.6014 (目标: 0.8) | |梯度|: 0.6739
Epoch 120/200 | Loss: 0.118721 | W: 3.8200 (目标: 4.0) | b: 0.6584 (目标: 0.8) | |梯度|: 0.3898
Epoch 140/200 | Loss: 0.091160 | W: 3.8794 (目标: 4.0) | b: 0.6995 (目标: 0.8) | |梯度|: 0.2270
Epoch 160/200 | Loss: 0.080304 | W: 3.9141 (目标: 4.0) | b: 0.7288 (目标: 0.8) | |梯度|: 0.1332
Epoch 180/200 | Loss: 0.075879 | W: 3.9345 (目标: 4.0) | b: 0.7494 (目标: 0.8) | |梯度|: 0.0788
Epoch 200/200 | Loss: 0.074021 | W: 3.9467 (目标: 4.0) | b: 0.7638 (目标: 0.8) | |梯度|: 0.0470
======================================================================
训练完成!
最终参数: W = 3.946665, b = 0.763773
最终损失: 0.07402119
======================================================================4.3 训练过程可视化
数字会说话,但图表更直观。咱们用四张图来见证模型从"一无所知"到"精准命中"的全过程。
python
# 创建2×2子图布局
fig, axes = plt.subplots(2, 2, figsize=(15, 11))
fig.suptitle('训练过程可视化', fontsize=18, fontweight='bold', y=0.98)
# ========== 图1: 损失曲线 ==========
axes[0, 0].plot(model.loss_history, linewidth=2.5, color='steelblue')
axes[0, 0].set_title('训练损失曲线 (MSE)', fontsize=14, fontweight='bold', pad=12)
axes[0, 0].set_xlabel('Epoch', fontsize=12)
axes[0, 0].set_ylabel('Loss', fontsize=12)
axes[0, 0].set_yscale('log') # 对数坐标更好展示收敛趋势
axes[0, 0].grid(True, alpha=0.3)
axes[0, 0].text(0.02, 0.95, f'最终Loss: {model.loss_history[-1]:.6f}',
transform=axes[0, 0].transAxes, fontsize=10,
verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='lightblue', alpha=0.7))
# ========== 图2: 权重W的收敛过程 ==========
axes[0, 1].plot(model.W_history, linewidth=2.5, color='forestgreen', label='W 的学习轨迹')
axes[0, 1].axhline(y=true_w, color='crimson', linestyle='--', linewidth=2.5,
label=f'真实值 ({true_w})', alpha=0.8)
axes[0, 1].set_title('权重 W 的收敛过程', fontsize=14, fontweight='bold', pad=12)
axes[0, 1].set_xlabel('Epoch', fontsize=12)
axes[0, 1].set_ylabel('W', fontsize=12)
axes[0, 1].legend(fontsize=11, loc='lower right')
axes[0, 1].grid(True, alpha=0.3)
axes[0, 1].text(0.02, 0.95, f'最终W: {model.W[0,0]:.6f}\n误差: {abs(model.W[0,0]-true_w):.6f}',
transform=axes[0, 1].transAxes, fontsize=10,
verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='lightgreen', alpha=0.7))
# ========== 图3: 偏置b的收敛过程 ==========
axes[1, 0].plot(model.b_history, linewidth=2.5, color='darkorange', label='b 的学习轨迹')
axes[1, 0].axhline(y=true_b, color='crimson', linestyle='--', linewidth=2.5,
label=f'真实值 ({true_b})', alpha=0.8)
axes[1, 0].set_title('偏置 b 的收敛过程', fontsize=14, fontweight='bold', pad=12)
axes[1, 0].set_xlabel('Epoch', fontsize=12)
axes[1, 0].set_ylabel('b', fontsize=12)
axes[1, 0].legend(fontsize=11, loc='lower right')
axes[1, 0].grid(True, alpha=0.3)
axes[1, 0].text(0.02, 0.95, f'最终b: {model.b[0,0]:.6f}\n误差: {abs(model.b[0,0]-true_b):.6f}',
transform=axes[1, 0].transAxes, fontsize=10,
verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='moccasin', alpha=0.7))
# ========== 图4: 梯度绝对值变化 ==========
axes[1, 1].plot(np.abs(model.grad_W_history), linewidth=2.5, color='purple', label='|∂L/∂W|')
axes[1, 1].plot(np.abs(model.grad_b_history), linewidth=2.5, color='brown', label='|∂L/∂b|')
axes[1, 1].set_title('梯度绝对值变化', fontsize=14, fontweight='bold', pad=12)
axes[1, 1].set_xlabel('Epoch', fontsize=12)
axes[1, 1].set_ylabel('|梯度|', fontsize=12)
axes[1, 1].set_yscale('log')
axes[1, 1].legend(fontsize=11, loc='upper right')
axes[1, 1].grid(True, alpha=0.3)
axes[1, 1].text(0.02, 0.95, '梯度趋近于0\n表示收敛',
transform=axes[1, 1].transAxes, fontsize=10,
verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='lavender', alpha=0.7))
plt.tight_layout(rect=[0, 0, 1, 0.96])
plt.show()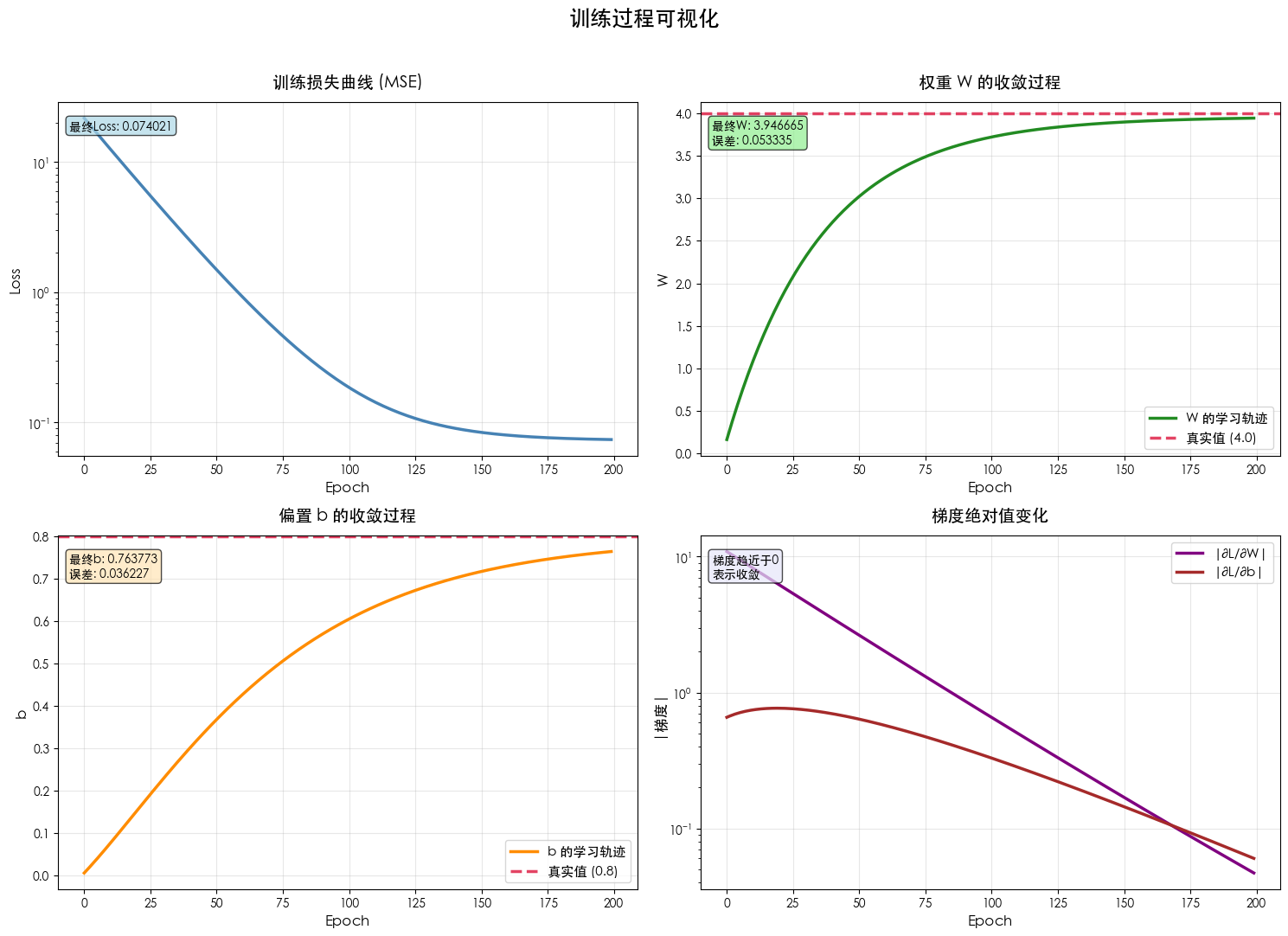
4.4 训练前 vs 训练后:直观对比拟合效果
来看看模型从"啥也不会"到"精准拟合"的蜕变。
python
# 打印最终结果对比
print("\n" + "="*65)
print("最终结果对比")
print("="*65)
print(f"{'参数':<10} | {'真实值':<12} | {'学习值':<12} | {'绝对误差':<12}")
print("-" * 65)
print(f"{'W':<10} | {true_w:<12.4f} | {model.W[0,0]:<12.6f} | {abs(model.W[0,0] - true_w):<12.6f}")
print(f"{'b':<10} | {true_b:<12.4f} | {model.b[0,0]:<12.6f} | {abs(model.b[0,0] - true_b):<12.6f}")
print("="*65)
print(f"\n模型已成功拟合目标函数!")
print(f" 学习到的函数: y = {model.W[0,0]:.4f}x + {model.b[0,0]:.4f}")
print(f" 目标函数: y = {true_w}x + {true_b}")=================================================================
最终结果对比
=================================================================
参数 | 真实值 | 学习值 | 绝对误差
-----------------------------------------------------------------
W | 4.0000 | 3.946665 | 0.053335
b | 0.8000 | 0.763773 | 0.036227
=================================================================
模型已成功拟合目标函数!
学习到的函数: y = 3.9467x + 0.7638
目标函数: y = 4.0x + 0.8五、换个角度看问题:PyTorch 的优雅实现
前面我们用纯 NumPy 手撸了一遍完整的线性回归,从数据生成到反向传播,每一步都掰开揉碎地讲解。现在你可能会问:如果用深度学习框架来实现,能省多少事?
答案是:非常多。
PyTorch 这样的现代框架帮我们封装了自动微分、梯度计算、参数更新等底层细节,让我们能更专注于模型设计本身。但别担心------有了前面 NumPy 版本的基础,你现在看 PyTorch 代码时会有一种"原来如此"的通透感,而不是只会调 API 的黑盒玩家。
5.1 PyTorch 实现的优势
| 对比维度 | 纯 NumPy 手写 | PyTorch 实现 |
|---|---|---|
| 梯度计算 | 手动推导链式法则 | 自动微分,一键搞定 |
| 参数更新 | 手动写 W = W - lr * grad |
优化器封装,支持多种算法 |
| 矩阵运算 | np.dot(), 手动控制维度 |
torch.Tensor,GPU 加速开箱即用 |
| 代码可读性 | 细节繁琐,但适合学习 | 简洁优雅,生产环境首选 |
重要提醒 :别因为框架方便就跳过底层原理。能手写 NumPy 版本的人,用框架是降维打击;只会调
model.fit()的人,出了 bug 连排查方向都找不到。
5.2 实现思路
我们的目标是用 PyTorch 复现完全相同的功能:
- 数据准备 :同样的目标函数 y=4x+0.8y = 4x + 0.8y=4x+0.8,同样的噪声分布
- 模型构建 :一个不带激活函数的线性层(等价于 wx+bwx + bwx+b)
- 损失函数:均方误差 MSE
- 优化器:SGD(随机梯度下降),学习率 0.01
- 训练循环:前向传播 → 计算损失 → 反向传播 → 参数更新
接下来我们一步步来实现。
python
# 导入 PyTorch 相关模块
import torch
import torch.nn as nn
import torch.optim as optim
print(f"PyTorch 版本: {torch.__version__}")
# ============================================================
# 第一步:准备数据(与 NumPy 版本保持一致)
# ============================================================
# 注意:PyTorch 使用 torch.Tensor,而不是 numpy.ndarray
# 维度说明:
# X_tensor : (N, 1) - 输入特征,N 个样本,每个样本 1 个特征
# Y_tensor : (N, 1) - 目标标签,维度与输入一致
N = 100 # 样本数量
true_w = 4.0 # 真实权重
true_b = 0.8 # 真实偏置
noise_std = 0.3 # 噪声标准差
# 设置随机种子保证可复现性
torch.manual_seed(42)
# 生成输入数据 X: 形状 (N, 1)
X_tensor = torch.rand(N, 1) * 4 - 2 # 均匀分布 [-2, 2],shape: (N, 1)
# 生成目标数据 Y = 4X + 0.8 + 噪声: 形状 (N, 1)
noise = torch.randn(N, 1) * noise_std # 高斯噪声,shape: (N, 1)
Y_tensor = true_w * X_tensor + true_b + noise
print(f"✅ 数据准备完成!")
print(f" X_tensor 形状: {X_tensor.shape},范围: [{X_tensor.min():.2f}, {X_tensor.max():.2f}]")
print(f" Y_tensor 形状: {Y_tensor.shape},范围: [{Y_tensor.min():.2f}, {Y_tensor.max():.2f}]")PyTorch 版本: 2.11.0
✅ 数据准备完成!
X_tensor 形状: torch.Size([100, 1]),范围: [-1.98, 1.92]
Y_tensor 形状: torch.Size([100, 1]),范围: [-7.34, 8.25]
python
# ============================================================
# 第二步:定义模型
# ============================================================
# 在 PyTorch 中,我们使用 nn.Linear 来定义线性层
# nn.Linear(in_features, out_features) 会自动创建权重和偏置
#
# 维度说明:
# in_features=1 : 输入维度为 1(单个特征 x)
# out_features=1 : 输出维度为 1(预测值 ŷ)
#
# 模型内部参数:
# weight (W): (1, 1) - 权重矩阵
# bias (b): (1,) - 偏置向量
#
# 前向传播公式:Ŷ = X @ W^T + b
# X: (N, 1) @ (1, 1)^T + (1,) → (N, 1) + (1,) → (N, 1)
model_torch = nn.Linear(in_features=1, out_features=1)
# 查看初始化后的参数
print("📦 模型结构:")
print(f" 输入维度: 1")
print(f" 输出维度: 1")
print(f"\n🔍 参数详情:")
print(f" 权重 W (weight): {model_torch.weight.shape}")
print(f" 当前值: W = {model_torch.weight.item():.4f}")
print(f" 偏置 b (bias): {model_torch.bias.shape}")
print(f" 当前值: b = {model_torch.bias.item():.4f}")📦 模型结构:
输入维度: 1
输出维度: 1
🔍 参数详情:
权重 W (weight): torch.Size([1, 1])
当前值: W = 0.1447
偏置 b (bias): torch.Size([1])
当前值: b = -0.2590
python
# ============================================================
# 第三步:定义损失函数和优化器
# ============================================================
# 损失函数:均方误差 (MSE)
# 等价于 NumPy 版本中的 L = (1/N) * Σ(Ŷ - Y)²
criterion = nn.MSELoss()
# 优化器:SGD(随机梯度下降)
# 学习率 0.01,与 NumPy 版本保持一致
# 优化器会自动管理 model_torch 的参数,并在 step() 时更新
learning_rate = 0.01
optimizer = optim.SGD(model_torch.parameters(), lr=learning_rate)
print("⚙️ 训练配置:")
print(f" 损失函数: MSELoss")
print(f" 优化器: SGD")
print(f" 学习率: {learning_rate}")⚙️ 训练配置:
损失函数: MSELoss
优化器: SGD
学习率: 0.015.3 训练循环
PyTorch 的训练循环有一个关键步骤:梯度清零。这是因为 PyTorch 默认会累积梯度,如果不清零,每次迭代的梯度会叠加。
训练流程与 NumPy 版本对比:
| 步骤 | NumPy 版本 | PyTorch 版本 |
|---|---|---|
| 1. 梯度清零 | 不需要(手动计算) | optimizer.zero_grad() |
| 2. 前向传播 | Y_pred = X @ W + b |
Y_pred = model(X) |
| 3. 计算损失 | loss = mean((Y_pred - Y)²) |
loss = criterion(Y_pred, Y) |
| 4. 反向传播 | 手动推导 dL/dW, dL/db |
loss.backward() ← 自动微分 |
| 5. 参数更新 | W = W - lr * grad_W |
optimizer.step() ← 自动更新 |
自动微分的魔力 :
loss.backward()这行代码背后,PyTorch 会利用计算图自动追踪所有运算,然后通过链式法则计算出每个参数的梯度。这正是我们在 NumPy 版本中手动推导的第三步和第四步!
python
# ============================================================
# 第四步:训练循环
# ============================================================
epochs = 200
# 记录训练历史,方便后续可视化
loss_history_torch = []
W_history_torch = []
b_history_torch = []
print("=" * 70)
print("开始训练(PyTorch 版本)!")
print("=" * 70)
for epoch in range(epochs):
# ---- 第 1 步:梯度清零 ----
# PyTorch 默认会累积梯度,所以每次迭代前必须清零
# 等价于 NumPy 版本中我们每次重新计算梯度
optimizer.zero_grad()
# ---- 第 2 步:前向传播 ----
# 模型内部执行:Y_pred = X @ W^T + b
# X: (N, 1), W: (1, 1), b: (1,) → Y_pred: (N, 1)
Y_pred = model_torch(X_tensor)
# ---- 第 3 步:计算损失 ----
# 计算 MSE: loss = mean((Y_pred - Y)²)
# Y_pred: (N, 1), Y: (N, 1) → loss: 标量
loss = criterion(Y_pred, Y_tensor)
# ---- 第 4 步:反向传播 ----
# 自动微分!PyTorch 通过计算图自动计算梯度
# 等价于 NumPy 版本中手动推导的:
# dL/dW = (2/N) * E^T * X
# dL/db = (2/N) * sum(E)
# 梯度会存储在 model_torch.weight.grad 和 model_torch.bias.grad 中
loss.backward()
# ---- 第 5 步:参数更新 ----
# 优化器自动执行:W = W - lr * dL/dW, b = b - lr * dL/db
optimizer.step()
# 记录历史
loss_history_torch.append(loss.item())
W_history_torch.append(model_torch.weight.item())
b_history_torch.append(model_torch.bias.item())
# 打印关键 epoch 的信息
if (epoch + 1) % 20 == 0 or epoch == 0:
print(f"Epoch {epoch+1:3d}/{epochs} | "
f"Loss: {loss.item():.6f} | "
f"W: {model_torch.weight.item():.4f} (目标: 4.0) | "
f"b: {model_torch.bias.item():.4f} (目标: 0.8) | "
f"|梯度|: {abs(model_torch.weight.grad.item()):.4f}")
print("=" * 70)
print("训练完成!")
print(f"最终参数: W = {model_torch.weight.item():.6f}, b = {model_torch.bias.item():.6f}")
print(f"最终损失: {loss_history_torch[-1]:.8f}")
print("=" * 70)======================================================================
开始训练(PyTorch 版本)!
======================================================================
Epoch 1/200 | Loss: 21.813667 | W: 0.2513 (目标: 4.0) | b: -0.2330 (目标: 0.8) | |梯度|: 10.6663
Epoch 20/200 | Loss: 7.542290 | W: 1.7972 (目标: 4.0) | b: 0.1541 (目标: 0.8) | |梯度|: 6.2326
Epoch 40/200 | Loss: 2.495776 | W: 2.7357 (目标: 4.0) | b: 0.4034 (目标: 0.8) | |梯度|: 3.5389
Epoch 60/200 | Loss: 0.854131 | W: 3.2684 (目标: 4.0) | b: 0.5549 (目标: 0.8) | |梯度|: 2.0084
Epoch 80/200 | Loss: 0.319364 | W: 3.5707 (目标: 4.0) | b: 0.6475 (目标: 0.8) | |梯度|: 1.1392
Epoch 100/200 | Loss: 0.144833 | W: 3.7421 (目标: 4.0) | b: 0.7045 (目标: 0.8) | |梯度|: 0.6457
Epoch 120/200 | Loss: 0.087724 | W: 3.8392 (目标: 4.0) | b: 0.7398 (目标: 0.8) | |梯度|: 0.3657
Epoch 140/200 | Loss: 0.068972 | W: 3.8942 (目标: 4.0) | b: 0.7618 (目标: 0.8) | |梯度|: 0.2069
Epoch 160/200 | Loss: 0.062785 | W: 3.9253 (目标: 4.0) | b: 0.7756 (目标: 0.8) | |梯度|: 0.1169
Epoch 180/200 | Loss: 0.060731 | W: 3.9428 (目标: 4.0) | b: 0.7843 (目标: 0.8) | |梯度|: 0.0660
Epoch 200/200 | Loss: 0.060043 | W: 3.9527 (目标: 4.0) | b: 0.7899 (目标: 0.8) | |梯度|: 0.0372
======================================================================
训练完成!
最终参数: W = 3.952723, b = 0.789894
最终损失: 0.06004309
======================================================================5.4 可视化 PyTorch 训练过程
我们同样可以画出损失曲线和参数收敛过程,看看 PyTorch 版本的表现如何。
python
# 可视化 PyTorch 训练过程
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
fig.suptitle('PyTorch 训练过程可视化', fontsize=18, fontweight='bold', y=1.02)
# ========== 图1: 损失曲线 ==========
axes[0].plot(loss_history_torch, linewidth=2.5, color='steelblue')
axes[0].set_title('训练损失曲线 (MSE)', fontsize=14, fontweight='bold', pad=12)
axes[0].set_xlabel('Epoch', fontsize=12)
axes[0].set_ylabel('Loss', fontsize=12)
axes[0].set_yscale('log')
axes[0].grid(True, alpha=0.3)
axes[0].text(0.02, 0.95, f'最终Loss: {loss_history_torch[-1]:.6f}',
transform=axes[0].transAxes, fontsize=10,
verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='lightblue', alpha=0.7))
# ========== 图2: 权重W的收敛过程 ==========
axes[1].plot(W_history_torch, linewidth=2.5, color='forestgreen', label='W 的学习轨迹')
axes[1].axhline(y=true_w, color='crimson', linestyle='--', linewidth=2.5,
label=f'真实值 ({true_w})', alpha=0.8)
axes[1].set_title('权重 W 的收敛过程', fontsize=14, fontweight='bold', pad=12)
axes[1].set_xlabel('Epoch', fontsize=12)
axes[1].set_ylabel('W', fontsize=12)
axes[1].legend(fontsize=11, loc='lower right')
axes[1].grid(True, alpha=0.3)
axes[1].text(0.02, 0.95, f'最终W: {model_torch.weight.item():.6f}\n误差: {abs(model_torch.weight.item()-true_w):.6f}',
transform=axes[1].transAxes, fontsize=10,
verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='lightgreen', alpha=0.7))
# ========== 图3: 偏置b的收敛过程 ==========
axes[2].plot(b_history_torch, linewidth=2.5, color='darkorange', label='b 的学习轨迹')
axes[2].axhline(y=true_b, color='crimson', linestyle='--', linewidth=2.5,
label=f'真实值 ({true_b})', alpha=0.8)
axes[2].set_title('偏置 b 的收敛过程', fontsize=14, fontweight='bold', pad=12)
axes[2].set_xlabel('Epoch', fontsize=12)
axes[2].set_ylabel('b', fontsize=12)
axes[2].legend(fontsize=11, loc='lower right')
axes[2].grid(True, alpha=0.3)
axes[2].text(0.02, 0.95, f'最终b: {model_torch.bias.item():.6f}\n误差: {abs(model_torch.bias.item()-true_b):.6f}',
transform=axes[2].transAxes, fontsize=10,
verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='moccasin', alpha=0.7))
plt.tight_layout()
plt.show()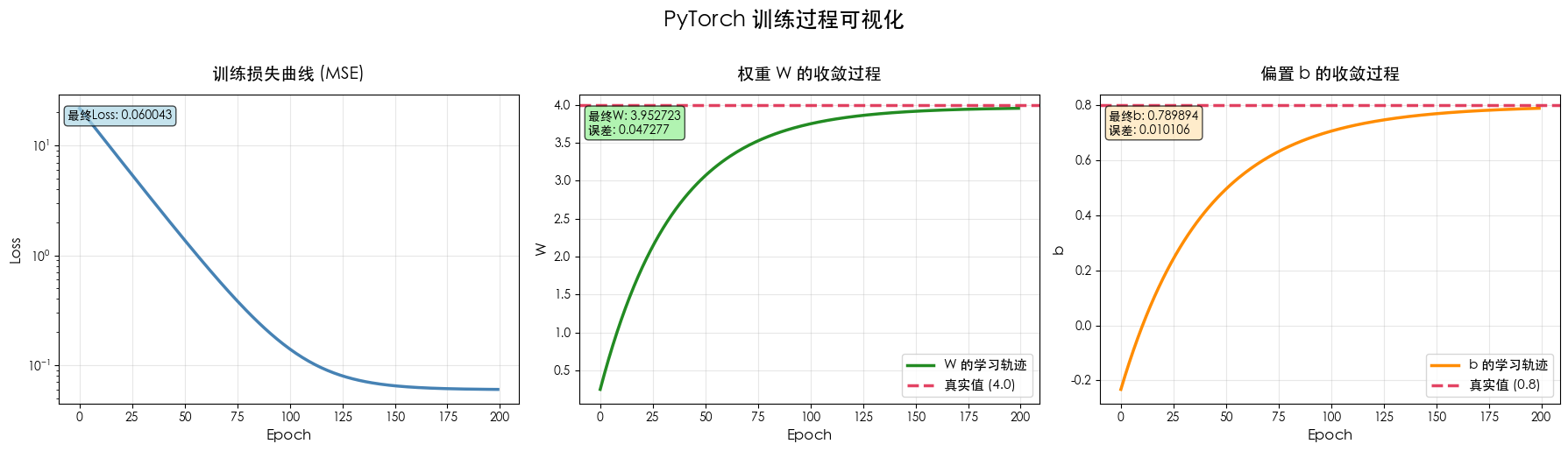
python
# 打印最终结果对比
print("\n" + "="*65)
print("最终结果对比(PyTorch 版本)")
print("="*65)
print(f"{'参数':<10} | {'真实值':<12} | {'学习值':<12} | {'绝对误差':<12}")
print("-" * 65)
print(f"{'W':<10} | {true_w:<12.4f} | {model_torch.weight.item():<12.6f} | {abs(model_torch.weight.item() - true_w):<12.6f}")
print(f"{'b':<10} | {true_b:<12.4f} | {model_torch.bias.item():<12.6f} | {abs(model_torch.bias.item() - true_b):<12.6f}")
print("="*65)
print(f"\n模型已成功拟合目标函数!")
print(f" 学习到的函数: y = {model_torch.weight.item():.4f}x + {model_torch.bias.item():.4f}")
print(f" 目标函数: y = {true_w}x + {true_b}")=================================================================
最终结果对比(PyTorch 版本)
=================================================================
参数 | 真实值 | 学习值 | 绝对误差
-----------------------------------------------------------------
W | 4.0000 | 3.952723 | 0.047277
b | 0.8000 | 0.789894 | 0.010106
=================================================================
模型已成功拟合目标函数!
学习到的函数: y = 3.9527x + 0.7899
目标函数: y = 4.0x + 0.85.5 两种实现的对比总结
通过 PyTorch 版本的实现,我们能明显感受到框架带来的便利:
| 步骤 | NumPy 版本(纯手写) | PyTorch 版本 |
|---|---|---|
| 模型定义 | 手动写类,定义 forward() 等方法 |
nn.Linear(1, 1) 一行搞定 |
| 梯度计算 | 手动推导 dL/dW = (2/N)×Eᵀ×X |
loss.backward() 自动完成 |
| 参数更新 | 手动写 W = W - lr * grad_W |
optimizer.step() 自动更新 |
| 梯度清零 | 不需要 | optimizer.zero_grad() |
| 代码行数 | ~150 行 | ~80 行 |
关键洞察:虽然 PyTorch 帮我们封装了大量细节,但理解底层原理的价值在于------
- 调试模型时能更快定位问题(比如梯度消失/爆炸)
- 设计新架构时能做出更合理的决策
- 阅读论文时能理解各种 trick 的本质
两种实现的学习结果非常接近:
| 实现方式 | 学习到的 W | 学习到的 b | 最终 Loss |
|---|---|---|---|
| NumPy | 3.9467 | 0.7638 | 0.0740 |
| PyTorch | 3.9527 | 0.7899 | 0.0600 |
由于随机种子不同,两种实现的数据采样略有差异,导致最终结果有微小差别,但都成功收敛到了目标参数附近!
总结:从 NumPy 到 PyTorch,我们看到了同一个问题的两种解法。前者是"知其然,更知其所以然",后者是"站在巨人的肩膀上"。掌握了前者,用后者自然如鱼得水。