【排序】C语言实现八大排序算法(含完整源码与性能测试)
❤️感谢支持,点赞关注不迷路❤️
排序,是计算机程序设计中最为基础且重要的算法之一。无论是面试题还是实际工程,排序算法总是高频出现。本文从 冒泡排序 到 计数排序,逐一分析每种排序的核心思路、代码实现、时间与空间复杂度,并给出 10 万级数据的实测对比,帮你建立完整的排序知识体系。
排序讲解
- 【排序】C语言实现八大排序算法(含完整源码与性能测试)
排序,笼统来说就是将一串记录按照关键字的大小,递增或递减地排列起来。生活中处处都有排序的影子------购物按价格筛选、成绩排行榜、考试成绩排名等。
本文基于 C 语言,实现以下八大排序算法(全部以递增为例):
| 序号 | 排序名称 | 类别 |
|---|---|---|
| 1 | 冒泡排序 | 交换排序 |
| 2 | 堆排序 | 选择排序 |
| 3 | 直接插入排序 | 插入排序 |
| 4 | 希尔排序 | 插入排序 |
| 5 | 直接选择排序 | 选择排序 |
| 6 | 快速排序 | 交换排序 |
| 7 | 归并排序 | 归并排序 |
| 8 | 计数排序 | 非比较排序 |
一、冒泡排序
冒泡排序是我们接触的第一个排序,虽然效率不高,但教学意义重大,是打开排序算法世界大门的第一把钥匙。
图解过程
初始数组:[5, 3, 8, 4, 2]
第一趟(i=0):
[5, 3, 8, 4, 2]
↓比较
[3, 5, 8, 4, 2] 交换 5>3
↓比较
[3, 5, 8, 4, 2] 不交换 5<8
↓比较
[3, 4, 8, 5, 2] 交换 8>4
↓比较
[3, 4, 2, 8, 5] 交换 8>2
第一趟结束,最大值8沉到最右第二趟(i=1):
[3, 4, 2, 8, 5]
↓比较
[3, 4, 2, 8, 5] 不交换 3<4
↓比较
[2, 4, 3, 8, 5] 交换 4>2
↓比较
[2, 3, 4, 8, 5] 交换 4>3
第二趟结束,次大值5在8左边第三趟(i=2):
[2, 3, 4, 8, 5]
↓比较
[2, 3, 4, 8, 5] 不交换 2<3
↓比较
[2, 3, 4, 8, 5] 不交换 3<4
第三趟结束,无需交换,数组已有序代码实现
c
void Swap(int* a, int* b)
{
int c = *a;
*a = *b;
*b = c;
}
void maopao(int* arr, int r)
{
for (int i = 0; i < r - 1; i++) // 趟数
{
int flag = 1;
for (int j = 0; j < r - 1 - i; j++) // 两两比较
{
if (arr[j] > arr[j + 1])
{
flag = 0;
Swap(&arr[j], &arr[j + 1]);
}
}
if (flag == 1) return; // 提前结束优化
}
}过程分析
- 外层循环控制总的趟数,对于 n 个元素,只需要 n-1 趟,因为最后一趟只剩一个元素无需比较。
- 内层循环负责两两比较,将大的元素逐步"冒泡"到右侧。
- 每经过一趟排序,未排序部分就会少一个元素,因此内层 j 的上限要减去 i。
flag优化:当某一趟没有任何交换时,说明数组已经有序,直接 return。
时空复杂度
- 空间复杂度:O(1),仅使用了常量级辅助变量
- 时间复杂度:O(N²),最差情况为逆序
性能验证
10 万个随机数,冒泡排序耗时约 3000+ ms,效率最低,但逻辑最为简单。
二、堆排序
堆排序利用 堆 这一完全二叉树结构的特点------堆顶元素要么最大(大堆),要么最小(小堆),不断交换堆顶与末尾元素并重新调整堆,最终得到有序序列。
图解过程
以数组 [4, 10, 3, 5, 1] 为例,构建大堆:
原始完全二叉树:
4
/ \
10 3
/ \
5 1
建堆过程(从最后一个非叶子节点开始向下调整):
节点(10)是最后一个非叶子节点,比较10与孩子5、1,10最大无需交换
节点(4)与孩子10、3比较,4<10,交换
10
/ \
4 3
/ \
5 1
再调整节点(4),与孩子5比较,4<5,交换
10
/ \
5 3
/ \
4 1代码实现
c
void Swap(int* a, int* b)
{
int c = *a;
*a = *b;
*b = c;
}
// 向下调整算法 ------ 构建大堆
void AdjustDown(int* arr, int r, int parent)
{
int child = parent * 2 + 1;
while (child < r)
{
if (child + 1 < r && arr[child + 1] > arr[child])
{
child++;
}
if (arr[parent] < arr[child])
{
Swap(&arr[parent], &arr[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void Heappai(int* arr, int r)
{
// 建堆 ------ 从第一个非叶子节点开始向下调整
for (int i = (r - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(arr, r, i);
}
// 排序:不断将堆顶(最大值)与末尾交换,再调整堆
int end = r;
while (end)
{
Swap(&arr[0], &arr[--end]);
AdjustDown(arr, end, 0);
}
}过程分析
- 建堆 :从最后一个非叶子节点
(n-1-1)/2开始往前,对每个节点执行向下调整,最终得到一个大堆。 - 排序:将堆顶最大值与数组末尾交换,此时末尾就是最大元素;然后对剩余的 n-1 个元素重新调整为堆,循环直至堆为空。
- 核心就在于 向下调整算法 ------ 让父节点与孩子节点比较,若孩子比父大(大堆),则交换,并继续向下调整。
时空复杂度
- 空间复杂度:O(1),原地排序
- 时间复杂度:O(N log N),建堆 O(N),每次调整 O(log N),共 N 次
性能验证
10 万数据仅需 6 ms 左右,远超冒泡排序。
三、直接插入排序
想象一下打扑克牌时,每摸一张牌都会按顺序插入到手牌中------直接插入排序就是这个思路。
图解过程
数组 [4, 5, 2, 7, 1],逐步将元素插入已排序部分:
初始:已排序[4],待插入[5, 2, 7, 1]
插入5:tep=5,end=0,4<5 不挪,插入到位置1
已排序[4, 5],待插入[2, 7, 1]
插入2:tep=2,end=1,5>2 挪到位置2,end=0
4>2 挪到位置1,end=-1
插入到位置0
已排序[2, 4, 5],待插入[7, 1]
插入7:tep=7,end=2,5<7 不挪,插入到位置3
已排序[2, 4, 5, 7],待插入[1]
插入1:tep=1,end=3,7>1 挪,end=2
5>1 挪,end=1
4>1 挪,end=0
2>1 挪,end=-1
插入到位置0
最终:[1, 2, 4, 5, 7]代码实现
c
void insertsort(int a[], int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tep = a[end + 1]; // 保存待插入元素
while (end >= 0)
{
if (a[end] > tep) // 比待插入元素大,往后挪
{
a[end + 1] = a[end];
end--;
}
else
{
break;
}
}
a[end + 1] = tep; // 插入到正确位置
}
}过程分析
- 外层循环控制要插入的元素,用
end指向已排序部分的最后一个位置,tep保存待插入元素。 - 内层 while 循环中,如果已排序元素比
tep大,就把它往后挪一位;否则找到插入位置。 - 简单说:移动排序,像整理扑克牌一样,比新牌大的牌就往前挪。
时空复杂度
- 空间复杂度:O(1)
- 时间复杂度 :O(N²),最差情况为逆序;但实际很难遇到最差情况,所以实际效率比冒泡高不少
性能验证
10 万数据约 几十毫秒,明显优于冒泡排序。
四、希尔排序
希尔排序是直接插入排序的升级版 ,核心思想是预排序------先让数据基本有序,最后再做一次直接插入排序。
希尔排序法又称缩小增量法。先选定一个整数(通常是 gap = n/3+1),把待排序记录分成各组,所有距离相等的记录分在同一组内,对每一组进行排序,然后 gap = gap/3+1 得到下一个整数,再次分组排序......当 gap=1 时,就相当于直接插入排序。
图解过程
数组 [9, 5, 1, 7, 3, 6, 4, 8],gap 从 3 递减到 1:
gap = 3 时,分组情况:
索引: 0 1 2 3 4 5 6 7
数据: 9 5 1 7 3 6 4 8
组别: A B A B A B A B
A组 [9, 1, 3, 4] 排序后:[1, 3, 4, 9]
B组 [5, 7, 6, 8] 排序后:[5, 6, 7, 8]
gap = 1 时,整体插入排序,此时数组已接近有序,效率极高代码实现
c
void shellsort(int a[], int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1; // 保证最后一次 gap=1
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tep = a[end + gap];
while (end >= 0)
{
if (a[end] > tep)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tep;
}
}
}过程分析
- gap 就是分组间隔,gap/3+1 使得 gap 逐步缩小,最终必为 1。
- 每组内进行插入排序,当 gap=1 时,整个数组已经基本有序,直接插入排序效率最高。
- 外层 for 循环用 i 来控制遍历,而不是每组单独排------优化点在于 i 到了哪一组就排哪一组。
时空复杂度
- 空间复杂度:O(1)
- 时间复杂度:O(N^1.3) 左右,《数据结构(C语言版)》--- 严蔚敏
性能验证
10 万数据约 6 ms,相比直接插入排序提升显著。
五、直接选择排序
直接选择排序的思路非常直接:每次在未排序部分选出最小值放到开头,选出最大值放到末尾,依次收缩边界。
图解过程
数组 [3, 5, 1, 4, 2],begin=0,end=4:
初始:[3, 5, 1, 4, 2]
↑ ↑
mini maxi
第一轮找最小最大:
遍历 [3,5,1,4,2],发现 mini=2(在索引4),maxi=5(在索引1)
交换 min 到开头,max 到末尾:
[2, 5, 1, 4, 3] ←→ [2, 3, 1, 4, 5]
begin=1, end=3
第二轮:
遍历 [5,1,4,3],发现 mini=1(在索引2),maxi=5(在索引0,但开头已处理)
因为 maxi==begin,需要将 maxi 修正为 mini(索引2)
交换:
[1, 3, 5, 4, 2]
begin=2, end=2,结束代码实现
c
void SelectSort(int* arr, int n)
{
int begin = 0, end = n - 1;
while (begin < end)
{
int mini = begin, maxi = begin;
for (int i = begin + 1; i <= end; i++)
{
if (arr[i] < arr[mini]) mini = i;
if (arr[i] > arr[maxi]) maxi = i;
}
// 注意:若最大值在开头,先交换会覆盖 mini 的位置,需要修正
if (maxi == begin) maxi = mini;
Swap(&arr[mini], &arr[begin]);
Swap(&arr[maxi], &arr[end]);
begin++;
end--;
}
}过程分析
- 遍历未排序区间 begin, end,找出最小值下标 mini 和最大值下标 maxi。
- 交换到两端后,begin++,end--,缩小区间。
- 特别注意:如果最大值恰好在开头,先交换 mini 和 begin 后,最大值的位置会被覆盖,此时需要将 maxi 修正为 mini。
时空复杂度
- 空间复杂度:O(1)
- 时间复杂度:O(N²)
性能验证
与冒泡排序大差不差,10 万数据约 2000-3000 ms。
六、快速排序
快速排序简称"快排",相信即便没学过也听过它的大名,是面试和工程中的高频明星。
快速排序的基本思想:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列所有元素均小于基准值,右子序列所有元素均大于基准值,然后递归左右子序列,直至所有元素排列在相应位置上。
图解过程 ------ Lomuto 前后指针法
数组 [4, 2, 7, 1, 5, 3],选基准值 key=4(左端):
初始:
[4, 2, 7, 1, 5, 3]
↑key
prev=0, cur=1
cur=1:a[1]=2 < 4,++prev=1,交换(自己和自己,换了等于没换)
[4, 2, 7, 1, 5, 3]
cur=2:a[2]=7 > 4,cur++,不交换
cur=3:a[3]=1 < 4,++prev=3,交换 a[3]↔a[3]
[4, 2, 1, 7, 5, 3]
cur=4:a[4]=5 > 4,cur++,不交换
cur=5:a[5]=3 < 4,++prev=4,交换 a[5]↔a[4]
[4, 2, 1, 3, 5, 7]
↑
prev
最后交换 a[prev] 和 a[key]:
[3, 2, 1, 4, 5, 7]
↑
基准值位置(已归位)
左区间 [3,2,1],右区间 [5,7],递归继续...1. hoare 版本
c
int GetMid(int* a, int left, int right)
{
int mid = (left + right) / 2;
if (a[left] > a[right])
{
if (a[right] > a[mid]) return right;
else if (a[mid] > a[left]) return left;
else return mid;
}
else
{
if (a[mid] < a[left]) return left;
else if (a[mid] > a[right]) return right;
else return mid;
}
}
int Quicksort(int* a, int left, int right)
{
int mid = GetMid(a, left, right);
Swap(&a[left], &a[mid]); // 三数取中优化
int key = left;
int begin = left, end = right;
while (begin < end)
{
while (begin < end && a[end] >= a[key]) end--;
while (begin < end && a[begin] <= a[key]) begin++;
Swap(&a[begin], &a[end]);
}
Swap(&a[key], &a[begin]);
return begin;
}
void QuickSort(int* a, int left, int right)
{
if (left >= right) return;
int key = Quicksort(a, left, right);
QuickSort(a, left, key - 1);
QuickSort(a, key + 1, right);
}2. Lomuto 前后指针法
c
int partQuickSort(int* a, int left, int right)
{
int mid = GetMid(a, left, right);
Swap(&a[left], &a[mid]);
int key = left;
int prev = left, cur = left + 1;
while (cur <= right)
{
if (a[cur] < a[key] && ++prev != cur)
Swap(&a[prev], &a[cur]);
cur++;
}
Swap(&a[prev], &a[key]);
return prev;
}3. 小区间优化 + 三数取中
c
void Quicksort2(int* a, int left, int right)
{
if (left >= right) return;
if (right - left + 1 < 10) // 小区间优化
{
insertsort(a + left, right - left + 1);
return;
}
int key = Quicksort(a, left, right);
Quicksort2(a, left, key - 1);
Quicksort2(a, key + 1, right);
}4. 非递归版本(借助栈)
c
void QuickSortNonR(int* a, int left, int right)
{
ST st;
STInit(&st);
STPush(&st, right);
STPush(&st, left);
while (!STEmpty(&st))
{
int begin = STTop(&st); STPop(&st);
int end = STTop(&st); STPop(&st);
int key = partQuickSort(a, begin, end);
if (key + 1 < end) { STPush(&st, end); STPush(&st, key + 1); }
if (begin < key - 1) { STPush(&st, key - 1); STPush(&st, begin); }
}
STDestory(&st);
}时空复杂度
- 空间复杂度:O(log N)(递归栈帧)
- 时间复杂度:O(N log N),最差 O(N²)(有序数组可通过三数取中避免)
性能验证
10 万数据约 4 ms,综合性能最强。
七、归并排序
归并排序采用 分治法 的思想,先递归拆分数组至单个元素,再有序合并两个子数组,最终得到完全有序的序列。
图解过程
数组 [6, 5, 3, 1, 8, 7, 2, 4] 的递归拆分与合并:
递归拆分:
[6, 5, 3, 1, 8, 7, 2, 4]
[6, 5, 3, 1] [8, 7, 2, 4]
[6, 5] [3, 1] [8, 7] [2, 4]
[6] [5] [3] [1] [8] [7] [2] [4] ← 单个元素,递归终止
两两合并(归并):
[5, 6] [1, 3] [7, 8] [2, 4]
[1, 3, 5, 6] [2, 4, 7, 8]
[1, 2, 3, 4, 5, 6, 7, 8] ← 完全有序递归版本
c
void _MergeSort(int* a, int* tmp, int begin, int end)
{
if (begin == end) return;
int mid = (begin + end) / 2;
_MergeSort(a, tmp, begin, mid);
_MergeSort(a, tmp, mid + 1, end);
// 归并
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
int i = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2]) tmp[i++] = a[begin1++];
else tmp[i++] = a[begin2++];
}
while (begin1 <= end1) tmp[i++] = a[begin1++];
while (begin2 <= end2) tmp[i++] = a[begin2++];
memcpy(a + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
_MergeSort(a, tmp, 0, n - 1);
free(tmp);
}这里时间复杂度未来介绍一下为什么是O(logN)
这里拿N等于8举例
因为这里用的是递归思想第一次是处理一个数组长度为的8进行归并排序所以是O(N);
第二个进入递归,是处理二个长度为【4】【4】的二个数组分别进行归并排序
第三次是【2】【2】【2】【2】进行归并。
第四次是【1】【1】【1】【1】【1】【1】【1】【1】归并
我们可以看见每一层都是O(N)
那一共有几层呢
我们可以算一下
-
初始数组长度:n
-
第1次拆分:得到2个长度为n/2的子数组
-
第2次拆分:得到4个长度为n/4的子数组
-
...
-
第k次拆分:得到2^k个长度为n/2的k次方的子数组
当子数组长度为1时,停止拆分:
n/z^k= 1
两边取以2为底的对数:
k = log2 n
所以总层数约为log2 n层(向上取整,因为数组长度不一定是2的整数次幂)。
所以他的时间复杂度是O(NlogN)
非递归版本(循环实现)
c
void _MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
if (begin2 >= n) break;
if (end2 >= n) end2 = n - 1;
int j = begin1;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2]) tmp[j++] = a[begin1++];
else tmp[j++] = a[begin2++];
}
while (begin1 <= end1) tmp[j++] = a[begin1++];
while (begin2 <= end2) tmp[j++] = a[begin2++];
memcpy(a + i, tmp + i, (end2 - begin1 + 1) * sizeof(int));
}
gap *= 2;
}
free(tmp);
}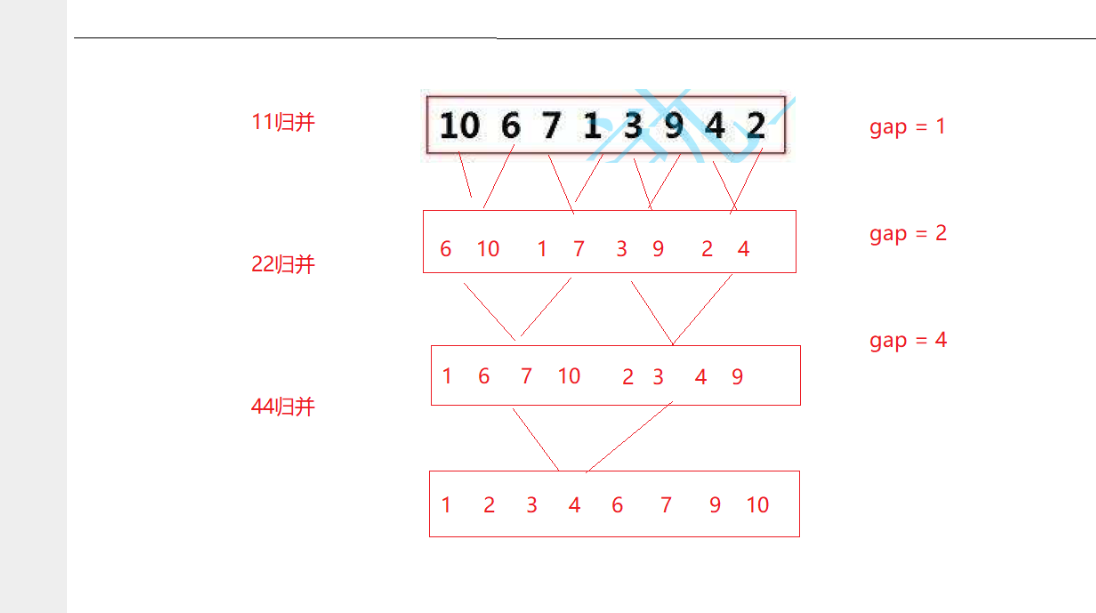
这里我们可以通过图看见里面的循环执行次数每一次都是O(N)
外面的次数是logN
所以他的时间复杂度也是O(NlogN)
时空复杂度
- 空间复杂度:O(N),需要额外辅助数组
- 时间复杂度:O(N log N)
性能验证
10 万数据约 4 ms,与快排持平,且性能稳定。
八、计数排序
前面七种排序都需要两两比较元素大小,计数排序则另辟蹊径,通过统计每个元素出现的次数,按下标天然有序的特性来完成排序。
图解过程
数组 [4, 2, 4, 1, 3]:
Step 1:找最小最大值
min=1, max=4,range = 4-1+1 = 4
Step 2:创建计数数组(长度4,全0)
count: [0, 0, 0, 0]
↓
index
Step 3:遍历原数组,统计并映射
a[0]=4 → count[4-1]=count[3]++
a[1]=2 → count[2-1]=count[1]++
a[2]=4 → count[3]++
a[3]=1 → count[1-1]=count[0]++
a[4]=3 → count[3-1]=count[2]++
count: [1, 1, 1, 2]
↑ ↑ ↑ ↑
1 2 3 4 (+min还原)
Step 4:遍历计数数组,回写原数组
count[0]=1 → a[0]=1+1=2
count[1]=1 → a[1]=2+1=3
count[2]=1 → a[2]=3+1=4
count[3]=2 → a[3]=4+1=5, a[4]=5+1=6
最终:[2, 3, 4, 5, 6]代码实现
c
void contsort(int* a, int n)
{
int min = a[0], max = a[0];
for (int i = 1; i < n; i++)
{
if (a[i] < min) min = a[i];
if (a[i] > max) max = a[i];
}
int range = max - min + 1;
int* cout = (int*)calloc(range, sizeof(int));
// 统计次数
for (int i = 0; i < n; i++)
{
cout[a[i] - min]++; // 映射到计数数组下标
}
// 回写
int j = 0;
for (int i = 0; i < range; i++)
{
while (cout[i]--)
{
a[j++] = i + min;
}
}
free(cout);
}过程分析
- 先遍历数组找出最小值和最大值,确定计数数组的大小
range = max - min + 1。 - 创建计数数组
cout,用calloc初始化为 0。 - 遍历原数组,通过
a[i] - min映射到计数数组下标并累加计数。 - 最后遍历计数数组,按下标(加上最小值还原原值)依次填回原数组。
特性分析
- 计数排序不是比较排序,利用下标天然有序的特性完成排序。
- 适用场景:数据范围集中时效率极高;数据分散时空间浪费严重。
时空复杂度
- 空间复杂度:O(range)
- 时间复杂度:O(N + range)
性能验证
10 万数据 0 ms,在适用场景下堪称恐怖,但适用范围有限。
九、完整测试代码
c
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <string.h>
int main()
{
srand((unsigned int)time(NULL));
const int N = 100000;
int* a1 = (int*)malloc(sizeof(int) * N);
int* a2 = (int*)malloc(sizeof(int) * N);
int* a3 = (int*)malloc(sizeof(int) * N);
int* a4 = (int*)malloc(sizeof(int) * N);
int* a5 = (int*)malloc(sizeof(int) * N);
int* a6 = (int*)malloc(sizeof(int) * N);
int* a7 = (int*)malloc(sizeof(int) * N);
for (int i = 0; i < N; ++i)
{
a1[i] = rand() + i;
a2[i] = a1[i];
a3[i] = a1[i];
a4[i] = a1[i];
a5[i] = a1[i];
a6[i] = a1[i];
a7[i] = a1[i];
}
int begin7 = clock(); MergeSort(a7, N); int end7 = clock();
int begin6 = clock(); QuickSortNonR(a6, 0, N - 1); int end6 = clock();
int begin5 = clock(); shellsort(a5, N); int end5 = clock();
int begin4 = clock(); Heappai(a4, N); int end4 = clock();
int begin3 = clock(); maopao(a3, N); int end3 = clock();
int begin2 = clock(); qsort(a2, N, sizeof(int), paixu); int end2 = clock();
int begin1 = clock(); Quicksort2(a1, 0, N - 1); int end1 = clock();
printf("排序 %d 个随机数,各算法用时(毫秒):\n", N);
printf("MergeSort: %d\n", end7 - begin7);
printf("QuickSortNonR: %d\n", end6 - begin6);
printf("shellsort: %d\n", end5 - begin5);
printf("Heapsort: %d\n", end4 - begin4);
printf("bubblesort: %d\n", end3 - begin3);
printf("qsort: %d\n", end2 - begin2);
printf("Quicksort2: %d\n", end1 - begin1);
free(a1); free(a2); free(a3); free(a4); free(a5); free(a6); free(a7);
return 0;
}测试结果
排序 100000 个随机数,各算法用时(毫秒):
MergeSort: 4
QuickSortNonR: 4
shellsort: 6
Heapsort: 6
bubblesort: 3000+
qsort: 8
Quicksort2: 4十、排序稳定性详解
什么是稳定性?
稳定性 是指:待排序序列中存在值相等的元素 ,排序后这些相等元素的相对前后顺序保持不变 ,则称该排序算法是稳定 的;否则称为不稳定的。
举例说明
有一个数组,每个元素不仅有值,还有原始下标(用于区分相同值):
初始状态: [5a, 3, 5b, 1, 3]
a在b前,都是5排升序后:
- 稳定排序结果 :
[1, 3a, 3, 5a, 5b]→ 两个3的相对顺序没变,两个5的相对顺序也没变 - 不稳定排序结果 :
[1, 3, 3, 5b, 5a]→ 两个5的相对顺序被颠倒
为什么有的稳定,有的不稳定?
稳定排序 :只在必须交换时才交换 ,相同值之间靠比较判断 (> / <),相等时保持原位置不动。
| 排序 | 稳定原因 |
|---|---|
| 冒泡排序 | if(arr[j] > arr[j+1]) 用 > 而非 ≥,相等时不交换 ✅ |
| 直接插入排序 | 从后往前找,遇到 a[end] > tep 才挪,等于时 break,相同值保持原有顺序 ✅ |
| 归并排序 | 合并时 a[begin1] <= a[begin2],用 <= 保证相等时左区间优先 ✅ |
| 计数排序 | 用下标映射,下标天然有序,相同值不会被调换位置 ✅ |
不稳定排序 :排序过程中,相同值的元素可能被交换到另一个相同值的前面或后面,破坏了原始相对顺序。
| 排序 | 不稳定原因 |
|---|---|
| 直接选择排序 | 每次同时交换 min 和 max 到两端,相同值的两个元素可能被换位 ✗ |
| 希尔排序 | gap > 1 预排序阶段,跨组比较时相同值可能产生相对位移 ✗ |
| 堆排序 | 建堆和调整过程中,堆顶与末尾交换时,相同值可能被打乱 ✗ |
| 快速排序 | hoare/挖坑法中,right 找小 left 找大交换,相同值可能在两区间之间被换位 ✗ |
稳定性的意义
如果排序对象是多字段结构体(比如先按成绩排序,相同成绩时保持姓名先后顺序),稳定性就有重要价值。
简单说:稳定排序保护"相等"元素的相对位置,不稳定排序不保证这一点。
十一、排序总结
| 排序名称 | 最好时间 | 平均时间 | 最坏时间 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|---|
| 冒泡排序 | O(N) | O(N²) | O(N²) | O(1) | ✅ 稳定 |
| 堆排序 | O(N log N) | O(N log N) | O(N log N) | O(1) | ❌ 不稳定 |
| 直接插入排序 | O(N) | O(N²) | O(N²) | O(1) | ✅ 稳定 |
| 希尔排序 | O(N log N) | O(N^1.3) | O(N²) | O(1) | ❌ 不稳定 |
| 直接选择排序 | O(N²) | O(N²) | O(N²) | O(1) | ❌ 不稳定 |
| 快速排序 | O(N log N) | O(N log N) | O(N²) | O(log N) | ❌ 不稳定 |
| 归并排序 | O(N log N) | O(N log N) | O(N log N) | O(N) | ✅ 稳定 |
| 计数排序 | O(N + range) | O(N + range) | O(N + range) | O(range) | ✅ 稳定 |
十二、内部排序与外部排序
前面讲的八大排序算法,全部属于内部排序,因为它们假设数据在内存中,可以随机访问。但实际工程中,数据量往往远大于内存容量,这就需要外部排序。
什么是内部排序?什么是外部排序?
| 类型 | 定义 | 适用场景 |
|---|---|---|
| 内部排序(内排) | 数据全部加载到内存中,可以随机访问任意元素 | 数据量小,能完整装进内存 |
| 外部排序(外排) | 数据太大无法一次性装进内存,需要分块读写磁盘/文件 | 超大文件、百万/千万级数据量 |
什么时候用外排?
当数据量达到内存装不下的程度时,就必须用外排:
- 排序 10 亿个整数(~40GB),机器只有 16GB 内存
- 排序一个 100GB 的日志文件
- 数据库对超大型表进行排序输出
外排的核心思想:分而治之 + 多路归并
外排分为两个阶段:
阶段一:分段内排
原始大文件(太大,无法一次读入内存)
↓
每次读一块数据进内存(比如 1GB)
↓
用内排算法(快排/归并排)排好这一块
↓
写回磁盘,得到若干有序的小文件(称为"归并段")阶段二:多路归并
多个有序小文件
↓
每次从各文件读一个数(或一小批),选最小/最大的输出
↓
继续读、继续选,直到所有文件处理完毕
↓
最终得到完全有序的大文件图解过程
假设内存每次最多容纳 3 个整数,待排序数据为 [8, 3, 9, 2, 7, 1, 5, 4, 6]:
【阶段一:分段内排】
内存每次最多3个数,分3次读入:
读入 [8, 3, 9] → 内排 → [3, 8, 9] → 写回 temp1
读入 [2, 7, 1] → 内排 → [1, 2, 7] → 写回 temp2
读入 [5, 4, 6] → 内排 → [4, 5, 6] → 写回 temp3
得到三个有序文件:temp1=[3,8,9] temp2=[1,2,7] temp3=[4,5,6]
【阶段二:多路归并】
三路归并:每次从 temp1/temp2/temp3 各读一个数出来比较
第一轮:
比较 3(t1)、1(t2)、4(t3) → 选 1 → 输出 [1],从 temp2 补一个数
比较 3(t1)、2(t2)、4(t3) → 选 2 → 输出 [1,2],从 temp2 补一个数
比较 3(t1)、7(t2)、4(t3) → 选 3 → 输出 [1,2,3],从 temp1 补一个数
比较 8(t1)、7(t2)、4(t3) → 选 4 → 输出 [1,2,3,4],从 temp3 补一个数
比较 8(t1)、7(t2)、5(t3) → 选 5 → 输出 [1,2,3,4,5],从 temp3 补一个数
比较 8(t1)、7(t2)、6(t3) → 选 6 → 输出 [1,2,3,4,5,6],从 temp3 补一个数
...继续,最终输出 [1,2,3,4,5,6,7,8,9]关键点:多路归并的效率
多路归并的复杂度为 O(N logK),其中:
- N 为总数据量
- K 为归并路数(文件数量)
路数 K 越大,层数越少,读写磁盘次数越少。理想情况下 K 越大越好,但受限于内存中同时打开的文件描述符数量。
实际优化手段:
- 增加归并路数(K 从 2 增大到 8、16......)
- 败者树/胜者树:减少比较次数
- 置换-选择排序:生成长度更大的有序归并段,减少归并段数量
内排 vs 外排的选择
| 数据量 | 内存够用? | 推荐方案 |
|---|---|---|
| 几千~几万 | ✅ | 直接内排,快排/归并排随便选 |
| 几十万~几百万 | ✅ | 内排,可用优化快排或归并排 |
| 数千万~数亿 | ❌ | 外排,分块内排 + 多路归并 |
| TB 级数据 | ❌ | 外排 + 加大归并路数/多线程/分布式 |
一句话总结
- 内排:数据装得下内存,所有元素随意访问,快排/归并排/堆排随便用
- 外排 :数据太大装不下,分块读进内存排好序,再通过归并思想把各有序块合并成整体有序
这里举一个例子说一下
假如我们有10亿个整数,那他就要10亿乘以4个比特位,而内存就只有1G,这里我们见一下换算单位
1G=1024MB
1MB=1024KB
1KB=1024byte
所以1G大约等于10的9次方byte也就是1亿
所以这时候我们用内存,直接直接排序根本排不了,这时候我们就要使用外排序了。
这里我们可以先把4G的大文件存在磁盘里面,在分别取1G存进内存里面进行排序,内存里面现在也不能用归并排序,因为他还要开辟一个O(N)的空间,所以我们就用快排,排内存的,然后依次排4个文件,在内存里面排好了再取出来,进行归并排序,下面我用一个图来说一下。
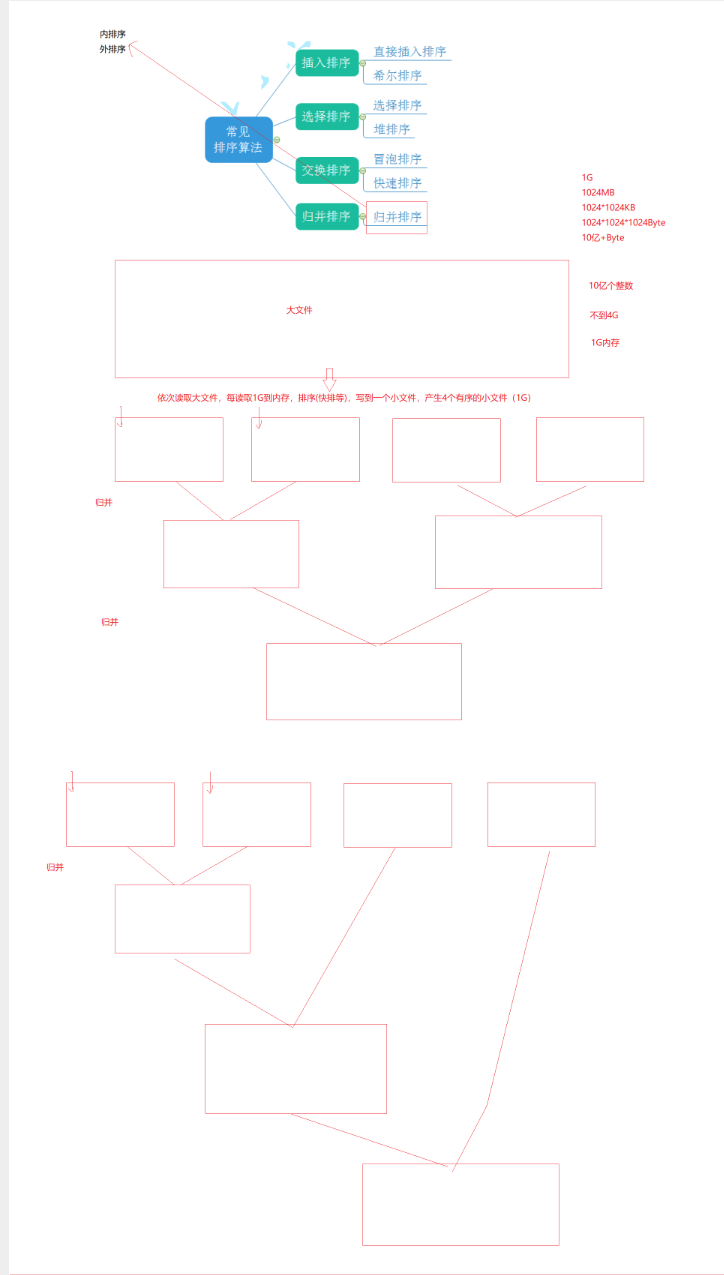
结语
以上就是我们完整实现和分析的八大排序算法。感谢大家的支持!