
大家好,我是铭毅天下。Elasticsearch 我们聊了近10年,从 1.x 一路用到 8.x,深知它在"近实时、refresh_interval、segment merge、bulk update、shard 数量规划"上的种种工程取舍与历史包袱。
今天要给大家介绍的,是一款由国内团队 INFINI Labs 主导、用 Rust 完整重写、定位"Next-Gen Real-Time Search & AI-Native Innovation Engine"的产品 ------ INFINI Pizza(官网:pizza.rs)。
本文从产品定位、设计哲学、核心概念、分布式架构、实时机制、WASM 生态、典型场景到与 Elasticsearch 的对照,做一次全方位、成体系的拆解。
一、Pizza 是什么:一句话定位
INFINI Pizza is a distributed hybrid search database system,使命是基于现代硬件与 AI 能力,为企业提供真正的实时智能搜索。
如果用一句话概括 Pizza,它是:
一个用 Rust 编写、面向可变数据(mutable data)、原生支持原地局部更新(in-place partial update)、采用 share-nothing + io_uring 架构、面向 PB 级规模、对 LLM/ML 原生友好的分布式实时搜索引擎。
它的代号叫 FIRE(Fast Indexing and Retrieval Engine),是 INFINI Labs 开源生态中的核心引擎层,与 Coco AI(企业级 AI 统一搜索)、Gateway、Console 等共同构成完整产品矩阵。INFINI Labs GitHub
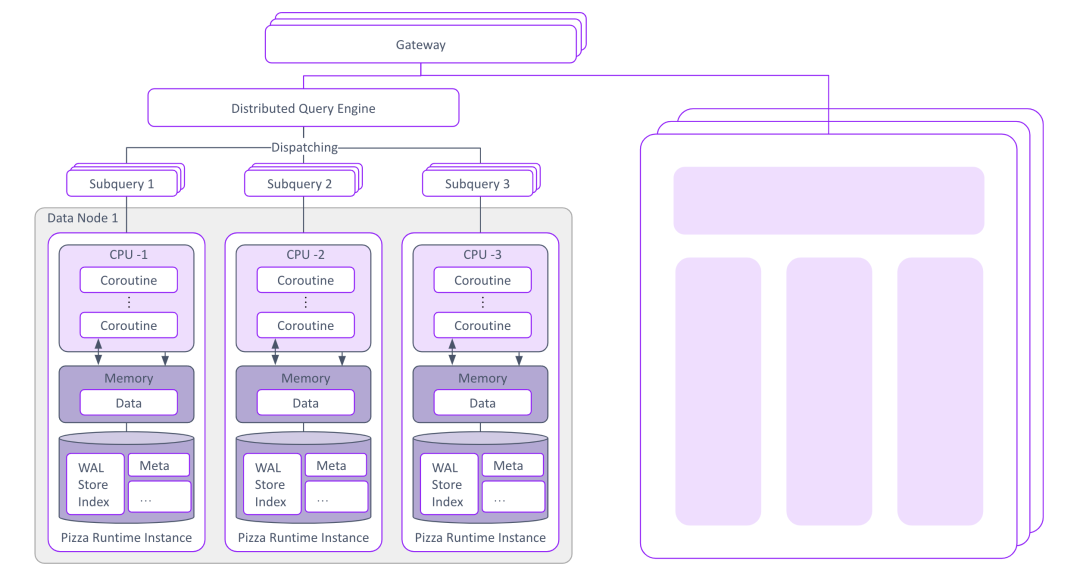 Pizza 架构示意
Pizza 架构示意
二、为什么要做 Pizza:动机与设计哲学
Elasticsearch 这一代搜索引擎诞生在十多年前,其底层 Lucene 的 segment 不可变模型、refresh_interval 的"近实时"折中、bulk update 必须 fetch-modify-reindex 整个文档、分片数一旦确定就无法动态调整等问题,长期被工程师反复诟病。
Pizza 官方文档对自己的目标场景给出了非常清晰的"应用边界",这其实就是 Pizza 的设计动机:
https://pizza.rs/docs/overview/
-
对毫秒级延迟敏感的搜索应用;
-
数据是可变的(mutable),需要新鲜数据 + 快速查询;
-
需要承载高并发 + 复杂查询;
-
数据规模超过 PB,且面向用户侧(user-facing)使用;
-
需要处理JOIN 等复杂数据关系;
-
文档拥有数千个字段,但只有少量字段需要频繁变更;
-
需要统一处理结构化与非结构化数据。
围绕这些场景,Pizza 给出了与传统搜索引擎截然不同的设计哲学:
-
Indices should be designed per use case:
不要试图用一个 index 覆盖全部场景,而是引入 Views,允许将不同文档源组合为一个索引,或将一个文档切分为多层索引服务于不同用例。
-
Storage / Computation Separation:
存储与计算分离。
-
Storage / Index Separation:
存储与索引分离 ------ 这是 Pizza 区别于 Lucene 系最关键的一处。
-
Native LLM / ML Integration:
将 LLM 与 ML 能力原生嵌入到搜索与数据检索 pipeline 中。
-
Modern Hardware First:
面向多核、大内存、NVMe SSD、io_uring 等现代硬件特性进行底层重构。
可以这样理解:Elasticsearch 是把 Lucene 做成分布式,Pizza 则是从零设计一个分布式优先、AI 优先、Rust 优先的搜索数据库。
三、核心概念体系:从 Cluster 到 Field 的层级模型
Pizza 的数据组织模型非常体系化,这一点对从 Elasticsearch 迁移过来的同学非常友好,但又有自己的独到设计。
来自官方 Concepts 文档:
https://pizza.rs/docs/overview/concept/
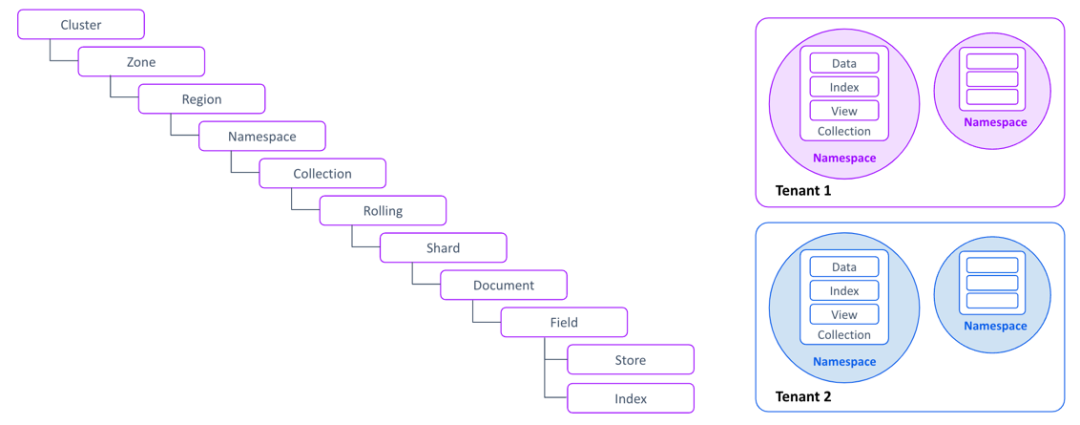 Pizza Concepts
Pizza Concepts
我把它整理成一张层级关系表:
| 层级 | 概念 | 作用 | 类比 Elasticsearch |
|---|---|---|---|
| 物理层 | Cluster | 一组互联节点构成 Pizza 集群 | Cluster |
| 物理层 | Zone | 节点的逻辑分组,按地理或网络拓扑划分 | Rack / Zone awareness |
| 物理层 | Region | Zone 下的更细分区域,优化访问延迟 | (无直接对应) |
| 逻辑层 | Namespace | 多租户隔离的逻辑容器,承载 Collection | (无直接对应,可类比 SaaS 租户) |
| 逻辑层 | Collection | 具备相似属性文档的集合,存储与检索的主单元 | Index |
| 数据层 | Rolling | Collection 的纵向分区 ,单 rolling 上限 42 亿(uint32) 文档,写满自动滚到下一 rolling | Rollover Index |
| 数据层 | Partition | 单个 rolling 的横向逻辑切分 ,固定 256 个/rolling,按需动态映射到 Shard | (类似 virtual shard / bucket) |
| 数据层 | Shard | Partition 的物理容器,可拆可合 | Shard |
| 文档层 | Document | 索引的基本数据单元 | Document |
| 文档层 | Field | 文档的属性字段 | Field |
| 存储层 | Store | 主存储(forward records),默认基于 Parquet | _source |
| 存储层 | Index | 加速检索的倒排/向量等数据结构 | Inverted Index |
这里有几个非常关键的设计要点值得展开:
① Rolling 的引入彻底解决了"分片数一旦确定就难以调整"的痛点。
一个 Collection 可以从 0 增长到 PB 级,无需提前规划分片数;每个 rolling 内部固定 256 partition,写满之后自动滚到新的 rolling,而新 rolling 又可以采用不同的 shard 配置。这相当于把 Elasticsearch 中需要业务方自己手工做的 ILM + rollover + reindex,下沉到引擎自身。
② 256 partition 是固定的、shard 是动态的。
Partition 到 Shard 是一个多对一的动态映射,支持 Hash 与 Range 两种策略 :
https://pizza.rs/docs/references/collection/create/
go
// Hash 策略:shard_index = hash(partition_id) mod number_of_shards
"hash": { "number_of_shards": 8 }
// Range 策略:按区间将 partition 显式分配给 shard
"range": ["0..128, 129..255"]这样设计的最大好处是:业务方眼里"分片"是一个稳定的逻辑概念,运维侧可以随时通过 partition→shard 的重映射做 scale-out / merge,业务无感知。
这正是官网首页强调的 "from zero to petabytes, without the need to worry about sharding or reindexing" 的工程基础。https://pizza.rs/
③ Store 默认采用 Parquet。
文档持久化为对象存储中的 Parquet 文件 ------ 这一点意义重大,它直接打通了 Pizza 与现代数据湖(Iceberg、Delta、Hive、Spark、Trino、DuckDB......)的生态。"Native integration with other big data systems through object storage and the standard Parquet format" 不再是一句口号。
https://pizza.rs/docs/overview/
四、分布式架构:Share-Nothing + 异步 I/O 的底层革新
如果说概念模型是 Pizza 的"骨架",那么 share-nothing 架构就是它的"血液循环系统"。来自官方 Architecture 文档:
https://pizza.rs/docs/overview/architecture/
Pizza is built upon a robust share-nothing architecture, ensuring complete isolation of resources at both the node and per-CPU level.
4.1 Per-CPU 级别的资源隔离
传统 Elasticsearch / Lucene 是典型的 share-everything:
所有线程共享 heap,依赖 JVM GC,依赖 OS page cache,靠锁与原子变量协调并发。在 64 核乃至 256 核的现代服务器上,这种模型会遭遇严重的 cache coherence、false sharing、锁竞争问题。
Pizza 反其道而行:每个 CPU 核心拥有独立线程,互不共享内存与资源。这带来四重收益:
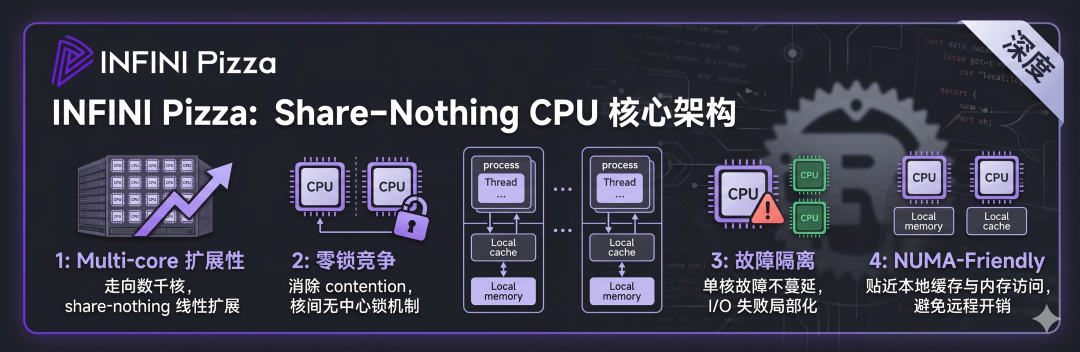
-
Multi-core 扩展性:
当机器走向上千核,share-nothing 几乎是唯一能线性扩展的选择;
-
零锁竞争:
核之间无需中心化锁机制,消除 contention;
-
故障隔离:
单核单线程的故障不会蔓延,I/O 失败也被局部化;
-
NUMA-Friendly
贴近本地内存、本地缓存访问,避免跨 NUMA node 的远程内存访问开销。
4.2 io_uring 驱动的全异步 I/O
Pizza 在 I/O 层全面采用 Linux 内核的 io_uring,替代传统的同步 / epoll 模型:
-
系统调用开销下降;
-
缓冲区管理更高效;
-
在 I/O 密集型场景下吞吐量与延迟同步改善;
-
与 share-nothing 模型天然契合 ------ 每个核独立提交 / 收割 I/O 完成事件,零跨核协调。
share-nothing + io_uring + Rust 零成本抽象,构成了 Pizza 性能宣传的底层基础设施。
五、True Real-Time:彻底告别 refresh_interval
这是 Pizza 最具差异化的卖点之一。
在 Elasticsearch 中,新写入的文档默认要等到 refresh_interval(默认 1s)触发,才能被搜索到。
在高写入场景下,这个"近实时"既是优势也是约束 ------ 调小会引发 segment 爆炸与 merge 压力,调大则牺牲数据新鲜度。
而 Pizza 的官网与文档明确给出了"True Real-Time"的承诺:Pizza Docs
Instantly see results as soon as data is inserted, no index refresh needed. Our system updates seamlessly in the background, providing immediate feedback and delivering the fastest search experience possible. pizza.rs
Pizza 实时机制示意
它通过两条路径协同实现:
-
写入即可见:
文档插入完成后无需等待 refresh,立即对查询可见,索引构建在后台完成;
-
In-place Partial Update:
对字段做局部更新,无需像 Elasticsearch 那样 fetch 全文档 → 修改 → 重新索引整篇文档。
5.1 Partial Update 的工程价值
来自 Partial Update 文档 的示例:
go
PUT /my-collection/_doc/news_001/_update
{
"sync": {
"replace": {
"org": { "id": "infinilabs" }
}
}
}支持的操作类型:add、replace、remove、array_append。
更精彩的是它同时支持 sync / async 两种模式:
-
sync:实时更新,立即可查询;
-
async:请求落 WAL 即返回,后台异步消费 ------ 适合写多查少、追求极致写入吞吐的场景。
这种设计直接对标了 Elasticsearch update API 一直以来的痛点:一个 1000 字段的文档,只想改一个字段的值,却必须把整篇拉出来、改完、再整篇写回,IO 放大严重。Pizza 把它做成了"真正的就地更新"。
六、统一搜索:从全文到向量再到多模态
Pizza 把自己定位为 Hybrid Search Database,宣称"advanced search for all data types, integrating numbers, geopoints, vectors, text, images, videos, and insights"。pizza.rs
这意味着在一个 Collection 内,可以同时承载:
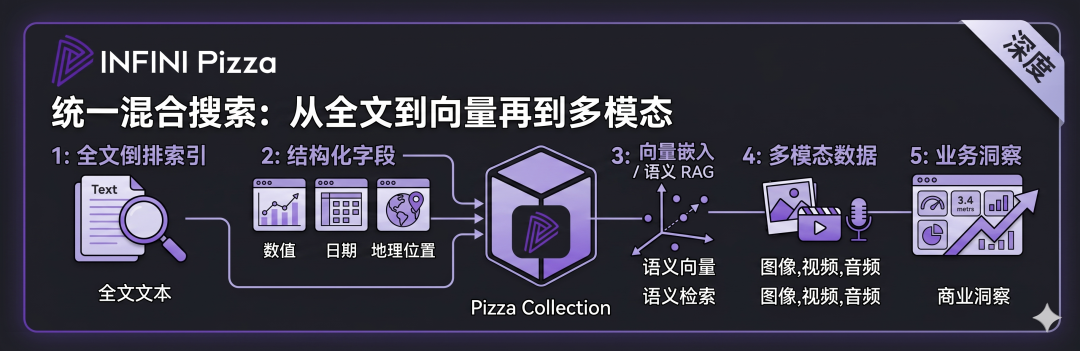
-
结构化字段(数值、日期、地理位置);
-
全文倒排索引;
-
向量(用于语义检索 / RAG);
-
图像、视频等多模态数据;
-
业务洞察(insights)。
配合"Native integration with LLMs and ML",Pizza 的目标其实是成为 AI-Native 时代的搜索数据底座 ------ 它不仅是检索器,更是 RAG / Agent 应用的数据中枢。
这与同集团的 Coco AI 形成上层应用 + 底层引擎的闭环。
七、Pizza 开源生态:四件套全景
Pizza 不是单一产品,而是一个生态。来自官网 pizza.rs 与 INFINI Labs GitHub:
| 项目 | License | 定位 | 适用场景 |
|---|---|---|---|
| Pizza Engine(FIRE) | MIT | Rust 实时搜索引擎核心库 | 嵌入式 / 自研集成 |
| Pizza Server | AGPL-v3 | 分布式版 Pizza,多节点高可用 | 生产环境数据底座 |
| Pizza WASM | MIT | WebAssembly 封装,浏览器内运行 | 静态站搜索、隐私场景 |
| Pizza Searchbox | MIT | 配套搜索 UI 组件 | 一行代码集成搜索框 |
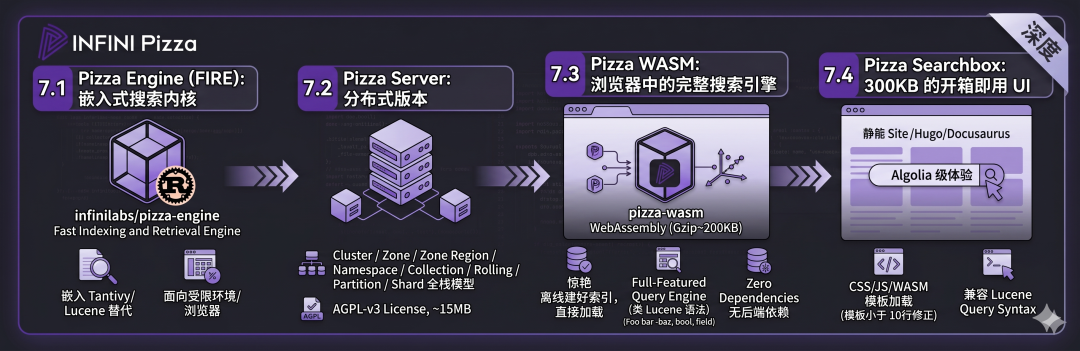
7.1 Pizza Engine(FIRE):嵌入式搜索内核
Pizza engine, code name FIRE (Fast Indexing and Retrieval Engine), is a fully functional real-time search engine library developed in Rust. pizza.rs
定位类似 Tantivy / Lucene 之于 Elasticsearch,是一个**可独立嵌入的、设计面向受限环境(包括浏览器)**的高性能搜索库。代码托管在 infinilabs/pizza-engine。
7.2 Pizza Server:分布式版本
承载前面讲到的 Cluster / Zone / Region / Namespace / Collection / Rolling / Partition / Shard 全栈数据模型,License 为 AGPL-v3,约 15MB 体量。INFINI Labs GitHub
7.3 Pizza WASM:浏览器中的完整搜索引擎
这是我个人觉得最"惊艳"的工程产物。来自 pizza-wasm GitHub:
INFINI Pizza for WebAssembly is a fully functional search engine that can run entirely in your browser with zero dependencies.
特性概览:
-
Full-Featured Query Engine:
在浏览器里跑完整查询引擎,支持类 Lucene 语法(
foo bar -baz "qux"、布尔表达式、字段限定); -
Offline Indexing:
离线建好索引,浏览器直接加载使用;
-
Zero Dependencies:
不依赖任何后端服务;
-
极致轻量:
WASM 包约 500KB ,Gzip 压缩后仅 ~200KB。medcl 教程
这意味着:Hugo / Docusaurus / VitePress 等静态站点,现在可以用一个 200KB 的资源,获得 Lucene 语法级别的全文搜索体验,且完全离线、无后端、零成本。
7.4 Pizza Searchbox:300KB 的开箱即用 UI
pizza-searchbox fork 自 meilisearch-docsearch,灵感来自 algolia/docsearch:
-
Gzip 后约 300KB;
-
完全兼容 Lucene Query Syntax;
-
与 Pizza WASM 无缝协作。
集成示例(Hugo 站点)的核心流程非常清爽:
-
Hugo 配置启用
index.json输出; -
在主题 head 模板加载 Searchbox CSS;
-
在 footer 模板加载 Searchbox JS + WASM;
-
在合适位置插入
<DocSearch />标签即可。
整套流程不到 10 行模板修改,就能为静态博客加上"Algolia 级别"的搜索体验,且不需要把内容上传到任何第三方服务,完美符合数据主权与隐私合规的诉求。
八、技术亮点小结:Pizza 的"七张牌"
为了便于记忆,我把 Pizza 的核心技术亮点归纳为七条:
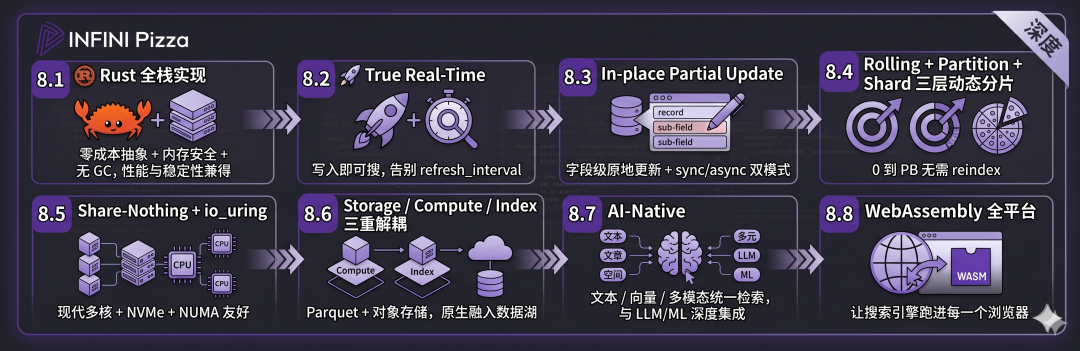
-
🦀 Rust 全栈实现
------ 零成本抽象 + 内存安全 + 无 GC,性能与稳定性兼得;
-
🚀 True Real-Time
------ 写入即可搜,告别 refresh_interval;
-
✏️ In-place Partial Update
------ 字段级原地更新 + sync/async 双模式;
-
🍕 Rolling + Partition + Shard 三层动态分片
------ 0 到 PB 无需 reindex;
-
🏗️ Share-Nothing + io_uring
------ 现代多核 + NVMe + NUMA 友好;
-
📦 Storage / Compute / Index 三重解耦
------ Parquet + 对象存储,原生融入数据湖;
-
🧠 AI-Native
------ 文本 / 向量 / 多模态统一检索,与 LLM/ML 深度集成;
附赠第八张牌:🌐 WebAssembly 全平台,让搜索引擎跑进每一个浏览器。
九、Pizza vs Elasticsearch:一张对照表
作为长期玩 Elasticsearch 的人,我整理了一张主观对比表,仅供大家在技术选型时参考:
| 维度 | Elasticsearch / OpenSearch | INFINI Pizza |
|---|---|---|
| 实现语言 | Java / JVM | Rust(无 GC) |
| 实时性 | Near Real-Time,依赖 refresh_interval |
True Real-Time ,写入即可见 |
| 文档更新 | Fetch-Modify-Reindex 整文档 | In-place Partial Update (支持 sync/async) |
| 分片模型 | 创建时固定(reindex 才能变更) | Rolling + 256 Partition + 动态 Shard 映射 |
| 扩缩容 | 需 reindex / shrink / split | partition→shard 动态重映射 ,业务无感 |
| 存储格式 | Lucene 私有 segment | Parquet + 对象存储,数据湖原生互通 |
| 架构 | Share-everything + JVM 线程池 | Share-nothing + io_uring + per-CPU 隔离 |
| AI / 向量 | 8.x 起支持 dense_vector / kNN | AI-Native ,文本/向量/多模态统一设计 |
| WASM / 嵌入 | 不支持 | Pizza WASM ,200KB Gzip 浏览器内运行 |
| 适用规模 | TB ~ 数十 TB(常见) | PB 级 user-facing |
| 成熟度 | 工业级,生态完备 | 起步阶段,快速演进中 |
需要特别强调的是最后一行:Elasticsearch 是过去十年的事实标准,Pizza 是面向下一个十年的探索。
现在选型不是替换,而是评估 ------ 一旦你的业务命中 Pizza 官方列出的那七种场景(毫秒延迟、PB 级、可变数据、复杂 JOIN、高并发、千字段少变更、结构化+非结构化统一),Pizza 就值得放进你的雷达图。
十、典型应用场景:什么时候该选 Pizza?
结合官方 "When to use Pizza" 与我自己的工程经验,我把适用场景归纳为四类:
1. 用户面(User-Facing)的大规模实时搜索
电商商品搜索、订单实时检索、社交动态时间线 ------ 写入必须立即可查,且要扛住瞬时高并发。
2. 频繁局部更新的业务实体
广告库存、CRM、订单状态机、IoT 设备影子 ------ 千字段的实体只有 status / count / score 等少数字段在反复变化。
3. 数据湖一体化检索
已有 Parquet 数据沉淀在 S3 / OSS / MinIO 中,希望直接索引、不二次搬运 ------ Pizza 的 Parquet 原生 store 几乎是为此而生。
4. AI-Native 应用底座
RAG / Agent / 企业搜索(配合 Coco AI),需要在一个引擎内同时承载关键词检索、向量检索、过滤、聚合,避免"ES + 向量库"双系统的运维负担。
5. 静态站点 / 隐私敏感场景
不想买 Algolia、不想搭后端、又对数据隐私敏感 ------ Pizza WASM + Searchbox 是当下最优雅的方案之一。
十一、写在最后:值得长期关注的 Rust 系搜索新势力
INFINI Labs 这家公司,在中文搜索社区里其实是一个"老熟人" ------ 其 Gateway、Console、Easysearch 已经在很多企业的 Elasticsearch 治理栈中默默服役多年。这次他们把对搜索的所有理解,浓缩进 Pizza 这个全新的 Rust 项目里,并且选择了真正的开源(核心引擎 MIT、服务端 AGPL-v3),生态全部托管在 GitHub @infinilabs。
从我的角度看,Pizza 的技术叙事有三个"对的方向":
-
方向对
Rust + share-nothing + io_uring + 存算分离 + Parquet + AI-Native,每一条都踩在 2024-2026 数据基础设施演进的主航道上;
-
抽象对:
Rolling / Partition / Shard 的三层分片抽象,是对 Elasticsearch 八年实战痛点的正面回应;
-
生态对:
从嵌入式 Engine、到分布式 Server、到 WASM、到 Searchbox UI、再到上层 Coco AI 应用,纵深完整,不是孤立的"轮子"。
当然 Pizza 仍处于早期阶段,社区规模、生态插件、可观测性工具链、和 Elasticsearch 生态的兼容层都还在建设中。但这正是一个值得长期跟踪、深入参与、积累认知红利的窗口期。
Easysearch------Elasticsearch 国产化替代方案!
Elasticsearch 国产化替代 ------信创政策到技术选型的全面指南调研报告 V1.0
EasySearch 最常见问题答疑------国产化搜索引擎实战指南