零、论文相关信息
- TGC-Net --- 2026_Information Fusion 方向期刊论文
- 全名 :TGC-Net: A Structure-Aware and Semantically-Aligned Framework for Text-Guided Medical Image Segmentation
- 类型:文本引导医学图像分割,非 SAM
- 是否冻结 CLIP:是,论文写明 CLIP image encoder 和 CLIP text encoder 在训练中都保持冻结。
- 核心功能:用医学报告/文本提示辅助病灶或器官分割,重点解决 CLIP 在医学分割中的结构细节不足和语义错配问题。
- 模型怎么改 CLIP:
- TGC-Net 很适合你说的"冻结 CLIP 但改进 CLIP"的思路。它认为原始 CLIP 直接做医学分割有三个 gap:
- Structural gap:CLIP ViT 语义强,但边界、病灶细节弱。
- Semantic gap:CLIP 文本端不理解复杂医学描述。
- Calibration gap:自然图像上的图文对齐迁移到医学域会错位。
- 对应提出三个模块:
- TGC-Net 很适合你说的"冻结 CLIP 但改进 CLIP"的思路。它认为原始 CLIP 直接做医学分割有三个 gap:
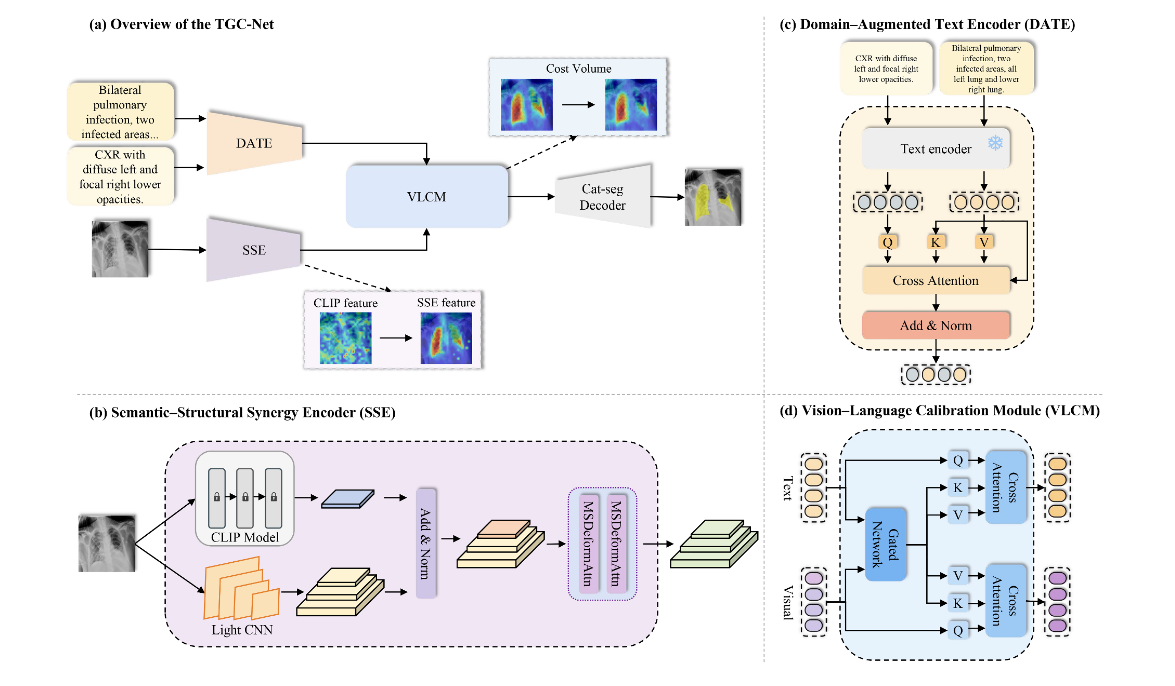
| 模块 | 作用 |
|---|---|
| SSE: Semantic--Structural Synergy Encoder | 在冻结 CLIP ViT 旁边加 CNN 分支,补充多尺度局部结构和边界信息。 |
| DATE: Domain-Augmented Text Encoder | 用 LLM 生成/注入医学知识,增强文本 embedding 的医学语义。 |
| VLCM: Vision--Language Calibration Module | 重新校准图像 patch 与文本 token 的对应关系。 |
论文明确写到,CLIP ViT 分支参数保持冻结,同时并行 CNN 分支提取细粒度结构;训练时 CLIP 图像和文本编码器都冻结,只训练轻量模块和 decoder。
- 功能总结:
TGC-Net 的功能不是"让 CLIP 分类更强",而是把 CLIP 的全局语义能力变成可用于像素级分割的医学语义结构特征。它更像是:
frozen CLIP semantic prior + CNN structural prior + medical text calibration。
- 适合借鉴的点:
- frozen CLIP ViT + CNN local branch;
- 在 skip connection 或 decoder 里引入 CLIP semantic prior;
- 用 LLM/医学知识增强 text prompt;
- 加轻量 vision-language calibration module。
一、Abstract
这篇论文的核心问题是:CLIP 虽然已经具备图文对齐能力,但直接迁移到医学图像分割任务中效果不好 。原因主要有三个:结构信息不够细、医学文本理解不充分、医学领域图文对齐不准确。
作者提出 TGC-Net 来解决这三个问题。它是一个基于 CLIP 的轻量化文本引导医学图像分割框架,冻结 CLIP 主干,只训练少量任务相关模块,从而实现参数高效适配。
TGC-Net 包含三个核心模块:
| 模块 | 解决的问题 | 作用 |
|---|---|---|
| SSE | Structural Gap | 增强多尺度结构信息,让模型更好保留病灶边界和解剖细节 |
| DATE | Semantic Gap | 处理复杂临床文本,使文本表示更适合 CLIP 理解 |
| VLCM | Alignment Gap | 校准医学图像特征和文本特征之间的对齐关系 |
这段摘要的逻辑可以概括为:
bash
临床报告有语义价值
→ 现有方法需要复杂图文交互模块
→ CLIP 有天然图文对齐空间
→ 但 CLIP 直接用于医学分割存在三个 gap
→ 提出 TGC-Net,用三个轻量模块分别解决
→ 在 7 个数据集、4 种医学模态上达到 SOTA实验上,TGC-Net 在胸部 X-ray、CT、皮肤镜和 MRI 等多种模态上都取得了最先进性能,并且只使用 10.3M 任务特定可训练参数。这说明作者想证明的核心观点是:
不需要重新训练庞大的医学视觉语言模型,只要针对 CLIP 的结构、语义和对齐短板进行轻量适配,就可以有效提升文本引导医学图像分割性能。
你记住这部分最关键的一句话就行:
TGC-Net = 基于冻结 CLIP 的三重 gap 适配框架:SSE 让图像看得更细,DATE 让文本读得更懂,VLCM 让图文对得更准。
二、引言
1. 研究背景:医学图像分割很重要,但标注成本高
MIS(医学图像分割),是很多临床任务的基础,例如:
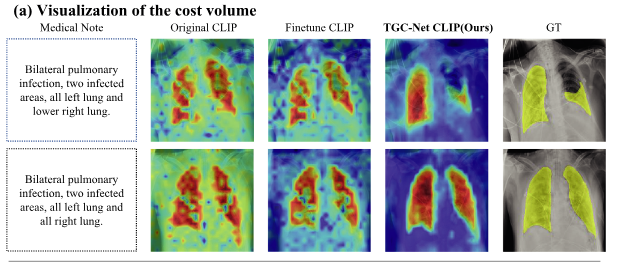
该图对应_文本和图像 patch 之间的相似度响应图------给模型一段医学文本,模型去图像里找"哪些区域和这段文本最相关.
| 列名 | 含义 |
|---|---|
| Original CLIP | 原始冻结 CLIP 的图文相似度图 |
| Finetune CLIP | 直接微调 CLIP 后的相似度图 |
| TGC-Net CLIP(Ours) | 加入 TGC-Net 适配模块后的相似度图 |
| GT | 真实分割标签,黄色区域是真实病灶 |
热力图中:
- 红色/黄色区域表示模型认为"这里和文本最相关";
- 蓝色/绿色区域表示相关性较低。
| 应用场景 | 作用 |
|---|---|
| 计算机辅助诊断 | 帮助医生定位病灶、器官或异常区域 |
| 治疗方案制定 | 辅助放疗、手术规划、病灶范围评估 |
| 临床决策支持 | 为医生提供可量化、可解释的影像分析结果 |
但是传统医学分割方法严重依赖 像素级标注。
问题是:
像素级标注需要专家逐像素勾画
↓
成本高、耗时长
↓
大规模高质量 mask 难以获取所以作者引出一个替代思路:
临床报告本来就存在,而且包含丰富语义信息,可以作为分割任务的补充监督。
2. 为什么使用临床报告?
临床报告中通常包含三类关键信息:
| 信息类型 | 举例 | 对分割的帮助 |
|---|---|---|
| 病灶特征 | infection, opacity, lesion | 告诉模型分割什么 |
| 解剖位置 | left lung, lower right lung | 告诉模型目标在哪里 |
| 疾病背景 | pulmonary infection, tumor | 提供诊断语义上下文 |
因此,文本引导医学图像分割的目标是:
输入:医学图像 + 临床文本
输出:文本描述对应区域的分割 mask它的优势是:
- 利用临床报告减少对纯像素标注的依赖;
- 通过文本语义提升分割准确性;
- 让模型预测结果更具可解释性。
3. 现有文本引导医学分割方法的问题
大多数现有方法采用 dual-encoder paradigm,双编码器范式:
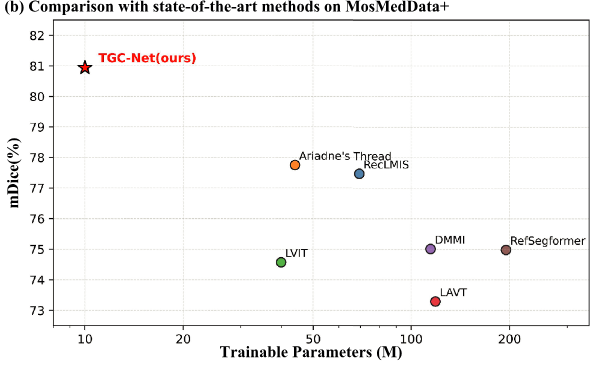
参数量和性能对比图
图像 → visual backbone
文本 → text encoder
然后通过 cross-modal interaction module 进行融合这类方法的问题在于:
| 问题 | 解释 |
|---|---|
| 图像编码器和文本编码器独立训练 | 二者天然不在同一个语义空间 |
| 需要复杂跨模态交互模块 | 需要 cross-attention、多阶段融合、复杂 decoder |
| 参数量大 | 引入大量可训练参数 |
| 医学数据集小 | 复杂模型容易过拟合 |
| 从零学习图文对应关系 | 没有利用预训练图文对齐能力 |
作者认为,这些复杂结构的根本原因是:
现有方法缺乏一个天然对齐的视觉-语言表示空间。
4. 为什么想到 CLIP?
CLIP 的优势是:
CLIP 已经通过大量自然图像-文本对预训练
↓
图像和文本被映射到共享语义空间
↓
天然具备 image-text alignment 能力所以作者提出一个关键问题:
既然 CLIP 已经有图文对齐空间,是否可以不再从零构建复杂多模态交互模块,而是轻量地把 CLIP 适配到医学分割任务?
这就是 TGC-Net 的出发点。
5. CLIP 不能直接用于医学分割的三个原因
虽然 CLIP 有潜力,但作者指出直接迁移并不简单。主要有三个 gap。
5.1 Structural Gap:结构差距
CLIP 的视觉编码器主要适合自然图像的全局语义理解。
它更擅长回答:
这张图像大概是什么?但医学分割需要回答:
病灶具体在哪里?
边界在哪里?
小结构在哪里?所以 CLIP 不擅长保留:
- 病灶边界;
- 小目标区域;
- 器官轮廓;
- 局部纹理;
- 细粒度解剖结构。
这就是 Structural Gap。
5.2 Semantic Gap:语义差距
CLIP 的文本编码器通常在短 caption 上训练,例如:
a photo of a dog
a man riding a bike但医学文本往往是复杂的临床描述,例如:
bilateral pulmonary infection involving the left lung and lower right lung医学文本具有:
- 长句描述;
- 医学术语;
- 解剖位置;
- 病灶属性;
- 隐含医学知识。
CLIP 原始文本编码器不一定能充分理解这种复杂医学文本。
这就是 Semantic Gap。
5.3 Alignment Gap:对齐差距
CLIP 的图文对齐来自自然图像领域,例如:
dog ↔ 狗的图片
car ↔ 汽车图片但医学领域需要的是:
pulmonary infection ↔ 肺部感染区域
hypodense lesion ↔ CT 低密度病灶
skin lesion ↔ 皮肤镜病灶边界自然图像中的图文对齐关系,不能直接迁移到医学图像中。
这就是 Alignment Gap。
6. TGC-Net 的整体解决方案
作者提出 TGC-Net,Tri-Gap Calibration Network,即三重差距校准网络。
核心思想是:
不重新训练一个大型医学视觉语言模型
不从零构建复杂图文交互模块
而是在冻结 CLIP 的基础上
针对三个 gap 设计轻量适配模块TGC-Net 的三个模块分别对应三个问题:
| Gap | 模块 | 作用 |
|---|---|---|
| Structural Gap | SSE | 增强多尺度结构信息,让 CLIP 看得更细 |
| Semantic Gap | DATE | 处理复杂临床文本,让 CLIP 读得更懂 |
| Alignment Gap | VLCM | 校准医学图文特征,让图文对得更准 |
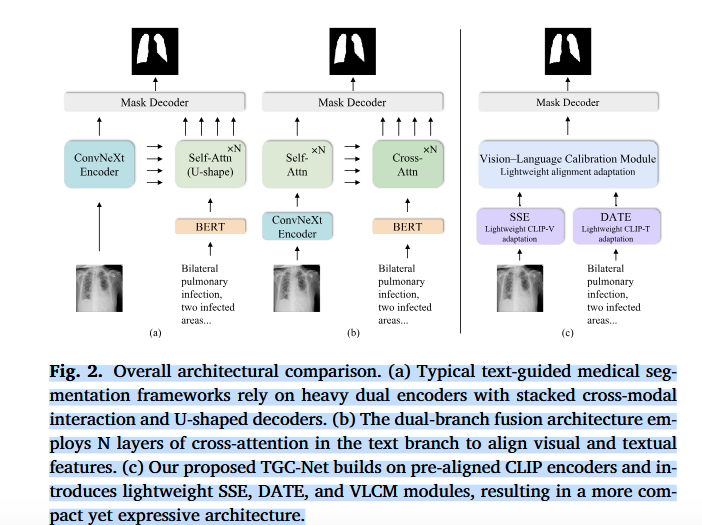
整体架构对比图:
(a) 典型文本引导医学分割框架
(b) 双分支融合架构
(c) TGC-Net 架构
原始 CLIP 有粗略定位能力,但医学分割需要更精细的结构、更准确的医学语义理解和更可靠的图文对齐;TGC-Net 通过 SSE、DATE、VLCM 三个轻量模块,在不大量增加可训练参数的情况下,把 CLIP 适配成更适合医学文本引导分割的模型。
7. 三个模块的作用总结
7.1 SSE:语义-结构协同编码器
全称:Semantic--Structural Synergy Encoder
作用:
用多尺度结构线索增强 CLIP 的视觉表示,使其更适合细粒度医学分割。
它主要解决:
CLIP 视觉特征太粗
↓
边界和局部结构不足
↓
加入结构增强,让分割更精细7.2 DATE:领域增强文本编码器
全称:Domain--Augmented Text Encoder
作用:
借助大语言模型,将复杂临床文本转换成更适合 CLIP 理解的文本表示。
它主要解决:
临床文本复杂、专业、长
↓
CLIP 原始文本编码器难以充分处理
↓
通过领域增强构造 CLIP-compatible text representation7.3 VLCM:视觉-语言校准模块
全称:Vision--Language Calibration Module
作用:
在医学领域中重新校准图像特征和文本特征之间的对应关系。
它主要解决:
CLIP 图文对齐来自自然图像
↓
医学图像和医学文本存在 domain shift
↓
需要重新校准医学域图文对齐8. 作者声称的主要贡献
这部分最后列了四个贡献,可以结构化为:
| 贡献 | 内容 |
|---|---|
| 贡献 1 | 提出 TGC-Net,并把 CLIP 迁移到医学分割定义为 tri-gap adaptation 问题 |
| 贡献 2 | 设计 SSE、DATE、VLCM 组成渐进式适配流程 |
| 贡献 3 | 冻结 CLIP 主干,只训练轻量任务模块,实现参数高效迁移 |
| 贡献 4 | 在 7 个数据集、4 种医学模态上验证有效性、泛化能力和效率 |
特别重要的是第三点:
TGC-Net 只使用 10.3M task-specific trainable parameters,也就是只训练 10.3M 个任务相关参数。
9. 这一节的完整逻辑链
可以用下面这条线串起来:
医学图像分割重要
↓
但像素级标注昂贵
↓
临床报告天然存在,包含语义信息
↓
文本引导医学分割可以利用这些报告
↓
现有方法使用独立图像编码器和文本编码器
↓
因此需要复杂跨模态融合,参数多,容易过拟合
↓
CLIP 已经有预训练图文对齐空间
↓
但直接迁移到医学分割存在三个 gap:
结构 gap、语义 gap、对齐 gap
↓
提出 TGC-Net
↓
SSE 解决结构问题
DATE 解决文本问题
VLCM 解决对齐问题
↓
冻结 CLIP,只训练轻量模块
↓
实现参数高效且性能强的文本引导医学图像分割10. 一句话总结
这一节的核心意思是:
TGC-Net 的动机是:临床报告可以帮助医学分割,CLIP 可以提供预训练图文对齐空间,但 CLIP 直接迁移到医学分割会遇到结构、语义和对齐三个问题,因此作者设计 SSE、DATE、VLCM 三个轻量模块进行针对性适配。
三、相关工作
1. 医学图像分割的发展逻辑
医学图像分割最早主要依赖 CNN ,代表方法是 U-Net 和 nnU-Net。
CNN / U-Net 的优势是
局部细节强
边界恢复好
适合医学图像中的器官、病灶轮廓分割但是 CNN 的问题是:
感受野有限
全局上下文建模能力不足
难以捕捉远距离区域关系所以后来引入 Transformer。
Transformer 的优势是:
全局建模强
长距离依赖关系建模好
语义理解能力强但是 Transformer 的问题是:
局部归纳偏置弱
边界细节和高分辨率结构不如 CNN因此作者总结出一个关键矛盾:
CNN 擅长局部结构,Transformer 擅长全局语义,但医学分割同时需要二者。
这就是本文提出的 Structural Gap,结构差距。
2. Structural Gap 是什么?
Structural Gap 指的是:
CLIP 的视觉编码器通常是 ViT,擅长全局语义表达,但不擅长保留医学分割需要的细粒度结构、边界和局部纹理。
医学分割需要的不只是"这张图里有病灶",还需要知道:
病灶边界在哪里?
器官轮廓在哪里?
小目标区域在哪里?
局部结构是否完整?所以作者提出 SSE 来解决这个问题。
SSE 的核心思想是:
CLIP ViT → 提供全局语义
CNN 分支 → 提供局部结构
二者融合 → 得到结构感知的视觉特征一句话概括:
SSE 是为了解决 CLIP 视觉特征太粗、不够适合精细医学分割的问题。
3. CLIP / VLM 的优势
第二部分讲的是 CLIP 和医学领域适配。
CLIP 这类大规模视觉语言模型通过大量图像-文本对进行预训练,已经学到了一个共享的图文语义空间。
它的优势是:
图像特征和文本特征天然对齐
匹配图文在 embedding space 中距离更近
不需要完全从零开始学习图文对应关系相比 LViT 这类早期方法,CLIP 的优势很明显。
LViT 使用的是:
CNN 图像编码器 + BERT 文本编码器但二者是独立训练的,天然不对齐,所以需要复杂的跨模态融合模块。
CLIP 则不同:
图像编码器和文本编码器已经在预训练阶段对齐所以 CLIP 是文本引导医学图像分割的一个更好起点。
4. 但 CLIP 直接用于医学领域仍然有问题
虽然 CLIP 有图文对齐能力,但它是在自然图像和通用文本上训练的,直接迁移到医学领域会遇到明显的 domain shift,领域偏移。
作者指出两个关键问题。
4.1 Semantic Gap:语义差距
CLIP 的文本训练数据主要是通用 caption,例如:
a dog
a car
a person riding a bike但医学文本包含大量专业术语,例如:
hypoechoic
parenchymal heterogeneity
hypodense lesion
pulmonary infectionCLIP 原始文本编码器不一定能理解这些复杂医学术语和临床表达。
所以 Semantic Gap 指的是:
CLIP 的文本编码能力与复杂医学文本之间存在差距。
对应的解决模块是 DATE。
DATE 的作用是:
把复杂临床文本转换成更适合 CLIP 理解的医学文本表示4.2 Alignment Gap:对齐差距
CLIP 学到的对齐关系来自自然图像,例如:
dog ↔ 狗的图片
car ↔ 汽车图片但医学图像中的对齐关系完全不同,例如:
hypodense lesion ↔ CT 中的低密度病灶
pulmonary infection ↔ 肺部感染区域
skin lesion ↔ 皮肤镜病灶区域所以 Alignment Gap 指的是:
CLIP 在自然图像中学到的图文对齐关系,不能可靠迁移到医学图像和医学文本之间。
对应的解决模块是 VLCM。
VLCM 的作用是:
重新校准医学图像特征和医学文本特征之间的对应关系5. 现有医学 VLM 适配方法的不足
作者提到一些已有方法已经尝试解决部分问题:
| 方法 | 主要解决的问题 | 局限 |
|---|---|---|
| GLoRIA | 用医学图文对做对比学习 | 偏医学图文预训练,不是完整分割适配框架 |
| MedCLIP | 用医学图文对增强 CLIP 医学语义 | 没有系统解决分割结构问题 |
| CAT | 用医学知识增强文本 prompt | 主要解决 Semantic Gap |
| RecLMIS | 用跨模态重建重新建立图文关系 | 主要解决 Alignment Gap |
作者认为这些方法的问题是:
它们通常只解决某一个方面,比如语义或对齐,但没有同时考虑结构、语义和图文对齐三个问题。
所以本文提出 TGC-Net,试图成为一个更系统的解决方案。
6. Related Work 和 TGC-Net 的对应关系
这一节的最终目的,是把已有方法的问题和 TGC-Net 的模块对应起来:
| 已有问题 | 本文定义 | 解决模块 |
|---|---|---|
| Transformer / CLIP ViT 全局强但局部结构弱 | Structural Gap | SSE |
| CLIP 文本编码器不擅长医学术语和复杂临床描述 | Semantic Gap | DATE |
| CLIP 自然图文对齐无法直接迁移到医学图文 | Alignment Gap | VLCM |
因此,TGC-Net 的设计逻辑是:
SSE 解决视觉结构问题
DATE 解决医学文本语义问题
VLCM 解决医学图文对齐问题7. 一句话总结
Related Work 这一节的核心是:医学分割需要同时具备局部结构和全局语义,而 CLIP 虽然有预训练图文对齐能力,但直接迁移到医学领域会遇到结构、语义和对齐三个 gap。因此,作者提出 TGC-Net,用 SSE、DATE、VLCM 分别解决这三个问题。
四、方法
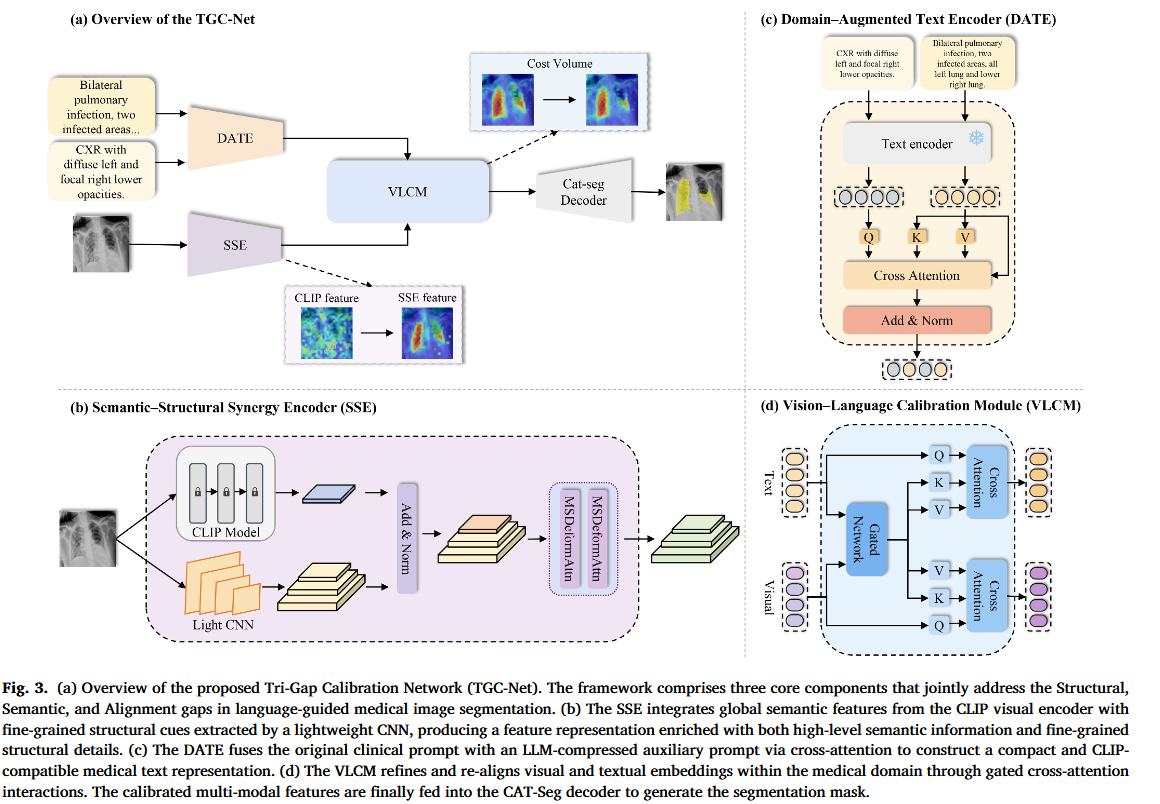
这张 Fig.3 是 TGC-Net 的核心方法图,对应论文 Method 部分。它把整套模型拆成四块:整体流程、SSE、DATE、VLCM。整篇方法可以理解为一句话:
图像侧用 SSE 补结构,文本侧用 DATE 补医学语义,然后用 VLCM 做医学域图文校准,最后用 CAT-Seg decoder 根据图文相似度生成分割 mask
五、实验
下面是结合论文 Experiment 部分 的有结构总结。整体上,实验部分想证明三件事:
1. TGC-Net 在多个医学分割数据集上性能更强;
2. SSE、DATE、VLCM 三个模块确实分别有效;
3. TGC-Net 在参数效率上优于大量已有方法。1. 实验目的
实验部分主要围绕作者前面提出的 tri-gap adaptation 展开验证。
也就是验证:
| 问题 | 对应模块 | 实验要证明什么 |
|---|---|---|
| Structural Gap | SSE | 加入结构增强后,分割边界和病灶定位更准 |
| Semantic Gap | DATE | 原始医学文本 + LLM 辅助文本比单独文本更有效 |
| Alignment Gap | VLCM | 医学图文校准比普通 cross-attention 更强 |
| 参数效率 | 冻结 CLIP + 轻量模块 | 少量可训练参数也能达到 SOTA |
所以实验部分不是只展示主结果,而是围绕 性能、泛化、可解释可视化、消融、参数效率 五个方面验证 TGC-Net。
2. 数据集设置
作者在 7 个医学图像分割数据集 上做实验,覆盖 4 种医学影像模态:胸部 X-ray、CT、皮肤镜和 MRI。
| 数据集 | 模态 | 任务类型 | 作用 |
|---|---|---|---|
| QaTa-COV19 | 胸部 X-ray | COVID-19 感染区域分割 | 验证文本引导胸片分割 |
| MosMedData+ | CT | 肺部感染区域分割 | 验证 CT 病灶分割 |
| MSD-Spleen | CT | 脾脏分割 | 验证单器官分割 |
| WORD | CT | 多腹部器官分割 | 验证复杂多器官场景 |
| AbdomenCT-1k | CT | 腹部器官分割 | 验证大规模 CT 器官分割 |
| ISIC 2018 | 皮肤镜 | 皮肤病灶分割 | 验证跨模态泛化 |
| ACDC | MRI | 心脏结构分割 | 验证 MRI 场景泛化 |
作者这样设计数据集的目的很明确:
不只在一个肺部数据集上刷点,而是证明 TGC-Net 能跨数据集、跨器官、跨模态泛化。
3. 评价指标
实验中主要使用两个指标:
| 指标 | 中文含义 | 作用 |
|---|---|---|
| Dice / mDice | Dice 系数 / 平均 Dice | 衡量预测 mask 和真实 mask 的重合程度 |
| mIoU | 平均交并比 | 衡量预测区域和真实区域的交集占并集比例 |
其中:
- QaTa-COV19 和 MosMedData+ 同时报告 mDice 和 mIoU;
- MSD-Spleen、WORD、AbdomenCT-1k、ISIC 2018、ACDC 主要报告 mDice。
医学分割里,Dice 是最核心的指标,因为它直接反映分割 mask 和 ground truth 的重叠程度。
4. 实现细节
作者的实现设置主要有几个关键点:
| 设置 | 内容 |
|---|---|
| 框架 | PyTorch |
| CLIP 图像输入分辨率 | 336 × 336 |
| CNN 分支输入分辨率 | 768 × 768 |
| Batch size | 8 |
| 基础视觉语言模型 | CLIP-ViT-L |
| DATE 辅助 prompt 生成模型 | DeepSeekV3 |
| CLIP 训练策略 | 冻结 CLIP image encoder 和 text encoder |
| 可训练部分 | SSE、DATE、VLCM 和 decoder 等轻量任务模块 |
这里最关键的是:
CLIP 图像编码器和文本编码器都被冻结,只训练外部轻量模块。
这直接服务于作者的核心主张:
TGC-Net 不是靠大规模 fine-tune CLIP 提升性能,
而是靠结构、语义、对齐三个方向的轻量适配。5. 主实验结果:和 SOTA 方法对比
5.1 胸部数据集:QaTa-COV19 和 MosMedData+
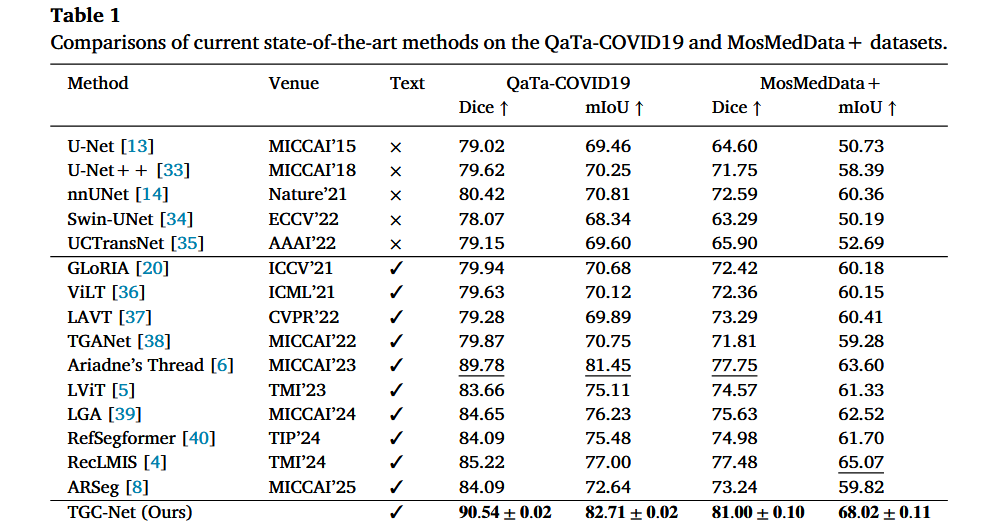
这是最贴合文本引导医学分割任务的实验。
在 QaTa-COV19 上:
| 方法 | Dice | mIoU |
|---|---|---|
| Ariadne's Thread | 89.78 | 81.45 |
| TGC-Net | 90.54 | 82.71 |
TGC-Net 比之前最强方法 Ariadne's Thread 提升:
Dice +0.76
mIoU +1.26在 MosMedData+ 上:
| 方法 | Dice | mIoU |
|---|---|---|
| RecLMIS | 77.48 | 65.07 |
| TGC-Net | 81.00 | 68.02 |
TGC-Net 比 RecLMIS 提升:
Dice +3.52
mIoU +2.95这个结果很重要,因为 MosMedData+ 是 CT 肺部感染分割,病灶边界、低对比度区域、图文对应都更难。TGC-Net 在这里提升明显,说明它的 结构增强 + 医学图文校准 确实有效。
5.2 腹部 CT 数据集:MSD-Spleen、AbdomenCT-1k、WORD
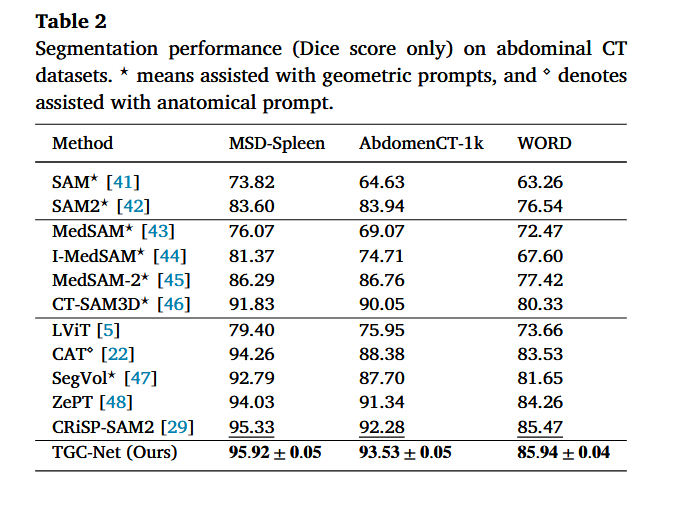
这部分用来验证 TGC-Net 不只是适合肺部感染,也能做器官分割。
| 数据集 | TGC-Net Dice | 对比前 SOTA CRiSP-SAM2 的提升 |
|---|---|---|
| MSD-Spleen | 95.92 | +0.59 |
| AbdomenCT-1k | 93.53 | +1.25 |
| WORD | 85.94 | +0.47 |
这些数据集的难点不一样:
- MSD-Spleen 更偏单器官;
- AbdomenCT-1k 是较大规模腹部 CT;
- WORD 是多器官分割,结构更复杂。
TGC-Net 在三者上都取得最好结果,说明它的泛化能力比较强。
5.3 皮肤镜和心脏 MRI:ISIC 2018 和 ACDC
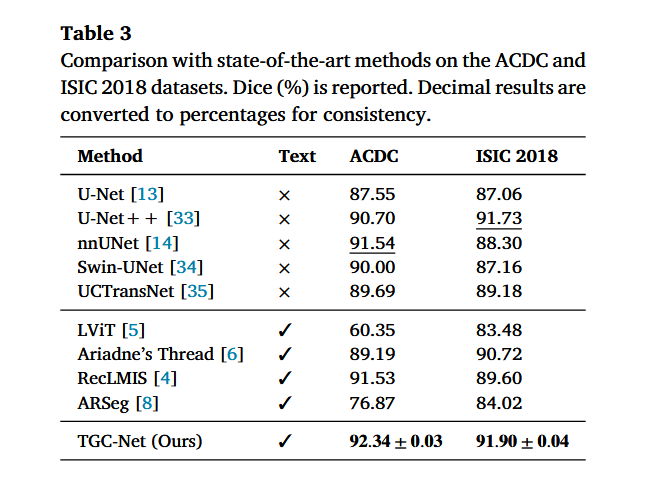
这部分验证跨模态能力。
| 数据集 | 模态 | TGC-Net Dice |
|---|---|---|
| ACDC | MRI | 92.34 |
| ISIC 2018 | Dermoscopy | 91.90 |
这说明 TGC-Net 不只适用于 X-ray 和 CT,也能迁移到皮肤镜和 MRI 场景。作者用这部分支持其"跨模态泛化能力"的主张。
6. 定性实验:可视化结果说明什么?
论文中主要有三类定性分析。
6.1 Fig.4:分割结果可视化
Fig.4 比较了 U-Net、LViT、Ariadne's Thread、RecLMIS 和 TGC-Net 的分割 mask。
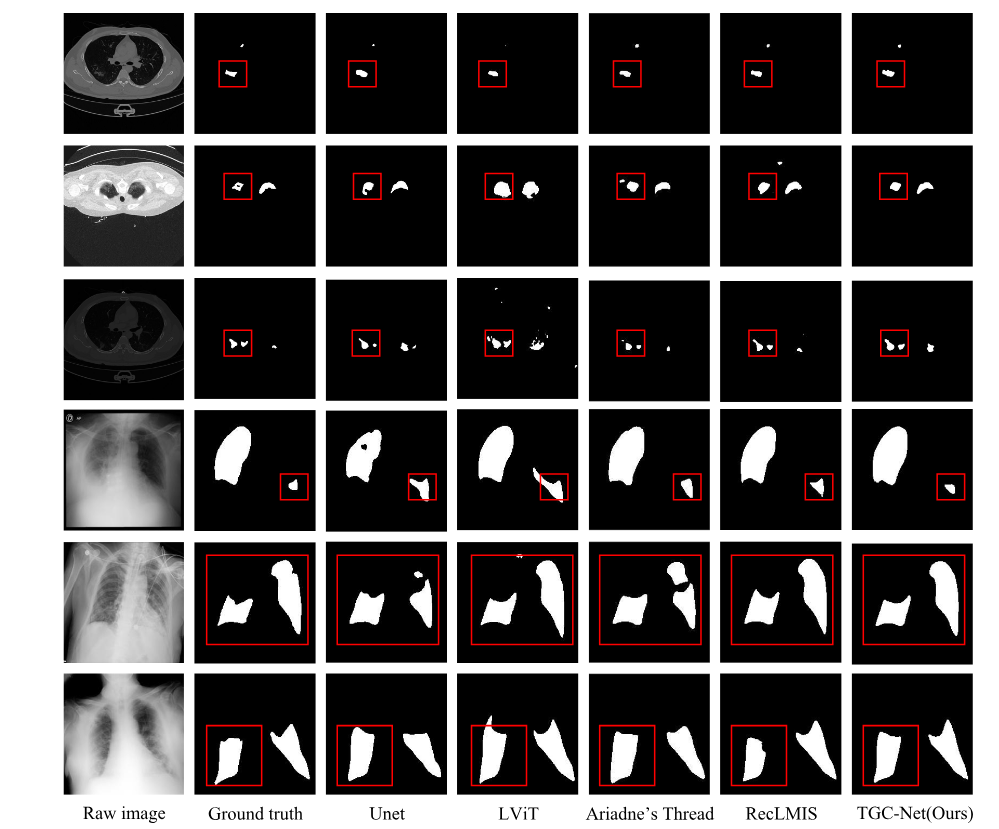
作者观察到:
| 方法类型 | 问题 |
|---|---|
| U-Net | 缺乏文本语义,mask 容易粗糙或漏分 |
| LViT / Ariadne's Thread | 有文本帮助,但边界仍不够精细 |
| RecLMIS | 边界更好,但仍可能出现伪阳性区域 |
| TGC-Net | 区域更完整,边界更接近 GT |
这说明 TGC-Net 的优势不仅体现在数值指标上,也体现在病灶定位和边界质量上。
6.2 Fig.5:SSE 和 VLCM 可视化
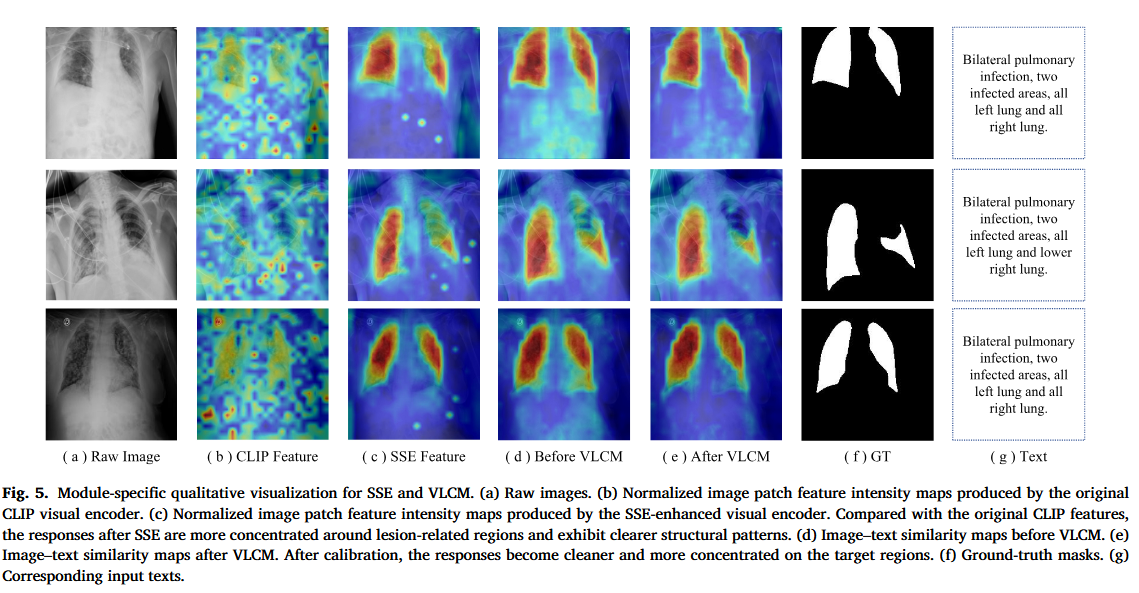
Fig.5 主要展示两个现象:
SSE 的作用
原始 CLIP feature:
响应分散
噪声多
病灶区域不集中经过 SSE 后:
响应更集中在病灶区域
结构模式更清晰这说明 SSE 确实增强了 CLIP 的结构表示能力。
VLCM 的作用
VLCM 前的 image-text similarity map:
存在无关区域响应
图文对齐不够干净VLCM 后:
响应更集中在目标区域
噪声更少
图文对应更准确这说明 VLCM 有助于缓解医学领域的 Alignment Gap。
6.3 Fig.6:DATE 可视化

Fig.6 比较:
只用 main text
vs
main text + auxiliary text结果显示,加入 LLM 生成的辅助 prompt 后,mask 更接近 ground truth。
这说明:
复杂临床文本直接送入 CLIP 不一定最优,经过 LLM 压缩后的辅助文本可以帮助 CLIP 抓住更紧凑、更关键的医学语义。
7. 消融实验:三个模块是否真的有效?
7.1 核心模块消融
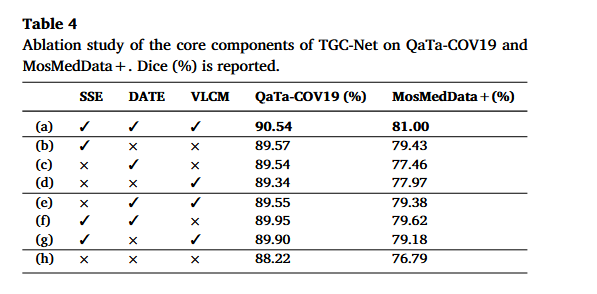
作者在 QaTa-COV19 和 MosMedData+ 上验证 SSE、DATE、VLCM 的贡献。
| 设置 | QaTa-COV19 | MosMedData+ |
|---|---|---|
| 无 SSE / DATE / VLCM | 88.22 | 76.79 |
| 只加 SSE | 89.57 | 79.43 |
| 只加 DATE | 89.54 | 77.46 |
| 只加 VLCM | 89.34 | 77.97 |
| 全部加入 | 90.54 | 81.00 |
结论很清楚:
- 三个模块单独加入都有提升;
- SSE 单独提升最大,说明医学分割最需要结构增强;
- 三个模块联合效果最好,说明它们是互补的;
- MosMedData+ 上提升更明显,说明 TGC-Net 对 CT 病灶这种难分割场景更有帮助。
7.2 SSE 消融:为什么需要 CLIP + CNN?
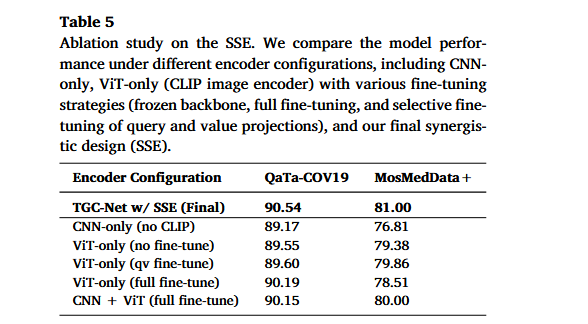
作者比较了不同视觉编码器配置。
| 配置 | QaTa-COV19 | MosMedData+ |
|---|---|---|
| CNN-only | 89.17 | 76.81 |
| ViT-only,无 fine-tune | 89.55 | 79.38 |
| ViT-only,qv fine-tune | 89.60 | 79.86 |
| ViT-only,full fine-tune | 90.19 | 78.51 |
| CNN + ViT full fine-tune | 90.15 | 80.00 |
| TGC-Net w/ SSE | 90.54 | 81.00 |
这里最有价值的结论是:
直接 full fine-tune ViT 在 QaTa-COV19 上有提升,但在 MosMedData+ 上反而下降,说明过度微调可能破坏 CLIP 原有图文对齐或导致过拟合。
而最终 SSE 最好,说明:
CLIP ViT 提供全局语义
CNN 提供局部结构
冻结 CLIP 保留预训练对齐能力
轻量结构分支补足边界细节这也解释了为什么作者不直接 fine-tune CLIP。
7.3 DATE 消融:为什么不是只用 LLM 文本?
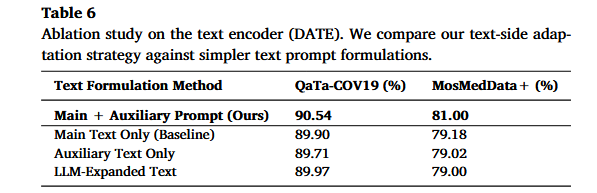
作者比较了四种文本方式:
| 文本方式 | QaTa-COV19 | MosMedData+ |
|---|---|---|
| Main Text Only | 89.90 | 79.18 |
| Auxiliary Text Only | 89.71 | 79.02 |
| LLM-Expanded Text | 89.97 | 79.00 |
| Main + Auxiliary Prompt | 90.54 | 81.00 |
结论是:
医学文本不是越长越好,也不是只用 LLM 改写就好。
DATE 的有效性来自:
Main Text 保留完整医学细节
Auxiliary Text 提供更简洁、更 CLIP-compatible 的表达
Cross-Attention 融合两者所以作者强调的是 semantics-preserving condensation,保语义压缩,不是简单扩写。
7.4 VLCM 消融:为什么需要 gated global alignment?
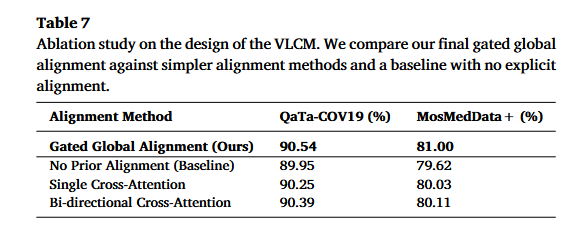
作者比较了几种对齐方式:
| 对齐方式 | QaTa-COV19 | MosMedData+ |
|---|---|---|
| No Prior Alignment | 89.95 | 79.62 |
| Single Cross-Attention | 90.25 | 80.03 |
| Bi-directional Cross-Attention | 90.39 | 80.11 |
| Gated Global Alignment | 90.54 | 81.00 |
结论:
- 不做显式对齐会明显下降;
- 普通 cross-attention 有帮助;
- 双向 cross-attention 更强;
- 作者提出的 gated global alignment 最好。
这说明 VLCM 不只是简单融合图文,而是通过共享上下文 FctxF_{ctx}Fctx 进行更稳定的医学域对齐。
8. 参数效率实验
这是论文的一个重要卖点。
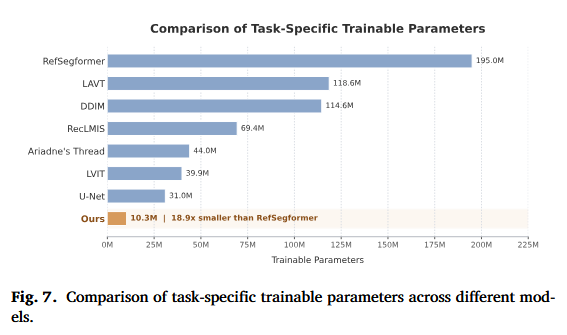
TGC-Net 只需要 10.3M task-specific trainable parameters。
对比其他方法:
| 方法 | 可训练参数量 |
|---|---|
| TGC-Net | 10.3M |
| U-Net | 31.0M |
| LViT | 39.9M |
| Ariadne's Thread | 44.0M |
| RecLMIS | 69.4M |
| DDIM | 114.6M |
| LAVT | 118.6M |
| RefSegformer | 195.0M |
作者想证明:
TGC-Net 不是靠增加大量参数取得提升,而是靠冻结 CLIP 后,对结构、文本、对齐做轻量任务适配。
不过这里也要注意一个细节:论文讨论部分强调,TGC-Net 的优势主要是 任务特定可训练参数少,并不等于总参数量一定最少,也不等于所有设置下推理速度一定最快。
9. 实验部分整体结论
实验部分最终支撑了四个核心结论:
结论 1:TGC-Net 性能强
在 7 个数据集上,TGC-Net 基本都达到最优或最强结果,尤其在 MosMedData+ 上提升明显。
结论 2:TGC-Net 泛化能力强
它不仅在肺部 X-ray 和 CT 上有效,也能迁移到腹部 CT、皮肤镜和心脏 MRI。
结论 3:三个模块确实有效
消融实验说明:
SSE:主要提升结构和边界
DATE:提升复杂医学文本利用能力
VLCM:提升医学图文对齐能力三个模块联合时效果最好。
结论 4:参数效率高
TGC-Net 只训练 10.3M 任务相关参数,比很多已有方法少得多,但性能更高。
10. 你读实验部分时要抓的重点
这部分最值得关注的不是"它拿了 SOTA",而是实验如何反过来支撑作者的核心叙事:
主实验:证明整体框架有效
跨模态实验:证明泛化能力
可视化实验:证明模块确实改善定位和对齐
消融实验:证明 SSE / DATE / VLCM 分别有贡献
参数实验:证明冻结 CLIP + 轻量适配是高效路线一句话总结:
实验部分证明了 TGC-Net 的核心观点:相比从零构建复杂图文交互网络,基于冻结 CLIP 的结构增强、文本适配和图文校准,可以用更少可训练参数,在多模态医学分割任务上取得更强表现。
六、讨论
Discussion 部分主要说明:TGC-Net 的价值不只是取得较高分割精度,而是提出了一条更适合医学小数据场景的 冻结 CLIP + 轻量任务适配 路线;它通过 SSE、DATE、VLCM 分别补足结构、语义和图文对齐问题,只训练少量任务特定参数,从而降低 full fine-tuning 带来的计算负担、过拟合风险和预训练对齐破坏风险。但作者也指出其局限:冻结 CLIP 可能限制医学域深层适配能力,双分支双分辨率设计会增加计算开销,且目前虽然验证了 X-ray、CT、皮肤镜和 MRI,但在超声、病理等更多复杂模态上的泛化能力仍需进一步验证。整体来看,Discussion 强调 TGC-Net 是一种有效且参数高效的医学文本引导分割框架,但未来仍可从部分微调 CLIP、降低结构分支计算成本、扩展更多医学模态和改进医学文本建模等方向继续优化。
七、总结
作者提出了 TGC-Net ,一个用于将预训练 CLIP 适配到语言引导医学图像分割任务的统一框架。它的目标不是重新训练大型医学视觉语言模型,也不是从零设计复杂跨模态融合网络,而是在 CLIP 已有图文对齐能力的基础上,针对医学分割的特殊需求进行轻量适配。
作者强调,CLIP 迁移到医学分割时主要面临三个问题:
| 问题 | 含义 | 对应模块 |
|---|---|---|
| 结构细节不足 | CLIP 视觉特征不够保留病灶边界、局部结构 | SSE |
| 医学语义不足 | CLIP 文本编码器不擅长复杂临床描述 | DATE |
| 跨模态对齐偏移 | 自然图文对齐不能直接迁移到医学图文 | VLCM |
因此,TGC-Net 采用 tri-gap calibration strategy,三重差距校准策略:
SSE:增强医学图像的结构表达
DATE:构建 CLIP-compatible 医学文本表示
VLCM:重新校准医学图像和文本之间的对齐关系实验方面,作者总结说,TGC-Net 在 7 个数据集 上取得了稳定的 SOTA 表现,并表现出较好的鲁棒性和跨领域泛化能力。这说明该方法不仅在单一数据集有效,也能适用于不同医学影像模态和分割任务。
一句话总结 Conclusion:
TGC-Net 证明了:通过结构增强、医学文本适配和图文对齐校准,可以有效地把 CLIP 迁移到文本引导医学图像分割任务中,从而实现更准确、更可靠、更具语义依据的医学分割