1. 理解硬件
1-1 磁盘、服务器、机柜、机房
机械磁盘是计算机中唯一的机械设备,慢但容量大、便宜。其他的不用管。
1-2 磁盘物理结构
内部组件就5个:
- 主轴(马达) ------ 带动盘片旋转
- 磁盘(盘片) ------ 相当于"纸",存储数据的载体
- 磁头 ------ 相当于"笔",读写数据
- 磁头臂 ------ 携带磁头移动
- 永磁铁
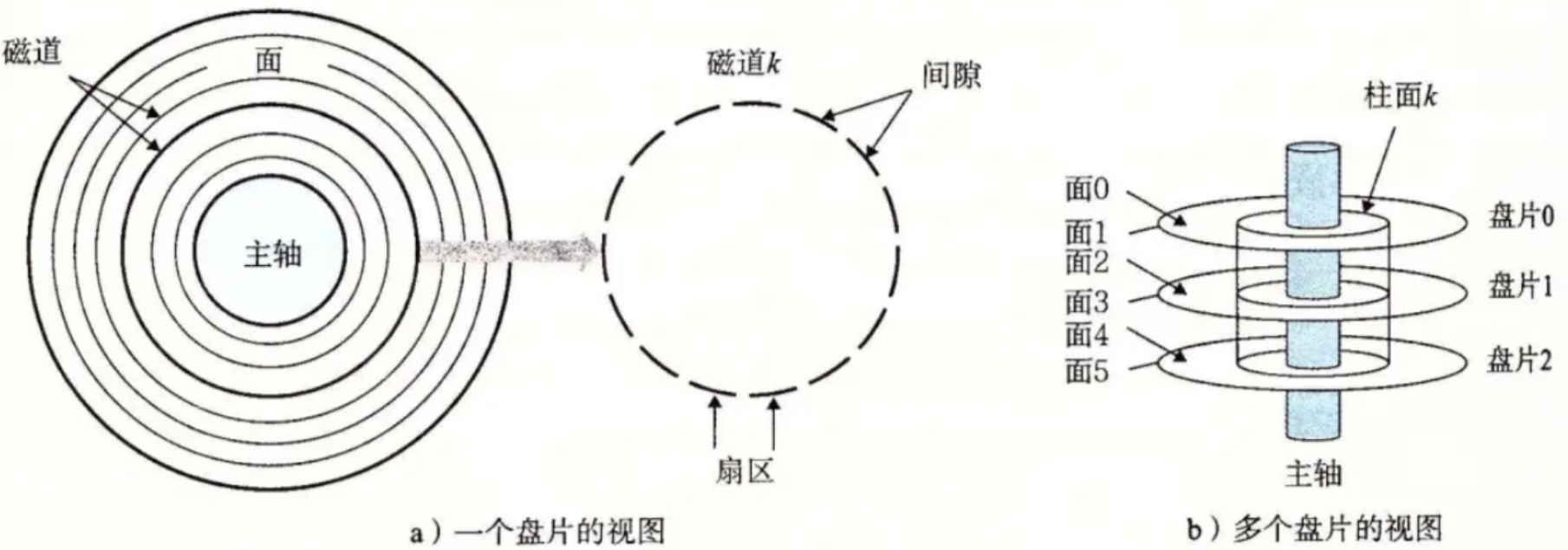
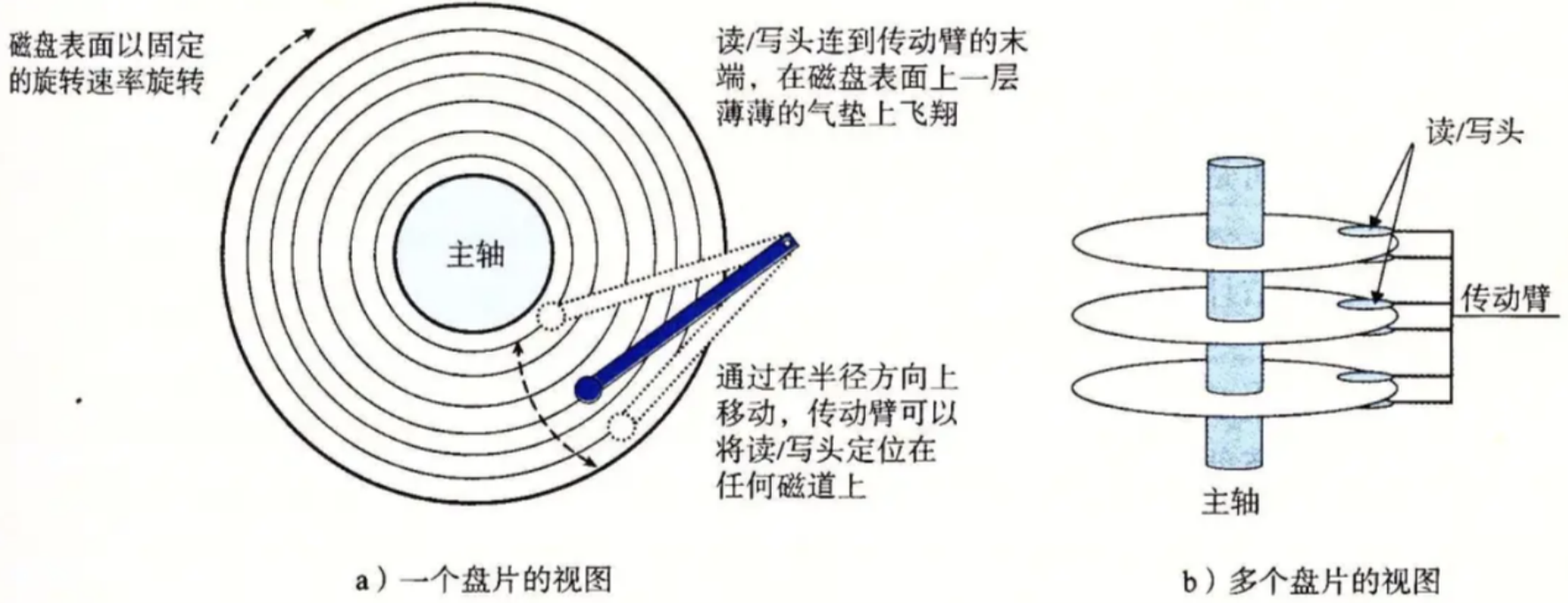
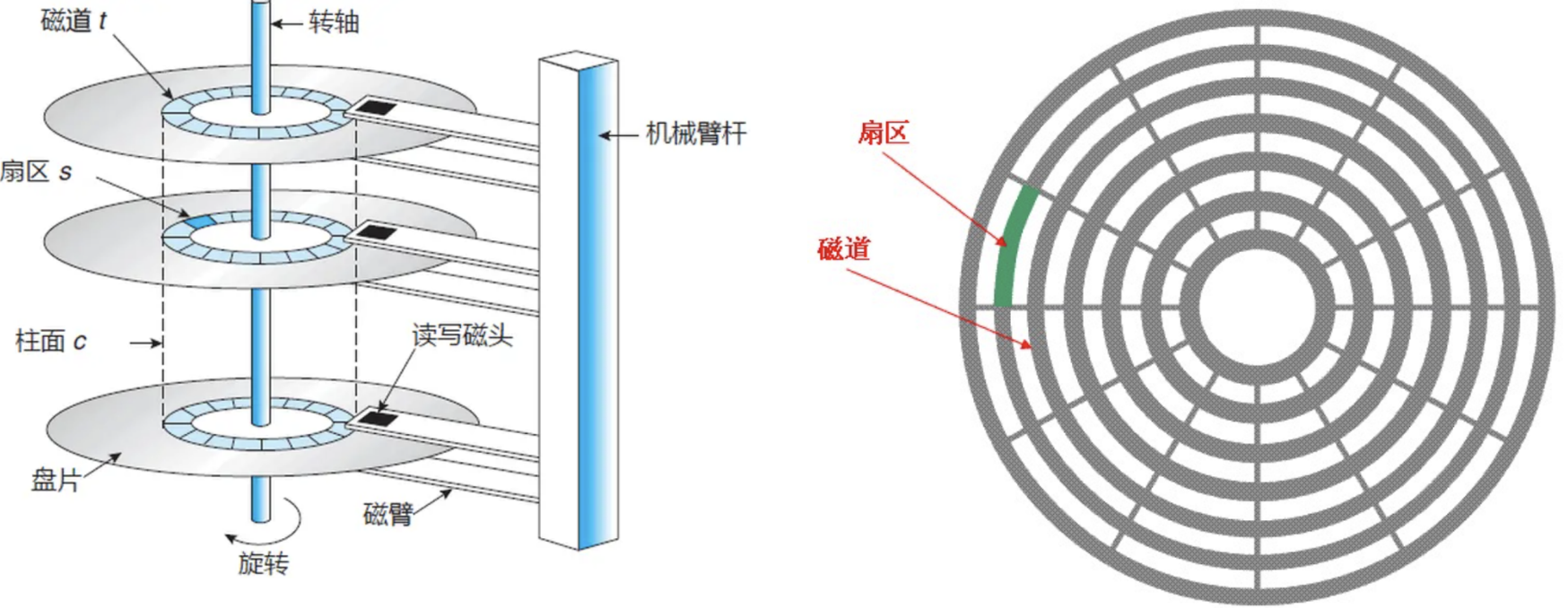
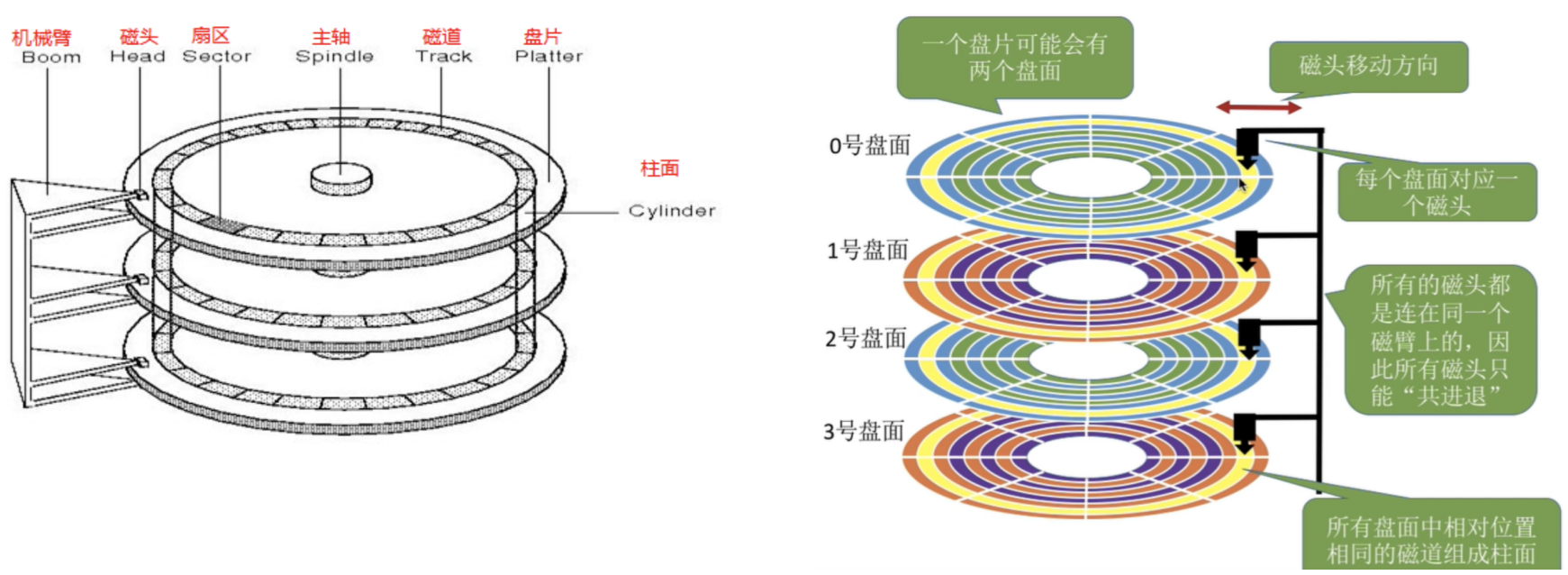
1-3 磁盘的存储结构
| 概念 | 含义 |
|---|---|
| 磁道(track) | 盘片上的同心圆,从外到内编号0、1、2... |
| 扇区(sector) | 每个磁道切出的扇形块,512字节,磁盘最小读写单位 |
| 柱面(cylinder) | 不同盘片上相同半径的磁道组成的"圆柱面"(逻辑概念) |
| 磁头(head) | 每个盘面一个磁头,磁头臂上的磁头共进退 |
定位一个扇区 = CHS寻址:先选磁头(H)→再选柱面(C)→再选扇区(S)
CHS的局限:用8bit存磁头、10bit存柱面、6bit存扇区,最大只能寻址约8GB,所以被淘汰了。
1-4 磁盘的逻辑结构(核心)
关键思想:把磁盘想象成一维数组。
磁带上面可以存储数据,我们可以把磁带"拉直",形成线性结构

那么磁盘本质上虽然是硬质的,但是逻辑上我们可以把磁盘想象成为卷在一起的磁带,那么磁盘的逻 辑存储结构我们也可以类似于:

这样每一个扇区,就有了一个线性地址(其实就是数组下标),这种地址叫做LBA
虽然物理上是三维的(柱面×磁头×扇区),但逻辑上就是一个一维数组,每个扇区有一个线性编号,叫做LBA(Logical Block Address)。
| 扇区 | 扇区 | 扇区 | 扇区 | 扇区 | ...
[0] [1] [2] [3] [4] ... ← 这就是LBA地址(数组下标)1-5 CHS 与 LBA 互转
CHS → LBA:
LBA = C × (磁头数 × 每道扇区数) + H × 每道扇区数 + S - 1本质就是三维数组展平成一维的公式,(磁头数 × 每道扇区数) 就是"一个柱面有多少个扇区"。
LBA → CHS:
C = LBA ÷ (磁头数 × 每道扇区数) // 第几个柱面
H = (LBA % (磁头数 × 每道扇区数)) ÷ 每道扇区数 // 柱面内第几个磁头
S = (LBA % 每道扇区数) + 1 // 磁道内第几个扇区(从1开始)最重要的结论:
OS只使用LBA地址,不需要关心CHS。LBA到CHS的转换由**磁盘固件(硬件电路)**自动完成。
从现在开始,磁盘就是一个元素为扇区的一维数组,下标就是LBA。OS用一个数字就能访问任意扇区。
这一节总结就一句话:磁盘在OS看来是一维扇区数组,用LBA下标访问,物理细节由磁盘自己处理。
2. 引入文件系统
2-1 引入"块"概念
OS不会一个扇区一个扇区地读,太慢了。所以把连续8个扇区 打包成一个块(block):
扇区: [0] [1] [2] [3] [4] [5] [6] [7] | [8] [9] [10] ...
├─── 块0 (4KB) ──────────────────┤├── 块1 ──...| 概念 | 值 |
|---|---|
| 一个扇区 | 512字节 |
| 一个块 | 4KB = 8个扇区 |
| 块是文件存取的最小单位 | 不是扇区 |
LBA和块号的换算:
块号 = LBA ÷ 8
LBA = 块号 × 8 + n(n是块内第几个扇区)验证命令:stat main.c 会看到 IO Block: 4096,就是4KB。
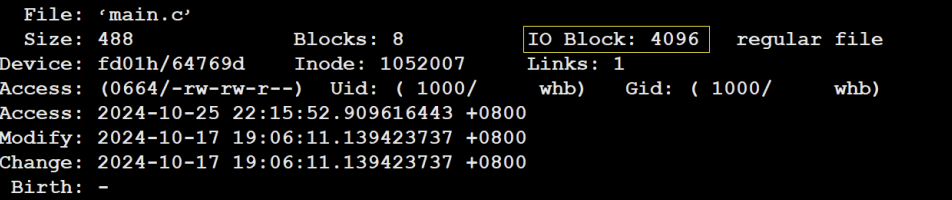
2-2 引入"分区"概念
其实磁盘是可以被分成多个分区(partition)的,以Windows观点来看,你可能会有一块磁盘并且将 它分区成C,D,E盘。那个C,D,E就是分区。**分区从实质上说就是对硬盘的一种格式化。**但是Linux的设备 都是以文件形式存在,那是怎么分区的呢?
- **柱面是分区的最小单位:**我们可以利用参考柱面号码的方式来进行分区,其本质就是设置每个区的起 始柱面和结束柱面号码。 此时我们可以将硬盘上的柱面(分区)进行平铺,将其想象成一个大的平 面,如下图所示:

- 分区本质上就是记录:这个区从哪个柱面开始,到哪个柱面结束
- 分区之后,每个分区可以独立格式化为不同的文件系统
- 柱面大小一致,扇区个位一致,那么其实只要知道每个分区的起始和结束柱面号,知道每 一个柱面多少个扇区,那么该分区多大,其实和解释LBA是多少也就清楚了

2-3 引入"inode"概念(重点)
文件 = 内容 + 属性,内容存在数据块里,属性存在inode里。
inode是什么:索引节点,存储文件的元信息(属性),包括:
- 文件大小、权限、所有者、时间戳、链接数等
- 不包含文件名(这个很关键,面试常考)
inode的特点:
- 每个文件对应一个inode,有唯一的inode号
- inode大小固定(128字节或256字节),不管文件内容多大
- 文件名不在inode里,而在目录的数据块里
- inode号以分区为单位,不跨分区
注意:
• 文件名属性并未纳入到inode数据结构内部
• inode的大小一般是128字节或者256,我们后面统一128字节
• 任何文件的内容大小可以不同,但是属性大小一定是相同的
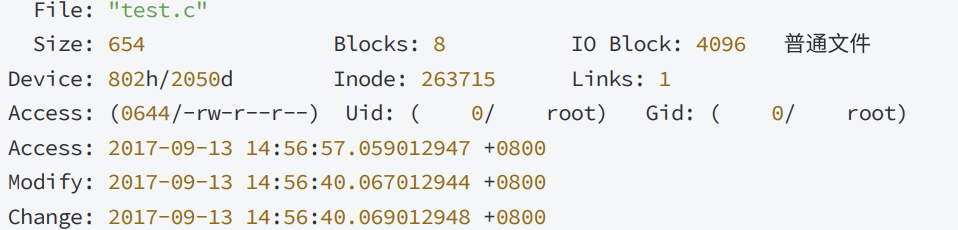
# 查看文件的inode号
ls -li test.c
# 1052007 -rw-rw-r-- 1 whb whb 488 Oct 17 19:06 test.c
# 查看详细inode信息
stat test.c
inode里的关键字段(知道有这些就行,不用背结构体):
i_mode 文件类型和权限
i_uid/i_gid 所有者/组
i_size 文件大小
i_atime 最后访问时间
i_ctime 创建时间
i_mtime 最后修改时间
i_links_count 硬链接数
i_block[15] 指向数据块的指针(12个直接+1个一级间接+1个二级间接+1个三级间接)i_block15的映射结构:
inode
├── 12个直接块指针 ──→ 直接指向数据块(能管理 12×4KB = 48KB)
├── 一级间接指针 ──→ 指向一个"索引块",索引块里存的都是块号
├── 二级间接指针 ──→ 索引块→索引块→数据块
└── 三级间接指针 ──→ 索引块→索引块→索引块→数据块这样设计是为了支持非常大的文件,小文件用直接块就够了,大文件才用到间接块。
第2节核心就三个词 :块(4KB) 、分区 、inode(属性+块指针)。这三个搞清楚了,后面ext2就顺了。
3. ext2 文件系统
3-1 宏观认识
所有的准备工作都已经做完,是时候认识下文件系统了。**我们想要在硬盘上储文件,必须先把硬盘格 式化为某种格式的文件系统,才能存储文件。文件系统的目的就是组织和管理硬盘中的文件。**在 Linux 系统中,最常见的是 ext2 系列的文件系统。
先把整体结构搞清楚。ext2把一个分区 划分成多个块组(Block Group),每个块组结构相同,只要能管理一个 分区就能管理所有分区,也就能管理所有磁盘文件:
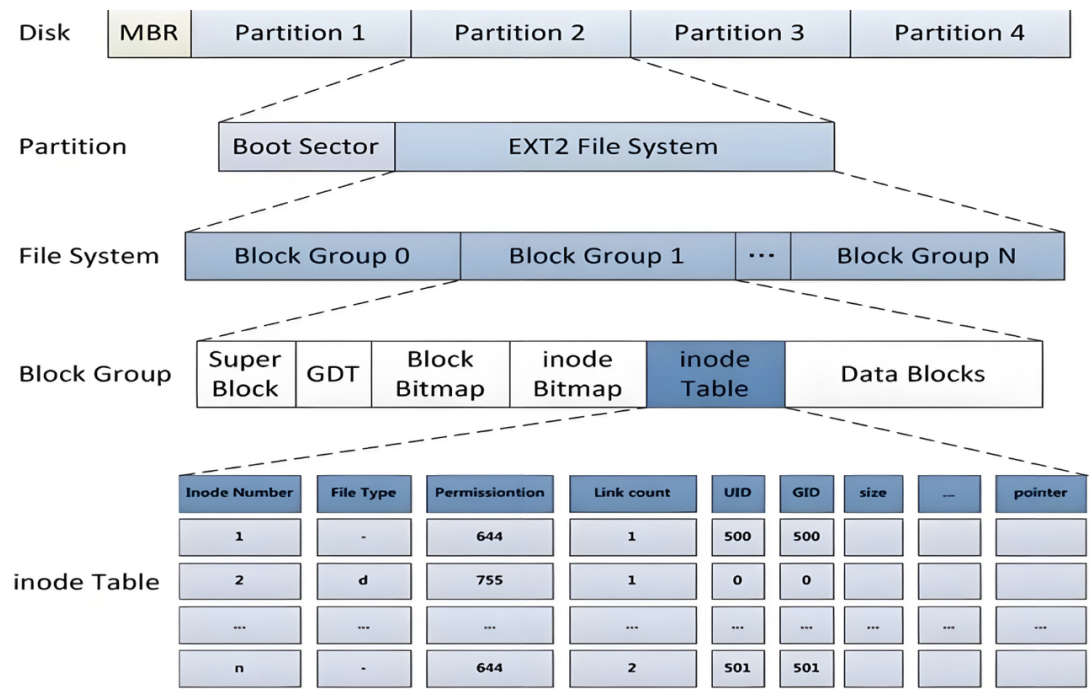
分区:
┌─────────────┬─────────────┬─────────────┬─────────────┐
│ Boot Sector │ Block Grp 0 │ Block Grp 1 │ Block Grp N │
└─────────────┴─────────────┴─────────────┴─────────────┘
每个Block Group内部:
┌────────────┬─────┬──────────────┬──────────────┬──────────────┬─────────────┐
│ Super Block│ GDT │ Block Bitmap │ Inode Bitmap │ Inode Table │ Data Blocks │
└────────────┴─────┴──────────────┴──────────────┴──────────────┴─────────────┘Boot Sector:启动块,1KB,由PC标准规定,存磁盘分区信息和启动信息,任何文件系统都不能改它。启动块之后才是ext2的开始。
为什么分成多个块组?就像政府管理城市一样,分而治之。一个块组管一部分inode和数据块,比整个分区一起管效率高得多。
3-2 Block Group
ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组 成。
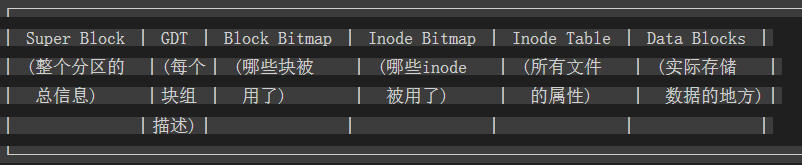
每个块组结构完全相同,都包含6个部分:
Block Group:
┌────────────┬─────┬──────────────┬──────────────┬──────────────┬─────────────┐
│ Super Block│ GDT │ Block Bitmap │ Inode Bitmap │ Inode Table │ Data Blocks │
│ (超级块) │ │ (块位图) │ (inode位图) │ (inode表) │ (数据块) │
└────────────┴─────┴──────────────┴──────────────┴──────────────┴─────────────┘管理信息(前5个)+ 实际数据(最后1个),就这个套路。
3-3 块组内部构成
3-3-1 超级块(Super Block)
作用 :存放文件系统本身的结构信息,描述整个分区的文件系统信息,不是单个块组的。
存什么:
-
inode总数、块总数
-
空闲inode数、空闲块数
-
inode大小、块大小
-
最近挂载时间、最近写入时间
-
文件系统状态、魔数(magic number)
struct ext2_super_block {
__le32 s_inodes_count; // inode总数
__le32 s_blocks_count; // 块总数
__le32 s_free_blocks_count; // 空闲块数
__le32 s_free_inodes_count; // 空闲inode数
__le32 s_first_data_block; // 第一个数据块
__le32 s_log_block_size; // 块大小
__le32 s_blocks_per_group; // 每组块数
__le32 s_inodes_per_group; // 每组inode数
__le16 s_magic; // 魔数,用于识别文件系统类型
__le16 s_inode_size; // inode结构大小
// ...
};
关键细节 :超级块在每个块组的开头都有备份(第一个块组必须有,后面的可选)。为什么?因为超级块太重要了,一旦损坏整个文件系统就废了,多备份几份保平安。
3-3-2 GDT(Group Descriptor Table)
作用 :块组描述符表,描述每个块组的属性信息,整个分区分成多个块组就对应有多少个块组描述符。每个块组描 述符存储一个块组 的描述信息
存什么(每个块组描述符):
-
本块组的块位图在哪个块
-
本块组的inode位图在哪个块
-
本块组的inode表从哪个块开始
-
本块组空闲块数、空闲inode数
-
本块组使用的目录数
struct ext2_group_desc {
__le32 bg_block_bitmap; // 块位图的位置
__le32 bg_inode_bitmap; // inode位图的位置
__le32 bg_inode_table; // inode表的起始位置
__le16 bg_free_blocks_count; // 空闲块数
__le16 bg_free_inodes_count; // 空闲inode数
__le16 bg_used_dirs_count; // 目录数
// ...
};
类比:超级块是"全市总览",GDT是"各区街道办的地址簿",告诉你每个块组的各个设施在哪里。
GDT也有备份,每个块组开头都有一份,和超级块一样是为了安全。
3-3-3 块位图(Block Bitmap)
作用 :记录本块组中哪些数据块被占用、哪些空闲。
原理很简单:一个bit对应一个数据块:
1= 已占用0= 空闲
举例:假设一个块组有4096个数据块,那块位图就是 4096 ÷ 8 = 512字节 = 1个块就能表示完。
位图(二进制): 1 1 1 1 1 1 1 1 | 1 1 1 1 1 0 0 0 | ...
块0-7全被占用 块12以后空闲为什么要位图? 因为如果用一个字节表示一个块的状态太浪费了,用1个bit就够,空间效率提高8倍。
3-3-4 inode位图(Inode Bitmap)
和块位图完全一样的思想,只是它记录的是inode的使用情况:
- 每个bit表示一个inode是否空闲
1= 已使用,0= 空闲
面试常考:inode位图和块位图的区别? → 一个管inode,一个管数据块,都用位图来高效记录占用情况。
3-3-5 inode表(Inode Table)
作用 :存放本块组所有inode的属性信息。
就是第2节学的 struct ext2_inode 结构体数组,每个文件一个inode,包含:
- 文件类型、权限(i_mode)
- 所有者(i_uid/i_gid)
- 文件大小(i_size)
- 三个时间(i_atime/i_ctime/i_mtime)
- 硬链接数(i_links_count)
- i_block15 ------ 指向数据块的指针(最重要)
重要规则:
- inode编号以分区为单位,整体编号,不跨分区
- 每个块组分配一定数量的inode,不是所有inode都在同一个块组
怎么根据inode号找inode?
1. inode号 ÷ 每组inode数 = 在第几个块组
2. inode号 % 每组inode数 = 在该块组inode表中的第几个
3. 偏移量 = 第几个 × inode大小(128字节)
4. 从该块组的inode表起始位置 + 偏移量,读出inode结构3-3-6 Data Block(数据区)
作用 :存放文件的实际内容。
不同类型的文件,数据块的用法不同:
| 文件类型 | 数据块内容 |
|---|---|
| 普通文件 | 存文件内容数据 |
| 目录文件 | 存该目录下所有文件名和inode号的映射表 |
| 符号链接(软链接) | 如果路径短,直接存在inode里不占数据块;路径长才用数据块 |
目录的数据块长什么样:
目录数据块内容:
┌──────────┬──────────┬──────────┐
│ inode号 │ 记录长度 │ 文件名 │
├──────────┼──────────┼──────────┤
│ 263136 │ 12 │ . │ ← 当前目录
│ 263488 │ 12 │ .. │ ← 上级目录
│ 263563 │ 12 │ abc │
│ 263563 │ 12 │ def │
│ 261678 │ 16 │ abc.s │
└──────────┴──────────┴──────────┘这就是为什么文件名不在inode里而在目录里 ------ 文件名是目录的内容,不是文件本身的属性。同一个inode可以有多个文件名(硬链接)。
重要规则:
- 块号以分区为单位,不跨分区
- 知道inode → 通过i_block找到数据块 → 拿到文件内容
到这里做个阶段性总结
一个块组的完整图景:
Block Group:
创建一个新文件的4步(这个面试考过):
- 存储属性:在inode位图找一个空闲inode,写入文件属性
- 存储数据:在块位图找空闲数据块,写入文件内容
- 记录映射:在inode的i_block里记录数据块编号
- 添加文件名 :在目录的数据块里写入
(inode号, 文件名)的映射