****论文题目:****Dual selective fusion transformer network for hyperspectral image classification(用于高光谱图像分类的双选择融合变压器网络)
****期刊:****Neural Networks
****摘要:****Transformer在高光谱图像(HSI)分类领域取得了满意的效果。然而,现有的Transformer模型在处理具有不同土地覆盖类型和丰富光谱信息的HSI场景时面临两个关键挑战:(1)固定的感受野忽略了各种HSI对象所需的有效上下文尺度;(2)无效的自注意力机制特征会影响模型的性能。为了解决这些限制,我们提出了一种新的双选择融合变压器网络(DSFormer)用于HSI分类。DSFormer通过灵活选择和融合不同感受野之间的特征,实现空间和光谱的联合上下文建模,通过聚焦最相关的空间光谱标记,有效减少不必要的信息干扰。具体来说,我们设计了一个核选择融合变压器块(KSFTB),通过自适应融合不同尺度的空间和光谱特征来学习最佳感受野,增强了模型准确识别不同HSI对象的能力。此外,我们引入了Token选择性融合变压器块(TSFTB),该块在空间-光谱自注意力机制融合过程中策略性地选择和组合必要的Token,以捕获最关键的上下文。在四个基准HSI数据集上进行的大量实验表明,提出的DSFormer显著提高了土地覆盖分类精度,优于现有的最先进方法。其中,DSFormer在Pavia University、Houston、Indian Pines和Whu-HongHu数据集上的总体准确率分别为96.59%、97.66%、95.17%和94.59%,比之前的模型分别提高了3.19%、1.14%、0.91%和2.80%。该代码将在https://github.com/YichuXu/DSFormer上在线提供。
DSFormer:双选择融合Transformer用于高光谱图像分类
1. 引言:高光谱图像分类面临的挑战
高光谱图像(HSI)凭借其丰富的空间-光谱信息,在灾害监测、精准农业、城市规划等遥感领域有着广泛的应用。HSI分类的核心目标是为图像中的每个像素分配特定的类别标签。近年来,Transformer凭借其强大的长距离依赖捕获能力,已经成为HSI分类研究的主流方向。
然而,现有的Transformer方法在处理HSI场景时存在两个关键问题:
问题一:固定感受野无法适应多样化的地物尺度。 不同类型的地物需要不同范围的上下文信息来进行准确识别。例如,沥青类地物由于与砖块在局部特征上较为相似,需要更大的感受野来获取足够的上下文信息才能避免误分类;而具有空间连续性的草地或裸土,则只需要较小的感受野就足以完成分类。
问题二:密集自注意力引入了冗余噪声。 传统的多头自注意力(MHSA)机制让每个token与所有其他token进行交互。但在HSI场景中,并非所有token都包含有用信息------那些与当前查询无关的token(如在识别沥青时,草地和沥青油等区域的token)会引入噪声,降低分类精度。
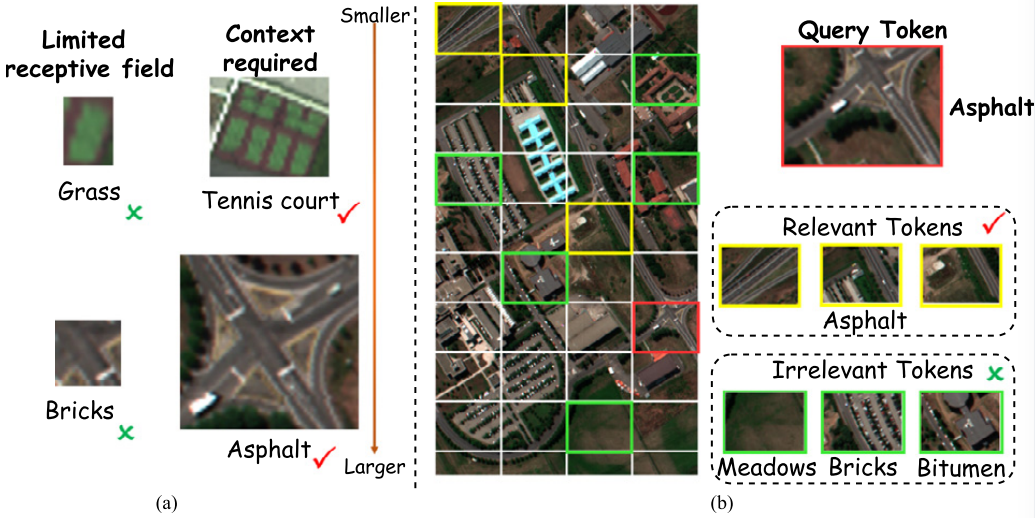
Figure 1:展示固定感受野导致的误分类问题(a),以及无关token引入噪声的问题(b)
为解决上述问题,本文提出了双选择融合Transformer网络(DSFormer),其核心思想是"在合理的感受野范围内,选择并融合最有价值和最相关的空间-光谱信息"。
2. DSFormer整体架构
DSFormer的整体流程如下:首先对HSI进行PCA降维,然后提取重叠的patch cube作为输入;经过一个3×3卷积层获取浅层特征后,依次通过两个**双选择融合Transformer组(DSFTG)**进行深层特征提取;最后通过层归一化和全连接层完成分类。
每个DSFTG由一个**核选择融合Transformer模块(KSFTB)和三个连续的Token选择融合Transformer模块(TSFTB)**组成。
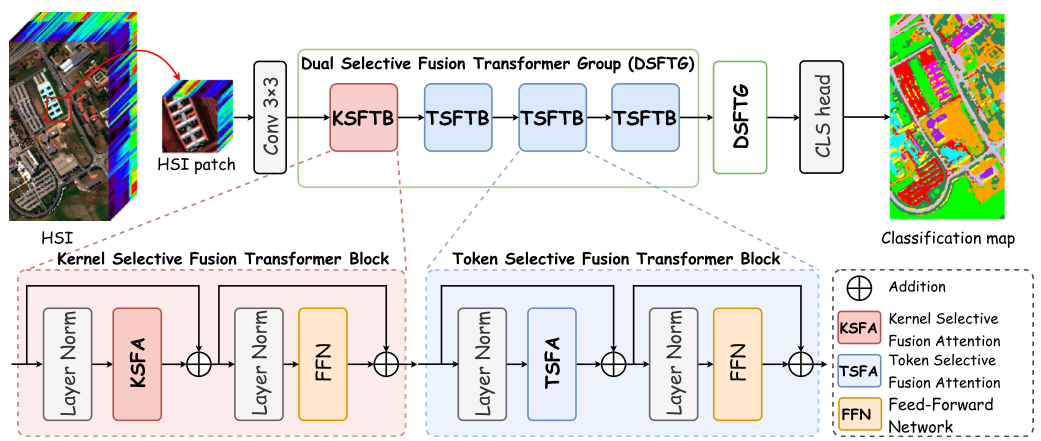
Figure 2:DSFormer整体架构图,包含DSFTG的组成结构
3. 核心模块详解
3.1 核选择融合Transformer模块(KSFTB)
KSFTB的目标是学习最优的感受野 ,使网络能够根据不同地物类型自适应地选择和融合合适尺度的空间-光谱特征。其核心是**核选择融合注意力(KSFA)**模块。
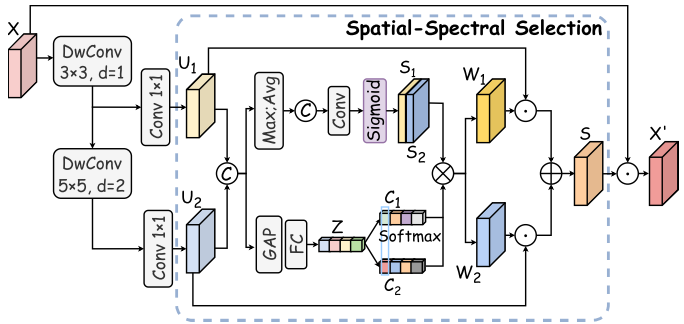
Figure 3:KSFA模块的结构示意图
KSFA的工作流程:
(1)多尺度特征提取。 对输入特征 使用两组解耦的深度卷积(DwConv)进行特征提取:一组使用3×3 DwConv,另一组在3×3 DwConv之后再接一个膨胀率为2的5×5 DwConv,从而构建不同大小的感受野。然后分别通过1×1卷积整合通道信息,得到两个不同感受野下的特征
和
。
(2)空间选择机制。 将 和
拼接后,通过通道级的平均池化和最大池化获取空间描述符,再经过1×1卷积和sigmoid激活函数,生成对应不同卷积核的空间选择掩码
和
。
(3)光谱选择机制。 对拼接特征进行空间全局平均池化压缩为光谱描述符,再通过全连接层和softmax操作生成光谱选择掩码 和
。其中使用两个可学习向量
和
来引导光谱注意力的生成。
(4)空间-光谱联合选择与融合。 将空间选择掩码和光谱选择掩码通过矩阵乘法得到空间-光谱联合选择权重 ,对各尺度特征进行加权融合,最终通过1×1卷积得到注意力特征
,并与输入特征进行逐元素相乘得到输出。
KSFTB在KSFA之后还接了一个FFN模块(由全连接层、深度卷积、GELU激活和第二个全连接层组成)。
3.2 Token选择融合Transformer模块(TSFTB)
TSFTB的目标是在自注意力计算中只选择最相关的token进行融合 ,减少冗余和无关信息的干扰。其核心是**Token选择融合注意力(TSFA)**机制。
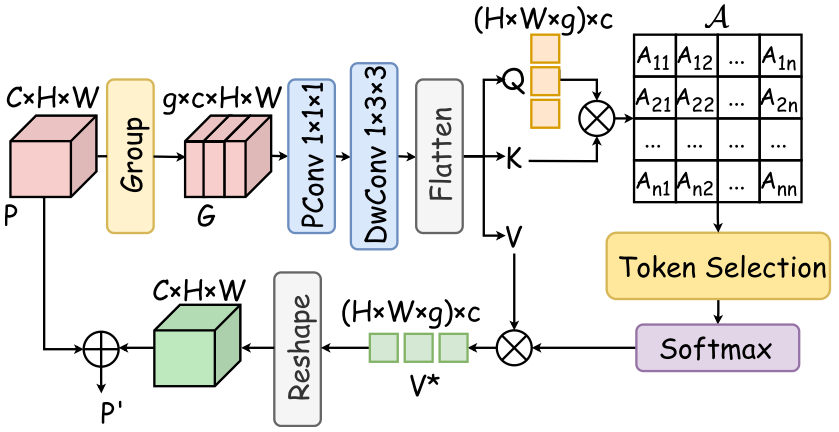
Figure 4:TSFA模块的结构示意图
TSFA的工作流程:
(1)分组与3D卷积提取token。 将输入特征 分为 g 个组,通过3D点卷积(1×1×1)和3D深度卷积(1×3×3)提取具有空间-光谱属性的Query、Key和Value。这种分组策略保留了HSI三维数据立方体的特性。
(2)密集注意力矩阵计算。 将Q、K、V重塑和展平后,通过Q和K的点积计算密集注意力矩阵 。
(3)Top-k Token选择。 这是TSFA的核心操作。对密集注意力矩阵的每一行,找出前 k% 最大的注意力值,保留这些值,其余位置设为 。这样经过softmax后,被屏蔽的位置注意力权重趋近于0,实现了对最相关token的选择性关注。
(4)选择性注意力融合。 使用稀疏化后的注意力矩阵与Value相乘,得到选择性注意力特征,再加上残差连接。多头输出通过拼接和1×1卷积聚合。
整个TSFA的伪代码详见论文的Algorithm 1。

4. 实验设置
4.1 数据集
论文在四个基准HSI数据集上进行了实验:
- Pavia University:103个光谱波段,610×340像素,9个类别,由ROSIS传感器在意大利帕维亚大学校园采集。
- Houston:144个光谱波段(400-1000nm),349×1905像素,15个类别,空间分辨率2.5m。
- Indian Pines:200个光谱波段(400-2500nm),145×145像素,16个植被类别,空间分辨率20m。
- Whu-HongHu:270个光谱波段(400-1000nm),940×475像素,22个(论文中实际为17个典型作物类型,但表中含22类)作物类型,空间分辨率约0.04m。
4.2 实验配置
实验在PyTorch平台上使用NVIDIA GeForce RTX 3090 GPU进行。Pavia University每类随机选取30个训练样本,其余数据集每类选取50个样本(Indian Pines的第1、7、9类仅选取15个样本)。使用AdamW优化器,初始学习率1e-4,权重衰减1e-5,训练500个epoch。Patch大小为C×10×10,Transformer中patch size为2,嵌入维度固定为128。评价指标包括总体精度(OA)、平均精度(AA)和Kappa系数,每个实验重复10次取均值和标准差。
5. 参数分析
5.1 Token选择率 k 的影响
k 是TSFTB模块中控制保留token比例的核心参数。论文测试了 k 分别为0.2、0.4、0.6、0.8和1(即传统全自注意力)的效果。
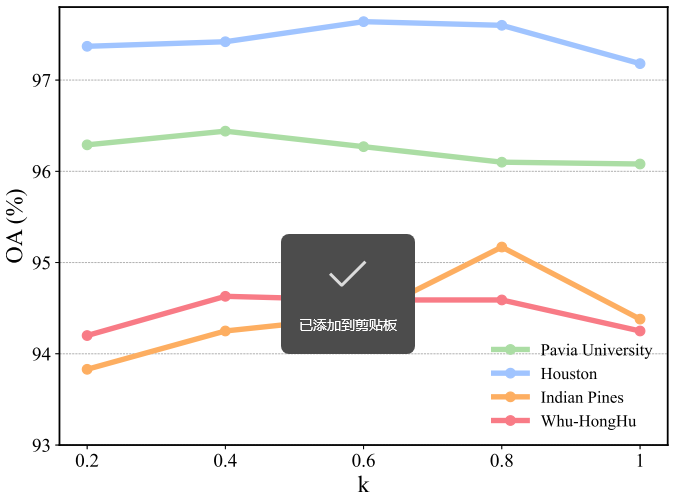
Figure 5:四个数据集在不同k值下的OA对比图
实验结果显示:当 时,由于可用于长距离建模的信息不足,分类精度较低;随着 k 增大,OA逐渐提升;但当 k 超过最优值后,OA开始下降,这是因为包含了过多无关或冗余信息。最终,四个数据集的最优 k 值分别为0.4、0.6、0.8和0.8。值得注意的是,在大多数 k 配置下,性能都优于传统全自注意力(k=1),验证了token选择策略的有效性。
5.2 分组数 g 的影响
g 是TSFTB中的关键参数,直接影响注意力矩阵的大小和计算复杂度。论文测试了 g 为1、2、4和8的效果。
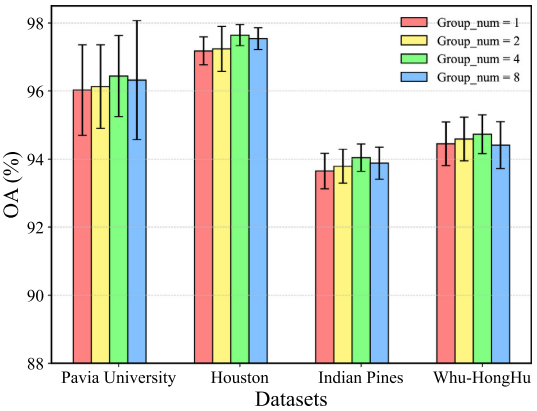
Figure 6:四个数据集在不同分组数g下的OA对比图
当 g=1 时不进行分组,退化为纯空间token选择,分类精度最低。分组策略显著提升了分类性能,最优结果在 g=4 时取得。
6. 消融实验
6.1 各模块的性能贡献
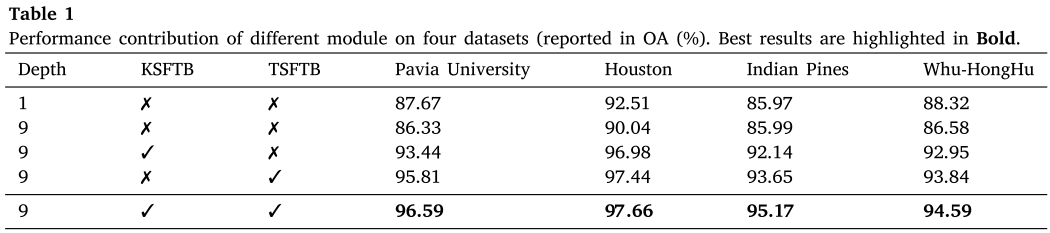
Table 1:不同模块组合在四个数据集上的OA对比
论文通过消融实验验证了KSFTB和TSFTB各自的贡献。以Pavia University数据集为例:
- 单层3×3卷积基线:OA = 87.67%
- 九层3×3卷积(与DSFormer同深度):OA = 86.33%(增加层数反而下降)
- 仅使用KSFTB:OA = 93.44%(提升约7个百分点)
- 仅使用TSFTB:OA = 95.81%(提升约9个百分点)
- KSFTB + TSFTB联合使用:OA = 96.59%(最优)
两个模块在所有四个数据集上都展现了协同增效效果。KSFTB通过自适应选择和融合合适感受野的特征来提升多尺度地物的识别精度,TSFTB通过在最相关token上计算自注意力来减少冗余干扰。
6.2 空间-光谱选择机制的贡献
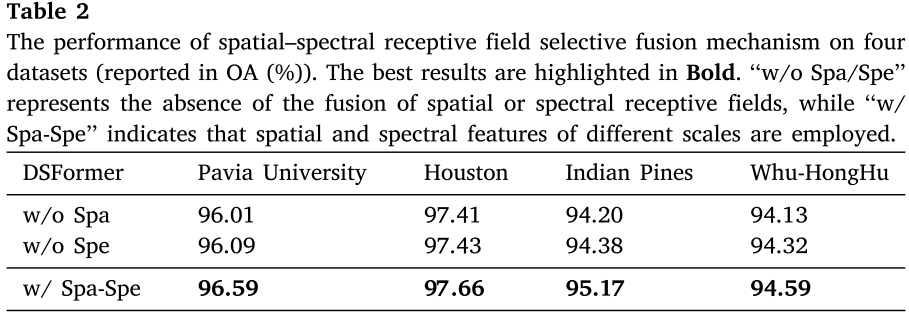
Table 2:空间/光谱单独使用与联合使用的OA对比
消融实验还验证了KSFTB中空间-光谱联合选择机制的重要性。以Pavia University为例:仅使用空间选择(w/o Spe)OA为96.09%,仅使用光谱选择(w/o Spa)OA为96.01%,而空间-光谱联合使用时OA达到96.59%。这说明对于HSI中不同地物的准确识别,同时自适应优化空间感受野和光谱尺度特征是非常必要的。
7. 性能对比与分析
7.1 定量结果
论文将DSFormer与9种经典和最新方法进行了对比,包括CNN系列(3D-CNN、SSFCN、SACNet、FcontNet)和Transformer系列(SpectralFormer、SSFTT、GAHT、MorphFormer、GSCViT)。
Pavia University数据集:
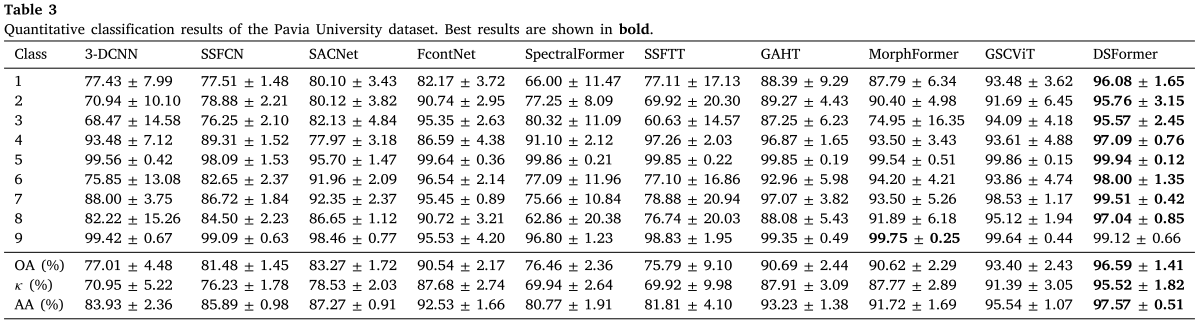
Table 3:Pavia University数据集的逐类及整体定量结果
DSFormer取得了96.59%的OA,比第二名GSCViT(93.40%)提升了3.19个百分点。在几乎所有类别上都取得了最优精度,仅在第9类(shadows)上略低于MorphFormer,这可能是因为MorphFormer的形态学操作为阴影识别提供了更明确的类别先验。
Houston数据集:
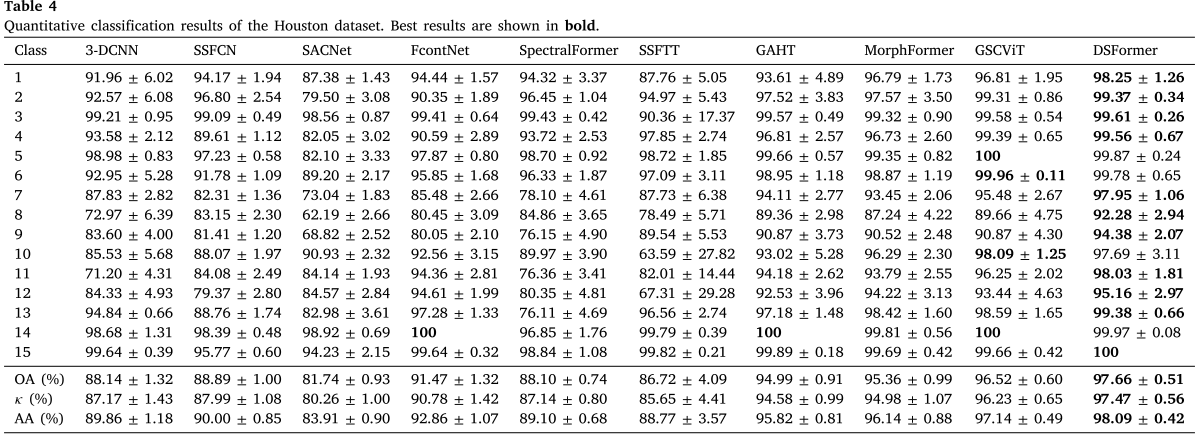
Table 4:Houston数据集的逐类及整体定量结果
DSFormer取得了97.66%的OA,Kappa系数97.47%,AA达到98.09%,全面领先于所有对比方法。
Indian Pines数据集:
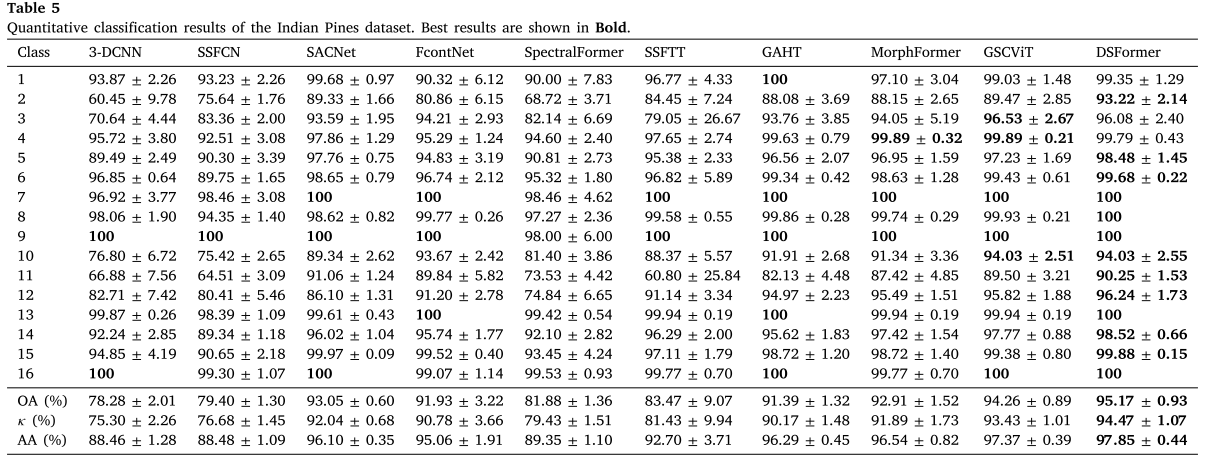
Table 5:Indian Pines数据集的逐类及整体定量结果
DSFormer取得了95.17%的OA,相比GSCViT(94.26%)提升了0.91个百分点。
Whu-HongHu数据集:
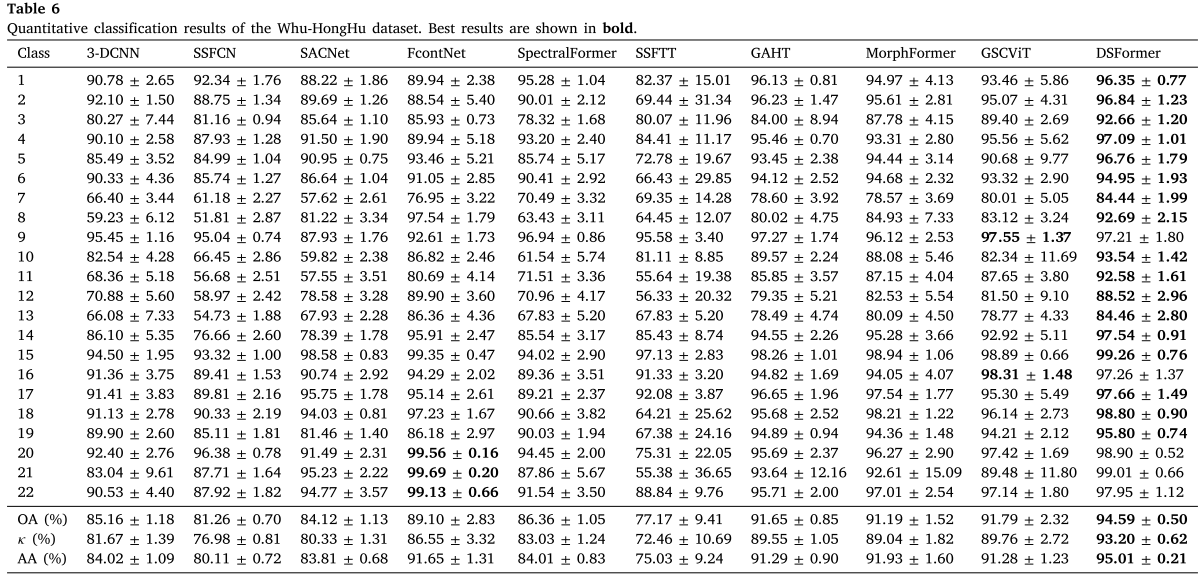
Table 6:Whu-HongHu数据集的逐类及整体定量结果
DSFormer取得了94.59%的OA,相比第二名GSCViT(91.79%)提升了2.80个百分点。该数据集包含22种地物类别,类别数量多且复杂度高,DSFormer仍然展现了显著优势。
7.2 定性结果(分类图可视化)
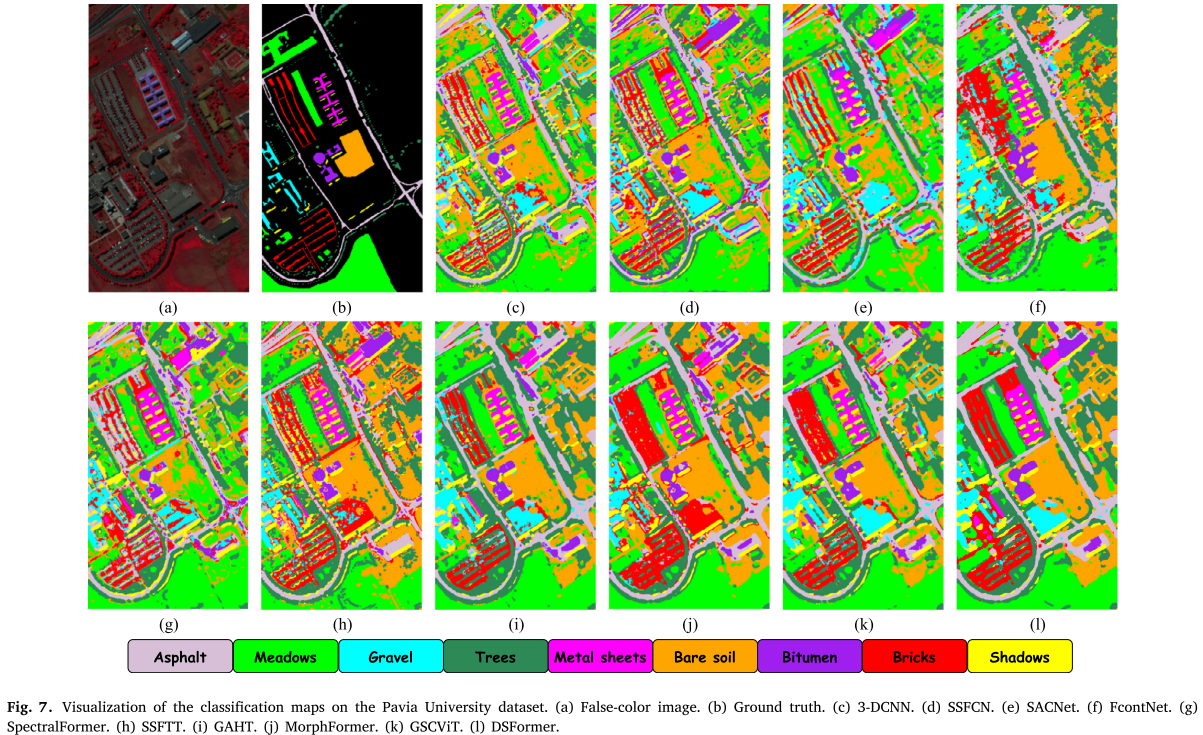
Figure 7:Pavia University数据集的分类图可视化
以Pavia University为例,3D-CNN和SSFCN等方法产生了明显的椒盐噪声。FcontNet和最新的Transformer方法生成了更平滑的分类图。特别值得注意的是在bricks类的分类上,大多数现有方法存在遗漏或误分类,而DSFormer显著减少了这些错误,输出结果更接近真实标签。



Figure 8:Houston数据集的分类图可视化
Figure 9:Indian Pines数据集的分类图可视化
Figure 10:Whu-HongHu数据集的分类图可视化
7.3 不同训练样本数量下的鲁棒性
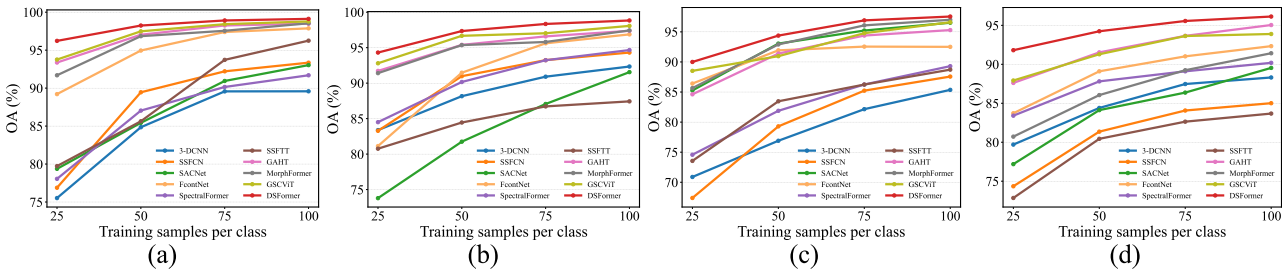
Figure 11:四个数据集在不同训练样本数(25、50、75、100)下的OA对比
论文在每类分别选取25、50、75和100个训练样本的设置下测试了DSFormer的稳定性。结果表明,随着训练样本数增加,DSFormer的分类精度稳步提升,展现出良好的鲁棒性,并在所有训练样本配置下持续优于现有最先进方法。
7.4 计算效率分析
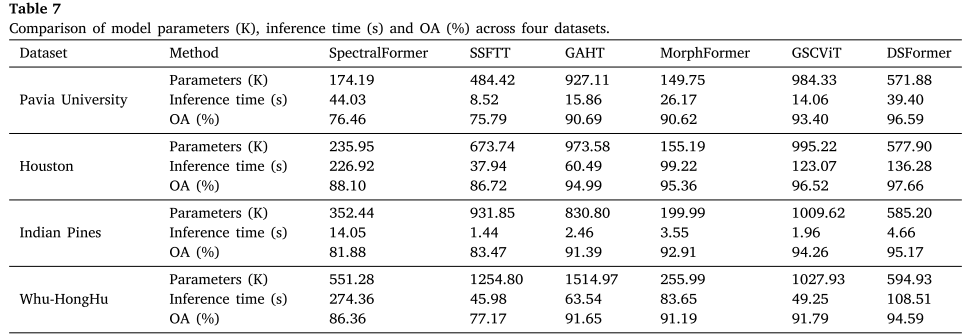
Table 7:各Transformer方法的参数量、推理时间与OA对比
在模型参数方面,DSFormer(约571K-594K参数)少于GAHT和GSCViT。在推理时间方面,DSFormer虽然比SSFTT等轻量方法稍慢(主要受TSFTB中分组策略产生大量token的影响),但快于SpectralFormer。总体而言,DSFormer在计算资源使用和复杂场景感知之间实现了良好的平衡。
8. 可视化分析
8.1 不同地物的感受野选择权重
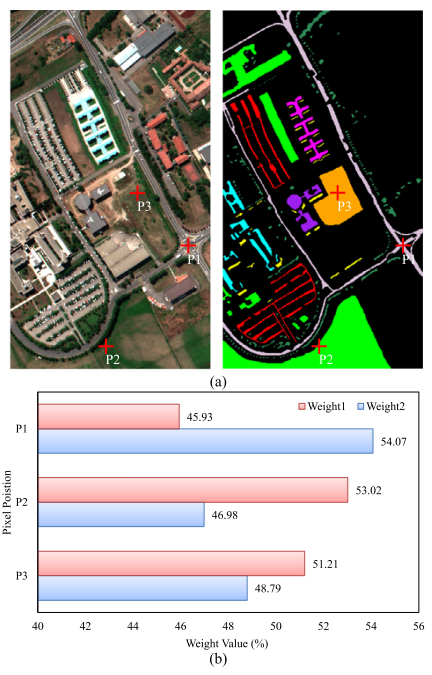
Figure 12:Pavia University数据集上三个地物(沥青P1、草地P2、裸土P3)的感受野选择权重可视化
论文可视化了KSFTB在融合不同感受野时的选择权重。在沥青位置P1,较大感受野对应的权重为54.07%,印证了沥青需要更多上下文信息才能准确分类的分析。而在草地P2和裸土P3位置,由于这些地物具有空间连续性,较小感受野的特征已足够用于分类。
8.2 Token选择前后的注意力矩阵变化
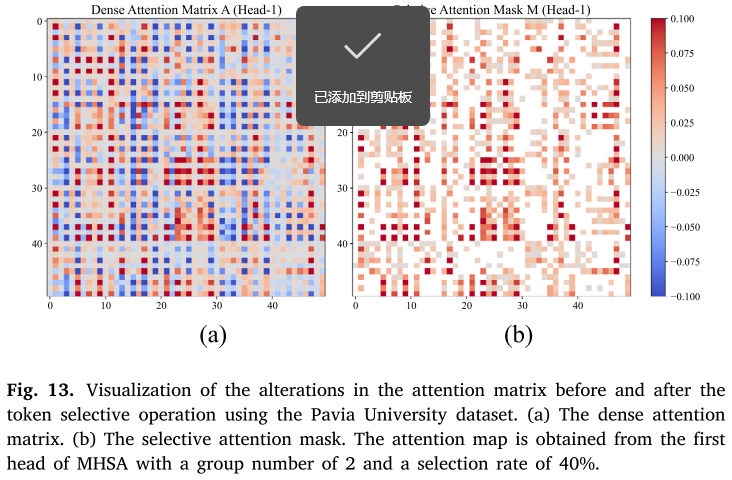
Figure 13:Pavia University数据集上token选择操作前后的注意力矩阵变化
论文展示了TSFTB中token选择操作前后注意力矩阵的变化(分组数为2,选择率为40%)。可以看到,经过token选择后,原始密集注意力矩阵中只有40%的元素保留了其值,其余60%被设为0,形成了稀疏的选择性注意力掩码。通过这一过程,与分类相关的信息被保留,而无关和冗余的信息被丢弃。
9. 总结
DSFormer针对高光谱图像分类中的两个核心问题------固定感受野和密集自注意力噪声------提出了两个精巧的解决方案:
- KSFTB通过膨胀深度卷积构建多尺度感受野,并利用空间-光谱联合选择机制自适应地融合最合适的感受野特征。
- TSFTB通过光谱分组策略保留HSI的3D特性,并在自注意力计算中选择top-k%最相关的token,有效过滤冗余信息。
这两个模块的协同工作使DSFormer在四个基准数据集上均取得了最优的分类精度,相比此前最优方法实现了0.91%-3.19%的提升,同时保持了合理的计算开销。