一、项目介绍
Apache Gravitino 是一个统一的元数据管理平台,旨在打破数据孤岛,为Data+AI资产提供单一事实来源。它的核心优势在于 "目录的目录"(Catalog of Catalogs) 架构、对海量引擎和AI工作的原生支持,以及从被动的元数据服务向主动的"元数据驱动行动系统"的演进。
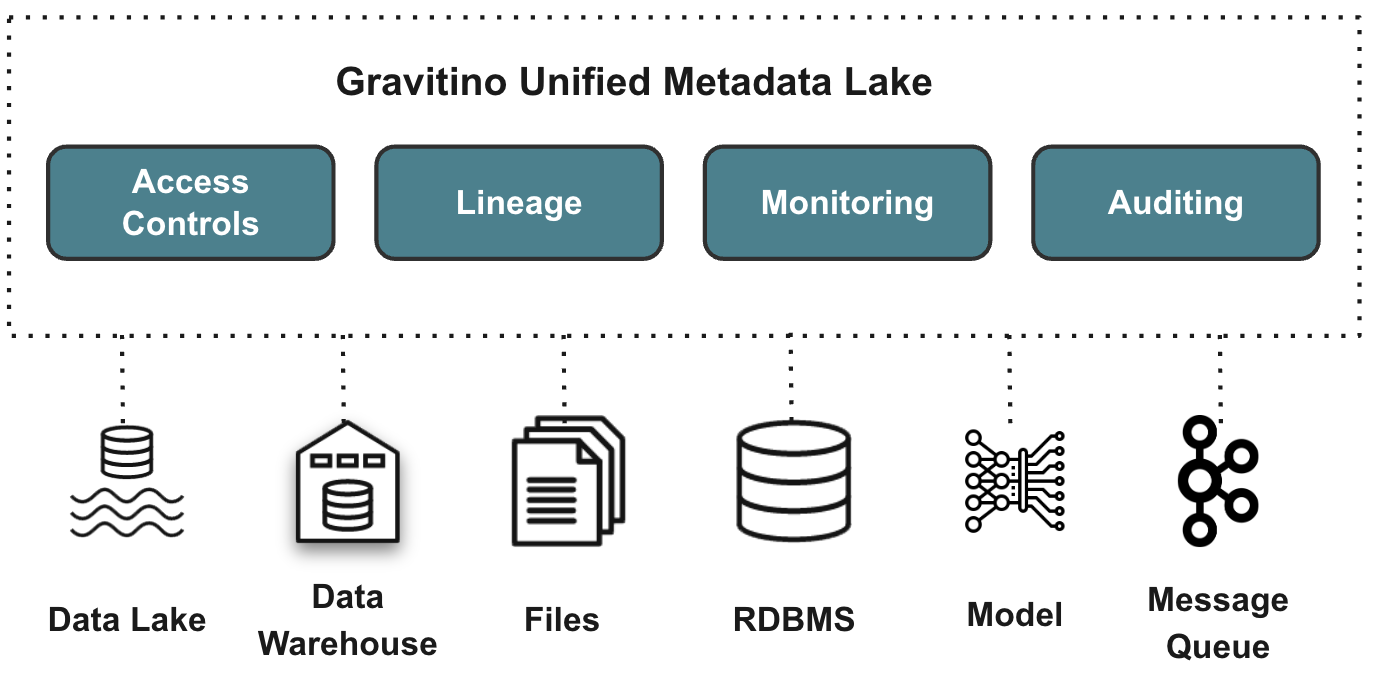
主要特点
- 统一元数据管理:通过单一模型和 API 管理各种元数据源(例如 Hive、MySQL、HDFS、S3)。
- 端到端数据治理:对所有元数据资产进行访问控制、审计和发现等功能。
- 直接元数据集成:底层系统的变化会立即通过 Gravitino 的连接器反映出来。
- 地理分布支持:跨区域和云共享元数据,以支持全球架构。
- 多引擎兼容性:无需修改 SQL 方言即可与查询引擎无缝集成。
- AI资产管理(开发中):支持AI模型和特征跟踪。
常见用例
- 跨数据湖和数据仓库的联合元数据发现
- 混合云或多云环境下的多区域元数据同步
- 通过统一的审计和访问控制进行数据和人工智能资产治理
- 即插即用,适用于 Trino 或 Spark 等发动机。
- 支持不断发展的元数据标准,包括人工智能模型谱系
二、快速部署启动项目
环境要求:
安装 Git(可选)、Docker、Docker Compose。
系统资源要求:
2 个 CPU 核心,8 GB 内存,25 GB 磁盘存储空间,MacOS 或 Linux 操作系统(已验证 Ubuntu22.04、Ubuntu24.04 和 AmazonLinux)。
需使用的端口:
该项目环境运行多个服务。后续使用到的端口如下:(确保与你已经运行的服务端口不要冲突)
注:如果有些端口已经被使用了,可以修改docker-compose.yaml文件里面的端口
|-----------------------|------------------------|
| docker容器 | 使用到的端口 |
| playground-gravitino | 8090 9001 |
| playground-hive | 3307 19000 19083 60070 |
| playground-ranger | 6080 |
| playground-mysql | 13306 |
| playground-spark | 14040 |
| playground-postgresql | 15432 |
| playground-trino | 18080 |
| playground-jupyter | 18888 |
| playground-prometheus | 19090 |
| playground-grafana | 13000 |
下载并启动项目:
bash
git clone git@github.com:apache/gravitino-playground.git
cd gravitino-playground运行脚本启动所以服务:
bash
./playground.sh start检查运行状态:
bash
./playground.sh status停止服务指令(需要时使用):
bash
./playground.sh stop三、使用 Trino SQL 体验 Apache Gravitino
在 Docker 容器中使用 Trino CLI
使用以下命令登录到 Gravitino playground Trino Docker 容器:
bash
docker exec -it playground-trino bash进入容器后输入:
bash
trino四、使用 Jupyter Notebook
-
在浏览器中打开 Jupyter Notebook,网址为http://localhost:18888。
-
打开
gravitino-trino-example.ipynb笔记本。 -
启动笔记本并运行单元格
五、使用 Spark 客户端
使用以下命令登录到 Gravitino playground Spark Docker 容器:
bash
docker exec -it playground-spark bash在容器中打开 Spark SQL 客户端:
bash
cd /opt/spark && /bin/bash bin/spark-sql六、监控Gravitino
-
在浏览器中打开 Grafana,网址为http://localhost:13000。
-
在导航菜单中,点击**"仪表盘"** -> "Gravitino Playground"。
-
尝试使用默认模板。
七、实践案例
简单的Trino查询
可以使用简单的查询在 Trino CLI 中进行测试:
sql
SHOW CATALOGS;
CREATE SCHEMA catalog_hive.company
WITH (location = 'hdfs://hive:9000/user/hive/warehouse/company.db');
SHOW CREATE SCHEMA catalog_hive.company;
CREATE TABLE catalog_hive.company.employees
(
name varchar,
salary decimal(10,2)
)
WITH (
format = 'TEXTFILE'
);
INSERT INTO catalog_hive.company.employees (name, salary) VALUES ('Sam Evans', 55000);
SELECT * FROM catalog_hive.company.employees;
SHOW SCHEMAS from catalog_hive;
DESCRIBE catalog_hive.company.employees;
SHOW TABLES from catalog_hive.company;跨目录查询
在一家公司里,不同的部门可能使用不同的数据栈。例如,人力资源部门使用 Apache Hive 存储数据,而销售部门使用 PostgreSQL。你可以使用 Gravitino 将这两个部门的数据连接起来,运行一些查询。
要了解哪位员工的销售额最高,可以运行以下 SQL 语句:
sql
SELECT given_name, family_name, job_title, sum(total_amount) AS total_sales
FROM catalog_hive.sales.sales as s,
catalog_postgres.hr.employees AS e
where s.employee_id = e.employee_id
GROUP BY given_name, family_name, job_title
ORDER BY total_sales DESC
LIMIT 1;要了解购买量最高的客户,可以运行以下 SQL 语句:
sql
SELECT customer_name, location, SUM(total_amount) AS total_spent
FROM catalog_hive.sales.sales AS s,
catalog_hive.sales.stores AS l,
catalog_hive.sales.customers AS c
WHERE s.store_id = l.store_id AND s.customer_id = c.customer_id
GROUP BY location, customer_name
ORDER BY location, SUM(total_amount) DESC;要了解员工的平均绩效评分和总销售额,可以运行以下 SQL 语句:
sql
SELECT e.employee_id, given_name, family_name, AVG(rating) AS average_rating, SUM(total_amount) AS total_sales
FROM catalog_postgres.hr.employees AS e,
catalog_postgres.hr.employee_performance AS p,
catalog_hive.sales.sales AS s
WHERE e.employee_id = p.employee_id AND p.employee_id = s.employee_id
GROUP BY e.employee_id, given_name, family_name;用 Spark 和 Trino
可以考虑使用 SparkSQL 生成数据,然后使用 Trino 查询这些数据。不妨试试 Gravitino:
1、登录 Spark 容器并执行 SQL 语句:
sql
// 使用Hive目录创建Hive表
USE catalog_hive;
CREATE DATABASE product;
USE product;
CREATE TABLE IF NOT EXISTS employees (
id INT,
name STRING,
age INT
)
PARTITIONED BY (department STRING)
STORED AS PARQUET;
DESC TABLE EXTENDED employees;
INSERT OVERWRITE TABLE employees PARTITION(department='Engineering') VALUES (1, 'John Doe', 30), (2, 'Jane Smith', 28);
INSERT OVERWRITE TABLE employees PARTITION(department='Marketing') VALUES (3, 'Mike Brown', 32);2、登录 Trino 容器并执行 SQL:
sql
SELECT * FROM catalog_hive.product.employees WHERE department = 'Engineering';演示程序位于该jupyter文件夹中,可以通过访问http://localhost:18888 gravitino-spark-trino-example.ipynb 通过 Jupyter Notebook 打开演示程序。
八、使用 Apache Iceberg REST 服务
假设您想将业务从 Hive 迁移到 Iceberg。部分表将使用 Hive,其他表将使用 Iceberg。Gravitino 也提供了一个 Iceberg REST 目录服务。您可以使用 Spark 访问该 REST 目录来写入表数据。然后,您可以使用 Trino 从 Hive 表中读取数据,并将数据与 Iceberg 表连接起来。
spark-defaults.conf具体如下(已在 Playground 中配置好):
bash
spark.sql.extensions org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
spark.sql.catalog.catalog_rest org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.catalog_rest.type rest
spark.sql.catalog.catalog_rest.uri http://gravitino:9001/iceberg/
spark.locality.wait.node 0请注意,catalog_rest SparkSQL 和catalog_iceberg Gravitino 以及 Trino 共享同一个 Iceberg JDBC 后端,这意味着它们可以访问同一个数据集。
1、登录 Spark 容器并执行以下步骤。
bash
docker exec -it playground-spark bash
bash
spark@container_id:/$ cd /opt/spark && /bin/bash bin/spark-sql
sql
use catalog_rest;
create database sales;
use sales;
create table customers (customer_id int, customer_name varchar(100), customer_email varchar(100));
describe extended customers;
insert into customers (customer_id, customer_name, customer_email) values (11,'Rory Brown','rory@123.com');
insert into customers (customer_id, customer_name, customer_email) values (12,'Jerry Washington','jerry@dt.com');2、 登录 Trino 容器并执行以下步骤。您可以从 Hive 表和 Iceberg 表中获取所有客户信息。
bash
docker exec -it playground-trino bash
bash
trino@container_id:/$ trino
sql
select * from catalog_hive.sales.customers
union
select * from catalog_iceberg.sales.customers;演示程序位于该jupyter文件夹中,可以 gravitino-spark-trino-example.ipynb 通过 Jupyter Notebook访问 http://localhost:18888 打开演示程序。
九、将 Gravitino 与 LlamaIndex 结合使用
Gravitino Playground 还提供了一个简单的 RAG 演示,该演示使用了 LlamaIndex。此演示展示如何使用 Gravitino 管理表格和非表格数据集,将 LlamaIndex 作为统一数据源连接起来,然后使用 LlamaIndex 和 LLM 通过一条自然语言查询来查询表格和非表格数据。
演示程序位于该jupyter文件夹中,可以通过http://localhost:18888gravitino_llama_index_demo.ipynb 通过 Jupyter Notebook 打开演示程序。
演示场景为:基本结构化的城市统计数据存储在 MySQL 数据库中,详细的城市介绍信息存储在 PDF 文件中。用户希望同时获取结构化数据和 PDF 文件中关于城市的答案。
在本演示中,将使用 Gravitino 通过关系目录管理 MySQL 表,使用文件集目录管理 PDF 文件,并将 Gravitino 作为 LlamaIndex 的统一数据源,以便为表格数据和非表格数据构建索引。然后,将使用 LLM 通过自然语言查询来查询数据。
注意:要运行此演示,需要在设置OPENAI_API_KEY中gravitino_llama_index_demo.ipynb,如下所示,OPENAI_API_BASE是可选的。
java
import os
os.environ["OPENAI_API_KEY"] = ""
os.environ["OPENAI_API_BASE"] = ""十、使用 Gravitino 并已获得 Ranger 授权
Gravitino 支持使用 Ranger 插件为 Hive 表提供访问控制功能。
例如,您的公司有一位经理和若干员工。经理创建 Hive 目录并创建不同的角色。经理可以将不同的角色分配给不同的员工。
你可以运行该命令:
bash
./playground.sh start --enable-ranger演示程序位于该jupyter文件夹中,您可以 gravitino-access-control-example.ipynb 通过 Jupyter Notebook访问 http://localhost:18888 打开演示程序。
十一、使用 Gravitino Iceberg REST 服务器进行访问控制
Gravitino 1.1 为 Iceberg REST 服务器引入了内置访问控制功能,无需 Ranger 等外部授权服务即可对 Iceberg 表进行细粒度授权。此功能允许通过 Gravitino 的统一 API 管理用户权限,并在 REST API 层实现原生访问控制。
安全提示(身份验证) :此处所示的 Iceberg REST 目录示例仅使用 HTTP 基本身份验证作为传输方式,通过Authorization请求头传递用户名。Gravitino 目前不验证基本身份验证密码 ,而是完全信任请求头中提供的用户名来进行访问控制决策。因此,此机制无法提供真正的身份验证:任何能够访问 REST 端点的客户端都可以通过在请求头中选择用户名来冒充任何用户。
此行为仅供本地/演示环境使用 (例如运行 Playground 时),不得在生产环境或任何暴露给不受信任客户端的环境中依赖 。为了确保安全部署,必须在 Iceberg REST 服务器前端部署真正的身份验证机制(例如,身份验证反向代理、API 网关或其他身份提供程序),并配置 Gravitino 来验证已认证的身份,而不是信任请求Authorization头中的任意用户名。
演示步骤
步骤 1:启动 Playground 并启用身份验证
bash
./playground.sh start --enable-auth注意 :该--enable-auth标志通过移除 PassThroughAuthorizer 来启用 Gravitino 的访问控制,从而允许对 Iceberg REST 目录进行适当的权限强制执行。
步骤 2:创建用户
通过 Gravitino 的 REST API 创建用户:
bash
# 添加管理员(manager)用户
curl -X POST -H "Accept: application/vnd.gravitino.v1+json" \
-H "Content-Type: application/json" \
-d '{"name":"manager"}' \
http://localhost:8090/api/metalakes/metalake_demo/users
# 添加数据分析师(data_analyst)用户
curl -X POST -H "Accept: application/vnd.gravitino.v1+json" \
-H "Content-Type: application/json" \
-d '{"name":"data_analyst"}' \
http://localhost:8090/api/metalakes/metalake_demo/users
# 将管理员设置为 metalake 的所有者
curl -X PUT -H "Accept: application/vnd.gravitino.v1+json" \
-H "Content-Type: application/json" \
-d '{"name":"manager","type":"USER"}' \
http://localhost:8090/api/metalakes/metalake_demo/owners/metalake/metalake_demo步骤 3:创建数据库和包含管理器的表
登录到 Spark 容器:
bash
docker exec -it playground-spark bash以管理器身份启动 spark-sql:
bash
cd /opt/spark && /bin/bash bin/spark-sql --conf spark.sql.catalog.catalog_rest.rest.auth.type=basic --conf spark.sql.catalog.catalog_rest.rest.auth.basic.username=manager --conf spark.sql.catalog.catalog_rest.rest.auth.basic.password=123创建数据库和表:
sql
USE catalog_rest;
CREATE DATABASE IF NOT EXISTS demo_db;
USE demo_db;
CREATE TABLE IF NOT EXISTS employees (
employee_id INT,
name STRING,
department STRING,
salary DECIMAL(10,2)
) USING iceberg;
INSERT INTO employees VALUES
(1, 'Alice Johnson', 'Engineering', 95000.00),
(2, 'Bob Smith', 'Sales', 75000.00);
SELECT * FROM employees;步骤 4:授予权限前测试访问控制
退出 spark-sql 并以 data_analyst 身份(暂无任何权限)启动一个新会话:
bash
export HADOOP_USER_NAME=data_analyst
cd /opt/spark
/bin/bash bin/spark-sql --conf spark.sql.catalog.catalog_rest.rest.auth.type=basic --conf spark.sql.catalog.catalog_rest.rest.auth.basic.username=data_analyst --conf spark.sql.catalog.catalog_rest.rest.auth.basic.password=123尝试查询该表(此操作应该失败):
sql
USE catalog_rest.demo_db;
-- 这应该失败 - 模式不存在,因为我们没有 USE_SCHEMA 权限步骤 5:创建具有权限的角色并分配给用户
退出 spark-sql 并创建一个具有必要权限的角色:
bash
# 创建具有所有必需权限的角色
curl -X POST -H "Accept: application/vnd.gravitino.v1+json" \
-H "Content-Type: application/json" \
-u manager:123 \
-d '{
"name": "analyst_role",
"securableObjects": [
{
"fullName": "catalog_iceberg",
"type": "CATALOG",
"privileges": [
{"name": "USE_CATALOG", "condition": "ALLOW"}
]
},
{
"fullName": "catalog_iceberg.demo_db",
"type": "SCHEMA",
"privileges": [
{"name": "USE_SCHEMA", "condition": "ALLOW"}
]
},
{
"fullName": "catalog_iceberg.demo_db.employees",
"type": "TABLE",
"privileges": [
{"name": "SELECT_TABLE", "condition": "ALLOW"}
]
}
]
}' \
http://localhost:8090/api/metalakes/metalake_demo/roles
# 为用户分配角色
curl -X PUT -H "Accept: application/vnd.gravitino.v1+json" \
-H "Content-Type: application/json" \
-u manager:123 \
-d '{
"roleNames": ["analyst_role"]
}' http://localhost:8090/api/metalakes/metalake_demo/permissions/users/data_analyst/grant以 data_analyst 用户身份再次启动 spark-sql 并进行测试:
bash
cd /opt/spark && /bin/bash bin/spark-sql \
--conf spark.sql.catalog.catalog_rest.rest.auth.type=basic \
--conf spark.sql.catalog.catalog_rest.rest.auth.basic.username=data_analyst \
--conf spark.sql.catalog.catalog_rest.rest.auth.basic.password=123请再次尝试查询该表(这次应该会成功):
sql
USE catalog_rest.demo_db;
-- 这样应该会成功 - 现在拥有SELECT_TABLE权限
SELECT * FROM employees;这演示了 Gravitino 的访问控制是如何工作的:
- 授予权限前:访问被拒绝
- 授予权限后:访问已允许
更多详情请参阅官方文档:Gravitino 文档![]() https://gravitino.apache.org/docs/latest/security/access-control。
https://gravitino.apache.org/docs/latest/security/access-control。
十二、使用 Gravitino 策略、统计信息和作业删除未使用的表
Gravitino 1.0+ 提供了强大的策略、统计和作业组合,可实现数据治理任务的自动化。本演示展示了如何识别并删除长期未访问的表,从而帮助您管理数据生命周期并降低存储成本。
工作流程概述:
- 统计信息 - 使用自定义统计信息跟踪表格使用情况(例如:
custom-lastAccessTime) - 策略- 定义用于识别未使用表(例如:90 天未访问的表)的规则
- 作业- 执行自动化操作以删除未使用的表
演示步骤:
步骤 1**:启动Playground**
bash
./playground.sh start步骤 2:更新现有表的统计信息
Playground 中已经存在 Hive 目录中的表。我们将使用其中一个现有表,并更新其统计信息来模拟一个旧的、未使用的表:
bash
# 首先,验证现有表
docker exec -it playground-trino trino --execute "SELECT * FROM catalog_hive.sales.customers LIMIT 5"
# 计算100天前的日期(超过90天的阈值)
OLD_DATE=$(date -u -d '100 days ago' +%Y-%m-%dT%H:%M:%SZ 2>/dev/null || date -u -v-100d +%Y-%m-%dT%H:%M:%SZ)
# 更新表的最后访问时间,使其显示为未使用
curl -X PUT -H "Accept: application/vnd.gravitino.v1+json" \
-H "Content-Type: application/json" \
-d "{
\"updates\": {
\"custom-lastAccessTime\": \"$OLD_DATE\",
\"custom-rowCount\": \"10\"
}
}" \
http://localhost:8090/api/metalakes/metalake_demo/objects/table/catalog_hive.sales.customers/statistics
# 检查统计数据以验证它们是否已设置
curl -X GET -H "Accept: application/vnd.gravitino.v1+json" \
http://localhost:8090/api/metalakes/metalake_demo/objects/table/catalog_hive.sales.customers/statistics你应该看到类似这样的输出:
bash
{
"statistics": {
"custom-lastAccessTime": {
"value": "2024-09-08T10:30:00Z"
},
"custom-rowCount": {
"value": "10"
}
}
}步骤 3:创建未使用表的策略
创建自定义策略,以识别超过 90 天未访问的表:
bash
curl -X POST -H "Accept: application/vnd.gravitino.v1+json" \
-H "Content-Type: application/json" \
-d '{
"name": "unused_table_policy",
"comment": "Policy to identify tables not accessed for 90+ days",
"policyType": "custom",
"enabled": true,
"content": {
"customRules": {
"maxIdleDays": 90,
"action": "drop"
},
"supportedObjectTypes": ["TABLE"],
"properties": {
"checkStatistic": "custom-lastAccessTime",
"threshold": "90d"
}
}
}' \
http://localhost:8090/api/metalakes/metalake_demo/policies步骤 4**:将策略与表关联**
将该策略与现有客户表关联:
bash
# 将策略与客户表关联
curl -X POST -H "Accept: application/vnd.gravitino.v1+json" \
-H "Content-Type: application/json" \
-d '{
"policiesToAdd": ["unused_table_policy"]
}' \
http://localhost:8090/api/metalakes/metalake_demo/objects/table/catalog_hive.sales.customers/policies
# 验证策略已关联
curl -X GET -H "Accept: application/vnd.gravitino.v1+json" \
http://localhost:8090/api/metalakes/metalake_demo/objects/table/catalog_hive.sales.customers/policies或者,您可以将该策略与整个架构关联起来,以监控所有表:
bash
# 与整个架构关联(将应用于销售中的所有表)
curl -X POST -H "Accept: application/vnd.gravitino.v1+json" \
-H "Content-Type: application/json" \
-d '{
"policiesToAdd": ["unused_table_policy"]
}' \
http://localhost:8090/api/metalakes/metalake_demo/objects/schema/catalog_hive.sales/policies步骤 5:注册一个job模板以删除未使用的表
创建job模板用于删除表的 shell 脚本:
bash
# 首先,在主机上创建删除脚本
cat > /tmp/drop_unused_tables.sh << 'EOF'
#!/bin/bash
# 根据策略评估删除未使用表的脚本
CATALOG=$1
SCHEMA=$2
TABLE=$3
echo "正在检查是否应删除表${CATALOG}.${SCHEMA}.${TABLE}..."
# 获取表统计信息(由于脚本在主机上运行或在具有端口映射的容器中运行,因此使用本地主机)
STATS=$(curl -s -X GET -H "Accept: application/vnd.gravitino.v1+json" \
"http://localhost:8090/api/metalakes/metalake_demo/objects/table/${CATALOG}.${SCHEMA}.${TABLE}/statistics")
echo "统计响应:$STATS"
# 解析统计数组以查找custom-lastAccessTime
LAST_ACCESS=$(echo $STATS | jq -r '.statistics[] | select(.name=="custom-lastAccessTime") | .value')
echo "最后访问时间:$LAST_ACCESS"
# 计算自上次访问以来的天数
if [ -n "$LAST_ACCESS" ] && [ "$LAST_ACCESS" != "null" ]; then
CURRENT_DATE=$(date +%s)
LAST_ACCESS_DATE=$(date -d "$LAST_ACCESS" +%s 2>/dev/null || date -j -f "%Y-%m-%dT%H:%M:%SZ" "$LAST_ACCESS" +%s)
DAYS_IDLE=$(( ($CURRENT_DATE - $LAST_ACCESS_DATE) / 86400 ))
echo "自上次访问以来的天数:$DAYS_IDLE"
if [ $DAYS_IDLE -gt 90 ]; then
echo "表已闲置超过90天。正在删除表..."
# 通过Gravitino API删除表
DROP_RESPONSE=$(curl -s -X DELETE -H "Accept: application/vnd.gravitino.v1+json" \
"http://localhost:8090/api/metalakes/metalake_demo/catalogs/${CATALOG}/schemas/${SCHEMA}/tables/${TABLE}")
echo "丢弃响应:$DROP_RESPONSE"
echo "表${CATALOG}.${SCHEMA}.${TABLE}已成功删除"
else
echo "表格仍处于活动状态,无需采取任何行动。"
fi
else
echo "未找到最后访问时间。跳过..."
fi
EOF
chmod +x /tmp/drop_unused_tables.sh
# 将脚本复制到Gravitino容器中
docker cp /tmp/drop_unused_tables.sh playground-gravitino:/tmp/drop_unused_tables.sh
# 使其在容器中可执行
docker exec playground-gravitino chmod +x /tmp/drop_unused_tables.sh
# 注册job模板
curl -X POST -H "Accept: application/vnd.gravitino.v1+json" \
-H "Content-Type: application/json" \
-d '{
"jobTemplate": {
"name": "drop_unused_table_job",
"jobType": "shell",
"comment": "Job to drop unused tables based on policy",
"executable": "file:///tmp/drop_unused_tables.sh",
"arguments": ["{{catalog}}", "{{schema}}", "{{table}}"],
"environments": {},
"customFields": {},
"scripts": []
}
}' \
http://localhost:8090/api/metalakes/metalake_demo/jobs/templates步骤 6:运行作业以删除未使用的表
执行客户表(customers)的job:
bash
# 运行客户表(customers)的job(由于该表已超过90天,应删除)
curl -X POST -H "Accept: application/vnd.gravitino.v1+json" \
-H "Content-Type: application/json" \
-d '{
"jobTemplateName": "drop_unused_table_job",
"jobConf": {
"catalog": "catalog_hive",
"schema": "sales",
"table": "customers"
}
}' \
http://localhost:8090/api/metalakes/metalake_demo/jobs/runs响应中将包含一个jobRunId可用于检查作业状态的标识符。
步骤 7:验证工作结果
检查job执行状态和结果:
bash
# 获取job运行详情(将 {jobRunId} 替换为步骤 6 响应中的实际 ID)
curl -X GET -H "Accept: application/vnd.gravitino.v1+json" \
http://localhost:8090/api/metalakes/metalake_demo/jobs/runs/{jobRunId}
# 示例:如果jobRunId为"job-123"
curl -X GET -H "Accept: application/vnd.gravitino.v1+json" \
http://localhost:8090/api/metalakes/metalake_demo/jobs/runs/job-123响应将显示:
- 状态 :作业状态(
QUEUED,,,,,RUNNING)SUCCEEDED``FAILED``CANCELLING``CANCELLED - startTime:作业开始的时间
- endTime:作业完成时间
- 输出:作业执行输出/日志
还可以验证该表是否确实已被删除:
bash
# 检查表格是否仍然存在(应该显示已删除)
docker exec -it playground-trino trino --execute "SHOW TABLES FROM catalog_hive.sales"
# 或者尝试查询已删除的表(应该会因"表未找到"而失败)
docker exec -it playground-trino trino --execute "SELECT * FROM catalog_hive.sales.customers LIMIT 1"如果表已成功删除,您将看到类似如下的错误信息:
sql
Query failed: line 1:15: Table 'hive.sales.customers' does not exist关键概念:
- 统计信息 :跟踪自定义指标,例如
custom-lastAccessTime监控表格使用情况 - 策略:定义治理规则,以识别符合特定条件的表(例如,闲置 90 天以上)。
- 任务:根据策略评估执行自动化操作(删除表)
- 元数据驱动的操作:利用 Gravitino 的元数据(统计数据、策略)来驱动数据治理决策。
这种方法可以实现:
- ✅ 自动化数据生命周期管理
- ✅ 通过删除未使用的数据来降低成本
- ✅ 遵守数据保留政策
- ✅ 跨多个目录的集中管理
更多详情请参考官网:
- 在 Gravitino 中管理统计数据
 https://gravitino.apache.org/docs/latest/manage-statistics-in-gravitino
https://gravitino.apache.org/docs/latest/manage-statistics-in-gravitino - 在 Gravitino 中管理策略https://gravitino.apache.org/docs/latest/manage-policies-in-gravitino
- 在 Gravitino 中管理工作https://gravitino.apache.org/docs/latest/manage-jobs-in-gravitino
十三、注意
如果要清除缓存文件,可以删除data此仓库的目录。
最新的 Gravitino 文档可在官方地址获取。gravitino.apache.org/docs/latest![]() https://gravitino.apache.org/docs/latest/
https://gravitino.apache.org/docs/latest/