文章目录
-
- 前言
- 一、理解基础:大模型如何处理输入和生成输出
-
- [1.1 大模型处理的是 token,不是直接处理文字**](#1.1 大模型处理的是 token,不是直接处理文字**)
-
- [1.1.1 那么什么是 token?](#1.1.1 那么什么是 token?)
- [1.1.2 大模型输入输出的流程](#1.1.2 大模型输入输出的流程)
- [1.2 模型不是一次性生成完整答案**](#1.2 模型不是一次性生成完整答案**)
-
- [1.2.1 自回归预测](#1.2.1 自回归预测)
- [1.2.2 采样技术](#1.2.2 采样技术)
- [1.3 一次请求通常有两个阶段**](#1.3 一次请求通常有两个阶段**)
- [二、理解 KV Cache:Transformer 内部的缓存机制](#二、理解 KV Cache:Transformer 内部的缓存机制)
-
- [2.1 Transformer 中的 Q、K、V 是什么](#2.1 Transformer 中的 Q、K、V 是什么)
- [2.2 为什么需要缓存 Key 和 Value](#2.2 为什么需要缓存 Key 和 Value)
- [三、理解 Prompt Caching](#三、理解 Prompt Caching)
-
- [3.1 Prompt Caching 是什么](#3.1 Prompt Caching 是什么)
- [3.2 Prompt Caching 和 KV Cache 的关系](#3.2 Prompt Caching 和 KV Cache 的关系)
- [3.3 Prompt Caching机制](#3.3 Prompt Caching机制)
- [3.4 Prompt Caching 是谁在做](#3.4 Prompt Caching 是谁在做)
- [3.5 Agent 负责"让 prompt 更容易被缓存"](#3.5 Agent 负责“让 prompt 更容易被缓存”)
- [四、Claude Code 的 Prompt Caching 技术脉络](#四、Claude Code 的 Prompt Caching 技术脉络)
-
- [4.1 Claude Code 为什么特别依赖 Prompt Caching](#4.1 Claude Code 为什么特别依赖 Prompt Caching)
- [4.2 五个技术脉络](#4.2 五个技术脉络)
- [五、Prompt Caching 的应用场景](#五、Prompt Caching 的应用场景)
- 六、参考资料
- 总结
前言
Claude Code 这类编程 Agent 为什么能在长上下文、多轮对话、频繁工具调用中保持相对可用的速度和成本?一个关键答案是:Prompt Caching。
它并不是简单地缓存模型回答,而是缓存模型处理稳定 prompt 前缀时产生的中间状态,让后续请求不必反复计算相同的系统提示、工具定义、项目文档和历史上下文。
本文会从大模型的 token 生成机制讲起,逐步解释 KV Cache、Prompt Caching 以及它们之间的关系,再梳理 Claude Code 如何通过 prompt 编排、工具设计、模型选择和上下文压缩来提高缓存命中率。
最后也会讨论一个现实问题:如果把 Claude Code 底层模型换成其他模型或 API,缓存机制是否还会生效。
一、理解基础:大模型如何处理输入和生成输出
1.1 大模型处理的是 token,不是直接处理文字**
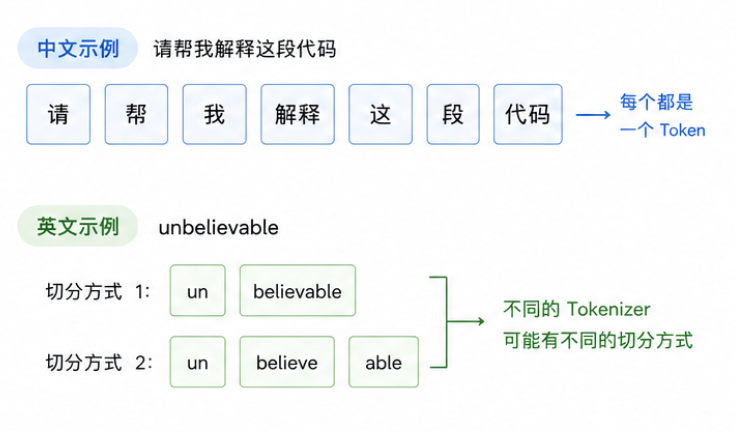
我们平时看到的是自然语言文本,比如:
请帮我解释这段代码
但模型真正接收的不是这句话本身,而是 tokenizer 切分后的 token 序列。
1.1.1 那么什么是 token?
可以先粗略理解为:
Token 是大模型处理文本时使用的最小输入单位。它可能是一个汉字、一个英文单词、一个词的一部分、一个标点符号,甚至是一段常见字符组合。
1.1.2 大模型输入输出的流程
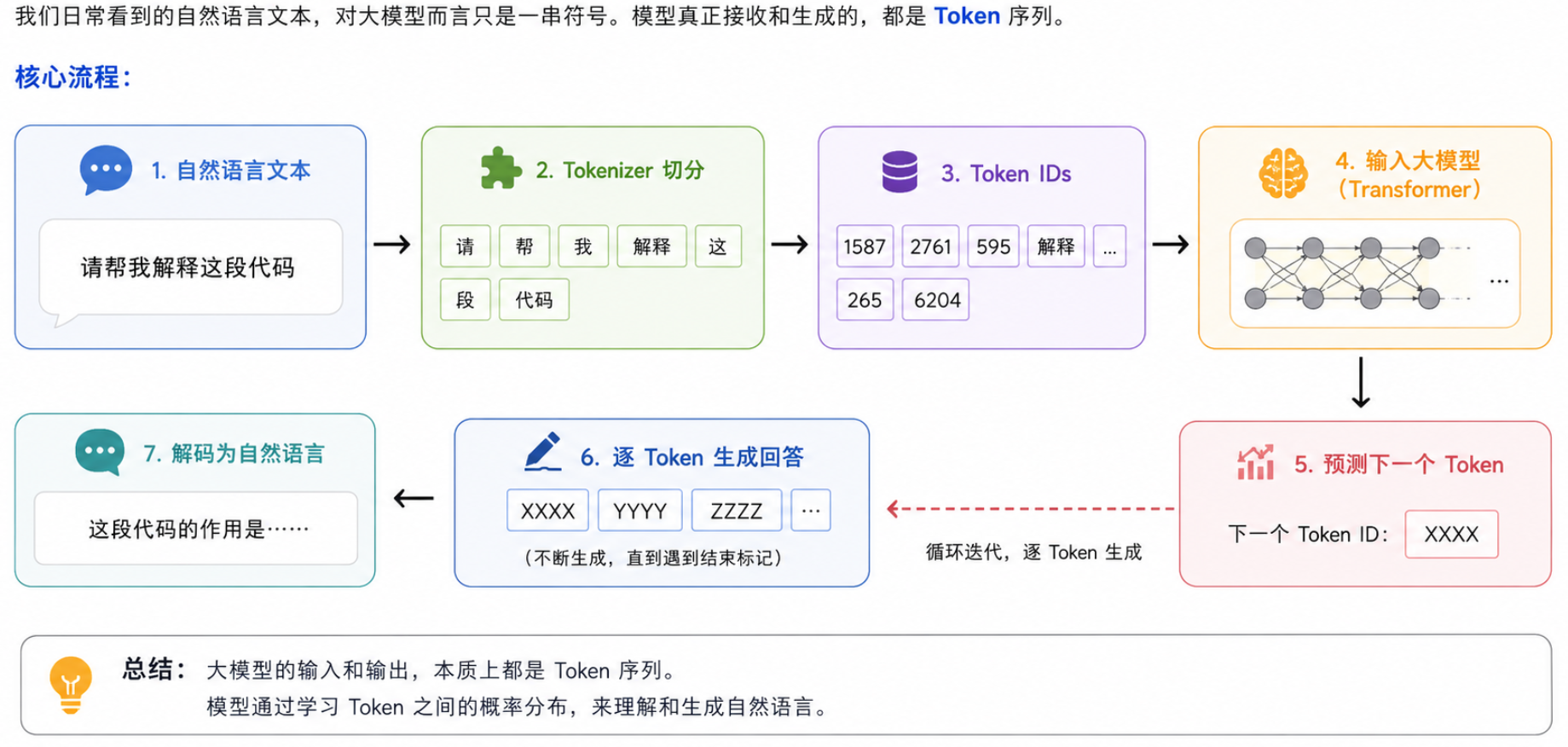
大语言模型在回答我们的问题时,流程大概是:
- 输入文本:接收自然语言(e.g., "请帮我解释...")。
- Tokenizer 切分:Tokenizer 将文本切分为最小语义单元(Tokens)。
- Token IDs 转换:每个 Token 被映射为词表中的唯一数字索引(Token IDs)。
- 输入 Transformer 模型:这串数字序列作为模型的真实输入。
- 模型预测:Transformer 根据当前序列,预测下一个最可能出现的 Token ID。
- 逐 Token 生成:预测出的 Token 被加入序列,不断重复,最终生成完整的回答。
简而言之,大模型的输入和输出,在本质上都是 Token 序列。
1.2 模型不是一次性生成完整答案**
1.2.1 自回归预测
大语言模型(LLM)生成回答并非瞬间完成,而是采用一种称为**自回归(Autoregressive)**的方式,一个 token 一个 token 地逐步构建。其核心循环过程如下:
- 输入上下文:模型首先接收当前的上下文(包括 prompt 和已生成的所有 token)。
- 预测概率分布 :模型分析上下文,输出对下一个可能 token 的完整概率分布(Probability Distribution)。
- 采样选择:模型根据设定的参数,从该概率分布中采样(Sample)选出一个 token。
- 更新上下文:将选出的新 token 追加到旧上下文的末尾,形成新的上下文。
- 重复循环:新的上下文作为输入,再次执行上述步骤。
- 生成结束 :这个循环会一直持续,直到模型预测出特定的结束标记(End-of-Sequence token,
<EOS>)。

因此,我们可以给出一个更准确的技术定义:大语言模型本质上是一个基于已有 token 序列,迭代地预测下一个 token 概率分布的统计模型。
1.2.2 采样技术
虽然模型输出了一个完整的概率分布,但实际生成时并不一定永远选择概率最高的那个 token。
为了引入多样性、创造性或避免陷入死循环,模型使用了采样(Sampling)技术。
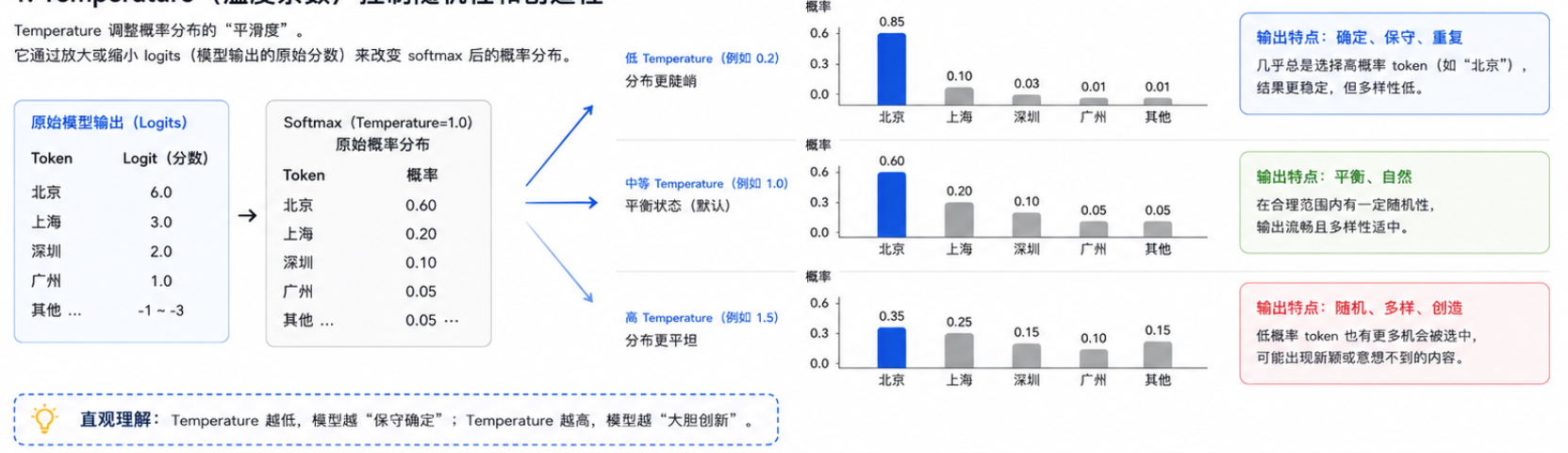
同一个 Prompt 有时会生成不同的回答,关键在于以下两个核心参数对采样过程的控制:
-
Temperature(温度系数):
- 低 Temperature(例如 0.2) :使概率分布更加陡峭(对高概率 token 更有利),导致输出更加确定(Deterministic)、保守和重复。
- 高 Temperature(例如 1.0) :使概率分布更加平坦,给予低概率 token 更多机会,导致输出更加随机(Random)、多样和创造。
-
Top-P(Nucleus Sampling,核心采样):
- 模型不从所有可能的 token 中采样,而是仅从累积概率之和超过设定阈值
P(例如 0.9)的"核心" token 集合中进行采样。 - 这可以过滤掉极端低概率的长尾 token,同时保留高概率 token 之间的合理随机性。
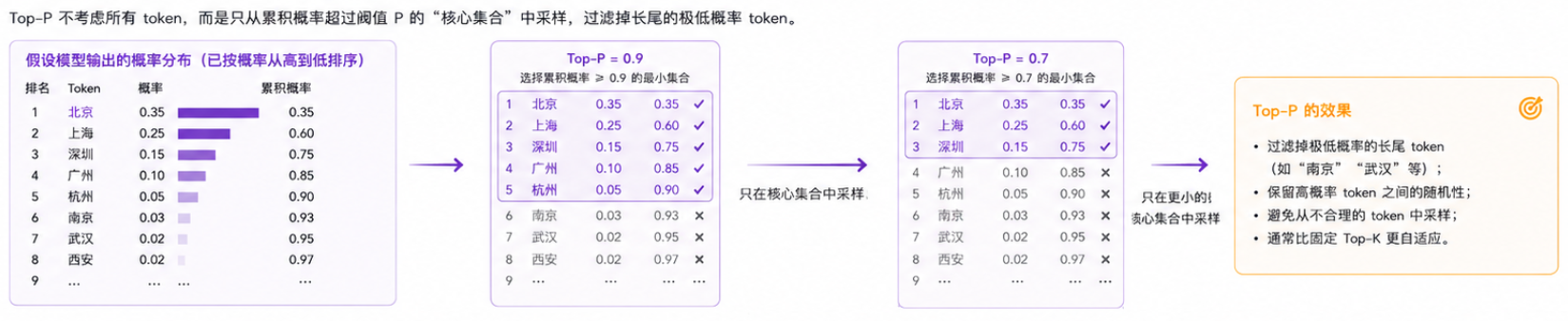
- 模型不从所有可能的 token 中采样,而是仅从累积概率之和超过设定阈值
1.3 一次请求通常有两个阶段**
大模型推理通常可以分成两个阶段:
- Prefill 阶段:处理输入 prompt,读完整个上下文。
- Decode 阶段:一个 token 一个 token 生成输出。
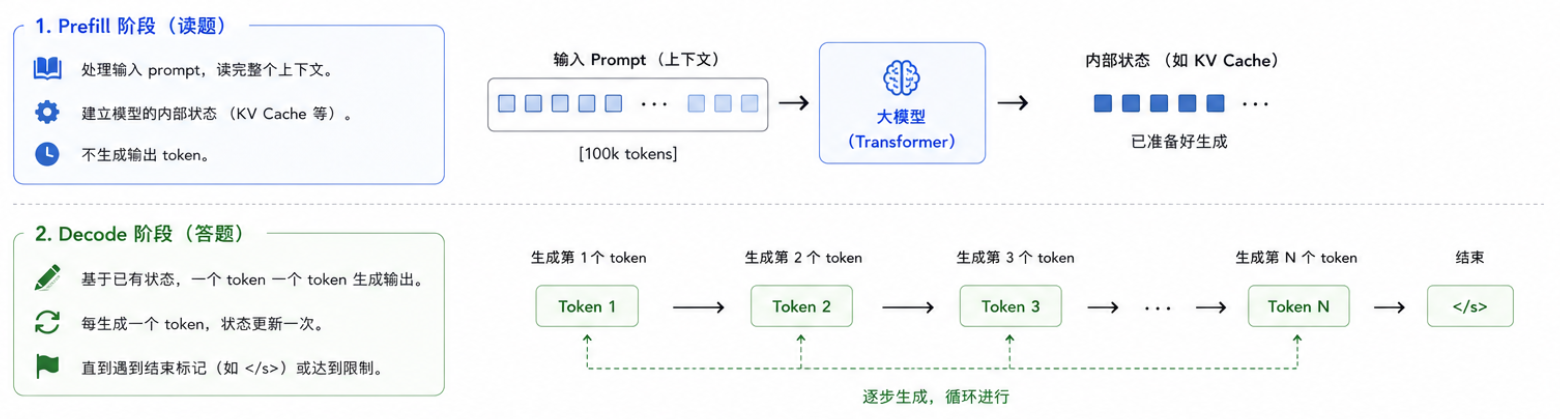
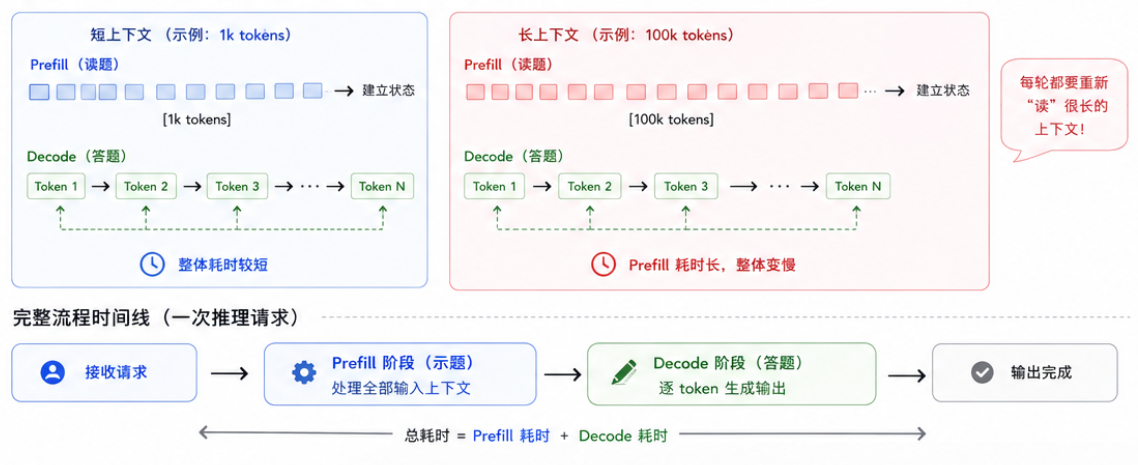
长上下文 Agent 变慢,很多时候慢在 Prefill 阶段:模型每一轮都要重新"读"一遍很长的上下文。
二、理解 KV Cache:Transformer 内部的缓存机制
2.1 Transformer 中的 Q、K、V 是什么
要理解 Prompt Caching,需要先理解 KV Cache。
Transformer 的注意力机制中,每个 token 会产生三类向量:
- Q = Query:查询,我现在想找什么信息?
- K = Key:索引,我这里有什么信息,别人怎么找到我?
- V = Value:内容,如果别人关注我,实际拿走什么信息?
注意,这里的 Key 和 Value 不是数据库里的键值对,而是神经网络里的向量表示。
可以用一个简单比喻理解:
Query 像问题,Key 像标签,Value 像内容。
当前 token 会用自己的 Query 去匹配前面 token 的 Key。
匹配度越高,说明当前 token 越应该关注那个历史 token,然后取用对应的 Value。
2.2 为什么需要缓存 Key 和 Value
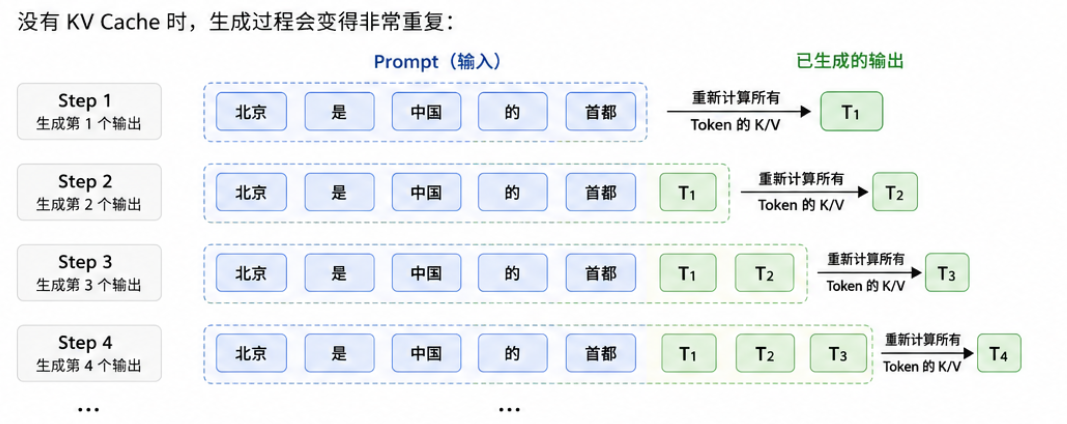
假设模型正在处理:
text
北京 是 中国 的 首都当模型要预测后续 token 时,它需要回看前面的 token:
text
当前 Query vs "北京"的 Key
当前 Query vs "中国"的 Key
当前 Query vs "首都"的 Key这些历史 token 的 Key 和 Value 已经算过了。如果每生成一个新 token,都重新计算所有历史 token 的 Key/Value,会非常浪费。
所以推理系统会把已经算过的 Key/Value 存起来,这就是 KV Cache。
没有 KV Cache 时,生成过程会变得非常重复:
有 KV Cache 后,流程变成:
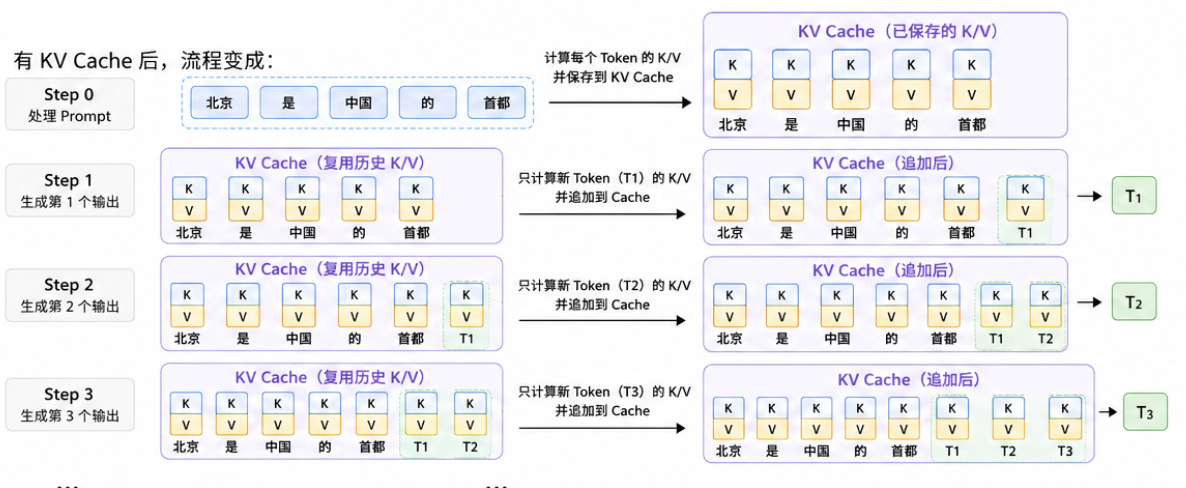
所以 KV Cache 解决的是:
在单次请求内部,生成后续 token 时,不要反复重算前面 token 的 Key/Value。
它是 Transformer 推理中的底层优化机制。
三、理解 Prompt Caching
3.1 Prompt Caching 是什么
Prompt Caching 比 KV Cache 更上一层。
KV Cache 通常发生在一次请求内部;Prompt Caching 是把"相同 prompt 前缀"的计算结果跨请求复用。
一句话定义:
Prompt Caching 是把已经处理过的一大段相同 prompt 前缀对应的模型内部状态缓存起来,下次遇到同样前缀时直接复用,而不是重新从第一个 token 算一遍。
这里非常重要:Prompt Caching 缓存的不是最终答案。
普通答案缓存是:
text
用户问 A
模型答 B
下次用户又问 A
直接返回 B这叫 response cache 或 answer cache。
Prompt Caching 不是这样。Prompt Caching 缓存的是模型处理输入 prompt 时产生的中间计算状态。
举一个具体例子
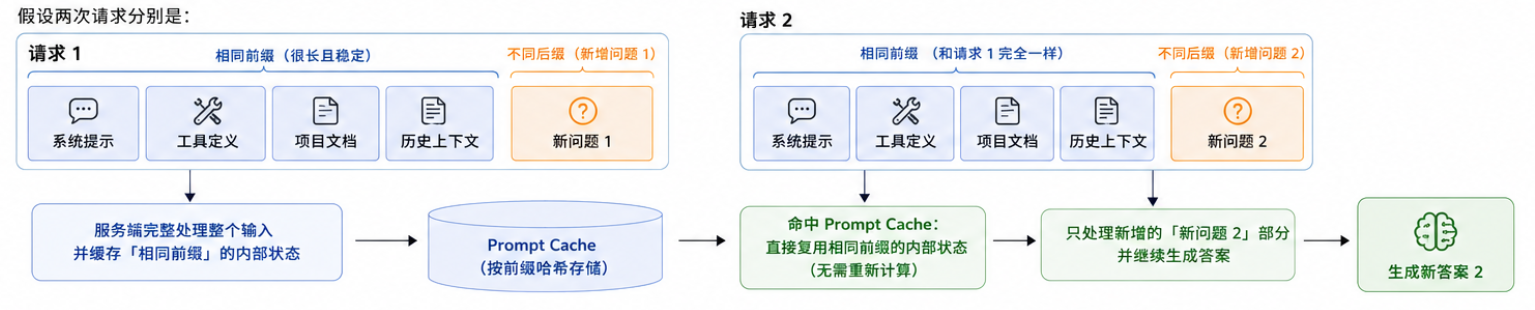
text
[系统提示 + 工具定义 + 项目文档 + 历史上下文]第一次请求时,服务端完整处理这段内容,并保存它对应的内部计算结果。
第二次请求时,服务端发现前缀一样,就可以直接复用之前保存的内部状态,只处理后面新增的"新问题 2"。
所以模型仍然会正常生成新答案,只是不用重复计算前面那一大段稳定上下文。
3.2 Prompt Caching 和 KV Cache 的关系
可以这样理解:
- KV Cache = 单次模型推理时,真正被保存和复用的模型中间状态
- Prompt Caching =多次api请求时, 判断之前请求中哪些 prompt 前缀可以跨请求复用的工程机制
它们的关系可以总结成表格:
| 概念 | 作用范围 | 缓存内容 | 解决问题 |
|---|---|---|---|
| KV Cache | 单次请求内部 | 历史 token 的 Key/Value 张量 | 生成新 token 时不用重算历史 |
| Prompt Caching | 多次请求之间 | 相同 prompt 前缀对应的内部状态,通常包含 KV 表示 | 多轮请求不用重复处理相同长上下文 |
| Response Cache | 应用层 | 最终回答文本 | 相同问题直接返回旧答案 |
3.3 Prompt Caching机制
一个简化版 Prompt Caching 实现流程如下:
- 接收 prompt
- tokenizer 把 prompt 转成 token IDs
- 从开头开始把 token 切成若干 block
- 对 block 计算 hash
- 查询缓存表,看这些 block 是否出现过
- 找到最长可复用前缀
- 命中部分:加载已有 KV Cache
- 未命中部分:正常执行 Transformer prefill
- 进入 decode 阶段,逐 token 生成答案
- 把新计算出的 KV Cache 写回缓存
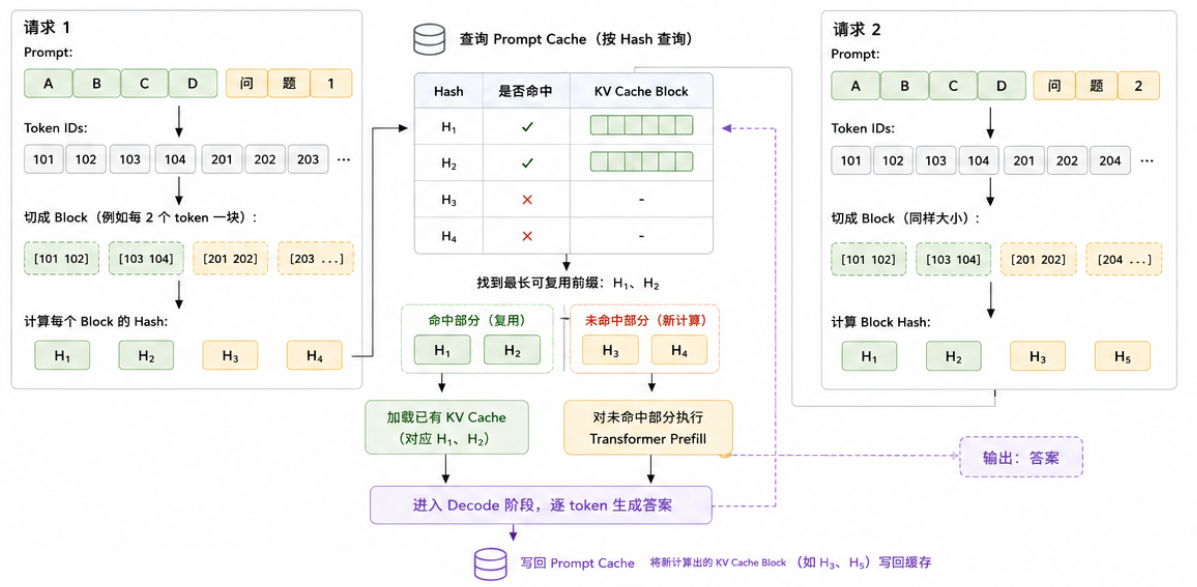
这里最关键的是"最长可复用前缀"。
因为 Transformer 是因果模型,后面的 token 依赖前面的 token。如果前面某个位置变了,后面即使文字相同,内部状态也可能不同。
Prompt Caching 整体架构图如下:
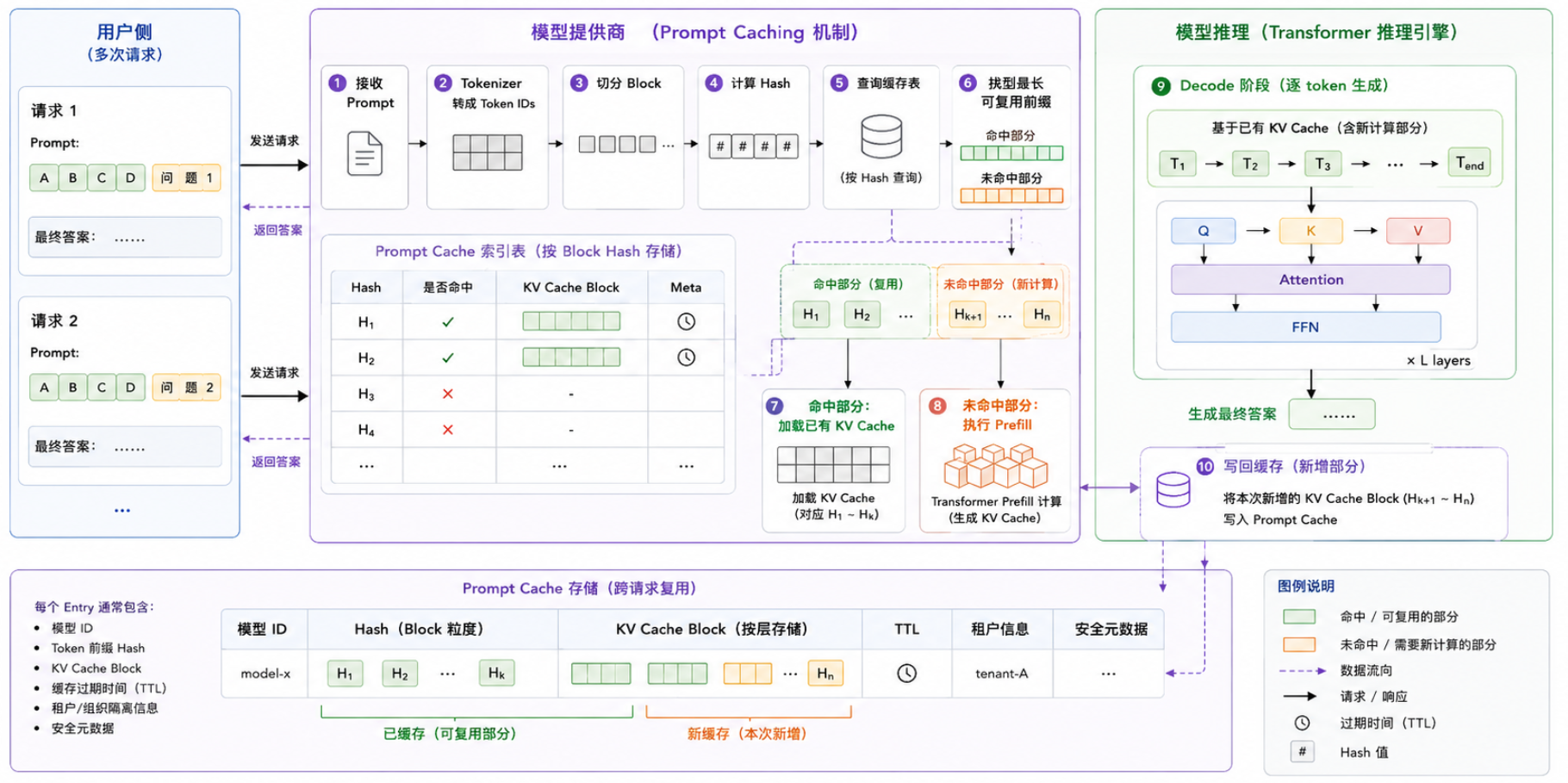
3.4 Prompt Caching 是谁在做
一个常见误解是:模型自己记住了上次的 prompt。
实际上不是。
模型本身,比如 Qwen、Llama、DeepSeek、Claude、GPT,主要负责根据 token 计算下一个 token 的概率分布。
Prompt Caching 通常是模型外层的推理服务系统做的。
可以理解为:
prompt Caching 不是模型权重本身做的,也不是用户应用直接做的,而是 API 服务商或推理框架 在做。
例如:
- 使用 Claude API:Anthropic 服务端负责缓存机制。
- 使用 OpenAI API:OpenAI 服务端负责缓存机制。
- 使用 DeepSeek API:DeepSeek 服务端负责 Context Caching。
- 自己部署模型:vLLM / SGLang / TensorRT-LLM / LMCache 等推理框架负责类似机制。
Anthropic 文档明确说 Prompt Caching 会缓存 KV cache representations 和 cryptographic hashes,不是原始 prompt 或回答文本:https://platform.claude.com/docs/en/build-with-claude/prompt-caching
DeepSeek 官方文档也说,它的 Context Caching 是 API 侧默认启用的硬盘缓存技术,后续请求如果和之前请求有重叠前缀,就可以从缓存取出对应部分:https://api-docs.deepseek.com/guides/kv_cache
3.5 Agent 负责"让 prompt 更容易被缓存"
当我们使用Claude Code 这样的 Agent时,Claude Code作为客户端,自己不负责真正保存 KV Cache。它主要负责:
- 组织 prompt
- 保持系统提示稳定
- 保持工具定义稳定
- 把动态内容放到后面
- 必要时使用 cache_control / breakpoint
- 记录 usage 中的缓存命中情况
也就是说,Claude Code 做的是 cache-friendly prompt design。
例如 Claude Code 会尽量做到:
- 静态 system prompt 放前面
- 工具定义放前面且保持稳定
- CLAUDE.md 放在稳定区域
- 动态状态放到后面的 message 或 tool result
- 不要中途乱改工具列表
- 不要中途乱切模型
- compaction 也沿用父会话前缀
这些是 Agent Harness 层的设计。
所以说:
Claude Code作用客户端: 负责组织 cache-friendly prompt。
Anthropic API作为api模型商:负责真正执行 Prompt Caching。
Claude系列大模型:负责推理。、
Prompt Caching 的底层计算和存储是由大模型 API 厂商(如 Anthropic、DeepSeek)处理的;但能不能高效"命中"缓存,完全取决于 Agent(如 Claude Code)的 Prompt 编排架构,这也是agent harness设计的一个重要思考。
因此,看到这一小节就可以回答这个问题了:
"既然 Claude Code 的架构是深度适配 Anthropic 的 Prompt Caching 机制的,那如果我通过修改配置或使用代理,把底层模型换成 DeepSeek(比如 DeepSeek-V4),这种缓存机制会不会失效?性能会不会暴跌?"
咳咳:我没有实验验证所以无法给出确定结论,但是个人想法是也许有些差别,但是不至于暴跌。毕竟:
deepseek不会继承 Anthropic 的缓存;
不会天然共享 Claude 的 KV Cache;
Anthropic cache_control 在 DeepSeek 兼容层会被忽略;
但 DeepSeek 有自己的 Context Caching;
所以不是"必然失效",而是"需要按 DeepSeek 的缓存规则重新命中"。
四、Claude Code 的 Prompt Caching 技术脉络
4.1 Claude Code 为什么特别依赖 Prompt Caching
Claude Code 是一个长时间运行的编程 Agent。它每一轮请求都可能携带大量上下文:
text
系统提示
工具定义
项目 CLAUDE.md
当前任务状态
历史对话
读取过的文件内容
工具调用结果
最新用户输入如果每一轮都重新处理这些内容,成本和延迟都会很高。
所以 Claude Code 的重要经验不是简单"启用了 Prompt Caching",而是:
整个 Agent Harness 的 prompt 组织、工具设计、模式切换和上下文压缩,都围绕 Prompt Caching 设计。
4.2 五个技术脉络
- 前缀匹配是第一性原理:
-
Prompt caching 是 prefix matching。只要前缀中任何位置发生变化,后面的缓存都可能失效;
-
因此 Claude Code 把 prompt 组织成从稳定到动态的顺序:静态系统提示与工具定义、项目级
CLAUDE.md、会话上下文、最后才是对话消息; -
这个顺序的目标是让更多请求共享同一个开头。
-
动态信息尽量放到消息,而不是改系统提示
- system prompt 被改,稳定前缀就变了;
- Claude Code 的做法是把这类更新包进下一条 user message 或 tool result,例如
<system-reminder>,让主前缀保持稳定。
-
不要在会话中途切换模型
- 缓存与模型绑定,即使 prompt 字节完全相同,Opus 和 Haiku 的内部 KV 表示也不同;
- 原文博客指出,在一个已经有 100k token 的 Opus 会话中,为了"便宜地问一个简单问题"切到 Haiku,反而可能更贵;
- 因为 Haiku 需要从零构建自己的缓存,更合理的模式是让父 agent 准备简短 hand-off,再启动子 agent。
-
不要在会话中途增删工具
- 工具定义属于缓存前缀。增删工具看似节约 prompt,实际会破坏整段前缀;
- Claude Code 的 Plan Mode 没有切换成"只读工具集",而是把 EnterPlanMode / ExitPlanMode 设计成工具本身;
- 工具集合保持稳定,状态变化通过消息和工具调用表达。
-
Compaction 也要 cache-safe
- 当上下文快满时,系统需要压缩历史;
- 如果单独发一个"请总结这段对话"的新请求,并换掉系统提示和工具定义,缓存从第一个 token 就失效;
- Claude Code 的做法是"fork 父会话":保留父会话完全相同的系统提示、工具、上下文和历史前缀,只在末尾追加 compaction prompt;
- 这样 compaction 也能复用父会话的缓存;
- Anthropic 的 compaction 文档也强调,服务端 compaction 会在接近阈值时总结旧上下文,并可与 prompt caching 配合使用:https://platform.claude.com/docs/en/build-with-claude/compaction
五、Prompt Caching 的应用场景
Prompt Caching 最直接解决的是长上下文、多轮 agent 的经济性问题。它尤其适合:
- AI 编程助手:代码仓库说明、工具定义、项目约束、历史编辑轨迹会反复出现在每一轮请求中。缓存命中后,模型不用每次重新处理这些稳定上下文。
- 企业知识库问答 / RAG:公司政策、产品手册、合同模板、医学指南等大段上下文可能被许多请求复用。缓存能降低 prefill 延迟。
- 多 agent 调度系统:主 agent、探索 agent、审阅 agent、执行 agent 往往共享相同规则和任务背景。通过 cache-safe hand-off,可以避免每个子 agent 重建巨型上下文。
- 长时任务与会话记忆:研究写作、代码迁移、数据分析、客服工单连续处理都需要长历史。Prompt caching 与 compaction 结合,可以在保留连续性的同时压低成本。
- 边缘设备和 IoT 命令系统:大量自然语言命令只有参数不同,例如"把卧室灯打开""把客厅灯打开"。语义级或代码片段级缓存可以绕开重复 LLM 调用。
- 推理平台调度:服务端可以基于 prefix-aware routing,把请求路由到已经持有对应 KV cache 的 GPU 或推理引擎,减少重复 prefill。
六、参考资料
- Anthropic Claude Code 博客:https://claude.com/blog/lessons-from-building-claude-code-prompt-caching-is-everything
- Anthropic Prompt Caching 文档:https://platform.claude.com/docs/en/build-with-claude/prompt-caching
- Anthropic Compaction 文档:https://platform.claude.com/docs/en/build-with-claude/compaction
- OpenAI Prompt Caching 文档:https://platform.openai.com/docs/guides/prompt-caching
- OpenAI Prompt Caching 介绍:https://openai.com/index/api-prompt-caching/
总结
Prompt Caching 的核心并不复杂:复用相同 prompt 前缀的计算结果,减少长上下文重复 prefill 的成本和延迟。
要理解它,需要先分清几层关系:
- LLM 的输入输出本质上是 token 序列,模型通过自回归方式逐 token 生成答案。
- 一次推理分为 prefill 和 decode 两个阶段,长上下文 Agent 的主要压力往往来自反复处理庞大的输入前缀。
- KV Cache 是单次请求内部的底层缓存,避免生成每个新 token 时重复计算历史 token 的 Key/Value。
- Prompt Caching 是跨请求的工程机制,通过最长相同前缀匹配,把已经计算过的内部状态复用到后续请求中。
- Claude Code 的关键不是"用了缓存",而是整个 Agent Harness 都在围绕缓存命中率设计:稳定系统提示、稳定工具定义、动态内容后置、避免中途切模型或工具集、让 compaction 也尽量复用父会话前缀。
因此,Prompt Caching 不是模型"记住了上次对话",也不是应用层直接返回旧答案,而是 API 服务商或推理框架在模型外层做的推理优化。
对于 Claude Code 来说,Anthropic 负责真正的缓存计算与存储,Claude Code 负责组织更容易命中的 prompt。换成其他底层模型或兼容 API 后,Anthropic 的缓存不会被继承,cache_control 也可能失效;但如果目标服务本身支持类似 Context Caching,仍然有机会通过相同的前缀组织方式获得收益。
最终结论是:
Prompt Caching 是长上下文 Agent 可扩展性的关键基础设施之一。它真正优化的不是"回答",而是反复出现的上下文前缀;而 Agent 的工程能力,很大一部分体现在如何让这些前缀稳定、可复用、容易命中缓存。