作为后端开发,Redis 几乎是每个项目的标配。它凭借极高的读写性能,成为了缓解数据库压力、提升系统响应速度的首选方案。但如果使用不当,Redis 不仅不能提升性能,反而会成为系统的隐患,甚至引发整个服务的雪崩。
缓存穿透、缓存击穿、缓存雪崩,是 Redis 缓存最常见的三大问题,也是面试中 100% 会被问到的高频考点。很多人能背出这三个名词,却搞不清它们的本质区别,也不知道线上遇到时该怎么解决。
这篇文章,我们就从问题本质、产生原因、常见场景、解决方案四个维度,全面拆解这三大缓存问题。不仅会讲清楚理论,还会提供可直接落地的代码示例和线上最佳实践,让你看完既能应对面试,又能解决实际问题。
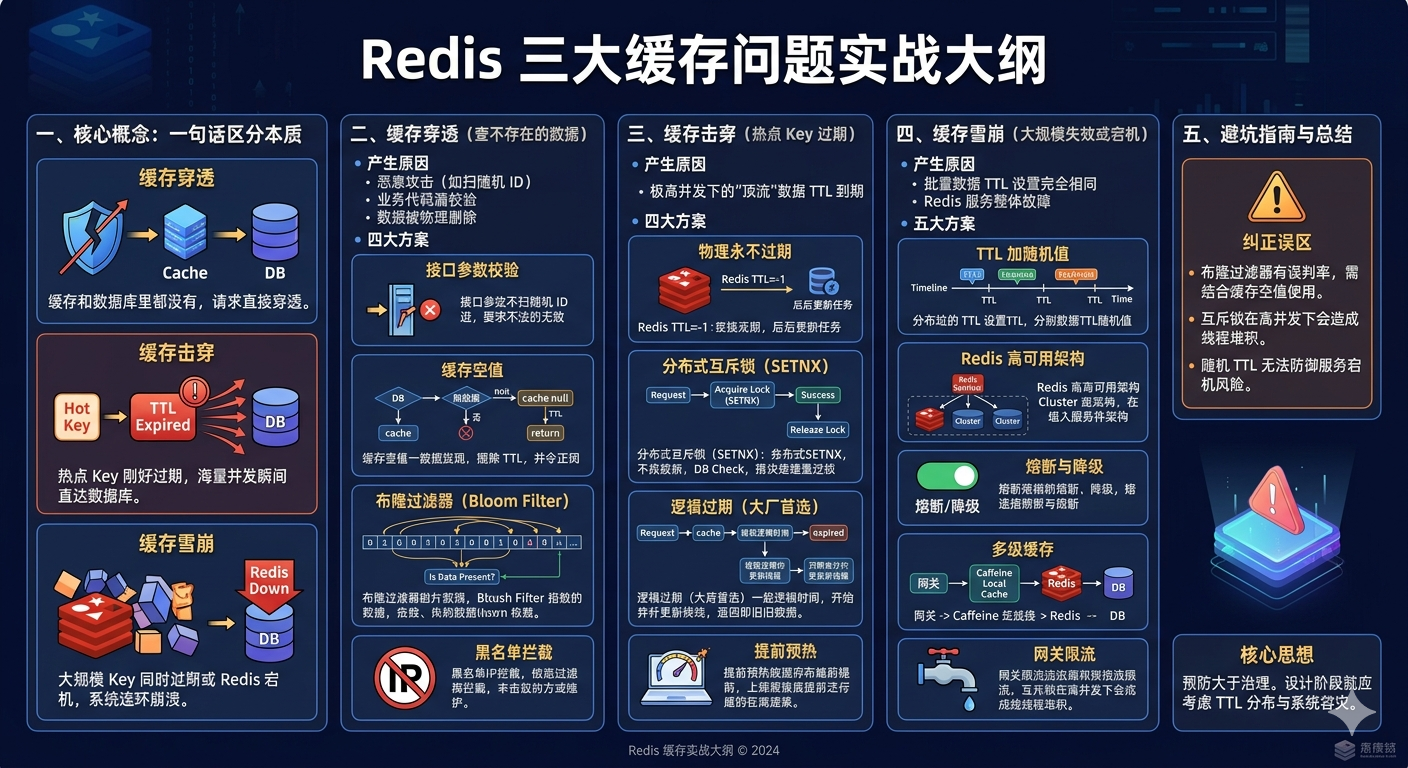
一、先搞懂:三个问题的核心区别
很多人容易混淆这三个问题,其实它们的本质完全不同,一句话就能区分:
- 缓存穿透 :查询数据库和缓存中都不存在的数据,导致请求直接穿透缓存,全部打到数据库。
- 缓存击穿 :一个热点 key 在缓存过期的瞬间,有大量并发请求过来,全部打到数据库。
- 缓存雪崩 :大量 key 同时过期 ,或者Redis 服务宕机,导致所有请求都打到数据库,数据库压力骤增甚至宕机。
用一个简单的比喻来理解:
- 穿透:有人故意去敲你家不存在的门,你每次都要开门看看有没有人。
- 击穿:你家最热门的那个门(比如大门)突然坏了,所有人都挤着要从这个门进去。
- 雪崩:你家所有的门同时坏了,所有人都只能从窗户爬进去,窗户直接被挤爆。
二、缓存穿透:查询不存在的数据
1. 什么是缓存穿透?
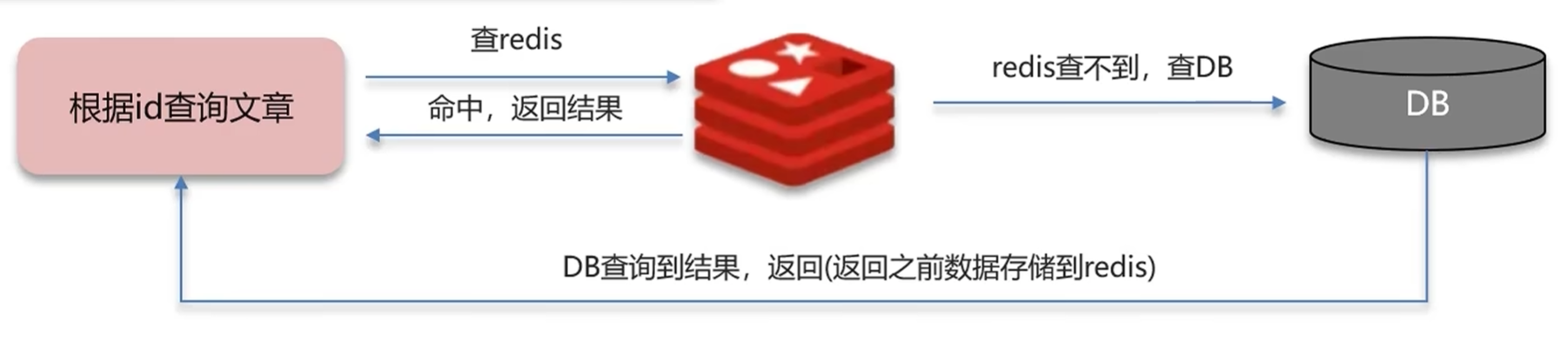
正常的缓存流程是:请求先查 Redis,如果 Redis 中有数据,直接返回;如果 Redis 中没有,再查数据库,查到后将数据写入 Redis,然后返回。
但如果查询的是一个数据库和缓存中都不存在的数据,那么每次请求都会走到数据库这一步。如果有大量这样的请求,数据库的压力会骤增,甚至被打垮。
这就是缓存穿透:请求绕过了缓存,直接穿透到了数据库。
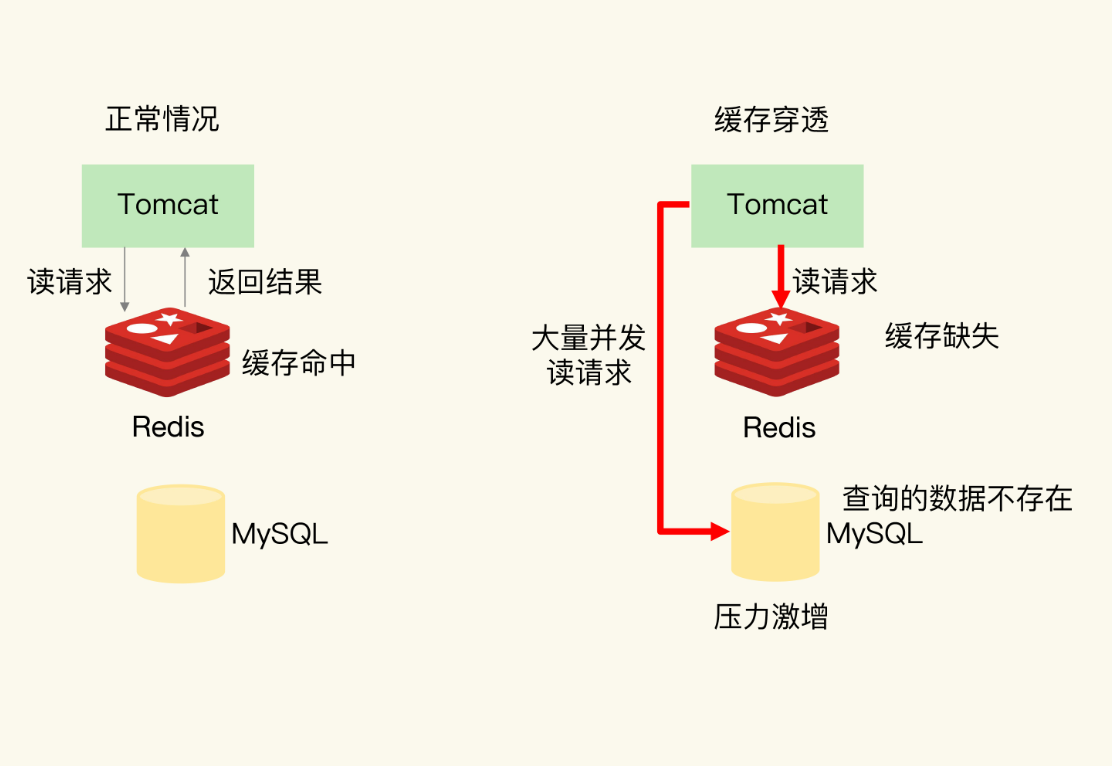
2. 产生原因与常见场景
缓存穿透通常由以下几种情况导致:
- 恶意攻击:黑客故意构造大量不存在的参数(比如随机的用户 ID、商品 ID)发起请求,恶意打垮数据库。
- 业务逻辑漏洞:比如用户输入了非法的参数,或者业务代码没有做参数校验,导致查询了不存在的数据。
- 数据被物理删除:数据库中的数据被删除了,但缓存中没有对应的空值,导致后续查询还是会打到数据库。
最典型的场景就是恶意攻击:黑客通过脚本每秒发起几万次查询不存在的用户 ID 的请求,Redis 完全没有起到缓存的作用,所有请求都打到数据库,数据库很快就会被打垮。
3. 完整解决方案
针对缓存穿透,有以下几种常用的解决方案,根据业务场景选择合适的组合:
方案 1:接口参数校验
这是最基础也是最有效的第一道防线。在请求到达 Redis 之前,先对参数进行合法性校验,过滤掉明显非法的参数。
比如用户 ID 必须是正整数、商品 ID 必须在指定的范围内、手机号必须符合格式等。对于非法参数,直接返回错误,不需要走到 Redis 和数据库层。
java
// 示例:参数校验
public User getUserById(Long userId) {
// 第一道防线:参数合法性校验
if (userId == null || userId <= 0) {
throw new IllegalArgumentException("用户ID不合法");
}
// 再查Redis和数据库
User user = redisTemplate.opsForValue().get("user:" + userId);
if (user != null) {
return user;
}
user = userMapper.selectById(userId);
if (user != null) {
redisTemplate.opsForValue().set("user:" + userId, user, 1, TimeUnit.HOURS);
}
return user;
}方案 2:缓存空值
如果数据库中查询不到数据,就向 Redis 中写入一个空值(或者特殊标记),并设置一个较短的过期时间(比如 5 分钟)。
这样后续的请求就会直接从 Redis 中拿到空值返回,不会再打到数据库。
java
public User getUserById(Long userId) {
if (userId == null || userId <= 0) {
throw new IllegalArgumentException("用户ID不合法");
}
String key = "user:" + userId;
User user = redisTemplate.opsForValue().get(key);
if (user != null) {
// 如果是缓存的空值,返回null
if (user.getId() == -1) {
return null;
}
return user;
}
user = userMapper.selectById(userId);
if (user != null) {
redisTemplate.opsForValue().set(key, user, 1, TimeUnit.HOURS);
} else {
// 数据库中不存在,缓存空值,设置较短的过期时间
User emptyUser = new User();
emptyUser.setId(-1L);
redisTemplate.opsForValue().set(key, emptyUser, 5, TimeUnit.MINUTES);
}
return user;
}注意事项:
- 空值必须设置过期时间,否则会导致 Redis 中存在大量的空值,占用内存。
- 过期时间不能太长,否则如果数据库中新增了这条数据,缓存中还是空值,会导致数据不一致。
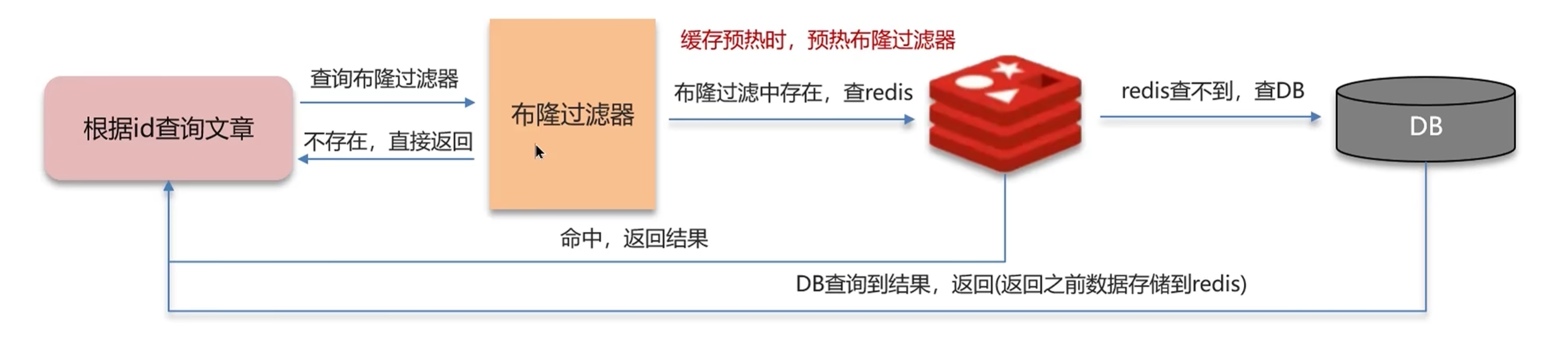
方案 3:布隆过滤器(Bloom Filter)
布隆过滤器是一种空间效率极高的概率型数据结构,专门用来判断一个元素是否存在于一个集合中。
它的核心原理是:使用一个位数组和多个哈希函数,将元素映射到位数组的多个位置上。当判断一个元素是否存在时,检查这些位置是否都为 1。如果有任何一个位置为 0,说明元素一定不存在;如果都为 1,说明元素可能存在(存在一定的误判率)。
布隆过滤器可以挡住所有不存在的请求,只有布隆过滤器认为存在的请求,才会走到 Redis 和数据库层。
实现步骤:
- 系统启动时,将数据库中所有的合法 ID 加载到布隆过滤器中。
- 新增数据时,同时将 ID 添加到布隆过滤器中。
- 请求到来时,先通过布隆过滤器判断 ID 是否存在,如果不存在,直接返回错误。
java
// 示例:使用Guava的布隆过滤器
// 初始化布隆过滤器:预计插入100万个元素,误判率0.01%
private static final BloomFilter<Long> BLOOM_FILTER = BloomFilter.create(
Funnels.longFunnel(), 1000000, 0.0001
);
// 系统启动时加载所有用户ID到布隆过滤器
@PostConstruct
public void init() {
List<Long> userIdList = userMapper.selectAllUserId();
for (Long userId : userIdList) {
BLOOM_FILTER.put(userId);
}
}
public User getUserById(Long userId) {
if (userId == null || userId <= 0) {
throw new IllegalArgumentException("用户ID不合法");
}
// 第二道防线:布隆过滤器判断是否存在
if (!BLOOM_FILTER.mightContain(userId)) {
return null;
}
// 再查Redis和数据库
String key = "user:" + userId;
User user = redisTemplate.opsForValue().get(key);
if (user != null) {
return user;
}
user = userMapper.selectById(userId);
if (user != null) {
redisTemplate.opsForValue().set(key, user, 1, TimeUnit.HOURS);
}
return user;
}优点:空间效率极高,100 万个元素只需要几 MB 的内存;性能极高,判断速度是纳秒级。
缺点:存在一定的误判率(可以通过调整参数降低);不支持删除元素。
适用场景:数据量较大、新增不频繁、对误判率有一定容忍度的场景。
方案 4:黑名单拦截
对于已经识别的恶意 IP 或者恶意参数,可以加入黑名单,直接拦截所有请求。
最佳实践
线上环境建议使用参数校验 + 布隆过滤器 + 缓存空值的组合方案:
- 第一层:接口参数校验,过滤明显非法的参数。
- 第二层:布隆过滤器,过滤所有不存在的 ID。
- 第三层:缓存空值,处理布隆过滤器的误判和少量漏网之鱼。
三、缓存击穿:热点 key 过期
1. 什么是缓存击穿?
缓存击穿是指一个非常热点的 key,承载着大量的并发请求。在这个 key 缓存过期的瞬间,所有的并发请求都打到了数据库,导致数据库压力骤增,甚至宕机。
和缓存穿透不同,缓存击穿查询的是数据库中存在的数据,只是缓存刚好过期了。
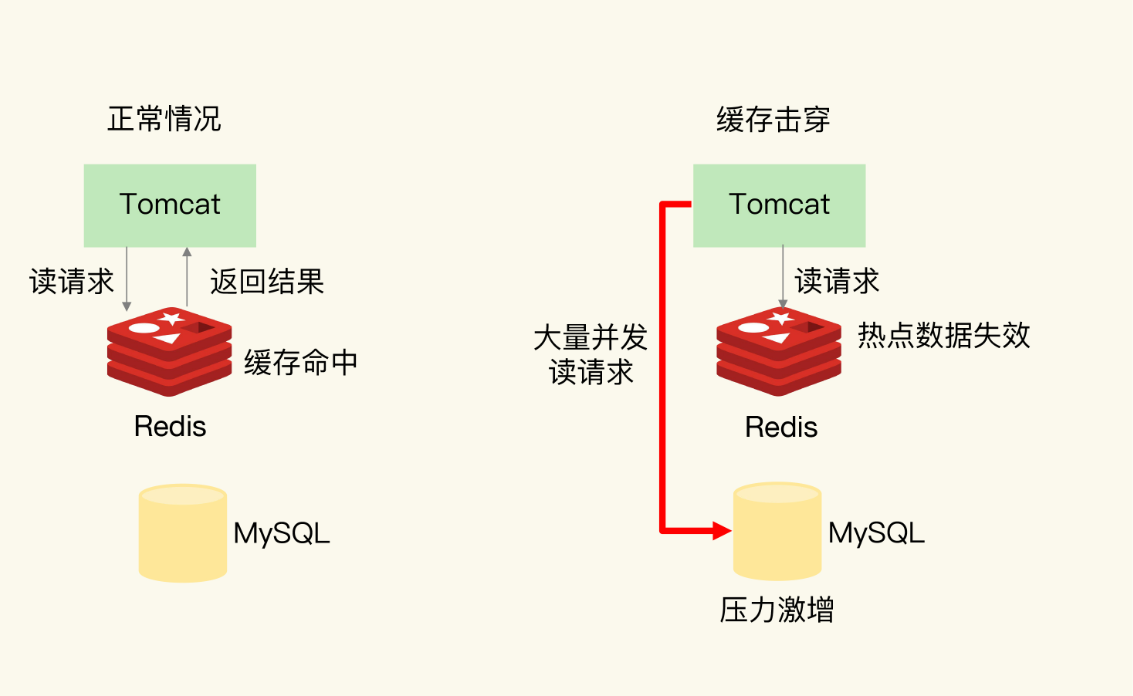
2. 产生原因与常见场景
缓存击穿的产生需要同时满足两个条件:
- 这个 key 是热点 key,有大量的并发请求。
- 这个 key刚好过期。
最典型的场景就是秒杀活动:某个热门商品的详情页,每秒有几万次请求。如果这个商品的缓存刚好在秒杀开始的时候过期,那么所有的请求都会打到数据库,数据库瞬间就会被打垮。
其他常见场景还有:热点新闻、热门话题、爆款商品等。
3. 完整解决方案
针对缓存击穿,有以下几种常用的解决方案:
方案 1:热点 key 永不过期
最简单粗暴的解决方案:对于热点 key,不设置过期时间,或者设置一个非常长的过期时间(比如 1 天)。
然后通过后台的定时任务,异步更新缓存中的数据。这样缓存永远不会过期,自然就不会出现缓存击穿的问题。
java
// 缓存热点商品,不设置过期时间
public Product getHotProductById(Long productId) {
String key = "hot_product:" + productId;
Product product = redisTemplate.opsForValue().get(key);
if (product != null) {
return product;
}
// 只有缓存不存在时才查数据库,正常情况下不会走到这里
product = productMapper.selectById(productId);
if (product != null) {
// 不设置过期时间
redisTemplate.opsForValue().set(key, product);
}
return product;
}
// 后台定时任务,每30分钟更新一次热点商品缓存
@Scheduled(fixedRate = 30 * 60 * 1000)
public void updateHotProductCache() {
List<Long> hotProductIdList = getHotProductIdList();
for (Long productId : hotProductIdList) {
Product product = productMapper.selectById(productId);
if (product != null) {
redisTemplate.opsForValue().set("hot_product:" + productId, product);
}
}
}优点:实现简单,完全避免了缓存击穿的问题。
缺点:缓存和数据库的数据一致性较差;占用内存较多。
适用场景:对数据一致性要求不高、热点 key 数量不多的场景。
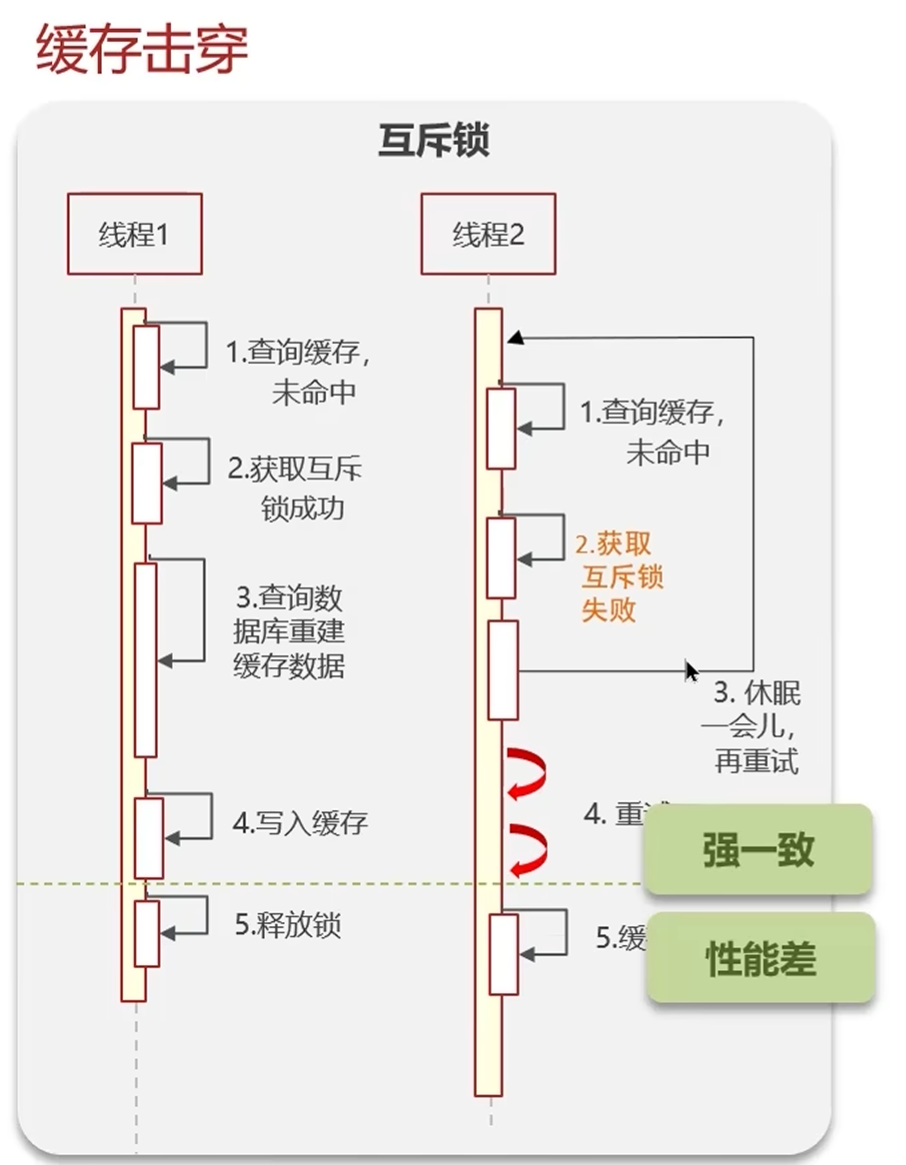
方案 2:加互斥锁
当缓存过期时,不是所有请求都去查数据库,而是只让一个请求去查数据库并更新缓存,其他请求等待缓存更新完成后,再从缓存中获取数据。
可以使用 Redis 的SETNX命令实现分布式互斥锁:
java
public Product getProductById(Long productId) {
String key = "product:" + productId;
Product product = redisTemplate.opsForValue().get(key);
if (product != null) {
return product;
}
// 缓存过期,尝试加锁
String lockKey = "lock:product:" + productId;
String lockValue = UUID.randomUUID().toString();
try {
// 加锁,设置10秒过期时间,防止死锁
Boolean locked = redisTemplate.opsForValue().setIfAbsent(lockKey, lockValue, 10, TimeUnit.SECONDS);
if (Boolean.TRUE.equals(locked)) {
// 拿到锁,查数据库并更新缓存
product = productMapper.selectById(productId);
if (product != null) {
redisTemplate.opsForValue().set(key, product, 1, TimeUnit.HOURS);
} else {
// 缓存空值
redisTemplate.opsForValue().set(key, new Product(-1L), 5, TimeUnit.MINUTES);
}
return product;
} else {
// 没拿到锁,等待100毫秒后重试
Thread.sleep(100);
return getProductById(productId);
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return null;
} finally {
// 释放锁,只能释放自己加的锁
if (lockValue.equals(redisTemplate.opsForValue().get(lockKey))) {
redisTemplate.delete(lockKey);
}
}
}注意事项:
- 锁必须设置过期时间,防止拿到锁的服务宕机,导致死锁。
- 释放锁时必须判断锁的值,只能释放自己加的锁,防止误删其他线程的锁。
- 重试次数不能太多,防止线程阻塞时间过长。
优点:保证了数据一致性;占用内存较少。
缺点:实现复杂;会导致部分线程阻塞,影响用户体验。
适用场景:对数据一致性要求较高、并发量不是特别极端的场景。
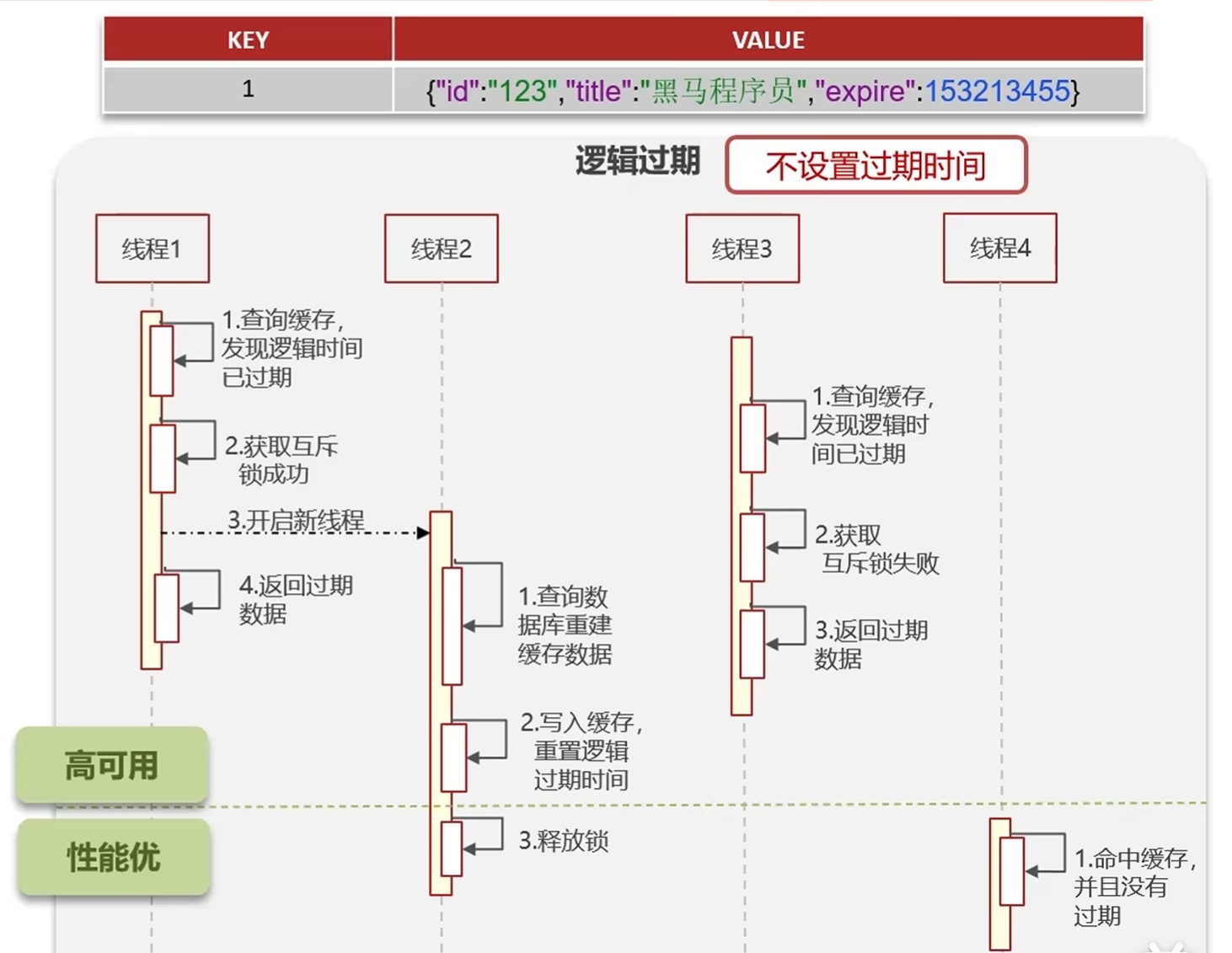
这是解决高并发热点 key 击穿的最优方案,也是互联网大厂最常用的方案。它的核心思想是:不设置 Redis 的物理过期时间,而是在缓存的 value 中自己维护一个逻辑过期时间。当查询到逻辑过期时,不是立即去查数据库,而是先返回旧数据,同时异步开启一个线程去更新缓存。
这样做的好处是:永远不会有线程阻塞,永远不会有大量请求打到数据库,性能和可用性都是最高的。
方案 3:逻辑过期(推荐,大厂首选)
这是解决高并发热点 key 击穿的最优方案,也是互联网大厂最常用的方案。它的核心思想是:不设置 Redis 的物理过期时间,而是在缓存的 value 中自己维护一个逻辑过期时间。当查询到逻辑过期时,不是立即去查数据库,而是先返回旧数据,同时异步开启一个线程去更新缓存。
这样做的好处是:永远不会有线程阻塞,永远不会有大量请求打到数据库,性能和可用性都是最高的。
核心原理
- 不设置物理过期:Redis 中的 key 永远不会被 Redis 主动删除,从根本上避免了缓存击穿的发生。
- 维护逻辑过期 :在缓存的 value 中,除了存储业务数据,还额外存储一个
expire字段,表示这个数据的逻辑过期时间戳。 - 异步更新:当查询到数据逻辑过期时,只让一个请求拿到互斥锁,开启异步线程去更新缓存。其他所有请求都直接返回旧数据,不需要等待。
完整执行流程
- 线程 1 查询缓存,解析 value 中的
expire字段,发现逻辑时间已过期。 - 线程 1尝试获取互斥锁,成功拿到锁。
- 线程 1 不自己去查数据库,而是开启一个新的异步线程执行更新操作。
- 线程 1 自己立即返回旧的缓存数据,不需要等待异步线程执行完成。
- 线程 2、线程 3同时查询缓存,也发现逻辑过期,尝试获取互斥锁失败。
- 线程 2、线程 3 直接返回旧的缓存数据,全程不会打到数据库。
- 线程 4查询缓存,发现逻辑时间未过期,直接返回缓存数据。
- 异步线程执行完成:查询数据库获取最新数据 → 写入 Redis 并重置逻辑过期时间 → 释放互斥锁。
可直接落地的代码实现
java
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
@Component
public class CacheService {
private final StringRedisTemplate redisTemplate;
private final ObjectMapper objectMapper;
// 线程池,用于异步更新缓存(建议根据业务量调整大小)
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
public CacheService(StringRedisTemplate redisTemplate, ObjectMapper objectMapper) {
this.redisTemplate = redisTemplate;
this.objectMapper = objectMapper;
}
// 缓存数据封装类,包含业务数据和逻辑过期时间
private static class CacheData<T> {
private T data;
private Long expire; // 逻辑过期时间戳(毫秒)
public CacheData() {}
public CacheData(T data, Long expire) {
this.data = data;
this.expire = expire;
}
// 判断是否逻辑过期
public boolean isExpired() {
return System.currentTimeMillis() > expire;
}
// getter/setter
public T getData() { return data; }
public void setData(T data) { this.data = data; }
public Long getExpire() { return expire; }
public void setExpire(Long expire) { this.expire = expire; }
}
/**
* 逻辑过期方式获取热点商品
* @param productId 商品ID
* @return 商品信息
*/
public Product getHotProductWithLogicalExpire(Long productId) {
String key = "hot_product:" + productId;
// 1. 查询Redis缓存
String json = redisTemplate.opsForValue().get(key);
if (json == null) {
// 热点key必须提前预热,正常情况下不会为null
return null;
}
try {
// 2. 解析缓存数据
CacheData<Product> cacheData = objectMapper.readValue(json,
objectMapper.getTypeFactory().constructParametricType(CacheData.class, Product.class));
// 3. 判断是否逻辑过期
if (!cacheData.isExpired()) {
// 未过期,直接返回数据
return cacheData.getData();
}
// 4. 已过期,尝试获取互斥锁
String lockKey = "lock:hot_product:" + productId;
Boolean locked = redisTemplate.opsForValue().setIfAbsent(lockKey, "1", 10, TimeUnit.SECONDS);
if (Boolean.TRUE.equals(locked)) {
// 5. 拿到锁,开启异步线程更新缓存
CACHE_REBUILD_EXECUTOR.submit(() -> {
try {
// 查询数据库
Product product = productMapper.selectById(productId);
if (product != null) {
// 写入缓存,设置新的逻辑过期时间(30分钟)
CacheData<Product> newCacheData = new CacheData<>(product,
System.currentTimeMillis() + 30 * 60 * 1000);
redisTemplate.opsForValue().set(key, objectMapper.writeValueAsString(newCacheData));
}
} finally {
// 释放锁
redisTemplate.delete(lockKey);
}
});
}
// 6. 无论是否拿到锁,都直接返回旧数据
return cacheData.getData();
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
// 热点key预热方法,系统启动或活动开始前调用
public void preheatHotProduct(Long productId) {
Product product = productMapper.selectById(productId);
if (product != null) {
String key = "hot_product:" + productId;
CacheData<Product> cacheData = new CacheData<>(product,
System.currentTimeMillis() + 30 * 60 * 1000);
try {
redisTemplate.opsForValue().set(key, objectMapper.writeValueAsString(cacheData));
} catch (Exception e) {
e.printStackTrace();
}
}
}
}注意事项
- 锁必须设置过期时间,防止拿到锁的服务宕机导致死锁。
- 热点 key 必须提前预热,否则第一次查询会返回 null。
- 异步线程池要合理配置大小,避免线程过多导致 OOM。
| 优点 | 缺点 |
|---|---|
| 性能极高:无任何线程阻塞,所有请求立即返回 | 数据一致性较差:会返回短暂的旧数据(通常几秒到几分钟) |
| 可用性极高:数据库永远只会收到 1 个更新请求,压力为 0 | 实现稍复杂:需要封装缓存对象,维护逻辑过期时间 |
| 内存占用小:不需要永久缓存,逻辑过期后会自动异步更新 | 需要提前预热:热点 key 必须提前写入缓存 |
适用场景
- 极端高并发场景:秒杀、大促、热点新闻等每秒几万甚至几十万次请求的场景
- 对可用性要求极高:绝对不能出现服务阻塞或数据库宕机的情况
- 可以接受短暂数据不一致:允许用户看到几秒前的旧数据
方案 4:提前预热
在热点 key 即将过期之前,提前更新缓存。比如设置缓存过期时间为 1 小时,然后在 50 分钟的时候,就提前从数据库中查询最新的数据,更新缓存。
可以通过在缓存中存储过期时间,然后后台定时任务检查即将过期的热点 key,提前更新。
优点:用户体验好,不会出现线程阻塞。
缺点:实现复杂;需要额外的定时任务。
适用场景:热点 key 可以提前预知的场景,比如秒杀活动、热点新闻发布等。
四大方案对比与最佳实践
现在我们把四个方案放在一起对比,清晰地知道什么时候该用哪个:
| 方案 | 核心思想 | 数据一致性 | 性能 | 实现复杂度 | 推荐指数 | 适用场景 |
|---|---|---|---|---|---|---|
| 永不过期 | 缓存永久有效,后台异步更新 | 一般 | 极高 | 中等 | ⭐⭐⭐ | 热点 key 少,对一致性要求低 |
| 逻辑过期 | 返回旧数据,异步更新缓存 | 一般 | 极高 | 较高 | ⭐⭐⭐⭐⭐ | 高并发秒杀、大促等极端场景 |
| 互斥锁 | 单线程查库,其他线程等待 | 高 | 一般 | 中等 | ⭐⭐⭐⭐ | 普通业务热点 key,要求一致性 |
| 提前预热 | 过期前主动更新缓存 | 高 | 极高 | 高 | ⭐⭐⭐ | 可提前预知的热点事件 |
最佳实践:
- 秒杀、大促等极端高并发场景 :必须使用逻辑过期,这是唯一能扛住每秒几十万请求的方案
- 普通业务热点 key :优先使用互斥锁,保证数据一致性
- 可以提前预知的热点 key :提前预热,系统启动或活动开始前就写入缓存
- 绝对禁止:不要给热点 key 设置物理过期时间,这是缓存击穿的根源
四、缓存雪崩:大量 key 同时过期或 Redis 宕机
1. 什么是缓存雪崩?
缓存雪崩是指大量的 key 在同一时间过期 ,或者Redis 服务宕机,导致所有的请求都打到数据库,数据库的压力瞬间达到峰值,甚至宕机。
和缓存击穿不同,缓存击穿是单个热点 key 的问题,而缓存雪崩是大量 key同时失效的问题,影响范围更大,破坏力更强。
2. 产生原因与常见场景
缓存雪崩主要有两个原因:
- 大量 key 同时过期:比如在系统上线时,批量向 Redis 中写入了大量数据,并且都设置了相同的过期时间(比如 1 小时)。1 小时后,这些 key 同时过期,所有请求都打到数据库。
- Redis 服务宕机:Redis 集群发生故障,所有节点都无法提供服务,导致所有请求都直接打到数据库。
最典型的场景就是电商促销活动:活动开始前,批量将所有商品的缓存写入 Redis,并且都设置了 1 小时的过期时间。1 小时后,所有商品的缓存同时过期,数据库瞬间被打垮。
3. 完整解决方案
针对缓存雪崩,需要从预防 和容灾两个方面入手:
方案 1:过期时间加随机值
这是解决大量 key 同时过期最简单有效的方案。在设置过期时间时,给每个 key 的过期时间加上一个随机值,避免所有 key 在同一时间过期。
java
// 基础过期时间1小时,加上0-10分钟的随机值
int baseExpire = 3600;
int randomExpire = new Random().nextInt(600);
redisTemplate.opsForValue().set(key, value, baseExpire + randomExpire, TimeUnit.SECONDS);这样所有 key 的过期时间会均匀分布在 1 小时到 1 小时 10 分钟之间,不会出现同时过期的情况,数据库的压力会被均匀分散。
优点:实现简单,效果显著。
缺点:无法完全避免同时过期,只是降低了概率。
适用场景:绝大多数业务场景,是必须使用的基础方案。
方案 2:Redis 集群高可用
为了防止 Redis 服务宕机导致的缓存雪崩,必须搭建 Redis 集群,保证 Redis 的高可用。
常用的 Redis 集群方案有:
- 主从复制 + 哨兵模式:一主多从,哨兵负责监控主从节点的状态,主库宕机时自动将从库提升为主库。
- Redis Cluster:分片集群,将数据分散到多个节点上,每个节点都有主从备份,单个节点宕机不会影响整个集群的服务。
线上生产环境必须使用至少一主一从的架构,并且开启哨兵模式,保证 Redis 的高可用。
方案 3:服务熔断与降级
当数据库的压力达到阈值时,触发熔断机制,直接返回降级结果,避免数据库被打垮。
可以使用 Sentinel、Hystrix 等熔断框架实现:
- 当数据库的 QPS 超过阈值时,熔断所有数据库请求,直接返回默认值或者错误信息。
- 当数据库恢复正常后,自动关闭熔断,恢复服务。
同时,对于非核心业务,可以进行降级处理,比如暂时关闭商品推荐、评论等功能,保证核心业务(比如下单、支付)的正常运行。
方案 4:多级缓存
搭建多级缓存架构,避免所有请求都直接打到数据库:
- 一级缓存:本地缓存(Caffeine、Guava Cache),速度最快,用来缓存最热点的数据。
- 二级缓存:Redis 缓存,用来缓存大部分热点数据。
- 三级缓存:数据库,只有前两级缓存都没有命中时,才会走到数据库。
这样即使 Redis 宕机,本地缓存还能挡住一部分请求,不会所有请求都直接打到数据库。
方案 5:限流
在网关层或者服务层进行限流,限制每秒的请求数,避免数据库被突发的流量打垮。
常用的限流算法有令牌桶算法、漏桶算法,可以使用 Sentinel、Guava RateLimiter 等工具实现。
最佳实践
线上环境建议使用以下组合方案:
- 基础防护:所有 key 的过期时间都加上随机值,避免同时过期。
- 高可用:搭建 Redis 集群,开启哨兵模式,保证 Redis 不宕机。
- 容灾:使用熔断降级和多级缓存,即使 Redis 宕机,也能保证核心业务的正常运行。
- 限流:在网关层进行限流,防止突发流量打垮数据库。
五、三大问题对比与总结
为了方便大家记忆和对比,我整理了一张核心对比表:
| 问题 | 核心原因 | 影响范围 | 核心解决方案 |
|---|---|---|---|
| 缓存穿透 | 查询不存在的数据 | 小到中 | 参数校验、布隆过滤器、缓存空值 |
| 缓存击穿 | 单个热点 key 过期 | 中 | 逻辑过期、互斥锁、永不过期 |
| 缓存雪崩 | 大量 key 同时过期或 Redis 宕机 | 大 | 过期时间加随机值、Redis 高可用、熔断降级 |
六、常见误区纠正
-
误区 :布隆过滤器可以解决所有缓存穿透问题。纠正:布隆过滤器存在一定的误判率,会把不存在的数据误判为存在。所以需要配合缓存空值一起使用,处理误判的情况。
-
误区 :互斥锁可以完全解决缓存击穿问题。纠正:互斥锁会导致线程阻塞,在并发量特别大的情况下,会有大量线程等待,影响用户体验。对于极端热点 key,优先使用逻辑过期方案。
-
误区 :只要设置了过期时间加随机值,就不会发生缓存雪崩。纠正:过期时间加随机值只能解决大量 key 同时过期的问题,无法解决 Redis 宕机的问题。必须搭建 Redis 集群,保证高可用。
-
误区 :缓存雪崩是 Redis 的问题,和数据库无关。纠正:缓存雪崩最终会导致数据库宕机,所以必须从数据库层面做好防护,比如熔断、降级、限流等。
七、总结
缓存穿透、缓存击穿、缓存雪崩,是 Redis 缓存最常见的三大问题,也是每个后端开发者必须掌握的核心技能。
这三个问题的本质,都是缓存失效导致请求打到数据库,只是失效的范围和原因不同:
- 穿透是缓存和数据库都没有数据,请求直接穿透。
- 击穿是单个热点 key 失效,大量并发请求打到数据库。
- 雪崩是大量 key 同时失效或者 Redis 宕机,所有请求打到数据库。
解决这些问题的核心思路,就是尽量让请求在缓存层就被处理掉,不要打到数据库。同时,做好容灾和防护措施,即使缓存出现问题,也不会导致整个系统崩溃。
记住:预防大于治理。在设计缓存架构的时候,就要提前考虑到这些问题,做好相应的防护措施,而不是等到线上出了问题再去救火。