重温总结一下强化学习的圣经-- ppo算法
在 PPO 之前,最基础的策略梯度方法是通过计算策略梯度的估计值,并将其代入随机梯度上升算法
先从最基础的策略梯度方法(Vanilla Policy Gradient, VPG)开始,
从零推导公式1梯度更新器的来源

基于轨迹视角的策略更新
机器人的运动状态用轨迹来表示

我们要所做的工作就是选出一个最好的策略 让这个策略下产生的轨迹平均回报值 使其回报尽可能高

但是同样的策略在同一个环境里跑,每次跑出的轨迹可能都不一样(因为网络有探索噪声,物理引擎也可能有随机性)
于是我们用概率来表示轨迹的集合
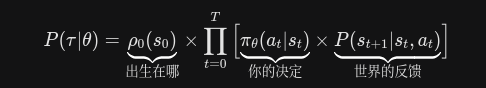
现在已经确定了轨迹的定义以及其评价标准 现在的重点就是
在无数种可能的神经网络权重中,寻找那一组最优的权重,使得它所对应的策略跑出来的平均轨迹总回报最高
所以定义期望总回报函数(基于轨迹的视角)尽可能寻找使其最大的参数权重值
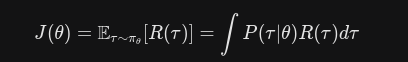
对此公式进行梯度更新
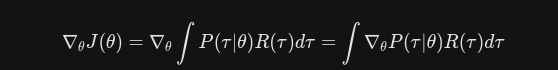
利用对数求导技巧进行计算
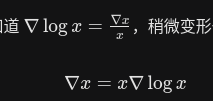
对轨迹概率进行处理
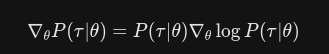
再将处理之后的代入至梯度更新公式里面

再来拆解一条轨迹的对数概率
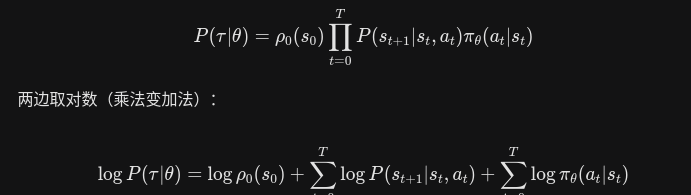
再对此式求梯度

但是如果按照上述公式进行轨迹计算的话 效率不高 因为轨迹很长 实际编程中用局部状态来替代
基于状态视角的梯度更新
状态值公式为
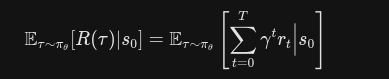
利用概率论知识

于是可以重写上述的目标函数
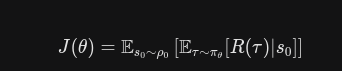
对比两个函数可以发现进行完美的替换
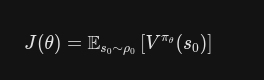
有了状态值 接下来引入动作值

算法改进
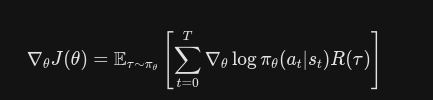
直接使用这个公式会遇到一个严重的信用分配问题
假设机器人第 1 步蹬地非常完美,但第 100 步脚滑摔倒了。整条轨迹的总分 R(\\tau) 很低。如果直接乘进去,神经网络就会把第 1 步那个完美的动作也给连带惩罚了
针对这个问题进行了3次改进
第一次:Reward-to-go (未来收益) 第 t步的动作,不应该为t时刻之前的错误背锅。所以把总分换成从t时刻开始往后的累积得分G_t
第二次:引入 Baseline (基线) 直接用得分容易波动,我们引入 Critic 预测的平均水平V(s_t)
用实际得分减去平均水平:G_t - V(s_t)
第三次:优势函数 (Advantage Function, A_t) 动作的绝对好坏不重要,相对好坏才重要。我们用动作价值减去状态价值:A_t = Q(s_t, a_t) - V(s_t)
经过这三次处理 就得到了公式1
优势函数的推导
优势函数的定义:
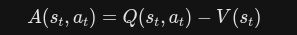
在现实代码中,真实的Q值是不知道的 已知的只有环境给出的即时奖励 以及critic网络给出的状态价值预测值 使用这两个值把优势函数的值计算出来
第一种:1-步 TD误差
只看当前这一步的奖励 下一步及以后的事情,依赖Critic 网络的预测
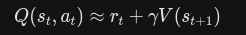
-
优点:方差极小。因为只用了一个真实的回报 r_t,不会因为后面的随机事件而大起大落。
-
缺点:偏差极大(Bias)。如果Critic 网络还没训练好,预测的 V(s_{t+1}) 纯属瞎猜,那么你的 \\hat{A}_t 也就是瞎算,Actor 网络会被带进沟里
第二种:蒙特卡洛估计
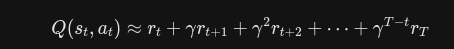
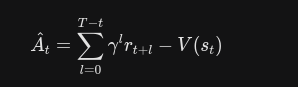
用数据来替代模型 让机器人一直跑,把从当前步到回合结束的所有真实奖励全加起来
-
优点:无偏差(Unbiased)。全用的真实数据,不存在预测错误。
-
缺点:方差爆炸(Variance Explosion)。假设 100 步里有 99 步跑得极好,最后一步因为物理引擎 Bug 摔倒了,这 100 步的真实奖励总和都会变成负数,导致你前面所有完美的动作都被错误惩罚
第三种:广义优势估计
既然 1 步估计偏差大,\\infty 步估计方差大,那就把 1 步、2 步、3 步......到 N 步的估计全部加权平均起来
GAE 引入了一个全新的超参数 \\lambda (Lambda),它控制着对未来的"信任衰减度"
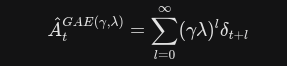

-
当 \\lambda = 0 时:公式后面全变成 0,\\hat{A}_t = \\delta_t。退化成了第一种
-
当 \\lambda = 1 时:公式可以被数学证明完全等价于"长期主义流"(蒙特卡洛估计)。
-
当 \\lambda = 0.95 时(这是几乎所有 RL 库的默认黄金值):我们在方差和偏差之间找到了最完美的平衡。它告诉机器人:你当前动作的好坏,很大程度上取决于眼前这一步(\\delta_t),但如果这个动作在接下来的几步里(\\delta_{t+1}, \\delta_{t+2})也引发了好的连锁反应,我们也要算一点功劳给它,只不过功劳越往后越小
代码实现-倒推法
在代码中 优势函数是倒着计算的 机器人跑完一定步数 将所有数据存放在经验回放池里面 然后代码再一次性算有每个步数的delta_t:delta = r + gamma * next_v - v
然后 从规定步数从后向前遍历 利用递推公式

此计算方法将复杂度降到了O(N)
当算出了所有的 {A}_t 后,在真正送进公式 (1) 之前,所有的成熟框架都会对这些 {A}_t 做一件事:求均值和标准差,把它们变成标准正态分布(均值为 0,方差为 1)
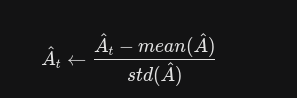
这就意味着,在一个批次的数据里,总有一半的动作会被判定为好动作(优势为正,鼓励),一半被判定为坏动作(优势为负,惩罚)。
这强制 Actor 网络在每一批经验中都必须"优胜劣汰",极大地提升了训练的稳定性
ps:上述内容结合ai回答 公式还是要自己手推一遍更好