paper: emnlp2023
code:
1. 研究动机:大模型的幻觉反而更严重?
- 现象发现: 研究人员首先使用传统的 CHAIR(一种通过解析模型生成的文本来检查是否包含多余物体的指标)测试了当时主流的 LVLMs(如 LLaVA、MiniGPT-4、mPLUG-Owl 等)。结果令人惊讶:这些基于大语言模型的大模型,其物体幻觉问题甚至比传统的小型视觉-语言模型(如 OSCAR、BLIP)还要严重得多。
- 传统评估指标的缺陷: 研究发现,传统的 CHAIR 指标非常不稳定。它对提示词(Prompt)和生成文本的长度极其敏感,且依赖人工设计的复杂解析规则,很容易发生误判。因此,学术界急需一种更稳定、更公平的评估方法。
2. 深度剖析:大模型为什么会"无中生有"?
论文并没有止步于"发现幻觉",而是深入探究了大模型到底喜欢在什么情况下产生幻觉。他们得出了两个极为重要的结论:大模型的幻觉高度受其微调数据集(如 MSCOCO)中的统计学偏差影响。
- 高频物体偏差(Popular Bias): 模型特别容易幻觉出在训练集中出现频率极高的物体。例如,图里根本没有人,但模型往往会由于"人(person)"在数据集中太常见而盲目生成它。
- 共现偏差(Co-occurrence Bias): 模型很容易被图片中真实存在的物体"带偏",进而幻觉出与它经常成对出现的其他物体。例如,图片里有一张"餐桌(dining table)",模型就会顺理成章地幻觉出图片中其实并不存在的"椅子(chair)"或"杯子(cup)"。

3. 破局之法:提出 POPE 评估基准
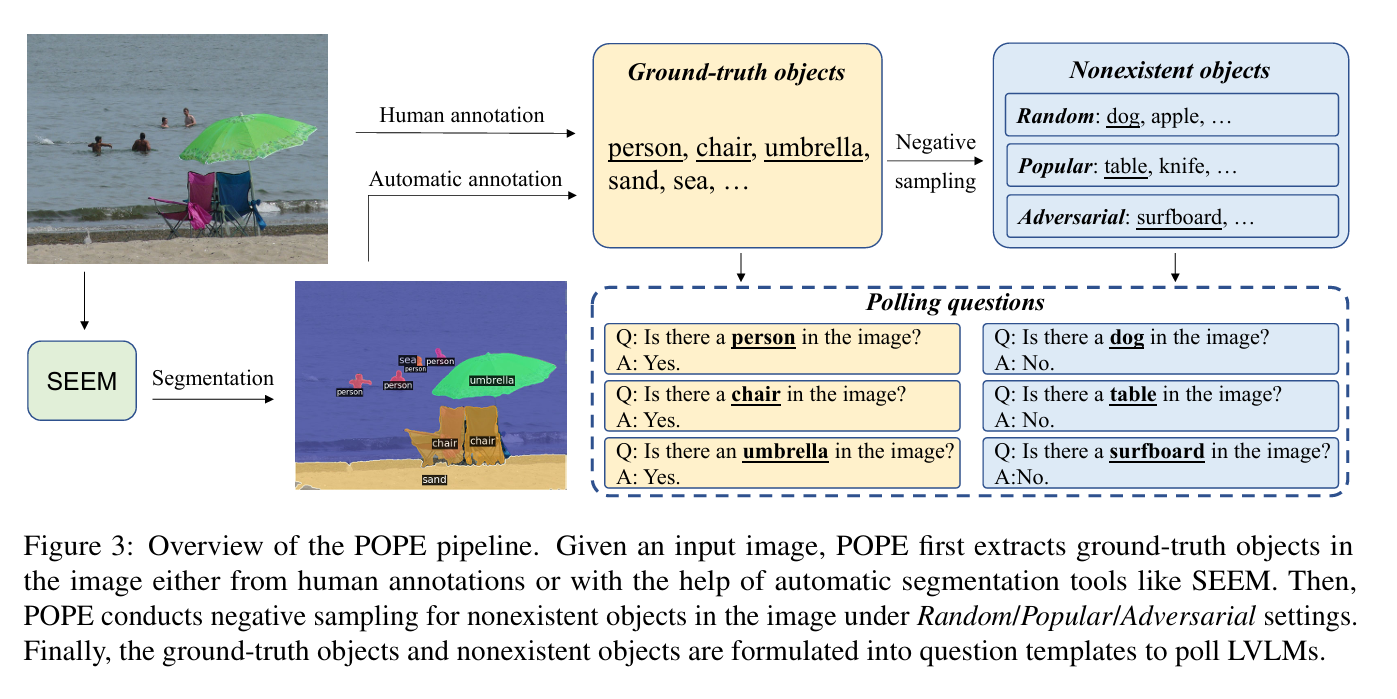
基于上述痛点和发现,作者摒弃了让模型自由生成长文本再进行解析的老路,提出了一种**"轮询式物体探测评估"(Polling-based Object Probing Evaluation, 简称 POPE)**方法。
POPE 的核心思想是把幻觉评估变成简单的"是非题(Yes/No)"(例如:"图片里有狗吗?"),并基于模型容易踩坑的统计偏差,设计了三种不同难度的负样本(假物体)提问策略:
- Random(随机): 随机问一个图片中不存在的物体(最简单)。
- Popular(高频): 专门挑数据集中最常见、但当前图片中没有的物体来问大模型,诱导它犯错。
- Adversarial(对抗): 最阴险的一种。专门挑那些和图片中真实存在的物体"高度共现",但偏偏这次没出现的物体来问模型(比如图里有键盘,专门问有没有鼠标)。
4. 实验结果与有趣的洞察
作者利用 POPE 对主流大模型进行了"大考",得到了几个非常有趣的洞察:
- 大模型变成了"Yes Man(老好人)": 实验发现,像 LLaVA、mPLUG-Owl 和 MultiModal-GPT 这样的模型,在面对 POPE 的提问时过度自信,几乎 99% 的情况下都会回答"Yes"。这就导致它们在回答真正没有该物体的负面问题时,准确率暴跌。
- 难度梯度的有效性: 模型在 Random -> Popular -> Adversarial 这三种设置下的 F1 得分呈现稳定下降的趋势。这完美印证了作者前文的假设:模型在面对高频词和共现词时,最容易被诱导产生幻觉。
- POPE 的高扩展性与稳定性: 与传统指标不同,POPE 对提示词的变化非常稳定。此外,如果结合自动化分割工具(如 SEEM),POPE 甚至可以在完全没有人工标注的数据集上"零成本"构建幻觉测试集,具有极强的扩展性。
- 幻觉率与整体能力的背离: 论文还发现,幻觉较少(POPE 得分高)的模型,其在传统的 VQA(视觉问答)任务上的得分不一定最高。这说明在实际应用中,抑制幻觉和提升模型解决复杂问题的能力需要进行平衡和双向评估。
总结
如果说 《DHCP》 是一篇"教你如何造测谎仪"的实战手册,那么这篇 《POPE》 就是"分析嫌疑人犯罪心理,并为其量身定制一套笔录审讯标准"的犯罪心理学教科书。正是因为 POPE 揭示了幻觉的成因并提供了标准的"Yes/No"测试集,后续如 DHCP 等机制视角的防幻觉研究才有了稳固的实验基础。
**POPE(Polling-based Object Probing Evaluation,轮询式物体探测评估)**是一个专门针对多模态大模型(LVLM)物体幻觉设计的评估基准。它的核心逻辑非常直接:摒弃让模型自由生成长篇大论的传统做法,把幻觉评估转化为做最简单的"是非题(Yes/No)"。
以前的方法(如 CHAIR 指标)需要解析模型生成的长描述,这极度依赖复杂的人工提取规则,且非常容易受到提示词变化和句子长度的干扰。为了解决这些痛点,POPE 设定了以下标准化的"审讯"流程:
1. 题目构建与 1:1 平衡机制
对于每一张图片,POPE 都会套用极其简单的固定句式向模型提问,例如:"图片里有某物体吗?"(Is there a/an in the image?) 。 为了防止模型投机取巧(比如为了迎合人类全部回答"Yes"),POPE 严格设定了 1:1 的正负样本比例:
- 正样本(答案为 Yes):直接从图片真实的标注(或 SEEM 等自动分割工具提取的特征)中获取真实存在的物体。
- 负样本(答案为 No) :提取图片中根本不存在的物体来反问模型。如何挑选这些不存在的物体,就是 POPE 测试大模型底线的核心所在。
2. 三种不同难度的"陷阱"策略(负采样)
为了诊断出模型产生幻觉的"病因",POPE 针对答案为"No"的负样本设计了三种不同难度的采样策略,一步步诱导模型犯错:
- 随机策略(Random Sampling):最基础的测试。 系统完全随机地从物体库中挑选一个图片里没有的物体来提问。
- 高频策略(Popular Sampling):针对"流行度偏差"。 专门挑选在整个训练数据集中出现频率最高,但在当前图片里却没有的物体来提问。因为大模型在训练时看这些高频物体(如"人"、"车")看得最多,很容易产生"肌肉记忆"从而闭着眼睛回答"Yes"。
- 对抗策略(Adversarial Sampling):最阴险的测试,针对"共现偏差"。 专门挑选那些和图片中真实存在的物体**"经常成对出现"**、但偏偏这张图里没有的物体来提问。比如,如果图片里有一张"餐桌",它就会特意问"图片里有椅子吗?",以此来测试模型是真的看见了,还是仅仅凭借常识关联在"瞎猜"。
3. 评估与打分
由于所有问题的标准答案只有确定的"Yes"或"No",这完美避开了复杂的文本解析。POPE 使用经典的分类指标来打分,包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)以及 F1 分数(F1 Score),其中 F1 分数被作为评估模型幻觉程度的最主要指标。
总结来说,POPE 就像是一套标准化的"视力测试表"。它通过极其稳定的"Yes/No"提问方式和精心设计的陷阱,精准且公平地测出了大模型到底是真的拥有了视觉理解能力,还是仅仅在根据语言数据的统计规律"胡说八道"。