用 Claude Code、Codex、Cursor 写代码,绑外币卡和多平台管理是两个绕不开的问题。这篇记录我实测几种 AI API 接入方案的过程,包括官方直连、自建网关、第三方聚合平台的价格对比和配置踩坑。
为什么需要聚合网关
天天用 Claude Code、Codex、Cursor 写代码,两件事让我头疼:
一是绑卡。OpenAI 要一张,Anthropic 要一张,Google 又要一张,都是外币卡,有的还挑卡段。二是管理。三个平台三套 Key、三套用量面板、三套账单,团队几个人一起用的时候更乱。
所以我开始看"聚合网关"这条路------用一个统一的 OpenAI 兼容接口,后面帮你转发到各家 API。目前主流的方案大概三类:
国内聚合平台 :人民币计价,国内网络直连,不用绑外币卡。缺点是多了一层中间商,数据经过第三方。这类平台不少,我这次挑了一家叫「微元算力」的试了三周,下面的价格和配置数据都来自这家。
海外聚合平台 :比如 OpenRouter,模型覆盖广,社区活跃。但它本身就是美元计价,还是要外币卡,而且国内网络访问不太稳定,等于没解决我的核心痛点。
自建开源方案 :比如 one-api、new-api,自己部署一个网关服务,配好上游渠道,Key 管理和负载均衡都自己搞。优点是数据完全可控、不多一层中间商;缺点是要自己运维、上游渠道还是得自己去各家开号绑卡,并没有省掉绑卡这一步。适合有运维能力且对数据安全要求高的团队。
价格对比
这是我最关心的部分。下面的数据是我对着后台一条条抄的,按 token 计费,单位是人民币每百万 token。
主力模型定价
| 模型 | 输入(¥/百万 token) | 输出(¥/百万 token) | 缓存读取(¥/百万 token) |
|---|---|---|---|
| claude-opus-4-7 | 10.5 | 52.5 | 1.05 |
| claude-opus-4-7-thinking | 11.76 | 58.8 | 1.176 |
| claude-opus-4-8 | 10.5 | 52.5 | 1.05 |
| claude-sonnet-4-6 | 6.3 | 31.5 | 0.63 |
| claude-haiku-4-5 | 4.2 | 21.0 | 0.42 |
| gpt-5.5 | 2.4 | 19.2 | 0.24 |
| gpt-5.4 | 2.0 | 16.0 | 0.2 |
| gpt-5.4-mini | 0.6 | 4.8 | --- |
| gemini-3.1-pro-preview | 8.0 | 32.0 | --- |
| gemini-3.5-flash | 8.0 | 32.0 | --- |
| gemini-2.5-pro | 4.0 | 32.0 | --- |
| deepseek-v4-pro | 4.2 | 8.4 | --- |
| deepseek-v4-flash | 0.525 | 1.05 | --- |
跟官方价算一下
Claude 是我日常主力,重点算这个。Anthropic 官方定价:
| claude-opus-4-7 | 输入 | 输出 | 缓存读取 |
|---|---|---|---|
| 官方价($/百万 token) | 5 | 25 | 0.5 |
| 聚合平台(¥/百万 token) | 10.5 | 52.5 | 1.05 |
| 人民币 ÷ 美元 | 2.1 | 2.1 | 2.1 |
三个价位全部 2.1 倍,即官方美元数字乘以 2.1 当人民币价。真实汇率 ¥7.3 ≈ $1,直连官方同样的调用得花 5×7.3=¥36.5,这边 ¥10.5,大概官方价的三成。
便宜是便宜,但本质上是聚合平台的定价策略。它们拿到的上游价格(批量账号、Bedrock 预留实例之类)比零售低,但具体低多少、利润多少,外面人不知道。这一点所有聚合平台都一样,包括 OpenRouter 的部分模型定价也低于官方零售价。
作为对比:OpenRouter 上 Claude Opus 4.7 标价 5/25(和官方一样),但它有 arena 模式和部分模型的折扣通道;自建 one-api 的成本取决于你上游渠道拿到什么价格,如果走 AWS Bedrock 预留实例,长期看可能更便宜,但前期投入大。
1 块钱能买多少 token
| 模型 | 价格 输入/输出(¥/百万) | ¥1 买的输入 token | ¥1 买的输出 token |
|---|---|---|---|
| gpt-5.4 | 2.0 / 16.0 | 约 50 万 | 约 6.25 万 |
| gpt-5.4-mini | 0.6 / 4.8 | 约 167 万 | 约 20.8 万 |
| claude-opus-4-7 | 10.5 / 52.5 | 约 9.5 万 | 约 1.9 万 |
| claude-sonnet-4-6 | 6.3 / 31.5 | 约 15.9 万 | 约 3.2 万 |
| deepseek-v4-flash | 0.525 / 1.05 | 约 190 万 | 约 95 万 |
日常调试用 Sonnet 或 Haiku 就够了,Opus 留给复杂推理。缓存读取只要输入价的十分之一,Claude Code 那种长系统提示词的场景,缓存命中后成本能降一个数量级。
接入配置实操
不管用哪家聚合平台,接入方式都差不多------OpenAI 标准协议,改个 Base URL 和 Key。下面贴几个常用工具的配置,YOUR_BASE_URL 换成你实际用的网关地址。
基本验证:
bash
curl ${YOUR_BASE_URL}/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-你的Key" \
-d '{
"model": "claude-opus-4-7",
"messages": [{"role": "user", "content": "写一个快速排序"}]
}'Claude Code
改 ~/.claude/settings.json:
json
{
"env": {
"ANTHROPIC_BASE_URL": "${YOUR_BASE_URL}",
"ANTHROPIC_AUTH_TOKEN": "sk-你的Key"
}
}注意 Base URL 不带 /v1 后缀,这个容易搞错。
Codex CLI
在 ~/.codex/ 下建两个文件。config.toml:
toml
model_provider = "custom"
model = "gpt-5.4"
model_reasoning_effort = "xhigh"
network_access = "enabled"
disable_response_storage = true
[model_providers.custom]
name = "custom"
base_url = "${YOUR_BASE_URL}/v1"
wire_api = "responses"
requires_openai_auth = trueauth.json:
json
{
"OPENAI_API_KEY": "sk-你的Key"
}Gemini CLI
改 ~/.gemini/.env,设 GOOGLE_GEMINI_BASE_URL=${YOUR_BASE_URL},模型用 gemini-3.1-pro-preview。
Cursor
Settings → Models 里 Override OpenAI Base URL,填 ${YOUR_BASE_URL}/v1,再填 Key 和模型名。
Python
python
from openai import OpenAI
client = OpenAI(
api_key="sk-你的Key",
base_url="${YOUR_BASE_URL}/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Hello!"}]
)
print(response.choices[0].message.content)踩过的坑
报 Invalid API Key 大概率是 Base URL 没改对,先跑一下 curl ${YOUR_BASE_URL}/v1/models 验证连通性。
另外一个常见问题:有些聚合平台的模型名跟官方不完全一致,比如 claude-3-5-sonnet 和 claude-3-5-sonnet-20241022 可能是不同的模型映射。调不通先看文档确认模型名。
稳定性和数据安全
先说我自己的体感:用了大概三周,Claude 系列的调用成功率还行,偶尔会有几秒的延迟波动,但没遇到长时间不可用的情况。GPT 系列偶尔会返回 rate limit 错误,估计是上游的号池不够,等一会儿再试就好了。
这其实是所有聚合平台的通病------你的请求多了一跳,延迟和错误率天然比直连高。自建 one-api 也一样,上游渠道挂了你也得等。区别在于自建的话你能看到是哪个渠道挂了,第三方平台你只能等它恢复。
数据安全方面,说实在话,你用任何第三方聚合平台都得信它那句"不存 Prompt"------你没法审计它后端到底存没存。这一点不分国内国外,OpenRouter 也一样。如果调用内容涉及真正敏感的商业机密,建议直连官方 API 或者走企业版合同。日常写代码、做个人项目、跑实验,问题不大。
团队管控:一个被忽视的刚需
这块我多说几句,因为之前我们组吃过亏。
五六个人共用一把 Key,月底谁用了多少全靠猜,有人离职了 Key 还在跑,想禁用都不知道该禁哪个。这不是某个平台的问题,而是"团队用 API"这个场景天然需要管控。
自建 one-api / new-api 在这方面做得不错,支持多用户、多渠道、按用户设配额,但你得自己部署运维。
第三方聚合平台里,我试的这家有个企业管理后台,我进去看了一圈:
三级角色(所有者/管理员/成员),权限分得比较清楚:
| 功能 | 所有者 | 管理员 | 成员 |
|---|---|---|---|
| 数据看板 | ✅ | ✅ | ❌ |
| 成员管理 | ✅ | ✅ | ❌ |
| 配额与模型限制 | ✅ | ✅ | ❌ |
| 审计日志 | ✅ | ✅ | ❌ |
| 全部令牌管理 | ✅ | ✅ | ❌ |
| 个人令牌 | ✅ | ✅ | ✅ |
| IP 白名单 | ✅ | ❌ | ❌ |
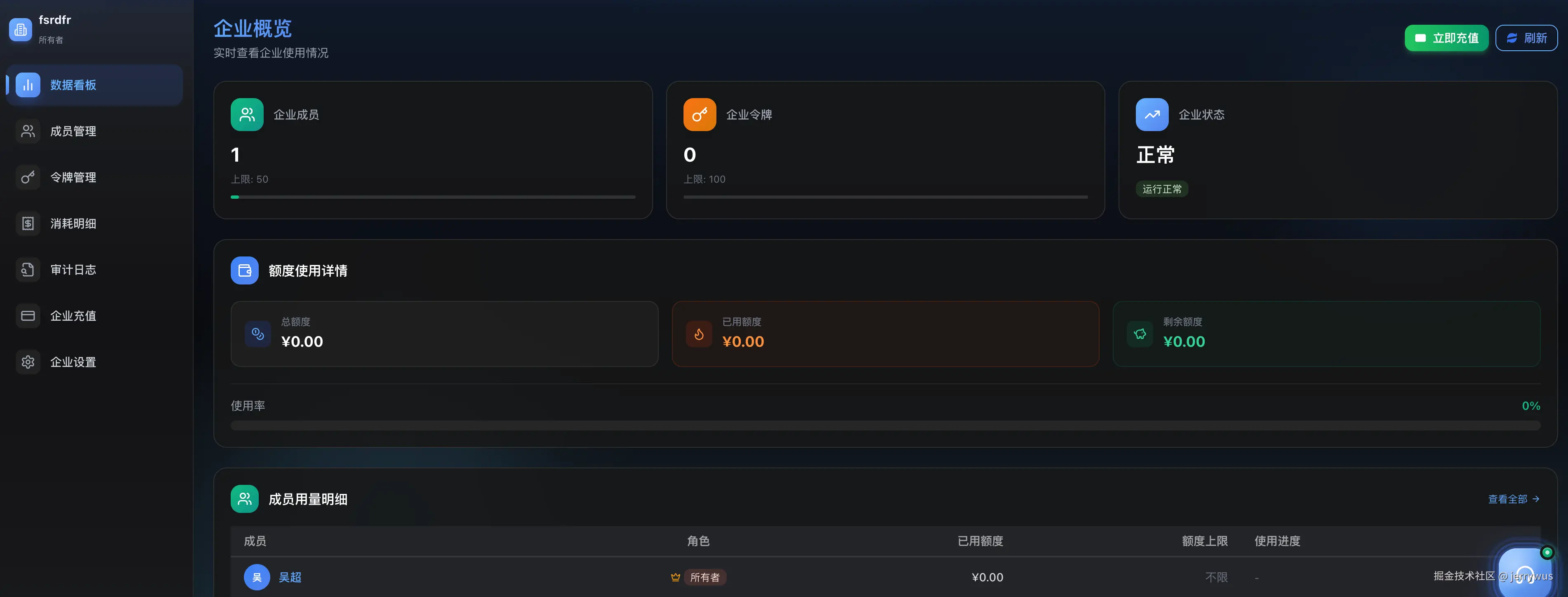
几个对我有用的点:给每个人设额度上限,限制可用模型(实习生用 Haiku 就够了),人走了一键禁用。IP 白名单分两层(企业级 + 令牌级),Key 泄露了但 IP 不在白名单里就调不了。
不过跟真正的企业级 API 管理平台(Kong、Apigee)比,颗粒度还是差不少。没有按部门分层级、没有审批流、没有跟内部 SSO 对接。几十人以上的团队可能还是得在上面再包一层自己的管控。
三种方案怎么选
| 维度 | 自建 one-api | 海外聚合(OpenRouter) | 国内聚合平台 |
|---|---|---|---|
| 绑外币卡 | 需要(上游渠道) | 需要 | 不需要 |
| 国内网络 | 取决于部署位置 | 不稳定 | 直连 |
| 数据可控性 | 完全可控 | 第三方 | 第三方 |
| 运维成本 | 高(自己部署维护) | 无 | 无 |
| 团队管控 | 内置(需配置) | 有限 | 内置 |
| 价格 | 取决于上游渠道 | 接近官方 | 低于官方 |
| 适合场景 | 有运维能力、数据敏感 | 不在意网络和币种 | 国内团队、个人开发者 |
我个人的选择:日常开发调试用国内聚合平台(省事),涉及敏感数据的项目直连官方 API。如果团队有专职运维且调用量大,自建 one-api 长期成本最低。
踩坑总结
- 聚合平台的文档普遍比较散,模型参数支持情况(function calling、vision 的具体限制)经常得自己试。
- 价格调整不一定有提前通知,定期看账单比看公告靠谱。
- 不同平台对模型名的映射可能不一致,调不通先确认模型名拼写。
- Base URL 带不带
/v1后缀因工具而异,Claude Code 不带,OpenAI SDK 带,搞混了就是Invalid API Key。 - 聚合平台的 rate limit 策略不透明,高并发场景建议做好重试和降级逻辑。
没有完美的方案,只有适合当前阶段的方案。先搞清楚自己最在意什么(价格、稳定性、数据安全、运维成本),再选路线。