项目介绍
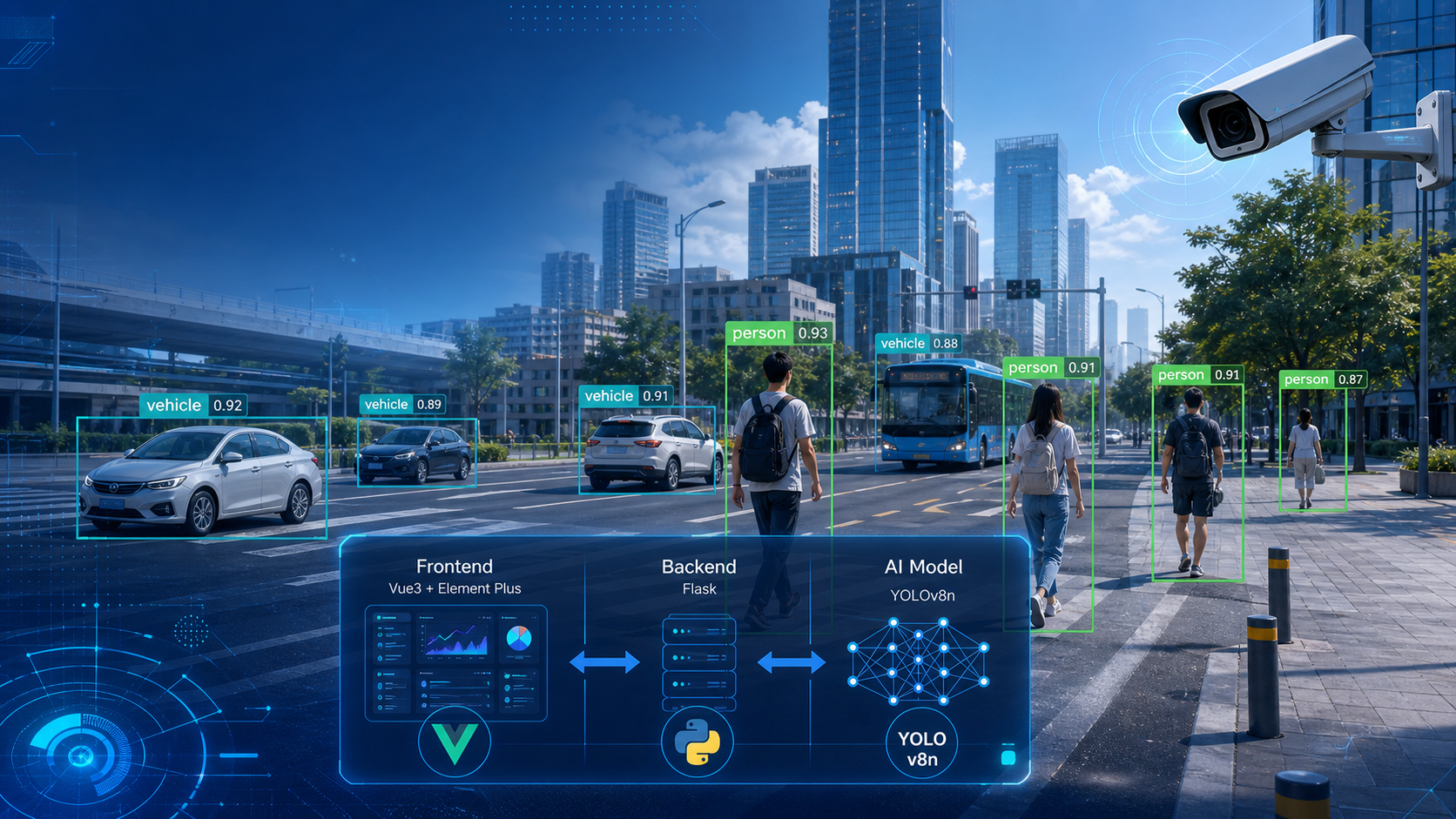
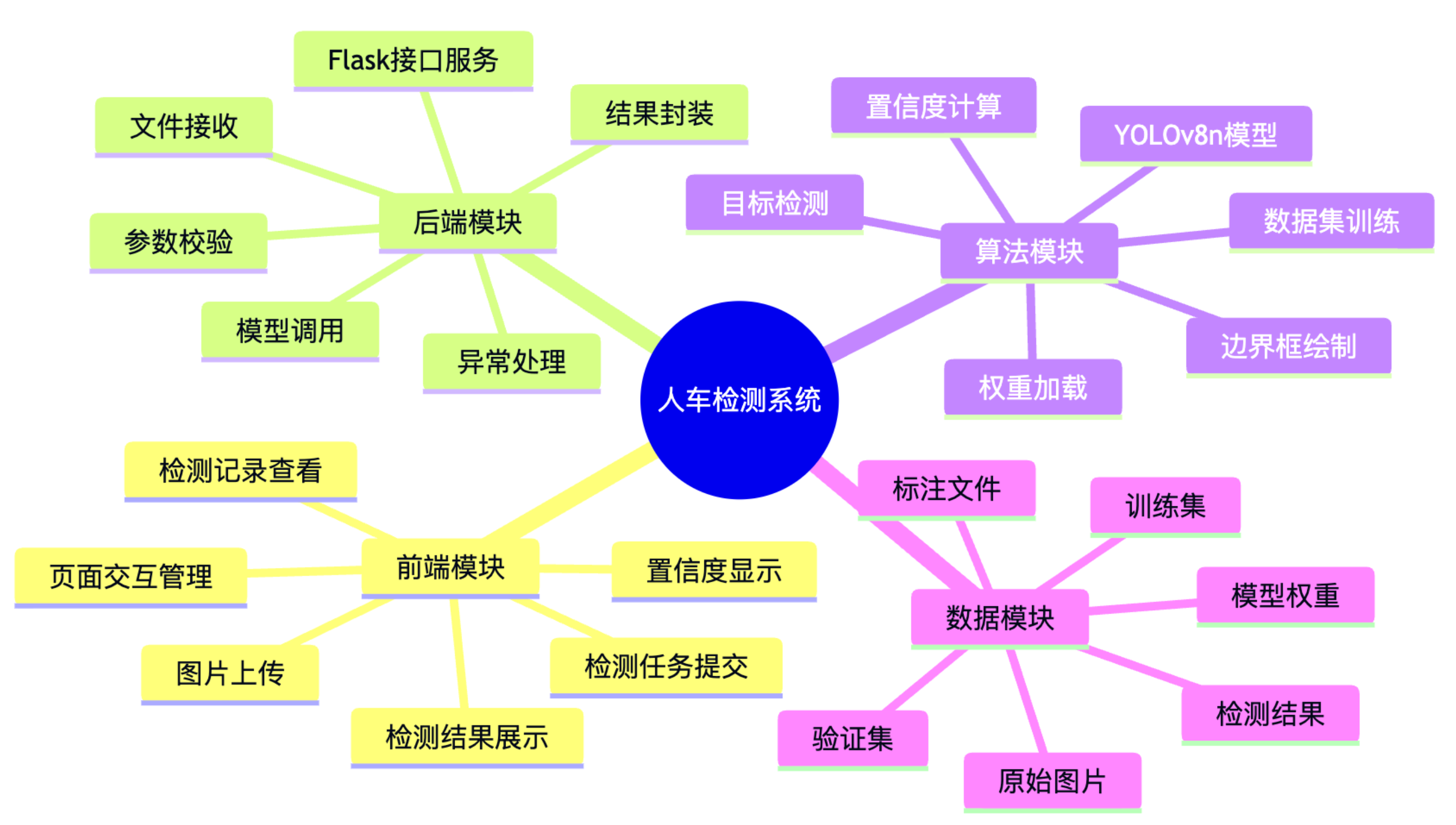
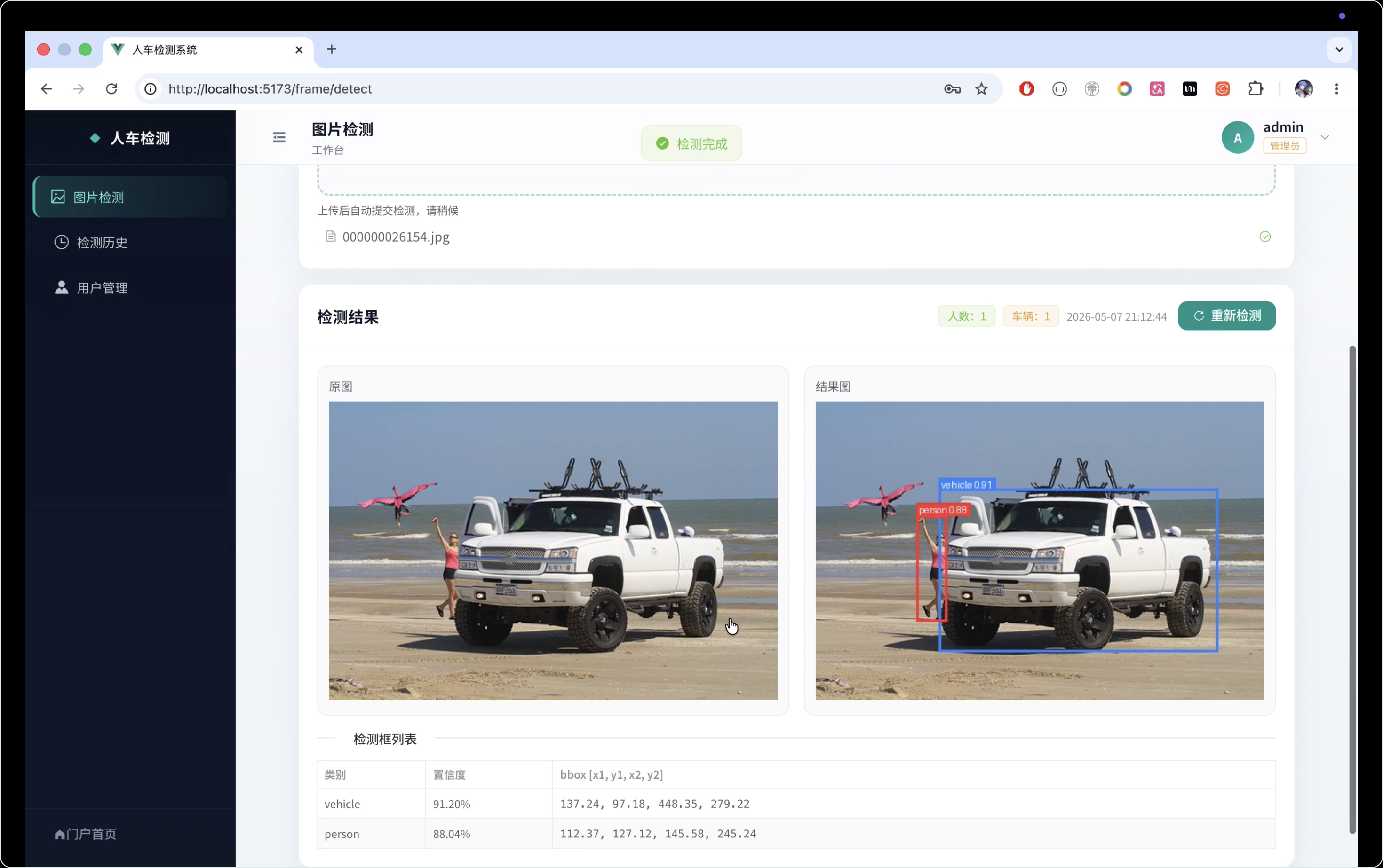
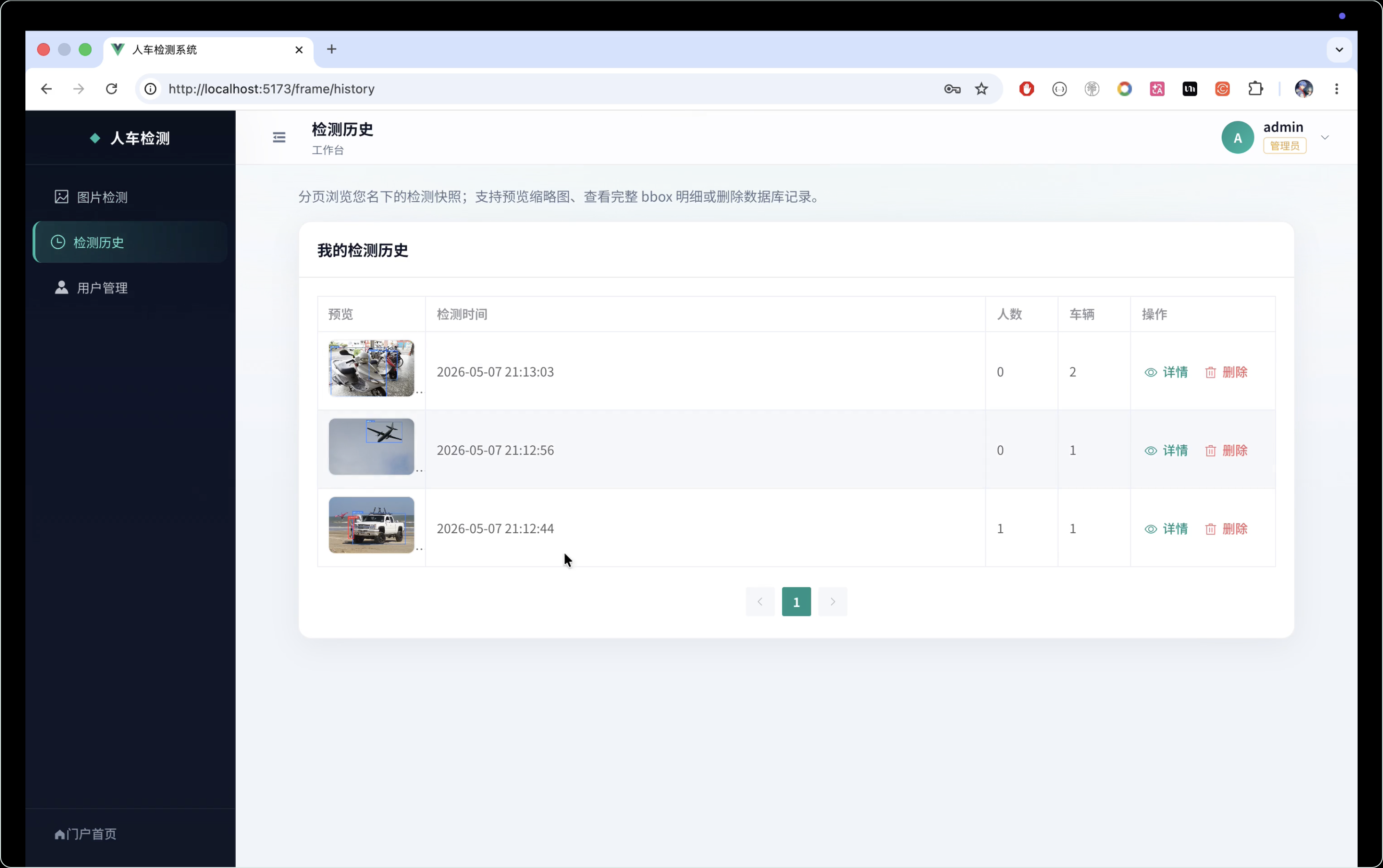
本项目设计并实现了一个基于 YOLOv8n 的人车检测系统,主要用于对图片或视频中的行人与车辆目标进行自动识别、定位和结果展示。系统整体采用前后端分离架构,前端使用 Vue3 与 Element Plus 构建交互界面,提供图片上传、检测任务提交、结果预览、检测记录展示等功能;后端采用 Flask 框架,负责接收前端请求、调用 YOLOv8n 模型完成目标检测,并将检测结果以结构化数据和可视化图片的形式返回给前端。算法部分选用轻量化的 YOLOv8n 模型,在保证检测精度的同时兼顾推理速度,适合部署在普通服务器或轻量级 GPU 环境中。系统能够识别 person 和 vehicle 两类目标,并在检测结果中标注类别名称、置信度和目标位置,为交通监控、园区安防、智能管理等场景提供辅助分析能力。
选题背景与意义
随着城市交通规模扩大和公共安全管理需求提升,传统依赖人工查看监控画面的方式已经难以满足实时性和准确性的要求。行人与车辆是交通场景、园区监控和道路管理中最常见也最重要的目标对象,对其进行自动检测具有较高的实际应用价值。近年来,深度学习目标检测算法发展迅速,YOLO 系列模型因其检测速度快、部署方便、实时性强等特点,被广泛应用于智能交通、视频监控和工业视觉等领域。基于 YOLOv8n 构建人车检测系统,不仅能够提升目标识别效率,还可以减少人工巡检成本,提高监控数据的利用价值。从毕业设计角度来看,本课题综合涉及前端开发、后端接口设计、深度学习模型训练与部署等内容,具有较强的工程实践意义,也能够体现人工智能技术在实际业务系统中的完整应用流程。
关键技术栈:YOLOv8n
YOLOv8 是 Ultralytics 推出的新一代目标检测模型,具有训练流程简洁、推理速度快、精度表现稳定等特点。YOLOv8n 是 YOLOv8 系列中的轻量化版本,其中 n 表示 nano,模型参数量较小,推理速度较快,适合在计算资源有限的环境中部署。本系统使用 YOLOv8n 作为核心检测算法,通过人车检测数据集进行训练,使模型能够识别图片或视频中的行人和车辆目标。YOLOv8n 采用端到端检测思想,可以直接输出目标类别、置信度以及边界框坐标。相比传统目标检测方法,YOLOv8n 不需要复杂的候选区域生成过程,能够在较短时间内完成目标定位与分类。在系统中,后端 Flask 服务负责加载训练好的 YOLOv8n 权重文件,并对前端上传的图片执行推理,最终将检测结果返回给前端页面展示。
技术架构图
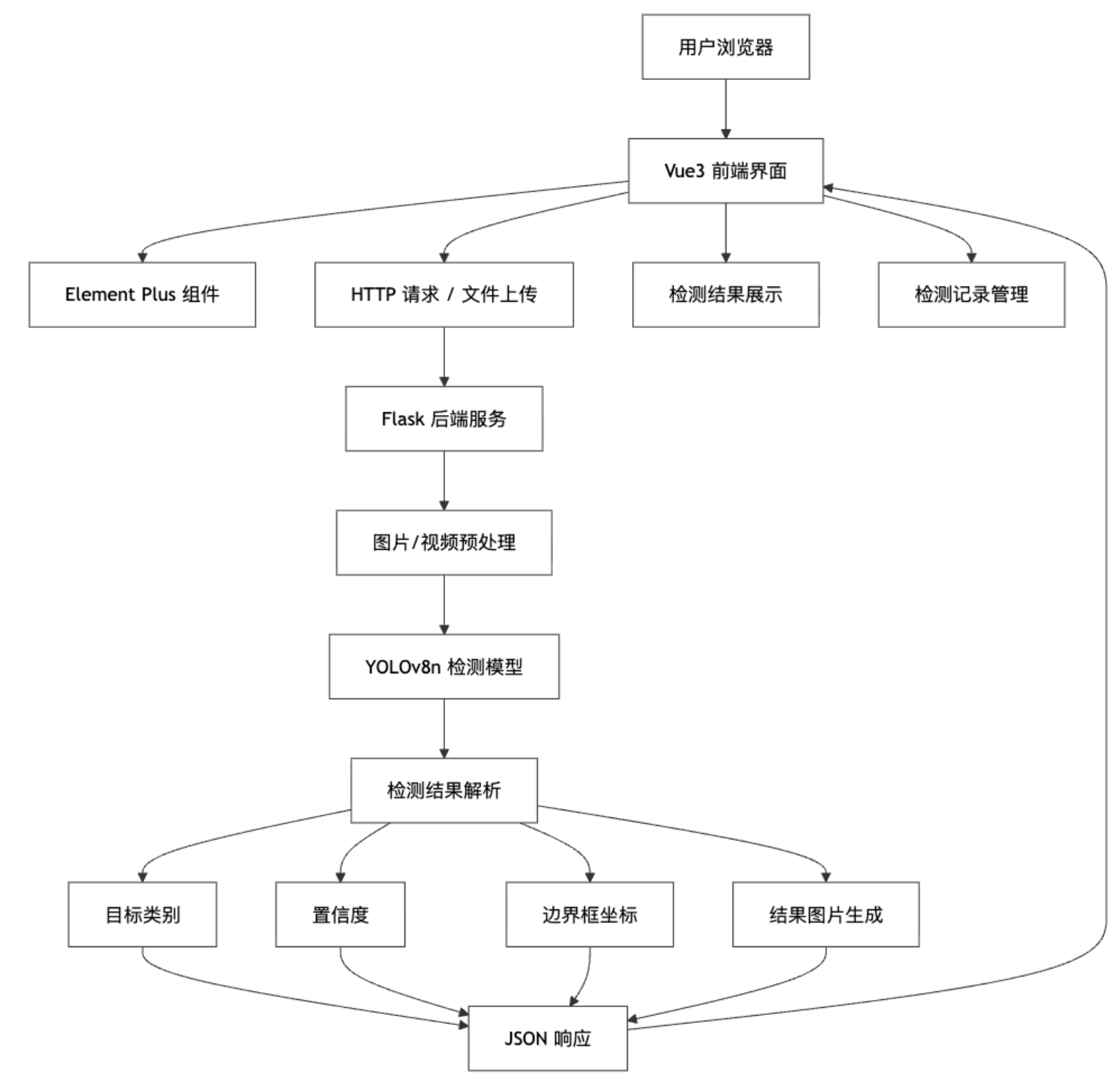
系统功能模块图