一、 研究背景与动机
本文聚焦于多模态大语言模型(MLLM)在"视觉到代码"生成领域的可靠性问题,具体以"电路图到Verilog代码"这一安全攸关的任务作为极限测试场景。电路图作为一种视觉领域特定语言(DSL),其编码的拓扑、时序和位级语义对最终芯片功能至关重要,任何误读都可能导致代价高昂的物理缺陷。

研究发现,现有的MLLM在处理此类任务时存在一个名为"海市蜃楼"(Mirage)的严重缺陷。模型看似能理解电路图,但实际上会绕过视觉输入,转而利用文本提示中module_header(模块头)里包含的标识符(如端口名sum, cout)的语义信息,直接从其内部知识库中检索并生成标准代码模板。这种对文本捷径的依赖,而非真正的视觉理解,不仅导致其在面对无语义信息的匿名化电路图时性能急剧下降,甚至有时真实的电路图反而会干扰其生成过程,这构成了AI辅助编程中一种隐蔽且危险的缺陷,严重威胁了MLLMs的可靠性。
为帮助大家更好地复现,我整理了这篇论文的完整架构图 + 核心算法和零上手复现教程 关注公众号"LLM炼丹炉 ",后台回复"B473"
二、 核心方法
-
整体思路:通过在训练数据中引入标识符匿名化、增加拒绝式回答的负样本,并采用一种决策聚焦的偏好对齐算法(D-ORPO),来强制模型学习电路图的视觉拓扑结构,而不是依赖文本语义捷径,从而实现可靠的视觉-代码生成。
-
关键公式/步骤 : 该方法的核心是一种名为**决策聚焦ORPO(D-ORPO)**的偏好对齐算法。它改进了标准的ORPO(Odds Ratio Preference Optimization)目标函数。标准ORPO损失为:
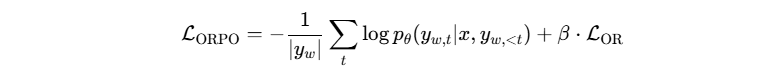
其中,第一项是标准语言模型损失,第二项是偏好损失。D-ORPO的关键创新在于,它认为生成代码还是选择拒绝,这个决策主要由生成序列的最初几个token决定。因此,它引入了一个权重函数来强化对这些关键决策token的梯度。
-
权重函数
w_t:为每个token定义一个权重。 其中,K是决策窗口大小 (如前8个token),α(>1)是决策权重。这使得模型在训练时更加关注生成/拒绝的初始决策。 -
D-ORPO目标函数 :使用加权后的对数概率
\bar{\ell}^D_\theta来替代原有的计算方式,最终的损失函数为:
这使得模型能更好地平衡生成高质量代码与拒绝无效输入之间的关系,避免了标准ORPO因答复长度不一(代码长,拒绝短)而导致的"过度拒绝"问题。
-
-
技术实现要点:
-
区分重要/可变换部分 :通过构建两套并行的训练数据。一套是
Normal数据,保留原始标识符;另一套是Anony数据,将所有有意义的标识符(如模块名、端口名)替换为module_name、val_0等无意义的占位符。通过混合训练这两套数据,迫使模型学习独立于标识符语义的电路拓扑结构。 -
保证语义一致性与多样性:语义一致性通过上述的匿名化混合SFT(监督微调)和D-ORPO对齐来强制实现,确保代码逻辑源于视觉输入。多样性并非本文核心,主要通过标准的代码生成采样策略(如温度采样)来保障。
-
训练策略 :采用三阶段训练流程。首先,在混合了
Normal和Anony数据的数据集上进行监督微调(SFT);其次,构建三类偏好对((chosen, rejected)):(正确代码, 拒绝)、(拒绝, 基于空图像生成的代码)、(拒绝, 基于不匹配图像生成的代码);最后,使用D-ORPO算法对模型进行偏好对齐。
-
三、 实验验证与效果
- 主实验对比 :该方法(名为VeriGround)在作者构建的C2VEVAL基准上进行了评估。
-
在**Normal(标准)**模式下,4B参数的VeriGround功能正确率(Functional Pass@1)达到46.11%,与GPT-5.4(45.51%)相当。
-
在**Anony(匿名化)**模式下,VeriGround的功能正确率达到42.51%,显著优于所有基线模型,包括GPT-5.4(24.55%)和Opus-4.6(11.38%)。这证明了其真正的视觉"接地"(Grounding)能力。
-
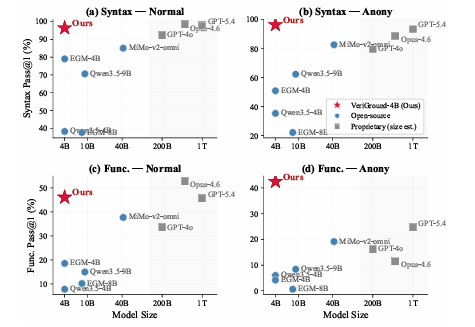
图6
- 深入分析 :
-
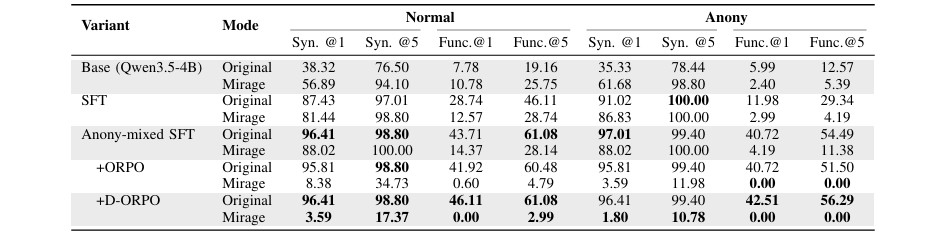
消融实验证明了每个组件的有效性:仅使用标准SFT的模型依然严重依赖文本捷径;加入"匿名化混合SFT"是提升视觉 grounding能力的关键;而D-ORPO相比标准ORPO,在有效抑制错误生成(Mirage)的同时,显著降低了对有效输入的"错误拒绝率"(False Refusal Rate),从8.98%降至1.20%。
-
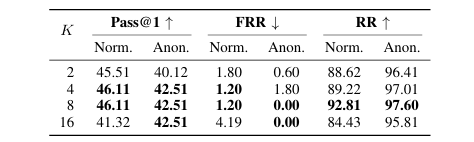
超参数分析 验证了D-ORPO中决策窗口
K=8和决策权重α=2.0为最佳配置,实现了生成质量、错误拒绝和空白图像拒绝率之间的最佳平衡。
-
表VIII
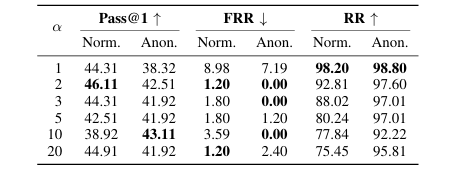
表IX
- 结论与价值:论文的主要贡献是:1)首次识别并系统性地揭示了MLLM在视觉到代码任务中的"海市蜃楼"现象;2)构建了C2VEVAL这一可诊断该问题的基准;3)提出了VeriGround模型,其"匿名化-拒绝增强-对齐"三步训练法能有效恢复模型的视觉 grounding能力。该方法论(如匿名化评估协议)和训练范式具有很强的通用性,可以推广到其他视觉到代码任务,如UI到HTML、图表到Python等。
四、小编总结
这篇论文干脆利落地揭示了一个普遍但易被忽视的问题:多模态模型在代码生成任务中可能在"假装"看图。作者通过一个巧妙的"匿名化"测试(C2VEVAL),证实了顶尖模型也严重依赖文本提示中的"小抄",而非真正理解视觉内容,这种现象被其贴切地称为"海市蜃楼"。
为了解决这个问题,论文提出的VeriGround模型及其训练方法堪称"对症下药":通过混合训练正常和匿名化的数据,强迫模型"睁眼看图";通过专门的拒绝策略教会模型在看不懂或图不对板时"知之为知之,不知为不知";最后用创新的D-ORPO算法精调火候,确保模型既不乱答也不动辄罢工。最终,一个仅4B参数的"小模型"在匿名测试中击败了所有大模型,有力地证明了"真才实学"远比"死记硬背"更可靠。这项工作不仅为硬件设计自动化领域提供了更可信的AI工具,其诊断和训练方法对整个"视觉到代码"领域都具有重要的借鉴意义。