Excel Python:飞速搞定数据分析与处理

第三部分 在 Excel 之外读写 Excel 文件
第八章 使用读写包操作 Excel 文件
本章介绍 OpenPyXL、XlsxWriter、pyxlsb、xlrd 和 xlwt:它们都是可以用来读写 Excel 文件的包,在调用pandas 的 read_excel 函数和 to_excel 函数时,这些包就在背后完成相应的工作。我们可以利用这些读写包来创建更加复杂的 Excel 报表,也可以对文件读取过程进行优化。另外,如果你参与的项目中只需要读写 Excel 文件而不需要 pandas 的其他功能,那么安装整个 NumPy/pandas 技术栈完全就是"杀鸡用牛刀"。本章首先会介绍应当如何从诸多读写包中做出选择,其语法又是怎样的。然后再对一些高级主题进行研究,其中包括如何处理大型Excel 文件,以及如何将 pandas 和各种读写包相结合以改进 DataFrame 的样式。最后会回到第 7 章开头的案例研究,通过调整表格的格式并添加图表来改进这份报表。
8.2 读写包的高级主题
如果你要处理的文件比例子中的 Excel 文件更大且更复杂,默认的设置可能就不够好了。因此本节首先研究如何处理大型文件。然后学习如何将 pandas 和这些读写包结合使用:这样你就可以随心所欲地调整 pandas DataFrame 的样式。在本节末尾,我们会运用本章中学到的所有知识来让第 7 章案例研究中的报表看起来更加专业。
8.2.1 处理大型 Excel 文件
处理大型 Excel 文件时可能会遇到两个问题:一是读写的过程可能很慢;二是你的计算机可能会耗尽内存。内存不足通常是一个大问题,因为它会导致程序崩溃。一个文件大不大总是取决于你的系统资源以及你对慢的定义。本节会展示各个包提供的一些优化技巧,这些技巧可以让你尽可能地处理更庞大的 Excel 文件。我会先研究写入库提供的选项,然后再研究读取库提供的选项。在本节末尾,我会向你展示如何并行读取工作簿的工作表以减少处理时间。
1、使用 OpenPyXL 写入文件
在使用 OpenPyXL 写入大型文件时,一定要安装好 lxml 包,因为 lxml 可以让写入过程更迅速。Anaconda 中已经包含了这个包,所以无须再进行额外的操作。然而,最关键的选项是 write_only=True 标志,它可以让内存消耗保持在较低的水平。不过,这个参数会通过 append 方法强制逐行写入,并且不再允许写入单个单元格。
In [34]: book = openpyxl.Workbook(write_only=True)
# 设置 write_only=True 参数后 book.active 就不可用了
sheet = book.create_sheet()
# 生成一张包含 1000x200 个单元格的工作表
for row in range(1000):
sheet.append(list(range(200)))
book.save("openpyxl_optimized.xlsx")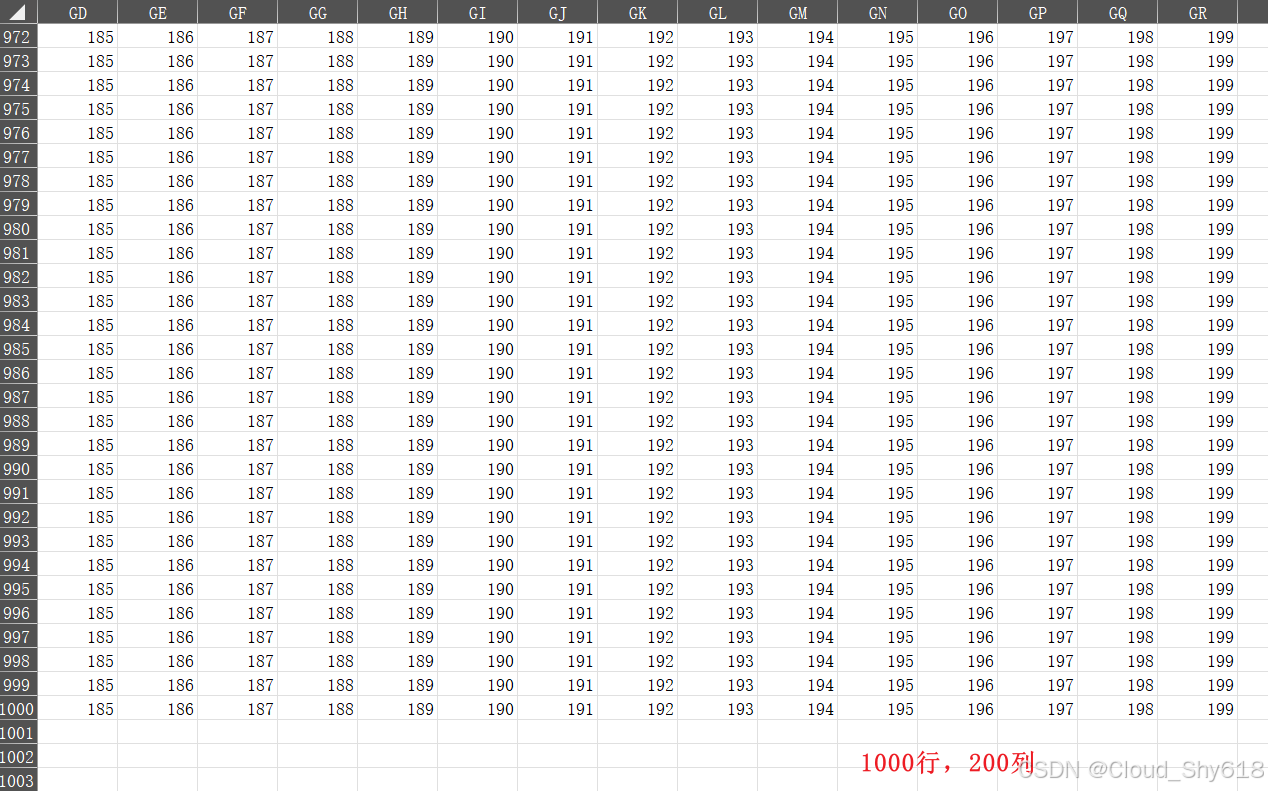
2、使用 XlsxWriter 写入文件
XlsxWriter 有一个和 OpenPyXL 类似的选项叫作 constant_memory。它也会强制逐行写入。 你需要像下面这样以字典的形式来传递 options 参数。
In [35]: book = xlsxwriter.Workbook("xlsxwriter_optimized.xlsx",
options={"constant_memory": True})
sheet = book.add_worksheet()
# 生成一张包含 1000x200 个单元格的工作表
for row in range(1000):
sheet.write_row(row , 0, list(range(200)))
book.close()生成的文件和上图是一样的。
3、使用 xlrd 读取文件
在读取旧式的 xls 格式的大型文件时,xlrd 可以按需加载工作表,就像下面这样:
In [36]: with xlrd.open_workbook("xl/stores.xls", on_demand=True) as book:
sheet = book.sheet_by_index(0) # 只加载第一张工作表如果不想像这里的代码这样将工作簿用作上下文管理器,则需要手动调用 book.release_ resources() 来正确关闭工作簿。要搭配 pandas 在上下文管理器模式下使用 xlrd,可以像下面这样编写代码。
In [37]: with xlrd.open_workbook("xl/stores.xls", on_demand=True) as book:
with pd.ExcelFile(book, engine="xlrd") as f:
df = pd.read_excel(f, sheet_name=0)
4、使用 OpenPyXL 读取文件
要在使用 OpenPyXL 读取大型 Excel 文件时控制内存 ,应该使用 read_only=True 参数来加载工作簿。由于OpenPyXL 并不支持 with 语句,因此需要确保在工作完成时关闭文件。 如果你的文件包含指向外部工作簿 的链接,那么可能还需要使用 keep_links=False 参数来加速读取过程。keep_links 可以确保对外部工作簿的引用不会丢失 ,因而如果你只对读取某个工作簿的值感兴趣,那么将这个参数设置为 True 可能会造成不必要的性能损失。
In [38]: book = openpyxl.load_workbook("xl/big.xlsx",
data_only=True, read_only=True,
keep_links=False)
# 在这里执行所需读取操作
book.close() # 需设置参数 read_only=True
5、并行读取工作表
在使用 pandas 的 read_excel 函数读取大型工作簿的多张工作表 时,你会发现这个过程会花很长时间(马上会看到一个具体的例子)。这是因为 pandas 会逐张读取 工作表。要想让这个过程更快,可以并行读取这些工作表。虽然由于文件的内部结构,并不存在一种简单的方法让工作簿写入过程并行化,但并行读取多张工作表还是非常简单的。不过,由于并行化 是一个高级主题,因此在 Python 入门部分略过了这个主题,将其放在了这里进行详细介绍。
在 Python 中,如果想充分利用现代计算机都具备的多核处理器 ,就需要使用标准库中的多线程包 。多线程包会生成多个并行执行任务的 Python 解释器 (通常一个 CPU 核心一个解释器 )。此时不再是逐张处理工作表,而是一个Python 解释器处理第一张工作表,与此同时另一个 Python 解释器处理第二张工作表,以此类推。然而,每个额外的 Python 解释器都需要一定时间启动且需要占用额外的内存,所以如果你的文件很小,那么并行读取反而可能会更慢。对于包含多个大型工作簿的大型文件的情况,多线程可以显著加快读取过程,不过这是在假定你的系统有足够的内存处理工作负载的情况下。如果像第 2 章所讲的那样在 Binder 中运行 Jupyter 笔记本,那么你就没有足够的内存,因此并行化的版本会运行得更慢。在配套代码库中,你可以找到 parallel_pandas.py,这是使用OpenPyXL 并行读取工作表的一种简单实现方式。这个模块用起来很简单,无须对多线程有任何了解:
import parallel_pandas
parallel_pandas.read_excel(filename, sheet_name=None)在默认情况下,它会读取所有工作表,不过你可以提供一个想要处理的工作表名称的列表。和 pandas 类似,这个函数会返回如下形式的字典:{"sheetname": df},即以工作表名称为键、DataFrame 为值。
魔法指令 %%time
让我们来了解一下 %%time 单元格魔法。第 5 章通过 Matplotlib 介绍过魔法指令。%%time 是一个可以用来优化性能 的实用单元格魔法,它可以轻松地对比不同代码片段的执行时间 。**真实时间(wall time)**是程序(在这里是单元格)从头到尾经过的时间。如果你使用的是 macOS 或 Linux,则不仅会得到真实时间,还会得到一行 CPU 时间:
CPU times: user 49.4 s, sys: 108 ms, total: 49.5 sCPU 时间测量的是程序在 CPU 上花费的时间,这个时间可能比真实时间短(如果程序必须等待 CPU 可用的话),也可能比真实时间长(如果程序在多核处理器上并行执行的话)。为了更准确地测量时间,需要使用 %%timeit 而不是 %%time,%%timeit 会运行单元格多次并取平均时间 。%%time 和 %%timeit 都是单元格魔法,也就是说它们必须出现在单元格的第一行,并且测量的是整个单元格的执行时间。如果你只想测量一行的执行时间,则可以在行首使用 %time 或 %timeit。
让我们先来看一下 big.xlsx 这个文件的大小如何:

下面来见识一下并行读取 big.xlsx(你可以在配套代码库的 xl 文件夹中找到)的代码有多快:
In [39]: %%time
data = pd.read_excel("xl/big.xlsx",
sheet_name=None, engine="openpyxl")
Wall time: 49.5 s # 真实时间
In [40]: %%time
import parallel_pandas
data = parallel_pandas.read_excel("xl/big.xlsx", sheet_name=None)
Wall time: 12.1 s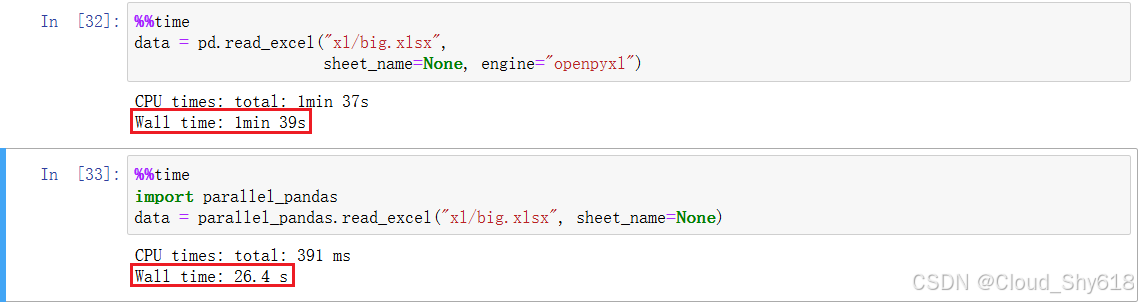
从上图的两段代码执行结果的对比不难看出:在引入 parallel_pandas 这个模块处理 big.xlsx 文件的时间大幅减少了将近 75% 左右。
要获得代表 Sheet1 的 DataFrame,在两种情况下都是使用 data"Sheet1"。如果还想更快,可以直接将OpenPyXL 并行化:在配套代码库中可以找到对应的实现(parallel_openpyxl.py),同时还有一个用于 xlrd 并行读取旧式 xls 格式文件的实现(parallel_xlrd.py)。通过底层的包而不是 panda 让你能够跳过 DataFrame 的转换过程, 也可以应用所需的清理过程。这很可能可以帮助你提升代码的运行速度------如果这对你很重要的话。
使用 Modin 并行读取工作表
如果只需读取单张大型工作表,那么值得了解一下 Modin。Modin 项目可以作为 pandas 的替代品。它会并行处理单张工作表的读取过程,并实现显著的速度提升。由于 Modin 需要指定版本的 pandas,因此你在安装 Modin时可能会导致 Anaconda 附带的 pandas 被降级。如果想尝试一下,建议你为此创建一个单独的 Conda 环境, 确保你的 base 环境不会被弄乱。参见附录 A 详细了解如何创建 Conda 环境:
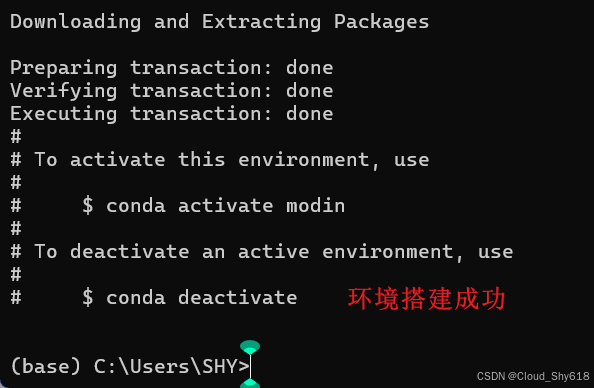
(base)> conda create --name modin python=3.8 -y
(base)> conda activate modin
(modin)> conda install -c conda-forge modin -y笔者在实际操作后,出现一点小问题,记录在此。
首先是在 Anaconda Prompt 窗口下,在 base 环境下输入 "conda create --name modin python=3.8 -y" 出现报错的情况。
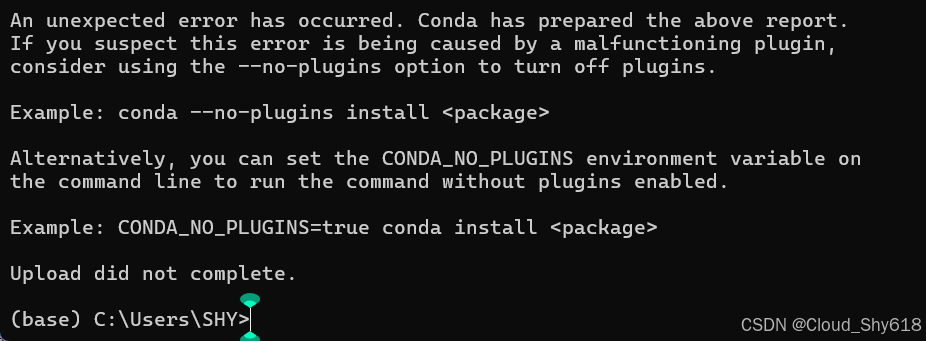
在网上查阅相关文档后,实现了解决:
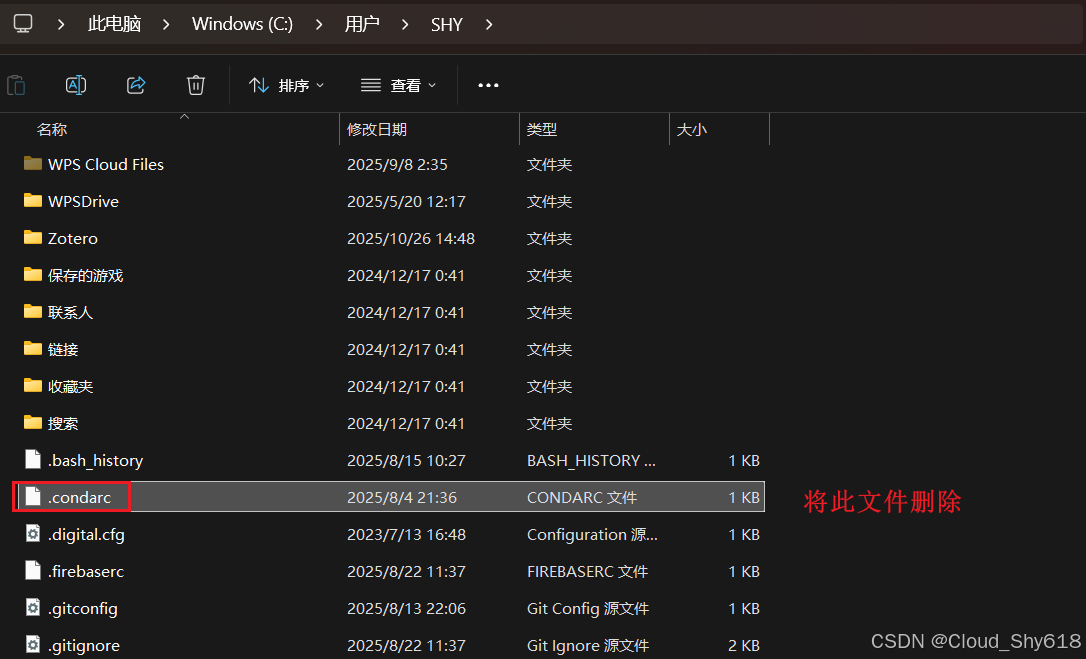
(base) C:\Users\SHY>conda config --show-sources # 查看是否存在.condarc文件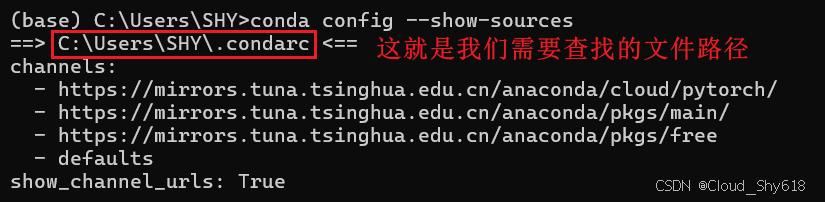
找到上面图片输出的.condarc的文件位置,将.condarc删除。
然后重新执行 conda 新建环境的命令 "conda create --name modin python=3.8 -y"。
接下来,博主激活 modin 环境,执行 "conda install -c conda-forge modin -y" 命令报错:

经过一番刨根问底后,博主发现是系统代理的问题(博主的主机挂了梯子),即:系统代理不支持HTTPS。但是使用命令 "conda install -c conda-forge modin -y" 依旧报错,于是博主改用 pip 命令进行安装(先别急执行此命令,继续往下看):
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple "modin[all]"问题又出现了,安装进行到一半又出现了下图中的报错:
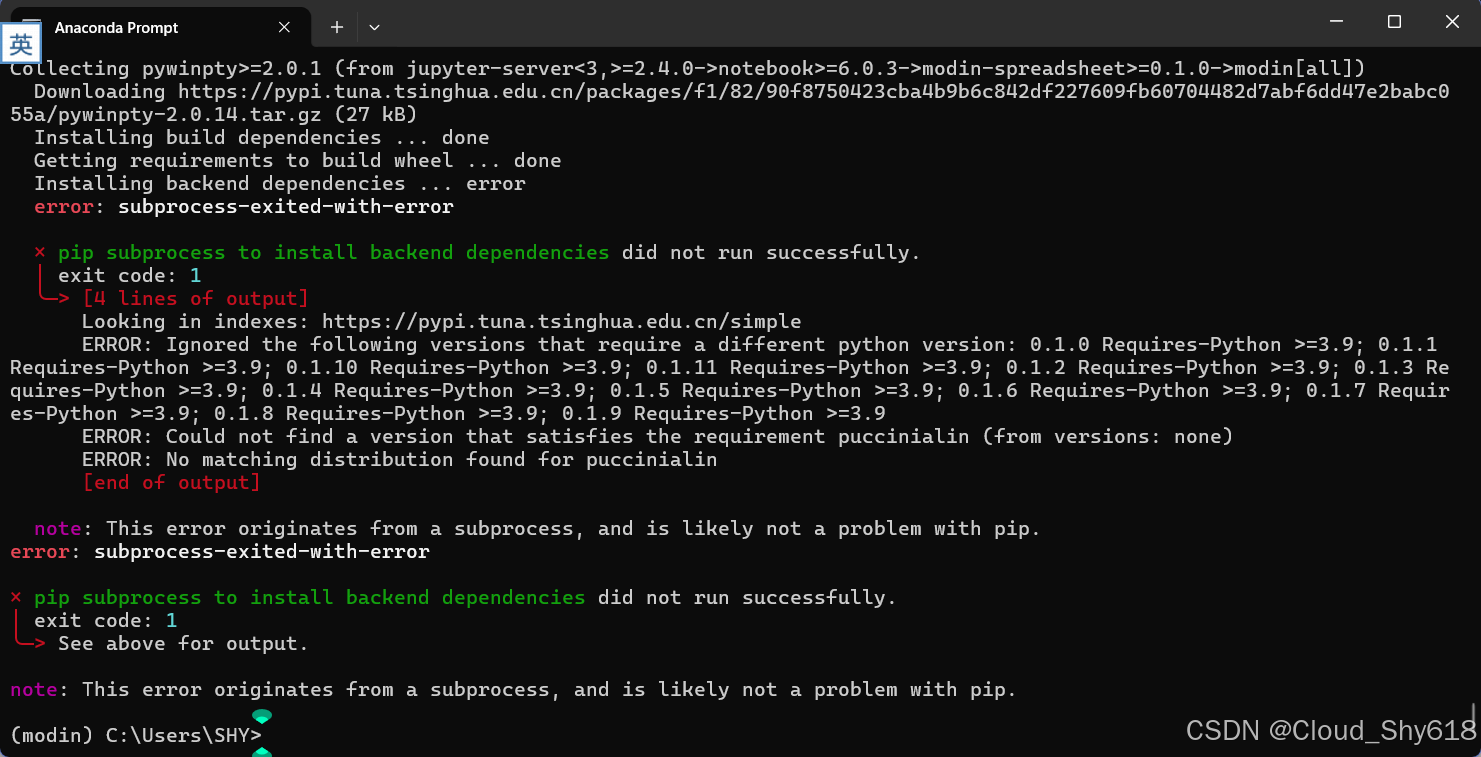
继续查阅相关文档,发现是由于 setuptools 版本问题引起的报错。根据上面报错中显示的要求 Python 版本至少是 3.9 以上,但是博主构建的 modin 环境是基于 python 3.8 版本的。因此需要安装与之对应的 setuptools 版本。先来查看当前 modin 环境下的 setuptools 的版本:
pip show setuptools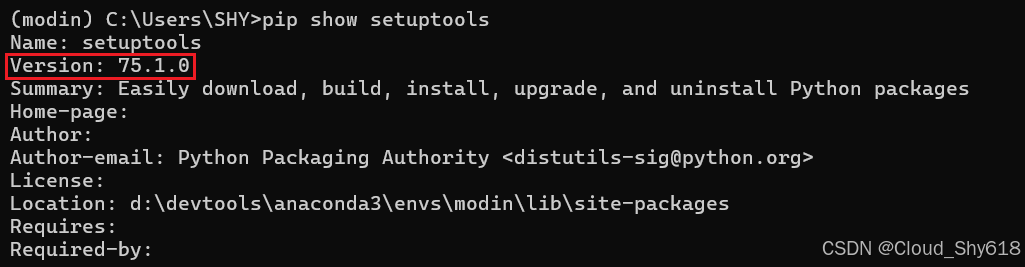
我们来到 setuptools 的官网查找对应的 setuptools 版本,找到 setuptools 70.0.0 正好对应 python >= 3.8。
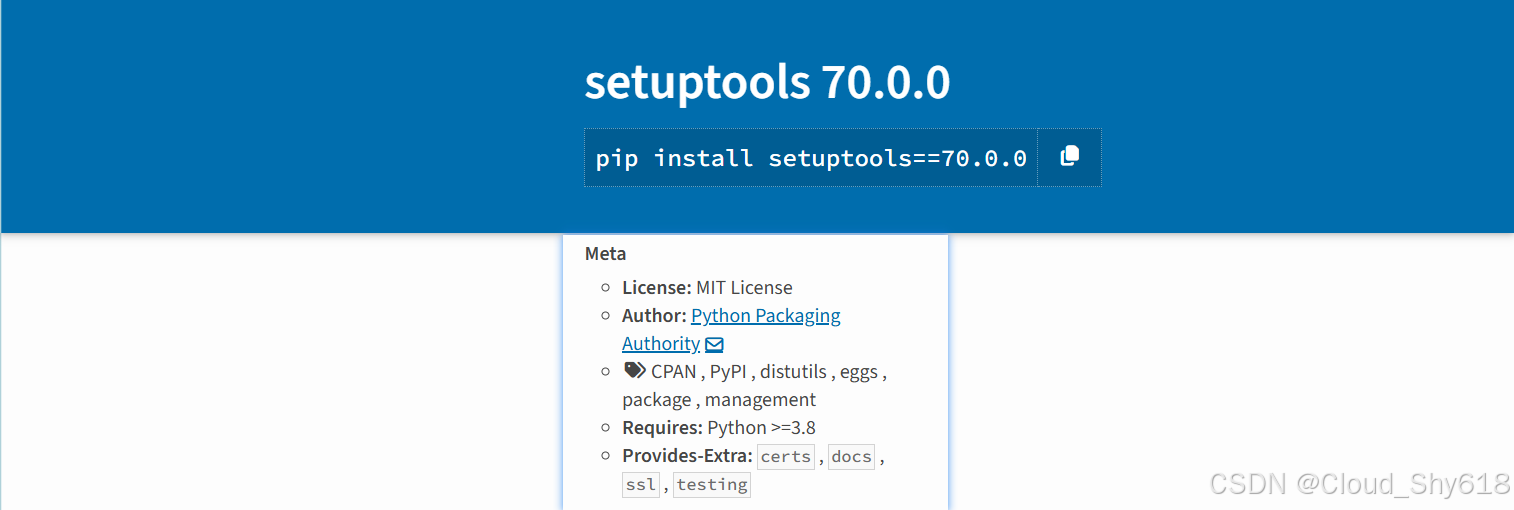
于是,回到命令行窗口,先将 setuptools 的当前版本卸载,重新安装对应的 70.0.0 版本。
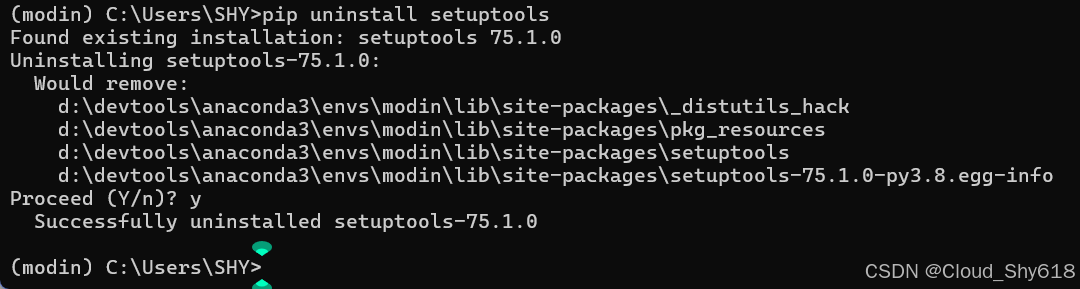
pip install setuptools==70.0.0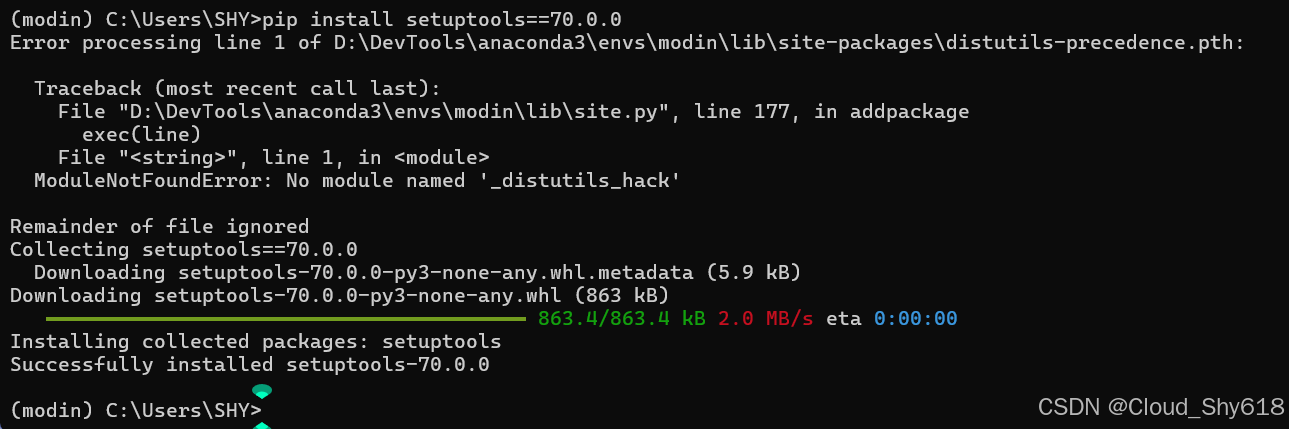
ok,重新执行命令 pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple "modinall",你会发现还是出现了相同的报错,博主哭了。但是困难就是这样,不断出现,才有挑战。于是,博主将这段报错 copy 下来,丢给 Claude Sonnet 帮我分析原因,给出了如下答案:
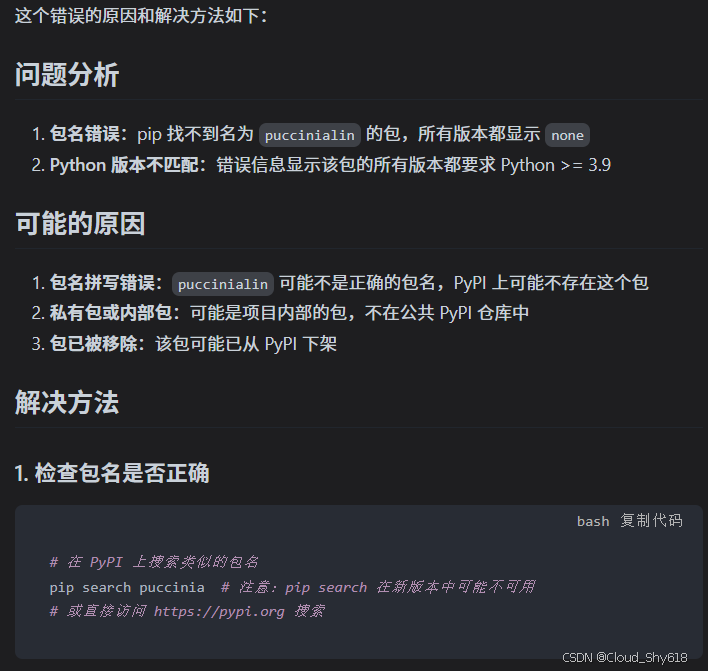
那么,博主就先来看看 puccinialin 是个什么。百度后得到这样的答案:
puccinialin是一个Python包,主要用于Rust环境的安装和构建依赖管理,在某些Python包安装过程中可能被误认为必需依赖。
好啊,原来是 Rust 环境的包。因为博主安装的是 modinall,所以导致报错。那么我们来安装 modindask 试一试。输入命令(放心执行吧!):
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple "modin[dask]" # 改成 modin[dask]
可以看到,安装没有问题,继续下一步。首先安装 conda 包,移步附录 A 按照步骤进行安装。然后,输入以下命令,激活内核:
pip install ipykernel -i https://pypi.tuna.tsinghua.edu.cn/simple
python -m ipykernel install --user --name=modin激活成功后,在 modin 环境下输入 "jupyter notebook",启动网页:

可以看到,我们成功地切换到 modin 环境下运行。输入以下命令:
import modin.pandas
import os
os.environ["MODIN_ENGINE"] = "dask"
%%time
data = modin.pandas.read_excel("xl/big.xlsx",
sheet_name=0, engine="openpyxl")
至此,经过一番折腾,我们成功地证明了在读取单张大型工作表时,Modin 确实能在读取速度上带来显著提升。
8.2.2 调整DataFrame在Excel中的格式
要想按照需求调整 DataFrame 在 Excel 中的格式,可以将 pandas 与 OpenPyXL 或 XlsxWriter 结合使用。首先用它们来为导出的 DataFrame 添加一个标题。然后对 DataFrame 的标题和索引进行格式化。最后再格式化 DataFrame 的数据部分。在读取文件的过程中将 pandas 和 OpenPyXL 搭配使用在有些时候相当强大,所以从这里开始:
In [41]: with pd.ExcelFile("xl/stores.xlsx", engine="openpyxl") as xlfile:
# 读取DataFrame
df = pd.read_excel(xlfile, sheet_name="2020")
# 获取OpenPyXL工作簿对象
book = xlfile.book
# OpenPyXL代码从这里开始
sheet = book["2019"]
value = sheet["B3"].value # 读取单个值
在写入工作簿时,其工作方式是类似的,我们可以方便地为 DataFrame 报表添加一个标题:
In [42]: with pd.ExcelWriter("pandas_and_openpyxl.xlsx",
engine="openpyxl") as writer:
df = pd.DataFrame({"col1": [1, 2, 3, 4], "col2": [5, 6, 7, 8]})
# 写入DataFrame
df.to_excel(writer, "Sheet1", startrow=4, startcol=2)
# 获取OpenPyXL工作簿和工作表对象
book = writer.book
sheet = writer.sheets["Sheet1"]
# OpenPyXL的代码从这里开始
sheet["A1"].value = "This is a Title" # 写入单个单元格的值
这些示例中使用了 OpenPyXL,但是对于其他包来说在概念上也是一样的。接下来了解一下应该如何调整 DataFrame 的索引和标题。
1、调整 DataFrame 索引和标题的格式
要想完全控制索引和列标题的格式,最简单的方式是亲自编写相应的代码。下面的示例分别展示了如何利用OpenPyXL 和 XlsxWriter 达到这一目的。先从创建 DataFrame 开始:
In [43]: df = pd.DataFrame({"col1": [1, -2], "col2": [-3, 4]},
index=["row1", "row2"])
df.index.name = "ix"
df
Out[43]: col1 col2
ix
row1 1 -3
row2 -2 4用 OpenPyXL 格式化索引和标题如下:
In [44]: from openpyxl.styles import PatternFill
In [45]: with pd.ExcelWriter("formatting_openpyxl.xlsx",
engine="openpyxl") as writer:
# 将整个df以默认格式从A1处写入
df.to_excel(writer, startrow=0, startcol=0)
# 将整个df以默认自定义索引/标题格式从A6处写入
startrow, startcol = 0, 5
# 1.写入DataFrame的数据部分
df.to_excel(writer, header=False, index=False,
startrow=startrow + 1, startcol=startcol + 1)
# 获取工作表对象并创建样式对象
sheet = writer.sheets["Sheet1"]
style = PatternFill(fgColor="D9D9D9", fill_type="solid")
# 2.写入带样式的列标题
for i, col in enumerate(df.columns):
sheet.cell(row=startrow + 1, column=i + startcol + 2,
value=col).fill = style
# 3.写入带样式的索引
index = [df.index.name if df.index.name else None] + list(df.index)
for i, row in enumerate(index):
sheet.cell(row=i + startrow + 1, column=startcol + 1,
value=row).fill = style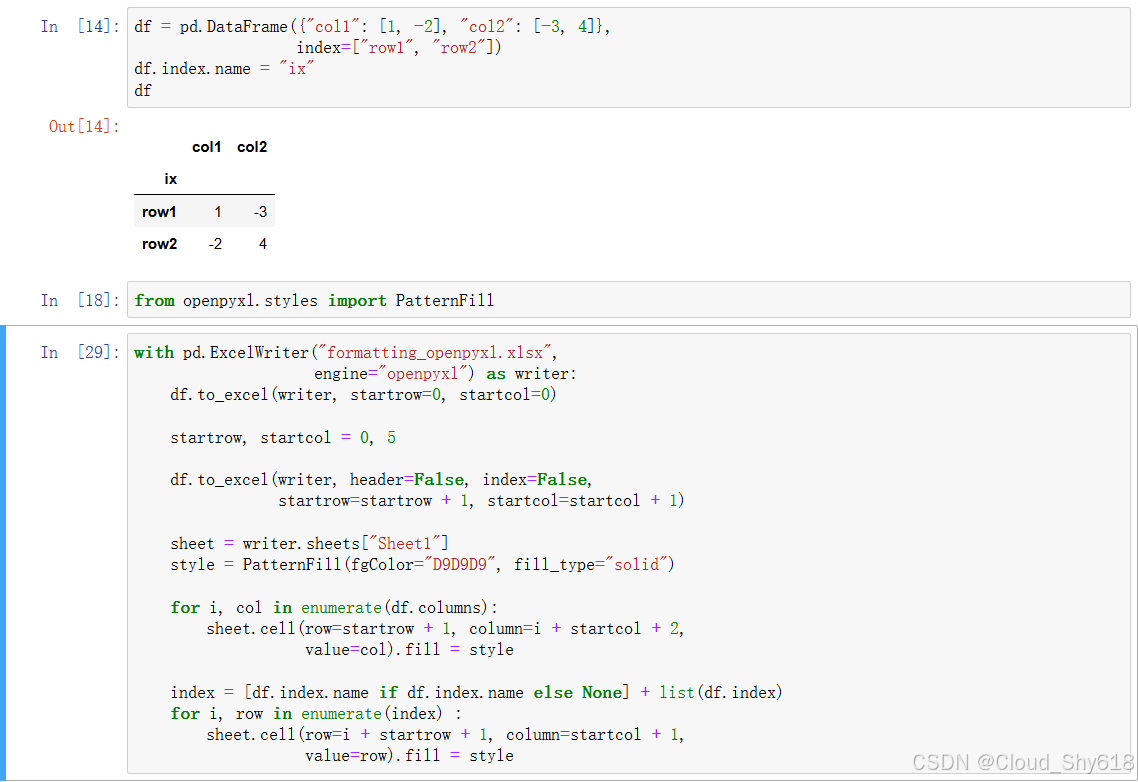
如果想使用 XlsxWriter 对索引和标题进行格式化,那么需要对代码进行一些微调:
In [46]: # 使用XlsxWriter对索引/标题进行格式化
with pd.ExcelWriter("formatting_xlsxwriter.xlsx",
engine="xlsxwriter") as writer:
# 将整个df以默认格式从A1处写入
df.to_excel(writer, startrow=0, startcol=0)
# 将整个df以默认自定义索引/标题格式从A6处写入
startrow, startcol = 0, 5
# 1.写入DataFrame的数据部分
df.to_excel(writer, header=False, index=False,
startrow=startrow + 1, startcol=startcol + 1)
# 获取工作簿对象和工作表对象并创建样式对象
book = writer.book
sheet = writer.sheets["Sheet1"]
style = book.add_format({"bg_color": "#D9D9D9"})
# 2.写入带样式的标题
for i, col in enumerate(df.columns):
sheet.write(startrow, startcol + i + 1, col, style)
# 3.写入带样式的索引
index = [df.index.name if df.index.name else None] + list(df.index)
for i, row in enumerate(index):
sheet.write(startrow + i, startcol, row, style)执行后生成的文件如下:

表格中为带有默认格式的DataFrame(左)和带有自定义格式的DataFrame(右)。
2、格式化 DataFrame 的数据部分
数据部分的格式化能达到何种程度取决于你所使用的是哪种包:如果你使用的是 pandas 的 to_excel 方法,那么OpenPyXL 可以为每一个单元格应用一种格式,而 XlsxWriter 只能对行或列应用格式。如果要设置单元格的数字格式为 3 位小数并居中内容(见下图), 那 么可以使用 OpenPyXL 编写如下代码。
In [47]: from openpyxl.styles import Alignment
In [48]: with pd.ExcelWriter("data_format_openpyxl.xlsx",
engine="openpyxl") as writer:
# 写入DataFrame
df.to_excel(writer)
# 获取工作簿对象和工作表对象
book = writer.book
sheet = writer.sheets["Sheet1"]
# 格式化每一个单元格
nrows, ncols = df.shape
for row in range(nrows):
for col in range(ncols):
# 考虑到标题/索引,这里加1
# 因为 OpenPyXL 的索引是从 1 开始的,所以还要加 1
cell = sheet.cell(row=row + 2,
column=col + 2)
cell.number_format = "0.000"
cell.alignment = Alignment(horizontal="center")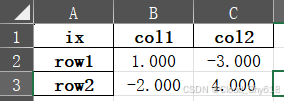
对于 XlsxWriter,将代码进行如下调整:
In [49]: with pd.ExcelWriter("data_format_xlsxwriter.xlsx",
engine="xlsxwriter") as writer:
# 写入DataFrame
df.to_excel(writer)
# 获取工作簿对象和工作表对象
book = writer.book
sheet = writer.sheets["Sheet1"]
# 格式化各列(无法格式化单个单元格)
number_format = book.add_format({"num_format": "0.000",
"align": "center"})
sheet.set_column(first_col=1, last_col=2,
cell_format=number_format)pandas 在 DataFrame 上提供了实验性的 style 属性作为一种替代品。"实验性"意味着其语法随时可能发生改变。由于样式属性是为了将 DataFrame 格式化为 HTML 而引入的,因此它们使用的是 CSS 语法。CSS 代表 cascading style sheet(层叠样式表),它是用来定义 HTML 元素的样式的。要应用与前面示例中相同的格式(3 位小数和居中对齐),需要通过 applymap 对 Styler 对象的每个元素应用一个函数。通过 df.style 属性可以获得 Styler 对象:
In [50]: df.style.applymap(lambda x: "number-format: 0.000;"
"text-align: center")\
.to_excel("styled.xlsx")在不依赖样式属性的情况下,pandas 还提供了对日期和时间的格式化支持:
In [51]: df = pd.DataFrame({"Date": [dt.date(2020, 1, 1)],
"Datetime": [dt.datetime(2020, 1, 1, 10)]})
with pd.ExcelWriter("date.xlsx",
date_format="yyyy-mm-dd",
datetime_format="yyyy-mm-dd hh:mm:ss") as writer:
df.to_excel(writer)
其他读写包
- pyexcel 为读写不同的 Excel 包以及其他文件格式(包括 CSV 文件和 OpenOffice 文 件)提供了一种通用的语法。
- PyExcelerate 的目标是以尽可能快的速度写入 Excel 文件。
- pylightxl 可以读取 xlsx 文件和 xlsm 文件,可以写入 xlsx 文件。
- styleframe 将 pandas 和 OpenPyXL 相结合以从格式规整的 DataFrame 生成 Excel 文件。
- oletools 并非一个经典的读写包,但它可以分析 Microsoft Office 文档(比如分析恶意软件)。它提供了一种便捷的方法来提取 Excel 工作簿中的 VBA 代码。
8.3 小结
本章首先介绍了 pandas 在底层使用的各种读写包。无须安装 pandas,直接使用这些读写包就能够读写 Excel 工作簿。不过,将它们和 pandas 结合起来则可以通过添加标题、图表、 格式等方式来改进 Excel DataFrame 报表。虽然目前的读写包已经非常强大,但还是希望在某一天出现一个 "NumPy 时刻" 将所有开发者的努力都汇聚到同一个项目中(天下大同)。如果不需要查表就能知道什么时候该用什么包,也不需要为不同的 Excel 文件使用不同的语法, 那就再好不过了。因此,一开始可以尽可能地使用 pandas 来解决这类问题,只在 pandas 没有提供你所需要的功能时才用到读写包。
不过,Excel 远非一个简单的数据文件,也不仅仅是一张简单的报表。Excel 应用程序拥有非常直观的用户界面,用户只需输入几个数字就可以让其显示所需信息。不直接读写 Excel 文件,而是对 Excel 应用程序进行自动化可以让我们进入一个全新的领域,这就是本书第四部分将要探索的内容。第 9 章会展示如何用 Python 远程控制Excel,这就是 Excel 自动化之旅的起点站。