一、引言
在日常的Flink开发与运维中,我们经常面临一个直击灵魂的问题:假设我们总共有 16 CPU核心 和 32GB 内存的资源额度,我们应该怎么分配?是选择"少量大规格slot + 低并行度"还是"大量小规格slot + 高并行度"?
- 方案A(大资源小并行度): 设置 并行度=2,每个Slot分配 8 Core / 16GB。
- 方案B(小资源大并行度): 设置 并行度=8,每个Slot分配 2 Core / 4GB。
这个选择直接影响作业的吞吐量、延迟、稳定性、容错恢复速度以及资源利用率。在Flink中,TaskManager(TM)是工作节点,Task Slot是资源调度的最小单位(主要隔离内存),并行度(Parallelism)决定了Job被拆分成多少个并行的SubTask运行在这些Slot上。本文将深入剖析两种策略的技术原理、适用场景与最佳实践。
二、大资源小并行度 (Fat Slot / Low Parallelism)
这种模式下,作业的SubTask数量少,但每个SubTask拥有充沛的内存和CPU预算。网络层面的Shuffle连接数较少,JVM内部的垃圾回收(GC)压力通常集中在少数几个大内存池中。
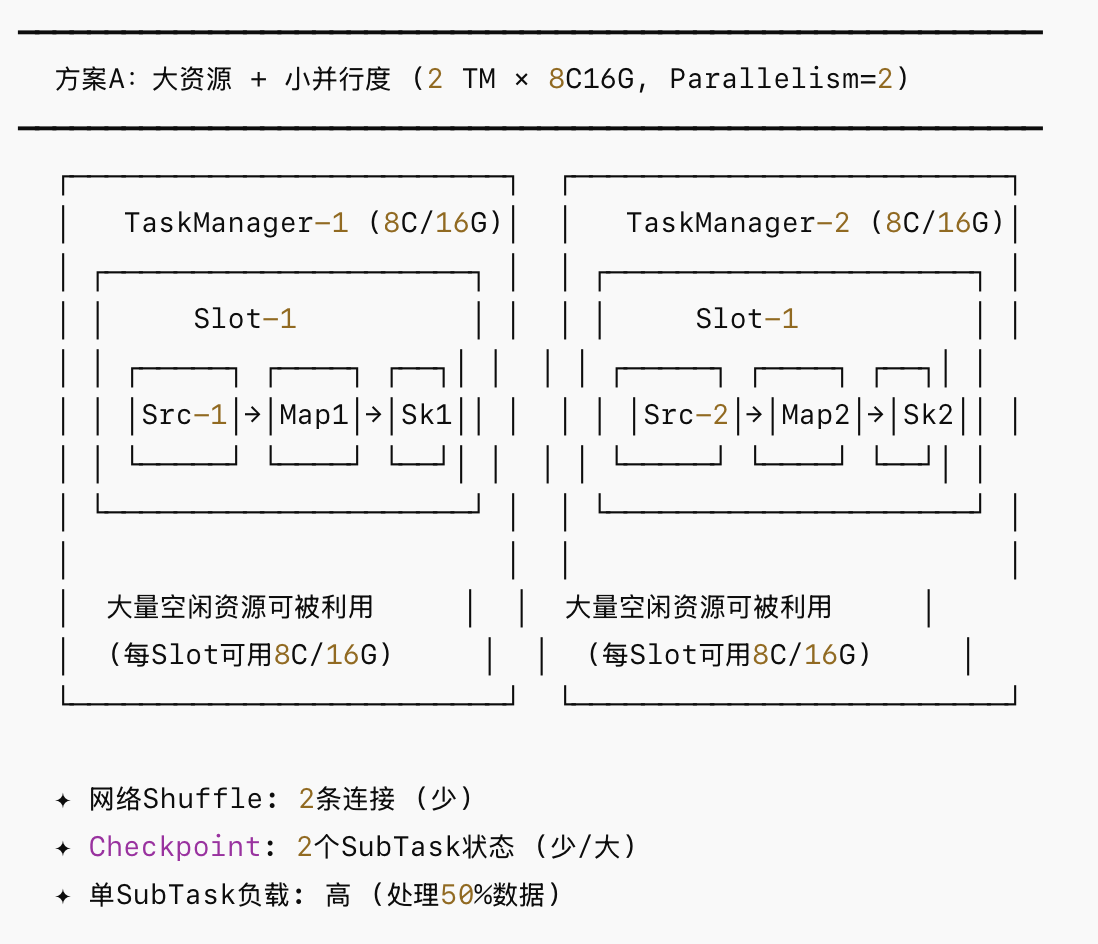
优点:
- 网络开销极小: Flink在Shuffle时,上游Task需要向下游Task发送数据。并行度越低,逻辑网络连接和网络缓冲(Network Buffer)的消耗越小,序列化/反序列化的CPU开销也越低。
- 状态后端(RocksDB)极其友好: RocksDB的内存分配是Per-SubTask的(每个SubTask独占Block Cache和Write Buffer)。大资源小并行度意味着单个TM内运行的RocksDB实例少,不易发生堆外内存溢出(Direct OOM)。
- Checkpoint对齐快: 并行度小,Barrier流动和对齐的节点少,Checkpoint耗时显著降低。
缺点:
- 并发处理能力受限: 对于纯CPU密集型任务(如复杂的JSON解析、解密算法),无法充分利用集群的多核优势。
- 数据倾斜几率大: 一旦发生数据倾斜,庞大的数据量压在一个Slot上,即使资源再大也可能被瞬间击穿。
- 大堆可能存在GC暂停时间长导致反压,Task异常容错恢复时间长、影响面相对大
适用场景:
- 超大状态计算: 包含超长窗口(如7天)聚合、海量维表Join等依赖大容量RocksDB的场景。
- 网络I/O瓶颈明显: 逻辑复杂、Shuffle数据量极大的任务。
三、小资源大并行度 (Skinny Slot / High Parallelism)
通过将作业拆分成大量细粒度的SubTask,分布在整个集群中。每个Slot分配的资源较少(例如1核2G),完全依赖横向扩展(Scale-out)来提升吞吐。

优点:
- 极致的CPU吞吐: 能够将计算逻辑(如Map、Filter)平摊到海量物理核上,处理无状态或轻状态的吞吐极高。
- 数据倾斜的分摊效应: 当并行度足够大且Key分布均匀时,原本可能集中在个别节点的倾斜数据会被打散得更细,降低单点雪崩风险。
缺点:
- 网络爆炸效应: 在KeyBy/Rebalance操作中,逻辑连接数呈 N×NN ×N 增长(N为并行度)。这会极大地消耗Network Buffer,极易引发
Insufficient number of network buffers异常。 - State与JVM额外开销: 并行度过大导致单个TM内产生大量的Thread和RocksDB实例,每个实例的基础内存开销相加,极易导致MetaSpace或堆外内存OOM(严重数据倾斜场景下加剧)。
适用场景:
- 无状态/轻状态ETL: 日志清洗、数据过滤、字段提取(如单纯的Kafka to Kafka任务)。
- CPU密集型计算: 需要大量并发处理且无需频繁网络Shuffle的场景。
四、资源策略最佳实践
| 场景特征 | 推荐策略 | 理由 |
|---|---|---|
| 大状态 + RocksDB (如实时Join、窗口聚合,State > 数十GB) | ✅ 大资源小并行度 | RocksDB单实例可分配更多Block Cache,减少磁盘IO;Checkpoint快照文件数少 |
| 计算密集 + 无明显倾斜 (如复杂CEP、ML推理) | ✅ 小资源大并行度 | 更多并行实例分摊CPU负载 |
| 计算密集 + 数据倾斜严重 | ✅ 大资源小并行度 | 热点SubTask拥有更多资源缓冲 |
| IO密集 (如多Source/多Sink、外部系统Lookup) | ✅ 小资源大并行度 | 更多并行连接提升IO吞吐 |
| Kafka消费 (分区数固定) | ⚡ 并行度=Kafka分区数 | 1:1映射最优,然后据此决定TM规格 |
| 低延迟敏感 (P99 < 100ms) | ✅ 大资源小并行度 | 减少网络Shuffle跳数和Barrier对齐延迟 |
| 高吞吐优先 (百万QPS+) | ✅ 小资源大并行度 | 更多并行度提供更高聚合吞吐 |
| 容器化/K8s环境 | ⚡ 适中资源适中并行度 | 考虑Pod调度效率和资源碎片 |
- 推荐taskmanager.memory.process.size配置在4g ~ 16g ,避免过大或过小
- 推荐taskmanager.numberOfTaskSlots配置在 1 ~ 4,避免资源竞争
- 建议将Source/ETL等无状态算子设置大并行度,将Window/Join等重状态算子设置小并行度
在固定总资源的情况下,建议从较小并行度(如分配单Slot 4C/8G)开始压测,逐步增加并行度(减小单Slot资源),观察吞吐量的增长曲线。当发现增加并行度不仅吞吐不再上升,反而导致Checkpoint变慢时,就找到了当前的资源"拐点"。