1. 什么是 RAG?
1.1 大模型的「阿克琉斯之踵」
在前面的章节中,大模型本质上是基于自身的训练语料和概率统计,结合用户的 prompt 来预测下一个 token(词或符号)的出现概率。这就意味着:模型输出的文本是"语言上最合理"的,但未必是"事实上的正确"。
大模型存在三个核心局限:
| 问题 | 表现 |
|---|---|
| 幻觉(Hallucination) | 模型会自信地编造不存在的事实、数据、引用 |
| 知识滞后性 | 训练数据有截止日期,无法获取最新信息 |
| 知识局限性 | 对垂直领域、私有数据缺乏覆盖 |
1.2 RAG 是什么?
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种让大模型在生成回答前,先从外部知识库中检索相关信息,然后结合这些检索到的内容来生成答案的技术。
核心理念:检索 + 生成 ------模型不再"凭自身经验瞎说",而是"查完资料再说"。

1.3 RAG vs 微调
| 维度 | RAG | 微调(Fine-tuning) |
|---|---|---|
| 知识更新方式 | 实时检索,知识库更新即可 | 需要重新训练 |
| 适用场景 | 时效性、事实性问答 | 风格、格式、行为模式调整 |
| 可解释性 | 可溯源到具体文档 | 黑盒,难以解释 |
| 成本 | 低(无需 GPU 训练) | 高(需要算力) |
| 幻觉控制 | 较好(有外部知识约束) | 仍然可能产生幻觉 |
2. RAG 的使用场景
RAG 非常适合用于那些需要事实性、专业性、时效性知识支撑的场景,它让大模型具备"知识更新"和"领域专精"的能力。
RAG 应用场景
企业知识问答
产品说明书
员工行为规范
业绩报告
智能客服
安全分析与情报检索
APT 攻击链分析
威胁情报分析
CVE 安全漏洞解读
专业领域问答
法律合规
医疗诊断辅助
金融风控
2.1 企业知识问答 / 智能客服
企业的知识往往比较私有化,不对外公布,大模型的训练数据集也没有相关的训练语料。通过 RAG,可以将企业的产品说明书、员工行为规范、业绩报告等资料构建为知识库,让客服智能体在回答问题时能够实时检索企业内部知识,生成基于事实的专业回答。
2.2 安全分析与情报检索
在网络安全领域,具有大量的威胁情报、漏洞数据、安全日志等知识源,RAG 可以构建这些数据的知识库,实现大模型对网络安全领域的 APT 攻击链分析、威胁情报分析、CVE 安全漏洞解读等。这类应用让安全分析师能够通过自然语言快速检索、分析和生成报告,大幅提升威胁处置效率。
2.3 法律、医疗、金融等专业领域问答
这些行业的专业知识更新快、术语多、错误代价高,传统大模型受限于训练数据的时间窗口和覆盖范围,往往无法准确反映最新法规、指南或政策变化。通过 RAG,我们可以把这些"新知识"持续地灌输给大模型,作为它的一个 "知识外挂",实现持续知识更新与高质量领域问答。
3. RAG 的核心流程
RAG 的整体流程,以用户提问的时机为分界点,主要可以分为两步:
A2"🔧 文档预处理
加载 / 清洗 / 标准化"
A2 --> A3["✂️ 文档分片<br/>切分为 Chunk"]
A3 --> A4["🧮 向量化<br/>Embedding"]
A4 --> A5["🗄️ 生成索引<br/>存入向量数据库"]
end
subgraph online["🟢 Phase 2: 检索生成(在线)"]
direction TB
B1["❓ 用户提问"] --> B2["🧮 问题向量化"]
B2 --> B3["🔍 相似度检索<br/>向量数据库"]
B3 --> B4["📋 召回 Top-K Chunks"]
B4 --> B5["📝 构建 Prompt<br/>将 Chunks 注入上下文"]
B5 --> B6["🤖 LLM 生成回答"]
end
A5 -.->|"知识库就绪"| B3
style offline fill:#e3f2fd,stroke:#1976d2
style online fill:#e8f5e9,stroke:#388e3c -->
⚠️ 核心警示:「垃圾进,垃圾出」(Garbage In, Garbage Out, GIGO)
在构建索引这一环节,有一句非常经典且核心的警示性原则------GIGO 。无论后续的检索环节做了什么高深莫测的优化和方案,数据源头的质量才是影响最终检索效果的最重要因素。源头数据脏、乱、差,后面的步骤做得再好也是徒劳。
4. 深入索引构建
索引构建的起点是文档 ,终点是索引。下面我们逐一拆解每个环节。
📄 原始文档
🔧 预处理
✂️ 分片
🧮 向量化
🗄️ 索引
• 格式统一
• 去除噪声
• 编码规范化
• 固定大小分片
• 递归分片
• 语义分片
• Embedding 模型
• 高维向量
• 向量数据库
• 相似度查询
4.1 文档预处理
文档预处理指的是将原始文档进行加载、解析,并转换为能够统一处理的标准化格式。
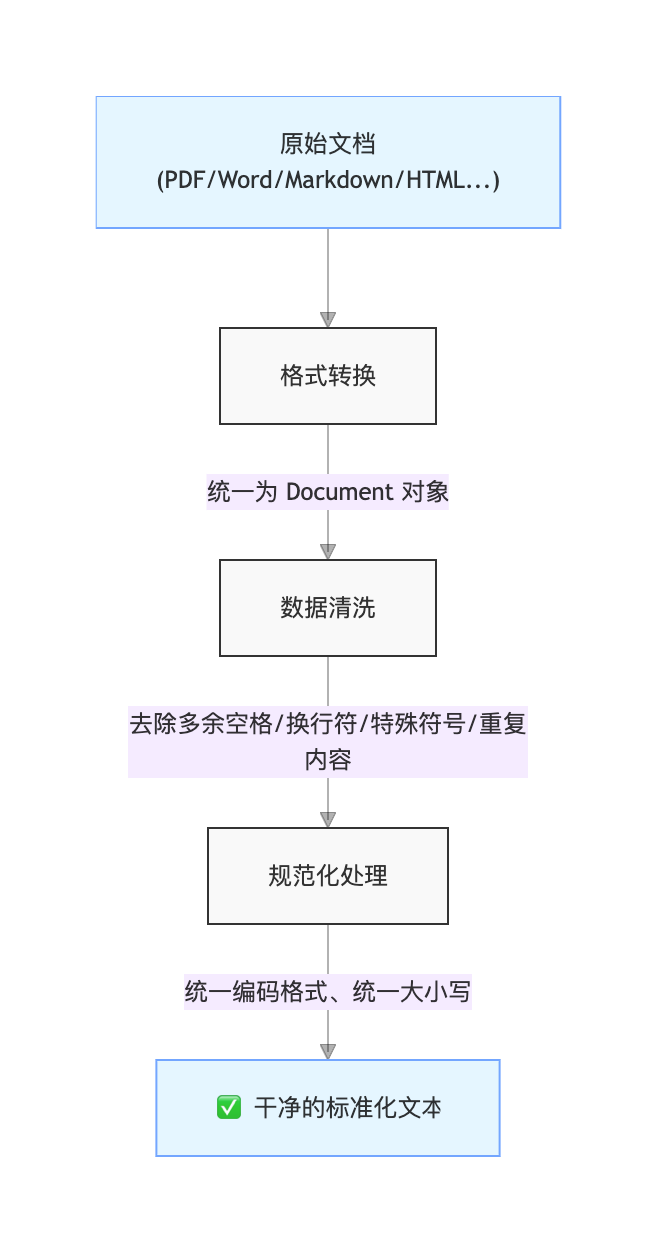
文档预处理的目标:让后续的「分片」和「向量化」能够在干净的数据上进行,从源头上保证知识库索引的质量。
4.2 文档分片(Chunking)
为什么需要分片?
一个文档可能有几十上百 MB,而 LLM 有 token 限制。如果将整篇文档全部丢给 LLM:
- Token 浪费:大量无关内容占据上下文空间
- 检索精度下降:无关信息会"淹没"真正相关的内容
所以我们需要把一个大的文档按照一定规则切分为较小的文本片段(Chunk)。检索时,匹配出来的是与用户问题最相关的那几个 Chunk,而不是整篇文档。
分片大小的权衡

主流分片方式对比
| 分片方式 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 固定大小分片 | 按固定字符数/token 数切分 | 简单高效 | 可能切断句子 |
| 递归分片 | 按优先级依次尝试多种分隔符 | 语义完整性好 | 实现稍复杂 |
| 文档结构分片 | 基于 Markdown/HTML 标题层级 | 保留结构信息 | 依赖文档格式 |
| 语义分片 | 基于 Embedding 相似度变化切分 | 语义边界精准 | 计算成本高 |
| 智能分片 | 综合多种策略,动态决策 | 效果最佳 | 复杂度最高 |
递归分片详解(Recursive Chunking)
递归分片是目前 LangChain / LlamaIndex 默认 的分片策略,也是实际生产中最常用的方式。其核心思想是:
按优先级依次尝试多种分隔符,只有当前分隔符无法将文本切到目标大小时,才降级使用下一个分隔符。
plain
优先级从高到低:
"\n\n" → "\n" → "。" → "." → " " → ""
段落保持完整 → 句子保持完整 → 词保持完整 → 字符级强制切分工作流程示意:

python
# LangChain 中的典型用法
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每个块的目标最大长度
chunk_overlap=50, # 相邻块之间的重叠量
separators=["\n\n", "\n", "。", ".", " ", ""] # 分隔符优先级
)
chunks = splitter.split_text(document)📌 chunk_overlap 的作用:让相邻 Chunk 之间有一定重叠,防止关键信息恰好被切在两个 Chunk 的边界上,导致信息断裂。
递归分片的本质,是在 「信息完整性」 和 「向量检索精度」 之间做权衡------Chunk 太大会稀释语义导致检索不准,太小又会丢失上下文。递归分片通过逐级降级的方式,尽可能用大的语义单元(段落 → 句子 → 词)填满目标大小,从而在两者间取得较好的平衡。
4.3 向量化(Embedding)
数据清洗 + 分片完成后,每个文本块都需要被转换成一个高维数值向量,这个过程就叫向量化 。目的是让文本的语义可以被机器理解 和相似度比较。
什么是向量?
向量是具有大小和方向的多维数值数组。在大模型中,每个维度代表某种语义特征。因此,语义相似的句子,其向量在高维空间中的"距离"更近。
plain
一维向量 [3] ------ 数轴上的一条有向线段
二维向量 [3, 4] ------ 平面上从原点指向 (3,4) 的有向线段
三维向量 [3, 4, 5] ------ 空间中从原点指向 (3,4,5) 的有向线段
高维向量 [0.32, -0.15, 0.78, ..., -0.42]
------ 384 / 768 / 1536 维
------ 每个维度不再代表物理坐标,而是某种"语义特征"
------ 维度越高,语义表达能力越强文本如何变成向量(Embedding 过程)
📝 文本块
'小明爱吃西瓜'
🧮 Embedding 模型
(如 text-embedding-3-small)
📊 高维向量
-0.32, 0.31, -0.23, ... , 0.12
每个维度的含义举例:
第1维:是否包含'人物'
第2维:是否涉及'动作'
第3维:是否包含'时间'
...
简单来说,就是用 Embedding 模型把文本"投影"到高维向量空间里。每个维度代表了文本在某个语义方向上的权重。最终,每段文字被转成一个高维坐标点,然后就可以进行数学上的比较了。
向量相似度计算方法
点积(Dot Product)
两个向量在同一方向上的重叠程度
值越大 → 越相似
最高效的计算方式
Transformer 注意力机制就使用点积
欧几里得距离(Euclidean Distance)
测量空间中两点之间的直线距离
距离越小 → 相似度越高
主要应用于图像相似度等几何场景
余弦相似度(Cosine Similarity)⭐ 最常用
比较两个向量的夹角
夹角越小 → 方向越一致 → 语义越相似
余弦值范围:-1, 1
1 = 语义高度相似,0 = 无关,-1 = 语义相反
✅ 只关心方向,不关心向量长度
✅ 特别适合文本语义匹配
✅ 大多数向量数据库默认支持
相似度直观示例
以下面这个二维坐标系为例(实际是多维度,此处简化为二维便于理解):
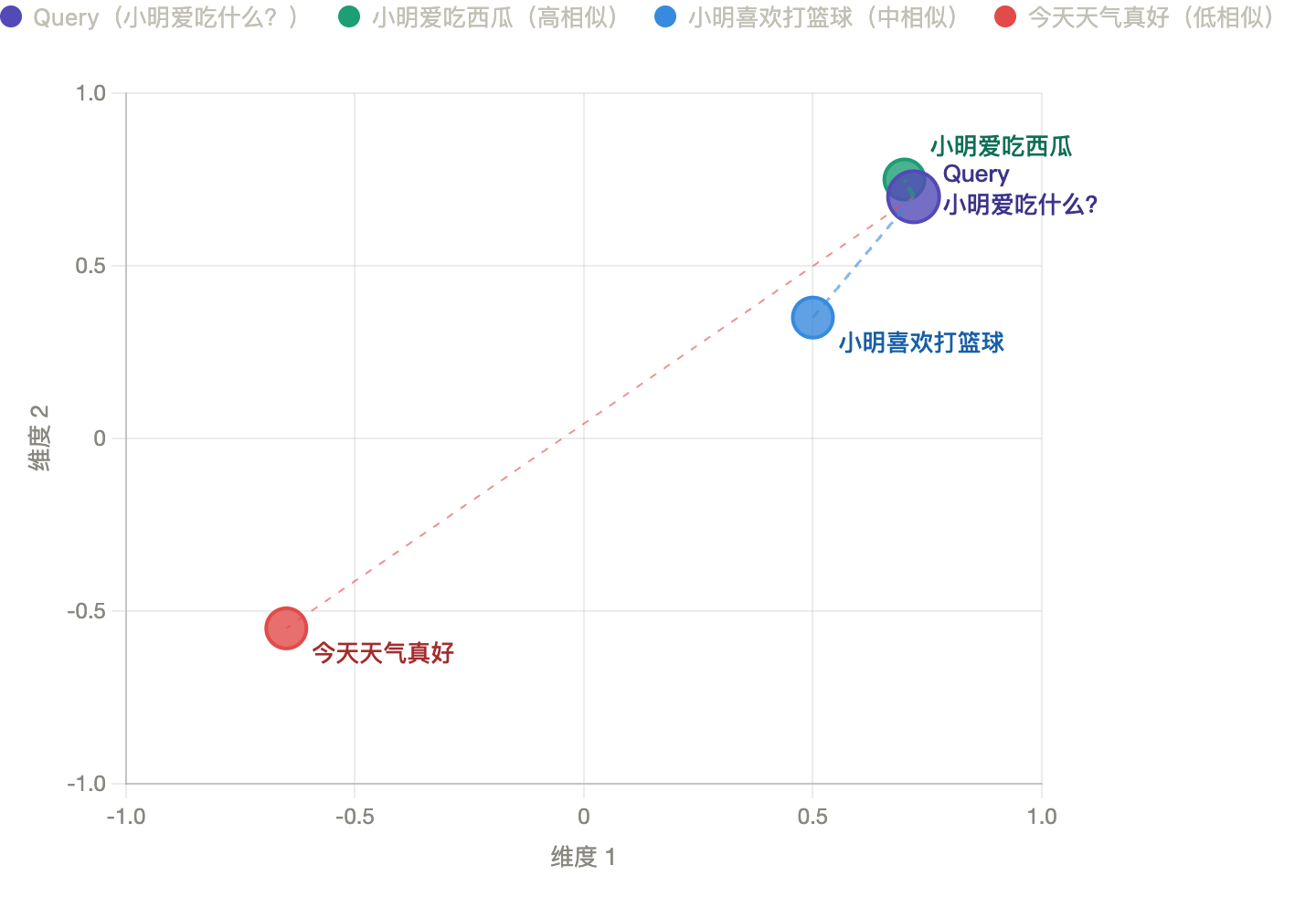
- Query "小明爱吃什么" 与 "小明爱吃西瓜" 夹角极小 → 余弦相似度 ≈ 1,高度相关 ✓
- Query "小明爱吃什么" 与 "小明喜欢打篮球" 夹角较大 → 余弦相似度较低
- Query "小明爱吃什么" 与 "今天天气真好" 几乎相反 → 余弦相似度 ≈ -1,完全不相关
4.4 生成索引
完成向量化后,每一个 Chunk 都对应一个高维向量。但这些向量如果只是存在内存里,并不能快速查询和比较。所以需要将文本内容和高维语义向量持久化存储下来,利用向量数据库构建索引结构,为后续的检索生成提供相似度查询的功能。
向量数据库
向量数据库是一类专门用于存储、管理和检索高维向量数据的数据库。与传统数据库(如 MySQL)不同,它并不是基于精确匹配 进行查询,而是通过计算向量之间的相似度来进行语义检索。
存储内容示例
以 Pgvector(PostgreSQL 的向量扩展)为例,直观地看下存储结构:
| 字段 | 类型 | 说明 |
|---|---|---|
embedding_id |
UUID | 主键,唯一标识 |
embedding |
vector(1536) | 高维向量,用于相似度匹配 |
text |
TEXT | 原始文本块,LLM 引用的实际内容 |
metadata |
JSONB | 元数据:文件名、页码、时间戳等 |
🗄️ 向量数据库存储结构
🏷️ metadata
{filename, page, timestamp, ...}
👆 精确过滤、分组、溯源
📝 text
'小明是一个喜欢吃西瓜的男孩...'
👆 LLM 引用的原始文本块
🧮 embedding
-0.32, 0.31, -0.23, ... , 0.12
👆 用于相似度查询的索引
📌 三者关系:
embedding是索引------用来做相似度匹配,把最相关的 Chunk 找出来text是内容------检索出来之后,真正注入给 LLM 做参考的是它metadata是辅助------让你能做精确过滤(如按文件名、时间戳过滤),提升检索精度
5. 总结
RAG 技术全景图
🟢 Phase 2: 检索生成
🔵 Phase 1: 构建索引
❓ 用户提问
📄 原始文档
(PDF/Word/MD...)
🔧 文档预处理
清洗 + 标准化
✂️ 文档分片
递归分片 / 语义分片
🧮 向量化
Embedding 模型
🗄️ 向量数据库
Pgvector / Milvus / FAISS
🧮 问题向量化
🔍 相似度检索
余弦相似度
📋 召回 Top-K
📝 构建 Prompt
注入上下文
🤖 LLM 生成回答
RAG 的本质:让 LLM 在回答问题前先"查资料",而不是凭记忆胡编。它的核心价值在于:
- 降低幻觉------回答有据可依、可溯源
- 知识可更新------不需要重新训练,更新知识库即可
- 领域可定制------企业私有数据、专业领域知识都能注入
整个系统的质量取决于两条线的协作:
- 离线线(索引构建)决定了知识库的上限------Garbage In, Garbage Out
- 在线线(检索生成)决定了实际用户体验------检索精度 × 生成质量
两者缺一不可,共同构成一个高质量的 RAG 系统。
📖 延伸阅读