作者:来自 Elastic Benjamin Trent

了解 Elasticsearch 9.4 如何通过避免在高选择性场景下浪费 centroid 和 postings-list 工作,使受限过滤条件下的 DiskBBQ 向量搜索速度提升 3--5 倍,并且更加稳定。
从向量搜索到强大的 REST API,Elasticsearch 为开发者提供了最全面的搜索工具集。你可以深入 Elasticsearch Labs 仓库中的示例 notebooks,尝试新的功能。你也可以立即开始免费试用,或在本地运行 Elasticsearch。
Elasticsearch 9.4 让受限过滤条件下的 DiskBBQ 向量搜索速度提升了 3--5 倍。DiskBBQ 是 Elasticsearch 新的基于分区(partition based)的索引。它致力于通过让向量索引尽可能贴合底层系统,在成本与性能之间实现最佳平衡。虽然 DiskBBQ 在宽松过滤条件下表现良好,但在受限过滤条件下表现较差。为了继续推进简单、快速、高效的向量索引,我们调整了过滤应用方式,并显著改善了延迟表现。
为什么过滤 partition indices 很困难
对于 partition indices,所有搜索都分为两个阶段:
- 找到最近的 centroids。
- 在最近 centroids 的 clusters 中找到最近的 vectors。
对于 DiskBBQ,centroids 会被量化(quantized),并且可能会被索引到它们自己的结构中。cluster 内容(下面我们称之为 postings lists)会以一种尽可能加速 vector scoring 的方式进行布局。
postings 以 32 个为一个 block 进行存储,每个 block 内按 doc_id 顺序排列。doc IDs 使用 delta encoding,以较低解码开销来最小化磁盘占用。
vector 值同样采用 block encoding,将维度数据与量化修正值(quantized corrections)分离,从而通过我们优化后的 kernels 最大化 SIMD(single instruction, multiple data)吞吐量。
Vector Cluster (Posting List) layout
| metadata |
| doc_deltas[32] | vec_quant[32] | vec_quant_corrections[32] |
| doc_deltas[32] | vec_quant[32] | vec_quant_corrections[32] |
| ... |
| doc_deltas[T] | vec_quant[T] | vec_quant_corrections[T] | (T <= 32)一旦我们到达 postings list,其布局已经针对快速 scoring 与 filtering 做了优化。例如,如果提供了 index sort,那么匹配过滤条件的 vector blocks 会在 list 中一起存储和评分。这使得系统能够一次性对连续 vector blocks 进行 scoring,从而充分利用底层 CPU 吞吐能力。
不过,在真正检查 doc_ids 之前,我们并不知道某个 cluster 是否匹配给定 filter。一旦验证完成,我们就能确保只对相关 vectors 进行 scoring。在受限过滤场景下,我们可能检查了一个 centroid,却发现其中没有任何 vector 匹配 filter。为了补偿这一点,我们会持续对 centroids 进行 scoring 和探索,直到获得足够具有代表性的 vector 集合用于 scoring。
这意味着在受限过滤条件下会产生大量浪费工作。我们会对 centroids 进行 scoring,但并不知道它们是否包含与 filter 相关的 vectors;准备对 postings list 进行 scoring,最后却发现其中没有任何 block 适用。这些浪费的计算会不断累积:
- 不必要地对 centroid 进行 scoring。
- 因为 postings list 接近 query vector 而加载它,即使它最终会被 filter 掉。
- 解码并检查 list 中的 document IDs,最后才发现没有任何一个匹配。
- 继续搜索,可能再次命中另一个完全被 filter 掉的 centroid,直到访问足够多的 centroids 来达到目标 recall。
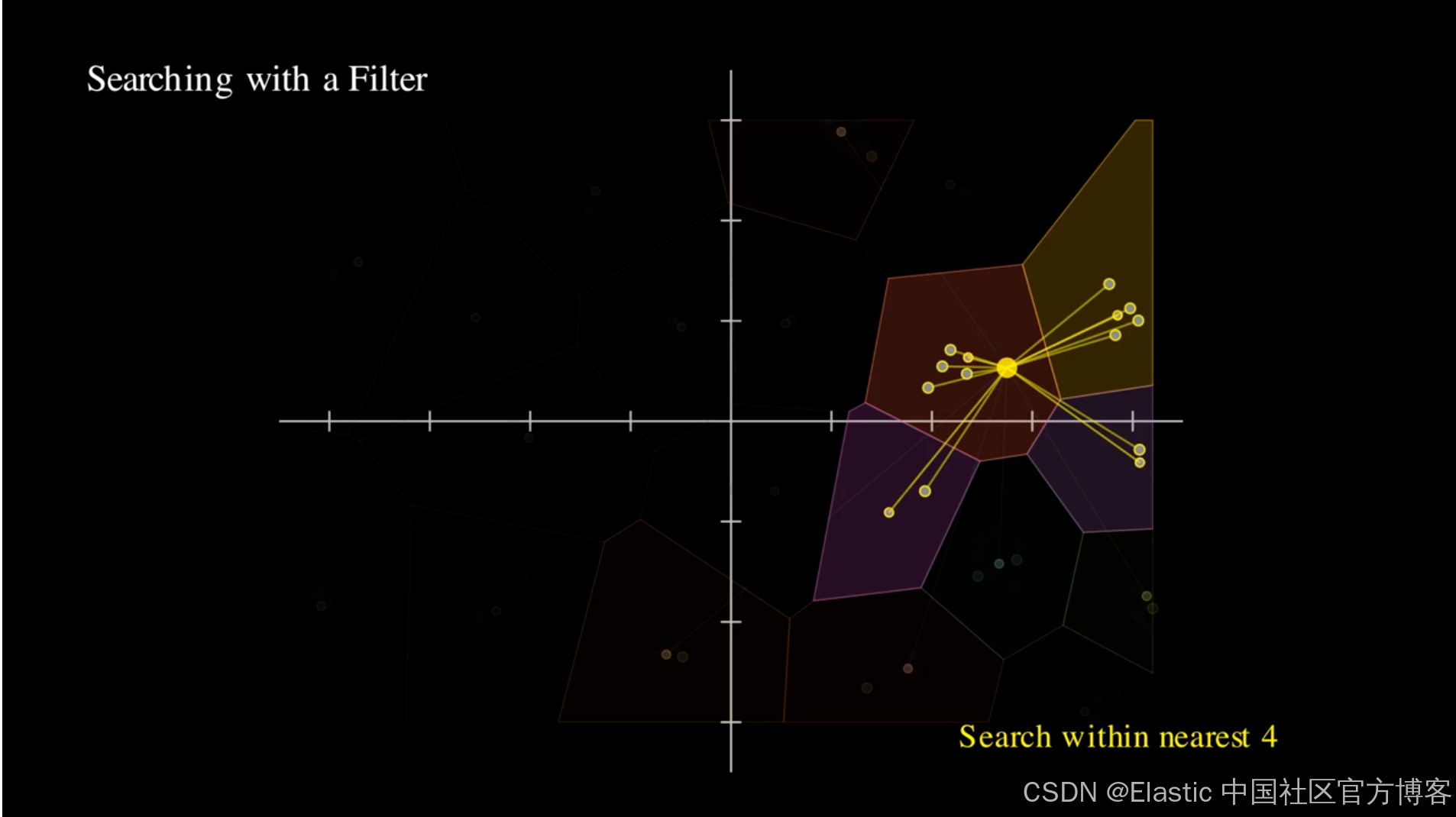
下面是一个展示旧流程的示例:检查所有 centroids,查看哪些匹配,然后移动到包含匹配 vectors 的 centroids。不断重复这一过程。
 https://www.bilibili.com/video/BV12x5D6tERG/
https://www.bilibili.com/video/BV12x5D6tERG/
这是新的方式。当检测到存在受限过滤条件时,直接跳转到经过过滤后的 centroids。
基准测试,基准测试,还是基准测试
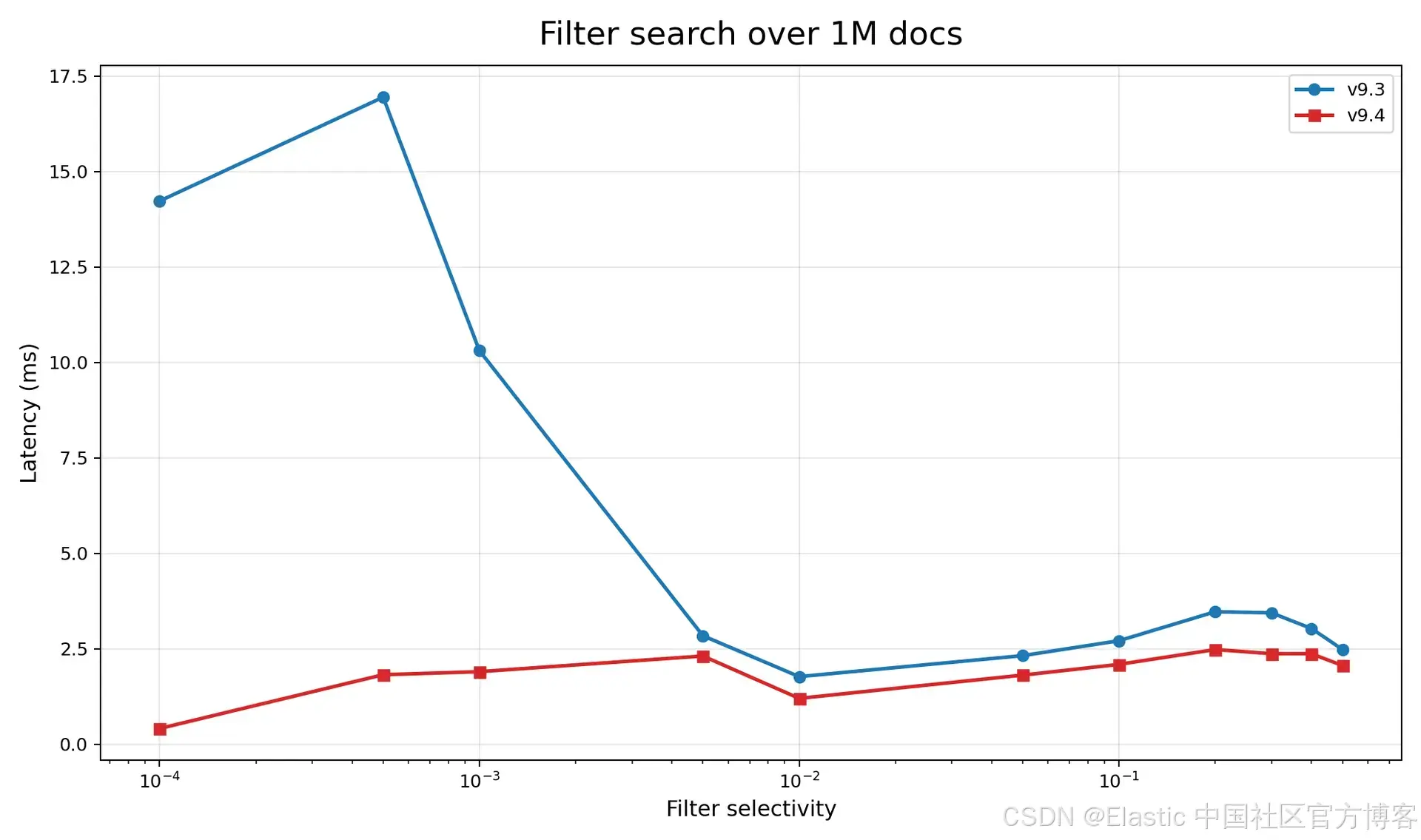
下面是一个带随机 filter 的宏基准测试。这里故意使用了极端 filter selectivity,以展示在超高限制过滤条件下的显著提升。在这里,我们看到接近一个数量级的性能提升。
过去,当 filter 变得非常受限时,延迟会出现非常糟糕的 "肘部" 拐点(horrible elbow)。而现在,延迟保持稳定,并且实际上会随着 filter 越来越受限而继续改善。
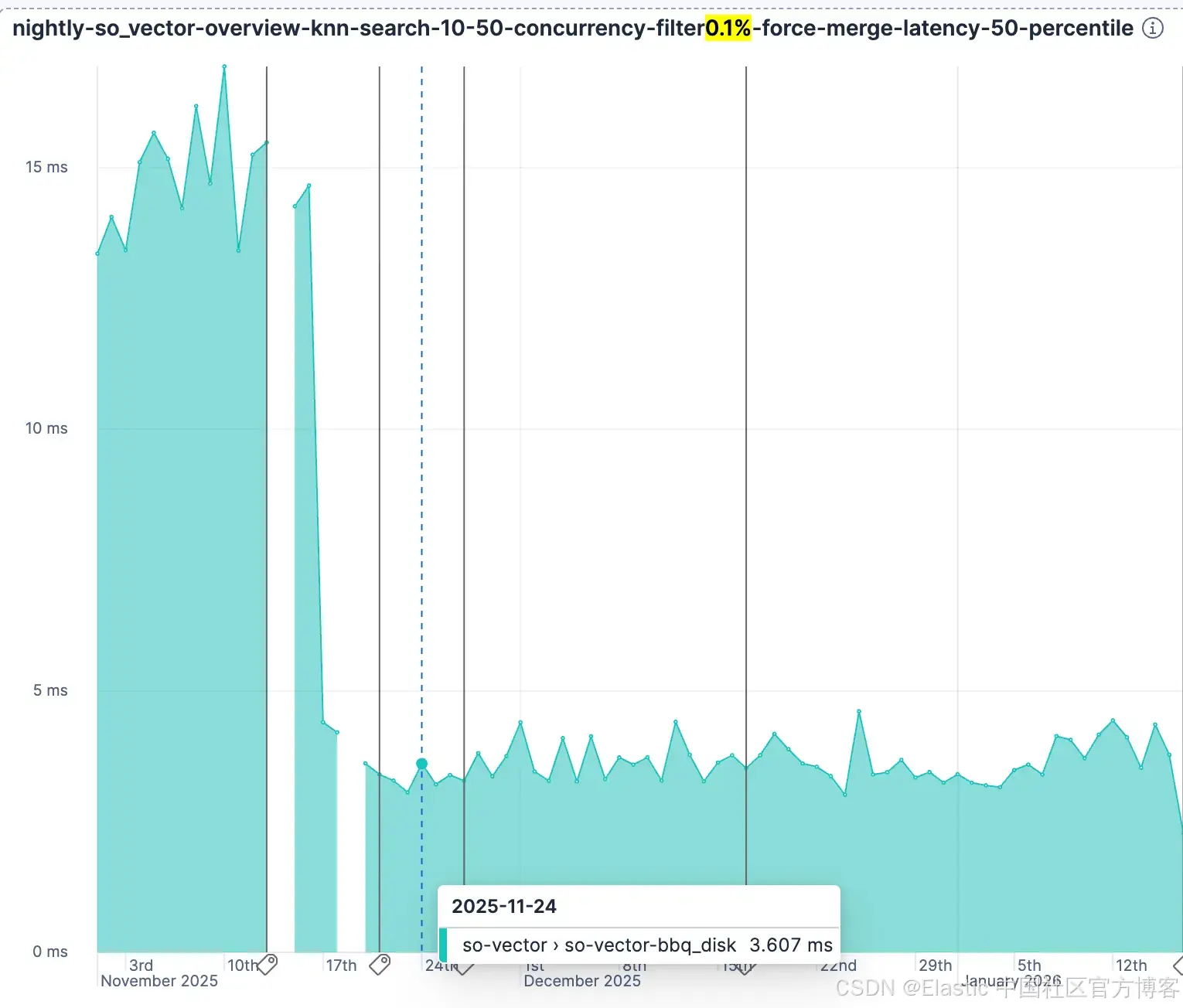
另一个验证来自我们在 rally 上运行的 so-vector 夜间运行,它展示了改进。
你可以通过在 rally 配置中的 vector_index_type 中指定 bbq_disk 来自己尝试这一点。
接下来是什么?
这项功能目前已在 Elastic Serverless 中上线,并将包含在 9.4.0 Stack 版本中。我们并不会停止对 Elasticsearch 向量搜索的改进。这只是我们持续前进的一步,目标是为你带来更简单、更高效、更实用且更快速的向量搜索。
非常感谢你使用我们编写的代码。我们 ❤️ 你。
原文:https://www.elastic.co/search-labs/blog/faster-restrictive-filters-diskbbq