作者:一个在金融风控系统和AI工程之间反复横跳、被vibe coding坑了无数次的中年开发者 发布时间:2026-05-15
先说一件让我沉默了整整五秒的事
2026年4月底,我刷到一个GitHub仓库。
发布方是 github(没错,就是GitHub官方组织账号)。
名字叫 spec-kit。副标题是:
"💫 Toolkit to help you get started with Spec-Driven Development"
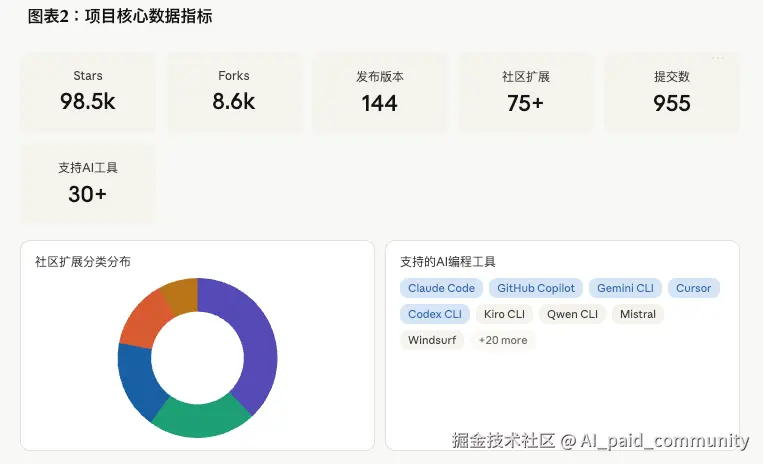
然后我看了一眼数据:
⭐ 98,500 Stars | 🍴 8,600 Forks | 📦 144个发布版本 | 🔧 955次提交 | 🤝 30+支持的AI工具
我沉默了五秒钟。
不是因为数字大(虽然确实大),而是因为一句话:
"An open source toolkit that allows you to focus on product scenarios and predictable outcomes instead of vibe coding every piece from scratch."
让你专注于产品场景和可预期结果,而不是从头vibe coding每一块。
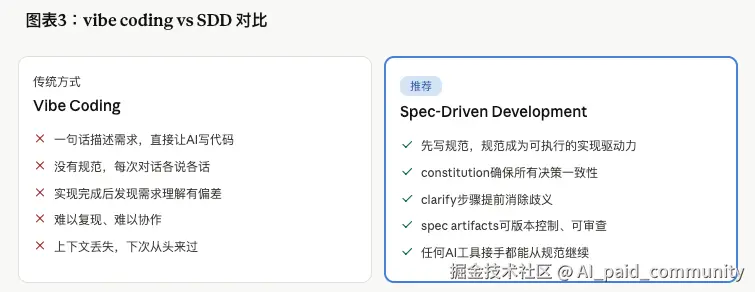
GitHub官方,亲自下场,对着整个AI编程社区喊了一句: "停止vibe coding!"
这件事,我觉得值得单独写一篇文章。 claude国内使用确实有点困难,订阅参考这个网站:claudemax.shop
"vibe coding"是什么,为什么GitHub觉得它有问题?
如果你这半年一直在用AI编程工具,你大概经历过这种场景:
打开Claude Code(或者Cursor,或者任何你喜欢的工具),输入:"帮我做一个用户管理系统,支持注册登录,有权限分组"。
AI开始写,你看着它写,偶尔说"这里改一下"、"加个功能"、"不对不对回滚"......
半小时后,你有了一堆代码。但你也有了这些问题:
- 这个系统的数据库设计是基于什么考虑的?不知道
- 异常处理的策略是什么?随机的
- 如果下周另一个AI来继续这个项目,它能接得上吗?大概率不行
- 你能向老板解释这套架构的设计决策吗?......你在想什么
这种"感觉不错就这么干"的编程方式,就是 vibe coding。
它在原型阶段很好,在生产环境是定时炸弹。
Spec-Driven Development:把规范从"脚手架"变成"发动机"
spec-kit 的核心理念可以用一句话概括:
"Spec-Driven Development flips the script on traditional software development. Specifications become executable, directly generating working implementations."
规范驱动开发翻转了传统开发的逻辑。规范不再是你写完然后扔掉的脚手架------它们变成了可执行的、直接驱动实现的核心产物。
具体来说:
在传统流程里,写PRD → 评审PRD → 丢开PRD → 开始coding,PRD在第一行代码落下的那一刻就开始腐烂。
在SDD流程里,写spec → spec驱动plan → plan驱动tasks → tasks驱动implement,规范文件全程活着,且可以被版本控制、被任何AI工具读取、被下一个接手的人理解。
这不是理论,这是 spec-kit 这套工具的实际工作方式。
七个命令,从0到产品
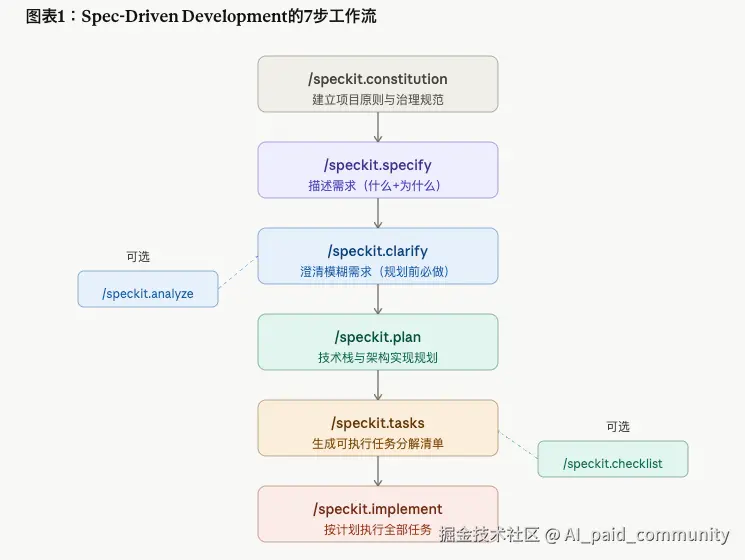
图表一:SDD七步工作流程图(见上方,点击各节点可以追问)
spec-kit 把整个开发流程拆成六个核心命令加两个可选命令:
第一步:/speckit.constitution --- 给AI立宪法
这是整个流程里最被低估的命令。
执行之后,它会创建 .specify/memory/constitution.md,里面是你这个项目的"治理原则":
sql
/speckit.constitution Create principles focused on code quality,
testing standards, user experience consistency, and performance requirements.这个文件会被后续所有步骤引用。如果你在 plan 阶段 Claude Code 突然想加一个你没要求的功能,你可以说:"检查一下这个是否符合 constitution"------它会自己审查自己。
这解决了一个我之前非常头疼的问题:AI喜欢过度工程化(over-engineer) ,你要什么它给你三倍,然后你花时间删。有了 constitution,你可以在里面写"遵循最小实现原则",它就真的不会乱加东西了(大多数时候)。
第二步:/speckit.specify --- 说你要什么,别说怎么做
这一步的关键是:只描述"什么"和"为什么",不提技术栈。
bash
/speckit.specify Build an application that can help me organize my photos
in separate photo albums...把业务需求说清楚,用户故事写完整,但完全不提"用什么框架"、"选什么数据库"。这一步产出的是 spec.md,里面是结构化的需求文档,还有 Review & Acceptance Checklist。
为什么不能在这一步说技术栈?因为一旦你说了"用React",AI会把所有决策都往React上靠,而不是先问清楚需求再选择最合适的技术。
第三步:/speckit.clarify --- 不要跳过这一步
这是optional但强烈建议的命令,必须在 plan 之前运行。
它会做覆盖式、系统性的问题追问,记录在 spec 的 Clarifications 区。意义在于:提前消除歧义,减少下游返工。
没有这一步,你的 plan 可能是基于你以为你想要的东西生成的,而不是你真正想要的东西。
(这跟我们做金融系统需求分析是一样的道理------需求澄清不清楚,你永远都在改代码。)
第四步:/speckit.plan --- 现在才说技术栈
typescript
/speckit.plan The application uses Vite with minimal number of libraries.
Use vanilla HTML, CSS, and JavaScript as much as possible.这一步会生成一套详细的实现计划文档,包括:
plan.md--- 主实现计划contracts/api-spec.json--- API规范data-model.md--- 数据模型research.md--- 技术栈研究quickstart.md--- 快速上手指南
这里有个有意思的细节:如果你用的是快速迭代中的框架(比如 .NET Aspire、最新的 Next.js),可以让 AI 专门做针对性研究,避免用了已经过时的 API:
css
I want you to look through the implementation plan for areas that could
benefit from additional research as .NET Aspire is a rapidly changing library...
spawn parallel research tasks to clarify any details.第五步:/speckit.tasks --- 任务清单自动生成
bash
/speckit.tasks生成 tasks.md,包含:
- 按用户故事组织的任务分解
- 依赖管理(先做模型再做服务,先做服务再做API)
- 并行任务标记(
[P]标注可以并行执行的任务) - 每个任务的精确文件路径
- TDD 结构(如果你要求写测试,测试任务会在实现任务之前)
- 每个用户故事完成后的 Checkpoint 验证
第六步(可选):/speckit.analyze --- 交叉一致性检查
在 tasks 生成之后、implement 之前运行。做跨文件的一致性和覆盖率分析,确保你的任务清单没有遗漏任何需求点。
第七步:/speckit.implement --- 执行
bash
/speckit.implement这一步会:
- 验证所有前置条件(constitution、spec、plan、tasks 都存在)
- 按正确顺序执行任务,尊重依赖关系
- 跟踪进度,处理错误
执行完之后,你应该有一个可以运行的应用,而不只是一堆代码文件。
安装和初始化:真的不复杂
csharp
# 推荐方式:用uv安装(需要先装uv)
uv tool install specify-cli --from git+https://github.com/github/spec-kit.git@v0.8.9
# 验证安装
specify version
# 在新项目里初始化(Claude Code集成)
specify init my-project --integration claude
# 或者在已有项目里初始化
specify init . --integration claude
# 或
specify init --here --integration claude初始化完成后,启动你的AI编程工具,如果看到 /speckit.constitution、/speckit.specify、/speckit.plan 等命令可用,就说明配置好了。
对于 Claude Code 用户,这些命令会出现在斜杠命令列表里。
扩展生态:这才是项目真正的价值所在
截至2026年5月15日,community extensions 目录里已经有 75+ 个社区扩展,覆盖五大类别:
| 类别 | 数量 | 代表扩展 |
|---|---|---|
process(流程) |
最多 | MAQA多Agent工作流、Fleet Orchestrator |
code(代码) |
较多 | Staff Review、OWASP威胁分析、SpecTest |
docs(文档) |
较多 | Red Team逆向审查、V-Model测试追踪 |
integration(集成) |
中等 | Jira、Azure DevOps、GitHub Issues |
visibility(可视化) |
少量 | Spec Diagram、Project Health Check |
让我特别想说几个:
MAQA(多Agent + QA) --- 协调者Agent → 功能实现Agent → QA Agent 的三层架构,基于 worktree 并行执行,有 CI 门控,还整合了 GitHub Projects、Jira、Linear、Trello 等看板工具。这基本上是一个完整的 AI 团队。
Red Team 扩展 --- 在 /speckit.plan 之前运行,用对抗性的视角审查规范,找出 prompt injection 风险、完整性缺口、跨 spec 漂移、无声失败......这是安全工程师的思维在 spec 审查里的体现,我很欣赏这个设计理念。
Cost Tracker --- 追踪每个 SDD 工作流的实际 LLM 成本,支持按功能预算、按集成工具对比,还能导出财务报告。这对于需要对 AI 开发成本负责的团队来说,是一个非常务实的工具。
Brownfield Bootstrap --- 为现有代码库引导 spec-kit,自动发现架构并增量采用 SDD。这解决了一个实际问题:你不可能为一个已经有10万行代码的项目从头写规范,但可以逐步引入。
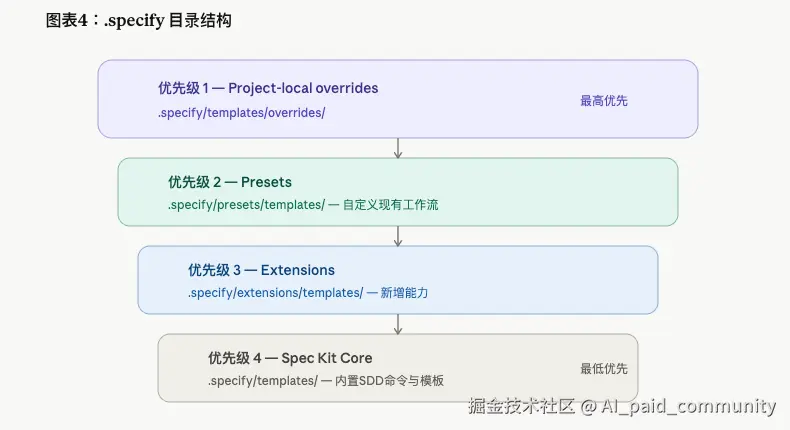
预设系统(Presets):改变规范的"语言"
这是很多人没注意到的功能,但实际上非常有趣。
Presets 可以在不改变工具能力的情况下,改变 spec-kit 生成的所有文档的格式、术语和规范。
图表四:
.specify目录优先级结构(见上方)
举几个可以用 Presets 做的事:
- 把 spec 模板改成符合某个金融监管框架要求的格式(可追溯性、合规性字段)
- 把整个工作流切换到中文(有人做了中文预设)
- 强制所有 plan 必须有安全审查门控
- 适配 Agile/Kanban/Waterfall 不同的项目管理方法论
- 最离谱的示范:pirate-speak 预设------把所有输出改成海盗腔
这个预设系统的设计有点像 CSS 的层叠机制------有明确的优先级,高优先级覆盖低优先级,多个预设可以叠加。
深度测评:我用它做了什么,发现了什么
作为一个同时做金融系统和 AI 工程的人,我有几个非常具体的感受:
真正解决了上下文丢失的问题
这是我用 spec-kit 之前最大的痛点:今天做了这些决策,明天开新会话,AI忘了。
CLAUDE.md 会随着 spec-kit 的流程自动更新,包含最新的项目状态。下次启动 Claude Code,它会读 CLAUDE.md,知道"我们现在在哪里,做了什么决定,下一步要干什么"。
这个设计和 claude-mem 的思路不同------claude-mem 是通过 hook 自动学习,spec-kit 是通过结构化的 spec artifacts 主动维护上下文。两者可以共存,但 spec-kit 的方式对于多人协作更友好,因为 spec 文件是可以 review 的。
AI 真的不再乱加东西了
我在 constitution 里加了这一条:
markdown
## 实现原则
- 最小化依赖原则:优先用语言/框架原生能力,非必要不引入第三方库
- 不得添加需求文档中未明确要求的功能然后让它做一个 REST API 服务。它真的没有自己加 Redis 缓存、没有加 Prometheus 监控、没有加 swagger-ui......这在之前是不可能的,Claude Code 会非常热情地"帮你想到"这些东西。
学习曲线:有,但不陡
如果你完全没用过,从零上手大概需要:
- 30分钟:理解 SDD 理念,装好 specify-cli
- 1小时:完整跑一遍7步流程,做一个小项目
- 1-2天:真正内化工作流,开始感受到效率提升
对比一下:从零开始配置 everything-claude-code 大概需要 2-4 小时,claude-mem 大概需要 30 分钟。spec-kit 在复杂度上居中,但带来的工程化价值要大很多。
坑:AI有时候还是会过度投入
README 自己也承认:Claude Code can be over-eager and add components you did not ask for.
一个具体建议:生成 plan 之后,专门跑一次"找过度工程化"的 prompt:
sql
Go through the implementation plan and identify any components that
seem over-engineered or that weren't explicitly requested in the spec.这一步能帮你在执行前删掉很多没必要的复杂性。
和我研究过的其他工具相比如何?
| 维度 | spec-kit | everything-claude-code | claude-mem | learn-claude-code |
|---|---|---|---|---|
| 核心价值 | 工程化开发流程 | Agent操作系统 | 跨会话记忆 | Harness教学 |
| 技术门槛 | 中等(需理解SDD理念) | 较高(需懂Hook/MCP) | 低(一行安装) | 中等(需理解架构) |
| 适合场景 | 产品功能开发 | 开发者工具定制 | 所有长期项目 | 学习AI工程架构 |
| 多AI工具 | 是(30+工具) | 主要Claude Code | 主要Claude Code | 教学示范用 |
| 社区生态 | 丰富(75+扩展) | 丰富(48 Agent) | 有限 | 教学为主 |
| 组织支持 | GitHub官方 | 社区维护 | 个人维护 | 社区维护 |
| 互补关系 | 可与claude-mem同时用 | 可作为底层 | 补充spec-kit记忆 | 理解底层原理 |
这几个工具之间不是竞争关系,而是不同层次的解决方案。spec-kit 解决的是"如何把项目开发流程工程化",其他工具解决的是"如何让AI工具本身更好用"。
在我自己的工作流里,我把它们叠在一起用:
- spec-kit:规范驱动的功能开发框架
- claude-mem:补充跨会话记忆(spec-kit 的 CLAUDE.md 是结构化的,claude-mem 是自动学习的,互补)
- Claude Code CLI:执行层,配 everything-claude-code 里的 Hook 和 MCP
给不同人群的具体建议
如果你是独立开发者,在做个人项目:
spec-kit 最适合的场景是"我有一个完整的功能要从头实现"。你不需要用它来修一个 bug,但你做大创、做毕业设计、做 SaaS 产品,spec-kit 会让你少走很多弯路。
最小化采用路径:只用 constitution + specify + plan + implement 四个命令,暂时跳过 clarify、analyze 和扩展。等你熟悉基础流程再加东西。
如果你在团队里:
spec 文件天生是可以被 review 的------它就是 Markdown,可以开 PR。你可以在 plan.md 阶段做技术评审,在 spec.md 阶段做需求评审,这和现有的 code review 流程完全兼容。
搭配 GitHub Issues 集成扩展(/speckit.taskstoissues 命令),可以把生成的任务清单直接同步成 GitHub Issues,进入你们现有的项目管理系统。
如果你是金融/医疗/法律等强合规行业的开发者:
这里 Presets 系统的价值最大。你可以定制一套强制包含合规字段(如可追溯性、数据分类、风险等级)的 spec 模板,让所有用这套工具的人自然地输出符合合规要求的文档。
98.5k Star:值不值这个数字?
这是 GitHub 官方账号发布的项目,背后有组织信用背书,不存在刷星的动机。
Fork/Star 比值:8600/98500 ≈ 8.7% ,在这个量级的项目里是健康的。意味着有实质性的采用,而不只是收藏。
144 个版本、955 次提交,说明这是活跃维护中的项目,而不是一次性发布就跑路的。
75+ 社区扩展是最重要的信号------这些扩展是独立开发者自己做的,说明有真实的用户群体在认真使用,并且觉得它值得投入时间扩展。
我的判断:98.5k 是实至名归的,甚至我认为还会继续涨。
因为它解决的问题不会消失------只要还有人在用 AI 工具开发软件,就会有人被 vibe coding 坑,就会有人想要找到一种更系统、更可预期的方式。
最后说一件有趣的事
spec-kit 的 README 里有一句话让我笑了:
"Spec-Driven Development is a process not tied to specific technologies, programming languages, or frameworks."
规范驱动开发是一个过程,不依赖于具体的技术、编程语言或框架。
然后它的支持列表里有 30+ 个 AI 工具。Copilot、Gemini、Claude Code、Cursor、Codex、Qwen......
所以 spec-kit 的野心是:不管你用什么 AI 工具,都可以用这套方法论来工程化你的开发流程。
这是一个非常务实的定位。AI 工具会变,模型会升级,今天的 Claude 3 明天可能就被 Claude 4 替代,但"先写规范、规范驱动实现"这个理念不会过时。
就像不管你用什么编程语言,单元测试的理念不会过时一样。
这才是 spec-kit 真正的护城河。