文章目录
- 引言
- 设计说明
-
- 三种知识来源
- [Web Search 的两种集成方式](#Web Search 的两种集成方式)
- 原理方案
-
- [Tavily 集成](#Tavily 集成)
- [SearXNG 集成](#SearXNG 集成)
- [与 RAG 流程的整合](#与 RAG 流程的整合)
- 源码解析
-
- [SearchUtils ------ Tavily 调用工具](#SearchUtils —— Tavily 调用工具)
- 配置项
- [包装成 Tool 的示例](#包装成 Tool 的示例)
- [Controller 层主动调用](#Controller 层主动调用)
- 验证结果
-
- [Tavily 检索测试](#Tavily 检索测试)
- [Tool 模式测试](#Tool 模式测试)
- 与内部知识库的协作测试
- 优化方向
-
- [Tavily 的高级参数](#Tavily 的高级参数)
- 缓存搜索结果
- 内容过滤
- 网页内容抓取
- [多轮检索(ReAct 模式)](#多轮检索(ReAct 模式))
- 把网络结果存入向量库
- 隐私与合规
- 小结
- 系列总结
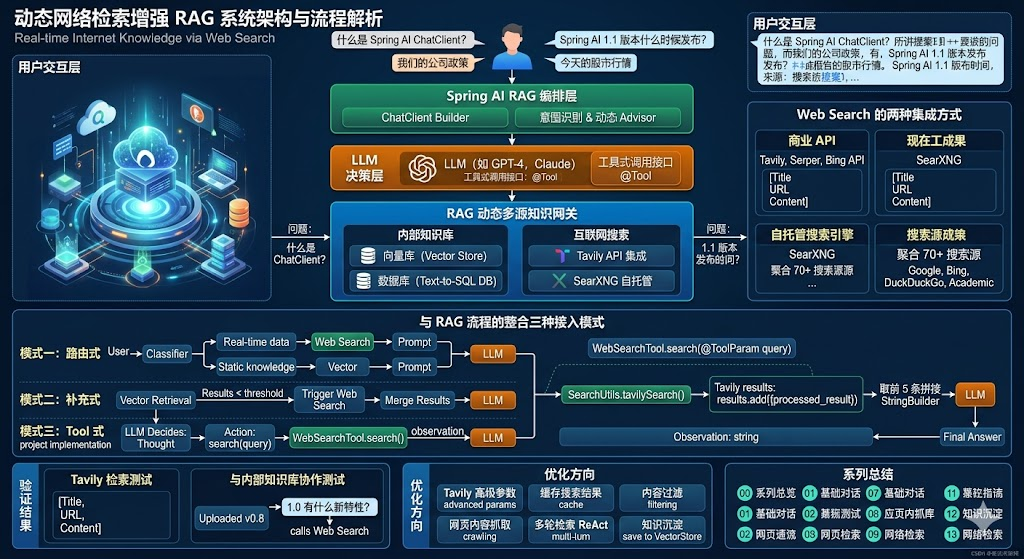
引言
RAG 系统的知识范围天然受限于已上传的文档。如果用户问的是"今天的股市行情"或"最新版本的 Spring AI",再完美的内部知识库也无能为力------这些信息根本没有被入库过。
网络检索增强(Web Search)让 RAG 系统具备了"实时获取互联网知识"的能力。本篇将解析项目中网络检索的设计:从 Tavily API 集成到 SearXNG 自托管搜索,以及如何把网络搜索结果优雅地融入对话。
设计说明
三种知识来源
经过前面的优化,一个完整的 RAG 系统其实有三类知识来源:
| 来源 | 优势 | 劣势 |
|---|---|---|
| 内部知识库(向量库) | 业务相关性高、可控 | 范围有限、需要维护 |
| 数据库(Text-to-SQL) | 精确的数值统计 | 只适合结构化数据 |
| 互联网(Web Search) | 实时性、覆盖广 | 噪音多、可信度参差 |
理想的系统会根据问题类型动态选择来源,甚至组合使用:
"什么是 Spring AI 的 ChatClient?" → 内部知识库
"日志表里有多少条记录?" → Text-to-SQL
"Spring AI 1.1 版本什么时候发布?" → 网络检索
"我们公司用 Spring AI 做了什么?" → 内部 + 网络Web Search 的两种集成方式
方式一:商业 API(Tavily、Serper、Bing API)
直接调用第三方服务,无需自己维护爬虫和索引。
- 优点:开箱即用、稳定、有结构化结果
- 缺点:付费、有调用限制、数据出口
方式二:自托管搜索引擎(SearXNG)
部署一个聚合搜索服务,本地调用,结果聚合自多个搜索引擎。
- 优点:免费、隐私可控、可定制
- 缺点:需要运维、稳定性靠自己
项目同时集成了这两种方式。
原理方案
Tavily 集成
Tavily 是专门为 LLM 设计的搜索 API,返回结果已经做过相关性精排和摘要:
POST https://api.tavily.com/search
Authorization: Bearer xxx
{
"query": "Spring AI 最新版本"
}
Response:
{
"results": [
{
"title": "Spring AI 1.0 GA Released",
"url": "https://spring.io/...",
"content": "Spring AI 1.0 GA 正式发布,主要特性包括..."
},
...
]
}返回的 content 已经是精炼摘要,可以直接拼接到 Prompt 中。
SearXNG 集成
SearXNG 是一个开源的元搜索引擎,聚合 70+ 搜索源:
yaml
spring:
ai:
websearch:
api-key: ${websearch.api-key}
searxng:
url: "http://127.0.0.1:8080/search"
nums: 10
engines: "duckduckgo,google,bing,brave,mojeek,presearch,qwant,startpage,yahoo,arxiv,crossref,google_scholar,internetarchivescholar,semantic_scholar"支持的引擎覆盖通用搜索(Google、Bing、DuckDuckGo)和学术搜索(arxiv、Google Scholar、Semantic Scholar)。
与 RAG 流程的整合
网络检索可以以多种姿态接入 RAG:
模式一:路由式
在意图识别后,如果判断需要实时信息,直接走网络检索:
用户问题
↓
LLM 路由判断
├─ 需要实时数据 → Web Search → 拼接结果到 Prompt → LLM 回答
└─ 静态知识 → 向量检索 → ...模式二:补充式
向量检索召回不足时,自动触发网络检索补充:
向量检索 → 结果数 < 阈值 → 触发 Web Search → 合并结果 → LLM 回答模式三:Tool 式
把 Web Search 包装成 @Tool,让 LLM 自己决定何时调用:
java
@Tool(description = "搜索互联网获取最新信息,适用于实时新闻、版本更新等")
public String webSearch(String query) {
return searchUtils.tavilySearch(query);
}项目代码暂时采用最灵活的"工具类 + 业务调用"形式,可以方便地切换为以上任意模式。
源码解析
SearchUtils ------ Tavily 调用工具
java
@Component
public class SearchUtils {
private String baseUrl = "https://api.tavily.com/search";
private String apiKey;
@Value("${artisan.websearch.api-key}")
private void readApiKey(String key) {
this.apiKey = key;
}
private final OkHttpClient client;
private final ObjectMapper objectMapper;
public SearchUtils() {
this.client = new OkHttpClient.Builder()
.connectTimeout(30, TimeUnit.SECONDS)
.readTimeout(30, TimeUnit.SECONDS)
.build();
this.objectMapper = new ObjectMapper();
}
public List<Map<String, String>> tavilySearch(String query) {
List<Map<String, String>> results = new ArrayList<>();
try {
// 构造请求体
Map<String, String> requestBody = new HashMap<>();
requestBody.put("query", query);
Request request = new Request.Builder()
.url(baseUrl)
.post(RequestBody.create(
MediaType.parse("application/json"),
objectMapper.writeValueAsString(requestBody)))
.header("Content-Type", "application/json")
.header("Authorization", "Bearer" + apiKey)
.build();
try (Response response = client.newCall(request).execute()) {
if (!response.isSuccessful()) {
throw new IOException("请求失败: " + response);
}
// 解析 results 数组
JsonNode jsonNode = objectMapper.readTree(response.body().string()).get("results");
if (!jsonNode.isEmpty()) {
jsonNode.forEach(data -> {
Map<String, String> processedResult = new HashMap<>();
processedResult.put("title", data.get("title").toString());
processedResult.put("url", data.get("url").toString());
processedResult.put("content", data.get("content").toString());
results.add(processedResult);
});
}
}
} catch (Exception e) {
System.err.println("搜索时发生错误: " + e.getMessage());
}
return results;
}
}关键点:
- OkHttpClient 复用:构造时创建一次,避免每次请求都新建连接
- 超时设置:搜索 API 有时较慢,30 秒超时是合理选择
- 结构化返回 :把每条结果转成
{title, url, content}的 Map,便于上层使用 - 异常吞噬:当前实现 catch 后只 print,生产环境应该抛出或返回标识
配置项
application.yml 中的相关配置:
yaml
artisan:
websearch:
api-key: ${websearch.api-key}
spring:
ai:
websearch:
api-key: ${websearch.api-key}
searxng:
url: "http://127.0.0.1:8080/search"
nums: 10
engines: "duckduckgo,google,bing,brave,mojeek,presearch,qwant,startpage,yahoo,arxiv,crossref,google_scholar,internetarchivescholar,semantic_scholar"通过 ${websearch.api-key} 引用环境变量,避免密钥泄露到代码库。
包装成 Tool 的示例
java
@Service
public class WebSearchTool {
@Autowired
private SearchUtils searchUtils;
@Tool(description = """
搜索互联网获取最新信息,适用场景:
- 询问最新新闻、行情、版本更新
- 询问知识库以外的通用知识
- 需要权威外部资料佐证的查询
不适用:纯主观问题、私域业务问题
""")
public String search(@ToolParam(description = "搜索关键词") String query) {
List<Map<String, String>> results = searchUtils.tavilySearch(query);
if (results.isEmpty()) {
return "未搜索到相关结果";
}
// 取前 5 条拼接
StringBuilder sb = new StringBuilder();
for (int i = 0; i < Math.min(5, results.size()); i++) {
Map<String, String> r = results.get(i);
sb.append(String.format("[%d] %s\n%s\n来源: %s\n\n",
i + 1, r.get("title"), r.get("content"), r.get("url")));
}
return sb.toString();
}
}注册到 ChatClient:
java
chatClient = ChatClient.builder(chatModel)
.defaultTools(ragTool, webSearchTool) // 多个 Tool 并存
.build();LLM 会在对话中根据问题类型自动选择调用哪个 Tool。
Controller 层主动调用
如果需要把网络检索作为强制流程(不依赖 LLM 判断),可以在 Controller 中主动调用:
java
@PostMapping("/web-rag")
public Flux<String> webRag(@RequestParam String message) {
// 1. 网络检索
List<Map<String, String>> webResults = searchUtils.tavilySearch(message);
// 2. 拼接到 user message
StringBuilder context = new StringBuilder("以下是网络搜索结果:\n");
for (Map<String, String> r : webResults) {
context.append("- ").append(r.get("title"))
.append(": ").append(r.get("content"))
.append("\n 来源: ").append(r.get("url"))
.append("\n");
}
String enhancedMessage = context.toString() + "\n\n基于以上信息回答用户的问题:" + message;
// 3. 调用 LLM
return chatClient.prompt()
.user(enhancedMessage)
.stream()
.content();
}验证结果
Tavily 检索测试
直接调用 SearchUtils:
java
List<Map<String, String>> results = searchUtils.tavilySearch("Spring AI 最新版本");
results.forEach(r -> {
System.out.println("Title: " + r.get("title"));
System.out.println("URL: " + r.get("url"));
System.out.println("Content: " + r.get("content"));
});输出:
Title: "Spring AI 1.0 GA Released"
URL: "https://spring.io/blog/2025/05/20/spring-ai-1-0-ga"
Content: "Spring AI 1.0 GA 正式发布,主要特性..."
Title: "Spring AI Documentation"
URL: "https://docs.spring.io/spring-ai/reference/"
Content: "..."Tool 模式测试
请求:
POST /api/v1/ai/rag?message=Spring AI 1.0 GA 是什么时候发布的?预期流程:
- LLM 识别这是"实时信息查询",调用 webSearchTool.search
- Tool 返回搜索结果摘要
- LLM 整合:
Spring AI 1.0 GA 于 2025 年 5 月 20 日正式发布...(来源:spring.io)
与内部知识库的协作测试
前置:上传一份 v0.8 时期的 Spring AI 内部教程。
请求: "Spring AI 的 ChatClient 怎么用?"
预期:内部知识库召回相关内容,LLM 优先使用内部资料回答。
请求: "Spring AI 1.0 有哪些新特性?"
预期:内部知识库无相关内容,LLM 调用 Web Search 获取最新信息。
优化方向
Tavily 的高级参数
Tavily 支持更多查询参数:
java
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("query", query);
requestBody.put("search_depth", "advanced"); // 深度搜索
requestBody.put("include_answer", true); // 包含 AI 摘要
requestBody.put("max_results", 10);
requestBody.put("include_domains", List.of("spring.io", "github.com")); // 域名白名单
requestBody.put("exclude_domains", List.of("xxx.com")); // 域名黑名单缓存搜索结果
热门查询不需要每次都打 API:
java
@Cacheable(value = "webSearch", key = "#query", unless = "#result.isEmpty()")
public List<Map<String, String>> tavilySearch(String query) {
// ...
}设置较短的 TTL(如 1 小时),平衡新鲜度和成本。
内容过滤
搜索结果中可能包含广告、低质量内容。可以做后处理:
java
private List<Map<String, String>> filter(List<Map<String, String>> results) {
return results.stream()
.filter(r -> r.get("content").length() > 50) // 过滤太短的
.filter(r -> !r.get("url").contains("ad")) // 过滤广告
.filter(r -> trustedDomains.stream()
.anyMatch(d -> r.get("url").contains(d))) // 仅保留可信域名
.collect(Collectors.toList());
}网页内容抓取
搜索结果只是摘要,有时需要完整内容。可以集成 Jina Reader、Crawl4AI 等工具:
java
@Tool(description = "抓取指定 URL 的完整网页内容")
public String fetchWebPage(@ToolParam(description = "要抓取的 URL") String url) {
// 调用网页抓取服务
return jinaReader.read(url);
}LLM 可以先 search 找到候选 URL,再 fetch 拿到完整内容。
多轮检索(ReAct 模式)
对复杂问题,单次检索可能不够。让 LLM 走 ReAct 循环:
java
Thought: 我需要先了解 X
Action: search("X 是什么")
Observation: X 是 ...
Thought: 现在需要进一步了解 X 的最新版本
Action: search("X 最新版本")
Observation: X 最新版本是 1.2
Thought: 已有足够信息,可以回答
Final Answer: ...Spring AI 通过 Tool + 多轮对话天然支持这种模式。
把网络结果存入向量库
频繁查询的网络内容可以"沉淀"到内部知识库:
java
public String search(String query) {
List<Map<String, String>> results = searchUtils.tavilySearch(query);
// 把高价值结果存入向量库
List<Document> docs = results.stream()
.filter(r -> isHighValue(r))
.map(r -> new Document(r.get("content"), Map.of(
"source", r.get("url"),
"type", "web",
"fetched_at", new Date().toString()
)))
.collect(Collectors.toList());
vectorStore.add(docs);
return formatResults(results);
}这样系统会"自我成长":用得越多,内部知识库越完善。
隐私与合规
网络检索意味着把用户的查询发送到外部服务。需要考虑:
- 敏感信息脱敏(公司内部代号、客户名等)
- 查询日志的审计
- 用户协议告知
某些行业(金融、医疗)可能完全不允许走外部 API,这种场景就只能用 SearXNG + 内网部署。
小结
本篇展示了如何为 RAG 系统增加"网络检索"能力:
- Tavily 提供专为 LLM 设计的结构化搜索 API
- SearXNG 作为自托管的元搜索方案,覆盖更广
- 三种集成模式:路由式、补充式、Tool 式
- 进阶方向:缓存、过滤、抓取、ReAct、知识沉淀
至此,这个 Spring AI RAG 知识库系统的核心能力已经全部解析完毕。从基础对话到 RAG,从来源追溯到 Text-to-SQL,从防幻觉到网络检索,每一块拼图组合起来,构成了一个生产级的智能问答系统。
系列总结
回顾整个系列,我们围绕一个真实项目走完了 RAG 系统的完整链路:
| 篇号 | 主题 | 核心收获 |
|---|---|---|
| 00 | 系列总览 | 项目架构与技术栈全景 |
| 01 | ChatClient 基础对话 | Spring AI 的 Fluent API 与流式输出 |
| 02 | ChatMemory 多轮会话 | Advisor 模式与用户隔离 |
| 03 | 文档上传与向量化 | Tika + TokenTextSplitter + VectorStore |
| 04 | RAG 检索阶段 | QuestionAnswerAdvisor 与 SearchRequest |
| 05 | 敏感词过滤 | 内容安全的前置防护 |
| 06 | AOP 日志与热词 | IK 分词与定时任务 |
| 07 | JWT 认证 | 无状态认证与 ThreadLocal |
| 08 | AI 绘图 | ImageModel 集成 |
| 09 | 来源追溯 | 自定义 Advisor 实现 |
| 10 | Text-to-SQL | 跨向量聚合的解法 |
| 11 | 文档更新与删除 | 全链路数据一致性 |
| 12 | 防幻觉与召回优化 | RetrievalAugmentationAdvisor 与 Rerank |
| 13 | 网络检索 | Tavily/SearXNG 集成 |
希望这个系列对你的 RAG 项目有所启发。技术世界变化很快,今天的"最佳实践"明天可能就被刷新,但基础的工程方法论------分层、抽象、可测、可观测------永远不会过时。
祝你在 AI 工程的路上走得稳、走得远。
