K8S学习
- 云计算课程学习笔记
-
- 公网ip与私网ip的区别
- 服务器集群
- VPC:专有网络、私有网络
- docker基本概念
- k8s
- Kubernetes核心实战
-
- 1、资源创建方式
- 2、Namespace
-
- [通过yaml 创建命名空间](#通过yaml 创建命名空间)
- 3、Pod
- 4、Deployment
-
- ```删除一个部署```
- ```副本能力:创建有三个副本的应用```
- ```分散部署:鸡蛋不放在一个篮子里```
- 扩缩容:动态扩缩容
- [修改 replicas](#修改 replicas)
- 自愈能力
- 滚动更新
- 滚动回退
- 5、Service服务发现与负载均衡
- [6、Ingress 网关入口](#6、Ingress 网关入口)
- 存储抽象
-
- [docker 方式的挂载在外面便于修改数据](#docker 方式的挂载在外面便于修改数据)
- 搭建NFS网络文件存储系统
- 让其他节点同步NFS
- 原生方式挂载数据
- PV/PVC
- [ConfigMap 配置文件挂载](#ConfigMap 配置文件挂载)
- 7、Secret
云计算课程学习笔记
公网ip与私网ip的区别
公网ip:任何人在任何地点都能访问到的ip
私网ip:内部服务器网卡真正用的ip,固定不变的,搭建的集群的每个私有ip都不变的。
服务器集群
服务器内部访问,通过私有ip访问。当然服务器之间通过公网ip访问也是可以的,但是如果是在同一个集群内,如果用私网ip,就不会走公网的流量,不会收费。而且网速比较快,不会有网络带宽的限制。
VPC:专有网络、私有网络
网段:这个网络(vpc)下,一定会连接很多的云服务器资源,以及每个服务器的ip地址都是vpc指定的网段范围。能够划分的可用的网段。
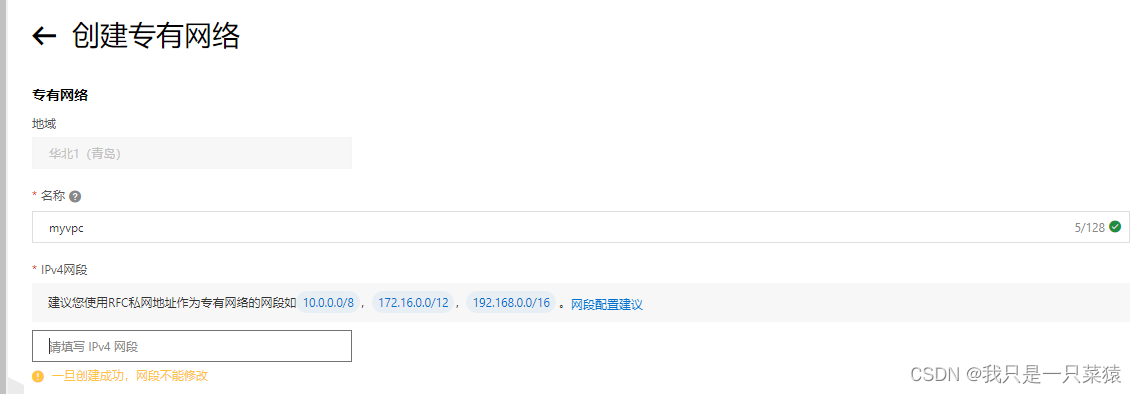
如192.168.0.0/16,表示成二进制后是一个八位数。利用子网计算功能:
掩码位的功能的是:
192.168.0.0转换成二进制是:
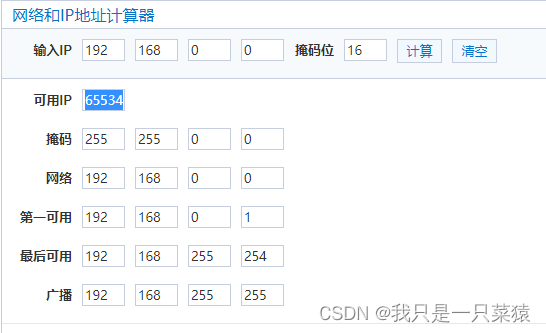
11000000.10101000.00000000.00000000/16,掩码位是指前16位不变,后面的随机变化。所以该网段是192.168.0.0~192.168.255.255=256*256=65536。可以有6万台左右机器。但是192.168.0.0是起始,192.168.255.255是广播地址,是不可用的。所以真正可用的ip数量一共是65536- 1- 1=65534
这个网段太大了。
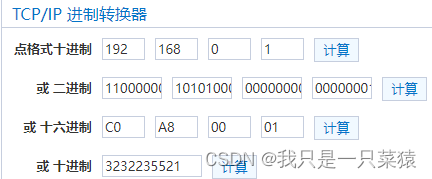
所以可以在vpc继续规划子网。
交换机的意思是继续创建子网。

IPv4网段的意思是继续用交换机继续划分子网:
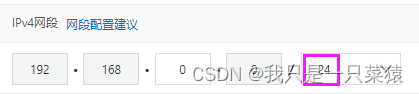
划分的依据是前面24位保持不变,那么这个网段有256个ip,一共有254个机器可用。

通过改变网段,又可以划分出来一个ip网段,也能容纳254个机器。
vpc之间是隔离的
途中两个vpc虽然使用了同一个ip网段,但是他们之间是隔离的,不会相互冲突。
比如两个小区都是192.168.0.0,网段是一样的,但是物理上隔离的。公网路由会丢掉保留的私网ip地址,所以这个ip是隔离的。在同一个vpc网络,网络是互通的。比如测试和生产的机器都是192.168.0.0这个网段,但是物理上隔离的,增加了安全性。

docker基本概念
解决问题:
应用构建的统一标准
Java、C++、Javascript
打成软件包。像window的exe一样,通过docker build命令=====>镜像
应用共享
旧的都是通过网络下载或者通过U盘下载,docker把所有的应用放到docker hub上下载,类似于安卓的应用市场。
应用的运行
旧:通过Java -jar 来运行,C++的通过编译。docker 通过docker run 统一运行。
容器化时代
虚拟化技术(重量级):通过给tomcat、数据库、redis安装一个虚拟机,即使一个发生内存泄漏而不会把内存使用完,能够保证程序的正常运行。缺点:镜像很大,启动速度很慢,移植与分享不方便(把虚拟机拷贝一份)。
容器化技术:将不同linux的操作系统的差异化函数库打包到镜像中。通过沙箱机制,保证容器安全,启动速度快。
资源隔离
cpu、memory资源隔离与限制
访问设备隔离与限制
资源仓库
docker hub
安装
bash
### 配置yum源
sudo yum install -y yum-utils
sudo yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
## 安装docker sudo yum install -y docker-ce docker-ce-cli containerd.io
#以下是在安装k8s的时候使用
yum install -y docker-ce-20.10.7 docker-ce-cli-20.10.7 containerd.io-1.4.6
## 配置镜像加速
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://s90ld29q.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker启动
systemctl enable docker --now
nginx的开机自动运行
docker run --name=mynginx -d --restart=always nginx
redis
安装redis
docker安装redis命令:
docker pull redis
安装时,考虑redis的数据和配置挂载到外部宿主机上。
配置:/data/redis/conf 数据:/data/redis/data
启动redis
docker run 命令如果没有指定自定义启动命令,容器是不会加载自定义的配置文件的。
容器内部使用自定义位置配置文件的启动命令:
"redis-server","/etc/redis/redis.conf"
docker run -p 6379:6379 --name myredis -v /usr/local/docker/redis.conf:/etc/redis/redis.conf -v /usr/local/docker/data:/data -d redis redis-server /etc/redis/redis.conf --appendonly yes
docker run -d redis redis-server /usr/local/etc/redis/redis.conf
部署
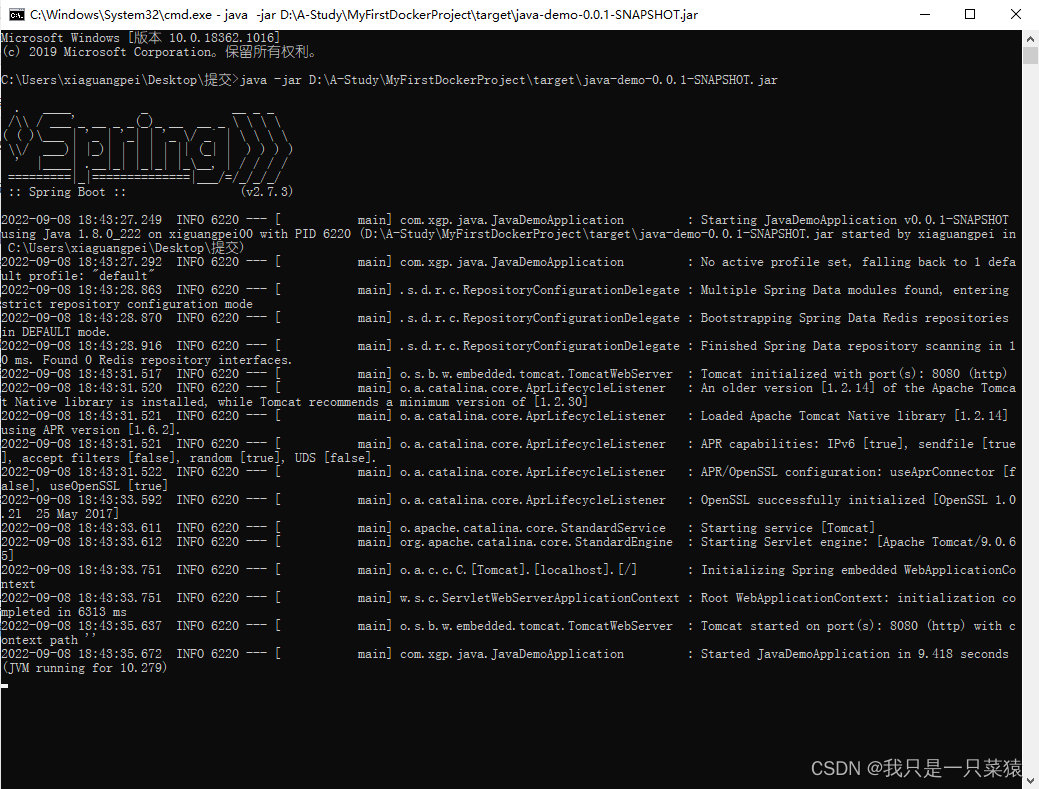
- 1、以前的方式
①springboot打包成可执行的jar包。
②拿到jar包后,上传到服务器,执行java -jar D:\A-Study\MyFirstDockerProject\target\java-demo-0.0.1-SNAPSHOT.jar
如下图:
存在问题:需要装Java环境,或者其他的Python环境
- 2、通过docker部署(DockerFile)
所有机器都安装docker ,任何应用都是镜像,所有机器都可以运行。
创建Dockerfile文件

①FROM 基础运行环境
在Docker hub上查找基础版本openjdk,在Tags中搜索8-jdk,不要window版本的,window版本的比较大。查找Linux版本的。
docker pull openjdk:8-jdk-slim
Dockerfile
FROM openjdk:8-jdk-slim② LABEL 写作者的标签
Dockerfile
FROM openjdk:8-jdk-slim
LABEL maintainer=leifengyang③COPY 把目标文件拷贝到镜像中
Dockerfile
FROM openjdk:8-jdk-slim
LABEL maintainer=leifengyang
COPY target/*.jar /java-demo.jar④ENTRYPOINT 镜像的启动命令或者写CMD
Dockerfile
FROM openjdk:8-jdk-slim
LABEL maintainer=xiaguangpei
COPY target/*.jar /java-demo.jar
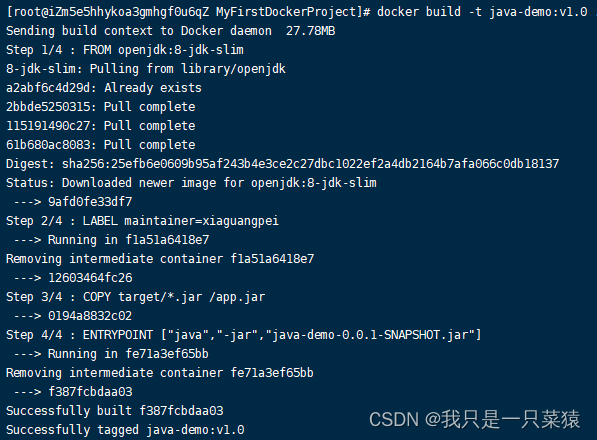
ENTRYPOINT ["java","-jar","java-demo.jar"]按照如下,在服务器打放置文件:
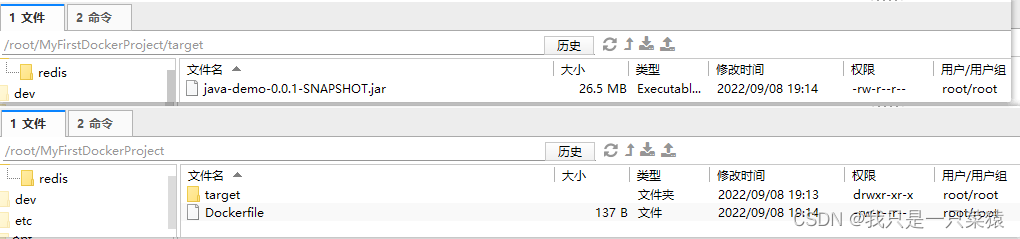
⑤采用docker命令制作镜像
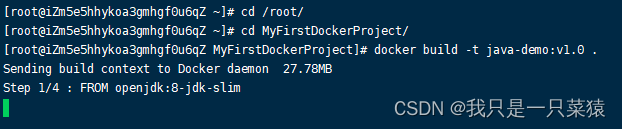
docker build -t java-demo:v1.0 .
-t的意思是标签名。
-f 是使用哪个文件指导创建镜像,,如果名字是Dockerfile就可以不写-f
.表示在哪个目录下构建镜像。
查看构建成功的镜像:
通过 docker logs -f --details containername查看docker详细日志
-f 是跟踪的意思,有日志就会打印出。
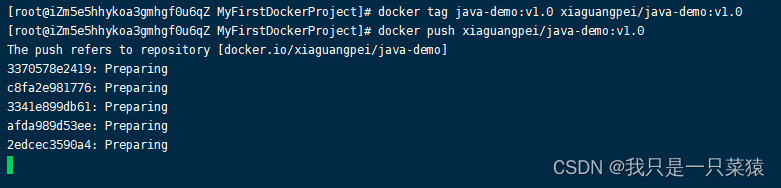
⑥将镜像推送到docker hub
给老的镜像打个标签
docker tag java-demo:v1.0 xiaguangpei/java-demo:v1.0
推送到docker hub仓库
docker push xiaguangpei/java-demo:v1.0

k8s
k8s:的集群架构:N Master Node + N Worker Node(N主节点+N工作节点) N >=1
k8s:容器编排技术。
组件架构
Control Plane控制面板(主节点)(硅谷总部):控制工厂生产。
Controller Mannager:决策者。维持副本期望数目。
etcd:资料,类似Redis的KeyValue。键值对数据库,存储K8S集群所有重要信息(持久化)。
Api Server:秘书部:与etcd与Nodes进行交互。所有服务访问统一入口
Scheduler:调度者。负责接受任务,选择合适的节点进行分配任务,需要清楚网盘,内存等资源大小。
Kubelet:每个厂的厂长。由ApiServer负责通知生产。监控每个厂的运行情况。本厂生产线的启动和停止。如果本厂实在坏了 ,就通知Api Server ,然后Api Server 通知决策者,决策者就更换其他厂生产,然后秘书处在etcd更新厂的运行和生产情况。秘书处通知调度者,就计算一下,把生产情况分析资料,并决策情况存储到etcd。然后api-server就把决策通知到每个厂的厂长。然后由厂长开始执行每个项目。直接跟容器引擎交互实现容器的生命周期管理。
K-proxy:看门大爷。本厂的传达室。相当于网关,负责对外的访问和路由、负载。负责写入规则至IPVS或者IPtable,实现服务的映射访问。
CoreDNS:可以为集群中的SVC创建一个域名IP的对应对应关系解析 。
DashBoard:给K8S集群提供一个B/S的访问结构体系 。
Ingress Controller:官方只能实现四层代理,而它可以实现七层代理 。
Fedetation:可以提供一个跨集群中心多K8S统一管理功能 。
Prometheus:提供一个K8S的集群监控能里
ELK:提供K8S集群日志统一分析 介入平台。
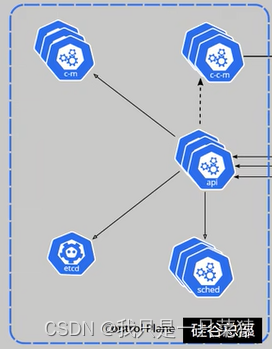
由程序员控制Kubernates控制中心:kubctl。
集群部署
kubectl和kubeadm、kubelet
kubelet:①k8s进行交互,获取pod相关的数据,监控当前的Pod变化的事件。②kubelet操作当前宿主机的资源信息,并启动Pod
kubectl:由程序员通过这两个命令给集群发号命令,但实际上只需要给master节点安装即可。
kubeadm:由程序员快速搭建集群。
docker::必须安装。
初始化
kubeadm:初始化一个主节点,k8s会把当前节点视为主节点。主节点的所有内容由kubelet安装,scheduler、kube-proxy、api-server、etcd、controller-manager。然后通过kubeadmin join 加入master节点,就可以了,kubelet就会给子节点安装kube-proxy。
集群部署
ip a:查看ip地址。输出如下:
root@iZm5e5hhykoa3gmhgf0u6sZ \~# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:16:3e:04:33:b0 brd ff:ff:ff:ff:ff:ff
inet 172.26.163.27/20 brd 172.26.175.255 scope global dynamic noprefixroute eth0
valid_lft 314925183sec preferred_lft 314925183sec
集群之间,通过内网通讯,通过eth0网卡通讯,通过私网ip通讯。ping心跳检测其他服务器。
kubectl和kubelet、kubeadm
装好kubectl和kubelet,用kubeadm工具整一个主节点,再通过kubeadm安装加入一些子节点。
kubelet:①k8s进行交互,获取pod相关的数据,监控当前的Pod变化的事件。②kubelet操作当前宿主机的资源信息,并启动Pod
kubectl:由程序员通过这两个命令给集群发号命令,但实际上只需要给master节点安装即可。
kubeadm:由程序员快速搭建集群。
docker::必须安装。即提供容器化运行环境。
初始化
kubeadm:初始化一个主节点,k8s会把当前节点视为主节点。主节点的所有内容由kubelet安装,scheduler、kube-proxy、api-server、etcd、controller-manager。然后通过kubeadmin join 加入master节点,就可以了,kubelet就会给子节点安装kube-proxy。
设置主机名与清空交换分区
1、hostnamectl 设置主机名
2、free -m清空交换分区
bash
#各个机器设置自己的域名
hostnamectl set-hostname k8s-node1
# 将 SELinux 设置为 permissive 模式(相当于将其禁用)
#控制当前窗口规则
sudo setenforce 0
# 通过修改配置达到永久禁用
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
#关闭swap
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
# 将ipv6的流量桥接至ipv4网卡上,便以统计。k8s官方要求这么做。
#允许 iptables 检查桥接流量
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# 察看所有的linux的内核配置。
sudo sysctl --system配置k8s的源地址及安装kubeadm、kubectl、kubelet
bash
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
exclude=kubelet kubeadm kubectl
EOF
sudo yum install -y kubelet-1.20.9 kubeadm-1.20.9 kubectl-1.20.9 --disableexcludes=kubernetes
sudo systemctl enable --now kubelet使用kubeadm引导启动集群
kubeadm:kubelet会在每一台机器上安装kube-proxy,kubelet会下载镜像,启动容器。所以除了kubelet,剩下的都是以容器化的方式运行。但是下载镜像可能会卡住,所以提前配置了镜像,防止下载阶段被卡住。
下载各个机器需要的镜像
一般情况下,主节点需要所有下载项镜像。子节点只需要kube-proxy。但是保险期间,所有的节点都配置这些镜像
bash
sudo tee ./images.sh <<-'EOF'
#!/bin/bash
images=(
kube-apiserver:v1.20.9
kube-proxy:v1.20.9
kube-controller-manager:v1.20.9
kube-scheduler:v1.20.9
coredns:1.7.0
etcd:3.4.13-0
pause:3.2
)
for imageName in ${images[@]} ; do
docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/$imageName
done
EOF
chmod +x ./images.sh && ./images.sh初始化主节点
bash
# 设置域名映射 所有节点都执行这句话,这样所有节点都知道主节点在哪里了。下面只有主节点才需要执行 172.26.163.34替换为主节点的ip
echo "172.26.163.34 cluster-endpoint" >> /etc/hosts
#主节点初始化 172.26.163.34替换为主节点的ip
# 主节点初始化时service-cidr和pod-network-cidr不能重叠且不能和机器的ip重叠
kubeadm init \
--apiserver-advertise-address=172.26.163.34 \
--control-plane-endpoint=cluster-endpoint \
--image-repository registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images \
--kubernetes-version v1.20.9 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=192.168.0.0/16
#
## 如果初始化时修改了pod-network-cidr=192.168.0.0/16
## 需要在images.sh中执行
cat calico.yaml |grep 192.168.0.0/16
## 把以上ip改成自定义的ip。
##初始化失败时,需要重新初始化:
kubeadm reset从初始化完成之后返回的信息,表示初始化成功!要保留kubeadm join cluster-endpoint:6443。。。。。
bash
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join cluster-endpoint:6443 --token vf9b2z.uaew25u339kryzfy \
--discovery-token-ca-cert-hash sha256:803831192e259ad8287751b244afb0e8c442b2e4223472b735eebd83515d81d0 \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join cluster-endpoint:6443 --token vf9b2z.uaew25u339kryzfy \
--discovery-token-ca-cert-hash sha256:803831192e259ad8287751b244afb0e8c442b2e4223472b735eebd83515d81d0
bash
# 把以下命令在控制台上执行:
# 把核心配置复制到了这个目录下,给了一些权限
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config根据提示安装网络组件
bash
### 下载配置文件
curl https://docs.projectcalico.org/v3.18/manifests/calico.yaml -O
### 给k8s集群创建资源:
kubectl apply -f calico.yaml
##查看集群部署了哪些应用。
## docker ps === kubectl get pods -A
kubectl get pods -A
## 只有在主节点kubectl get pods -A才能知道运行了多少个pods
## 运行中的应用:docker中叫容器,k8s中叫pods初始化从节点
bash
# 每个节点都执行,都能通过域名找到主节点.172.26.163.28替换为对应的主机IP.
echo "172.26.163.28 cluster-endpoint" >> /etc/hosts初始化从节点时报错问题
bash
[root@k8s-node2 ~]# kubeadm join cluster-endpoint:6443 --token 73nftg.oig0ajmy3e0tgqou --discovery-token-ca-cert-hash sha256:e49ef870805b18ba8df13a731e8428d1019d01a550b5d017a72b7bf1669ec76f
[preflight] Running pre-flight checks
[WARNING FileExisting-tc]: tc not found in system path
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 20.10.7. Latest validated version: 19.03
[WARNING Hostname]: hostname "k8s-node2" could not be reached
[WARNING Hostname]: hostname "k8s-node2": lookup k8s-node2 on 100.100.2.136:53: no such host
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
[kubelet-check] Initial timeout of 40s passed.
error execution phase kubelet-start: error uploading crisocket: timed out waiting for the condition
To see the stack trace of this error execute with --v=5 or higher采用以下命令修复
这项配置也需要:
bash
# Docker是用yum安装的,docker的cgroup驱动程序默认设置为system。默认情况下Kubernetes cgroup为systemd,我们需要更改Docker cgroup驱动,
vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
# 重启docker
systemctl restart docker
bash
rm -f /etc/kubernetes/pki/ca.crt
rm -f /etc/kubernetes/kubelet.conf
swapoff -a
kubeadm reset
systemctl daemon-reload
systemctl restart kubelet
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
kubeadm join cluster-endpoint:6443 --token 73nftg.oig0ajmy3e0tgqou --discovery-token-ca-cert-hash sha256:e49ef870805b18ba8df13a731e8428d1019d01a550b5d017a72b7bf1669ec76fk8s查看显示一个或者多个资源
bash
[root@k8s-master ~]# kubectl get pod -A
# 名称,就绪数量、状态(数量)、重启次数(k8s的自愈能力)
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-dd89d97f8-vd62f 1/1 Running 0 12m
kube-system calico-node-p54vb 0/1 Running 0 12m
kube-system coredns-5897cd56c4-g4p6s 1/1 Running 0 31m
kube-system coredns-5897cd56c4-m9ttx 1/1 Running 0 31m
kube-system etcd-k8s-master 1/1 Running 0 31m
kube-system kube-apiserver-k8s-master 1/1 Running 0 31m
kube-system kube-controller-manager-k8s-master 1/1 Running 0 31m
kube-system kube-proxy-5fttf 1/1 Running 0 31m
kube-system kube-scheduler-k8s-master 1/1 Running 0 31mk8s的自我修复能力测试
假设服务器宕机,然后重启k8s的整个集群,测试k8s的整个集群能不能重新启动起来,一切都准备好,不用人工干预。
模拟重启服务器
bash
reboot启动后:
bash
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane,master 37m v1.20.9
k8s-node1 Ready <none> 24m v1.20.9
k8s-node2 Ready <none> 24m v1.20.9
[root@k8s-master ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-577f77cb5c-6mzw4 1/1 Running 1 32m
kube-system calico-node-9lz2q 0/1 Running 1 25m
kube-system calico-node-hnhrt 1/1 Running 1 32m
kube-system calico-node-pz8d9 1/1 Running 1 25m
kube-system coredns-5897cd56c4-4nrvh 1/1 Running 1 37m
kube-system coredns-5897cd56c4-flc2m 1/1 Running 1 37m
kube-system etcd-k8s-master 1/1 Running 2 37m
kube-system kube-apiserver-k8s-master 1/1 Running 2 37m
kube-system kube-controller-manager-k8s-master 0/1 Running 2 37m
kube-system kube-proxy-fb99g 1/1 Running 1 25m
kube-system kube-proxy-h5dbx 1/1 Running 1 37m
kube-system kube-proxy-sh74f 1/1 Running 1 25m
kube-system kube-scheduler-k8s-master 0/1 Running 2 37m
[root@k8s-master ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-577f77cb5c-6mzw4 1/1 Running 1 35m
kube-system calico-node-9lz2q 1/1 Running 1 27m
kube-system calico-node-hnhrt 1/1 Running 1 35m
kube-system calico-node-pz8d9 1/1 Running 1 28m
kube-system coredns-5897cd56c4-4nrvh 1/1 Running 1 40m
kube-system coredns-5897cd56c4-flc2m 1/1 Running 1 40m
kube-system etcd-k8s-master 1/1 Running 2 40m
kube-system kube-apiserver-k8s-master 1/1 Running 2 40m
kube-system kube-controller-manager-k8s-master 1/1 Running 2 40m
kube-system kube-proxy-fb99g 1/1 Running 1 28m
kube-system kube-proxy-h5dbx 1/1 Running 1 40m
kube-system kube-proxy-sh74f 1/1 Running 1 27m
kube-system kube-scheduler-k8s-master 1/1 Running 2 40m重新获取令牌指令
bash
kubeadm token create --print-join-command部署dashboard
bash
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.3.1/aio/deploy/recommended.yaml
## 把k8s访问的端口号,暴漏到机器上。类似docker的-p 端口暴露
## 1、运行下面这个命令,输入 /type:搜索,将type: ClusterIP 改为 type: NodePort。然后保存
kubectl edit svc kubernetes-dashboard -n kubernetes-dashboard
kubectl get svc -A |grep kubernetes-dashboard
bash
ports:
- nodePort: 30955
port: 443
protocol: TCP
targetPort: 8443
selector:
k8s-app: kubernetes-dashboard
sessionAffinity: None
type: NodePort
status:
loadBalancer: {}
bash
[root@k8s-master ~]# kubectl get svc -A |grep kubernetes-dashboard
## 30955这个端口就是未来访问k8s控制台的。
## 访问: https://集群任意IP:端口 https://47.104.148.65:30955/
kubernetes-dashboard dashboard-metrics-scraper ClusterIP 10.96.113.14 <none> 8000/TCP 112m
kubernetes-dashboard kubernetes-dashboard NodePort 10.96.58.179 <none> 443:30955/TCP 112m创建k8s用户:
bash
## 创建文件 输入下面的文件内容
vi dash.yaml
## 应用
kubectl apply -f dash.yaml
yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
bash
[root@k8s-master ~]# kubectl apply -f dash-usr.yaml
serviceaccount/admin-user created
clusterrolebinding.rbac.authorization.k8s.io/admin-user createdadmin-user创建了,但是不是通过用户密码登录的,而是通过令牌登录的,通过下面的命令获取令牌:
bash
kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template="{{.data.token | base64decode}}"
bash
[root@k8s-master ~]# kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template="{{.data.token | base64decode}}"
eyJhbGciOiJSUzI1NiIsImtpZCI6ImIxSVg1TU9Ub3JXVjViNzRPNmdUeVhiQWlIZWpiOUdTVXFKaVVNcE9oUkEifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLTQ5Nnd3Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiI2OTQ4NGNlYi1mNGU0LTQ4MzAtYTJiMS1mNzEwZGY2ZTE5ZTgiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.K_dh8eO3SrCr6-s_xwr-xhlS7asZO3hW4wah16YMpJrPg8IOaFQYiiRMCD1CC8P7HD8cx-XXsRN2oNSjPudpTArZWP85u4qle3mHQOmbVuLdkEzVARRXsoKkl6T4Cfu-vGyOwmBjT5PhY6MzMKMS9ymhFmlBZ9ih7qi2QSg2C0CNRrHdh0xgevGYq8oZ-iGZSl84wLs74djynNaMQCqp782Ga9-sQ4YmGN20cIPbsZe0BiXP0IpHIqQ2y-4KR6jXxD48tjrcnPw8D6Bex2BLtOjWHRoNjx9w1BrwcOioWTmSBk0V5MoUzz_HfJ5pyWOo1yXAHLhxfQhFv8Ch5kf2jgKubernetes核心实战
1、资源创建方式
- 命令行
- YAML
2、Namespace
隔离资源,不隔离网络
- kubectl create ns hello
- kubectl delete ns hello
bash
# 获取所有的命名空间
kubectl get ns
bash
如果不加-A,只打印默认default命名空间下的
kubectl get pod -A
## -n kube-system 指定命名空间
kubectl get pod -n kube-system
## 删除命名空间
kubectl delete ns mykubectl
## 创建命名空间
kubectl create ns hello通过yaml 创建命名空间
yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: myapp
name: myapp
spec:
containers:
- image: nginx
name: nginx
- image: tomcat:8.5.68
name: tomcat
bash
## 创建命名空间
kubectl apply -f hello.yaml
## 删除命名空间
kubectl delete -f hello.yaml3、Pod
概念:pod是一组共享命名空间、卷、IP、PORT的运行中的一组容器,Pod是kubernetes中应用的最小单位。一组容器被k8s封装成了Pod,便于管理.。每个pod中有一个pause容器负责网络代理和挂载卷。k8s认为单个容器太小,不能视为一个单位,就将一组容器作为一个单位进行管理。一组容器负责一个事情。
bash
## 运行一个nginx,用nginx镜像,名字是mynginx
kubectl run mynginx --image=nginx
bash
[root@k8s-master ~]# kubectl run mynginx --image=nginx
pod/mynginx created
[root@k8s-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
mynginx 0/1 ContainerCreating 0 23sContainerCreating :表示容器正在创建中,需要下载并启动
bash
## k8s通过事件的方式描述容器
kubectl describe pod mynginx
bash
## 删除容器,默认的不需要加命名空间
[root@k8s-master ~]# kubectl delete pod mynginx
pod "mynginx" deleted网络通讯
同一个pod之间共享网络命名空间,共享同一个linux协议栈
pod之间:①pod1与pod2不在同一台主机,pod的地址是与docker0在同一个网段的,但docker0网段与宿主机网卡是两个完全不同的IP网段,并且不同的node之间通讯只能通过宿主机的物理网卡进行,将pod的ip地址和node的IP关联起来,通过这个关联可以互相访问。
②pod1与pod2在同一台机器,由docker0网桥直接转发请求至pod2,不需要Flannel.
pod与Service:①基于性能的考虑,全部为iptable、lvs维护和转发。
②pod到外网:pod向外网发送请求,查找路由表,转发数据包到宿主机的网卡,苏书记网卡完成路由选择后,iptables执行masquerade,把源ip更改为宿主机网卡的ip,然后向外网发送请求。
1、podA(这个ip地址CNI在Pod启动时分配的ip5)通过resolv.conf配置文件获取dns的ip地址ip1
2、向dns的ip1地址咨询实际服务B集群的虚拟服务地址ip2,根据集群B的服务地址向本机kube-proxy询问,
3、kubeproxy缓存或根据service的标签api-server向etcd获取了所有集群B的服务器ip列表,并根据
负载均衡选择一个健康节点ip3(这个ip地址CNI在Pod启动时分配的)
5、kubeproxy拿到这个podB的ip3(这个ip地址CNI在Pod启动时分配的ip3),然后根据访问的类型
5.0如果ip3是外网ip时,再把发送方ip5转换为主机网卡ip4(SNAT)。然后主机网卡将服务发送,然后返回后内核再将发送方ip4替换为ip5
将返回内容再返回给发送方的ip5。
5.1如果ip3是本pod的,就直接localhost访问.
5.2如果ip3是本node的(可以是物理机、虚拟机、云主机),就在本机器上做转发,通过内核/网桥直接转发,不经过物理网卡。
5.3如果ip3是其他node的,通过主机网卡ip4转发(一般保留源IP)。
通过yaml创建pod
bash
[root@k8s-master ~]# vi mynginx.yaml
[root@k8s-master ~]# kubectl apply -f mynginx.yaml
pod/mynginx created
[root@k8s-master ~]# kubectl delete -f mynginx.yaml
pod "mynginx" deleted
bash
apiVersion: v1
kind: Pod
metadata:
labels:
run: mynginx
name: mynginx
# namespace: default
spec:
containers:
- image: nginx
name: mynginxdashboard 创建pod方式
没有指定命名空间时,无法创建pod
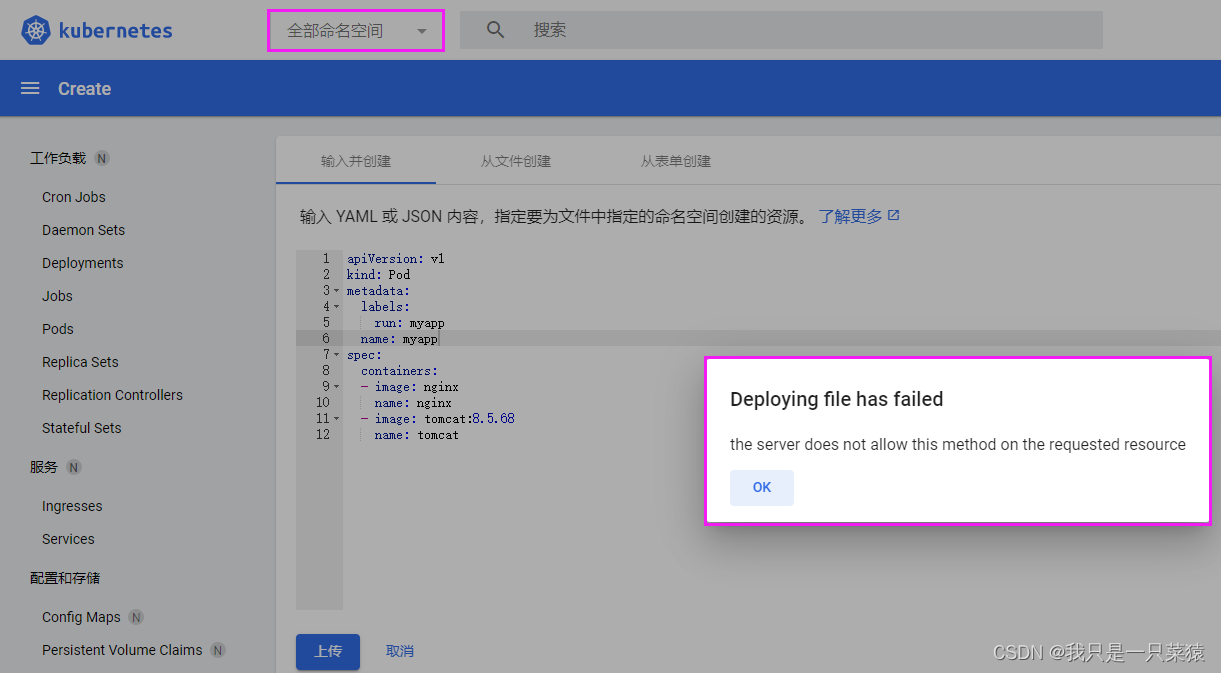
- 有两种解决方案
- 一种是通过指定命名空间
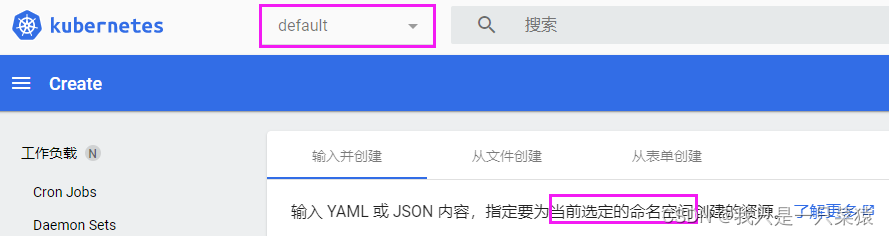
- 文件中指定命名空间
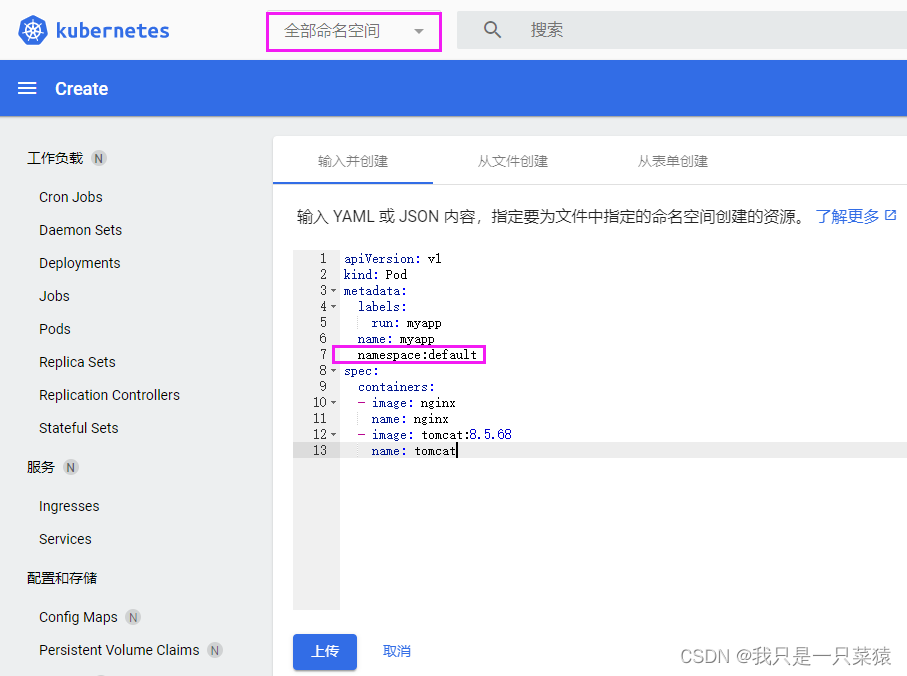
- 一种是通过指定命名空间
日志
bash
# 阻塞式查看日志
kubectl logs -f pod名称
bash
# 打印pod的完善信息,查看访问的ip
kubectl get pod -owide每个pod,k8s都会分配一个ip。采用ip+容器端口号就能访问到
进入容器内部
bash
kubectl exec -it mynginx -- /bin/bash
root@mynginx:/# ls -l
total 80
drwxr-xr-x 2 root root 4096 Dec 20 2021 bin
drwxr-xr-x 2 root root 4096 Dec 11 2021 boot
drwxr-xr-x 5 root root 360 Sep 13 13:23 dev
drwxr-xr-x 1 root root 4096 Dec 29 2021 docker-entrypoint.d
-rwxrwxr-x 1 root root 1202 Dec 29 2021 docker-entrypoint.sh
drwxr-xr-x 1 root root 4096 Sep 13 13:23 etc
drwxr-xr-x 2 root root 4096 Dec 11 2021 home
drwxr-xr-x 1 root root 4096 Dec 20 2021 lib
drwxr-xr-x 2 root root 4096 Dec 20 2021 lib64
drwxr-xr-x 2 root root 4096 Dec 20 2021 media
drwxr-xr-x 2 root root 4096 Dec 20 2021 mnt
drwxr-xr-x 2 root root 4096 Dec 20 2021 opt
dr-xr-xr-x 144 root root 0 Sep 13 13:23 proc
drwx------ 2 root root 4096 Dec 20 2021 root
drwxr-xr-x 1 root root 4096 Sep 13 13:23 run
drwxr-xr-x 2 root root 4096 Dec 20 2021 sbin
drwxr-xr-x 2 root root 4096 Dec 20 2021 srv
dr-xr-xr-x 13 root root 0 Sep 13 13:33 sys
drwxrwxrwt 1 root root 4096 Dec 29 2021 tmp
drwxr-xr-x 1 root root 4096 Dec 20 2021 usr
drwxr-xr-x 1 root root 4096 Dec 20 2021 var思考题
为什么给pod分配了一个ip是192.168.36.77
答:主节点初始化引导master节点的时候 --pod-network-cidr=192.168.0.0/16,pod的网络的范围域,k8s给每一个pod分配网络,应该在哪个范围里分配。
创建多个容器
myapp中在同一个网络空间中,共享网络和存储。
bash
apiVersion: v1
kind: Pod
metadata:
labels:
run: myapp
name: myapp
spec:
containers:
- image: nginx
name: nginx
- image: tomcat:8.5.68
name: tomcat
bash
curl 192.168.169.130:8080不能在一个pod中有两个nginx应用。因为一个pod中容器在一个网络空间中,可以认为一个pod代表一个Linux小虚拟机
4、Deployment
bash
#### 同时删除两个pod
[root@k8s-master ~]# kubectl delete pod myapp mynginx -n default
pod "myapp" deleted
pod "mynginx" deleted创建一个部署,而不是一个单纯的pod,那可以告诉k8s的副本数量,k8s就通过Deployment帮我控制副本的数量。
bash
# 比较下面两个命令有何不同效果?
[root@k8s-master ~]# kubectl run mynginx --image=nginx
pod/mynginx created
[root@k8s-master ~]# kubectl create deployment mytomcat --image=tomcat:8.5.68
deployment.apps/mytomcat created
[root@k8s-master ~]# kubectl delete pod mytomcat-6f5f895f4f-bzxjc
pod "mytomcat-6f5f895f4f-bzxjc" deleted
# 自愈能力。即使通过delete命令把容器删除了,k8s也会给我们重新创建一个容器。删除一个部署
bash
[root@k8s-master ~]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
mytomcat 1/1 1 1 4m59s
[root@k8s-master ~]# kubectl delete deploy mytomcat
deployment.apps "mytomcat" deleted
[root@k8s-master ~]# kubectl get deploy
No resources found in default namespace.副本能力:创建有三个副本的应用
bash
[root@k8s-master ~]# kubectl create deploy my-dep --image=nginx --replicas=3
deployment.apps/my-dep created
[root@k8s-master ~]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
my-dep 0/3 3 0 10s分散部署:鸡蛋不放在一个篮子里
bash
[root@k8s-master ~]# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-dep-01-6456cdfc7-bthwp 1/1 Running 0 56s 192.168.36.80 k8s-node1 <none> <none>
my-dep-01-6456cdfc7-g7m8g 1/1 Running 0 56s 192.168.169.137 k8s-node2 <none> <none>
my-dep-01-6456cdfc7-v4xmg 1/1 Running 0 56s 192.168.36.79 k8s-node1 <none> <none>
my-dep-01-6456cdfc7-wmfr4 1/1 Running 0 56s 192.168.169.139 k8s-node2 <none> <none>
my-dep-01-6456cdfc7-xj5z5 1/1 Running 0 56s 192.168.169.138 k8s-node2 <none> <none>
my-dep-5b7868d854-9kmm9 1/1 Running 0 4m30s 192.168.36.78 k8s-node1 <none> <none>
my-dep-5b7868d854-kf97p 1/1 Running 0 4m30s 192.168.169.135 k8s-node2 <none> <none>
my-dep-5b7868d854-qf2nz 1/1 Running 0 4m30s 192.168.169.136 k8s-node2 <none> <none>
mynginx 1/1 Running 0 13m 192.168.169.132 k8s-node2 <none> <none>通过配置文件的方式创建具有副本的deployment
bash
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: my-dep
name: my-dep
spec:
replicas: 3
selector:
matchLabels:
app: my-dep
template:
metadata:
labels:
app: my-dep
spec:
containers:
- image: nginx
name: nginx扩缩容:动态扩缩容
bash
[root@k8s-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
my-dep-5b7868d854-9kmm9 1/1 Running 0 12m
my-dep-5b7868d854-kf97p 1/1 Running 0 12m
my-dep-5b7868d854-qf2nz 1/1 Running 0 12m
mynginx 1/1 Running 0 21m
[root@k8s-master ~]# kubectl scale --replicas=5 deploy/my-dep
deployment.apps/my-dep scaled
[root@k8s-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
my-dep-5b7868d854-2dsfg 0/1 ContainerCreating 0 15s
my-dep-5b7868d854-4blfx 0/1 ContainerCreating 0 15s
my-dep-5b7868d854-9kmm9 1/1 Running 0 13m
my-dep-5b7868d854-kf97p 1/1 Running 0 13m
my-dep-5b7868d854-qf2nz 1/1 Running 0 13m
mynginx 1/1 Running 0 21m修改 replicas
bash
kubectl edit deployment my-dep自愈能力
如果某个容器故障或者主机宕机,当达到心跳检测阈值时,即k8s达到5分钟没有检测到心跳就会触发自愈机制,在另外一台主机上重新部署一定数量的容器。
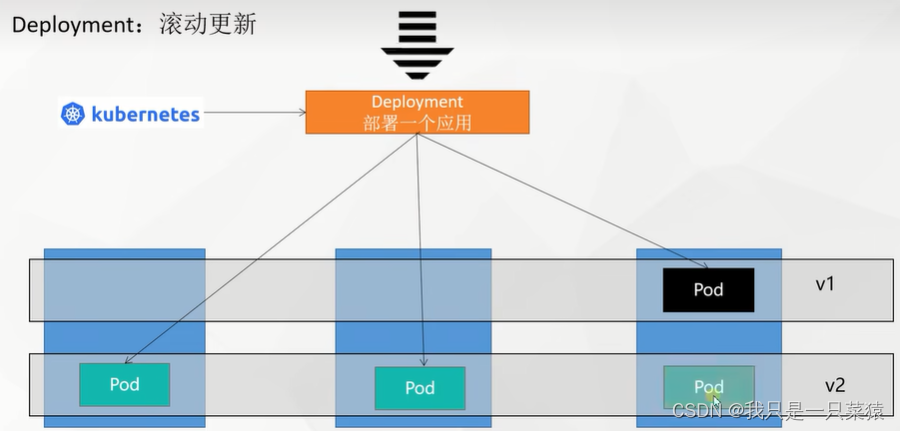
滚动更新
修改deployee中my-dep的nginx中的版本号,--record是记录一下。
bash
kubectl get deploy my-dep -oyaml
[root@k8s-master ~]# kubectl set image deploy/my-dep nginx=nginx:1.16.1 --record
不停机更新:假设旧的Deployment1运行时,重新部署新的Deployment2。他待Deployment2中的pod启动并运行稳定时,逐步用Deployment2中的pod替换Deployment1中的pod。实现滚动更新。
bash
[root@k8s-master ~]# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-dep-5b7868d854-4blfx 1/1 Running 1 21h 192.168.36.90 k8s-node1 <none> <none>
my-dep-5b7868d854-4phcv 1/1 Running 1 21h 192.168.36.86 k8s-node1 <none> <none>
my-dep-5b7868d854-9kmm9 1/1 Running 1 21h 192.168.36.89 k8s-node1 <none> <none>
[root@k8s-master ~]# kubectl get deploy my-dep
NAME READY UP-TO-DATE AVAILABLE AGE
my-dep 3/3 3 3 21h
[root@k8s-master ~]# kubectl get deploy my-dep -oyaml
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
creationTimestamp: "2022-09-13T14:44:59Z"
generation: 3
labels:
app: my-dep
managedFields:
- apiVersion: apps/v1
fieldsType: FieldsV1
fieldsV1:
f:metadata:
f:labels:
.: {}
f:app: {}
f:spec:
f:progressDeadlineSeconds: {}
f:replicas: {}
f:revisionHistoryLimit: {}
f:selector: {}
f:strategy:
f:rollingUpdate:
.: {}
f:maxSurge: {}
f:maxUnavailable: {}
f:type: {}
f:template:
f:metadata:
f:labels:
.: {}
f:app: {}
f:spec:
f:containers:
k:{"name":"nginx"}:
.: {}
f:image: {}
f:imagePullPolicy: {}
f:name: {}
f:resources: {}
f:terminationMessagePath: {}
f:terminationMessagePolicy: {}
f:dnsPolicy: {}
f:restartPolicy: {}
f:schedulerName: {}
f:securityContext: {}
f:terminationGracePeriodSeconds: {}
manager: kubectl-create
operation: Update
time: "2022-09-13T14:44:59Z"
- apiVersion: apps/v1
fieldsType: FieldsV1
fieldsV1:
f:metadata:
f:annotations:
.: {}
f:deployment.kubernetes.io/revision: {}
f:status:
f:availableReplicas: {}
f:conditions:
.: {}
k:{"type":"Available"}:
.: {}
f:lastTransitionTime: {}
f:lastUpdateTime: {}
f:message: {}
f:reason: {}
f:status: {}
f:type: {}
k:{"type":"Progressing"}:
.: {}
f:lastTransitionTime: {}
f:lastUpdateTime: {}
f:message: {}
f:reason: {}
f:status: {}
f:type: {}
f:observedGeneration: {}
f:readyReplicas: {}
f:replicas: {}
f:updatedReplicas: {}
manager: kube-controller-manager
operation: Update
time: "2022-09-14T12:06:13Z"
name: my-dep
namespace: default
resourceVersion: "46443"
uid: e1b2d136-e2c8-430a-a9d2-a5bc0b4365ec
spec:
progressDeadlineSeconds: 600
replicas: 3
revisionHistoryLimit: 10
selector:
matchLabels:
app: my-dep
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: my-dep
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nginx
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
status:
availableReplicas: 3
conditions:
- lastTransitionTime: "2022-09-13T14:44:59Z"
lastUpdateTime: "2022-09-13T14:45:16Z"
message: ReplicaSet "my-dep-5b7868d854" has successfully progressed.
reason: NewReplicaSetAvailable
status: "True"
type: Progressing
- lastTransitionTime: "2022-09-14T12:05:58Z"
lastUpdateTime: "2022-09-14T12:05:58Z"
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
observedGeneration: 3
readyReplicas: 3
replicas: 3
updatedReplicas: 3pod滚动更新
bash
[root@k8s-master ~]# kubectl get pod -w
NAME READY STATUS RESTARTS AGE
my-dep-5b7868d854-4blfx 1/1 Running 1 22h
my-dep-5b7868d854-4phcv 1/1 Running 1 21h
my-dep-5b7868d854-9kmm9 1/1 Running 1 22h
[root@k8s-master ~]# kubectl set image deploy/my-dep nginx=nginx:1.16.1 --record
deployment.apps/my-dep image updated
[root@k8s-master ~]# kubectl get pod -w
NAME READY STATUS RESTARTS AGE
my-dep-5b7868d854-4blfx 1/1 Running 1 22h
my-dep-5b7868d854-4phcv 1/1 Running 1 22h
my-dep-5b7868d854-9kmm9 1/1 Running 1 22h
my-dep-6b48cbf4f9-pqv85 0/1 Pending 0 0s
my-dep-6b48cbf4f9-pqv85 0/1 Pending 0 0s
my-dep-6b48cbf4f9-pqv85 0/1 ContainerCreating 0 0s
my-dep-6b48cbf4f9-pqv85 0/1 ContainerCreating 0 0s
my-dep-6b48cbf4f9-pqv85 1/1 Running 0 24s
my-dep-5b7868d854-4blfx 1/1 Terminating 1 22h
my-dep-6b48cbf4f9-8skqp 0/1 Pending 0 0s
my-dep-6b48cbf4f9-8skqp 0/1 Pending 0 0s
my-dep-6b48cbf4f9-8skqp 0/1 ContainerCreating 0 0s
my-dep-5b7868d854-4blfx 1/1 Terminating 1 22h
my-dep-6b48cbf4f9-8skqp 0/1 ContainerCreating 0 1s
my-dep-5b7868d854-4blfx 0/1 Terminating 1 22h
my-dep-5b7868d854-4blfx 0/1 Terminating 1 22h
my-dep-5b7868d854-4blfx 0/1 Terminating 1 22h
my-dep-6b48cbf4f9-8skqp 1/1 Running 0 17s
my-dep-5b7868d854-9kmm9 1/1 Terminating 1 22h
my-dep-6b48cbf4f9-d8pgs 0/1 Pending 0 0s
my-dep-6b48cbf4f9-d8pgs 0/1 Pending 0 0s
my-dep-6b48cbf4f9-d8pgs 0/1 ContainerCreating 0 0s
my-dep-5b7868d854-9kmm9 1/1 Terminating 1 22h
my-dep-6b48cbf4f9-d8pgs 0/1 ContainerCreating 0 1s
my-dep-5b7868d854-9kmm9 0/1 Terminating 1 22h
my-dep-5b7868d854-9kmm9 0/1 Terminating 1 22h
my-dep-5b7868d854-9kmm9 0/1 Terminating 1 22h
my-dep-6b48cbf4f9-d8pgs 1/1 Running 0 17s
my-dep-5b7868d854-4phcv 1/1 Terminating 1 22h
my-dep-5b7868d854-4phcv 1/1 Terminating 1 22h
my-dep-5b7868d854-4phcv 0/1 Terminating 1 22h
my-dep-5b7868d854-4phcv 0/1 Terminating 1 22h
my-dep-5b7868d854-4phcv 0/1 Terminating 1 22h滚动回退
滚动回退建立在滚动更新之后,发现产品有Bug,需要撤回。
查看my-dep部署的历史纪录1、第一次是部署
2、第二次是升级命令
bash
[root@k8s-master ~]# kubectl set image deploy/my-dep nginx=nginx:1.16.1 --record
deployment.apps/my-dep image updated
[root@k8s-master ~]# kubectl rollout history deployment/my-dep
deployment.apps/my-dep
REVISION CHANGE-CAUSE
1 <none>
2 kubectl set image deploy/my-dep nginx=nginx:1.16.1 --record=true
#查看某个历史详情
kubectl rollout history deployment/my-dep --revision=2
#回滚(回到上次)
kubectl rollout undo deployment/my-dep
#回滚(回到指定版本)
[root@k8s-master ~]# kubectl rollout undo deploy/my-dep --to-revision=1
deployment.apps/my-dep rolled back
[root@k8s-master ~]# kubectl get deploy/my-dep -oyaml|grep image
f:imagePullPolicy: {}
f:image: {}
- image: nginx
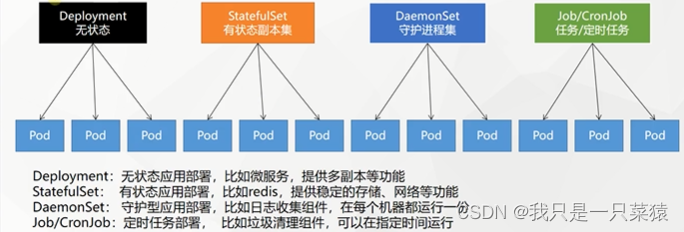
imagePullPolicy: Always微服务的应用都是无状态的,对于有状态的中间件Redis、Rabbitma。未来都不直接部署pod,虽然pod才是应用的载体。我们使用工作负载使用这些pod,这样让pod能够拥有比原先更强大的功能。
无状态(Deployment):应用挂了之后,无论何时被救起来都是一样的。启动之后ip就发生了变化
有状态(StatefulForSet):应用挂了之后,无论何时被就起来是不一样的。重启之后ip稳定,数据要挂载到外面,还要加载到原来的数据。提供了稳定的存储功能。
守护进程集(DaemonSet):比如集群中有十几台机器,每台机器都产生大量日志,为每台机器都驻留一个日志收集器,每台机器的日志收集器全部收集过来放到日志中心。
Job/CronJob(任务/定时任务):比如垃圾清理工作,可以在指定时间运行。
5、Service服务发现与负载均衡
将一组 Pods 公开为网络服务的抽象方法。
当前端访问Service时的时候,能够实现负载均衡的方式实现服务的访问。
暴漏服务:把deploy部署my-dep的pod的80端口的服务暴漏到service的8000端口上统一访问。
bash
## 删除暴漏的服务
[root@k8s-master ~]# kubectl delete service my-dep
[root@k8s-master ~]# kubectl expose deploy my-dep --port=8000 --target-port=80
service/my-dep exposed
## 查看服务,这个端口号只能在集群内访问的。
[root@k8s-master ~]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d4h
my-dep ClusterIP 10.96.12.62 <none> 8000/TCP 41s等同于;--type=ClusterIP暴露的ip只能在集群内访问
bash
```bash
kubectl expose deployment my-dep --port=8000 --target-port=80 --type=ClusterIP可以在外部访问的方式:通过32604端口访问
bash
[root@k8s-master ~]# kubectl expose deploy my-dep --port=8000 --target-port=80 --type=NodePort
service/my-dep exposed
[root@k8s-master ~]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d18h
my-dep NodePort 10.96.45.211 <none> 8000:32604/TCP 44s查看pod标签
bash
[root@k8s-master ~]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
my-dep-5b7868d854-2ts4b 1/1 Running 0 59m app=my-dep,pod-template-hash=5b7868d854
my-dep-5b7868d854-9nq7b 1/1 Running 0 59m app=my-dep,pod-template-hash=5b7868d854
my-dep-5b7868d854-jn4p2 1/1 Running 0 59m app=my-dep,pod-template-hash=5b7868d854通过配置文件的方式暴露服务:通过selector的label选择出来pod暴露服务的
yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: my-dep
name: my-dep
spec:
selector:
app: my-dep
ports:
- port: 8000
protocol: TCP
targetPort: 80使用tomcat创建模拟一个前端项目
bash
[root@k8s-master ~]# kubectl create deploy my-tomcat --image=tomcat
deployment.apps/my-tomcat createdtomcat容器内部想要访问我们的后台项目,写后台的ip地址。
域名方式
```bash
root@my-tomcat-b4c9b6565-zlssn:/usr/local/tomcat# curl 10.96.12.62:8000
root@my-tomcat-b4c9b6565-zlssn:/usr/local/tomcat# curl my-dep.default.svc:80006、Ingress 网关入口
service的统一网关入口。service是为一组pod服务提供一个统一集群内访问入口或外部访问的随机端口,而ingress做得是通过反射的形式对服务进行分发到对应的service上。
Ingress作为微服务的统一访问入口,将服务分配到不同的service节点。Ingress作为统一的入口,底层是nginx,根据不同的域名,交给不同的service。如order.service.com就交给orderservice.微服务之间的访问是应用层的事,应该也是走这一套的,这里属于基础设施
安装
bash
[root@k8s-master ~]# vi ingress.yaml
[root@k8s-master ~]# kubectl apply -f ingress.yaml
namespace/ingress-nginx created
serviceaccount/ingress-nginx created
configmap/ingress-nginx-controller created
clusterrole.rbac.authorization.k8s.io/ingress-nginx created
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx created
role.rbac.authorization.k8s.io/ingress-nginx created
rolebinding.rbac.authorization.k8s.io/ingress-nginx created
service/ingress-nginx-controller-admission created
service/ingress-nginx-controller created
deployment.apps/ingress-nginx-controller created
validatingwebhookconfiguration.admissionregistration.k8s.io/ingress-nginx-admission created
serviceaccount/ingress-nginx-admission created
clusterrole.rbac.authorization.k8s.io/ingress-nginx-admission created
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created
role.rbac.authorization.k8s.io/ingress-nginx-admission created
rolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created
job.batch/ingress-nginx-admission-create created
job.batch/ingress-nginx-admission-patch created
[root@k8s-master ~]# kubectl get pod -n ingress-nginx
NAME READY STATUS RESTARTS AGE
ingress-nginx-admission-create-bc4wd 0/1 Completed 0 3m29s
ingress-nginx-admission-patch-rc2fq 0/1 Completed 0 3m29s
ingress-nginx-controller-65bf56f7fc-r286m 1/1 Running 0 3m29singress作为统一入口,必须有一个端口接所有的流量,也就安装形成后会形成一个服务。如下是以NodePort 方式暴漏的端口,共暴漏了两个端口。
http://xxx.xxx.xxx.xxx:31081
https://xxx.xxx.xxx.xxx:31292
80:31081/TCP,443:31292/TCP
bash
[root@k8s-master ~]# kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller NodePort 10.96.178.133 <none> 80:31081/TCP,443:31292/TCP 4m34s
ingress-nginx-controller-admission ClusterIP 10.96.91.167 <none> 443/TCP 4m34s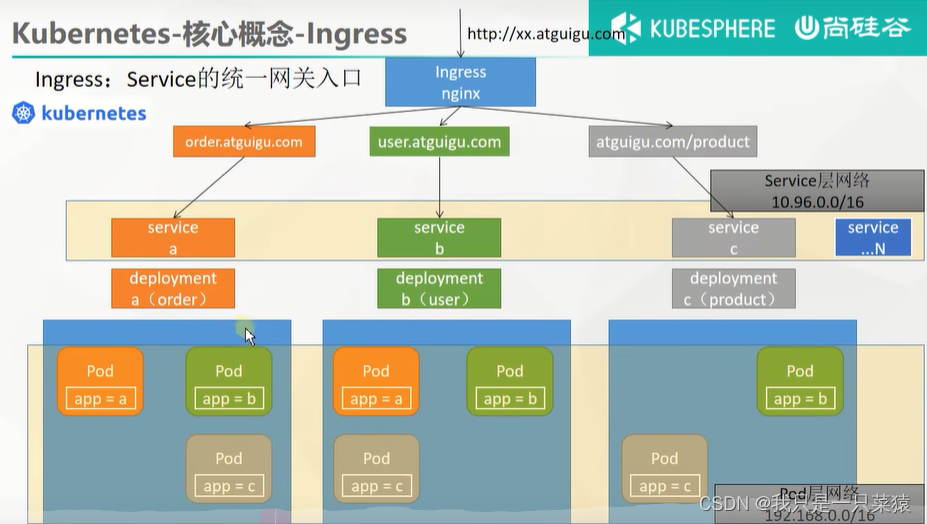
使用ingress
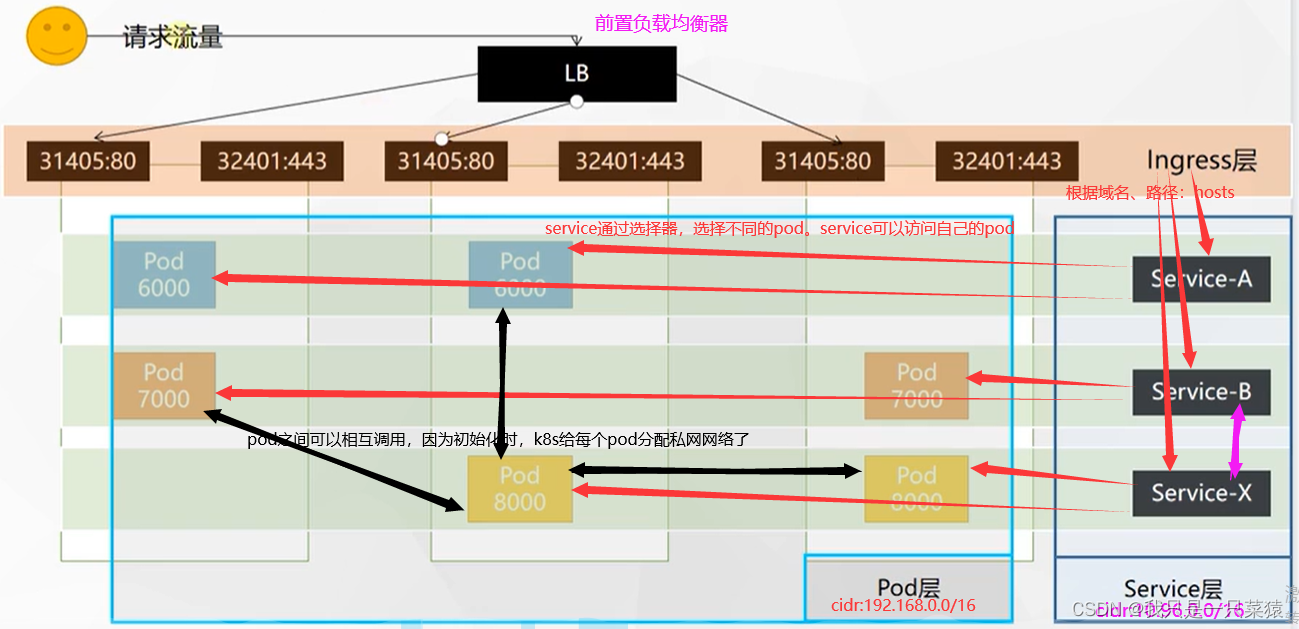
请求的流量可以请求到任意节点上,因为每个节点都放开了这两个端口。所以我们叫端口这一层叫ingress层。ingress层的目的就是所有进来的流量都经过我处理。
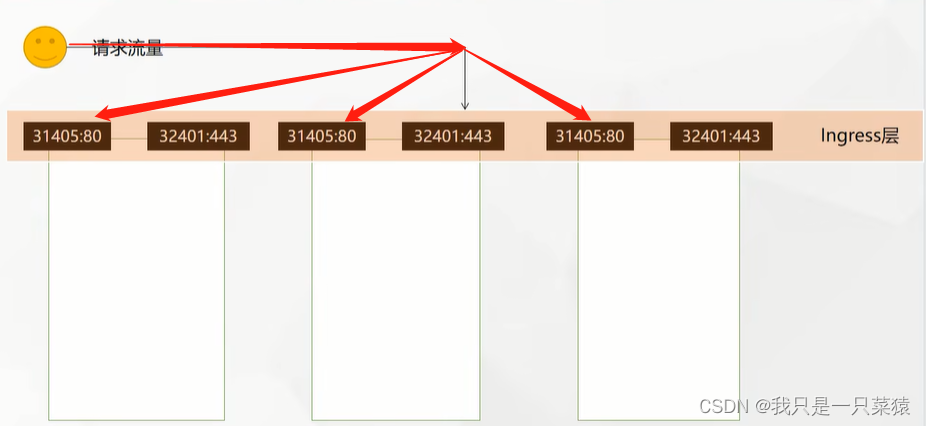
- yaml中部署了一次部署,名字叫做hello-server,有两个副本(pod),用了一个镜像叫做hello-server,工作端口是9000
- 另外又做了一个demo,2个副本,使用nginx镜像,镜像叫做nginx-demo,这次部署的工作端口号是80
- 还部署了服务,负载均衡网络,选中(管理)了标签app为nginx-demo的pod,名称name为nginx-demo,工作端口号是8000,代理端口号target-port是80,采用的协议是TCP
- 另外一个服务选中(管理)了标签为hello-server的pod,名称name为hello-server,工作端口号是8000,代理端口号target-port是9000,采用的协议是TCP
如果想访问pod,就访问管理pod的服务就可以了。采用哪种方式访问呢,采用服务名+端口号的访问即可,比如:hello-server:8000或nginx-demo:8000,就可以实现访问pod。
```bash
[root@k8s-master ~]# kubectl apply -f test.yaml
deployment.apps/hello-server created
deployment.apps/nginx-demo created
service/nginx-demo created
service/hello-server created
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-server
spec:
replicas: 2
selector:
matchLabels:
app: hello-server
template:
metadata:
labels:
app: hello-server
spec:
containers:
- name: hello-server
image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/hello-server
ports:
- containerPort: 9000
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-demo
name: nginx-demo
spec:
replicas: 2
selector:
matchLabels:
app: nginx-demo
template:
metadata:
labels:
app: nginx-demo
spec:
containers:
- image: nginx
name: nginx
---
apiVersion: v1
kind: Service
metadata:
labels:
app: nginx-demo
name: nginx-demo
spec:
selector:
app: nginx-demo
ports:
- port: 8000
protocol: TCP
targetPort: 80
---
apiVersion: v1
kind: Service
metadata:
labels:
app: hello-server
name: hello-server
spec:
selector:
app: hello-server
ports:
- port: 8000
protocol: TCP
targetPort: 9000通过在内网访问该端口的返回结果
bash
[root@k8s-master ~]# kubectl get svc -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default hello-server ClusterIP 10.96.114.8 <none> 8000/TCP 18m
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 3d4h
default my-dep NodePort 10.96.45.211 <none> 8000:32604/TCP 9h
default nginx-demo ClusterIP 10.96.218.222 <none> 8000/TCP 18m
[root@k8s-node1 ~]# curl 10.96.114.8:8000
Hello World!当前部署的两个部署和两个服务的代理关系如下图所示:
- 产生了四个pod,两个service.
- 相当于hello-server部署的两个pod会有一个hello-server的负载均衡的service
- 相当于nginx-demo部署的两个pod会有一个nginx-demo的负载均衡的service
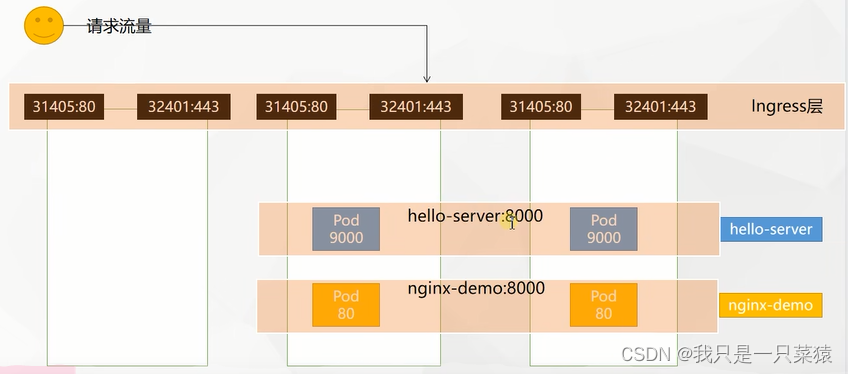
需求是:如果hello.atguigu.com:31405的服务转发给hello.server,如果是demo.atguigu.com:31405把请求转发给nginx-demo。下面的域名访问实现这个需求:
域名访问:创建ingress
host: "hello.atguigu.com"表示hello.atguigu.com下的所有请求,pathType是前置匹配,path表示什么路径:当前表示所有请求转发到service下,转发到哪个服务呢,name:hello-service,端口号是8000的服务。
这样就实现了将域名+资源路径的请求映射到了对应的backend服务上,服务又代理了pod。实现了整条连的映射。
yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-host-bar
spec:
ingressClassName: nginx
rules:
- host: "hello.atguigu.com"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: hello-server
port:
number: 8000
- host: "demo.atguigu.com"
http:
paths:
- pathType: Prefix
path: "/nginx" # 把请求会转给下面的服务,下面的服务一定要能处理这个路径,不能处理就是404
backend:
service:
name: nginx-demo ## java,比如使用路径重写,去掉前缀nginx
port:
number: 8000 报错问题处理及创建ingress
bash
[root@k8s-master ~]# kubectl apply -f ingress-rule.yaml
Error from server (InternalError): error when creating "ingress-rule.yaml": Internal error occurred: failed calling webhook "validate.nginx.ingress.kubernetes.io": Post "https://ingress-nginx-controller-admission.ingress-nginx.svc:443/networking/v1beta1/ingresses?timeout=10s": context deadline exceeded
[root@k8s-master ~]# kubectl get validatingwebhookconfigurations
NAME WEBHOOKS AGE
ingress-nginx-admission 1 72m
[root@k8s-master ~]# kubectl delete -A ValidatingWebhookConfiguration ingress-nginx-admission
validatingwebhookconfiguration.admissionregistration.k8s.io "ingress-nginx-admission" deleted
[root@k8s-master ~]# kubectl apply -f ingress-rule.yaml
ingress.networking.k8s.io/ingress-host-bar created域名访问:创建ingress
察看部署成功的ingress:匹配两个域名(hello.atguigu.com,demo.atguigu.com)
bash
[root@k8s-master ~]# kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
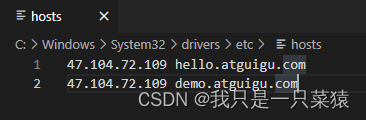
ingress-host-bar nginx hello.atguigu.com,demo.atguigu.com 172.26.1这两个域名要抵达任意一台的http://:31081或者https://:31292两个端口(ingress管理的端口)

在window的域名文件下输入以下映射,即可实现域名访问服务器ip。

ingress的修改
修改ingress的端口映射:从dermo.atguigu.com ==>demo.atguigu.com:31405/ingress
bash
[root@k8s-master ~]# kubectl get ing
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress-host-bar nginx hello.atguigu.com,demo.atguigu.com 172.26.163.33 80 22h
[root@k8s-master ~]# kubectl edit ing ingress-host-bar
ingress.networking.k8s.io/ingress-host-bar edited
yaml
- host: demo.atguigu.com
http:
paths:
- backend:
service:
name: nginx-demo
port:
number: 8000
path: /nginx
pathType: Prefix修改之后:ingress层的返回
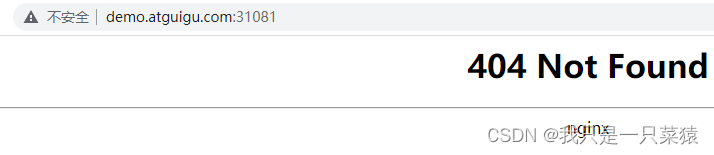
修改之后:部署的pod的返回
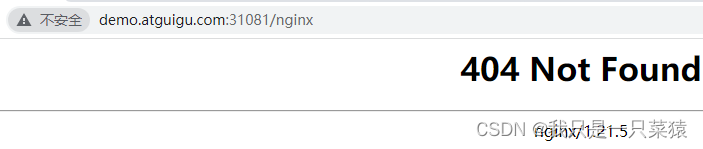
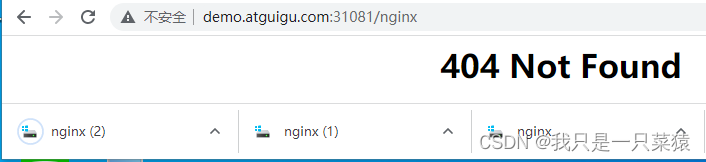
负载均衡测试
在任意nginx-demo容器中的静态文件目录,增加了一个nginx文件,此时再去访问demo.atguigu.com:31081时,就会下载增加的nginx文件。
网关路径重写
重新编辑ingress有两种方式可以编辑yaml,然后apply一下,或者采用kubectl edit 命令。
bash
## kubectl edit ing ingress-host-bar
[root@k8s-master ~]# vi ingress-rule.yaml
[root@k8s-master ~]# kubectl apply -f ingress-rule.yaml
ingress.networking.k8s.io/ingress-host-bar configured
yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /$2
name: ingress-host-bar
spec:
ingressClassName: nginx
rules:
- host: "hello.atguigu.com"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: hello-server
port:
number: 8000
- host: "demo.atguigu.com"
http:
paths:
- pathType: Prefix
path: "/nginx(/|$)(.*)" # 把请求会转给下面的服务,下面的服务一定要能处理这个路径,不能处理就是404
backend:
service:
name: nginx-demo ## java,比如使用路径重写,去掉前缀nginx
port:
number: 8000现在的结果是:访问了nginx的主页。原因是路径的重写将访问路径做了重定向,当访问31081/nginx时,将请求转发到了nginx的静态资源目录.user/share/nginx/html/下的根目录下,相当于31081/nginx是一个虚路径,nginx后的路径才是真正的要访问的资源路径。这就是路径重写
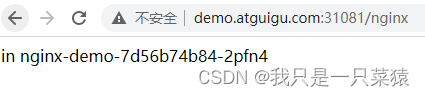
这样写是下载负载均衡测试中的=创建的nginx文件
流量限制
需求:当访问limit..atguigu.com时做一个流量控制。
Exact表示精确模式,表示当访问/是才做限流控制
bash
## 创建了一个限流的ingress
[root@k8s-master ~]# vi ingress-rule-limit.yaml
[root@k8s-master ~]# kubectl apply -f ingress-rule-limit.yaml
ingress.networking.k8s.io/ingress-limit-rate created添加ip映射:
yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-limit-rate
annotations:
nginx.ingress.kubernetes.io/limit-rps: "1"
spec:
ingressClassName: nginx
rules:
- host: "limit.atguigu.com"
http:
paths:
- pathType: Exact
path: "/"
backend:
service:
name: nginx-demo
port:
number: 8000测试结果:间歇性的不可访问界面。

最然做了限流处理,但是还是能将请求青映射到4个pod上,能够返回pod内的内容。因为limit没有做重定向,所以通过limit的url访问url时,无法下载nginx文件
网络模型
存储抽象
docker 方式的挂载在外面便于修改数据
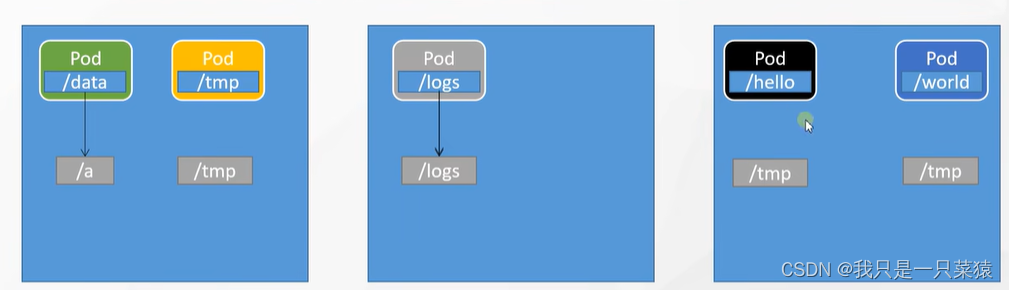
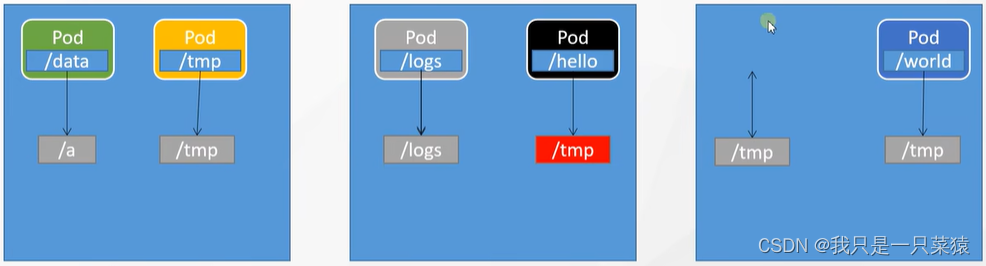
存在问题:k8s中,如果仍旧采用这种模式,如果pod宕机了,在另外一个pod上重启一个pod,所挂在的新的pod/tmp时没有数据的,就存在数据不一致的问题。而且数据量庞大的问题也很难解决
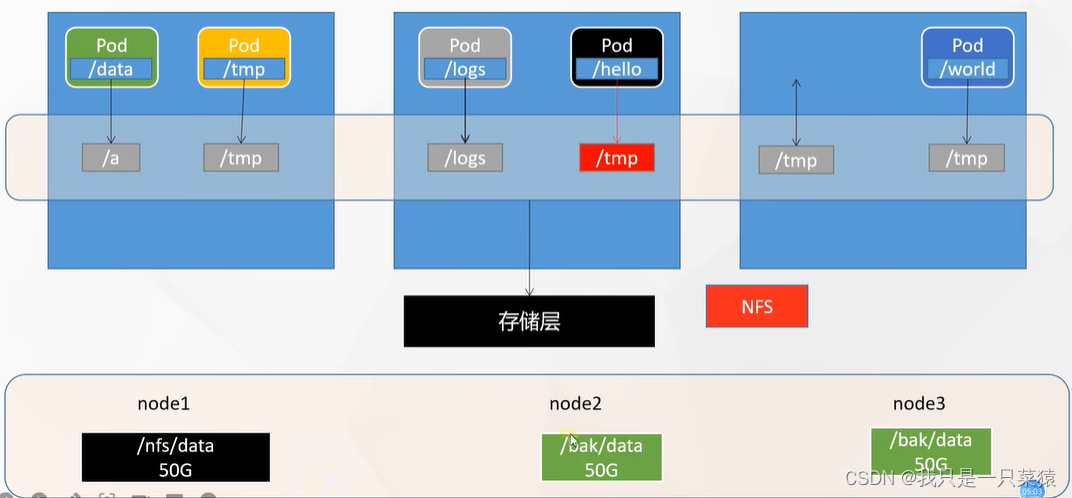
问题解决方案:存储层现在交给k8s存储层了,如果需要挂载什么数据,直接找k8s。即使pod宕机也能再次将pod关联到重启的pod上。k8s在存储层可以采用不同的方案,比如NFS(网络存储系统),是将文件统一管理到一处,同时会做一个数文件的备份目录,备份目录之间会做文件的同步更新,防止存储层炸了后数据的丢失。所以任意一个节点的数据是同步的。
搭建NFS网络文件存储系统
指定任意一台机器为NFS Server,比如指定K8S master为Server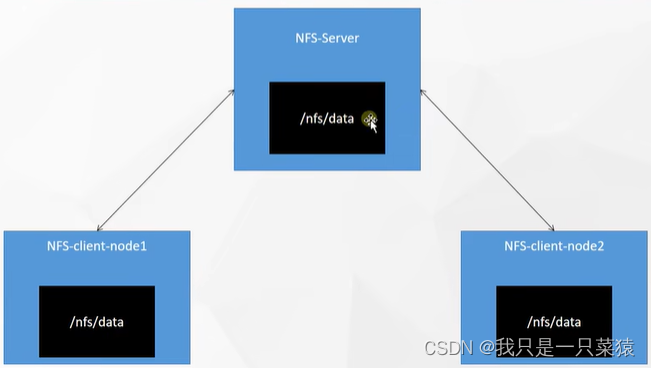
bash
#所有机器安装
yum install -y nfs-utils主节点
指定暴露目录/nfs/data/,并且以非安全的方式进行暴露,独写的方式进行同步
bash
## 在master节点暴漏一个nfs目录
[root@k8s-master ~]# echo "/nfs/data/ *(insecure,rw,sync,no_root_squash)" > /etc/exports
[root@k8s-master ~]# mkdir /nfs/data
[root@k8s-master ~]# mkdir -p /nfs/data
## rpc远程同步调用的服务。
[root@k8s-master ~]# systemctl enable rpcbind --now
## 开机启动nfs服务器
[root@k8s-master ~]# systemctl enable nfs-server --now
Created symlink from /etc/systemd/system/multi-user.target.wants/nfs-server.service to /usr/lib/systemd/system/nfs-server.service.
[root@k8s-master ~]# exportfs -r
# 检查nfs服务器是否设置正确路径
[root@k8s-master ~]# exportfs
/nfs/data <world>让其他节点同步NFS
任何一个节点对文件修改,都会同步。
bash
## 使用私有网卡的地址。ip a的eth0
## 检查命令
[root@k8s-node1 ~]# showmount -e 172.26.163.34
Export list for 172.26.163.34:
/nfs/data *
#执行以下命令挂载 nfs 服务器上的共享目录到本机路径 /root/nfsmount
mkdir -p /nfs/data
## 挂在同步master中的内容。远程服务器的ip:目录:172.26.163.34:/nfs/data
mount -t nfs 172.26.163.34:/nfs/data /nfs/data
# 写入一个测试文件
echo "hello nfs server" > /nfs/data/test.txt原生方式挂载数据
名字为nginx的pod,内部的mountPath: /usr/share/nginx/html目录,映射到服务器的/nfs/data/nginx-pv目录
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-pv-demo
name: nginx-pv-demo
spec:
replicas: 2
selector:
matchLabels:
app: nginx-pv-demo
template:
metadata:
labels:
app: nginx-pv-demo
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
volumes:
- name: html
nfs:
server: 172.26.163.34
path: /nfs/data/nginx-pv部署nginx文件绑定的pod
bash
[root@k8s-master ~]# vi deploy.yaml
[root@k8s-master ~]# kubectl apply -f deploy.yaml
deployment.apps/nginx-pv-demo created
[root@k8s-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
hello-server-6cbb679d85-m5nsc 1/1 Running 2 43h
hello-server-6cbb679d85-pcrnj 1/1 Running 2 43h
my-dep-5b7868d854-2ts4b 1/1 Running 4 2d19h
my-dep-5b7868d854-kmw8g 1/1 Running 3 2d5h
my-dep-5b7868d854-wrp6f 1/1 Running 3 2d5h
my-tomcat-b4c9b6565-zlssn 1/1 Running 4 2d18h
nginx-demo-7d56b74b84-2pfn4 1/1 Running 2 43h
nginx-demo-7d56b74b84-n4gff 1/1 Running 2 43h
nginx-pv-demo-8699c67f95-95wd6 0/1 ContainerCreating 0 13s
nginx-pv-demo-8699c67f95-kdv5j 0/1 ContainerCreating 0 13s
bash
### 当在主节点向index.html输入11112222后,在任意容器中都能看到输入的数据。
root@nginx-pv-demo-8699c67f95-95wd6:/# cd /usr/share/nginx/html/
root@nginx-pv-demo-8699c67f95-95wd6:/usr/share/nginx/html# ls
index.html
root@nginx-pv-demo-8699c67f95-95wd6:/usr/share/nginx/html# cat index.html
11112222
root@nginx-pv-demo-8699c67f95-95wd6:/usr/share/nginx/html# PV/PVC
原生方式存在的问题:①每个pod内的挂载的目录需要手动创建②当部署被删除后,文件未删除③每个pod所使用的目录文件的大小未做限制。
PV:持久卷(Persistent Volume),将应用需要持久化的数据保存到指定位置。空间
PVC:持久卷申明(Persistent Volume Claim),申明需要使用的持久卷规格。如果pod想挂载数据了,在pod上写一个申请书(PVC),按照合适的PV池给pod分配空间。避免空间的浪费。如果pod删除了,连带着pod所挂载的pvc也可以被删除,pvc中的pv也就被删除了。如果pvc未被删除,pv空间不会被删除。
PV池:需要多少空间,先声明好,提前供应规划好,形成一个池。而不是需要多少空间我动态创建。
PV的回收策略:①保留,该策略允许手动回收资源,当删除PVC时,PV仍然存在,PV被视为已释放,管理员可以手动回收卷。②删除,如果Volume插件支持,删除PVC时会同时删除PV,动态卷默认为Delete,目前支持Delete的存储后端包括AWS EBS。③回收。可以被PVC重复使用。rm-rf 清理该PV
bash啊发[root@k8s-master
index.html
[root@k8s-master nginx-pv]# cd ~
[root@k8s-master ~]# kubectl delete -f deploy.yaml
deployment.apps "nginx-pv-demo" deleted
[root@k8s-master ~]# cd /nfs/data/
[root@k8s-master data]# cd ./nginx-pv/
[root@k8s-master nginx-pv]# ls
index.htl- 创建pv池
bash
#nfs主节点
mkdir -p /nfs/data/01
mkdir -p /nfs/data/02
mkdir -p /nfs/data/03- 创建pv
---分隔符
kind: PersistentVolume 类型是PV
capacity:storage: 10M 限制文件的大小
yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv01-10m
spec:
capacity:
storage: 10M
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/01
server: 172.26.163.34
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv02-1gi
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/02
server: 172.26.163.34
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv03-3gi
spec:
capacity:
storage: 3Gi
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/03
server: 172.26.163.34
bash
[root@k8s-master ~]# kubectl apply -f pv.yaml
persistentvolume/pv01-10m created
persistentvolume/pv02-1gi created
persistentvolume/pv03-3gi created
[root@k8s-master ~]# kubectl get persistentvolume
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv01-10m 10M RWX Retain Available nfs 2m27s
pv02-1gi 1Gi RWX Retain Available nfs 2m27s
pv03-3gi 3Gi RWX Retain Available nfs 2m27s
[root@k8s-master ~]# vi pvc.yaml
[root@k8s-master ~]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv01-10m 10M RWX Retain Available nfs 8m22s
pv02-1gi 1Gi RWX Retain Available nfs 8m22s
pv03-3gi 3Gi RWX Retain Available nfs 8m22s
[root@k8s-master ~]# kubectl apply -f pvc.yaml
persistentvolumeclaim/nginx-pvc created
## c创建好后,就被绑定了。
[root@k8s-master ~]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv01-10m 10M RWX Retain Available nfs 8m56s
pv02-1gi 1Gi RWX Retain Bound default/nginx-pvc nfs 8m56s
pv03-3gi 3Gi RWX Retain Available nfs 8m56s- pvc创建与绑定
storageClassName要和上面的storageClassName保持一致。在storageClassName下找一个合适的空间
bash
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: nginx-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 200Mi
storageClassName: nfs- pvc删除
删除后处于Released,空间还未完全释放。此时如果再申请空间,会分配其他的空间。pv02-1gi会一直处于Released状态,需要编辑pv02-1gi资源,删除claimRef段落就可以变成可用了
bash
[root@k8s-master ~]# kubectl delete -f pvc.yaml
persistentvolumeclaim "nginx-pvc" deleted
[root@k8s-master ~]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv01-10m 10M RWX Retain Available nfs 10m
pv02-1gi 1Gi RWX Retain Released default/nginx-pvc nfs 10m
pv03-3gi 3Gi RWX Retain Available nfs 10m
[root@k8s-master ~]# kubectl apply -f pvc.yaml
persistentvolumeclaim/nginx-pvc created
[root@k8s-master ~]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv01-10m 10M RWX Retain Available nfs 15m
pv02-1gi 1Gi RWX Retain Released default/nginx-pvc nfs 15m
pv03-3gi 3Gi RWX Retain Bound default/nginx-pvc nfs 15m
[root@k8s-master ~]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
nginx-pvc Bound pv03-3gi 3Gi RWX nfs 74s- 通过PC创建绑定pod
我要用的空间是这个空间申请书的空间。
bash
[root@k8s-master ~]# vi dep02.yaml
[root@k8s-master ~]# kubectl apply -f dep02.yaml
deployment.apps/nginx-deploy-pvc created
[root@k8s-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
hello-server-6cbb679d85-m5nsc 1/1 Running 2 44h
hello-server-6cbb679d85-pcrnj 1/1 Running 2 44h
my-dep-5b7868d854-2ts4b 1/1 Running 4 2d21h
my-dep-5b7868d854-kmw8g 1/1 Running 3 2d6h
my-dep-5b7868d854-wrp6f 1/1 Running 3 2d6h
my-tomcat-b4c9b6565-zlssn 1/1 Running 4 2d20h
nginx-demo-7d56b74b84-2pfn4 1/1 Running 2 44h
nginx-demo-7d56b74b84-n4gff 1/1 Running 2 44h
nginx-deploy-pvc-79fc8558c7-2fz2z 1/1 Running 0 6s
nginx-deploy-pvc-79fc8558c7-x82v5 0/1 ContainerCreating 0 6s
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-deploy-pvc
name: nginx-deploy-pvc
spec:
replicas: 2
selector:
matchLabels:
app: nginx-deploy-pvc
template:
metadata:
labels:
app: nginx-deploy-pvc
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
volumes:
- name: html
persistentVolumeClaim:
claimName: nginx-pvc- pod,pvc,pv关系
pvc的状态是Bound,说明有pod绑定这个pvc。pvc跟volume(pv03-3gi)绑定了。pv中的pv03-3gi中的目录下就是数据
bash
[root@k8s-master ~]# kubectl get pvc,pv
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/nginx-pvc Bound pv03-3gi 3Gi RWX nfs 8m9s
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pv01-10m 10M RWX Retain Available nfs 23m
persistentvolume/pv02-1gi 1Gi RWX Retain Released default/nginx-pvc nfs 23m
persistentvolume/pv03-3gi 3Gi RWX Retain Bound default/nginx-pvc nfs 23m- 静态供应:pvc需要空间只能从pv池中选择
- 动态供应:pv会在一个地方自动的创建一个想要空间大小的空间。不需要手动创建好了
ConfigMap 配置文件挂载
- 创建ConfigMap 创建的配置集实际上是在etcd中存着
bash
[root@k8s-master 03]# vi redis.conf
[root@k8s-master 03]# kubectl create cm redis-conf --from-file=redis.conf
configmap/redis-conf created
[root@k8s-master 03]# kubectl get cm
NAME DATA AGE
kube-root-ca.crt 1 5d
redis-conf 1 9s
[root@k8s-master 03]# rm -rf redis.conf 查看数据集内容
data:key | configContent 。key是文件名。
bash
[root@k8s-master 03]# kubectl get cm redis-conf -oyaml
apiVersion: v1
data:
redis.conf: |
appendonly yes
kind: ConfigMap
metadata:
creationTimestamp: "2022-09-17T11:12:02Z"
managedFields:
- apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
f:data:
.: {}
f:redis.conf: {}
manager: kubectl-create
operation: Update
time: "2022-09-17T11:12:02Z"
name: redis-conf
namespace: default
resourceVersion: "141413"
uid: 6e1eeba3-ef19-42ee-bb52-4bd38d592e89- 使用配置集中的内容创建pod
bash
[root@k8s-master ~]# kubectl apply -f redis.yaml
pod/redis created
[root@k8s-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
hello-server-6cbb679d85-m5nsc 1/1 Running 2 45h
hello-server-6cbb679d85-pcrnj 1/1 Running 2 45h
my-dep-5b7868d854-2ts4b 1/1 Running 4 2d22h
my-dep-5b7868d854-kmw8g 1/1 Running 3 2d7h
my-dep-5b7868d854-wrp6f 1/1 Running 3 2d7h
my-tomcat-b4c9b6565-zlssn 1/1 Running 4 2d21h
nginx-demo-7d56b74b84-2pfn4 1/1 Running 2 45h
nginx-demo-7d56b74b84-n4gff 1/1 Running 2 45h
nginx-deploy-pvc-79fc8558c7-2fz2z 1/1 Running 0 55m
nginx-deploy-pvc-79fc8558c7-x82v5 1/1 Running 0 55m
redis 1/1 Running 0 16scommand 是启动命令,/redis-master/redis.conf是指容器内部的位置。volumeMounts指卷挂载,共挂载了两个:
①名字为data的挂载,容器内目录是/data,映射的宿主机目录是/redis-master。下面volumes下名为data做了详细说明。volumes下empty:{}空的工作目录。
②名为config的配置集。映射的宿主机目录是/redis-master,在volume中详细说明。映射给configMap,configMap中通过name(redis-conf)映射到了cm中名为redis-conf的cm配置。又通过item中的redis.conf映射到redis.conf的配置。path表示mountPath下的子路径。
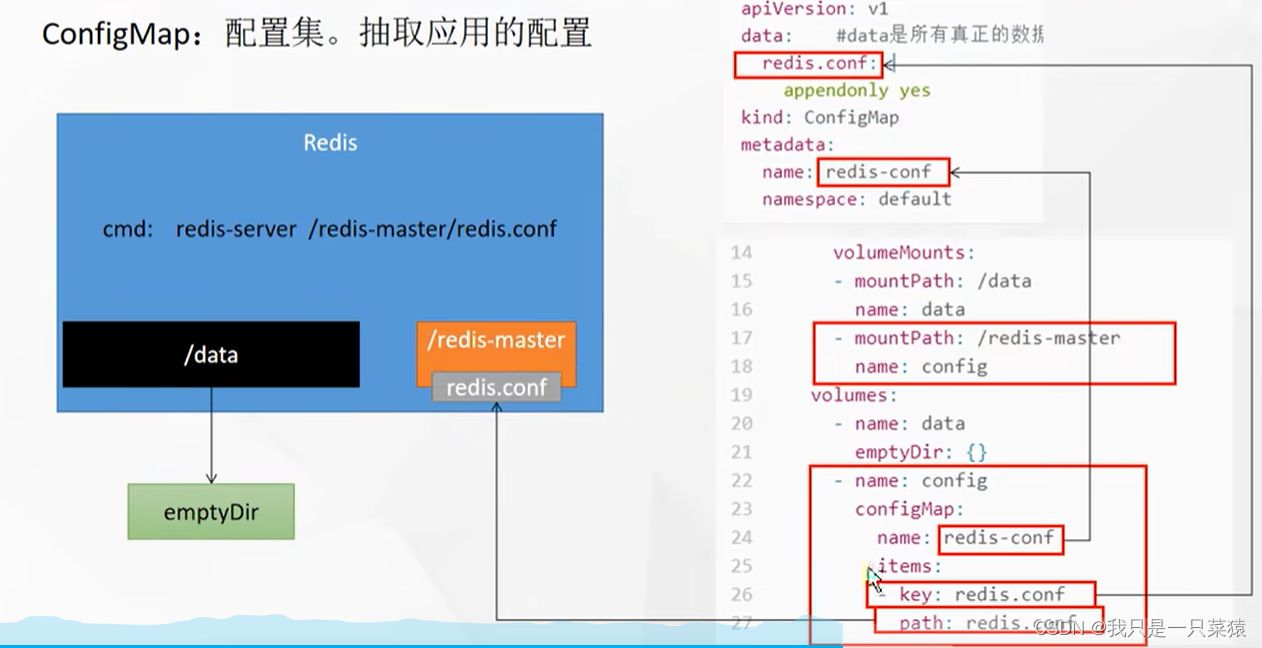
yaml
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
command:
- redis-server
- "/redis-master/redis.conf" #指的是redis容器内部的位置
ports:
- containerPort: 6379
volumeMounts:
- mountPath: /data
name: data
- mountPath: /redis-master
name: config
volumes:
- name: data
emptyDir: {}
- name: config
configMap:
name: redis-conf
items:
- key: redis.conf
path: redis.conf容器中查看
bash
root@redis:/data# cd /redis-master/redis.conf
bash: cd: /redis-master/redis.conf: Not a directory
root@redis:/data# cd /redis-master/
root@redis:/redis-master# cat redis.conf
appendonly yes- 编辑redis配置文件
在外面把配置文件改了,容器内部会跟着改变。cm改了之后容器内部也会跟着改。此时重启pod密码就会生效。
配置值未更改,因为需要重新启动 Pod 才能从关联的 ConfigMap 中获取更新的值。
原因:我们的Pod部署的中间件自己本身没有热更新能力
bash
[root@k8s-master ~]# kubectl get cm
NAME DATA AGE
kube-root-ca.crt 1 5d1h
redis-conf 1 42m
[root@k8s-master ~]# kubectl edit cm redis-conf
configmap/redis-conf edited
root@redis:/redis-master# cat redis.conf
appendonly yes
requirepass Test1127?!
root@redis:/redis-master#
[root@k8s-master ~]# kubectl exec -it redis -- redis-cli
127.0.0.1:6379> CONFIG GET appendonly
1) "appendonly"
2) "yes"
127.0.0.1:6379> CONFIG GET requirepass
1) "requirepass"
2) ""7、Secret
Secret 对象类型用来保存敏感信息,例如密码、OAuth 令牌和 SSH 密钥。 将这些信息放在 secret 中比放在 Pod 的定义或者 容器镜像 中来说更加安全和灵活。
我们都是直接拉去共有镜像。
公司私有的镜像仓库:存放所有的写的微服务的jar包,如果从私有仓库拉取jar需要登陆。如果把登陆账号密码写到每个pod中,不安全。如果采用k8ssecret的方式把docker的账号密码保存起来,如果以后想拉取镜像时,直接拉取就可以了。
没有账号密码的情况下下载不下来
bash
[root@k8s-master ~]# docker pull xiaguangpei/java-demo:v1.0
Error response from daemon: pull access denied for xiaguangpei/java-demo, repository does not exist or may require 'docker login': denied: requested access to the resource is denied错误范例
bash
apiVersion: latest
kind: Pod
metadata:
name: xgpnginx
spec:
containers:
- name: xgpnginx
image: xiaguangpei/xgpnginx登陆私有账号
##命令格式
kubectl create secret docker-registry regcred
--docker-server=<你的镜像仓库服务器>
--docker-username=<你的用户名>
--docker-password=<你的密码>
--docker-email=<你的邮箱地址>
bash
[root@k8s-master ~]# kubectl create secret docker-registry xiaguangpei-docker \
> --docker-username=xiaguangpei \
> --docker-password=Test1127?! \
> --docker-email=987224389@qq.com
secret/xiaguangpei-docker createdbase64加密
bash
[root@k8s-master ~]# kubectl get secret
NAME TYPE DATA AGE
default-token-ntj7s kubernetes.io/service-account-token 3 5d2h
xiaguangpei-docker kubernetes.io/dockerconfigjson 1 44s
[root@k8s-master ~]# kubectl get secret xiaguangpei-docker -oyaml
apiVersion: v1
data:
.dockerconfigjson:
xxxxxxxxxxxxxxxxxxx
kind: Secret
metadata:
creationTimestamp: "2022-09-17T12:40:10Z"
managedFields:
- apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
f:data:
.: {}
f:.dockerconfigjson: {}
f:type: {}
manager: kubectl-create
operation: Update
time: "2022-09-17T12:40:10Z"
name: xiaguangpei-docker
namespace: default
resourceVersion: "149588"
uid: 81421418-5482-4c22-a045-924ebbddd78f
type: kubernetes.io/dockerconfigjson真正的拉取私有云的镜像的方法
bash
[root@k8s-master ~]# vi java-demo.yaml
[root@k8s-master ~]# kubectl apply -f java-demo.yaml
pod/java-demo created
yaml
apiVersion: v1.0
kind: Pod
metadata:
name: java-demo
spec:
containers:
- name: java-demo
image: xiaguangpei/java-demo:v1.0
imagePullSecrets:
- name: xiaguangpei-docker