一、限流算法概述
1. 核心概念
限流算法是用于控制请求处理速率、保护服务资源的标准化算法,是所有流量管控策略的底层核心。在大模型服务中,算法的作用不再是简单限制请求数量,而是精准管控GPU 算力、显存占用、推理并发、Token 消耗,避免服务因流量过载崩溃。
传统接口服务CPU、内存可弹性扩容,限流仅用于防攻击;但大模型推理依赖专用硬件GPU、NPU,单卡算力、显存固定不可扩容,一次长上下文推理会占用大量资源,瞬时高并发会直接导致显存溢出OOM问题、推理延迟飙升、服务宕机。因此漏桶、令牌桶这两种经典算法,是大模型限流体系的底层地基,所有租户限流、Token限流、流式限流都基于这两种算法扩展实现。

2. 核心定位
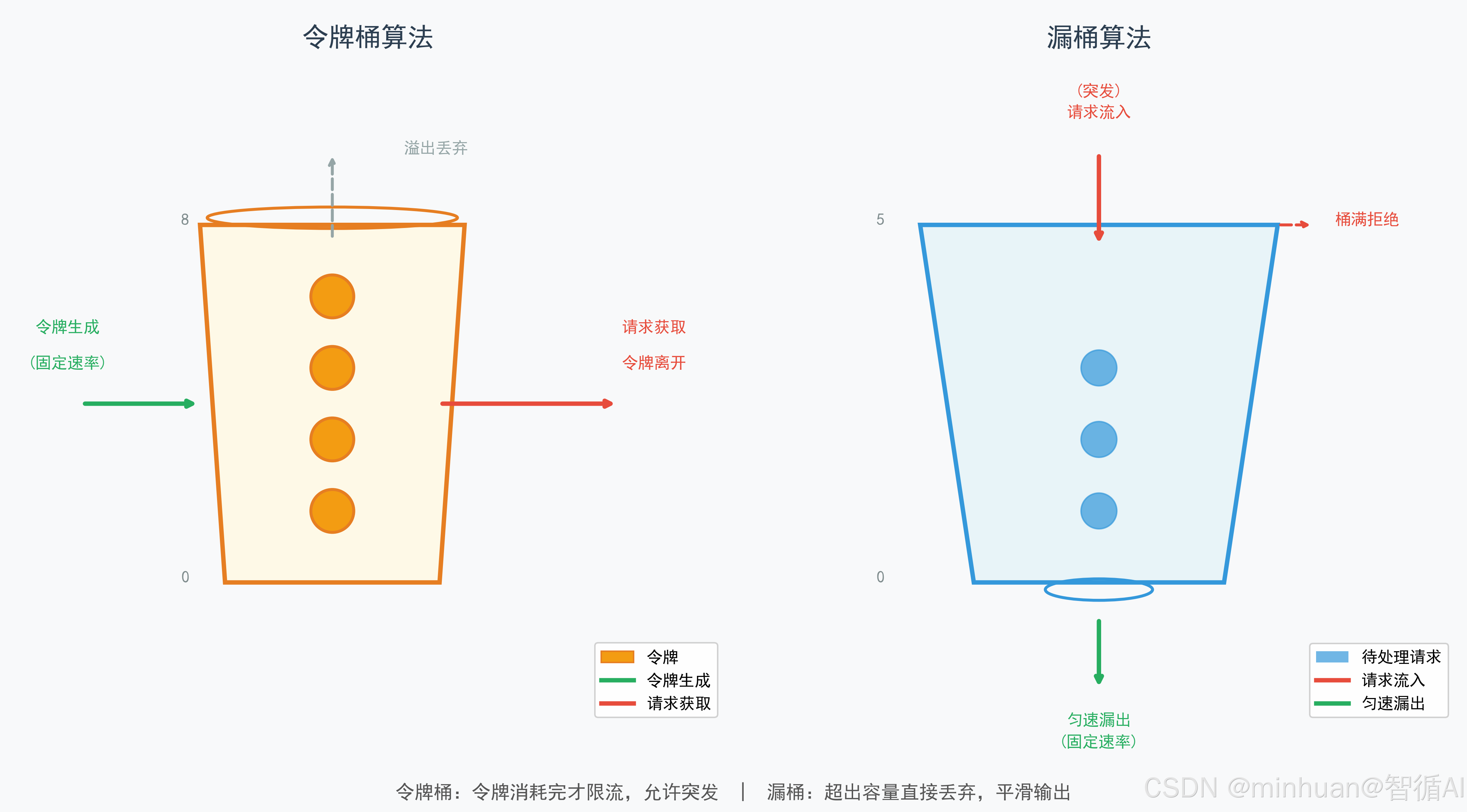
2.1 漏桶算法
强制匀速处理请求,绝对平滑流量,适合对算力稳定性要求极致的场景。漏桶的核心机制是"匀速漏水",无论外部请求(进水)多么汹涌,系统始终以固定的速率(漏水速率)处理任务。
- 这种机制能彻底消除流量尖峰,保护后端昂贵的GPU算力资源不被突发流量打垮。
- 它非常适合模型推理、批量生成等对响应时间要求不敏感,但必须保证算力负载绝对平稳的场景。
2.2 令牌桶算法
支持突发流量处理,兼顾平滑性与弹性,是工业级大模型服务的首选算法。令牌桶的核心机制是"积攒令牌",允许系统在空闲时积累令牌,从而在流量洪峰到来时一次性消耗,处理突发请求。
- 这种机制既限制了长期的平均请求速率,又保留了应对短时高并发的弹性。
- 它非常契合大模型API网关、用户交互式对话等场景,既能防止服务过载,又能保证用户在短时间内连续提问时的流畅体验。
3. 核心价值
- 硬件资源保护:通过固定速率限制,避免GPU瞬时满载、显存溢出,延长硬件使用寿命;
- 服务稳定性保障:无论外部流量如何波动,都能将推理请求的处理速度控制在硬件承载范围内;
- 推理体验均衡:防止部分请求抢占全部算力,保证所有合法请求都能获得稳定的推理延迟;
- 上层策略支撑:为租户隔离、Token限流、流式接口限流提供底层算法支持,实现精细化流量治理;
- 成本可控:避免无效高并发推理消耗算力资源,降低私有部署、云服务的算力成本。
二、漏桶算法
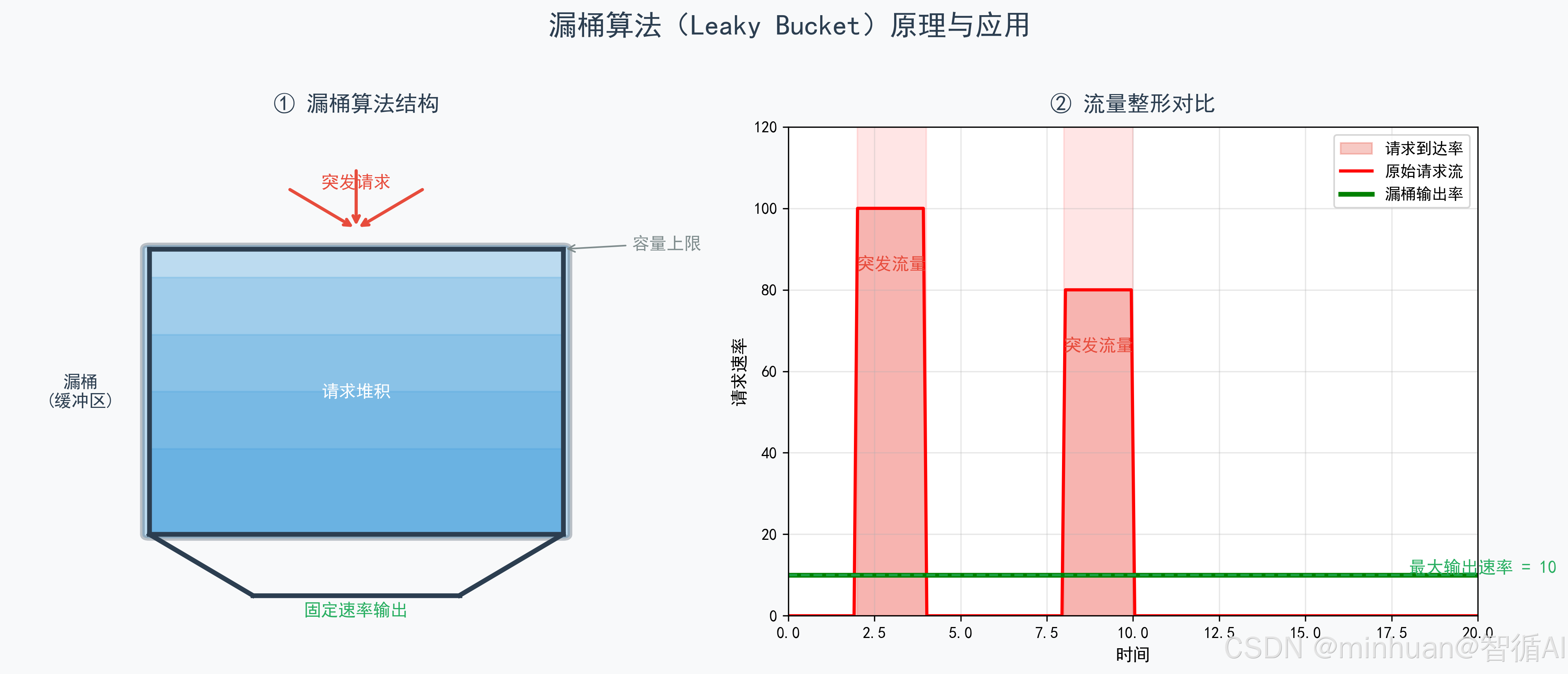
漏桶算法是一种强制输出速率恒定的流量整形方案。它将大模型请求视为流入固定容量水桶的水滴,无论上游请求如何突发,系统始终以预设的固定速率匀速"漏水"处理,可以通俗的理解为大模型静态流量平滑方案;
该算法能彻底消除流量尖峰,保护昂贵的GPU算力不被瞬时过载打垮,非常适合对算力稳定性要求极致的模型推理等场景。
1. 核心原理
漏桶算法的原理可以用带小孔的水桶完美类比:
- 水桶 = 等待处理的请求队列;
- 流入的水 = 用户发起的大模型推理请求,可以理解为流量;
- 桶底小孔 = 固定的推理处理速率;
- 漏水过程 = 大模型匀速执行推理;
- 水桶满溢 = 请求超出等待上限,直接被限流拒绝。
算法的核心规则:无论流入速度多快,流出速度永远固定。不会因为突发请求加快处理速度,从根源上杜绝算力瞬时过载。
2. 核心参数
针对大模型服务的漏桶算法,以下是核心技术参数的详细说明:
2.1 capacity:漏桶容量
代表系统允许的最大排队缓冲能力。在大模型推理场景中,它决定了最多能有多少个请求在队列中等待处理。
- 合理设置该值可以在拦截过载请求和保证一定吞吐量之间取得平衡;
- 若设置过大,可能会导致请求在队列中积压过久,增加整体的响应延迟。
2.2 rate:漏水速率
代表大模型服务处理请求的恒定吞吐量上限,例如每秒处理N个请求。
- 该参数通常需要根据底层GPU硬件的实际推理速度TPS来设定,强制将请求的处理速率稳定在系统可承载的安全范围内,从而彻底消除流量尖峰。
2.3 water:当前桶内水量
代表当前时刻正在排队、等待模型处理的请求总数。
- 系统通过实时对比water与capacity的大小来决定是否接纳新请求:
- 只要water小于capacity,新请求即可入队;
- 反之则触发限流,直接拒绝该请求。
2.4 last_time:上一次漏水的时间戳
记录系统上一次计算并扣除"漏出水量"的具体时间点。
- 在每次有新请求到达时,算法会结合当前时间与last_time的时间差,按固定速率推算出这段时间内应该处理掉漏出的请求数量,从而精准更新当前的water水位。
3. 执行流程

流程说明:
-
- 时间校准:请求到达时,计算当前时间与上一次处理的时间差,根据固定速率计算这段时间漏出的水量,即已处理的请求数;
-
- 水量更新:用当前水量减去漏出水量,得到实时等待请求数;
-
- 容量判断:如果等待请求数小于桶容量,允许请求入桶等待处理;
-
- 过载拒绝:如果等待请求数等于桶容量,直接拒绝请求,返回429限流响应;
-
- 匀速处理:桶内请求按照固定速率被大模型推理引擎消费,完成响应。
4. 算法特性
- 绝对流量平滑: 处理速率恒定,算力负载无波动,是最稳定的限流算法。
- 它能将不规则的突发流量整形为绝对平滑的匀速流,确保GPU等昂贵的算力资源始终处于平稳的负载水位,避免瞬时过载导致的显存溢出或服务崩溃。
- 无突发处理能力: 即使系统当前处于空闲状态,也无法快速处理突发的海量请求。
- 由于漏桶强制以固定速率"匀速漏水",无法像令牌桶那样利用空闲期积攒的额度来应对瞬时高峰,因此不适合对响应延迟极度敏感、需要应对突发并发的交互式业务。
- 无状态依赖: 仅需记录当前桶内水量,即排队请求数和上一次漏水的时间戳;
- 无需维护复杂的用户状态或历史窗口数据,内存占用极低,算法实现成本非常低,适合在资源受限的边缘设备或网关层快速部署。
- 无饥饿现象: 所有请求严格按照先进先出(FIFO)的原则排队等待,公平获取处理资源。
- 这种机制杜绝了某些高优先级或恶意请求抢占资源导致普通请求长时间无法被处理的情况,保证了服务调度的公平性。
5. 适用场景
- 私有部署大模型静态推理服务:适用于企业内部面向员工的固定流程服务,如夜间批量文档摘要、离线数据清洗等,这类场景流量相对平稳,无需应对突发,追求极致的算力利用率。
- 对算力稳定性要求极致的科研大模型:在材料科学、药物研发等工业领域,大模型往往需要长时间稳定运行以保障实验数据的连续性和准确性,漏桶算法能有效规避流量波动对精密计算任务的干扰。
- 长上下文大模型(128K+)推理:处理超长文本时,单次推理会占用极高的显存和计算资源。漏桶算法能严格控制并发请求数,防止因瞬时显存占用过高而触发OOM内存溢出错误,保障长文本任务的顺利执行。
- 低算力硬件或单卡小模型的流量防护:在普通显卡或边缘计算设备上部署轻量化模型时,硬件承载能力有限。漏桶算法能像一道坚固的水闸,将流入的请求严格限制在硬件的处理极限之内,防止低配硬件被瞬间打垮。
- 第三方大模型API调用代理:当企业作为中间层调用外部按次或按速率计费的第三方大模型API时,漏桶算法能确保发出的请求严格符合服务商的速率限制,避免因超频调用导致接口被封禁或产生额外费用。
6. 应用实践
以下示例主要体现漏桶算法在大模型限流中的应用:我们适配20个突发请求以每0.1秒1个的速率进入容量为5、速率2/s的漏桶,演示漏桶算法如何实现限流,保护后端系统不被突发流量冲垮,并将不均匀的流量整形为均匀输出,帮助理解如何将突发流量整形为均匀输出,防止后端服务被冲垮。
python
import time
import threading
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
class LeakyBucket4LLM:
def __init__(self, capacity: int, rate: float):
"""
漏桶算法(适配大模型限流)
:param capacity: 漏桶最大容量(最大等待推理请求数)
:param rate: 漏水速率(每秒处理的大模型请求数)
"""
self.capacity = capacity
self.rate = rate
self.water = 0 # 当前等待的请求数
self.last_time = time.time()
self.lock = threading.Lock() # 线程锁,保证高并发下数据安全
def allow_request(self) -> bool:
"""判断是否允许处理大模型推理请求"""
with self.lock:
now = time.time()
# 计算时间差,生成可漏出的水量
time_diff = now - self.last_time
leak_water = time_diff * self.rate
# 更新剩余水量(不能小于0)
self.water = max(0.0, self.water - leak_water)
self.last_time = now
# 桶未满:允许入队,水量+1
if self.water < self.capacity:
self.water += 1
return True
# 桶已满:拒绝请求
return False
# ==================== 漏桶算法可视化 ====================
def simulate_leaky_bucket(capacity: int, rate: float, request_times: list):
"""模拟漏桶算法,记录完整工作过程"""
if not request_times:
return [], [], [], []
max_time = max(request_times) + 6
dt = 0.01
times = np.arange(0, max_time, dt)
water_levels = []
input_events = []
output_events = []
rejected_events = []
current_water = 0
request_idx = 0
for t in times:
while request_idx < len(request_times) and abs(request_times[request_idx] - t) < dt/2:
if current_water < capacity:
current_water += 1
input_events.append((t, 1))
else:
rejected_events.append((t, 1))
request_idx += 1
leak_amount = rate * dt
leaked = min(current_water, leak_amount)
current_water -= leaked
if leaked > 0:
output_events.append((t, leaked))
water_levels.append(current_water)
return times, water_levels, input_events, output_events, rejected_events
def plot_bucket_level(capacity: int, rate: float, times, water_levels, input_events, rejected_events, total_requests: int):
"""图1:漏桶堆积曲线"""
fig, ax = plt.subplots(figsize=(14, 7))
fig.patch.set_facecolor('#f8f9fa')
ax.set_facecolor('#ffffff')
# 蓝色填充区域:桶内请求堆积
ax.fill_between(times, water_levels, alpha=0.4, color='#3498db')
ax.plot(times, water_levels, 'b-', linewidth=2, label='桶内请求数')
# 红色虚线:容量上限
ax.axhline(y=capacity, color='#e74c3c', linestyle='--', linewidth=2, label=f'容量上限 ({capacity})')
# 绿色点线:处理速率
ax.axhline(y=rate, color='#27ae60', linestyle=':', linewidth=2, label=f'处理速率 ({rate}/s)')
# 红色阴影区域:桶满时期
overflow_mask = np.array(water_levels) >= capacity
if np.any(overflow_mask):
start_idx = np.where(overflow_mask)[0][0]
end_idx = np.where(overflow_mask)[0][-1]
ax.axvspan(times[start_idx], times[end_idx], alpha=0.15, color='red')
ax.text((times[start_idx] + times[end_idx]) / 2, capacity + 0.5,
'桶满! 请求被拒绝', ha='center', fontsize=11, color='#e74c3c', fontweight='bold')
# 竖线标记请求到达
for t, _ in input_events:
ax.axvline(x=t, color='#3498db', alpha=0.4, linewidth=1)
# X标记拒绝的请求
for t, _ in rejected_events:
ax.scatter(t, capacity + 0.5, color='#e74c3c', s=80, marker='x', zorder=5)
ax.scatter([], [], color='#e74c3c', s=80, marker='x', label=f'被拒绝({len(rejected_events)}个)')
# 添加解释注解框
annotation_text = (
"【图例说明】\n"
"• 蓝色区域:桶内堆积的请求数量\n"
"• 红色虚线:漏桶容量上限,超出则拒绝\n"
"• 绿色点线:漏桶处理速率(匀速输出)\n"
"• 红色阴影:桶满时期,新请求被拒绝"
)
ax.text(0.02, 0.98, annotation_text, transform=ax.transAxes, fontsize=9,
verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.8))
ax.set_xlabel('时间 (秒)', fontsize=12)
ax.set_ylabel('请求数', fontsize=12)
ax.set_title(f'漏桶堆积过程 (容量={capacity}, 速率={rate}/s)\n{total_requests}个请求,每0.1秒到达1个',
fontsize=14, fontweight='bold', color='#2c3e50', pad=10)
ax.legend(loc='upper right')
ax.set_xlim(0, max(times))
ax.set_ylim(0, min(capacity * 2, 15))
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('图1-漏桶堆积曲线.png', dpi=300, bbox_inches='tight', facecolor='#f8f9fa')
plt.show()
print("✅ 图1已保存: 图1-漏桶堆积曲线.png")
def plot_flow_comparison(capacity: int, rate: float, times, input_events, output_events, rejected_events, total_requests: int):
"""图2:流量整形对比"""
fig, ax = plt.subplots(figsize=(14, 7))
fig.patch.set_facecolor('#f8f9fa')
ax.set_facecolor('#ffffff')
input_rate = np.zeros_like(times)
for t, _ in input_events:
mask = (times >= t - 0.5) & (times < t + 0.5)
input_rate[mask] += 1
output_rate = np.zeros_like(times)
for t, amount in output_events:
mask = (times >= t - 0.2) & (times < t + 0.2)
output_rate[mask] += amount * 5
# 红色填充:输入速率
ax.fill_between(times, input_rate, alpha=0.3, color='#e74c3c')
ax.plot(times, input_rate, 'r-', linewidth=2, label='输入速率(突发)')
# 绿色线:输出速率
ax.plot(times, output_rate, 'g-', linewidth=2.5, label='输出速率(恒定)')
# 绿色虚线:固定输出速率
ax.axhline(y=rate, color='#27ae60', linestyle='--', linewidth=2, alpha=0.7)
ax.text(max(times) * 0.85, rate + 0.3, f'固定输出={rate}/s', fontsize=10, color='#27ae60')
# X标记拒绝的请求
for t, _ in rejected_events:
ax.axvline(x=t, color='#e74c3c', alpha=0.5, linewidth=2, linestyle=':')
ax.scatter(t, rate + 1, color='#e74c3c', s=100, marker='x', zorder=5)
if rejected_events:
ax.scatter([], [], color='#e74c3c', s=100, marker='x', label=f'被拒绝({len(rejected_events)}个)')
# 添加解释注解框
annotation_text = (
"【图例说明】\n"
"• 红色曲线:请求到达速率(突发)\n"
"• 绿色曲线:漏桶输出速率(恒定)\n"
"• 漏桶将突发流量整形为均匀输出\n"
"• 桶满时请求被拒绝(X标记)"
)
ax.text(0.02, 0.98, annotation_text, transform=ax.transAxes, fontsize=9,
verticalalignment='top', bbox=dict(boxstyle='round', facecolor='honeydew', alpha=0.8))
ax.set_xlabel('时间 (秒)', fontsize=12)
ax.set_ylabel('请求速率 (req/s)', fontsize=12)
ax.set_title(f'流量整形效果对比 (容量={capacity}, 速率={rate}/s)\n{total_requests}个请求:突发流量被整形为恒定输出',
fontsize=14, fontweight='bold', color='#2c3e50', pad=10)
ax.legend(loc='upper right')
ax.set_xlim(0, max(times))
ax.set_ylim(0, max(max(input_rate) if len(input_rate) > 0 else 1, rate + 3))
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('图2-流量整形对比.png', dpi=300, bbox_inches='tight', facecolor='#f8f9fa')
plt.show()
print("✅ 图2已保存: 图2-流量整形对比.png")
def visualize_leaky_bucket():
"""可视化漏桶算法"""
# 使用示例中的参数: 容量=5, 速率=2
capacity = 5
rate = 2
total_requests = 20 # 20个请求
# 模拟20个请求,每0.1秒到达1个
request_times = [i * 0.1 for i in range(total_requests)]
times, water_levels, input_events, output_events, rejected_events = simulate_leaky_bucket(
capacity, rate, request_times
)
# 绘制两个独立的图
plot_bucket_level(capacity, rate, times, water_levels, input_events, rejected_events, total_requests)
plot_flow_comparison(capacity, rate, times, input_events, output_events, rejected_events, total_requests)
# ==================== 大模型场景测试 ====================
# 配置:漏桶容量=5(最多等待5个请求),每秒处理2个大模型推理请求
llm_leaky_bucket = LeakyBucket4LLM(capacity=5, rate=2)
# 记录入队和被处理的请求
request_log = [] # [(req_id, status, relative_time), ...]
log_lock = threading.Lock()
def llm_inference_request(req_id: int, start_time: float):
"""模拟大模型推理请求"""
if llm_leaky_bucket.allow_request():
with log_lock:
request_log.append((req_id, '入队', time.time() - start_time))
else:
with log_lock:
request_log.append((req_id, '拒绝', time.time() - start_time))
if __name__ == "__main__":
# 先显示可视化图
visualize_leaky_bucket()
# 测试限流功能
total_requests = 20
print("\n" + "="*50)
print(f"开始模拟{total_requests}个并发大模型请求...")
print("漏桶配置: 容量=5, 速率=2/s (每0.5秒处理1个请求)")
print("="*50)
start_time = time.time()
# 发送20个请求
for i in range(total_requests):
threading.Thread(target=llm_inference_request, args=(i, start_time)).start()
time.sleep(0.1)
# 等待所有请求处理完成
time.sleep(3)
# 按时间顺序打印日志
request_log.sort(key=lambda x: x[2])
for req_id, status, rel_time in request_log:
print(f"[{rel_time:.2f}s] 推理请求{req_id}:{'已入队,等待匀速处理' if status=='入队' else '限流拒绝,桶已满'}")
# 统计结果
queued = sum(1 for r in request_log if r[1] == '入队')
rejected = sum(1 for r in request_log if r[1] == '拒绝')
print("\n" + "="*50)
print(f"请求统计: 共{total_requests}个请求")
print(f" - 入队: {queued}个")
print(f" - 拒绝: {rejected}个")
print("="*50)输出结果:
==================================================
开始模拟20个并发大模型请求...
漏桶配置: 容量=5, 速率=2/s (每0.5秒处理1个请求)
==================================================
0.00s 推理请求0:已入队,等待匀速处理
0.10s 推理请求1:已入队,等待匀速处理
0.20s 推理请求2:已入队,等待匀速处理
0.30s 推理请求3:已入队,等待匀速处理
0.41s 推理请求4:已入队,等待匀速处理
0.51s 推理请求5:已入队,等待匀速处理
0.61s 推理请求6:已入队,等待匀速处理
0.71s 推理请求7:限流拒绝,桶已满
0.81s 推理请求8:限流拒绝,桶已满
0.92s 推理请求9:限流拒绝,桶已满
1.02s 推理请求10:已入队,等待匀速处理
1.12s 推理请求11:限流拒绝,桶已满
1.23s 推理请求12:限流拒绝,桶已满
1.33s 推理请求13:限流拒绝,桶已满
1.43s 推理请求14:限流拒绝,桶已满
1.53s 推理请求15:已入队,等待匀速处理
1.63s 推理请求16:限流拒绝,桶已满
1.73s 推理请求17:限流拒绝,桶已满
1.83s 推理请求18:限流拒绝,桶已满
1.93s 推理请求19:限流拒绝,桶已满
==================================================
请求统计: 共20个请求
入队: 9个
拒绝: 11个
==================================================
结果图示:
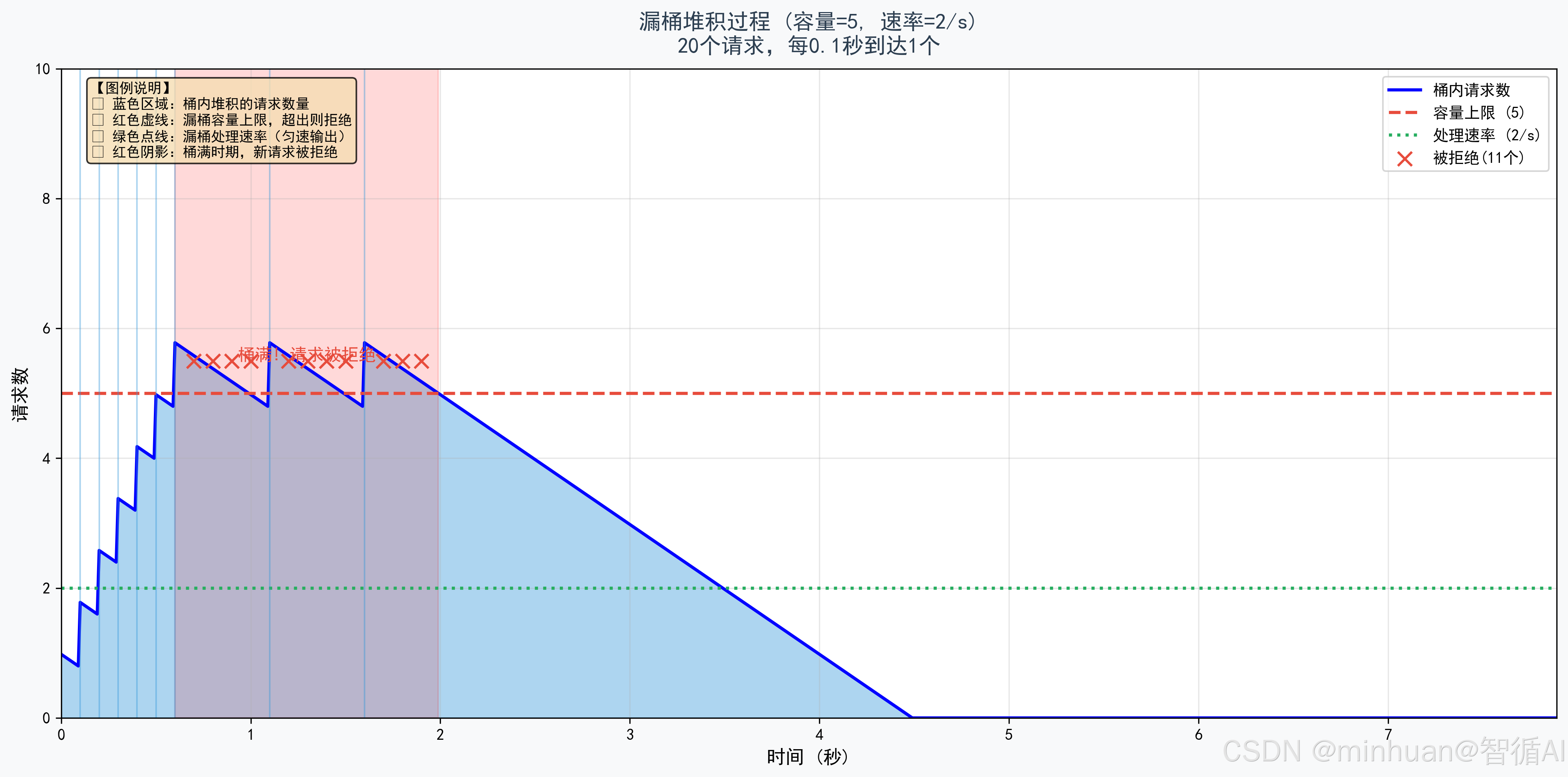
图示说明:展示漏桶容量从满到空的过程,蓝色区域表示堆积请求,红色虚线为容量上限。
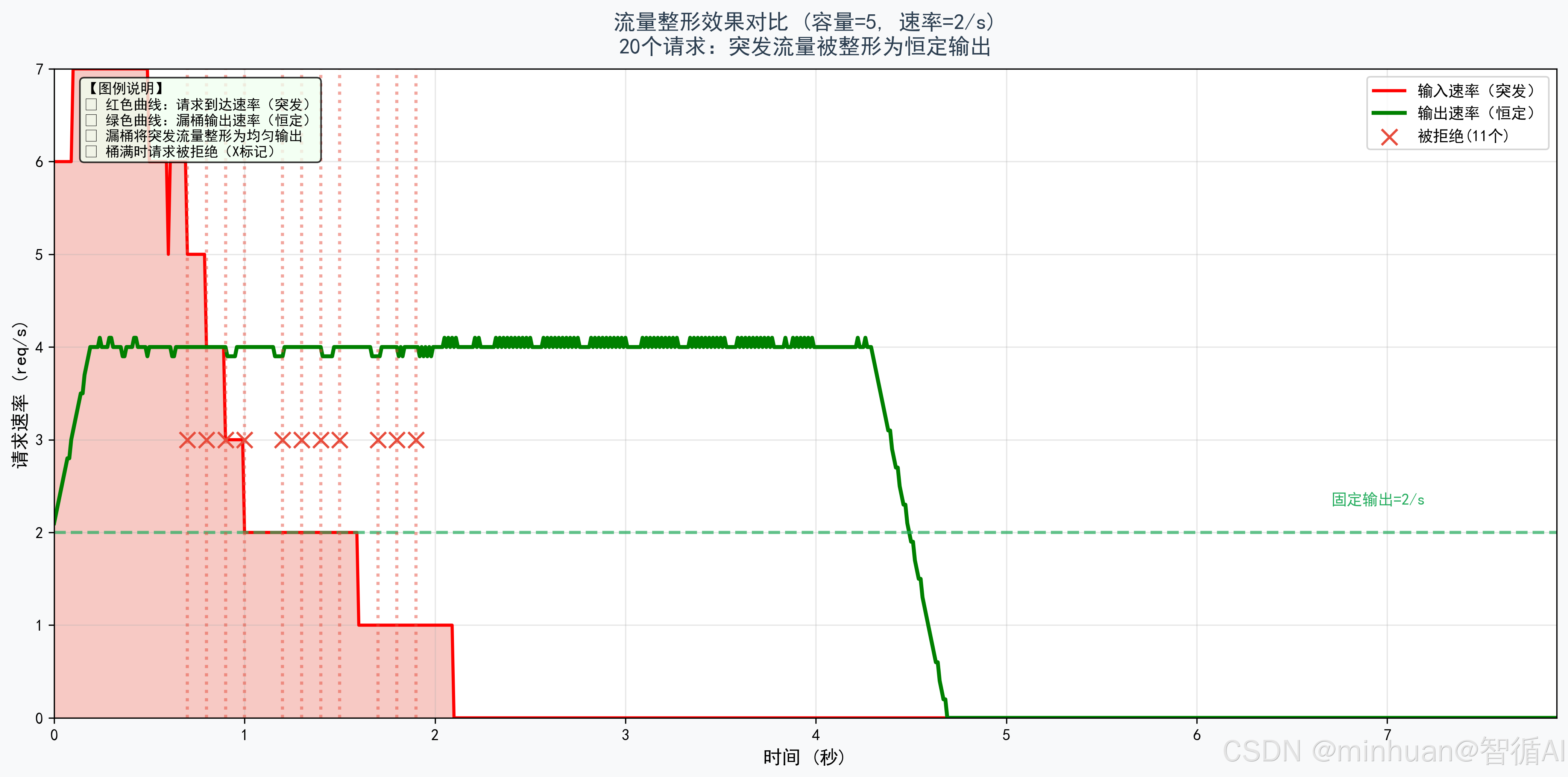
图示说明:对比突发输入(红色)与恒定输出(绿色),体现漏桶的流量整形效果。
三、令牌桶算法
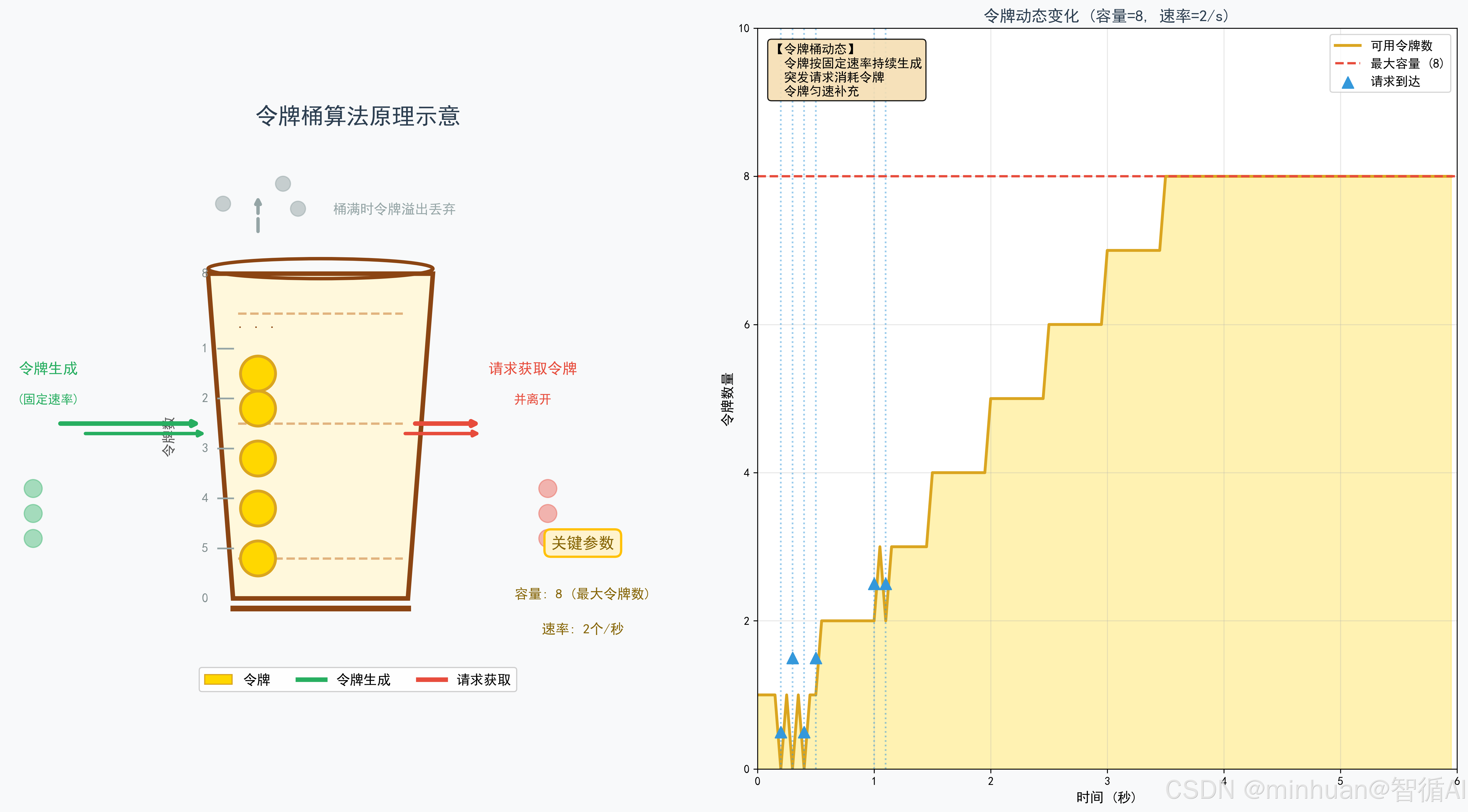
令牌桶算法是一种兼顾平滑性与突发弹性的流量控制方案。系统以恒定速率向桶中注入令牌,每个大模型请求需消耗令牌才能执行。它既限制了长期的平均请求速率,又允许在桶内有存量时应对短时高并发。
这种机制完美契合大模型API网关与交互式对话场景,是保障服务高可用的大模型应用首选。
1. 核心原理
令牌桶算法可以用自动发牌机类比:
- 令牌桶 = 存放推理权限的容器;
- 系统 = 以固定速率向桶内发放令牌;
- 大模型推理请求 = 必须拿到1个令牌才能执行;
- 桶满 = 多余令牌自动丢弃,不累积;
- 无令牌 = 请求被限流拒绝。
核心规则:空闲时累积令牌,突发时一次性消耗令牌,既保证算力平稳,又能应对业务流量波动。
2. 核心参数
针对大模型服务的令牌桶算法,以下是核心技术参数的详细说明,尽管从参数名称上看,和漏桶算法参数非常相似,都包含容量、速率、当前量、时间戳这四个核心维度,但在实际物理含义和底层逻辑上,两者有着本质的区别。
2.1 capacity:令牌桶最大容量
代表系统允许的最大突发处理能力。它决定了当大模型服务处于空闲状态时,最多能积攒多少令牌来应对瞬间涌入的高并发请求。
- 合理设置该值可以在保障系统不被突发流量打垮的同时,给予用户流畅的交互体验。
2.2 rate:令牌生成速率
代表系统长期允许的平均请求处理速率,例如每秒生成N个令牌。
- 该参数通常根据大模型的实际算力上限如GPU的推理吞吐量来设定,确保在长时间内,系统的请求处理量始终稳定在可承载的安全范围内。
2.3 tokens:当前可用令牌数
代表当前时刻桶内实际剩余的令牌数量。每当有新请求到达时,系统会尝试从中扣除相应数量的令牌;
- 若tokens充足则请求被立即处理,若令牌不足则触发限流,拒绝请求或排队等待。
2.4 last_time:上一次刷新令牌的时间戳
记录系统上一次计算并补充令牌的具体时间点。
- 在每次请求到达时,算法会结合当前时间与last_time的时间差,按固定速率推算出这段时间内应该新生成的令牌数量,从而精准更新当前的tokens存量。
3. 执行流程
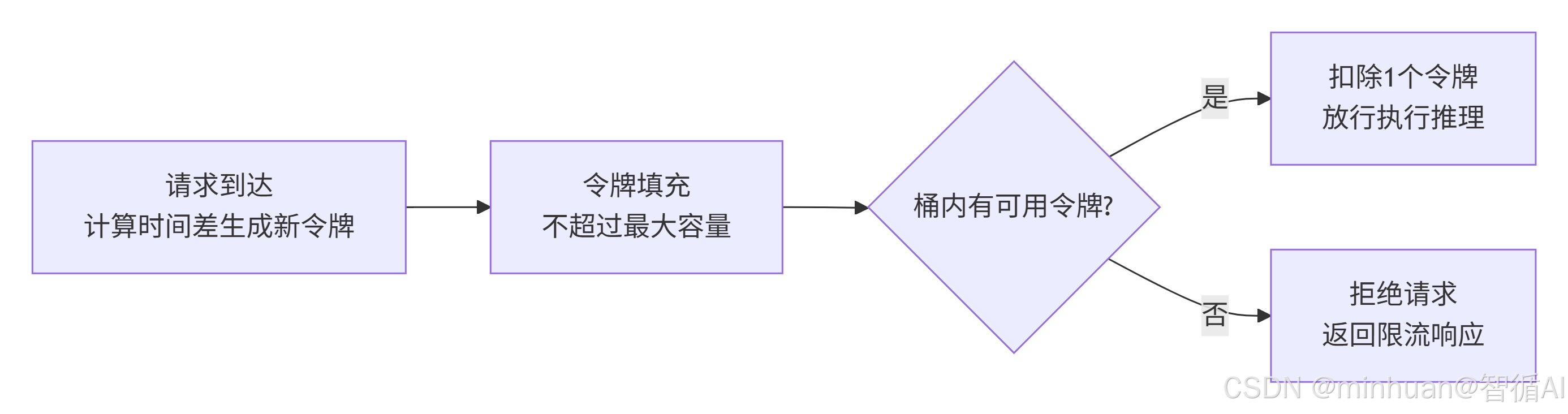
流程说明:
-
- 令牌刷新:请求到达时,根据时间差计算这段时间系统生成的新令牌;
-
- 令牌填充:将新令牌加入桶中,不超过最大容量;
-
- 令牌校验:判断桶内是否有可用令牌;
-
- 请求放行:有令牌则扣除1个令牌,允许执行大模型推理;
-
- 过载拒绝:无可用令牌,直接返回限流响应。
4. 算法特性
- 支持突发流量: 桶内累积的令牌可一次性消耗,适配大模型业务峰值。
- 它允许系统在空闲期积攒处理额度,当遇到瞬时高并发(如秒杀、热点事件)时,能迅速释放这些额度,避免大量正常请求被误杀。
- 算力负载可控: 平均处理速率固定,不会长期超出硬件承载能力。
- 虽然允许短时突发,但令牌的生成速率(长期平均速率)严格受控,确保了GPU等算力资源的长期利用率始终维持在安全线以内,防止系统被持续过载拖垮。
- 弹性适配性强: 可动态调整令牌生成速率,适配大模型算力负载变化。
- 在云原生环境中,可以根据当前集群的实际算力扩缩容情况,实时调大或调小令牌生成速率rate和桶容量capacity,实现灵活的流量治理。
- 线程安全与分布式友好: 高并发场景下通过锁或原子操作保证数据一致性,适配生产环境。
- 在单机多线程或分布式微服务架构中,能确保令牌扣减的准确性,防止因并发竞争导致限流失效。
5. 适用场景
- 大模型API服务:面向海量开发者开放的大模型接口,流量具有极强的不确定性。令牌桶既能限制每个用户的长期滥用,又能保证其在正常交互时的流畅体验。
- 多租户大模型平台:应对不同租户的突发流量。在SaaS化平台中,不同企业客户的调用高峰往往错开,令牌桶可以灵活地为每个租户分配突发额度,有效减少"嘈杂邻居"效应,保障平台整体的公平性。
- 电商、教育等有明显流量峰值的业务场景:例如在线教育平台的上课高峰期、电商大促期间的智能客服咨询。这些场景需要在特定时间段承受远超平时数倍的流量冲击,令牌桶的突发处理能力至关重要。
- 需要兼顾稳定性与用户体验的商业化大模型服务:对于直接面向C端用户的AI应用,如智能助手、AI写作工具,用户对延迟非常敏感。令牌桶能在保护后端模型不崩溃的前提下,最大程度地减少请求被拒绝的概率,从而提升用户满意度。
6. 应用实践
以下示例主要体现令牌桶算法在大模型限流中的应用:我们适配15个突发请求进入容量8、速率2/s的令牌桶,展示令牌生成与消耗过程,体现初始满桶时允许突发流量,无令牌时请求被拒绝。
python
import time
import threading
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
class TokenBucket:
"""令牌桶算法"""
def __init__(self, capacity: int, rate: float):
"""
令牌桶算法实现
:param capacity: 桶的最大容量(最大令牌数)
:param rate: 令牌生成速率(每秒生成的令牌数)
"""
self.capacity = capacity
self.rate = rate
self.tokens = float(capacity) # 初始令牌数(满桶)
self.last_time = time.time()
self.lock = threading.Lock()
def consume_token(self) -> bool:
"""
尝试消耗一个令牌
:return: 是否成功获取令牌
"""
with self.lock:
now = time.time()
# 计算新增的令牌数
time_diff = now - self.last_time
new_tokens = time_diff * self.rate
# 更新令牌数(不超过容量)
self.tokens = min(self.capacity, self.tokens + new_tokens)
self.last_time = now
# 尝试消耗令牌
if self.tokens >= 1:
self.tokens -= 1
return True
return False
def get_token_count(self) -> float:
"""获取当前令牌数"""
with self.lock:
return self.tokens
# ==================== 令牌桶可视化 ====================
def simulate_token_bucket(capacity: int, rate: float, request_times: list):
"""模拟令牌桶算法,记录完整工作过程"""
if not request_times:
return [], [], [], []
max_time = max(request_times) + 6
dt = 0.01
times = np.arange(0, max_time, dt)
token_levels = []
consume_events = []
generate_events = []
rejected_events = []
current_tokens = float(capacity)
next_generate_time = 0
for t in times:
# 生成令牌
if abs(t - next_generate_time) < dt/2 and current_tokens < capacity:
current_tokens = min(capacity, current_tokens + 1)
generate_events.append((t, 1))
next_generate_time += 1 / rate
# 尝试消耗令牌
for req_t in request_times:
if abs(t - req_t) < dt/2:
if current_tokens >= 1:
current_tokens -= 1
consume_events.append((t, 1))
else:
rejected_events.append((t, 1))
break
token_levels.append(current_tokens)
return times, token_levels, generate_events, consume_events, rejected_events
def plot_bucket_tokens(capacity: int, rate: float, times, token_levels, generate_events, consume_events, rejected_events, total_requests: int):
"""图1:令牌桶令牌变化"""
fig, ax = plt.subplots(figsize=(14, 7))
fig.patch.set_facecolor('#f8f9fa')
ax.set_facecolor('#ffffff')
# 填充区域表示令牌数
ax.fill_between(times, token_levels, alpha=0.3, color='#f39c12')
ax.plot(times, token_levels, color='#e67e22', linewidth=2, label='可用令牌数')
# 容量上限
ax.axhline(y=capacity, color='#e74c3c', linestyle='--', linewidth=2, label=f'容量上限 ({capacity})')
# 生成速率线
ax.axhline(y=rate, color='#27ae60', linestyle=':', linewidth=2, label=f'生成速率 ({rate}/s)')
# 令牌生成标记
for t, _ in generate_events:
ax.axvline(x=t, color='#27ae60', alpha=0.3, linewidth=1)
idx = int(t / 0.01)
if idx < len(token_levels):
ax.scatter(t, token_levels[idx] + 0.3, color='#27ae60', s=50, marker='^', zorder=5)
# 令牌消耗标记
for t, _ in consume_events:
ax.axvline(x=t, color='#3498db', alpha=0.3, linewidth=1)
idx = int(t / 0.01)
if idx < len(token_levels):
ax.scatter(t, token_levels[idx] - 0.3, color='#3498db', s=50, marker='v', zorder=5)
# 拒绝标记
for t, _ in rejected_events:
ax.scatter(t, -0.5, color='#e74c3c', s=100, marker='x', zorder=5)
ax.scatter([], [], color='#27ae60', s=50, marker='^', label=f'生成令牌({len(generate_events)}次)')
ax.scatter([], [], color='#3498db', s=50, marker='v', label=f'消耗令牌({len(consume_events)}次)')
ax.scatter([], [], color='#e74c3c', s=100, marker='x', label=f'拒绝请求({len(rejected_events)}次)')
# 注解框
annotation_text = (
"【图例说明】\n"
" 橙色曲线:桶内剩余令牌数\n"
" 红色虚线:容量上限,超出则丢弃\n"
" 绿色点线:令牌生成速率\n"
" ^ 标记:令牌生成\n"
" v 标记:令牌消耗\n"
" x 标记:无令牌时被拒绝"
)
ax.text(0.02, 0.98, annotation_text, transform=ax.transAxes, fontsize=10,
verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.9))
ax.set_xlabel('时间 (秒)', fontsize=12)
ax.set_ylabel('令牌数', fontsize=12)
ax.set_title(f'令牌桶令牌变化 (容量={capacity}, 速率={rate}/s)\n{total_requests}个请求,每0.2秒到达1个',
fontsize=14, fontweight='bold', color='#2c3e50', pad=10)
ax.legend(loc='upper right')
ax.set_xlim(0, max(times))
ax.set_ylim(-1, min(capacity * 2, 15))
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('图1-令牌桶变化.png', dpi=300, bbox_inches='tight', facecolor='#f8f9fa')
plt.show()
print("[OK] 图1已保存: 图1-令牌桶变化.png")
def plot_request_comparison(capacity: int, rate: float, times, generate_events, consume_events, rejected_events, total_requests: int):
"""图2:请求处理对比"""
fig, ax = plt.subplots(figsize=(14, 7))
fig.patch.set_facecolor('#f8f9fa')
ax.set_facecolor('#ffffff')
# 生成令牌速率
generate_rate = np.zeros_like(times)
for t, _ in generate_events:
mask = (times >= t - 0.5) & (times < t + 0.5)
generate_rate[mask] += 1
# 消耗令牌速率
consume_rate = np.zeros_like(times)
for t, _ in consume_events:
mask = (times >= t - 0.5) & (times < t + 0.5)
consume_rate[mask] += 1
# 固定生成速率线
ax.axhline(y=rate, color='#27ae60', linestyle='--', linewidth=2, alpha=0.7, label=f'固定生成速率={rate}/s')
# 填充:生成
ax.fill_between(times, generate_rate, alpha=0.3, color='#27ae60')
ax.plot(times, generate_rate, color='#27ae60', linewidth=2, label='令牌生成速率')
# 填充:消耗
ax.fill_between(times, consume_rate, alpha=0.3, color='#3498db')
ax.plot(times, consume_rate, color='#3498db', linewidth=2, label='令牌消耗速率')
# 拒绝标记
for t, _ in rejected_events:
ax.axvline(x=t, color='#e74c3c', alpha=0.5, linewidth=2, linestyle=':')
ax.scatter(t, rate + 1, color='#e74c3c', s=100, marker='x', zorder=5)
if rejected_events:
ax.scatter([], [], color='#e74c3c', s=100, marker='x', label=f'被拒绝({len(rejected_events)}次)')
# 注解框
annotation_text = (
"【令牌桶特点】\n"
" 令牌按固定速率持续生成\n"
" 允许突发:令牌积累后快速消费\n"
" 无令牌时请求被拒绝"
)
ax.text(0.02, 0.98, annotation_text, transform=ax.transAxes, fontsize=10,
verticalalignment='top', bbox=dict(boxstyle='round', facecolor='honeydew', alpha=0.9))
ax.set_xlabel('时间 (秒)', fontsize=12)
ax.set_ylabel('速率 (个/秒)', fontsize=12)
ax.set_title(f'请求处理对比 (容量={capacity}, 速率={rate}/s)\n{total_requests}个请求:允许突发流量,先积累后输出',
fontsize=14, fontweight='bold', color='#2c3e50', pad=10)
ax.legend(loc='upper right')
ax.set_xlim(0, max(times))
ax.set_ylim(0, max(max(generate_rate) if len(generate_rate) > 0 else 1,
max(consume_rate) if len(consume_rate) > 0 else 1, rate + 2))
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('图2-请求处理对比.png', dpi=300, bbox_inches='tight', facecolor='#f8f9fa')
plt.show()
print("[OK] 图2已保存: 图2-请求处理对比.png")
def visualize_token_bucket():
"""令牌桶可视化"""
capacity = 8
rate = 2
total_requests = 15
# 模拟15个请求,每0.2秒到达1个(突发)
request_times = [i * 0.2 for i in range(total_requests)]
times, token_levels, generate_events, consume_events, rejected_events = simulate_token_bucket(
capacity, rate, request_times
)
# 绘制图表
plot_bucket_tokens(capacity, rate, times, token_levels, generate_events, consume_events, rejected_events, total_requests)
plot_request_comparison(capacity, rate, times, generate_events, consume_events, rejected_events, total_requests)
# ==================== 大模型场景测试 ====================
# 配置:令牌桶容量=8(最多8个令牌),每秒生成2个令牌
llm_token_bucket = TokenBucket(capacity=8, rate=2)
# 记录日志
request_log = []
log_lock = threading.Lock()
def llm_inference_request(req_id: int, start_time: float):
"""模拟大模型推理请求"""
if llm_token_bucket.consume_token():
with log_lock:
request_log.append((req_id, '通过', time.time() - start_time))
print(f"[令牌桶] 推理请求{req_id}:获取令牌成功,处理中...")
time.sleep(0.3) # 模拟推理耗时
else:
with log_lock:
request_log.append((req_id, '拒绝', time.time() - start_time))
print(f"[令牌桶] 推理请求{req_id}:无令牌可用,请求被拒绝")
if __name__ == "__main__":
visualize_token_bucket()
# 测试限流功能
total_requests = 15
print("\n" + "=" * 60)
print(f"开始模拟{total_requests}个并发大模型请求...")
print("令牌桶配置: 容量=8, 生成速率=2/s (每0.5秒生成1个令牌)")
print("=" * 60)
start_time = time.time()
# 发送15个请求(突发)
for i in range(total_requests):
threading.Thread(target=llm_inference_request, args=(i, start_time)).start()
time.sleep(0.1) # 每0.1秒发送一个
# 等待所有请求处理完成
time.sleep(5)
# 按时间顺序打印日志
request_log.sort(key=lambda x: x[2])
print("\n" + "-" * 50)
print("请求处理日志:")
print("-" * 50)
for req_id, status, rel_time in request_log:
status_text = "通过" if status == '通过' else "拒绝"
print(f"[{rel_time:.2f}s] 推理请求{req_id}:{status_text}")
# 统计结果
passed = sum(1 for r in request_log if r[1] == '通过')
rejected = sum(1 for r in request_log if r[1] == '拒绝')
print("\n" + "=" * 60)
print(f"请求统计: 共{total_requests}个请求")
print(f" - 通过: {passed}个")
print(f" - 拒绝: {rejected}个")
print("=" * 60)输出结果:
============================================================
开始模拟15个并发大模型请求...
令牌桶配置: 容量=8, 生成速率=2/s (每0.5秒生成1个令牌)
============================================================
令牌桶 推理请求0:获取令牌成功,处理中...
令牌桶 推理请求1:获取令牌成功,处理中...
令牌桶 推理请求2:获取令牌成功,处理中...
令牌桶 推理请求3:获取令牌成功,处理中...
令牌桶 推理请求4:获取令牌成功,处理中...
令牌桶 推理请求5:获取令牌成功,处理中...
令牌桶 推理请求6:获取令牌成功,处理中...
令牌桶 推理请求7:获取令牌成功,处理中...
令牌桶 推理请求8:获取令牌成功,处理中...
令牌桶 推理请求9:无令牌可用,请求被拒绝
令牌桶 推理请求10:获取令牌成功,处理中...
令牌桶 推理请求11:无令牌可用,请求被拒绝
令牌桶 推理请求12:无令牌可用,请求被拒绝
令牌桶 推理请求13:无令牌可用,请求被拒绝
令牌桶 推理请求14:无令牌可用,请求被拒绝
请求处理日志:
0.00s 推理请求0:通过
0.12s 推理请求1:通过
0.26s 推理请求2:通过
0.36s 推理请求3:通过
0.46s 推理请求4:通过
0.56s 推理请求5:通过
0.66s 推理请求6:通过
0.77s 推理请求7:通过
0.87s 推理请求8:通过
0.97s 推理请求9:拒绝
1.07s 推理请求10:通过
1.17s 推理请求11:拒绝
1.27s 推理请求12:拒绝
1.37s 推理请求13:拒绝
1.47s 推理请求14:拒绝
============================================================
请求统计: 共15个请求
通过: 10个
拒绝: 5个
============================================================
图示结果:
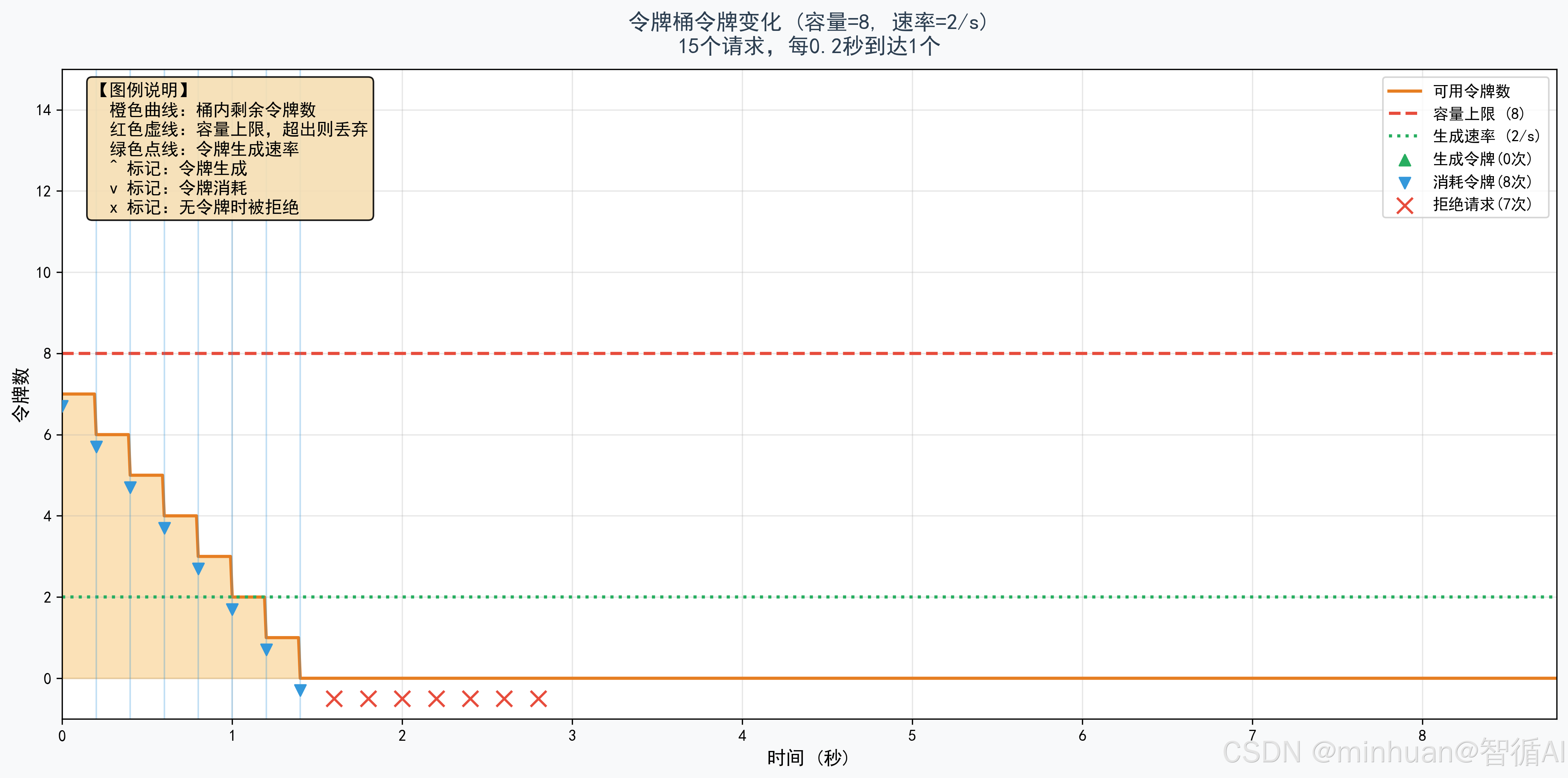
图示说明:令牌桶变化:展示令牌数随时间变化,^标记生成、v标记消耗、x标记拒绝
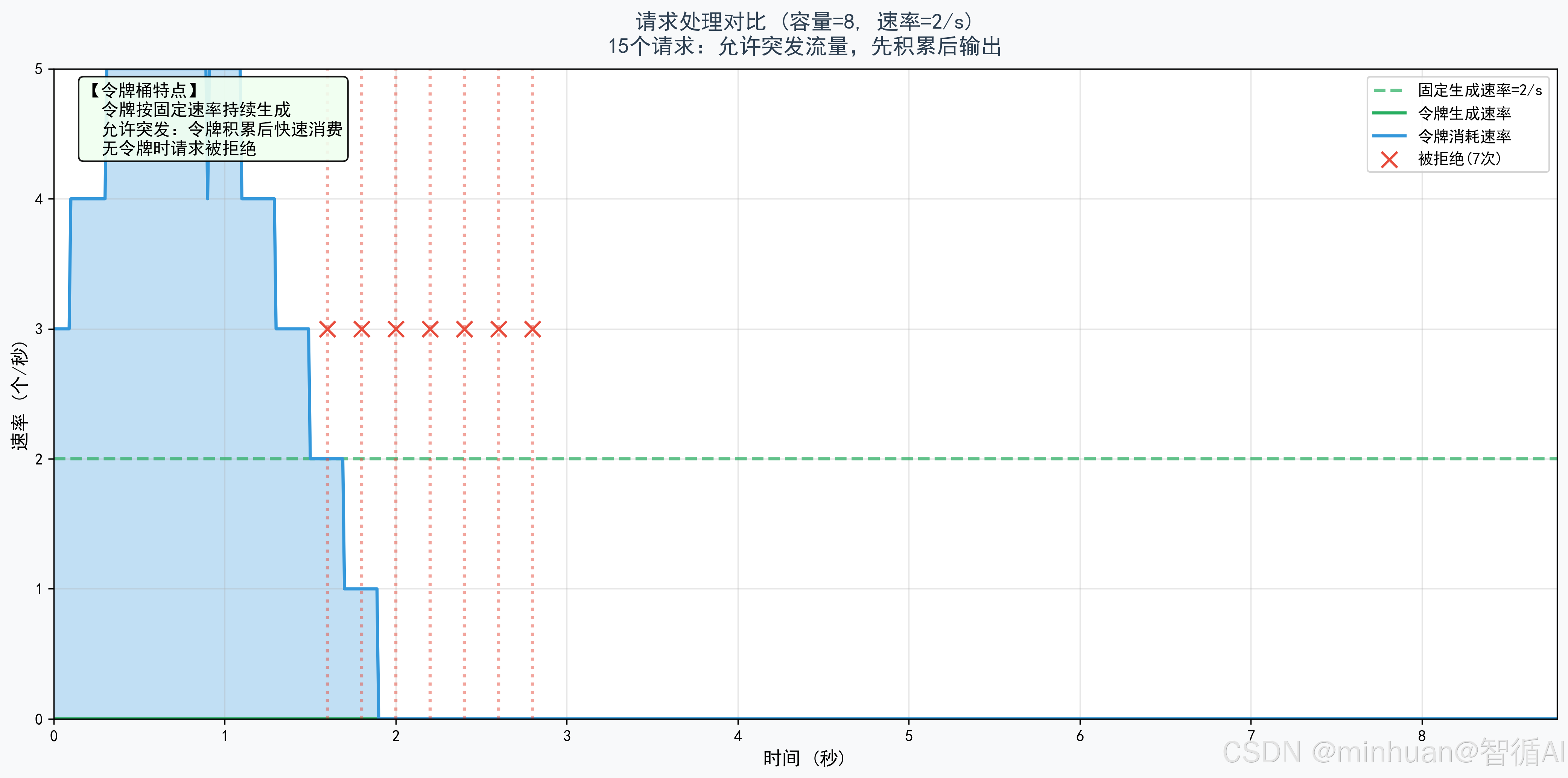
图示说明:请求处理对比:对比令牌生成速率与消耗速率
四、适应性对比
1. 核心维度对比
| 对比维度 | 漏桶算法 | 令牌桶算法 |
|---|---|---|
| 流量处理方式 | 强制固定速率,无突发能力 | 固定平均速率,支持瞬时突发 |
| 算力负载波动 | 绝对平稳,无波动 | 瞬时可冲高,长期平稳 |
| 大模型适配性 | 静态小模型、私有部署 | 90% 生产级大模型服务首选 |
| 实现复杂度 | 极低,逻辑简单 | 较低,易扩展 |
| 显存保护能力 | 最强,杜绝瞬时过载 | 强,可控范围内允许突发 |
| 多租户场景 | 不适用,无法弹性分配 | 完美适配,支持租户独立限流 |
| 典型应用 | 长上下文静态推理、科研模型 | 商用 API、高并发平台、SSE 流式接口 |
2. 差异说明
2.1 突发流量处理能力
- 漏桶算法完全拒绝突发流量,所有请求排队匀速处理,适合无流量波动的场景;
- 令牌桶算法在空闲时累积令牌,突发流量可一次性消耗存量令牌,完美适配大模型业务的流量峰值。
2.2 算力资源利用效率
- 漏桶算法算力利用率固定,空闲时段资源无法复用;
- 令牌桶算法可充分利用空闲算力,在低峰期累积令牌,高峰期提升处理效率,算力利用率更高,更适合商业化大模型。
2.3 大模型推理适配性
- 大模型推理的核心痛点是流量波动 + 硬件不可扩容,漏桶过于僵化,会导致用户等待时间过长;
- 令牌桶既限制了平均算力消耗,又能提升用户体验,是行业标准方案。
3. 选型建议
- 优先选择令牌桶算法:商用大模型、多租户平台、高并发接口、流式接口全部使用令牌桶;
- 选择漏桶算法:单用户私有部署、小算力硬件、长上下文静态推理、对稳定性要求极致的场景;
- 组合使用:核心推理引擎用漏桶保证算力平稳,网关层用令牌桶应对突发流量,实现双层防护。
五、总结
漏桶和令牌桶两大限流算法是大模型流量治理绕不开的底层根基,不是简单的接口限流那么浅显。漏桶核心特点是强制匀速、绝对平滑,不管外面请求多猛,都按固定节奏处理,能把大模型GPU算力、显存负载压得特别稳,特别适合长上下文推理、低配硬件私有部署这类求稳不求快的场景。而令牌桶刚好相反,空闲能攒令牌、高峰能扛突发流量,平均速率可控,又能兼容业务流量波动,现在绝大多数商用大模型 API、多租户平台基本都用它做主限流方案。
二者最关键的区别在于是否支持突发流量:漏桶一刀切限流,令牌桶弹性兼顾稳定与体验。实际应用要结合大模型GPU推理、显存占用、并发场景去思考选型逻辑。后续做服务开发、网关治理、高并发削峰时,才能精准判断什么时候用漏桶、什么时候用令牌桶,真正把理论落地到实践应用里。